- The paper presents a novel one-step inversion method that replaces random noise with semantically informed initialization to enhance inpainting.
- It introduces a re-blending operation and Gaussian regularization to maintain distributional consistency and mitigate harmonization failures.
- Experimental evaluations show improved IR and CLIP metrics with minimal overhead, rivaling results from multi-step baselines.
InverFill: One-Step Inversion for Enhanced Few-Step Diffusion Inpainting
Introduction and Motivation
Diffusion-based models have attained strong photorealistic fidelity in text-guided image inpainting, yet multi-step inference remains a significant bottleneck for real-time practical applications. Recent progress in distillation and consistency models provides few-step text-to-image generation, but inpainting using naïve blending approaches with such models produces severe harmonization failures and semantic misalignment between the masked region and surrounding context. This collapse stems from random Gaussian initialization, which, under the coarse updates of few-step denoising, fails to encode the structure and semantics of unmasked regions—unlike multi-step samplers that progressively adapt. The InverFill method directly addresses these failures by introducing an explicit one-step inversion network tailored for masked inpainting, providing semantically aligned inverted noise to initialize the denoising process. This approach bypasses the necessity for time-consuming task-specific retraining or cumbersome optimization, and maintains compatibility with off-the-shelf few-step text-to-image models.
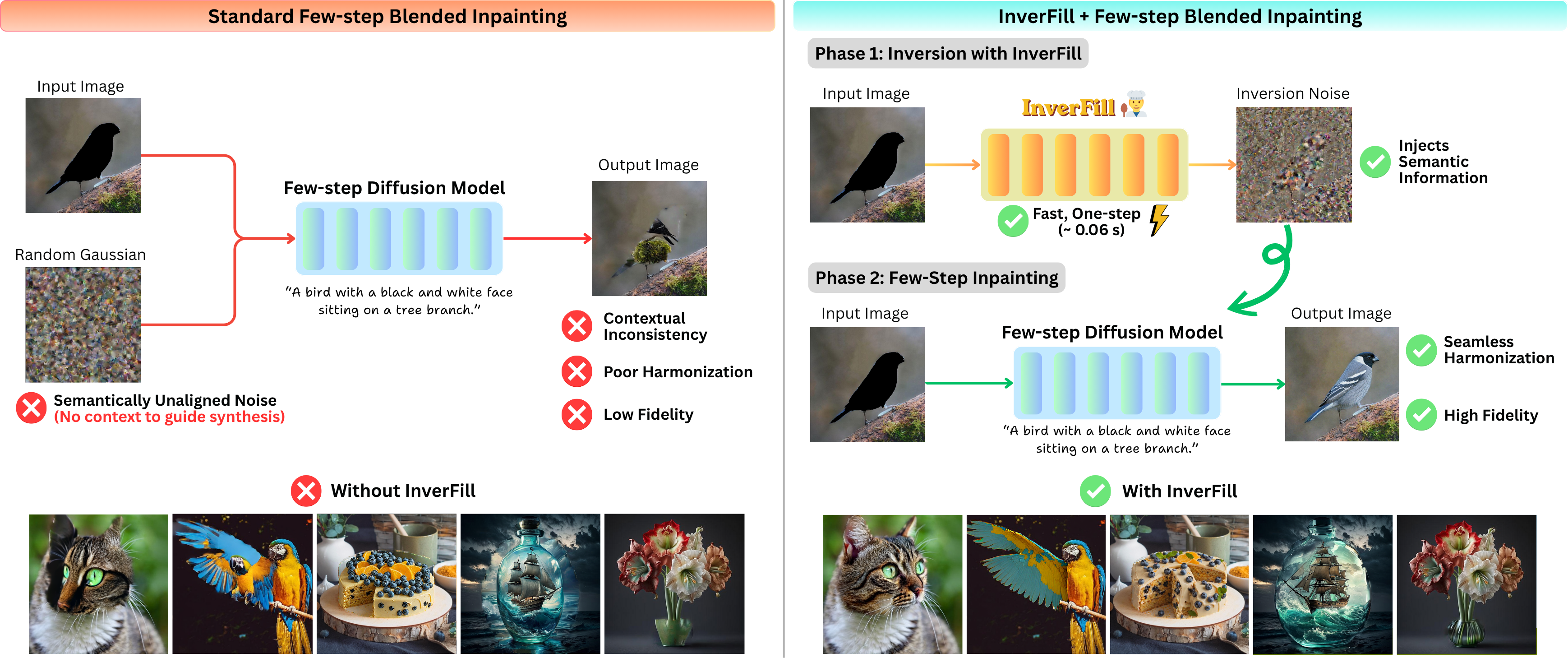
Figure 1: InverFill enhances few-step inpainting by generating semantically aligned inverted noise latents, while adding as little as 0.06 seconds of overhead on a single NVIDIA A100 40GB GPU.
Theoretical Foundations and Methodology
Blended Sampling Failure Analysis
Vanilla blended latent diffusion (BLD) operates by iteratively replacing denoised masked regions at each sampling step and works reasonably well for multi-step models. However, in the few-step setting, the limited number of iterations yields a catastrophic lack of harmonization, with visible artifacts and lack of semantic integration due to poor noise initialization.

Figure 2: Failure of BLD in few-step models (SDXL-Turbo, 4 steps) is illustrated in Column 3 and corrected by InverFill in Column 4. (Zoom in for details)
InverFill Inversion Architecture
The key insight is that, instead of initializing from pure Gaussian noise, the initial latent should encode semantic structure from the masked input. InverFill employs a one-step inversion network Fθ, with architectural and weight inheritance from the generator, that is trained to map the masked VAE-encoded latent to an inverted noise latent. Training is performed using text prompts and synthetic masks, with losses applied only over unmasked regions to avoid bias and information leakage. The addition of adversarial and image-level supervision further stabilizes optimization and improves perceptual quality.
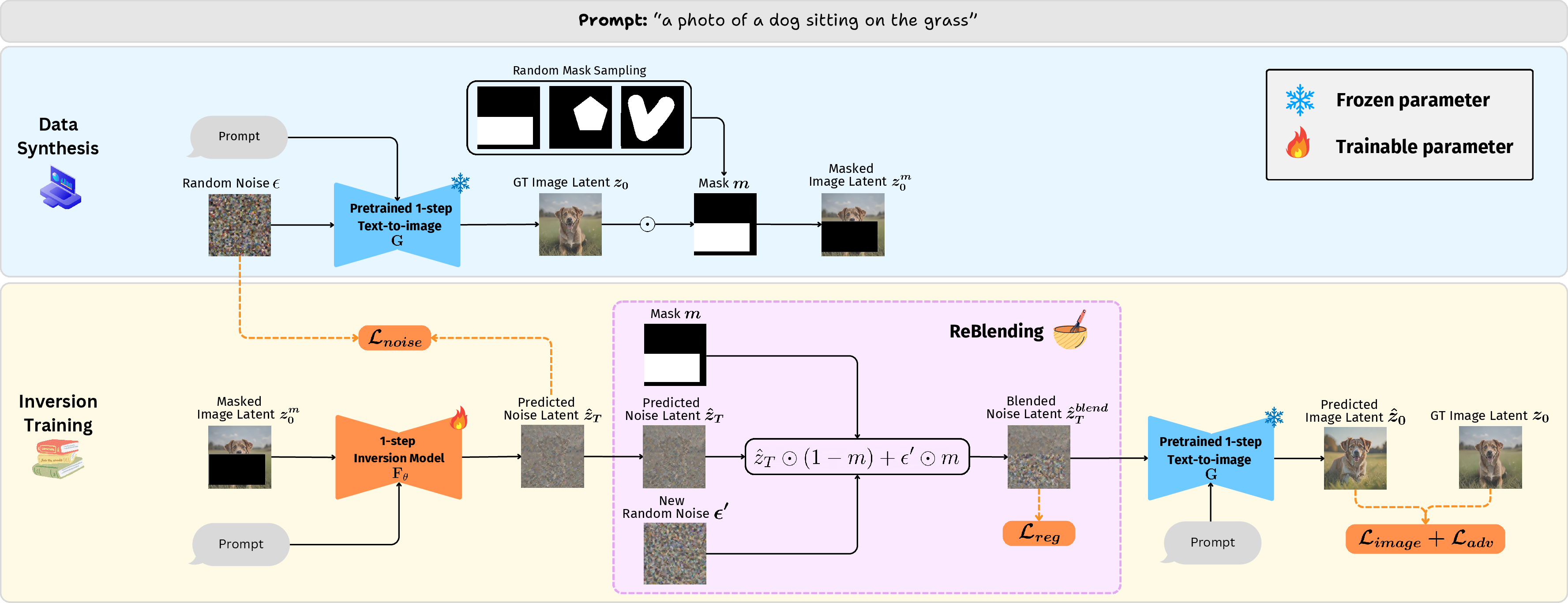
Figure 3: Inversion Network Training: The inversion network is trained to invert a masked image to an inverted noise latent that enables high-fidelity, well-harmonized reconstruction upon denoising.
Re-Blending and Gaussian Regularization
Masked-loss optimization leads to low-variance, out-of-distribution behavior in the masked latent regions. To address this, InverFill proposes a Re-Blending operation: masked areas of the predicted noise latent are replaced with random noise at each training iteration, restoring alignment with the Gaussian prior expected in generative sampling. Nonetheless, this is insufficient for consistently faithful reconstruction. A moment-based Gaussian regularization loss is introduced, matching the mean and variance of the blended latent distribution to those of standard Gaussian noise, and mitigating residual distributional mismatches.

Figure 4: Effects of the proposed Re-Blending operation during training, without Gaussian regularization, show partial improvements but incomplete preservation of content.

Figure 5: Ablation Study on Gaussian regularization: With the loss, background and fine details are preserved; without, the output is blurred and of low fidelity.
Inpainting Pipeline
At inference, the masked image is encoded, processed through the inversion network, merged via Re-Blending, and used as initialization to the standard few-step inpainting pipeline using blended infilling. This rectifies the harmonization issues present in direct blending with random initialization.
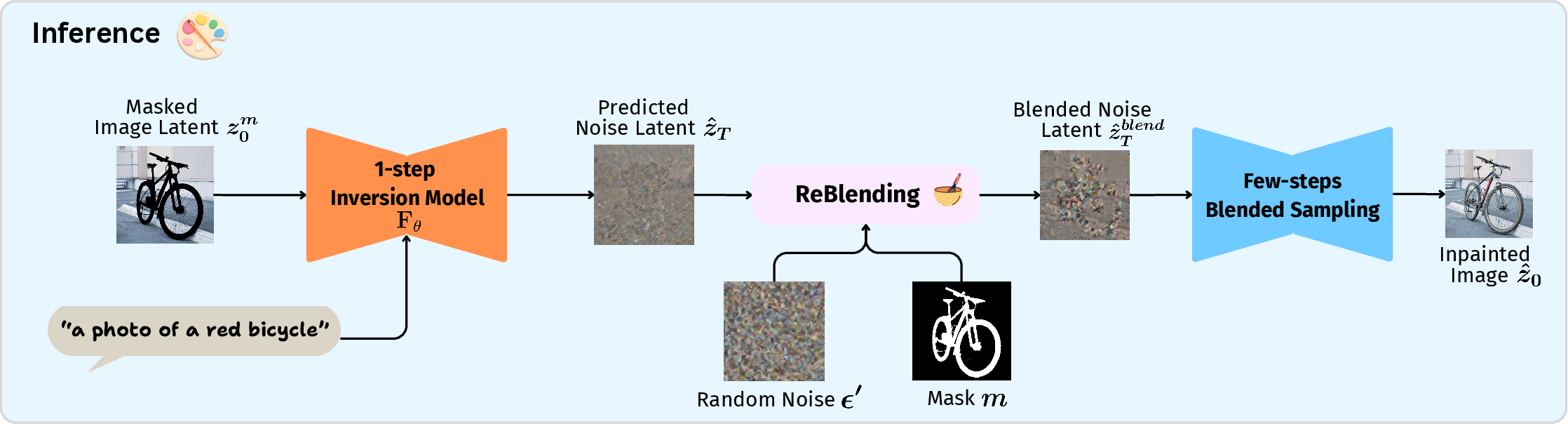
Figure 6: Inpainting Pipeline: The inversion network extracts the latent from a masked image, which is then blended and used to initialize the few-step inpainting pipeline.
Experimental Evaluation
Quantitative Analysis
In extensive evaluations on BrushBench and MagicBrush, InverFill integrated with both SANA-Sprint and SDXL-Turbo in two- and four-step regimes consistently improves perceptual (IR, HPS, AS) and text-image alignment (CLIP) metrics. Notably, with only 2 function evaluations (NFEs) on SANA-Sprint, IR increases from 11.02 to 11.65; with 4 NFEs on SDXL-Turbo, IR jumps from 11.42 to 12.38 and CLIP scores rise as well. These improvements are maintained with negligible (<0.06s) runtime overhead.
Qualitative Analysis
InverFill achieves image harmonization and semantic consistency competitive with multi-step and task-specific finetuned solutions, despite training with only text-based supervision and without explicit image-mask-prompt triples.

Figure 7: InverFill yields results comparable to multi-step SDXL-Inpainting and is on par with BrushNet (4 steps), despite training only with text prompts.
Additional ablation confirms the independent and joint contribution of Re-Blending and Gaussian regularization. Direct application of prior iterative inversion schemes (e.g., DDIM Inversion) fails to encode the masked regions and produces blank or incoherent inpainting. The adversarial loss further sharpens details and improves alignment without collapse.
Robustness, Failure Cases, and Generalization
The method demonstrates robustness to complex, compositional language prompts on BrushBench, yields high-fidelity reconstructions across datasets (FFHQ, DIV2K), and is agnostic to backbone architecture. Principal failure mode arises as occasional color inconsistency between inpainted and background regions, indicating room for future refinement.

Figure 8: Representative failure cases of InverFill, whereby color mismatches between inpainted and background regions may arise.
Implications and Future Outlook
The explicit use of a one-step masked inversion model tailored for inpainting fundamentally overcomes the harmonization challenge in few-step diffusion, a limiting factor for practical high-resolution editing and real-time creative applications. By removing the requirement for curation of image-mask-text datasets, the solution is attractive for widespread deployment and further scaling.
Practically, InverFill substantially reduces the barrier for interactive, user-facing image editing tools, enabling rapid semantic inpainting with quality previously achievable only with costly multi-step or dedicated models. Theoretically, the approach demonstrates the utility of distributional alignment and architecture-cognate inversion networks for the adaptation of fast generative models to spatially conditioned tasks. There is clear potential for extending this methodology to other conditional generation domains (e.g., outpainting, text-driven editing, video inpainting), and for further integration of advanced regularization and semantic guidance.
Conclusion
InverFill presents a rigorously structured approach to one-step inversion for few-step inpainting, solving the persistent issue of poor context integration in accelerated diffusion pipelines. Empirically, it achieves on-par or superior results to multi-step baselines and specialized inpainting models while maintaining negligible computational overhead and avoiding complex supervision, positioning it as a practical and theoretically meaningful advance for both diffusion model research and deployment in interactive generative systems.