- The paper introduces a tuning-free method that directly optimizes diffusion latents to improve prompt alignment in image inpainting.
- It employs Prior-Guided Noise Optimization and Decomposed Training-Free Guidance to focus attention on masked regions and adjust visual outputs in real time.
- Experimental results on datasets like EditBench and MSCOCO demonstrate substantial gains in ImageReward, CLIPScore, and InpaintReward metrics.
Detailed Summary of "FreeInpaint: Tuning-free Prompt Alignment and Visual Rationality Enhancement in Image Inpainting"
Introduction
The paper "FreeInpaint: Tuning-free Prompt Alignment and Visual Rationality Enhancement in Image Inpainting" (2512.21104) introduces a novel approach to the text-guided image inpainting problem. Traditional methods often struggle to balance prompt alignment and visual rationality. Existing models typically rely on pre-trained diffusion models, which, despite generating visually appealing outcomes, fall short of achieving precise alignment with user-defined text prompts. FreeInpaint circumvents these challenges by directly optimizing diffusion latents during inference without the need for additional tuning or training.
Methodology
FreeInpaint's methodology is structurally divided into two main components: Prior-Guided Noise Optimization (PriNo) and Decomposed Training-Free Guidance (DeGu).
Prior-Guided Noise Optimization
PriNo addresses the issue of prompt misalignment by optimizing initial noise, thereby steering the model's attention towards regions requiring inpainting. Unlike traditional approaches that experience scattered or misdirected attention, PriNo focuses on concentrating cross and self-attention on the masked regions. This optimization is performed at the initial stages of denoising, ensuring early incorporation of prompt-specific features.

















Figure 1: Visualization of cross-attention (cols 3-4) and self-attention (cols 5-6). Row 2 shows misdirected attention causing an unaligned result, while row 3 shows our optimized noise concentrates attention for a successful alignment.
Decomposed Training-Free Guidance
DeGu further refines inpainting by decomposing the conditioning of the inpainting process into three separate objectives: text alignment, visual rationality, and human preference. Each objective is steered using differentiable reward models, allowing the diffusion latents to be adjusted in real-time during the denoising process. This decomposition facilitates task-specific alignment, enhancing the overall coherence and aesthetic quality of the output.
Experimental Results
The effectiveness of FreeInpaint is demonstrated through extensive experiments across various datasets such as EditBench and MSCOCO. The model is evaluated against multiple baselines, including SDI, PPT, BN, SDXLI, and SD3I, showcasing substantial improvements in metrics related to human preference (ImageReward), prompt alignment (CLIPScore), and visual rationality (InpaintReward).





















Figure 2: Comparisons between our FreeInpaint and existing methods. FreeInpaint simultaneously enhances prompt alignment and visual rationality.
Sensitivity Analysis
The paper also investigates the sensitivity of PriNo's self-attention loss weight and DeGu's guidance weights, confirming that FreeInpaint maintains robustness across a wide range of hyperparameter settings. This flexibility underlines its adaptability to different inpainting tasks and architectures, including both U-Net and transformer-based models.
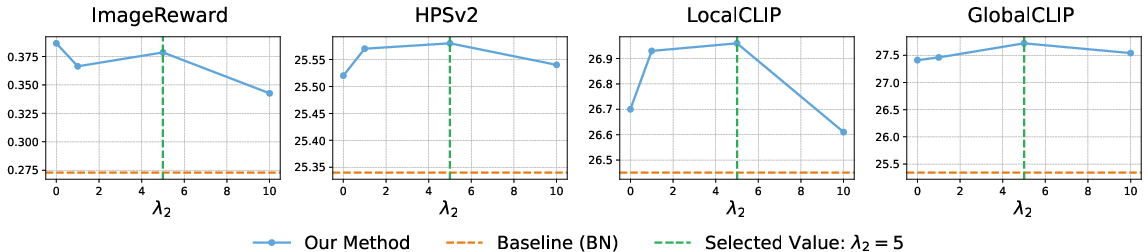
Figure 3: The sensitivity analysis of the Ls weight λ2.
Conclusion
FreeInpaint establishes a practical and effective framework for image inpainting, uniquely combining tuning-free optimization techniques with strategically decomposed guidance goals. It achieves a balanced improvement across multiple critical dimensions of inpainting, setting a precedent for future tuning-free methodologies in the domain of text-guided image editing.
The proposed method offers a significant leap forward by achieving superior prompt alignment and visual rationality without additional model tuning or retraining needs, thereby advancing the practicality and accessibility of high-quality text-guided image manipulation models in various applications.

