- The paper introduces a novel MLLM-driven semantic grouping mechanism that integrates geometric and language cues to form robust 3D instances.
- It employs a training-free, zero-shot framework on multi-view RGB images, effectively handling pose-known and pose-free settings.
- Experimental results show significant mAP improvements over geometry-only baselines on benchmarks like ScanNet and ARKitScenes.
Group3D: Integrating Semantic Grouping for Open-Vocabulary Multi-View 3D Object Detection
Introduction
Group3D introduces a novel multi-view 3D object detection framework that addresses the inherent limitations of geometry-centric object instance construction in open-vocabulary scenarios. Building upon observations that geometry-only merging is highly susceptible to association errors, especially under incomplete multi-view observations, this method leverages both semantic and geometric cues—integrating a multimodal LLM (MLLM)-driven grouping mechanism for robust, open-vocabulary 3D instance localization. The approach is specifically designed for RGB-only input, accommodating both pose-known and pose-free settings, and targets open-vocabulary detection where detectors must recognize categories beyond a fixed taxonomy.
Methodology
The core pipeline of Group3D is grounded in two primary innovations: the construction of semantic scene memories and MLLM-driven semantic compatibility grouping, which are intertwined during 3D instance formation.
Following acquisition of multi-view RGB images, an MLLM is queried to predict object categories for each view. These are aggregated and standardized into a scene-adaptive vocabulary (Scene Vocabulary Memory). For each view and category, a segmentation backbone (e.g., SAM 3) produces category-aware masks, which are lifted into 3D by leveraging depth and pose from reconstruction models. The resulting 3D fragments, indexed by their provenance, predicted label, and confidence, form the 3D Fragment Memory.
Crucially, the MLLM further organizes the scene vocabulary into semantic compatibility groups, capturing category-level substitutability (e.g., grouping "sofa" and "couch") and filtering out groups that reflect co-occurrence or part-whole relations, yielding grouping constraints robust to cross-view lexical variability. These groups act as explicit merge-time constraints: fragments may only merge if they fulfill both voxel-wise geometric consistency and semantic group compatibility.
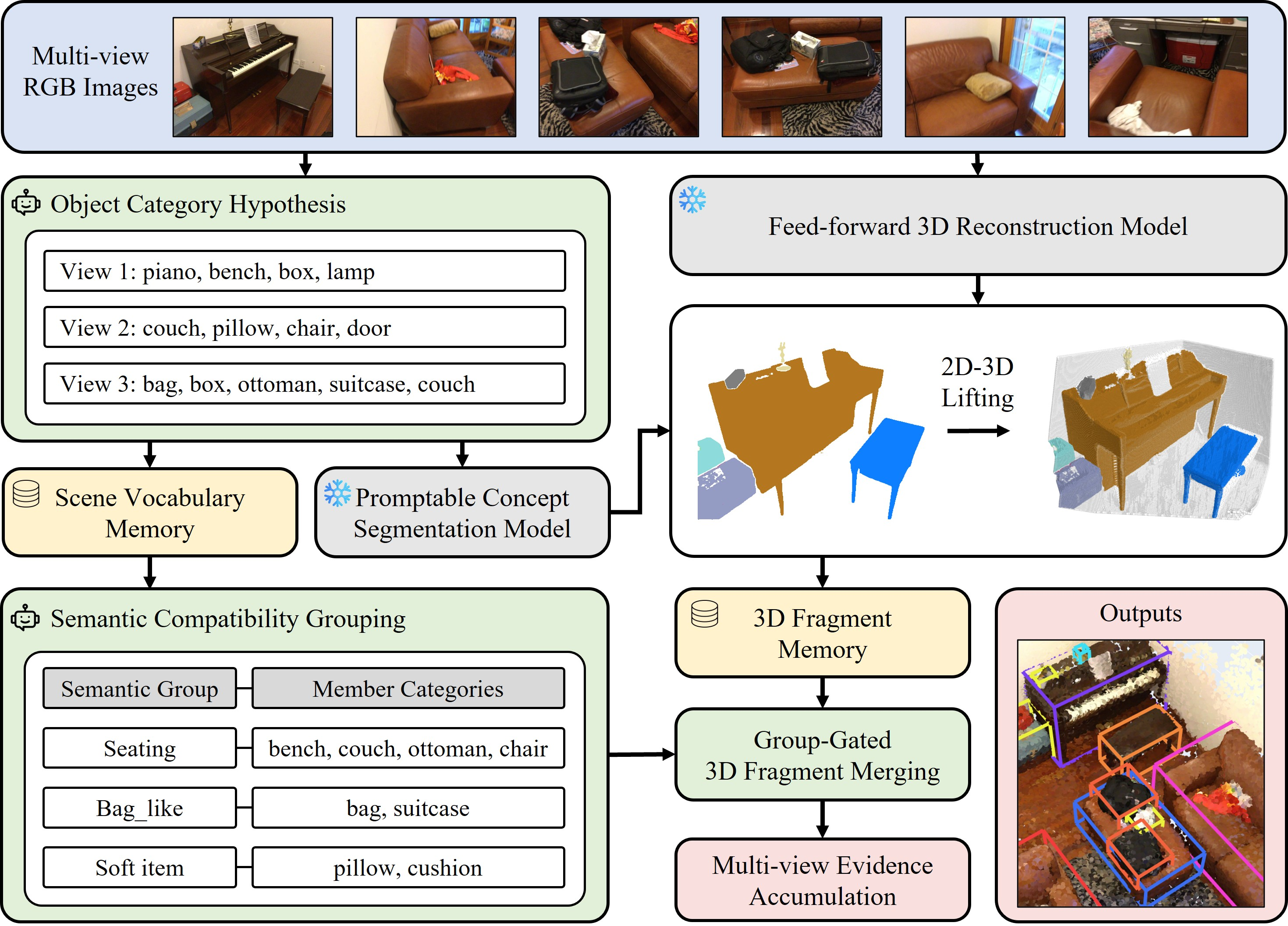
Figure 1: Overview of the Group3D pipeline, showing MLLM-driven category prediction, multi-view mask lifting, semantic group gating during fragment merging, and evidence aggregation for final instance prediction.
Geometric consistency is measured using both IoU and containment ratios over voxelized fragments, with thresholds optimized for asymmetric fragment size cases. After fragment merging under both constraints, multi-view evidence is aggregated, scoring candidate categories for each instance by cross-view support and mean confidence.
Experimental Evaluation
Group3D is evaluated on the ScanNet and ARKitScenes indoor benchmarks, considering open-vocabulary splits with progressively larger category vocabularies (ScanNet20, ScanNet60, ScanNet200), and in both pose-known and pose-free operational regimes. The framework is completely training-free with respect to the evaluation benchmarks, operating in a zero-shot paradigm.
The results reveal strong improvements over both geometry-only multi-view detectors and prior point cloud-based open-vocabulary baselines, with mAP25 significantly increased—e.g., 51.1 (pose-known) and 41.2 (pose-free) on ScanNet20, compared to Zoo3D's 37.2 and 27.9, respectively. Notably, Group3D's improvements hold even as the size and granularity of the label space scale to the long tail of ScanNet200 and across domain shifts to ARKitScenes, demonstrating robust generalization and semantic reasoning capabilities.
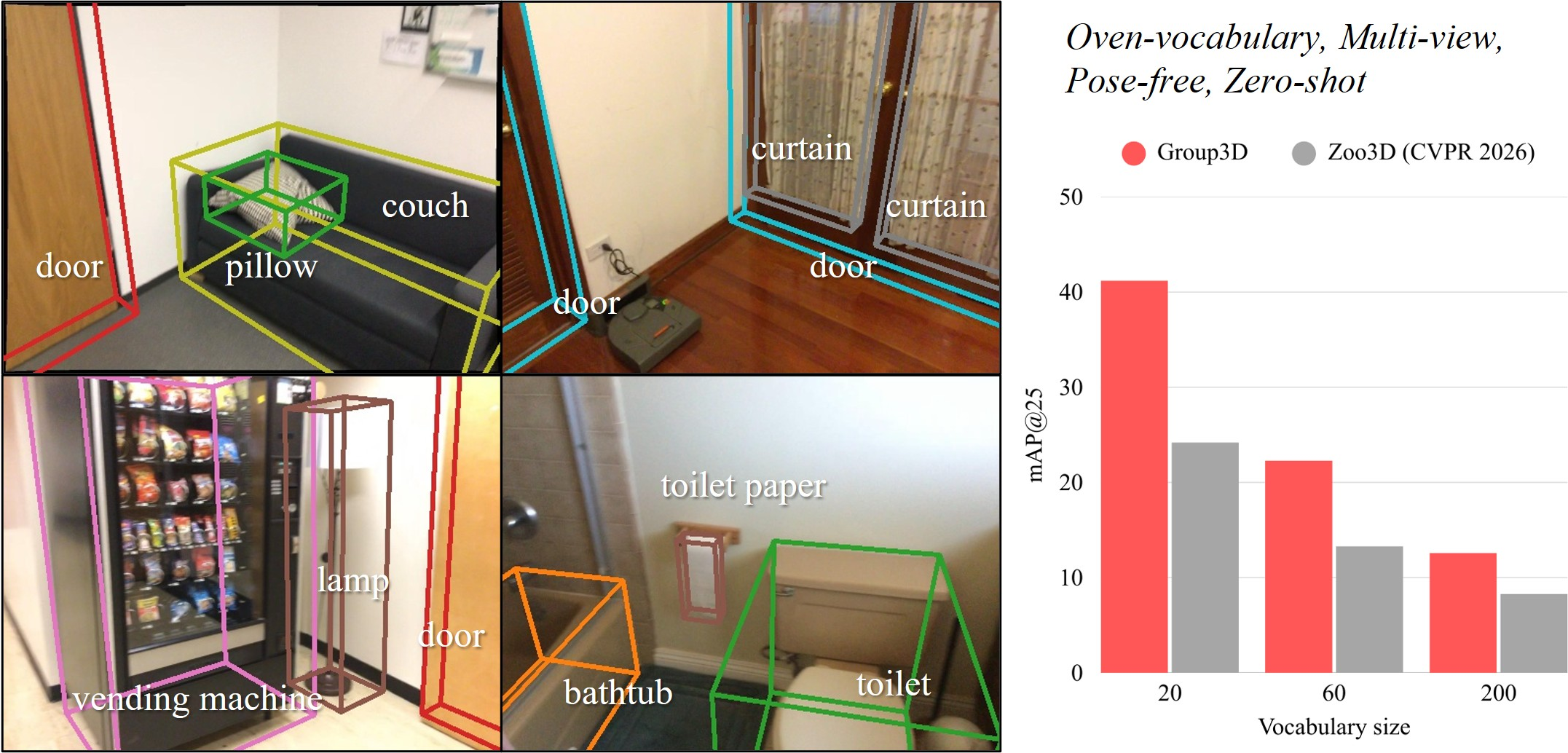
Figure 2: Left: Projected 3D box predictions on input RGB images; Right: Consistently higher mAP25 for Group3D compared to baselines over increasing label space sizes.
Qualitative analyses reaffirm that semantic group gating efficiently prevents over-merging and undersegmentation visible in geometry-driven pipelines, while ablation experiments confirm the essential role of MLLM-driven grouping: switching to strict category equality or no grouping severely degrades performance.

Figure 3: Visualizations of Group3D's qualitative predictions on ScanNet20, illustrating accurate instance grouping in complex multi-object scenes.
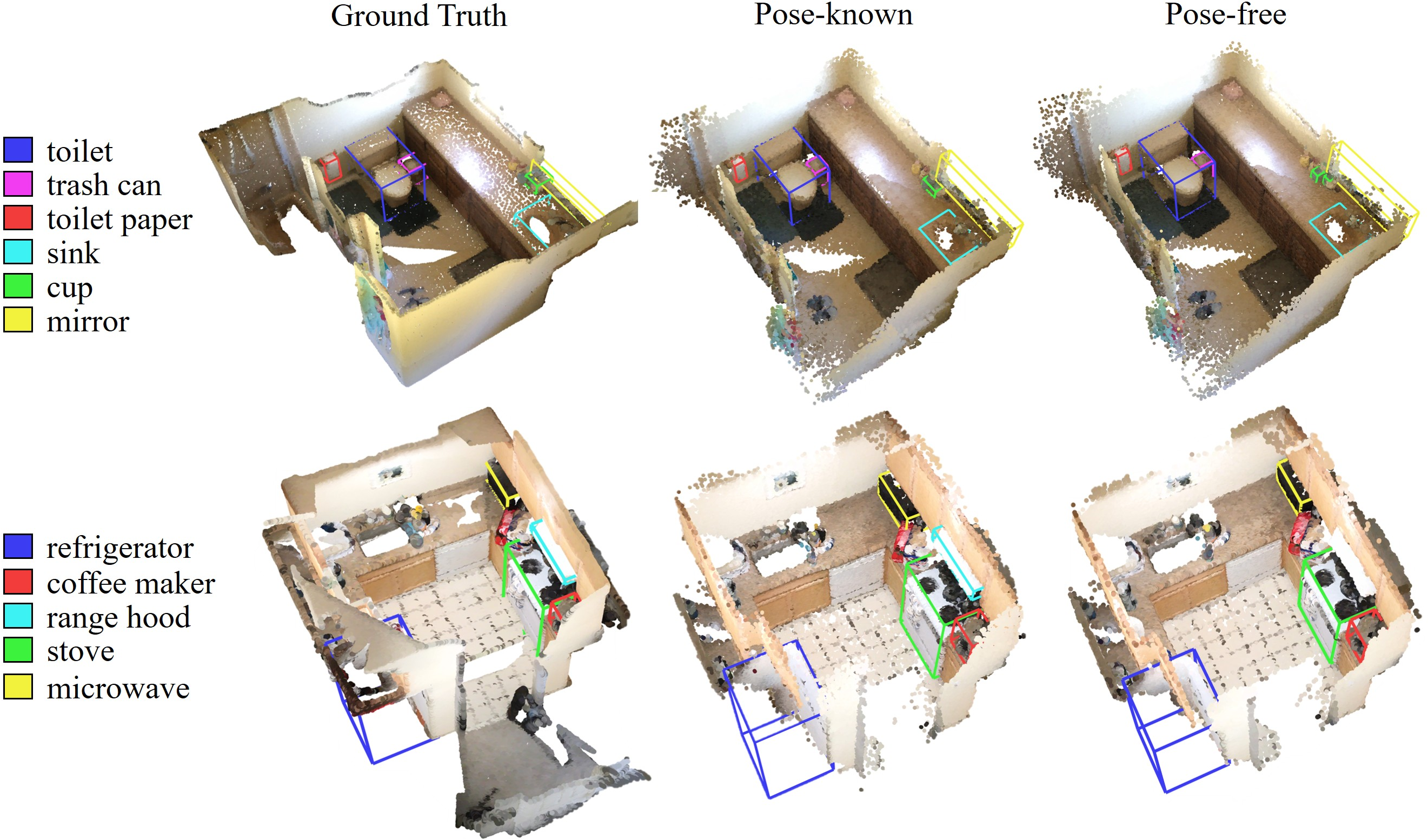
Figure 4: Example predictions from Group3D on ScanNet200, showcasing robust open-vocabulary grouping and localization across fine-grained categories.
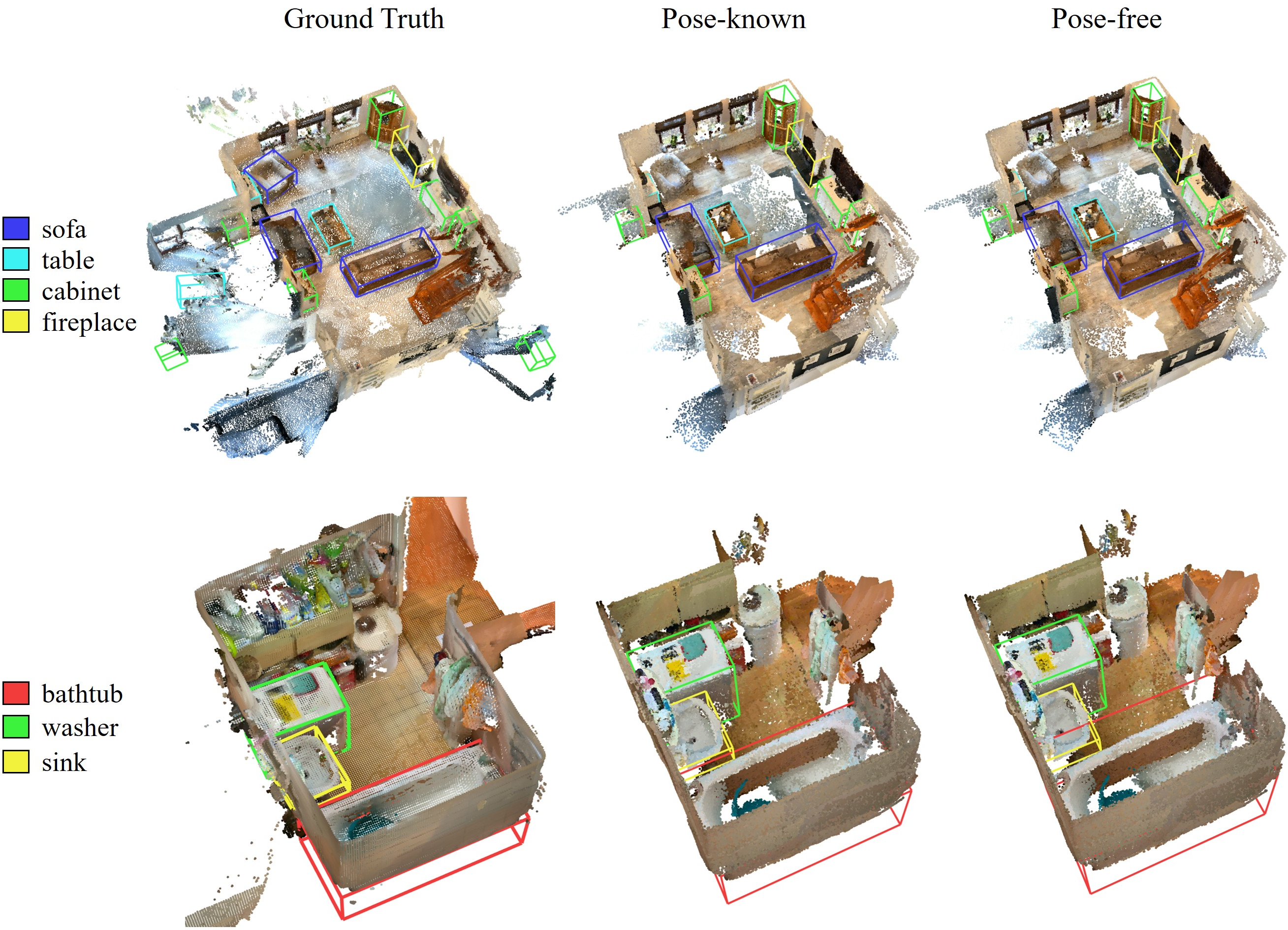
Figure 5: Results on ARKitScenes, demonstrating transferability to real-world scenes with distinct sensory statistics.
Ablation and Analysis
Multiple ablation studies reveal the impact of key architectural components:
- Semantic grouping strategy: Removing category information or enforcing only strict equality between category predictions sharply reduces mAP, exposing the importance of flexible yet structured compatibility grouping.
- MLLM and segmentation backbone: Replacing the MLLM or segmentation models leads to moderate performance drops but maintains overall trend, suggesting that the grouping scheme is robust to backbone choice.
- Voxel granularity & frame count: Smaller voxel sizes marginally improve geometric precision for merging; increasing the number of multi-view frames enhances performance up to a saturation point.
- Category hypothesis count (K): Varying the number of view-level hypotheses (K) has little impact, favoring efficiency at K=5.
Implications and Future Directions
The empirical strengths of Group3D demonstrate that semantic priors, when integrated at the structural decision points of instance formation, provide critical signal in ambiguous geometric contexts, especially where only RGB is available and in zero-shot deployments. This suggests a new paradigm for 3D perception frameworks: tight integration of language-driven structure and geometric reasoning, rather than post-hoc category assignment.
This approach supports practical extension to open-world 3D scene understanding, reducing dependence on domain-specific 3D annotations and specialized sensors. Future research could broaden the semantic constraint space (e.g., relational or compositional groupings), incorporate richer language supervision and contextual queries, or extend toward simultaneous reconstruction and open-vocabulary reasoning across entire scenes.
Conclusion
Group3D establishes a new state-of-the-art for training-free open-vocabulary 3D object detection under multi-view RGB inputs by coupling MLLM-induced semantic constraints with geometric consistency at the point of instance construction. This semantically gated merging decisively mitigates geometry-driven over-merging and fragmentation, robustly scales to large label spaces, and generalizes across domains. The framework paves the way for scalable, annotation-efficient, and linguistically grounded 3D perception systems.