- The paper introduces a conditional one-step generative transport model using neural operators for efficient Bayesian inversion of PDEs.
- It leverages prior-aligned trace-class Gaussian references to ensure globally Lipschitz transport and robust uncertainty quantification.
- Experimental evaluations across multiple PDE problems show relative errors below 10% and dramatic speed-ups compared to traditional MCMC.
Preconditioned One-Step Generative Modeling for Bayesian Inverse Problems in Function Spaces
Problem Description and Motivation
Bayesian inverse problems governed by PDEs require rigorous uncertainty quantification for function-valued unknowns amid noisy and partial observations, leading to high- or infinite-dimensional posterior distributions. Conventional methods such as MCMC, while theoretically exact and dimension-robust through preconditioning (e.g., pCN), are computationally infeasible for large-scale function-space inference due to their reliance on repeated expensive PDE solvers and correlated chains.
Recent advances in amortized generative modeling—diffusion models, score-based approaches, flow-matching, and especially Mean Flows—offer attractive alternatives by learning transports from reference measures to posterior distributions. However, most multi-step generative models incur inference costs proportional to the number of integration steps and fail to address geometric compatibility with the infinite-dimensional function spaces inherent to PDE inverse problems. This paper introduces a fully conditional, one-step generative transport model leveraging neural operators, designed to overcome these limitations and address measure-theoretic compatibility for robust and accelerated posterior sampling in function spaces.
Methodological Framework
The proposed approach formulates Bayesian inversion via conditional neural operators trained to map a reference Gaussian noise ξ∼ρ (with ρ either white or prior-aligned) and observations yobs to approximate posterior samples. The backbone is a Mean Flows methodology, where the transport is learned from prior simulations and noisy partial observations, without distillation from MCMC or teacher models. The model is fully amortized and conditional: given new observations, posterior samples are generated with a single forward evaluation of the trained operator, with generalization across all observation sets.
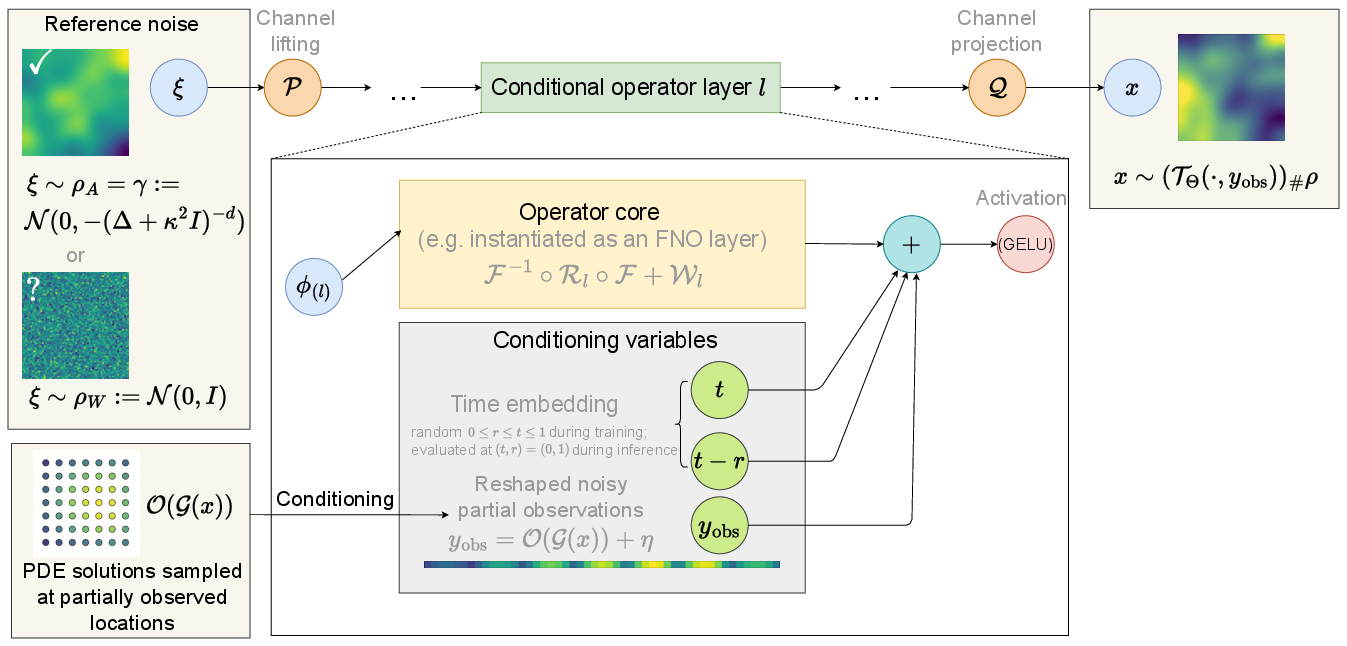
Figure 1: Conditional neural operator backbone for one-step posterior sampling, mapping a latent draw ξ through lifted operator layers to generate a posterior sample.
A central technical contribution is the justification and theoretical analysis of reference measures. In the function-space regime, white-noise latents become incompatible with the geometry of infinite-dimensional Bayesian posteriors, inducing instability and mutual singularity on the distribution space. The paper establishes that utilizing prior-aligned trace-class Gaussian references yields globally Lipschitz one-step transports, ensuring well-posedness and robust inference across resolution and discretization scales. The operator backbone adopts FNO-style architecture, with conditioning injected via embeddings of observation vectors and temporal variables.
Theoretical Guarantees
The paper rigorously demonstrates measure-theoretic incompatibility between white-noise and trace-class reference distributions as the discretization is refined: white-noise measures do not take values on the Hilbert space of the function-valued unknowns, and posterior distributions are mutually singular with respect to the white-noise law. Using prior-matched trace-class references aligns the geometry, ensures Gaussian-tail regularity, and enables dimension-free Lipschitz bounds on the learned one-step transport—critical for scalability and resolution-robust inference.
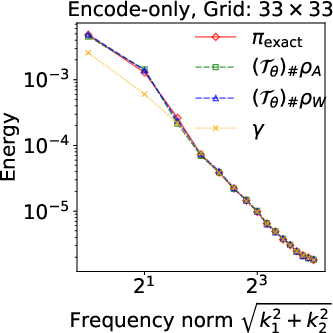
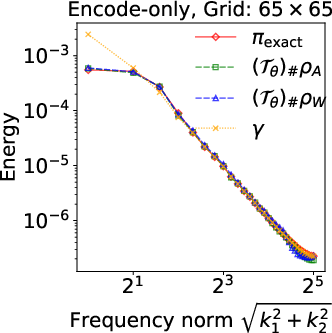
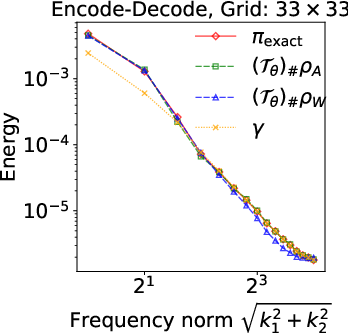
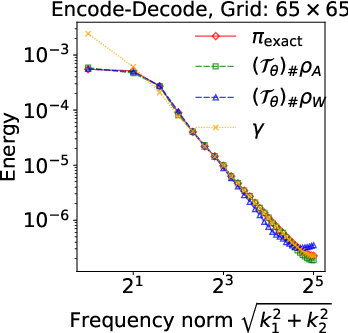
Figure 2: Energy spectra E(k) for the identity inverse problem, showing superiority of prior-aligned references in preserving spectral decay to match the closed-form posterior.
Numerical experiments validate these theoretical claims: at finer resolutions, encode-only models with white-noise references exhibit pronounced high-frequency artifacts and instability, while prior-aligned trace-class references consistently track spectral decay and posterior summaries—even when L2 errors may appear similar at low discretization.
Experimental Evaluation
The framework is evaluated on four canonical PDE-based inverse problems: Darcy flow, Advection, Allen-Cahn Reaction-Diffusion, and Navier-Stokes vorticity equations. Posterior quality is assessed via L2 errors in mean and pointwise standard deviation compared to trustworthy MCMC reference statistics. The one-step sampling model achieves relative errors below 10% in both mean and uncertainty across all tested PDEs, with a sampling time per posterior sample on the order of 10−3 seconds (GPU inference), drastically surpassing MCMC and multistep diffusion models.
Ablations show the approach is backbone-agnostic, with PODNO and FNO architectures yielding comparable accuracy and substantial computational benefits. UNet backbones, in contrast, demonstrate grid-dependent limitations and inferior uncertainty estimates due to restricted function-space expressivity. The multi-step diffusion baseline consistently underperforms in both speed and posterior accuracy relative to one-step Mean Flows.
Practical and Theoretical Implications
Practically, the proposed fully conditional, one-step transport enables real-time posterior sampling for PDE inverse problems without retraining, making uncertainty quantification feasible in settings previously precluded by computational cost. Theoretically, the work advances the understanding of measure compatibility and transport regularity in infinite-dimensional Bayesian inference. It emphasizes the criticality of reference measure selection for function-space generative modeling, with prior-aligned trace-class references being the only robust choice.
The limitations highlighted include reliance on the expressivity and conditioning of operator-learning architectures, difficulties in diagnosing velocity approximation bias, and the necessity of offline prior data generation. Addressing these may entail further architectural innovations and principled error diagnostics.
Conclusion
This paper introduces a resolution-robust, prior-aligned, one-step generative framework for Bayesian inverse problems in function spaces, advancing both computational tractability and measure-theoretic well-posedness. The approach is theoretically justified, empirically validated, and compatible with a range of operator-learning backbones. The findings clarify the role of reference measures in function-space generative modeling, offering a path forward for accelerated uncertainty quantification in scientific computing and PDE-constrained inverse tasks (2603.14798).