Why AI systems don't learn and what to do about it: Lessons on autonomous learning from cognitive science
Abstract: We critically examine the limitations of current AI models in achieving autonomous learning and propose a learning architecture inspired by human and animal cognition. The proposed framework integrates learning from observation (System A) and learning from active behavior (System B) while flexibly switching between these learning modes as a function of internally generated meta-control signals (System M). We discuss how this could be built by taking inspiration on how organisms adapt to real-world, dynamic environments across evolutionary and developmental timescales.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
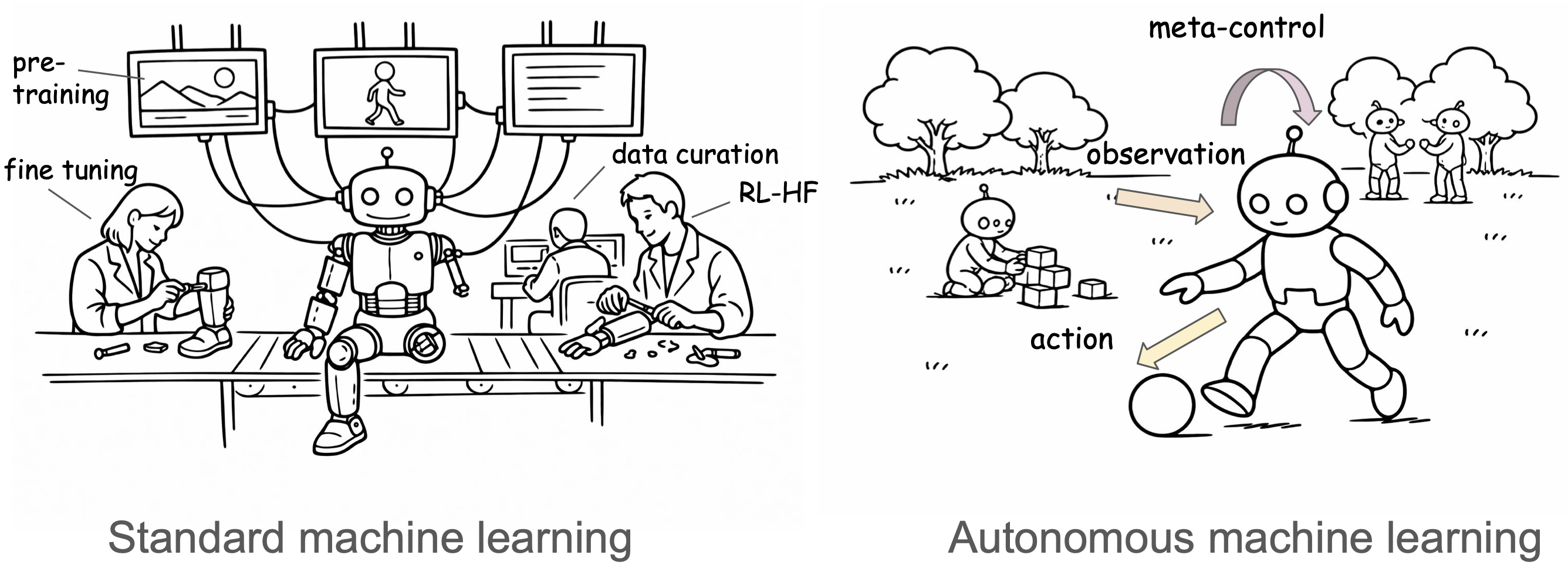
This paper asks a simple question: why don’t today’s AI systems keep learning on their own the way humans (and animals) do? The authors argue that most modern AI is great at training in the lab but learns almost nothing after it’s deployed. They propose a new, brain‑inspired blueprint for “autonomous learning,” so AI can keep improving from real‑world experience—much like a child exploring, watching others, and asking for guidance.
What questions is the paper trying to answer?
- Why do current AI models (like LLMs) hit limits when we just make them bigger and feed them more internet data?
- How do humans combine different ways of learning—by watching, by doing, by talking/listening, and by imagining—and can AI do the same?
- What kind of “manager” or “coach” inside the system could decide when to watch, when to act, and when to practice?
- How can we build such systems in a practical way, so they start with good instincts and then learn more through life?
How do the authors approach the problem?
The paper is a roadmap (not a single experiment). It reviews what works and what doesn’t, borrows ideas from cognitive science, and proposes a three‑part learning architecture:
System A: Learning by observation
- Think of System A as learning by watching, listening, and predicting—like “book learning.”
- In AI, this looks like self‑supervised learning: models learn patterns from raw data without needing labels (for example, predicting the next word in a sentence or the next frame in a video).
- Strengths: scales well, builds useful internal representations (like concepts).
- Limits: passive (doesn’t pick what to look at next), can confuse correlation with causation, and isn’t directly tied to taking action.
System B: Learning by action
- System B learns by doing—trial and error—like learning to ride a bike.
- In AI, this is reinforcement learning: the system tries actions, sees what works (rewards), and improves.
- Strengths: grounded in real outcomes, can discover new strategies.
- Limits: needs lots of practice, depends on good reward signals, and can struggle in complex, real‑world settings.
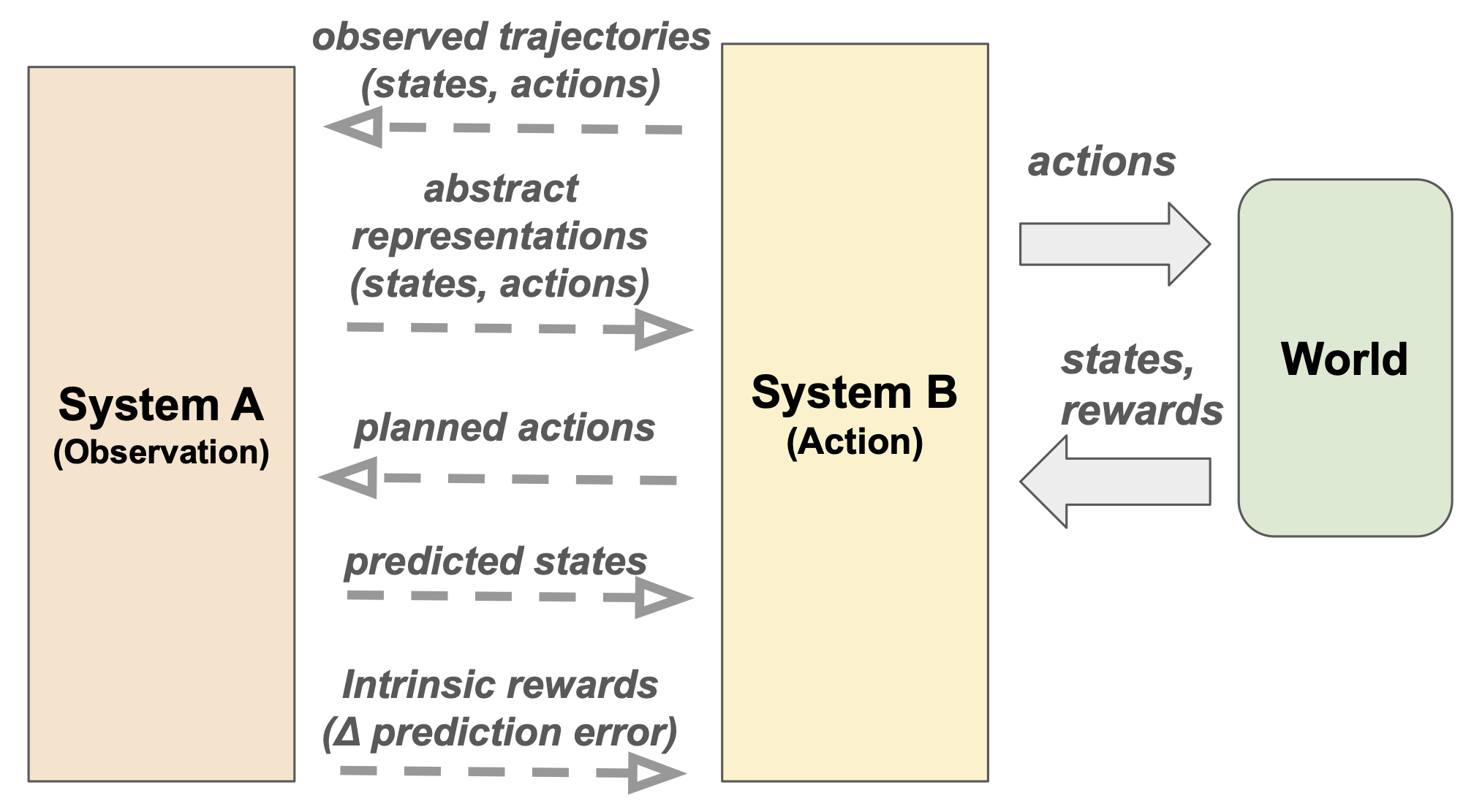
How A and B help each other
- A helps B: Watching helps shrink the search space. For example, learning a compact “world model” (an internal simulator) or “skills” makes trial-and-error faster and safer.
- B helps A: Acting collects better, more informative data (like moving your eyes to look at something surprising), which improves what A learns.
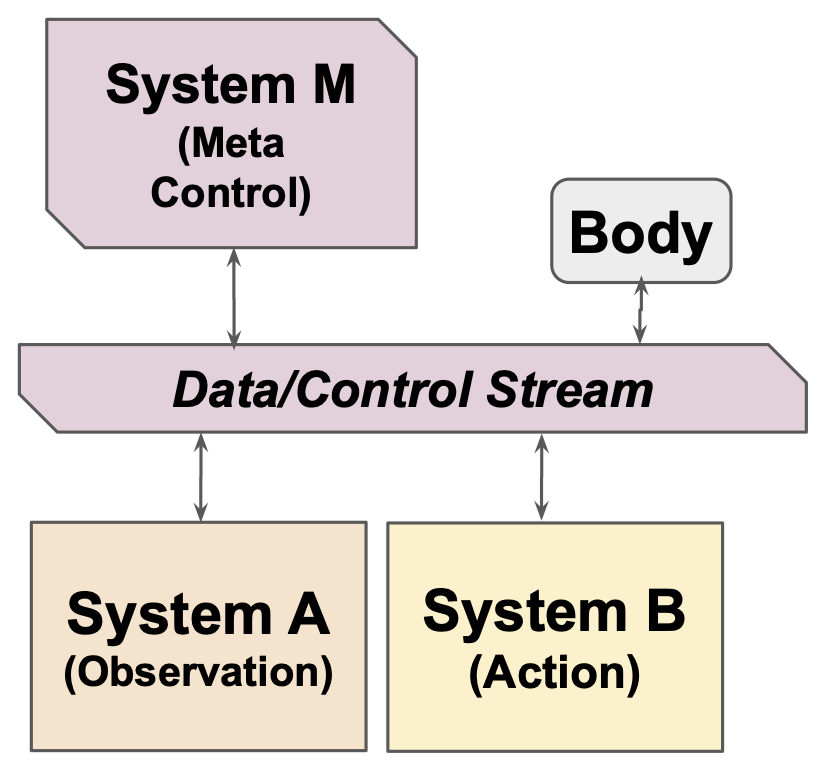
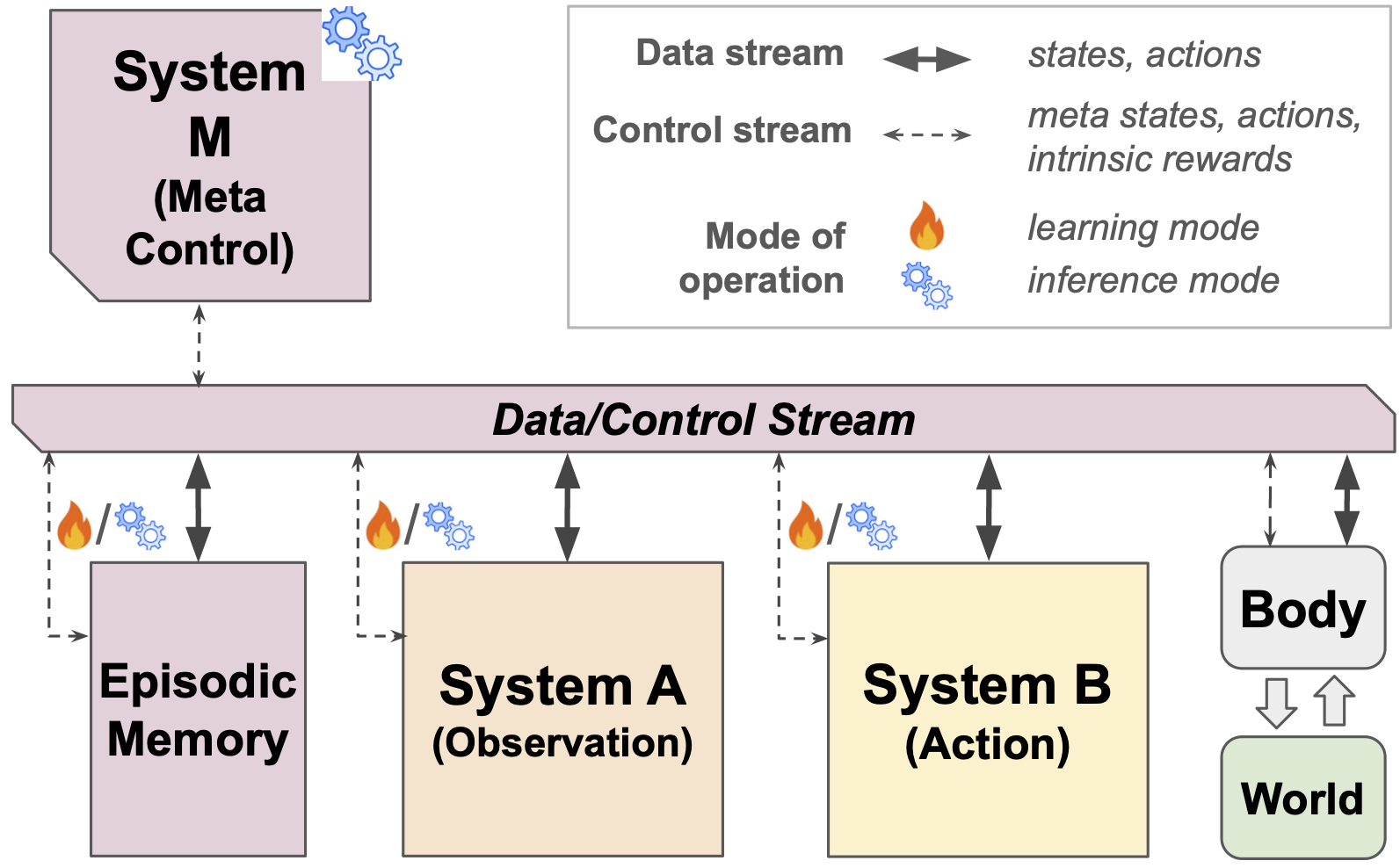
System M: The meta‑controller (the “coach”)
- System M is like a manager in the brain that decides when to watch, when to act, when to plan, when to rest and replay memories, and which data to keep.
- It monitors signals like surprise, uncertainty, or novelty (similar to curiosity), and then routes information between A, B, and memory.
- Today, humans do these “routing” jobs outside the model (data curation, training stages). The authors suggest building System M so the AI can do this itself.
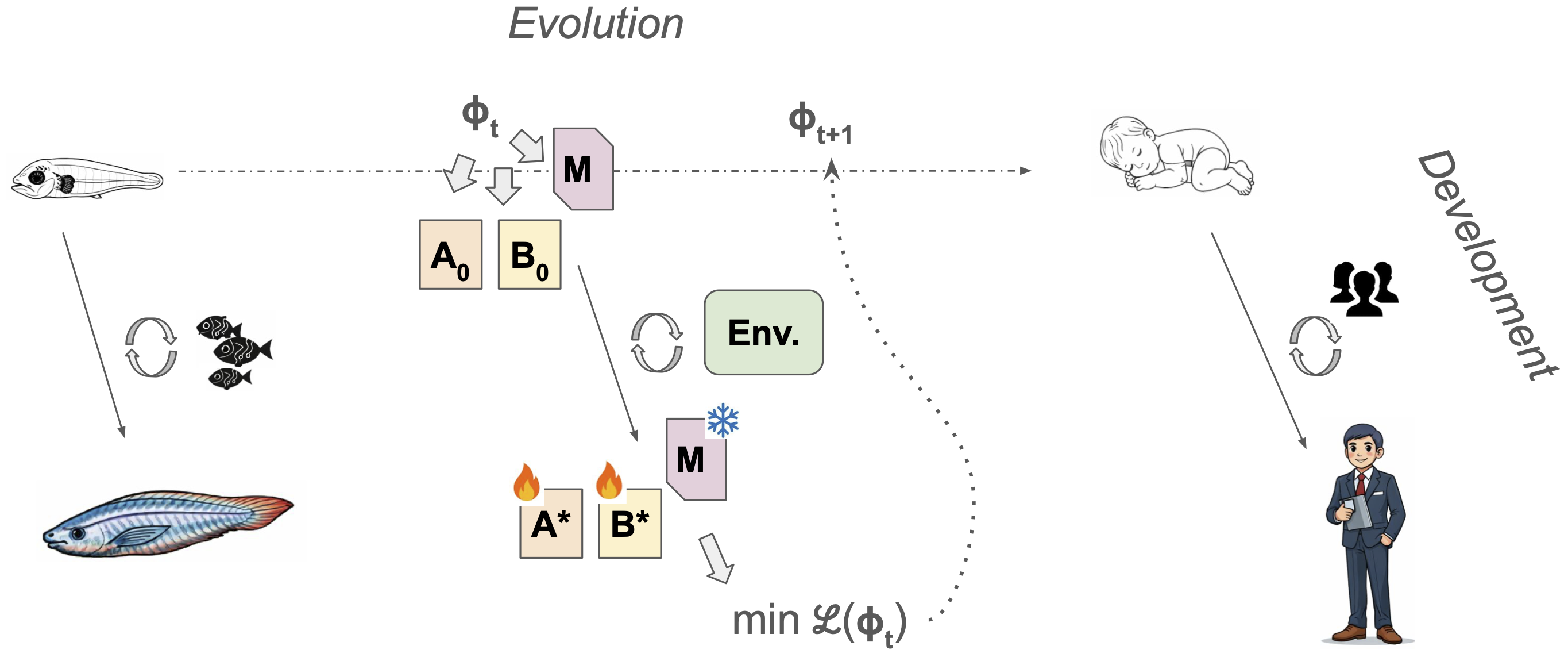
Evo/Devo bootstrapping: Starting smart, then learning more
- In nature, animals don’t start from scratch—they’re born with helpful wiring (evolution) and then learn a lot through experience (development).
- The authors suggest a similar two‑level approach for AI: use an outer loop (like evolution) to set good starting points and basic “rules,” then let the inner loop (development) learn and adapt during life.
What are the main findings or proposals, and why do they matter?
The paper identifies three big roadblocks—and offers directions to overcome them:
- Fragmented learning
- Problem: AI subfields (watching vs. doing) are siloed.
- Proposal: Integrate System A (observation) and System B (action) tightly so they share representations, world models, and goals.
- Outsourced learning
- Problem: After deployment, most models stop learning; humans must collect new data and hand‑tune recipes.
- Proposal: Build System M to automate data selection, training schedules, and switching between modes (observe, act, plan, replay).
- Building at scale
- Problem: It’s hard to design and train such complex systems from scratch.
- Proposal: Use an evolutionary‑developmental training framework to initialize good instincts (outer loop) and then refine through lifetime learning (inner loop).
Why this matters:
- Real life constantly changes and throws rare, unusual cases at AI. Just training on a fixed internet dataset isn’t enough.
- An AI that can keep learning (safely and efficiently) could adapt to new homes, cities, languages, tools, and tasks—without constant human babysitting.
- It could learn from watching humans (videos), from its own play, and from simple instructions—reducing the need for expensive, hand‑crafted training data.
What’s the potential impact?
If AI systems adopt this A‑B‑M blueprint:
- Robots and agents could learn new skills after deployment—like kids do—by observing, trying, asking, and imagining.
- They’d be more robust and safer, because they can notice when they’re unsure, explore carefully, and update themselves.
- AI and cognitive science would help each other: building such systems tests ideas about how human intelligence develops.
- We could move beyond “just make the model bigger” toward AI that’s truly adaptive, grounded in the real world, and able to improve over a lifetime.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated, actionable list of what the paper leaves missing, uncertain, or unexplored, to guide future research.
- Formal specification of System M: precise definition of meta-state space, meta-action set, objective function(s), decision horizon, and runtime constraints (latency, bandwidth) for the meta-controller.
- Learnability of System M: whether the meta-policy should be hardwired, learned, or meta-learned; what parts can/should adapt post-deployment; protocols for safely updating M without destabilizing A/B.
- Meta-signal design and calibration: which epistemic signals (uncertainty, prediction error, learning progress, novelty) are most informative; how to estimate and calibrate them in deep networks under distribution shift and partial observability.
- Data routing and gating policies: concrete algorithms to open/close data pathways between A, B, and memory; conflict resolution among competing objectives; scheduling and QoS guarantees under real-time constraints.
- Episodic memory architecture: what to store (raw vs latent), how to compress/index, retrieve, and prioritize replay; avoiding self-reinforcing feedback loops; privacy-aware storage and retention policies.
- Evaluation benchmarks for autonomy: standardized tasks that require switching among observation, action, and meta-control (A/B/M); metrics for autonomy (e.g., on-policy data efficiency, human-in-the-loop reduction, adaptation latency); ablation protocols isolating contributions of A, B, and M.
- Alignment of representations for control: methods to ensure System A’s learned abstractions (states, actions, skills) are control-useful for System B, including objective functions, contrastive couplings, and regularizers.
- Learning latent actions from third-person video: removal of teleoperation dependence; robust retargeting from exocentric human demos to egocentric agent embodiments with mismatched morphology; quantitative evaluation suites.
- World model fidelity for control: detecting, quantifying, and mitigating model bias/rollout error; arbitration rules for when to distrust the model and fall back to model-free control; support for stochastic dynamics and long horizons.
- Intrinsic motivation safety: intrinsic reward formulations that avoid “noisy TV” and distraction; principled schedules or gating between intrinsic and extrinsic rewards; theoretical exploration-efficiency guarantees.
- Arbitration between planning and reactive policies: compute-aware switching criteria; stability guarantees when toggling between model-based and model-free controllers; learned vs rule-based arbitration policies.
- Evo–Devo bilevel optimization details: explicit outer-loop “fitness” objectives, inner-loop learning curricula, regularization of initializations, and search algorithms; computational feasibility and sample complexity at scale; avoiding overfitting environments.
- Continual learning mechanisms: practical implementations of dynamic plasticity (critical periods), consolidation (sleep-like replay), and protection against catastrophic forgetting in integrated A/B systems.
- Communication and imagination modes: concrete architectures to enable instruction following, pedagogical learning, and offline imagination/simulation using a fixed System M; safeguards against compounding hallucinations during internal simulation.
- Active causal discovery: strategies for System B to design interventions that disambiguate causal structure; integration of interventional data into System A world models; causal benchmarks beyond toy settings.
- Multimodal uncertainty fusion: robust, learned weighting of heterogeneous sensors (vision, audition, proprioception) with calibrated cross-modal uncertainties; handling sensor dropout/failure.
- Cross-system credit assignment: learning signals that attribute gains to A, B, or M; differentiable or surrogate mechanisms to improve routing decisions based on downstream task performance.
- Tooling, observability, and interpretability of M: logging/telemetry standards for meta-decisions; inspectable routing policies; debugging tools when M induces performance regressions or unsafe behaviors.
- Safety and alignment in real-world exploration: formal safety shields and constraints for on-policy data collection; human override and recovery procedures; aligning intrinsic objectives with human values.
- Energy and compute budgeting: adaptive allocation of test-time compute and sensing under power/latency constraints in embodied agents; performance–energy trade-off policies.
- Robust social learning: criteria to select informative/trustworthy teachers; handling noisy, deceptive, or suboptimal demonstrations; uncertainty-aware weighting of social vs self-generated data.
- On-policy data acquisition at scale: infrastructure to collect large, diverse, and legally compliant sensorimotor datasets; balancing simulator pretraining with real-world data; sim2real transfer protocols.
- Simulator requirements: development of open-ended, physics- and social-rich simulators to pretrain A/B/M; methodologies to quantify transfer and detect sim-induced biases in meta-control.
- Failure-mode taxonomy and recovery: systematic catalog of ways A can misguide B (and vice versa) or M can route poorly; detection triggers and fallback strategies.
- Theoretical guarantees: stability, convergence, regret, and sample-complexity bounds for integrated A+B+M systems; impossibility or lower-bound results guiding design choices.
- Cross-disciplinary validation: testable predictions about infant/animal learning arising from the architecture; developmental robotics experiments to falsify or refine the proposed blueprint.
- Operational definition of “autonomy”: agreed metrics capturing degree of human-in-the-loop removal, on-policy adaptability, and lifetime self-improvement; standardized reporting.
- Hardware implications: architectural support for fast routing, prioritized replay, and uncertainty estimation (e.g., memory bandwidth, accelerators, neuromorphic options) required by System M at scale.
Practical Applications
Immediate Applications
The paper’s insights can be applied today by composing existing methods (self-supervised learning, model-based RL, active learning, prioritized replay, auto-curricula) into more integrated workflows, and by introducing lightweight “meta-control” heuristics to automate data routing and training recipes.
- Healthcare, Rehabilitation Robotics: Patient-specific adaptation of assistive/rehab robots — Combine pretrained vision encoders (e.g., R3M, DINO, V-JEPA-style video encoders) with model-based RL (Dreamer/PlaNet) and intrinsic motivation to personalize therapy trajectories while respecting safety constraints. Potential tools/products/workflows: Clinician-in-the-loop sandbox, on-device continual learning with prioritized experience replay (PER), uncertainty-triggered “safe mode” policies. Assumptions/dependencies: Certified safety monitor, clear reward shaping from clinical goals, privacy-preserving on-prem or edge training, regulatory approval.
- Manufacturing & Logistics Robotics: Sample-efficient skill learning and retargeted imitation from video — Pretrain System A on domain video to learn latent action/state spaces; fine-tune System B with offline RL and small amounts of teleoperation; use curiosity-based exploration to expand skill coverage. Potential tools/products/workflows: Latent-action imitation pipelines (e.g., VPT-like), auto-curricula in simulation, V-JEPA world models for planning, hybrid MoE policies for task routing. Assumptions/dependencies: High-fidelity simulators, calibrated uncertainty estimates, teleop fallback, robust sim-to-real transfer.
- Autonomous Vehicles & Mobile Robotics: Dynamic arbitration between reactive control and planning — Use test-time meta-control heuristics to switch between fast policy inference and “think” modes (e.g., MCTS/world-model rollouts) triggered by novelty or uncertainty signals. Potential tools/products/workflows: Risk-aware planning budget allocator, novelty detectors, memory of rare scenarios for targeted rehearsal (PER/ELS). Assumptions/dependencies: Real-time compute budgets, validated detectors for OOD and epistemic uncertainty, safety cases for selective planning.
- Software & Agentic LLMs: Adaptive “control plane” for test-time reasoning — Instrument LLM agents with epistemic telemetry (uncertainty proxies, self-evaluation) to route between fast responses and deliberate reasoning (e.g., chain-of-thought, tree-of-thoughts) and to request external tools or data. Potential tools/products/workflows: Quiet-STaR/Swift-style test-time compute manager, tool-use routers, episodic memory stores with prioritized replay for continual adaptation. Assumptions/dependencies: Reliable self-estimated confidence, guardrails to prevent reward hacking or hallucinated search, logging for auditability.
- Education/EdTech: Auto-curriculum tutors using learning progress as a meta-signal — Apply “Goldilocks” difficulty selection: select next items based on predicted learning gains, uncertainty, and prior performance; toggle between demonstration, practice, and reflection. Potential tools/products/workflows: Active learning-driven content schedulers, teacher dashboards showing meta-signals, offline replay to consolidate. Assumptions/dependencies: Validated proxies for learning progress, fairness across learners, privacy-compliant data handling.
- MLOps & Data Engineering: “Mini System M” to automate data curation and training recipes — Use active learning, hard-example mining, and uncertainty-based sampling to route data to SSL tasks, RL phases, or evaluation; schedule training modes (SSL pretrain, offline RL, fine-tune) based on telemetry. Potential tools/products/workflows: Control-plane orchestrator in pipelines (e.g., Airflow/Kubeflow plugins), PER-like storage for raw and latent streams, auto-curriculum generators. Assumptions/dependencies: Good telemetry instrumentation, stable interfaces across subsystems, change management and A/B evaluation.
- Finance & Operations Research: Exploration–exploitation meta-control for trading, bidding, and resource allocation — Use volatility/uncertainty meta-signals to switch between model-based planning and model-free policies; adjust intrinsic exploration budgets when regimes change. Potential tools/products/workflows: Mode-switching policy engines, uncertainty-gated backtesting and “shadow” deployment, episodic replay of shocks. Assumptions/dependencies: Robust regime-change detection, risk controls, compliance logging.
- Energy & Smart Grid Control: Hierarchical control with intrinsic rewards for discovering contingencies — Model-based planning for rare events, with meta-control increasing “imagination” budgets under high uncertainty or volatility; model-free reactive policies otherwise. Potential tools/products/workflows: Digital twins for UED/auto-curricula, prioritized replay for incident cases, operator-facing confidence dashboards. Assumptions/dependencies: High-fidelity grid simulators, strict safety interlocks, regulator buy-in.
- Human–Robot Interaction & Social Imitation: Reduce teleoperation via latent-action learning from video — Learn latent action/state spaces from human videos (System A); use goal imitation with small retargeting modules to bridge exocentric/egocentric differences; apply RL for final policy. Potential tools/products/workflows: Video-to-latent encoders, retargeting adapters, human preference feedback for refinement. Assumptions/dependencies: Diverse, consented video datasets; careful bias control; safety constraints.
- Personal Productivity & Daily Life: On-device adaptive assistants with safe, bounded continual learning — Meta-control to select which interactions are stored, what gets rehearsed, when to switch to deliberate planning or ask clarifying questions; notifications and content curated by user-modeled uncertainty and goals. Potential tools/products/workflows: Local episodic memory with PER; uncertainty-triggered “ask me” prompts; data minimization and federated updates. Assumptions/dependencies: Strong privacy, user consent and controls, on-device compute, clear opt-outs.
Long-Term Applications
These applications require further research, scaling, integration, or regulation—especially to realize a unified System M that autonomously orchestrates learning, safely explores open-ended environments, and generalizes across tasks and embodiments.
- General-Purpose Home and Service Robots: Fully autonomous, lifelong learning in the wild — Unified System A/B/M enabling robots to learn new tasks from passive observation, self-play, and social imitation without teleop; dynamic safety constraints and imagination budgets. Potential tools/products/workflows: Onboard control plane, causal video world models (V-JEPA-like), intrinsic-motivation engines, home-sandbox simulation for UED. Assumptions/dependencies: Reliable safety monitors, standardized in-home simulators, causal generalization, robust embodiment transfer, insurance/regulatory frameworks.
- Healthcare: Continually learning clinical decision support and adaptive devices — Agents that actively acquire information (order tests, ask questions) based on uncertainty; meta-control to arbitrate between guidelines (model-based) and heuristics (model-free) with human oversight. Potential tools/products/workflows: Certified control-plane orchestration with audit logs, causal world models for treatment effects, on-prem federated learning. Assumptions/dependencies: Strong causal validity, bias mitigation, clinical trials, regulatory approval (e.g., SaMD), privacy-by-design.
- Education: Open-ended AI tutors that learn to teach — System M arbitrates between demonstration, guided practice, Socratic questioning, and imagination (mental simulation) for learning transfer; agent learns pedagogical strategies across learners and subjects. Potential tools/products/workflows: Cross-modal student models with epistemic telemetry, imagination-mode drills, meta-curricula that adapt across semesters. Assumptions/dependencies: Robust, interpretable learner models; measurement of long-term outcomes; governance for fairness and transparency.
- Urban Autonomy (Mobility, Delivery, Infrastructure): City-scale agents with meta-control — Dynamic, uncertainty-aware control planes switching between reactive control and deliberative planning across fleets; coordinated exploration to reduce blind spots. Potential tools/products/workflows: Multi-agent imagination budgeting, shared episodic memories of rare events, city digital twins for UED/auto-curricula. Assumptions/dependencies: Data sharing standards, municipal regulation, safety cases for collective learning.
- Enterprise Software & AIOps: Self-improving, causally grounded agents — Agents that learn workflows by observing humans (System A), test hypotheses in safe sandboxes (model-based planning), then act with rollback plans; meta-control for change-risk gating. Potential tools/products/workflows: Control-plane plug-ins for CI/CD and incident response, causal log mining, organization-wide episodic memory. Assumptions/dependencies: Reliable counterfactual evaluation, strong RBAC and auditability, cultural adoption.
- Scientific Discovery & R&D: Autonomous labs with active experiment design — System M drives selection of experiments via uncertainty, learning progress, and desired causal identifiability; System A learns latent mechanisms, System B acts on instruments. Potential tools/products/workflows: Causal experiment planners, auto-curricula over hypothesis spaces, lab digital twins. Assumptions/dependencies: High-fidelity simulators/robots, reproducibility pipelines, oversight committees.
- Energy & Climate Systems: Adaptive, safe controllers for critical infrastructure — Agents that continually learn from disturbances while keeping exploration bounded; meta-control schedules offline consolidation (sleep-like replay) and online behavior. Potential tools/products/workflows: Fleet-wide control planes, causal disturbance models, safe exploration budgets and guards. Assumptions/dependencies: Regulatory compliance, verifiable safety envelopes, rigorous red-teaming.
- Finance & Macroeconomic Policy: Causally aware, meta-controlled strategy engines — Integrated world models (causal) learned from observation and policy/action data; imagination-mode stress testing; meta-control toggles between reactive and strategic regimes. Potential tools/products/workflows: Policy sandboxes with counterfactuals, long-horizon planning modules, governance dashboards with epistemic telemetry. Assumptions/dependencies: Robust causal inference, strict compliance, explainability requirements.
- Human–Robot Social Imitation: Retargeting across embodiments with minimal labels — Learn to map human exocentric video to robot egocentric actions at scale via shared latent world models; handle stylistic/goal-level imitation choices. Potential tools/products/workflows: Cross-embodiment retargeters, social learning curricula, multi-species (or multi-platform) latent action libraries. Assumptions/dependencies: Diverse multimodal datasets, ethical collection and consent, strong generalization.
- Consumer Assistants: Lifelong, on-device autonomous learning with imagination and communication modes — Assistants that rehearse plans offline (imagination), learn from user feedback, and proactively seek clarification; System M controls storage, rehearsal, and risk-aware action. Potential tools/products/workflows: Local control planes with episodic memory, privacy-preserving continual learning, user-configurable meta-policies. Assumptions/dependencies: On-device compute and energy, privacy guarantees, failure containment.
- Safety, Governance, and Standards: Regulating self-learning systems — Policy frameworks for meta-control telemetry logging, safe exploration budgets, memory sanitation, and audit trails; standards for introspective signals (uncertainty, novelty, learning progress). Potential tools/products/workflows: Compliance toolkits for autonomous learning, red-team protocols for exploration, certification of control planes. Assumptions/dependencies: Cross-industry consensus, measurement standards, enforceable logging and privacy norms.
- Academia (AI & Cognitive Science): Evo–Devo benchmarks and shared testbeds — Bilevel optimization to initialize Systems A/B and fixed meta-policies; developmental curricula evaluating switching between modes (observation, action, social learning, imagination). Potential tools/products/workflows: Open benchmarks for meta-control, standardized episodic memory formats, protocols for uncertainty/learning-gain telemetry. Assumptions/dependencies: Community datasets/simulators, agreement on metrics, compute for longitudinal experiments.
These applications hinge on key assumptions: access to safe simulators or sandboxes; accurate epistemic signals (uncertainty, prediction error, learning progress); robust causal world models; privacy-preserving data and consent; interpretable meta-control policies; and, for regulated sectors, clear safety cases and auditability.
Glossary
- Active Learning: A strategy where the model actively selects the most informative data points to label or learn from to improve efficiency. "the autonomous curation of data streams is explored through the lens of Active Learning"
- Active perception: The idea that perception and action are intertwined; agents move to gather better perceptual information. "Gibson's notion of active perception"
- Adaptive Control: Control methods that adjust their parameters online to handle changing system dynamics. "Adaptive Control"
- Auto-Curriculum algorithms: Methods that automatically adjust task difficulty or generate tasks at the edge of an agent’s capabilities. "Auto-Curriculum algorithms dynamically modulate the difficulty of the training environment generating tasks at the frontier of the agent's capabilities"
- bilevel optimization: An optimization framework with two nested problems (upper-level and lower-level), often used to tune meta-parameters. "an evolutionary inspired bilevel optimization approach"
- Control Plane: In analogy to networking, a centralized mechanism that makes routing/coordination decisions separate from data processing. "much like the Control Plane in Software-Defined Networking"
- Control Theory: A field focusing on deriving optimal control actions for systems with known dynamics. "as in control theory"
- critical periods: Developmental windows during which certain learning is most effective or only possible. "critical periods illustrate that specific learning components are highly plastic only at certain developmental stages"
- Cross-situational Learning: Learning word meanings by tracking co-occurrences of words and referents across different contexts. "Cross-situational Learning"
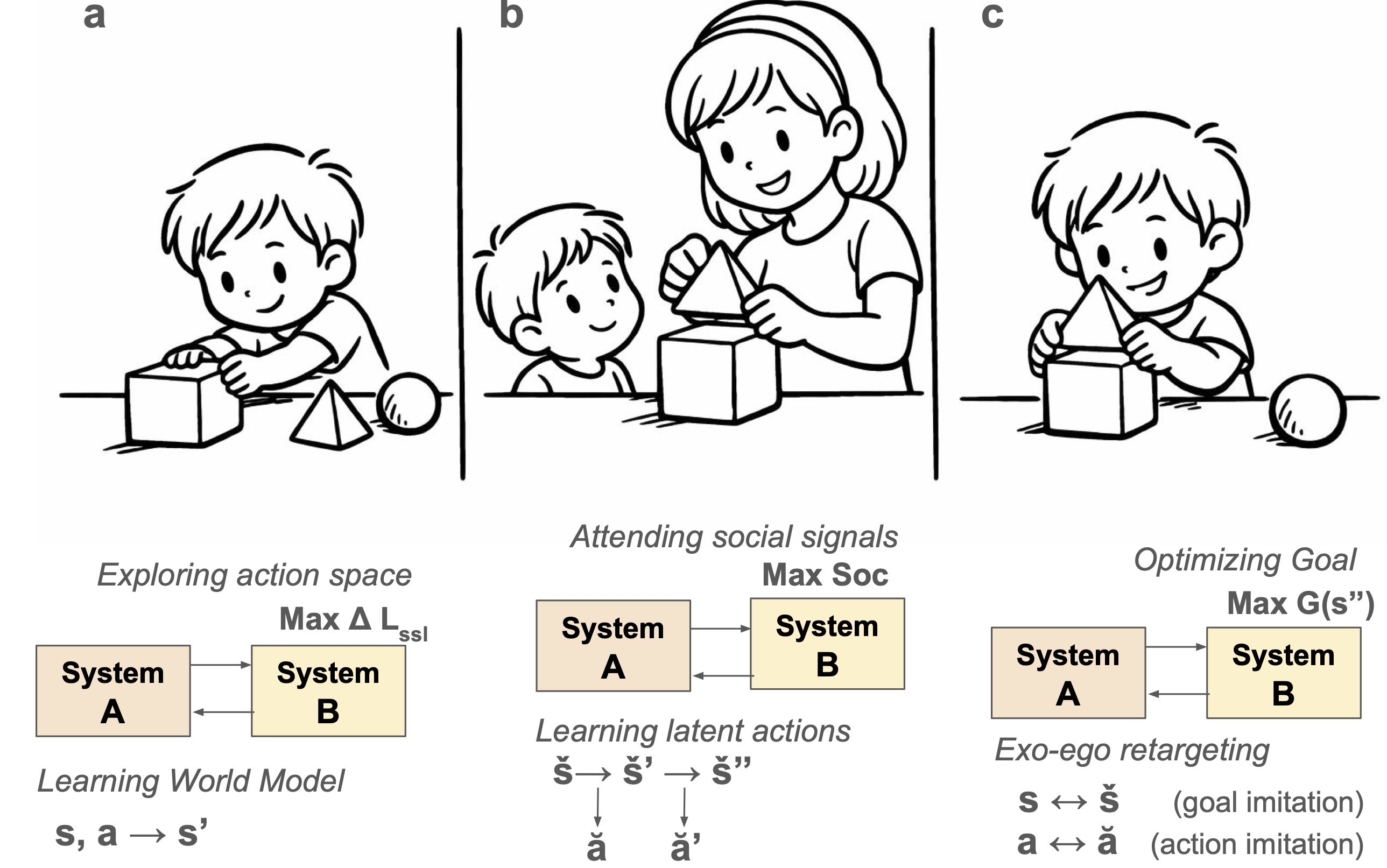
- curiosity-driven exploration: An intrinsic motivation strategy that drives agents to seek novel or informative experiences. "curiosity-driven exploration that mirrors biological exploratory play"
- Discount factor: The parameter that reduces the weight of future rewards in reinforcement learning. "Discount factor"
- domain mismatch: A discrepancy between training and deployment data distributions that degrades performance. "This phenomenon known as domain mismatch cannot be fixed by merely increasing the training set size"
- Elastic Weigh Consolidation (EWC): A continual learning method that penalizes changes to parameters important for prior tasks to reduce forgetting. "Elastic Weigh Consolidation mimick the biological critical periods discussed earlier"
- empowerment: An intrinsic reward concept measuring the agent’s potential influence over future states. "curiosity, novelty, or empowerment"
- energy based approach: A modeling framework where learning and inference minimize an energy function rather than predict explicit probabilities. "within an energy based approach"
- episodic memory: A memory system that stores specific events or trajectories for later replay or learning. "an episodic memory to store and replay raw or processed data"
- exploration/exploitation dilemma: The trade-off between choosing known rewarding actions and exploring to discover potentially better ones. "the exploration/exploitation dilemma"
- Evo/Devo: A perspective separating evolutionary timescale adaptations from developmental (lifetime) learning and organization. "Evo/Devo Scales for Organisms"
- Global Workspace Theory architectures: Cognitive architectures inspired by theories of consciousness that coordinate distributed modules via a shared workspace. "Global Workspace Theory architectures"
- heavy tailed: Refers to data distributions with a large probability of extreme or rare events. "(heavy tailed)"
- Hierarchical Reinforcement Learning (HRL): RL methods that learn or use behaviors at multiple temporal/abstraction scales (options/skills). "Hierarchical Reinforcement Learning (HRL)"
- imitation learning: Learning to perform tasks by observing and reproducing demonstrations from others. "imitation learning (also called social learning)"
- inductive biases: Built-in assumptions that guide learning, shaping what and how fast an agent can learn. "providing inductive biases that shape what can be learned"
- inference-time compute scaling: Allocating more computation at inference to improve reasoning or planning quality. "inference-time compute scaling"
- Intrinsic Motivation: Learning signals generated internally (e.g., novelty, surprise) to drive exploration without external rewards. "Intrinsic Motivation"
- Joint Embedding Predictive Architecture (V-JEPA): A predictive modeling approach that operates in latent (embedded) spaces, here specifically for video. "Video Joint Embedding Predictive Architecture (V-JEPA)"
- latent action spaces: Compact, learned representations of actions that can simplify policy learning or retargeting. "learn latent action spaces"
- Meta-control: Higher-level control that routes data, switches modes, and modulates learning across components. "System M (for Meta-control)"
- Mixtures of Experts: Architectures that route inputs to specialized sub-models (experts) to improve efficiency or robustness. "Mixtures of Experts were an early implementation of dynamic routing of subsystems"
- MLOps: Operational practices and tooling for managing ML data, training, deployment, and monitoring pipelines. "a pipeline generally referred to as MLOps"
- model-based RL: Reinforcement learning that uses a learned or known model of environment dynamics for planning. "turn System B into model-based RL"
- model-free RL: Reinforcement learning that directly learns policies or value functions from experience without an explicit dynamics model. "model-free RL"
- Monte Carlo Tree Search: A planning/search technique that builds a lookahead tree using stochastic sampling. "Monte Carlo Tree Search"
- non-stationarity: The property of data distributions changing over time. "(non-stationarity)"
- Perceptual Learning: Improvements in sensory discrimination or categorization through experience-driven changes in perception. "Perceptual Learning"
- Planning: Computing action sequences by reasoning over a world model rather than reacting purely from learned policies. "planning instead of blind trial-and-error"
- policy (π): A mapping from states to action distributions in reinforcement learning. "The transition dynamics of the agent is called a policy ()."
- Predictive World Models: Models that predict future states from past and current inputs, enabling planning and sample-efficient learning. "Predictive World Models."
- Prioritized Experience Replay (PER): Sampling stored experiences in RL with priority to more informative transitions (e.g., high TD error). "Prioritized Experience Replay (PER)"
- Reinforcement Learning (RL): Learning to make sequential decisions by maximizing cumulative reward through interaction. "reinforcement learning and planning"
- retargeting problem: The challenge of mapping observed actions from another body to the learner’s own embodiment for imitation. "this creates a 'retargeting problem'"
- Self Play: A training regime where an agent generates data by interacting with itself or its own policies. "Self Play."
- Self-Supervised Learning (SSL): Learning representations from raw data by solving proxy tasks without manual labels. "Self-Supervised Learning (SSL) models"
- species-specific signals: Built-in detectors for evolutionarily salient cues (e.g., faces, threats) that guide attention and learning. "species-specific signals"
- System A: The collection of mechanisms for learning from passive observation (e.g., predictive/statistical models). "We call the set of learning mechanisms that fall in this bucket: System A."
- System B: The collection of mechanisms for learning through action and feedback (e.g., RL, control). "We call the relevant set of mechanisms System B"
- System M: The meta-control system that orchestrates Systems A and B, routing data and switching learning modes. "We call the orchestrator System M (for Meta-control)"
- transition dynamics: The rules or model describing how states evolve given actions in an environment. "transition dynamics M(s_{t+1}|s_{t},a_{t})"
- Unsupervised Environment Design (UED): Methods that automatically generate or select environments/tasks to shape learning progress. "Unsupervised Environment Design (UED)"
- world model: An internal model of environment dynamics used for prediction, planning, or imagination. "world-model simulation"
Collections
Sign up for free to add this paper to one or more collections.