CAM3R: Camera-Agnostic Model for 3D Reconstruction
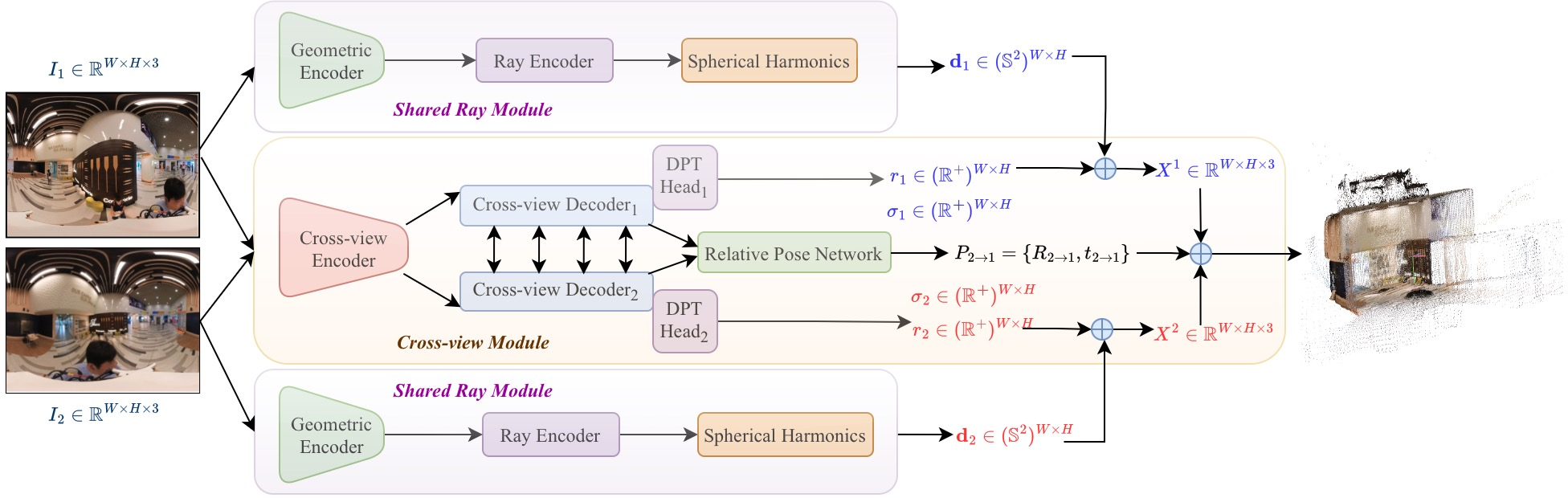
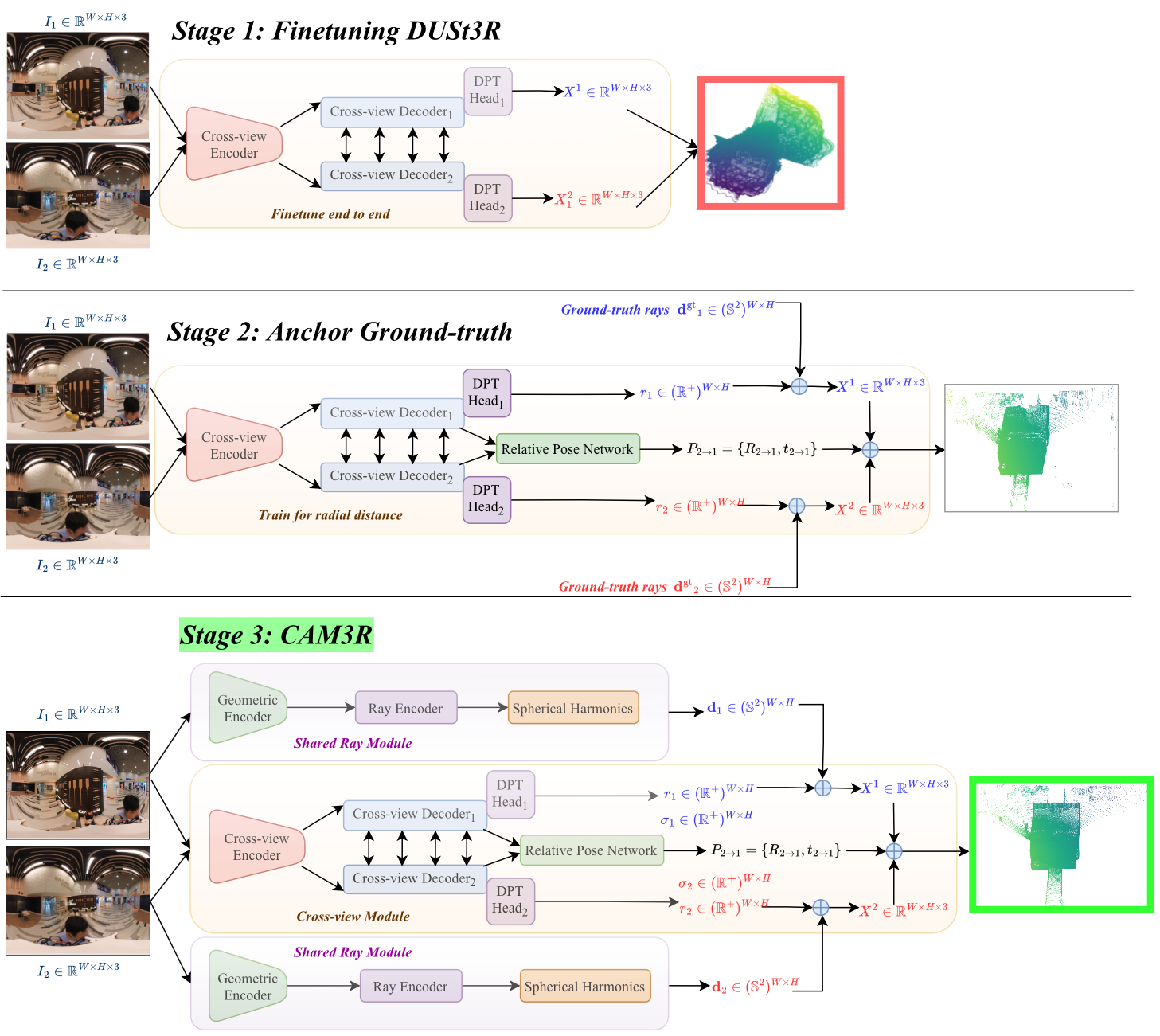
Abstract: Recovering dense 3D geometry from unposed images remains a foundational challenge in computer vision. Current state-of-the-art models are predominantly trained on perspective datasets, which implicitly constrains them to a standard pinhole camera geometry. As a result, these models suffer from significant geometric degradation when applied to wide-angle imagery captured via non-rectilinear optics, such as fisheye or panoramic sensors. To address this, we present CAM3R, a Camera-Agnostic, feed-forward Model for 3D Reconstruction capable of processing images from wide-angle camera models without prior calibration. Our framework consists of a two-view network which is bifurcated into a Ray Module (RM) to estimate per-pixel ray directions and a Cross-view Module (CVM) to infer radial distance with confidence maps, pointmaps, and relative poses. To unify these pairwise predictions into a consistent 3D scene, we introduce a Ray-Aware Global Alignment framework for pose refinement and scale optimization while strictly preserving the predicted local geometry. Extensive experiments on various camera model datasets, including panorama, fisheye and pinhole imagery, demonstrate that CAM3R establishes a new state-of-the-art in pose estimation and reconstruction.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces CAM3R, a new computer vision model that builds 3D scenes from regular photos, even when the photos come from very different kinds of cameras. It works with standard “pinhole” cameras, wide-angle “fisheye” lenses, and full 360° panoramic cameras—without needing to know the camera’s settings in advance. In short, it turns pairs or groups of images into a 3D model in a fast, feed-forward way and stays accurate even when the images are heavily distorted by wide lenses.
What questions were the researchers trying to answer?
The team focused on two simple questions:
- Can we make a single 3D reconstruction model that works well on photos from many different camera types (not just normal pinhole cameras)?
- Can we combine pairs of such photos into a full 3D scene without slow, fragile steps that break on distorted images?
How did they do it?
To make this easy to understand, think of each photo as a map of “light directions” and “distances.”
- A “ray” is the direction light came from for a pixel in the image—like pointing a laser pointer from the camera into the world along which that pixel “looks.”
- A “radial distance” is how far along that ray the real-world point is.
CAM3R learns both of these from image pairs and then stitches the results together across many images.
Step 1: Learning from two images at a time
CAM3R has two main parts that work together on a pair of images:
- Ray Module (RM): For every pixel, it predicts the direction of the incoming light ray. This lets the model understand how a specific camera bends or distorts the view (for example, how fisheye lenses curve straight lines). Importantly, it learns this directly from the image and does not need the camera’s calibration numbers.
- Cross-view Module (CVM): This part compares the two images. It estimates:
- How far each visible point is along its ray (the distance),
- How confident it is in that distance,
- A “point map” (the 3D points seen from each camera),
- The relative pose (how the second camera is rotated and moved compared to the first).
Analogy: Imagine standing in two different spots in a room and pointing laser pointers at the walls and furniture. The RM learns which way to point for each pixel, and the CVM figures out how far to go along those pointers and how the two camera positions are related.
Step 2: Building a full 3D model from many images
When there are lots of images, CAM3R uses a process the authors call Ray-Aware Global Alignment:
- It builds a graph that connects image pairs that look at the same parts of the scene.
- It prunes bad connections (for example, if two photos don’t actually overlap or the pairwise estimates disagree).
- It then aligns all the cameras and their 3D points together by optimizing in “ray space,” which respects how wide-angle images bend lines. This reduces drift and keeps the structure of the scene consistent.
Why “ray-aware” matters: Many traditional methods assume a simple, straight projection (pinhole model). That breaks on fisheye or 360° images. CAM3R instead uses the learned rays directly, so it aligns what the camera really sees, no matter the lens.
What did they find, and why is it important?
Here are the main results in plain terms:
- Works across many camera types: CAM3R performs strongly on pinhole, fisheye, and panoramic images. It avoids the common failure of other models that assume a simple camera and then struggle on wide-angle views.
- Accurate pairwise geometry: On pairs of images, CAM3R more reliably recovers how the two cameras are positioned and oriented relative to each other, especially for challenging wide-angle and mixed-camera pairs. This is important for clean 3D point clouds.
- Better multi-view reconstructions: When combining many images, the model’s ray-aware alignment produces more stable camera paths and denser, cleaner 3D scenes, with less “drift” over time.
- Strong generalization: Even on datasets and camera types it didn’t train on (zero-shot), CAM3R stays competitive or better than popular baselines. That means it’s more likely to work “in the wild.”
Why this matters: Most modern 3D models are trained on regular photos and assume a simple camera. In real life, phones and action cameras often use wide lenses, and robots may carry mixed sensors. CAM3R’s camera-agnostic design means fewer failures and better 3D maps in practical situations.
What’s the bigger impact?
- Fewer “fussy” steps: CAM3R doesn’t need manual camera calibration or pre-processing to “undistort” images, which can stretch or throw away parts of the photo. That simplifies real-world pipelines.
- Broader compatibility: It can handle mixed sets of images—say, a panoramic photo plus a fisheye frame—making it more flexible for drones, AR/VR, robotics, and mapping.
- More reliable 3D: The ray-aware global alignment keeps scenes consistent, which is crucial for navigation, scene understanding, and 3D content creation.
In short, CAM3R takes an important step toward robust, fast 3D reconstruction that doesn’t break when cameras change, making it a promising tool for devices and apps that see the world in many different ways.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what the paper leaves missing, uncertain, or unexplored, formulated to guide follow-up research:
- Central-camera assumption: The ray formulation assumes a single optical center per image (central projection). How to extend CAM3R to non-central/generalized cameras (e.g., catadioptric, multi-perspective, pushbroom) or rolling-shutter sensors remains open.
- SH-based ray representation limits: The Ray Module models per-image ray fields via spherical harmonics with finite degree L. The trade-offs between L, fidelity for extreme/non-monotonic distortions, numerical stability, and overfitting are not analyzed; no ablation quantifies representation error or physical plausibility (e.g., ray-field monotonicity, non-crossing constraints).
- Unseen lens families and out-of-distribution optics: Generalization to lens types beyond the trained set (e.g., equidistant vs equisolid vs stereographic fisheye, anamorphic, mirror-based catadioptric, severe vignetting/chromatic aberration) is not studied; practical limits of “camera-agnostic” performance remain unclear.
- Real-world calibration noise vs synthetic augmentation: Training relies heavily on synthetic re-projections for wide-angle/panoramic/fisheye variants. The impact of mismatches between synthetic camera models and real lenses (e.g., decentering/tangential distortions, manufacturing tolerances) is unquantified.
- Confidence modeling gaps: Only radial-distance confidence is predicted; no uncertainty is modeled for ray directions or poses. The calibration of confidence scores (e.g., reliability diagrams, NLL) and their effect on pruning/optimization is not evaluated.
- Ambiguity in σ usage: The global objective uses edge-specific confidences σ_{i,j}(u), but the paper defines σ_i(u) per image. The mapping from per-image confidences to per-edge weights (and whether ray- or pose-uncertainty is included) is unspecified.
- Absolute scale recovery: CAM3R recovers geometry up to scale (per-image scales s_i in GA). There is no mechanism to recover metric scale or leverage auxiliary cues (gravity/IMU, object priors), nor analysis of scale drift in long sequences.
- Global alignment convergence and sensitivity: The alternating optimization lacks convergence guarantees, sensitivity analysis to initialization, or robustness studies under sparse/weakly connected graphs. Hyperparameters (e.g., τ_rot, 20% MNN threshold) are not ablated.
- Graph connectivity and failure modes: The strict pruning (e.g., MNN < 20% overlap) risks disconnecting the scene graph; strategies for ensuring connectivity, handling low-overlap/pure-rotation pairs, or recovering from pruning mistakes are not developed.
- Outlier robustness: The global objective uses L2 errors; no robust loss or heavy-tailed modeling is employed. Sensitivity to outliers in predicted geometry/poses is unquantified.
- “Preserve local geometry” constraint: The global alignment freezes local pointmaps/rays as priors, limiting correction of systematic local errors. Joint refinement of geometry and rays during global optimization is not explored.
- Scalability and runtime: Pairwise inference on exhaustive graphs is O(N2), followed by iterative global optimization. Runtime, memory, and scaling to large (103–105 image) datasets or online/incremental settings are not reported.
- Real-time feasibility: The paper mentions future intent for efficiency but provides no current timing benchmarks or profiling of the RM/CVM/GA pipeline.
- Dynamic and non-rigid scenes: Robustness to moving objects, people, vehicles, or non-rigid deformations is not evaluated; the impact of dynamics on pruning and global alignment remains unknown.
- Challenging photometrics and sensor artifacts: The method’s robustness to severe illumination changes, HDR, motion blur, noise, and exposure/gain discrepancies is not quantified.
- Detail-level 3D quality: Evaluation focuses on pose metrics (RRA/RTA/mAA/ATE). Depth/pointmap fidelity metrics (e.g., REL/RMSE, Chamfer distance, completeness, accuracy vs scans) and high-frequency detail preservation are not reported.
- Baseline coverage: Comparisons exclude classical or modern distortion-aware SfM/BA pipelines and omnidirectional-specific methods. The fairness and competitiveness against these specialized baselines remain untested.
- Long trajectories and loop closure: Performance on very long sequences with loops (loop-closure detection, global consistency) is not studied; no mechanism beyond alternating GA is presented for loop closure.
- Parameter/data ablations: No ablations on the loss weights (λ), SH degree L, β in the asymmetric angular loss, training-curriculum schedule, or modality mix quantify their contributions or sensitivities.
- Pretraining dependency: The approach initializes from UniK3D and DUSt3R. The necessity and impact of these pretrains (vs training from scratch) are not ablated.
- Cross-image intrinsics consistency: The RM estimates rays per image independently; there is no constraint tying intrinsics across images from the same physical camera (temporal consistency, shared lens parameters).
- Visibility reasoning: The pipeline lacks explicit visibility/occlusion handling; MNN in 3D can connect occluded or spurious points. Incorporating visibility masks or ray-consistency tests is left unexplored.
- Semantic priors for pruning: Scene-graph pruning is purely geometric; leveraging semantics to disambiguate doppelgangers or repetitive structures is not considered.
- Heterogeneous resolutions/aspect ratios: Handling of large disparities in resolution, aspect ratio, and pixel footprint across modalities is not discussed; potential resampling biases are unaddressed.
- Failure-case characterization: The paper does not provide systematic negative results or diagnostic categories (e.g., >180° FoV, ultra-sparse overlap, pure rotations, glass/reflective scenes) to delineate operational boundaries.
Practical Applications
Immediate Applications
The following use cases can be implemented now using the paper’s core contributions—camera-agnostic two-view reconstruction (Ray Module + Cross-view Module) and multi-view Ray-Aware Global Alignment—without requiring prior camera calibration or pinhole-only optics.
- Jobsite reality capture from mixed cameras (AEC/BIM, Construction)
- Workflow: Capture overlapping panoramas (e.g., Ricoh Theta), fisheye action-cam frames, and phone photos; run CAM3R to produce poses and dense point clouds; export to BIM tools for as-built updates and progress tracking.
- Tools/products: A “camera-agnostic photogrammetry” desktop app or cloud API; a Revit/Navisworks plugin for point cloud ingestion.
- Assumptions/dependencies: Static scenes with sufficient overlap/parallax; scale requires a known distance or fiducial; commodity GPU recommended for speed.
- Post-incident scene reconstruction from CCTV fisheye feeds (Public safety, Forensics)
- Workflow: Extract overlapping frames from ceiling fisheye cameras and doorway pinhole cameras; run pairwise inference, prune inconsistent edges, apply Ray-Aware Global Alignment; obtain a unified 3D scene and camera trajectory for investigative analysis.
- Tools/products: A forensic add-on for video evidence analysis suites that accepts heterogeneous optics.
- Assumptions/dependencies: Not a certified forensic method; validation and chain-of-custody workflows required; dynamic objects should be masked when possible.
- Fast asset inspection in confined spaces using borescopes/fisheye cams (Industrial inspection, Energy/Utilities)
- Workflow: Record short sweeps with borescopes or helmet-mounted fisheye cameras; reconstruct to map corrosion, cracks, or anomalies on tanks/pipes; compare with prior scans for change detection.
- Tools/products: An inspection toolkit that outputs millimeter-scale point clouds and supports change maps.
- Assumptions/dependencies: Textured surfaces and overlap are needed; for metric measurements, introduce scale markers or integrate IMU/laser range data.
- Drone and handheld mapping with mixed optics (Mapping/Surveying)
- Workflow: Mix action-cam wide lenses and 360 cameras on drones/handheld rigs; reconstruct without undistortion; export to meshing/NeRF pipelines.
- Tools/products: A “lens-agnostic” photogrammetry front-end that replaces undistortion and pinhole-only SfM.
- Assumptions/dependencies: Adequate coverage; wind/rolling shutter can degrade results; scale via known baseline, GNSS, or ground control points.
- Set digitization and previz from 360 stills (Media/Film, VFX)
- Workflow: Capture a few 360s plus phone shots; produce a dimensionally consistent point cloud; block lighting and camera moves in DCC tools.
- Tools/products: A DCC (e.g., Blender, Unreal) bridge to import CAM3R outputs seamlessly.
- Assumptions/dependencies: For absolute scale, include a calibration stick or set references.
- Real estate and cultural heritage scanning with consumer 360 cameras (Real estate, Heritage)
- Workflow: Capture walk-through panoramas; reconstruct for virtual tours and archival documentation.
- Tools/products: A lightweight app that ingests 360 images from common cameras and outputs annotated floor plans/point clouds.
- Assumptions/dependencies: Static environment and overlap; for accurate measurements, add scale references.
- Camera-agnostic pose initialization for NeRFs/3DGS (Software, 3D vision research)
- Workflow: Use CAM3R to obtain poses and dense pointmaps from fisheye/panorama/pinhole mixes; initialize NeRF/3D Gaussian Splatting training without pinhole-only SfM.
- Tools/products: A preprocessing module for popular NeRF toolkits that consumes heterogeneous imagery.
- Assumptions/dependencies: Still up-to-scale geometry; dynamic content can cause artifacts.
- Drop-in calibration-free front-end for SLAM research (Academia, Robotics R&D)
- Workflow: Replace pinhole assumptions with per-pixel rays predicted by the Ray Module; use Ray-Aware alignment to stabilize pose graphs on wide-FOV cameras in lab settings.
- Tools/products: A ROS/node-based module that publishes per-pixel ray fields and relative poses.
- Assumptions/dependencies: Research-focused; not yet optimized for strict real-time latency; static-scene assumption for best results.
- Cloud API for heterogeneous camera reconstruction (Software, Platforms)
- Workflow: Developers upload unordered images (any lens); service returns camera poses, dense point clouds, and confidence maps.
- Tools/products: Managed API with usage-based pricing; integrations with storage/CDN providers.
- Assumptions/dependencies: Privacy/security handling for sensitive scenes; GPU-backed compute.
- Education and benchmarking across optics (Academia, Education)
- Workflow: Use CAM3R as a baseline for “beyond-pinhole” reconstruction assignments; benchmark across panorama/fisheye datasets.
- Tools/products: Teaching materials and standardized evaluation scripts for heterogeneous optics.
- Assumptions/dependencies: Access to datasets with varying lens models; classroom GPU resources.
- Helmet/body-worn 3D mapping for first responders (Public safety, Emergency response)
- Workflow: Capture overlapping snapshots or short bursts from wide-FOV cameras; reconstruct to orient teams in indoor environments.
- Tools/products: A field-deployable app that outputs coarse floorplans and obstacle maps.
- Assumptions/dependencies: Dynamic humans/objects can degrade quality; needs ruggedized hardware, offline capability.
- Mixed-optic automotive dataset reconstruction (Automotive R&D)
- Workflow: Use surround fisheye + pinhole cameras to reconstruct scenes offline for perception experiments and ground-truth generation.
- Tools/products: A data curation pipeline compatible with AV datasets to compute poses without per-lens calibration.
- Assumptions/dependencies: Production deployment requires robust handling of rolling shutter, HDR, and motion blur.
Long-Term Applications
These use cases require further research, engineering, scaling, or regulatory approval—often centering on real-time constraints, safety-critical operation, or domain adaptation.
- Real-time, on-device camera-agnostic SLAM (Robotics, AR/VR)
- Product vision: An embedded module that predicts per-pixel rays and depth/poses at video rates on edge SoCs for drones, mobile robots, and AR headsets with fisheye/360 cameras.
- Needed advances: Model compression, unified backbone (as noted by the authors), temporal consistency, robust dynamic-scene handling, IMU fusion.
- Dependencies: Low-latency inference, power constraints, time synchronization with IMU/encoders.
- Surround-camera self-calibration and 3D perception for production AV (Automotive)
- Product vision: Calibration-free, long-term-stable 3D reconstruction from heterogeneous surround cameras for redundancy with LiDAR/RADAR.
- Needed advances: Rolling-shutter modeling, motion compensation, severe weather/night robustness, safety certification.
- Dependencies: Extensive validation datasets, standards compliance, integration with multi-sensor fusion stacks.
- Endoscopic/medical 3D surface reconstruction (Healthcare)
- Product vision: Camera-agnostic mapping of internal anatomy using wide-angle endoscopes/capsules to assist navigation, measurement, and lesion tracking.
- Needed advances: Domain-specific training, specular/low-texture handling, fluid/tissue dynamics, sterilizable markers for scale, clinical validation.
- Dependencies: Regulatory approvals (e.g., FDA/CE), privacy and data security, clinician workflow integration.
- City- and facility-scale mapping with 360/fisheye fleets (Public sector, Smart cities, Infrastructure)
- Product vision: Cost-effective urban mapping using fleets of 360 cameras without per-unit calibration, enabling frequent updates of 3D twins.
- Needed advances: Scalable distributed alignment, loop-closure at scale, robust scene-graph pruning for repetitive facades, integration with GNSS/IMU.
- Dependencies: Data governance, privacy redaction, storage and bandwidth at scale.
- Evidence-grade standards and procurement guidelines for wide-FOV 3D (Policy, Standards)
- Product vision: Guidance for accepting 3D reconstructions from fisheye/panoramic imagery in inspections, permitting, and legal contexts.
- Needed advances: Benchmark suites across optics, uncertainty quantification using CAM3R’s confidence maps, reproducibility protocols.
- Dependencies: Inter-agency consensus, alignment with existing forensic and surveying standards, auditor training.
- Consumer-grade on-device 3D capture from 360 and ultrawide cameras (Consumer software/hardware)
- Product vision: Smartphone/360 camera firmware that turns casual panoramas into scaled 3D rooms or objects for AR staging and 3D printing.
- Needed advances: Energy-efficient inference, interactive feedback on coverage/overlap, robust scale estimation without markers.
- Dependencies: OEM partnerships, UX for non-experts, privacy-preserving local processing.
- Distortion-aware neural rendering pipelines (Software, Media)
- Product vision: Native support in NeRF/3DGS and virtual production tools for per-pixel rays from any lens, improving reconstruction fidelity and reducing pre-calibration.
- Needed advances: Tight integration of CAM3R-like ray fields with radiance field training, temporal consistency for video, production-grade tooling.
- Dependencies: Ecosystem adoption (DCC/engine plugins), standardized ray field interchange formats.
- Asset inspection automation with autonomous platforms (Energy/Utilities, Manufacturing)
- Product vision: Robots using fisheye sensors to autonomously map and assess large assets (turbines, refineries, factories) with minimal calibration and setup.
- Needed advances: Real-time mapping, anomaly detection atop coherent geometry, operation under low light/reflective surfaces.
- Dependencies: Safety certifications, robust autonomy stack integration, operator oversight interfaces.
- Telepresence and remote operations with 360 sensing (Enterprise collaboration, Robotics)
- Product vision: Reconstruct remote spaces in near-real-time from wearable 360 cameras to support collaborative planning, repair, and training.
- Needed advances: Streaming-friendly incremental reconstruction, bandwidth-aware compression, dynamic-scene resilience.
- Dependencies: Network constraints, security, human-in-the-loop tooling.
- Insurance, claims automation, and disaster assessment (Finance, Public sector)
- Product vision: Policyholders and field adjusters capture 360/fisheye imagery; systems produce metrically consistent 3D for damage quantification.
- Needed advances: Robust scale and measurement accuracy across diverse scenes, standardized reporting.
- Dependencies: Insurer acceptance criteria, auditability, user guidance to ensure sufficient overlap and coverage.
- Space and extreme-environment exploration (Aerospace, Defense)
- Product vision: Use fisheye/panoramic sensors on rovers or inspection drones to reconstruct without pre-calibration under extreme conditions.
- Needed advances: Radiation/temperature-hardened compute, domain adaptation for novel textures/lighting (regolith, ice).
- Dependencies: Mission-specific validation, communication constraints, resource limitations.
Cross-cutting assumptions and dependencies
- Static or quasi-static scenes and adequate image overlap/parallax are important for high-fidelity reconstructions; dynamic objects should be masked or handled with motion-aware extensions.
- Reconstructions are up-to-scale; obtaining metric scale typically requires a reference (known object size, IMU, GNSS, stereo baseline, or range sensors).
- Performance can degrade with severe rolling shutter, extreme motion blur, very low texture, or heavy specular/transparent surfaces; targeted training and sensor fusion can mitigate this.
- Compute: While feed-forward, practical deployments benefit from modern GPUs or optimized edge inference; real-time variants will require model compression and hardware acceleration.
- Ethics and compliance: 3D reconstructions can reveal sensitive details; privacy-by-design (redaction, on-device processing) and domain-specific regulatory approvals (e.g., medical, automotive) may be required.
Glossary
- Absolute Trajectory Error (ATE): A metric that measures the root-mean-square difference between estimated and ground-truth camera trajectories after alignment. "We report Accuracy (RRA@30/RTA@30), mean Average Accuracy (mAA@30), and Absolute Trajectory Error (ATE)."
- Alternating optimization scheme: An iterative strategy that alternates between optimizing different variable subsets (e.g., poses then scales) to improve convergence. "We employ a multi-stage alternating optimization scheme \cite{neal2011distributed} to obtain the global scene geometry."
- Asymmetric Angular Loss: A loss that penalizes underestimation of angles more than overestimation to counter dataset bias toward narrow fields of view. "To supervise the per-pixel directional rays predicted by our model, we adopt an asymmetric angular loss inspired by UniK3D \cite{piccinelli2025unik3d}."
- Bidirectional consistency: A check ensuring that pairwise predictions are consistent in both directions between two images. "We evaluate bidirectional consistency between reciprocal edges and ."
- Bundle adjustment: A nonlinear optimization that refines camera parameters and 3D points by minimizing reprojection error across views. "Traditional bundle adjustment often fails on distorted images due to the pinhole assumption, where pixel distances linearly correspond to 3D distances \cite{triggs1999bundle,wang2024dust3r}."
- Camera intrinsic calibration: The process of estimating internal camera parameters that map 3D rays to 2D pixels. "Camera intrinsic calibration involves estimating the parameters necessary to establish a mapping between the two-dimensional image plane and the three-dimensional coordinate system."
- Confidence map: A per-pixel reliability indicator used to weight geometric predictions like depth or distance. "infer radial distance with confidence maps, pointmaps, and relative poses."
- Cross-attention: An attention mechanism that allows one set of features to attend to another set for information exchange. "Each decoder block facilitates information exchange via self-attention and cross-attention mechanisms."
- Cross-view Module (CVM): The component that models relationships between image pairs to infer 3D structure and relative pose. "a Cross-view Module (CVM) to infer radial distance with confidence maps, pointmaps, and relative poses."
- Dense Prediction Transformer (DPT): A transformer head tailored for dense outputs (e.g., depth) from images. "A Dense Prediction Transformer (DPT) head \cite{ranftl2021vision} is integrated with the decoder blocks to regress the radial distance and an associated confidence map ."
- Epipolar geometry: The geometric relationship between two views that constrains corresponding points to lie on epipolar lines. "solving two-view epipolar geometry"
- Field-of-View (FoV): The angular extent of a scene captured by a camera. "including large Field-of-View (FoV) and panoramic captures."
- Geodesic distance on SO(3): The shortest-angle distance between two rotations on the rotation group, used to measure rotational error. "For rotation, we utilize the geodesic distance on , which provides a physically meaningful angular error."
- Global bundle adjustment: A joint multi-view optimization that refines camera poses and sparse 3D structures across an entire scene. "optimizing a multi-view sparse graph via global bundle adjustment \cite{triggs1999bundle}."
- Heterogeneous camera models: A setting where image pairs come from different projection types (e.g., fisheye and panorama). "even when the input pair originates from heterogeneous camera models."
- Mean Average Accuracy (mAA): An aggregate accuracy metric computed over multiple thresholds or conditions. "We report Accuracy (RRA@30/RTA@30), mean Average Accuracy (mAA@30), and Absolute Trajectory Error (ATE)."
- Mutual Nearest Neighbor (MNN): A correspondence criterion where two points are each other’s nearest neighbors, used to ensure reliable matches. "We compute strict Mutual Nearest Neighbor (MNN) correspondences in 3D space between and the transformed ."
- Non-rectilinear optics: Lens systems where straight lines do not necessarily project as straight lines in the image (e.g., fisheye). "non-rectilinear optics, such as fisheye or panoramic lenses."
- Optical aberrations: Imperfections in lens systems that cause distortions, blurring, or color fringing. "which prove effective for narrow FoV sensors with negligible optical aberrations."
- Optical manifold: The underlying mapping or geometry induced by a camera’s optics over image coordinates. "across disparate optical manifolds, including pinhole, fisheye and panoramic cameras, where recent 3D foundation models fail."
- Pinhole camera model: An idealized camera model with linear projection and no lens distortion. "these methods remain fundamentally limited by their reliance on the pinhole camera model, which dominates the training data and can lead to degraded performance on images from non-linear or wide-field-of-view lenses."
- Pointmap: A dense per-pixel representation of 3D points in a camera’s local coordinate frame. "Let be the dense pointmap for a given view "
- Quantile regression: A loss formulation that targets specific quantiles of the error distribution, enabling asymmetric penalties. "we employ a quantile regression framework that enforces a significantly heavier penalty for angular underestimation than for overestimation."
- Ray-Aware Global Alignment: A global optimization approach that aligns multi-view predictions while preserving per-pixel ray directions across cameras. "we introduce a Ray-Aware Global Alignment framework for pose refinement and scale optimization while strictly preserving the predicted local geometry."
- Ray-consistent 3D space: A representation where optimization respects per-pixel 3D ray directions rather than assuming linear pixel-to-depth relationships. "our approach optimizes scene geometry within a purely ray-consistent 3D space."
- Ray Module (RM): The component that predicts per-pixel viewing rays, decoupling camera intrinsics from scene geometry. "a Ray Module (RM) to estimate per-pixel ray directions"
- Rectified pinhole projection: A pre-processing step that undistorts images to mimic a pinhole model for downstream algorithms. "undistorting wide-angle images to simulate a rectified pinhole projection before processing via downstream reconstruction models."
- Relative Rotation Accuracy (RRA@15): The percentage of image pairs whose estimated relative rotation error is below 15 degrees. "We report Relative Rotation Accuracy (RRA@15) and Relative Translation Accuracy (RTA@15), defined as the percentage of pairs with angular errors below ."
- Relative Translation Accuracy (RTA@15): The percentage of image pairs whose estimated relative translation direction error is below 15 degrees. "We report Relative Rotation Accuracy (RRA@15) and Relative Translation Accuracy (RTA@15), defined as the percentage of pairs with angular errors below ."
- Rigid transformation: A transformation consisting of rotation and translation without scaling or deformation. "The relative pose network regresses a rigid transformation $P_{2\to1} = \{R_{2\to1}, \hat{\mathbf{t}_{2\to1}\}$"
- Root-mean-square error (RMSE): A standard measure of average squared error magnitude, used here to score trajectory alignment error. "ATE is computed via root-mean-square error (RMSE) after Umeyama alignment \cite{kabsch1976solution}"
- Scene-Graph Pruning: The process of removing unreliable or inconsistent pairwise edges from the image-pair graph before global optimization. "Scene-Graph Pruning."
- SE(3): The Lie group of 3D rigid motions (rotations and translations) used to represent camera poses. "Given camera poses "
- Siamese Cross-view encoder: A twin-branch encoder with shared weights that extracts features from two images for cross-view reasoning. "processes the input images through a Siamese Cross-view encoder to extract feature representations"
- SO(3): The Lie group of 3D rotations, representing all possible rotation matrices. "where is the rotation matrix"
- Spherical Harmonic expansion: A basis-function expansion on the sphere used to represent per-pixel ray directions compactly. "To represent these ray directions, we use Spherical Harmonic expansion where denotes the basis functions of degree and order ."
- Structure-from-Motion (SfM): A pipeline that jointly estimates camera motion and sparse 3D structure from image collections. "running Structure-from-Motion (SfM) or other optimizations, defeating the purpose of feed-forward models."
- Umeyama alignment: A similarity-transform alignment method that adjusts rotation, translation, and scale between point sets. "ATE is computed via root-mean-square error (RMSE) after Umeyama alignment \cite{kabsch1976solution} to account for global scale and pose."
- Wide-baseline configurations: Image pairs with large viewpoint changes used to increase geometric robustness and challenge. "by ensuring significant spatial overlap and wide-baseline configurations."
- Zero-shot generalization: The ability to perform well on unseen datasets or modalities without task-specific training. "and further assess zero-shot generalization using the augmented CO3Dv2 dataset."
Collections
Sign up for free to add this paper to one or more collections.

