FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution
Abstract: Diffusion models have recently advanced video restoration, but applying them to real-world video super-resolution (VSR) remains challenging due to high latency, prohibitive computation, and poor generalization to ultra-high resolutions. Our goal in this work is to make diffusion-based VSR practical by achieving efficiency, scalability, and real-time performance. To this end, we propose FlashVSR, the first diffusion-based one-step streaming framework towards real-time VSR. FlashVSR runs at approximately 17 FPS for 768x1408 videos on a single A100 GPU by combining three complementary innovations: (i) a train-friendly three-stage distillation pipeline that enables streaming super-resolution, (ii) locality-constrained sparse attention that cuts redundant computation while bridging the train-test resolution gap, and (iii) a tiny conditional decoder that accelerates reconstruction without sacrificing quality. To support large-scale training, we also construct VSR-120K, a new dataset with 120k videos and 180k images. Extensive experiments show that FlashVSR scales reliably to ultra-high resolutions and achieves state-of-the-art performance with up to 12x speedup over prior one-step diffusion VSR models. We will release the code, pretrained models, and dataset to foster future research in efficient diffusion-based VSR.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces FlashVSR, a new AI system that makes blurry or low-quality videos look sharp and detailed in real time. The authors focus on making a powerful type of AI called a diffusion model fast enough to fix high‑resolution videos while they are streaming, without long delays.
What questions are the authors trying to answer?
- How can we use diffusion models (which usually take many slow steps) to improve video quality fast enough for live or long videos?
- How do we make the model handle very large video frames (like 1440p) without breaking or slowing down too much?
- Can we reduce waiting time (latency) so viewers don’t have to wait for many frames to be processed before seeing the improved video?
- Can we keep high visual quality while making the system small and efficient?
How does FlashVSR work? (Methods and simple explanations)
FlashVSR combines three main ideas to be both fast and good:
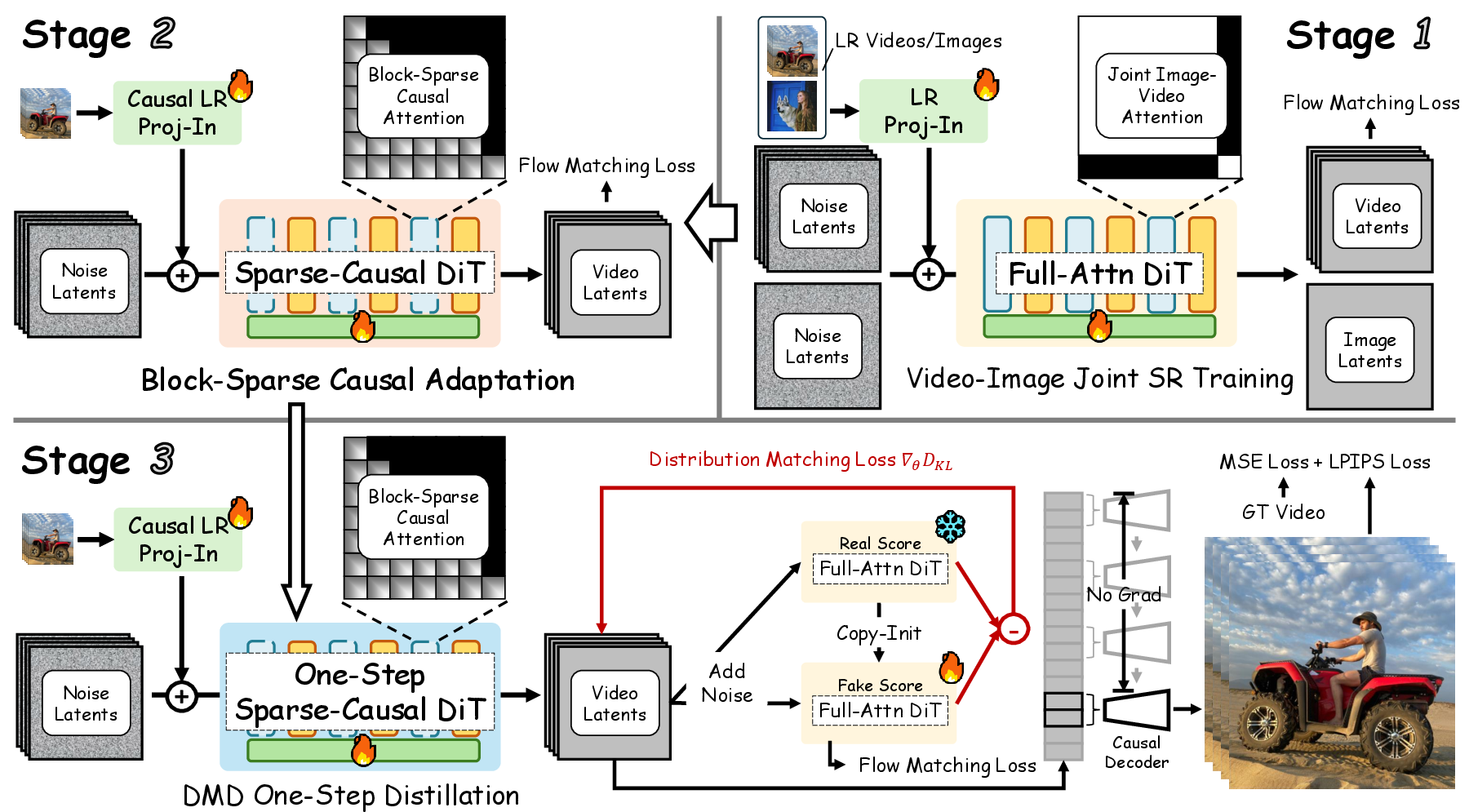
1) A three‑stage “teacher‑student” training pipeline
Think of this like learning from a coach and then training to do it faster:
- Stage 1: Train a strong “teacher” model on both images and videos. This model looks everywhere in the video to understand patterns and textures.
- Stage 2: Teach the model to work in a streaming way, only looking at the current and past frames (not future ones), and to focus attention only where it matters most (more on “attention” below).
- Stage 3: Distill the model into a “one‑step” student that can do the whole improvement in a single go, instead of many slow diffusion steps. This makes it much faster.
Simple term guide:
- Diffusion model: An AI that cleans up noise step by step to create or restore images/videos. One‑step means it does all the cleaning in one shot instead of many steps.
- Distillation: Training a smaller/faster student model to mimic a larger/slower teacher, like learning shortcuts without losing skill.
- Streaming: Processing frames as they arrive, like watching the video while it’s being improved.
2) Locality‑constrained sparse attention
Attention is like “where the model chooses to look.” Full attention tries to look everywhere in all frames, which is slow and heavy for big videos.
FlashVSR uses:
- Sparse attention: It only uses full attention on the most important regions (top‑k areas), saving time.
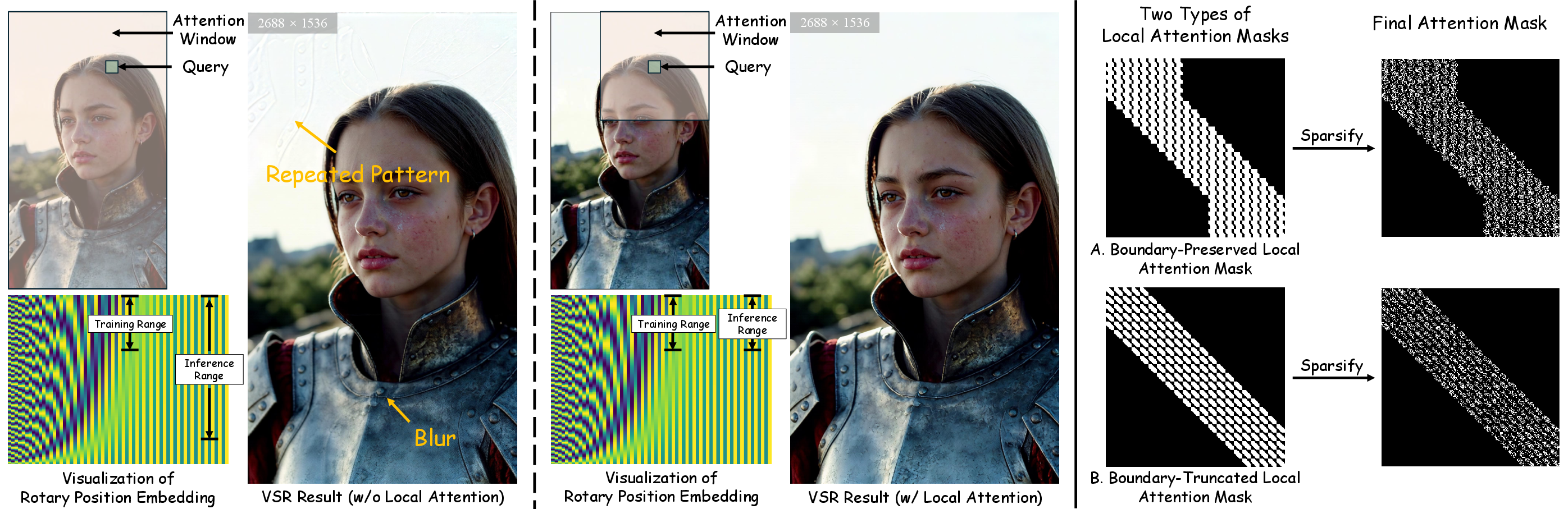
- Locality constraints: At very high resolutions, models can get confused about positions and repeat patterns or blur. So FlashVSR restricts attention to nearby areas (local windows), keeping the “sense of position” consistent between training and testing. This helps the model generalize better to ultra‑high resolutions.
Analogy:
- Instead of reading every word in a huge book, the model skims summaries first, then reads only the key paragraphs—and stays focused on the nearby context to avoid getting lost.
3) A tiny conditional decoder
After the main model improves the “compressed” representation of the video (called latents), a decoder turns it back into a full‑resolution frame. The usual decoder is big and slow.
FlashVSR’s decoder:
- Is smaller and faster (“tiny”).
- Uses the original low‑resolution frame as a helpful guide, so it can rebuild the full image with fewer parameters and less time, without losing detail.
Analogy:
- If you’re redrawing a picture from memory, it’s faster and more accurate if you can peek at the small version while you draw the big one.
Plus: A new large dataset for training
The authors built VSR‑120K, a large training set with about 120,000 videos and 180,000 high‑quality images, filtered by automated quality checks. This big, clean dataset helps the model learn strong, general skills.
What did they find? (Results and why they matter)
- Speed: FlashVSR runs at about 17 frames per second on 768×1408 videos using a single A100 GPU. That’s near real‑time and up to about 12× faster than the best previous one‑step diffusion VSR, and over 100× faster than some multi‑step methods.
- Low latency: It only needs to look ahead 8 frames, instead of waiting for whole chunks (like 32–100 frames) before showing results. This is better for streaming and live video.
- High quality: It produces sharper textures and more natural details. On several benchmarks (like YouHQ40, REDS, SPMCS, VideoLQ, and AIGC30), it scores state‑of‑the‑art or very competitive results—especially on “perceptual” metrics designed to match human judgment (MUSIQ, CLIPIQA, DOVER).
- Scales to big videos: Thanks to locality‑constrained attention, it handles ultra‑high resolutions (like 1440p) more reliably, avoiding repeating patterns and blur.
- Efficient decoding: The tiny conditional decoder is about 7× faster than the standard decoder while keeping similar visual quality.
Why this is important:
- It makes diffusion‑based video enhancement practical for real use—like streaming, mobile apps, or long videos—without huge delays or massive hardware.
- It keeps visual quality high while cutting compute and memory costs.
What is the potential impact?
- Better live streams and online videos: Viewers can see cleaner, sharper video with minimal delay.
- Mobile and edge devices: More efficient models mean this could eventually run outside large servers.
- High‑resolution content: Creators and platforms can improve 1080p–1440p videos consistently.
- Research boost: The team plans to release code, models, and the VSR‑120K dataset, helping others build even more efficient and high‑quality video restoration systems.
In short
FlashVSR is a fast, streaming-friendly video super‑resolution system based on diffusion models. By learning from a strong teacher, focusing attention only where needed, and using a tiny but smart decoder, it delivers sharp, detailed videos in near real time—even at high resolutions—with much lower delay and compute than previous methods.
Knowledge Gaps
Below is a concise list of the knowledge gaps, limitations, and open questions that remain unresolved and could guide future research:
- Real-world generalization: The model is trained with synthetic degradations (RealBasicVSR pipeline) and evaluated on real videos with only no-reference metrics; its fidelity under truly unknown, device-/codec-/sensor-specific degradations remains unquantified.
- Lack of temporal consistency metrics: No explicit temporal metrics (e.g., warping error, tLPIPS, temporal SSIM, FVD, VMAF) are reported, leaving temporal stability and flicker robustness underexplored.
- Failure-case characterization: There is no systematic analysis of failure modes (e.g., fast/complex motion, large parallax, occlusions, rolling shutter, severe compression, low-light/high-ISO noise, motion blur), making it unclear when one-step streaming may break down.
- Extremely long sequences: Although positioned for “minutes or longer,” experiments use 101-frame clips; performance, drift, and cache strategies for hour-long streams are not evaluated.
- Latency–quality trade-off: The choice of 8-frame lookahead is not ablated; it is unknown how latency constraints affect quality across content types and resolutions.
- 4K/8K scalability: Claims of scaling to high resolutions stop at 1440p; end-to-end throughput, memory, and quality for 4K/8K streams are unreported.
- Hardware portability: Real-time performance is shown only on an A100; feasibility on commodity GPUs (e.g., 4090, laptop GPUs) or edge devices, and the effect of reduced memory/compute, is unknown.
- Dataset bias and coverage: VSR-120K is curated from stock content with automatic quality/motion filters (LAION-Aesthetic, MUSIQ, RAFT); the content, motion, and scene diversity—and potential biases introduced by these filters—are not analyzed.
- Paired real data: The work does not evaluate on large-scale, truly paired real LR–HR video datasets, limiting conclusions about real-world fidelity versus hallucination.
- Human perceptual studies: No user studies are conducted; whether the perceptual gains on IQA metrics translate to human preference is unknown.
- Fidelity-sensitive content: Text legibility, faces/identity preservation, and fine structured patterns (e.g., signage, license plates, screens, moiré/aliasing) are not explicitly assessed.
- Hallucination control: Diffusion-based VSR can hallucinate textures; the paper lacks controls/metrics for hallucination detection and mitigation in safety-/accuracy-critical domains.
- Sparse attention design: The top-k block-sparse scheme is fixed; sensitivity to k, block size (2,8,8), and dynamic/adaptive sparsity under large motion or long-range dependencies is not studied.
- Missed long-range dependencies: Locality-constrained spatial attention may impair global structure modeling; the impact on scenes requiring nonlocal spatial or long-range temporal reasoning is not quantified.
- Temporal sparsity: Locality constraints are applied spatially; whether analogous temporal locality (e.g., variable temporal windows) would improve or harm consistency is unexplored.
- RoPE periodicity alternatives: The locality fix addresses positional range mismatch; comparisons to alternative positional schemes (e.g., NTK-scaled RoPE, ALiBi, learned relative PE) are missing.
- Learned routing vs heuristic sparsity: The coarse pooled attention used to rank blocks is heuristic; learned routing/gating or token pruning might yield better quality–efficiency trade-offs but are not explored.
- One-step distillation stability: The distribution-matching distillation (DMD) setup and loss blending (FM + pixel + LPIPS) are not ablated; stability, convergence, and sensitivity to hyperparameters are unclear.
- Dependence on large teacher: The pipeline relies on a WAN 2.1 1.3B teacher; portability to smaller/backbone-agnostic teachers and the impact on student quality/efficiency are not examined.
- KV-cache behavior: Cache length choices, memory–quality trade-offs, and strategies for cache refresh/reset on very long streams are not ablated.
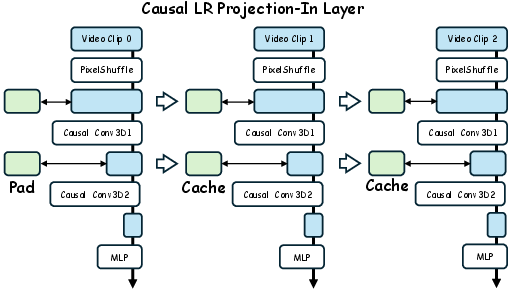
- LR Proj-In vs VAE encoder: Replacing the VAE encoder with LR Proj-In is introduced but not dissected; the trade-offs in information retention, robustness to LR noise, and generalization are unclear.
- Conditional decoder robustness: The tiny conditional decoder conditions on LR frames; robustness to LR artifacts (e.g., codec ringing, banding, sensor noise), domain shifts, and unseen codecs is not studied.
- TC decoder training scale: The TC decoder is trained at 384×384; its generalization to much higher resolutions (e.g., 4K) without retraining or tiling artifacts is untested.
- Semantic/text conditioning: A fixed text prompt is used; the effect of text conditioning on restoration (e.g., biasing content, hallucinations) and whether prompt-free variants perform better is unanswered.
- Variable and mixed framerates: Robustness to variable frame rate, dropped frames, and desynchronization typical in streaming pipelines is not evaluated.
- Streaming system integration: End-to-end system latencies (I/O, buffering, audio sync), adaptive bitrate integration, and online quality control are out of scope but critical for deployment.
- Quantization and low-precision inference: INT8/FP8/quantization-aware training effects on quality and speed are not reported; this limits deployability on constrained hardware.
- Energy and compute cost: Training requires 32×A100 GPUs for multiple days; carbon/energy footprint and cost–benefit relative to non-diffusion VSR are not assessed.
- Generalization beyond VSR: Extending the streaming one-step framework to other restoration tasks (deblurring, deblocking, denoising, demosaicing) or joint tasks (SR+denoise) is an open direction.
- Robustness to content domains: Performance on OOD domains (underwater, thermal/IR, night, dashcam, medical, satellite) is unknown.
- Scale factor clarity: The upscaling factor(s) used (e.g., 2×, 4×) are not clearly specified; support for variable or arbitrary scales is not discussed.
- Adaptive lookahead: A mechanism to adapt lookahead frames to content (motion, scene cuts) to balance latency and quality is not proposed.
- Licensing and ethics of VSR-120K: Dataset licensing, consent, and potential downstream ethical risks (e.g., upscaling sensitive content) are not discussed.
Glossary
- AdamW optimizer: An optimization algorithm that decouples weight decay from the gradient-based update to improve training stability. "The AdamW optimizer~\citep{loshchilov2017decoupled} is used with learning rate and weight decay $0.01$."
- adversarial training: A training strategy that pits a generator against a discriminator to improve sample realism or robustness. "and adversarial training~\citep{yin2024one,wang2023prolificdreamer} compress iterative denoising into a single step"
- autoregressive: A modeling approach where each output depends on previously generated outputs in sequence. "previous autoregressive VSRs~\citep{huang2025self,lin2025autoregressive}"
- block-diagonal segment mask: An attention mask that restricts attention to tokens within the same segment, preventing cross-segment interactions. "we apply a block-diagonal segment mask that restricts attention within the same segment:"
- block-sparse attention: An attention mechanism that computes attention only over selected blocks of tokens to reduce computation. "by introducing causal masking and block-sparse attention"
- block-wise sequential processing: Processing data in blocks sequentially to enable causal or streaming generation. "Diffusion Forcing~\citep{chen2024diffusion} reformulates denoising as block-wise sequential processing, enabling causal decoding."
- boundary-preserved (local window rule): A local attention windowing rule that preserves queries near boundaries within the window. "Two local window rules, namely boundary-preserved and boundary-truncated, are illustrated."
- boundary-truncated (local window rule): A local attention windowing rule that truncates attention windows at image boundaries. "Two local window rules, namely boundary-preserved and boundary-truncated, are illustrated."
- causal attention: Attention that only accesses current and past tokens, enforcing temporal causality. "combined causal attention, KV-cache, and distillation"
- causal decoding: Generating outputs in a time-ordered manner where each step only uses current/past information. "enabling causal decoding."
- causal masking: An attention mask that blocks access to future positions to enforce causality. "by introducing causal masking and block-sparse attention"
- CLIPIQA: A no-reference perceptual quality metric derived from CLIP-like models for IQA. "MUSIQ, CLIPIQA, and DOVER"
- cross-attention: Attention where queries attend to keys/values from a different modality or source (e.g., text to image/video). "with cross-attention keys and values reused across samples."
- dense 3D attention: Full spatiotemporal attention over all tokens in space and time, with quadratic complexity in resolution. "high computational cost of dense 3D attention."
- DiT (Diffusion Transformer): A transformer architecture tailored for diffusion models, often used for image/video generation or restoration. "the accelerating diffusion transformer block (DiT)"
- distribution-matching distillation (DMD): A distillation method that matches the student’s output distribution to a teacher’s via a learned objective. "The overall objective combines distribution-matching distillation, flow matching, and pixel-space reconstruction losses:"
- FlashAttention: An efficient attention algorithm that reduces memory overhead and supports sparsity for faster computation. "FlashAttention~\citep{dao2022flashattention} improves memory and computation efficiency while also supporting block-sparse mechanisms"
- flow matching loss: A training objective that aligns a model’s vector field with an ideal probability flow, enabling fast sampling. "Training employs the standard flow matching loss~\citep{lipman2022flow}."
- KV-cache: Cached key/value tensors from prior steps to reuse in attention and accelerate autoregressive or streaming inference. "combined causal attention, KV-cache, and distillation"
- latent: A compact representation in a learned latent space (e.g., VAE latents) used for efficient modeling and reconstruction. "all latents trained under a unified timestep"
- locality-constrained attention: Attention restricted to a spatial neighborhood to align positional ranges between training and inference. "we introduce locality-constrained attention"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects low-rank adapters into a pretrained model. "fine-tuned with LoRA~\citep{hu2022lora} (rank 384)."
- LPIPS: A learned perceptual image patch similarity metric that correlates with human judgments of visual quality. "LPIPS~\citep{zhang2018unreasonable}"
- lookahead latency: The delay introduced by needing future frames before producing the current output in streaming/chunked processing. "a high lookahead latency before the entire chunk finishes processing"
- NIQE: Naturalness Image Quality Evaluator; a no-reference metric that estimates perceptual quality. "NIQE "
- one-step distillation: Compressing multi-step diffusion sampling into a single step via distillation techniques. "One-step distillation."
- optical-flow-guided propagation: Using estimated motion (optical flow) to propagate information across frames for temporal consistency. "Upscale-A-Video~\citep{zhou2024upscale} employs optical-flow-guided propagation"
- positional encoding ranges: The span of positions covered by positional encodings; mismatches across train/test resolutions can degrade attention. "mismatched positional encoding ranges between training and inference."
- PSNR: Peak Signal-to-Noise Ratio; a fidelity metric comparing reconstructed and ground-truth images. "PSNR~\citep{psnr}"
- RAFT: Recurrent All-Pairs Field Transforms; a deep model for accurate optical flow estimation. "and RAFT~\citep{teed2020raft} for motion filtering."
- RealBasicVSR degradation pipeline: A synthetic degradation process used to generate realistic low-quality inputs for training VSR. "RealBasicVSR degradation pipeline~\citep{chan2022investigating}"
- rectified flows: A family of flow-based training techniques enabling straight-line probability flows for faster diffusion sampling. "Methods based on rectified flows~\citep{liu2022flow,liu2023instaflow}"
- RoPE: Rotary Position Embedding; a relative positional encoding method enabling extrapolation and efficient attention. "With the relative formulation of RoPE~\citep{su2024roformer}"
- score distillation: A method that distills guidance or scores from a teacher diffusion model to a student, often for one-step sampling. "score distillation~\citep{lin2025diffusion,zhang2024sf}"
- sparse attention: Limiting attention computations to a subset of tokens to reduce complexity while preserving performance. "Sparse attention."
- spatiotemporal attention: Attention operating jointly over spatial and temporal dimensions to model video dependencies. "full spatiotemporal attention"
- SSIM: Structural Similarity Index; a perceptual fidelity metric emphasizing structural information. "SSIM~\citep{ssim}"
- streaming inference: Online processing that emits outputs with minimal buffering, suitable for long or real-time sequences. "With streaming inference, block-sparse attention, one-step distillation, and a lightweight conditional decoder"
- student forcing: Training by conditioning on the model’s own previous predictions to mitigate exposure bias at inference. "student forcing (conditioning on predicted latents)"
- teacher forcing: Training by conditioning on ground-truth previous outputs, which can cause error accumulation at test time. "Teacher forcing (conditioning on ground truth)"
- Tiny Conditional Decoder (TC Decoder): A lightweight decoder that reconstructs high-resolution frames conditioned on both LR inputs and latents. "Tiny Conditional Decoder (TC Decoder, Fig.~\ref{fig:decoder})"
- top-k selection: Selecting the k most relevant regions or blocks for attention to focus computation. "apply full attention only to the top- regions with the highest scores."
- VAE decoder: The decoder part of a Variational Autoencoder that reconstructs images/videos from latent codes. "the causal 3D VAE decoder becomes the primary runtime bottleneck"
- video super-resolution (VSR): The task of enhancing the resolution and quality of video frames from low-resolution inputs. "Video super-resolution(VSR) has wide application in smartphone photography, social networks, and live streaming."
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage FlashVSR’s one-step streaming diffusion, locality-constrained sparse attention, and tiny conditional decoder to deliver real-time or near–real-time video super-resolution (VSR).
- Media/Streaming and Social Platforms
- Edge upscaling at CDN nodes for low-bitrate live streams (e.g., sports, esports, concerts), reducing origin bandwidth while restoring high-quality playback near real time.
- Tools/workflows: FFmpeg/GStreamer filter (e.g., vf=flashvsr), WebRTC SFU plugin for server-side enhancement, ONNX Runtime/TensorRT deployment for A100/L40.
- Assumptions/dependencies: GPU at edge PoPs; 8-frame lookahead buffering; content moderation policies acknowledging generative SR.
- Creator tools for UGC platforms: batch enhancement of uploaded videos to improve perceived quality and watch time with limited compute.
- Tools/products: Adobe/Premiere/DaVinci Resolve plugin; platform-side media pipeline operator.
- Assumptions: acceptable compute budgets and disclosure that fine textures may be synthesized.
- Video Conferencing and Remote Education
- Gateway- or client-side upscaling for low-bitrate calls to improve readability (slides, whiteboards, faces) without changing encoders.
- Tools/workflows: WebRTC insertable streams; Zoom/Teams SDK plugin; OBS Studio real-time filter for presenters.
- Assumptions: 8-frame lookahead (~250–500 ms at typical FPS) is tolerable in many education/broadcast settings; for interactive scenarios, reduce resolution or window size.
- Mobile and Consumer (Daily Life)
- Smartphone app or camera firmware to enhance archived clips and short live streams from action cams/drones in near real time.
- Tools/products: Mobile offload to laptop/console GPU; on-device NPU prototype using quantized sparse attention + tiny decoder.
- Assumptions: consumer GPUs deliver lower FPS than A100; real-time requires careful quantization/pruning and window tuning.
- Security/Surveillance and Retail Analytics
- Pre-analytics enhancement (license plate/text readability, person re-ID) for low-res CCTV feeds before OCR/reID models.
- Tools/workflows: GStreamer element in VMS pipeline; batched inference with KV-cache; downstream analytics integration.
- Assumptions: not for evidentiary use without policy safeguards; document synthetic-detail risks; domain-specific re-training may be required.
- Robotics/Teleoperation and Industrial Remote Inspection
- Operator-view enhancement for drones/ROVs to reduce link bandwidth while preserving situational detail.
- Tools/workflows: edge module on base station; ROS/GStreamer integration; adjustable attention locality for latency control.
- Assumptions: 8-frame lookahead may be borderline for closed-loop control—use lower resolutions or tighter windows; test task safety.
- Post-Production and Broadcast Operations
- Fast dailies/rough-cut upscaling and archival content enhancement with the tiny conditional decoder to cut render times by ~7× versus standard decoders.
- Tools/products: NLE plugin; cloud render microservice; overnight batch jobs.
- Assumptions: quality controls for hallucinated textures; retain originals for audits.
- Research Infrastructure (Academia/Industry R&D)
- Immediate benchmarking and training using VSR-120K (120k videos, 180k images) to study real-world degradations and scaling to ultra-high resolutions.
- Tools/workflows: open code/models/dataset; ablations of block-sparse attention and locality windows; reproducible baselines.
- Assumptions: verify licensing for commercial training; ensure degradation pipelines match deployment domains.
- Energy/Network Cost Optimization (Cross-Sector)
- Ship lower bitrates then restore at the edge, cutting transit bandwidth while maintaining QoE (MUSIQ/CLIPIQA/DOVER gains).
- Tools/workflows: A/B tests with VMAF/QoE telemetry; adaptive enablement by network conditions.
- Assumptions: compute vs. bandwidth trade-offs; carbon accounting for GPU nodes.
Long-Term Applications
Below are forward-looking applications that need further research, scaling, validation, or specialized compliance before routine deployment.
- Healthcare/Telemedicine
- Enhancement of clinical video (e.g., endoscopy, ultrasound cine) to improve visibility under bandwidth constraints.
- Potential product: regulated “assistive visualization” module with clinician-in-the-loop.
- Dependencies: rigorous clinical validation for diagnostic safety; FDA/CE approvals; domain-specific training; strict controls to prevent hallucination of anatomy/pathology.
- 4K/8K OTT and Broadcast at Scale
- Real-time 4K–8K upscaling for premium live events using locality-constrained sparse attention and one-step streaming on dedicated accelerators.
- Potential product: FPGA/ASIC or GPU cluster with KV-cache orchestration; CDN edge upgrade path.
- Dependencies: hardware acceleration for sparse attention; scheduler for multi-program channels; tighter latency budgets than current 8-frame lookahead.
- Satellite, Aerial, and Smart Infrastructure Inspection
- SR for UAV/satellite video and industrial inspections (power lines, rails, wind turbines) to improve defect detection at lower capture bitrates.
- Potential workflow: on-drone/edge inference; SLAM/GIS-aware postprocessing; analytics handoff.
- Dependencies: training on domain-specific textures and motion; robust performance under compression/atmospheric artifacts; safety cases for automated decisions.
- Automotive ADAS and V2X
- Enhancing teleoperation feeds or map-building video where sensors operate at constrained bitrates; improving OCR/sign detection in dashcam logs.
- Dependencies: ISO 26262 safety processes; deterministic latency bounds; exhaustive validation to avoid SR-induced perception errors.
- Policy, Standards, and Governance
- Standards for disclosure and metadata tagging of SR-enhanced video; guidance for forensic admissibility and auditing pipelines.
- Potential tools: tamper-evident provenance (C2PA) with SR indicators; “for review only” overlays for law enforcement use.
- Dependencies: multi-stakeholder consensus (platforms, regulators, broadcasters); best-practice playbooks addressing synthetic-detail risks.
- Generalized Real-Time Restoration Platform
- Extending the streaming one-step diffusion + sparse attention blueprint to deblurring, deblocking, denoising, and multi-task restoration.
- Potential product: unified “video restoration microservice” with task routing and shared KV-cache.
- Dependencies: multi-task training; scheduler for mixed workloads; dynamic sparsity controllers.
- On-Device and Edge-NPU Deployment
- Hardware-software co-design to exploit block-sparse attention and the tiny conditional decoder on mobile/embedded NPUs.
- Potential product: SDK for Android/iOS/AR glasses; browser/WebGPU prototype for client-side enhancement.
- Dependencies: quantization-aware training; memory-aware KV-cache; local-window tuning to meet <150 ms E2E latency.
- Academic Extensions
- Fundamental research on positional-encoding range alignment via locality constraints for long-context transformers; error accumulation vs. student/teacher forcing in restoration; scalable distribution-matching distillation for other spatiotemporal tasks.
- Dependencies: open benchmarks with ultra-high-resolution, long-duration sequences; shared protocols for latency/quality trade-offs.
Notes on feasibility and dependencies across applications:
- Hardware: The reported ~17 FPS at 768×1408 uses a single A100; achieving similar throughput on consumer GPUs or NPUs requires sparsity-aware kernels, quantization, and potential resolution/latency trade-offs.
- Latency: 8-frame lookahead reduces chunk latency dramatically but may still be high for some interactive controls; adjust local window sizes or run at lower resolutions for tighter budgets.
- Data and licensing: VSR-120K sources (Videvo, Pexels, Pixabay) should be reviewed for commercial terms; additional domain data may be needed for specialized sectors.
- Risk management: Diffusion-based SR can synthesize plausible textures; workflows should include disclosure, provenance, QA sampling, and “no-forensics” flags where appropriate.
- Training cost: The three-stage pipeline (teacher → sparse-causal → one-step) currently assumes multi-GPU resources; downstream adopters can fine-tune released weights instead of training from scratch.
Collections
Sign up for free to add this paper to one or more collections.