UMO: Unified In-Context Learning Unlocks Motion Foundation Model Priors
Abstract: Large-scale foundation models (LFMs) have recently made impressive progress in text-to-motion generation by learning strong generative priors from massive 3D human motion datasets and paired text descriptions. However, how to effectively and efficiently leverage such single-purpose motion LFMs, i.e., text-to-motion synthesis, in more diverse cross-modal and in-context motion generation downstream tasks remains largely unclear. Prior work typically adapts pretrained generative priors to individual downstream tasks in a task-specific manner. In contrast, our goal is to unlock such priors to support a broad spectrum of downstream motion generation tasks within a single unified framework. To bridge this gap, we present UMO, a simple yet general unified formulation that casts diverse downstream tasks into compositions of atomic per-frame operations, enabling in-context adaptation to unlock the generative priors of pretrained DiT-based motion LFMs. Specifically, UMO introduces three learnable frame-level meta-operation embeddings to specify per-frame intent and employs lightweight temporal fusion to inject in-context cues into the pretrained backbone, with negligible runtime overhead compared to the base model. With this design, UMO finetunes the pretrained model, originally limited to text-to-motion generation, to support diverse previously unsupported tasks, including temporal inpainting, text-guided motion editing, text-serialized geometric constraints, and multi-identity reaction generation. Experiments demonstrate that UMO consistently outperforms task-specific and training-free baselines across a wide range of benchmarks, despite using a single unified model. Code and model will be publicly available. Project Page: https://oliver-cong02.github.io/UMO.github.io/
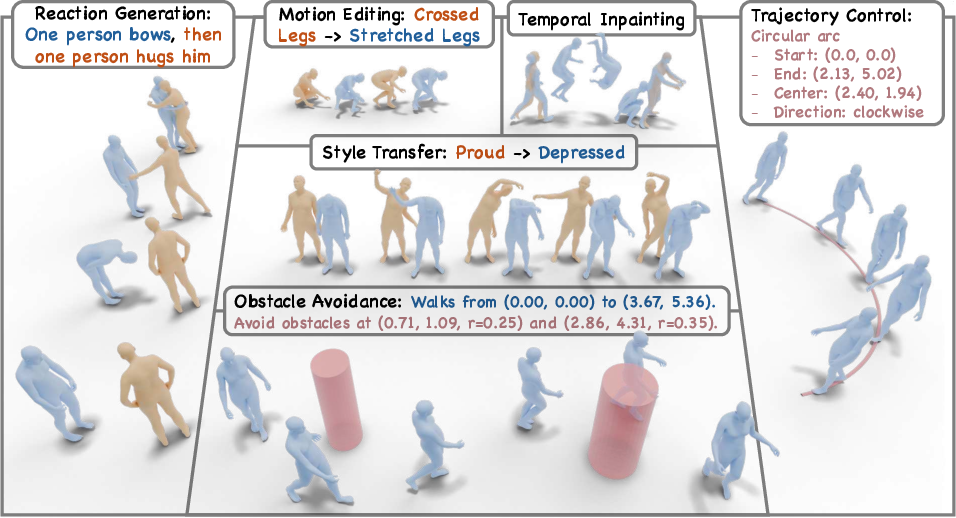
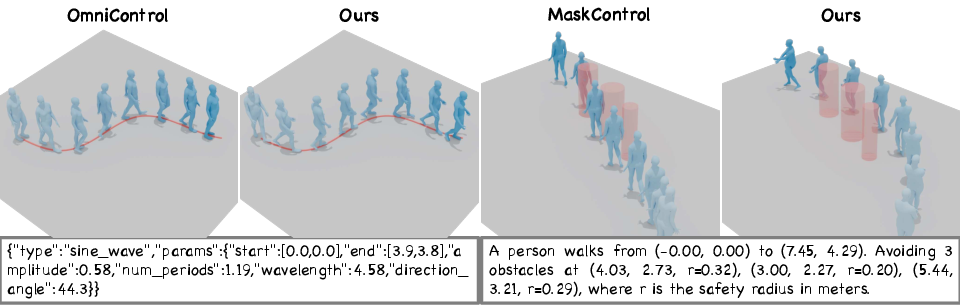

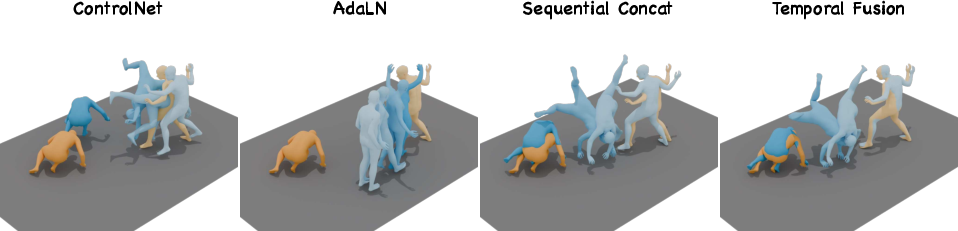





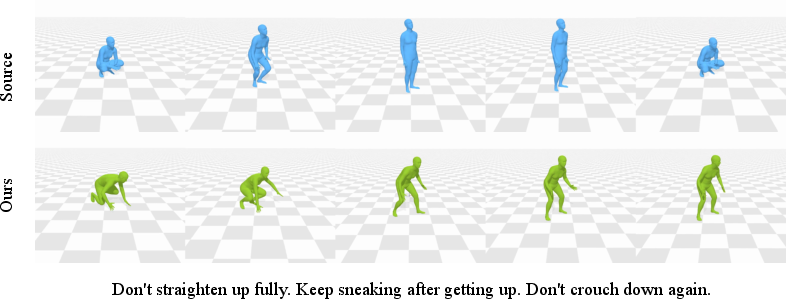


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a big “motion” AI model to do many different jobs with human movements—like filling in missing parts of a motion, editing a motion based on text instructions, following a path, avoiding obstacles, or reacting to another person—without rebuilding the model each time. The authors call their method UMO (Unified In-Context Learning for Motion), and it turns one powerful text-to-motion model into a flexible, all-in-one motion tool.
What questions did the researchers ask?
The researchers wanted to answer three simple questions:
- Can we reuse a single, strong motion model (originally trained just to turn text into motion) for many other motion tasks?
- Is there a simple way to “tell” the model what to do at each moment in a motion without changing its core design?
- Can we make this work fast and reliably across many tasks using the same setup?
How did they approach the problem?
Think of a motion (like someone walking, jumping, or waving) as a sequence of frames—like a flipbook. For each frame, UMO decides what to do using just three “buttons.” Then it tells the model what it wants in plain language.
The three “buttons” for each frame
UMO says every frame of motion you want can be handled by exactly one of three actions:
- Preserve: keep this frame exactly as it is.
- Generate: make a new frame from scratch.
- Edit: change this frame based on instructions.
You can imagine a timeline where each frame gets a small tag—[preserve], [generate], or [edit]—that tells the model the plan. By mixing and matching these tags along the timeline, you can describe lots of tasks:
- Filling in gaps (inpainting): mark missing frames as [generate] while keeping known frames as [preserve].
- Editing: mark frames as [edit] and give instructions like “walk faster” or “turn left.”
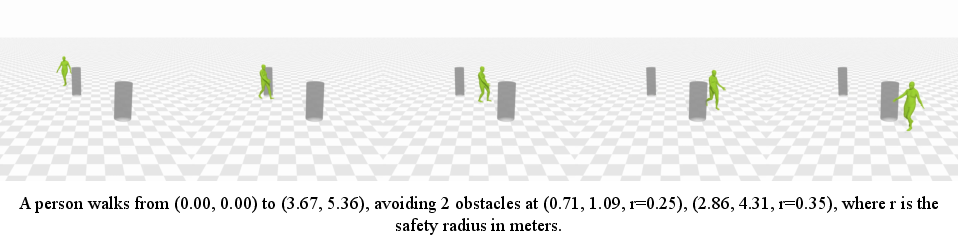
- Following paths or avoiding obstacles: mark frames as [generate] or [edit] and describe the path/obstacles in text.
- Reactions between two people: use one person’s motion as context and [edit]/[generate] the other person’s frames to react.
Telling the model what you want—using plain language
Instead of building a special input for each task, UMO turns all task instructions into text. That includes:
- Normal descriptions like “a person kicks a ball.”
- Editing instructions like “speed up the motion” or “make the person wave.”
- Geometry written as text, like “walk from (0,0) to (4,6) and avoid obstacles at (2.5, 3.0) with safety radius 0.4.”
A LLM (think: a big text understanding system) reads these prompts and passes the meaning to the motion model.
How UMO plugs into the model (without changing it)
UMO uses a tiny “adapter” that mixes the frame tags and any provided source motion into the model’s input—this is called “temporal fusion.” You can think of it like mixing two audio tracks: one is the model’s usual input, the other carries your “what to do” signals. This add-on is small and fast, and it doesn’t require changing the original model’s architecture.
What did they find?
Across many tests, UMO—with one unified model—beat or matched task-specific methods that were built just for one job. Here’s why that’s impressive and where it showed up:
- Text-to-motion (the original job): After fine-tuning, UMO produced motions that matched text well and looked realistic, reaching top results on standard benchmarks.
- Temporal inpainting (filling gaps, predicting the future, backcasting the past, infilling between keyframes): UMO generated smooth, natural motions that respected the frames it was supposed to keep and cleanly filled in the missing parts—often better than specialized tools.
- Text-guided editing: Given instructions like “slow down,” “turn right,” or “add happy style,” UMO made precise edits while preserving the rest of the motion well, scoring near-perfect on certain evaluation tests.
- Geometric constraints in text (following paths and avoiding obstacles): Even though the motion model had never seen this kind of input before, UMO learned to follow paths and avoid obstacles described in plain text, achieving accuracy close to specialized systems while being much faster than optimization-heavy methods.
- Two-person reactions: Although the base model was trained only on single-person motion, UMO could make a second person react naturally to the first (like dodging, greeting, backing away). This suggests the model’s “sense of movement” transfers to interactions when guided correctly.
Why this matters: Instead of building a new model or add‑on for every task, you can use one model with a simple, shared recipe—frame tags plus text prompts.
Why is this important?
- One model for many jobs: UMO shows a practical way to reuse a powerful motion model for a wide range of tasks. This saves time, data, and compute.
- Simple control language: Describing goals and constraints in text makes the system easy to extend—just write a new prompt style instead of redesigning the model.
- Speed and efficiency: The tiny adapter adds almost no extra runtime, so it’s still fast.
- Strong generalization: The big motion model’s “instincts” about how humans move can be unlocked for tasks it wasn’t originally trained for—like obstacle avoidance or two-person reactions.
What are the limits and what’s next?
- Whole-body control only: The three buttons work per frame for the whole body; controlling individual body parts independently (like only the right arm) isn’t built in yet.
- Only text inputs: The paper focuses on language instructions; future versions could include audio (like syncing to music) or other signals.
Bottom line
UMO is like turning a single-purpose athlete into a versatile team player using a simple playbook: three frame-level buttons and plain-language instructions. With this, a single pretrained motion model can fill gaps, edit motions, follow paths, avoid obstacles, and even create two-person reactions—all without changing the model’s core design. This points to a future where one unified system can handle most motion tasks just by changing the instructions you give it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that future work could address:
- Lack of part-level control: meta-operations are defined at the whole-body frame level; there is no per-joint/limb “preserve/edit/generate” control for spatially localized edits or mixed intents within a single frame.
- No automatic localization of edits: the framework assumes a pre-specified per-frame meta-operation schedule; it does not infer which temporal regions to edit/preserve from free-form instructions or from context automatically.
- No guarantees for hard constraints: [preserve] frames are not strictly copied (non-zero [P]-MPJPE); methods to enforce exact constraints (hard replacement, differentiable constraints, or constrained ODE solvers) are not explored.
- Limited modality coverage: conditioning is language-only; integration of audio, video, scene mesh, and object signals (and their conflicts) is not studied.
- Reliance on a single LLM encoder: sensitivity to prompt phrasing, numeric tokenization, unit conventions, and the choice or size of the LLM is not analyzed; robustness to noisy/mis-specified prompts is unknown.
- Language-serialized geometry scalability: only simple 2D trajectory and obstacle constraints are demonstrated; generalization to 3D scene constraints (stairs, slopes, uneven terrain), contact-rich behaviors, or dense/cluttered scenes is untested.
- Limited geometric data scale and diversity: trajectory/obstacle datasets contain 2,000 sequences per task; out-of-distribution generalization to complex, real-world scenes is unclear.
- Constraint compositionality and conflict resolution: how the model handles multiple simultaneous constraints (e.g., style + trajectory + obstacles + keyframe preservation), especially when they conflict, is not evaluated.
- Physical plausibility not measured: no metrics for foot sliding, contact consistency, dynamics plausibility, or interpenetration are reported; impact of adding physics priors or constraints remains open.
- Reaction generation scope: only two-person interactions are considered; extension to N-person scenarios, role-conditioned interactions, and explicit inter-body collision avoidance/contact modeling is unexplored.
- Identity and style control in multi-actor settings: mechanisms to preserve or control individual identity, style, or persona across interacting agents are not provided.
- Backbone generality: results are tied to HY-Motion (MMDiT, rectified flow); portability to other motion backbones (e.g., decoder-only NTP, diffusion U-Nets, masked models) is not validated.
- Scale vs. performance: the study uses HY-Motion-Lite (460M); whether the approach scales favorably to 1B+ backbones or smaller edge models, and the associated accuracy/latency trade-offs, is unreported.
- Adapter vs. full finetuning: while parameter overhead is small, the backbone is finetuned; the trade-offs of fully frozen backbones with parameter-efficient adapters (LoRA, IA³, adapters) are not analyzed.
- Long-horizon generation: behavior and stability on very long sequences (beyond those evaluated) and memory/runtime scaling with sequence length remain untested.
- ODE solver sensitivity: only a 50-step Euler ODE is used; effects of solver choice, step budget, and stability/quality trade-offs are not studied.
- Negative transfer and task balancing: unified training reportedly helps, but there is no analysis of task sampling strategies, curriculum learning, or interference across tasks and datasets.
- Robustness to dataset/domain shift: adaptation from pretraining to HumanML3D reveals distribution gaps; systematic evaluation across more datasets, motion styles, and skeleton variations (including cross-dataset skeleton retargeting) is missing.
- Skeleton/general rig support: the method assumes a fixed representation; generalization across rigs and retargeting to new skeletal topologies is not addressed.
- Evaluation breadth for editing: instruction-following accuracy is measured via retrieval; human studies or richer task-specific metrics (locality of edits, preservation of untouched attributes) are absent.
- Safety and social norms: for multi-actor motion, adherence to social distances, collision avoidance, and culturally appropriate reactions is not evaluated.
- Uncertainty handling: the framework does not quantify or propagate uncertainty (e.g., multiple plausible in-paintings or reactions); mechanisms for sampling diverse yet constraint-satisfying motions are not explored.
- Real-time/interactive control: although overhead is low, end-to-end latency and stability for interactive applications (live editing, on-the-fly constraints) are not characterized.
- Automatic meta-operation discovery: the three atomic operations are fixed a priori; whether additional operations (e.g., blend, constrain, copy-part) or learned/latent operation types could improve expressivity is an open question.
- Compositional generalization of prompt templates: while new constraint types can be added via templates, the limits of template compositionality and generalization to unseen template forms or numeric ranges are unclear.
Practical Applications
Overview
UMO introduces a unified, in-context motion generation framework that reuses a pretrained text-to-motion foundation model (HY-Motion) for a broad set of tasks through:
- Three per-frame meta-operation embeddings — [preserve], [generate], [edit] — to specify intent at frame granularity without modifying the backbone.
- Lightweight temporal fusion to inject in-context cues with negligible overhead (≈0.207M parameters, minimal latency).
- A unified language interface where all conditions (editing instructions, trajectories, obstacle maps) are serialized as text and encoded by an LLM.
Below are practical, real-world applications derived from these findings, grouped by deployment horizon. Each item notes relevant sectors and feasibility dependencies.
Immediate Applications
The following can be deployed now with modest integration and fine-tuning effort, leveraging UMO’s task performance (temporal completion, editing, geometric constraints, multi-identity reactions) and efficiency.
- Media, VFX, and Game Development: Text-to-motion and in-context editing copilot
- Sectors: Software, Creative industries (film/VFX/animation), Gaming
- Use cases:
- Prompt-based motion prototyping from storyboards or design notes.
- Timeline-aware editing using [preserve]/[edit]/[generate] per-frame tags to refine takes (e.g., “speed up this segment,” “add a lean,” “insert a turn between keyframes”).
- Keyframe in-betweening and gap filling for noisy or partial mocap streams.
- Style prompts (e.g., “more dramatic,” “subtle gait”) for rapid restyling.
- Potential tools/products/workflows:
- UMO plugins for Blender, Maya, Unity, Unreal with a timeline UI to assign per-frame tokens and prompt templates.
- “Mocap Repair” service to patch broken sequences (prediction/backcasting/in-betweening).
- Assumptions/dependencies:
- Rig/retargeting pipeline to map the model’s skeleton to production rigs.
- Access to a pretrained LFM (HY-Motion Lite) and GPU inference.
- Clear prompt templates and LLM encoder availability (e.g., Qwen3-8B).
- XR/Metaverse Avatars: Interactive avatar control and scene-aware pathing
- Sectors: Software, XR/AR/VR, Social platforms
- Use cases:
- Text-guided avatar motion generation and reactive behaviors for NPCs or social avatars.
- Obstacle-aware movement using text-serialized geometry (start/goal, obstacle radii).
- Missing-frame infill for tracked avatars in telepresence and VR capture.
- Potential tools/products/workflows:
- “Trajectory Prompt Console” for designers to author paths and obstacles via DSL-like text.
- On-platform motion-edit panels for live scene blocking.
- Assumptions/dependencies:
- Real-time constraints require further optimization; current 50-step ODE solver fits interactive authoring, not tight real-time loops.
- Scene obstacle serialization/export to prompt templates.
- Synthetic Data Generation for AI/ML
- Sectors: Software, AI/ML
- Use cases:
- Scalable generation of labeled 3D human motion sequences for action recognition, pose estimation, and tracking model training.
- Generation of rare or long-tail interactions and constrained walking trajectories for robustness testing.
- Potential tools/products/workflows:
- “Synthetic Motion Data Factory” with batch generation APIs and templated prompt catalogs.
- Assumptions/dependencies:
- Dataset diversity and prompt coverage determine downstream generalization.
- Data licensing/ethics policies for generated content.
- Human–Robot Interaction (HRI) and Robotics Simulation: Human-like motion priors for scenario design
- Sectors: Robotics, Simulation, Research
- Use cases:
- Generate realistic human behaviors for robot simulation environments to test navigation, handover, and social spacing.
- Two-identity reaction sequences for co-located tasks (e.g., “Person A approaches, Person B reacts by stepping aside”).
- Potential tools/products/workflows:
- “Reaction Composer” to script multi-identity interactions via text prompts, enabling dataset creation for HRI.
- Assumptions/dependencies:
- Currently outputs human motion; mapping to robot kinematics requires separate retargeting/control stacks.
- Safety constraints and contact physics are not explicitly enforced.
- Architecture, Retail, and Workplace Design: Path planning and human-flow prototyping
- Sectors: Architecture/Engineering/Construction (AEC), Retail, Workplace design
- Use cases:
- Simulate and visualize occupant paths (start/goal/obstacles) to test wayfinding and safety margins.
- Populate early-stage 3D scenes with plausible human movement using text-serialized constraints.
- Potential tools/products/workflows:
- BIM/CAD integration that exports obstacle and path specs into UMO prompt templates for quick motion renderings.
- Assumptions/dependencies:
- Geometric constraints are serialized as language; accurate coordinate transfer from CAD/BIM tools is needed.
- Not a substitute for detailed pedestrian dynamics models in regulatory contexts.
- Sports, Fitness, and Coaching Content Creation
- Sectors: Sports tech, Education
- Use cases:
- Generate exemplar motions (e.g., “slow down stride by 20%,” “exaggerate knee lift”) for tutorials and drills.
- Edit and curate movement libraries with fine-grained text instructions.
- Potential tools/products/workflows:
- Coaching content pipelines with batch editing and prompt-driven variation.
- Assumptions/dependencies:
- Not clinically validated for performance optimization; used for content/education rather than diagnostics.
- Policy, Training, and Public Safety Simulations (non-regulatory)
- Sectors: Public sector, Safety training, Insurance
- Use cases:
- Create motion scenarios demonstrating evacuation paths and basic obstacle avoidance for training materials.
- Generate diverse human behavior clips for situational awareness training.
- Potential tools/products/workflows:
- Scenario authoring templates with trajectory and obstacle definitions in natural language.
- Assumptions/dependencies:
- Outputs are illustrative; regulatory-grade planning tools require validated pedestrian models and standards compliance.
Long-Term Applications
These opportunities require further research, scaling, or tooling (e.g., real-time constraints, part-level control, multi-agent complexity, clinical validation).
- Real-Time On-Device Motion Generation for XR and Gaming
- Sectors: Software, XR/AR/VR, Gaming
- Use cases:
- Live avatar control with sub-10 ms latency for consumer devices.
- Needed advances:
- Distillation of ODE sampling to 1–2 steps, efficient backbones, and model compression/quantization.
- On-device LLM/lightweight encoders or pre-parsed constraint tokens.
- Audio-Conditioned Motion (Music/Speech)
- Sectors: Media, Education, Virtual events
- Use cases:
- Music-driven dance generation; speech gesture synthesis for virtual presenters.
- Needed advances:
- Multimodal conditioning (audio-language encoders), dataset integration for alignment to musical/linguistic features.
- Assumptions:
- Current UMO focuses on language; audio support adds modality-specific training.
- Part-Level and Contact-Aware Editing
- Sectors: Media, Robotics, Biomechanics
- Use cases:
- Limb-specific edits (“raise left arm only”), ground and object contact constraints, hand-object interactions.
- Needed advances:
- Extend [preserve]/[generate]/[edit] tokens to body-part granularity; integrate contact/collision objectives or physics priors.
- Robotics Deployment: Human-Inspired Planning and Imitation
- Sectors: Robotics (humanoids, cobots)
- Use cases:
- Use human-like motion priors to shape robot motion planners or imitation learning policies.
- Generate human behavior scenarios for robot validation under social constraints.
- Needed advances:
- Retargeting to robot kinematics, dynamics feasibility checking, safety validation and certification.
- Assumptions:
- Bridging from human to robot embodiment and control remains non-trivial.
- Autonomous Vehicle and Smart City Simulation: Pedestrian Scenario Generation
- Sectors: Mobility, Simulation
- Use cases:
- Diverse pedestrian trajectories and reaction behaviors for AV perception/planning testing.
- Needed advances:
- Multi-agent extensions beyond two identities; calibration against real-world pedestrian datasets; integration with traffic simulators.
- Clinical and Rehabilitation Applications
- Sectors: Healthcare
- Use cases:
- “What-if” motion edits for rehab planning, patient-specific motion synthesis, gap-filling in clinical mocap.
- Needed advances:
- Clinical validation, biomechanical plausibility guarantees, integration with patient-specific models and sensors.
- Assumptions:
- Regulatory compliance (HIPAA/GDPR), safety, and interpretability standards.
- Large-Scale Crowd Simulation with Social Norms
- Sectors: AEC, Public safety, Events
- Use cases:
- Procedural generation of crowds adhering to social spacing, group behaviors, and obstacle-rich navigation.
- Needed advances:
- Scaling to many identities with coordinated reactions; social force or learned social norm constraints; performance optimizations.
- Procedural Cinematography and Interactive Storytelling
- Sectors: Media, Gaming, Education
- Use cases:
- Dynamic scene blocking and camera planning co-designed with character motions, interactive narratives reacting to user input.
- Needed advances:
- Joint reasoning over cameras, staging, and motion; higher-level scene graphs and LLM agents orchestrating multi-asset timelines.
- Digital Twins and Human Factors Engineering
- Sectors: Manufacturing, Logistics, Workplace safety
- Use cases:
- Simulate task workflows, assess ergonomic risks, explore design alternatives with text-defined constraints and motion edits.
- Needed advances:
- Validation against ergonomic metrics (e.g., RULA/REBA), tighter coupling with physics and equipment interaction models.
- Governance and Standards for Text-Serialized Constraints
- Sectors: Policy, Standards bodies, DevOps
- Use cases:
- Establish a common DSL for geometric and task constraints to enable interoperable motion generation across tools/platforms.
- Needed advances:
- Community-driven schemas, validation suites, and safety checkers; provenance and audit mechanisms for generated motions.
Cross-Cutting Dependencies and Assumptions
- Foundation Model Availability and Licensing
- HY-Motion (or equivalent DiT-based T2M LFM) and an LLM encoder (e.g., Qwen3-8B) must be accessible under appropriate licenses.
- Prompt Engineering and Template Quality
- Success hinges on well-designed prompt templates for editing, trajectories, and obstacles; domain-specific lexicons improve reliability.
- Compute and Latency Constraints
- Current 50-step ODE solver supports interactive authoring but not strict real-time deployment; distillation/acceleration required for live applications.
- Skeleton and Retargeting
- Production pipelines require consistent skeleton mappings; high-quality retargeting reduces artifacts.
- Physical Plausibility and Safety
- UMO does not enforce physics or safety constraints; downstream checks (contact, collision, joint limits) are advisable for safety-critical use.
- Data and Domain Adaptation
- For niche domains (clinical, sports), additional fine-tuning and evaluation with domain-relevant metrics are necessary.
These applications leverage UMO’s core strengths: unified per-frame intent control via [preserve]/[generate]/[edit]; a single LLM-driven conditioning interface (including text-serialized geometry); and an efficient temporal fusion scheme that taps motion priors without architectural changes — enabling broad, practical adoption in content pipelines today and opening paths to real-time, multi-agent, and safety-critical systems tomorrow.
Glossary
- [edit] token: A learnable frame-level embedding indicating that a frame should be modified based on the source motion. "We introduce three learnable frame-level meta-operation embeddings, (), (), and ()"
- [generate] token: A learnable frame-level embedding indicating that a frame should be synthesized from scratch without reference motion. "We introduce three learnable frame-level meta-operation embeddings, (), (), and ()"
- [preserve] token: A learnable frame-level embedding indicating that a frame should be retained unchanged from the source motion. "We introduce three learnable frame-level meta-operation embeddings, (), (), and ()"
- [P]-MPJPE: A metric measuring joint position error only on frames designated to be preserved, evaluating how faithfully conditioning frames are respected. "and -MPJPE (cm) restricted to frames assigned tokens,"
- 6D continuous rotation: A joint rotation representation using six parameters to avoid singularities and ensure continuity. "root orientation in 6D continuous rotation"
- AdaLN: Adaptive Layer Normalization; a conditioning mechanism that injects global signals via layer normalization parameters. "AdaLN compresses $E_{\text{ctx}(\tilde{\mathbf{s})$ into a global vector via attention pooling and injects it through adaptive layer normalization"
- Asymmetric attention mask: An attention masking scheme that restricts information flow (e.g., making certain tokens read-only) to enforce conditioning behavior. "with an asymmetric attention mask that makes the in-context motion a read-only conditioning signal."
- Attention pooling: Aggregating token features into a single global vector using attention weights. "AdaLN compresses $E_{\text{ctx}(\tilde{\mathbf{s})$ into a global vector via attention pooling"
- Classifier-free guidance: A sampling technique that steers generative models by mixing conditional and unconditional predictions without an explicit classifier. "with a classifier-free guidance scale of $2.0$."
- CLIP encoder: A pretrained vision-language encoder used to provide semantic text features for conditioning. "and a CLIP encoder~\cite{radford2021learning}."
- ControlNet: A conditioning architecture that adds a parallel, trainable branch to a frozen backbone with zero-initialized residuals for controlled generation. "ControlNet~\cite{zhang2023adding} freezes the backbone and clones its double-stream blocks into a parallel trainable branch, injecting in-context motion through zero-initialized residual connections."
- DiT: Diffusion Transformer; a transformer-based diffusion architecture serving as the generative backbone. "injects this task-aware conditioning into the DiT backbone"
- Dual-identity reaction generation: Generating motion for two interacting entities where one reacts to the other. "The second is dual-identity reaction generation, a fundamentally different task topology"
- Euler ODE solver: A numerical method for integrating ordinary differential equations during generative flow sampling. "with $50$-step Euler ODE solver."
- Flow Matching: A generative training objective that learns a velocity field to transport noise to data along a continuous path. "Flow Matching."
- Fréchet Inception Distance (FID): A distributional metric comparing generated and real data using features of an Inception network. "achieving a state-of-the-art FID that surpasses even dedicated text-to-motion models."
- Generative priors: Learned statistical regularities that guide a generative model toward plausible outputs. "learning strong generative priors from massive 3D human motion datasets"
- Geometric constraints: Structured spatial specifications (e.g., trajectories, obstacles) that the generated motion must satisfy. "text-serialized geometric constraints"
- HY-Motion: A large-scale, DiT-based text-to-motion foundation model used as the pretrained backbone. "Specifically, we adopt HY-Motion~\cite{wen2025hy} as our motion LFM backbone, a large-scale DiT-based T2M model"
- In-betweening: Synthesizing motion frames between given start and end segments to produce smooth transitions. "prediction, backcasting, in-betweening, and keyframe control"
- In-context motion generation: Conditioning motion synthesis on existing motion sequences and other signals to produce context-aware outputs. "in-context motion generation downstream tasks"
- Instruction-based motion editing: Modifying an existing motion sequence according to textual editing instructions. "MotionFix~\cite{athanasiou2024motionfix} for instruction-based motion editing"
- Large-scale foundation models (LFMs): High-capacity models pretrained on massive datasets to learn general-purpose capabilities. "Large-scale foundation models (LFMs) have recently made impressive progress in text-to-motion generation"
- Mean Per-Joint Position Error (MPJPE): The average Euclidean distance between predicted and ground-truth joint positions, measuring accuracy in centimeters. "Mean Per-Joint Position Error (MPJPE, cm)"
- MMDiT: Multimodal Diffusion Transformer; a DiT variant designed to accept multiple modalities (e.g., text and motion). "It employs a multimodal DiT (MMDiT)~\cite{esser2024scaling} architecture"
- Multimodal Distance (MM-Dist): A metric assessing semantic alignment between text and motion in a shared embedding space. "Multimodal Distance (MM-Dist), measuring text-motion semantic alignment."
- Parameterized Trajectory: A structured text template encoding geometric paths (e.g., line, arc) via parameters like points and curvature. "The Parameterized Trajectory template defines a hierarchy of parameterized curves"
- Qwen3-8B: A specific LLM used to encode textual prompts for conditioning the motion model. "text conditioning via an LLM encoder (Qwen3-8B~\cite{yang2025qwen3})"
- R-Precision (R@1/2/3): A retrieval-based metric evaluating how well generated motions match their textual descriptions at various ranks. "R-Precision (R@1/2/3) and Multimodal Distance (MM-Dist), measuring text-motion semantic alignment."
- Reaction generation: Producing a motion that responds to or interacts with another entity’s motion. "multi-identity reaction generation"
- Rectified flow: A specific flow-matching formulation that simplifies training by defining a straight interpolation path and constant target velocity. "We adopt the rectified flow formulation"
- Sequential Concatenation: A conditioning architecture that concatenates context tokens with input tokens along the temporal dimension for attention-based fusion. "Sequential Concatenation concatenates $E_{\text{ctx}(\tilde{\mathbf{s})$ with $E_{\text{in}(\mathbf{x}_t)$ along the sequence dimension"
- Spatial Constraint: A structured text template specifying start/goal positions and obstacles to guide motion in a scene. "The Spatial Constraint template composes a natural-language sentence specifying the start and goal positions together with a list of obstacles"
- Temporal completion: Filling in missing segments of a motion sequence to complete it, often under constraints. "including motion editing and temporal completion"
- Temporal fusion: An input-level feature fusion method that adds context features to the noisy input embeddings before DiT blocks. "Temporal Fusion adds $E_{\text{ctx}(\tilde{\mathbf{s})$ element-wise to $E_{\text{in}(\mathbf{x}_t)$ before the DiT blocks"
- Temporal inpainting: Generating missing motion segments within a sequence (e.g., prediction, backcasting, in-betweening, keyframe infilling). "including temporal inpainting, text-guided motion editing, text-serialized geometric constraints, and multi-identity reaction generation."
- Text-to-motion (T2M): Generating 3D human motion sequences from natural language descriptions. "Early text-to-motion (T2M) models explored a variety of generative paradigms"
- Training-free inversion: A method to adapt pretrained generative models to new tasks by inverting conditioning without additional training. "the classic training-free inversion strategies"
- Zero-initialized residual connections: Residual pathways initialized at zero so added branches start as no-ops and gradually learn to modulate outputs. "injecting in-context motion through zero-initialized residual connections."
Collections
Sign up for free to add this paper to one or more collections.

