- The paper demonstrates that using sparse keyframe propagation with dual-space encoding and a Diffusion Transformer yields state-of-the-art video super-resolution while preserving fine textures and structural details.
- It introduces an interactive, human-in-the-loop workflow that utilizes flexible keyframe selection and reference-free guidance to accurately balance perceptual quality and restoration fidelity.
- Extensive experiments across synthetic and real-world datasets show that SparkVSR outperforms previous methods in both objective metrics (e.g., PSNR, SSIM) and perceptual quality.
Interactive Sparse Keyframe Propagation for Video Super-Resolution: SparkVSR
Introduction
The paper "SparkVSR: Interactive Video Super-Resolution via Sparse Keyframe Propagation" (2603.16864) introduces a novel paradigm for Video Super-Resolution (VSR) that fundamentally departs from conventional black-box approaches by offering precise, user-driven control via sparse keyframe propagation. VSR is an inherently ill-posed problem where multiple plausible HR reconstructions exist for a single LR input, necessitating human intervention to steer restoration outputs towards desired textures and structural fidelity. SparkVSR leverages this insight by enabling the user or an automated policy to select and restore high-quality HR keyframes—then propagates these priors to reconstruct a temporally consistent HR video grounded in the original LR motion trajectory.
The methodological foundation consists of dual-space encoding with a Diffusion Transformer architecture, flexible reference frame guidance, and rigorous latent-pixel fusion. This design unlocks modal controllability, robust temporal consistency, and integration of advances in single-image super-resolution (ISR) for video processing.
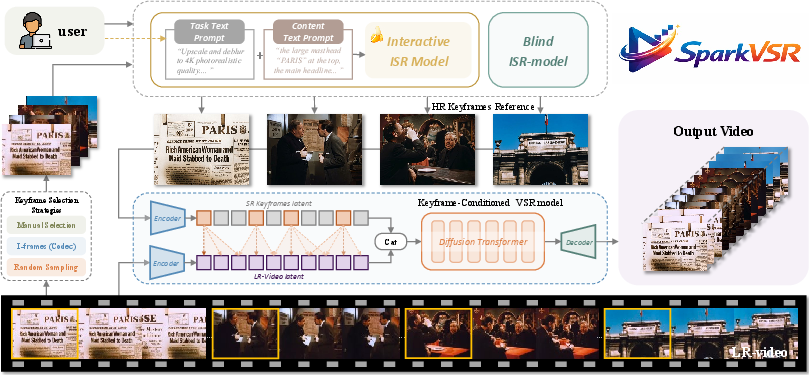
Figure 1: Overall inference framework of SparkVSR, illustrating the three stages: keyframe selection, HR reference generation, and conditional video reconstruction.
Methodology
The architecture establishes a human-in-the-loop workflow for VSR. LR video sequences are encoded into latent representations via a 3D causal VAE. Simultaneously, sparse, user-selected keyframes are restored to HR using ISR models—Nano-Banana-Pro for interactive, prompt-guided restoration or PiSA-SR for blind super-resolution. The keyframes are mapped to corresponding temporal indices and encoded into latents; non-reference indices are filled with zero tensors, forming a sparse reference latent structure.
The latent fusion process concatenates the LR and HR reference latents along the channel dimension, serving as joint input for the Diffusion Transformer. The model is initialized with the LR video latent as a noisy input at a mid-diffusion timestep, allowing the Transformer to generate high-frequency HR details with minimal global structural rewriting. Decoding yields the final HR video output.
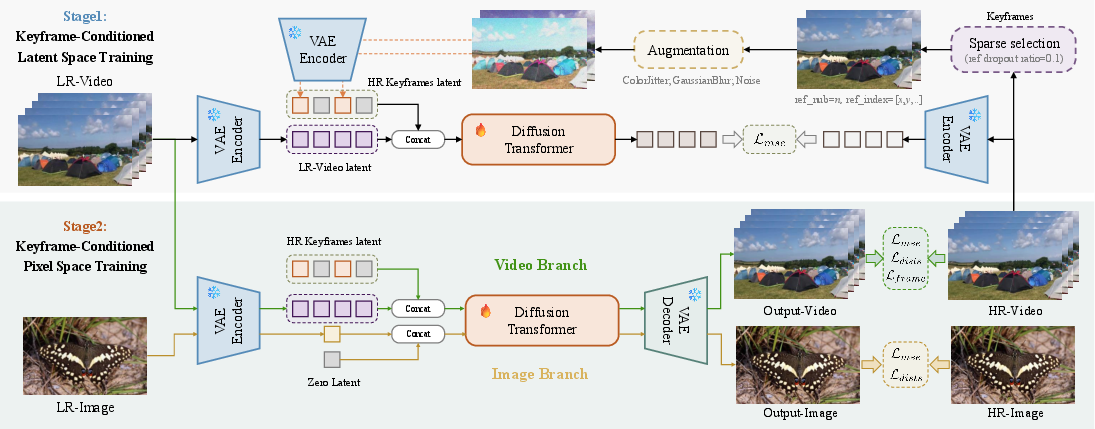
Figure 2: Two-stage keyframe-conditioned training pipeline, comprising latent-space optimization for efficient propagation and pixel-space refinement for perceptual and temporal consistency.
Training proceeds in two stages:
- Stage 1 (Latent Space): Transformer is trained to align LR and reference HR latents, minimizing MSE with HR ground-truth latent. HR keyframes are randomly selected and augmented to simulate diverse ISR priors. Reference-dropout is employed, compelling the model to learn robust blind restoration when no keyframe is provided.
- Stage 2 (Pixel Space): The model transitions to pixel-level output. Video branch uses reference latents, supervised with MSE, DISTS, and frame-consistency losses. Image branch aligns channel dimensions with zero latent input, solidifying generative capability in the absence of reference frames.
Inference enables three keyframe selection modes: manual (for maximum control), codec I-frame extraction (optimal spatial anchors), or random sampling (scalable automation). Interactive prompts decouple task objectives and content descriptors, facilitating fine semantic and structural guidance in ISR restoration.
Reference-Free Guidance (RFG), inspired by Classifier-Free Guidance (CFG), modulates the relative weight of reference priors during denoising. Increasing s amplifies keyframe propagation; decreasing s enhances reliance on the model's internal generative priors.
Experimental Results
Extensive evaluation across synthetic and real-world datasets (UDM10, SPMCS, YouHQ40, RealVSR, MovieLQ) demonstrates SparkVSR’s superior restoration quality and temporal consistency. The method achieves state-of-the-art scores in both full-reference and no-reference IQA/VQA metrics, surpassing the best previous methods by 24.6% (CLIP-IQA), 21.8% (DOVER), and 5.6% (MUSIQ). Its reference-guided variants consistently outperform baselines in challenging conditions, particularly on MovieLQ with vintage real-world degradations.
Qualitative results verify sharper recoveries of textural and structural details, especially in facial features and highly degraded text. SparkVSR's reference-guided propagation yields high-frequency texture regeneration while strictly preserving global motion structure, avoiding temporal flicker and artifact formation pervasive in per-frame ISR approaches.

Figure 3: SparkVSR demonstrates superior recovery of fine textures and structural details on the MovieLQ dataset.

Figure 4: On SPMCS and YouHQ40 datasets, high-resolution references enable precise restoration of animation edges and complex natural textures.
Ablation Studies and Tradeoff Analysis
Ablation experiments dissect the contributions of core components. The two-stage training pipeline is essential for balancing fidelity and perceptual quality; latent-only models maximize PSNR/SSIM but underperform in perception metrics, while pixel refinement achieves optimal perceptual realism.
Reference-Free Guidance offers fine control over the perception-distortion tradeoff. Higher RFG values decrease PSNR/SSIM but substantially increase perceptual metrics. SparkVSR establishes a superior Pareto front compared to DOVE, STAR, SeedVR2, and FlashVSR, consistently achieving superior perceptual quality at comparable distortion levels.
Reference frame selection is critical; a single keyframe markedly improves perceptual quality, while multiple distributed references further enhance temporal coherence and the propagation of fine textures. Codec I-frame selection matches or exceeds uniformly sampled strategies in objective and subjective metrics.
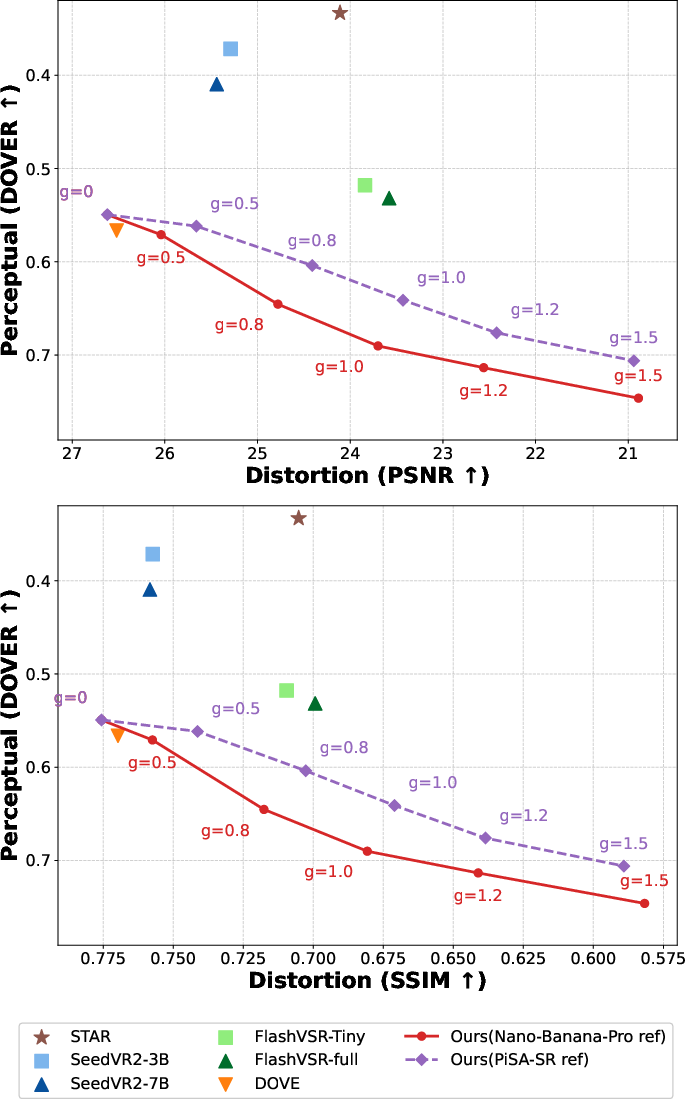
Figure 5: Perception-distortion tradeoff curve for SparkVSR (PSNR, SSIM vs. DOVER), outperforming leading baselines.

Figure 6: X-T slice profiles show SparkVSR's temporal stability; methods with waviness exhibit temporal inconsistency, while SparkVSR maintains sharp, straight textures.

Figure 7: Visual study comparing reference sources and RFG scales; Nano-Banana-Pro and PiSA-SR references yield high-fidelity results, with RFG modulating texture richness.

Figure 8: Ablation of the number and temporal positions of reference frames; multiple references ensure uniform propagation of high-resolution textures across the sequence.
Broader Applications and Implications
SparkVSR generalizes to zero-shot applications—old-film restoration, colorization, and video style transfer—by propagating features from edited keyframes while maintaining rigorous temporal alignment. The decoupling of spatial and temporal priors, along with flexible controllability, enables its deployment in diverse low-level video editing workflows.
Practically, SparkVSR allows user intervention to select, edit, or enhance anchor frames; theoretically, it advances the decomposition of ill-posed VSR problems by leveraging strong single-frame generative priors and explicit temporal propagation mechanisms. Future developments may include expansion to longer sequences, real-time processing, and integration with multi-modal editing tools.
Conclusion
SparkVSR delivers an interactive, keyframe-driven framework for Video Super-Resolution, providing robust controllability, optimal perception-distortion tradeoff, and state-of-the-art restoration quality. By incorporating dual-space encoding, flexible guidance, and rigorous training paradigms, SparkVSR shifts VSR from a deterministic mapping to a controllable, user-customizable process. Its architecture extends to broad video processing tasks, setting a new standard for temporally consistent, high-fidelity reconstruction.

