Delightful Policy Gradient
Abstract: Standard policy gradients weight each sampled action by advantage alone, regardless of how likely that action was under the current policy. This creates two pathologies: within a single decision context (e.g. one image or prompt), a rare negative-advantage action can disproportionately distort the update direction; across many such contexts in a batch, the expected gradient over-allocates budget to contexts the policy already handles well. We introduce the \textit{Delightful Policy Gradient} (DG), which gates each term with a sigmoid of \emph{delight}, the product of advantage and action surprisal (negative log-probability). For $K$-armed bandits, DG provably improves directional accuracy in a single context and, across multiple contexts, shifts the expected gradient strictly closer to the supervised cross-entropy oracle. This second effect is not variance reduction: it persists even with infinite samples. Empirically, DG outperforms REINFORCE, PPO, and advantage-weighted baselines across MNIST, transformer sequence modeling, and continuous control, with larger gains on harder tasks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new, simple way to train decision‑making AI systems called Delightful Policy Gradient (DG). It helps learning focus on “rare wins” and waste less effort on “rare mistakes.” The method is a tiny change to how many reinforcement learning (RL) systems already learn, but it makes training more stable and often faster.
What questions did the authors ask?
- Are standard policy‑gradient updates pointing in the best direction for learning, or are they biased in a way that slows progress?
- Can we make updates smarter by noticing how surprising an action was, not just whether it was good or bad?
- Will a tiny, drop‑in change improve learning both in theory and in real tasks like image classification, sequence modeling, and robot control?
The core idea in plain words
Imagine teaching a student. If they try something unusual and it works (a rare win), you want to encourage it a lot. If they try something unusual and it fails (a rare mistake), you don’t need to punish it much—they already don’t do it often. And if they do something they already tend to do, you don’t need to push very hard either way.
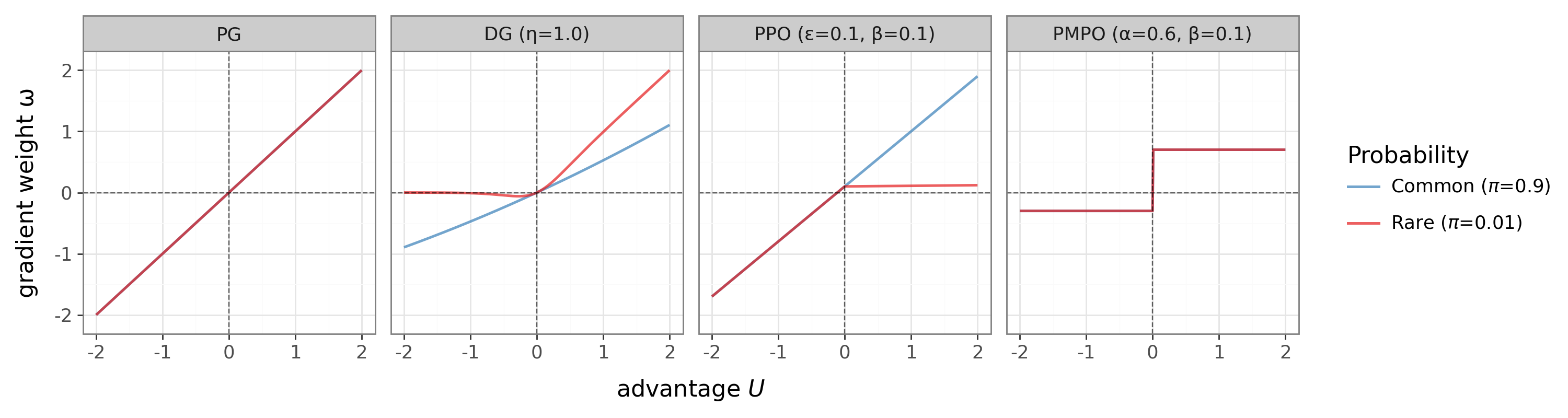
Standard policy gradient methods mostly care about whether the result was better or worse than usual (called “advantage”). They don’t care how likely the action was under the current policy. DG adds this missing piece: surprise.
- Advantage (U): How much better or worse the outcome was than expected.
- Surprisal (ℓ): How surprising the chosen action was (high if the policy thought it was very unlikely).
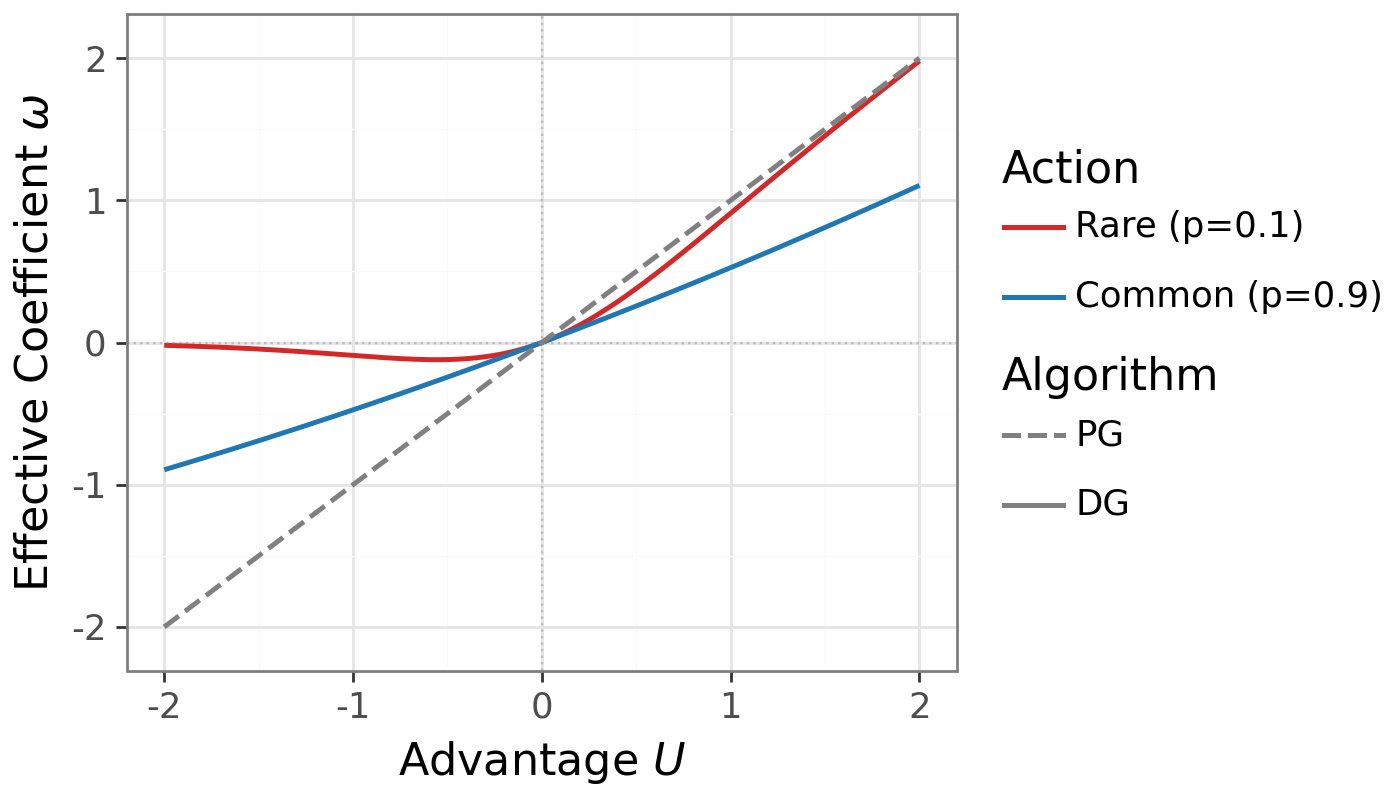
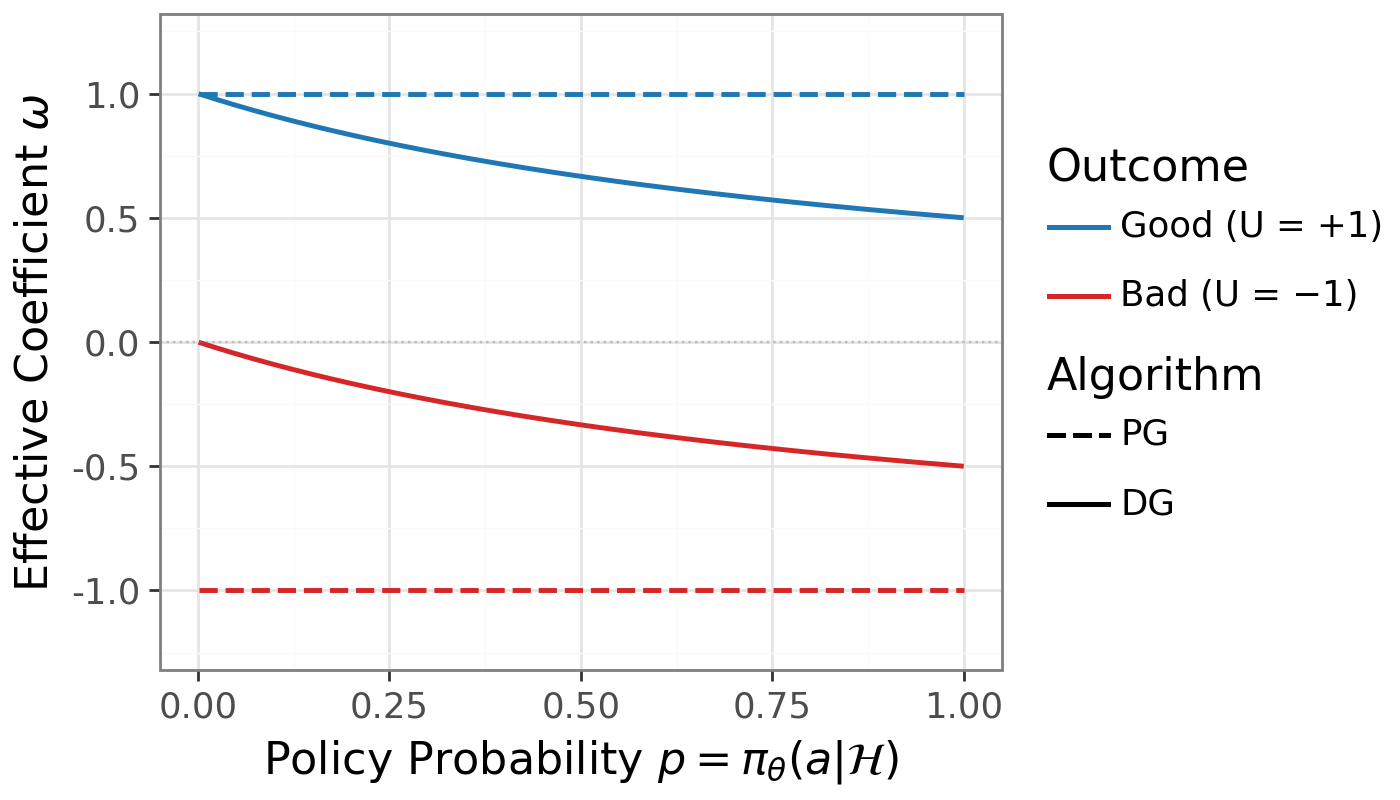
- Delight (χ): Multiply them: χ = U × ℓ. Big positive χ = rare win; big negative χ = rare mistake.
DG uses a smooth switch (a sigmoid) that turns the learning “up” for rare wins and “down” for rare mistakes:
- Gate weight: w = σ(χ) is near 1 for rare wins, near 0 for rare mistakes, and around 0.5 for common actions.
Practically, you take the usual policy‑gradient update and just multiply it by this gate. That’s it. No extra tricks like importance ratios are needed. The authors fix the gate’s sharpness to 1 in all experiments.
How they tested it
The authors combine theory and experiments:
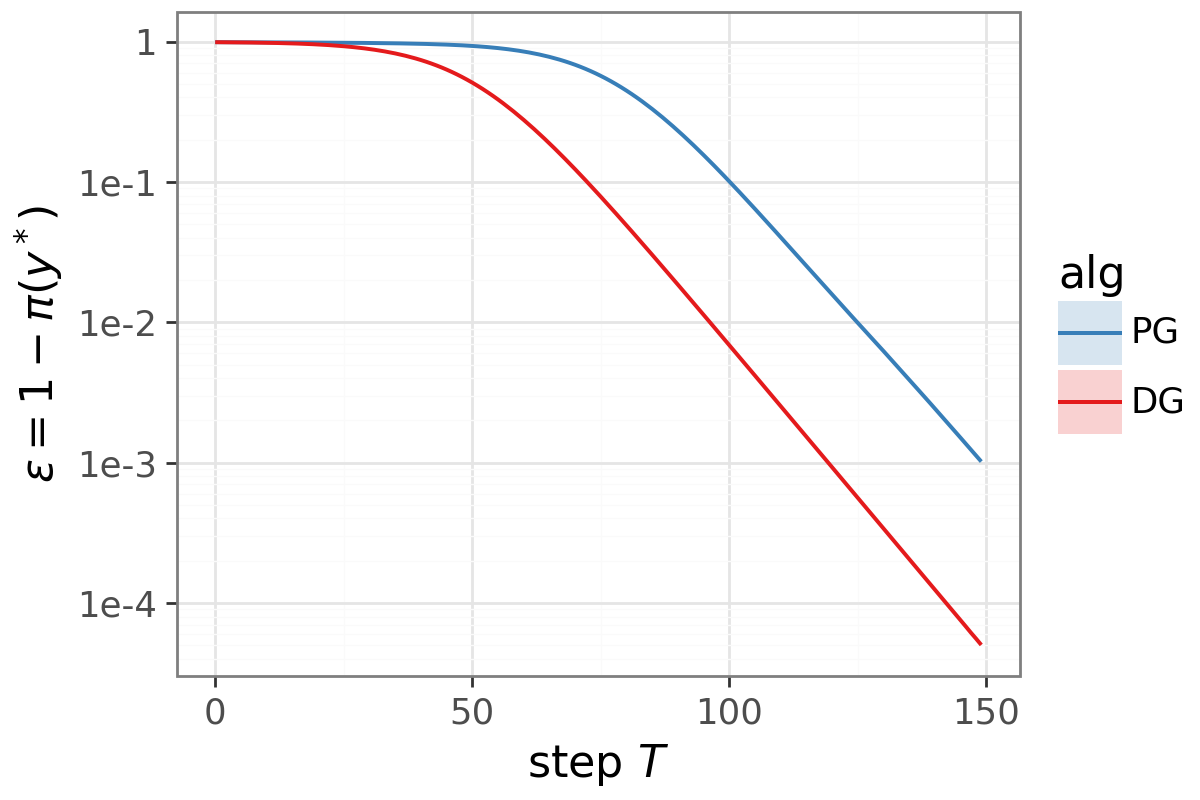
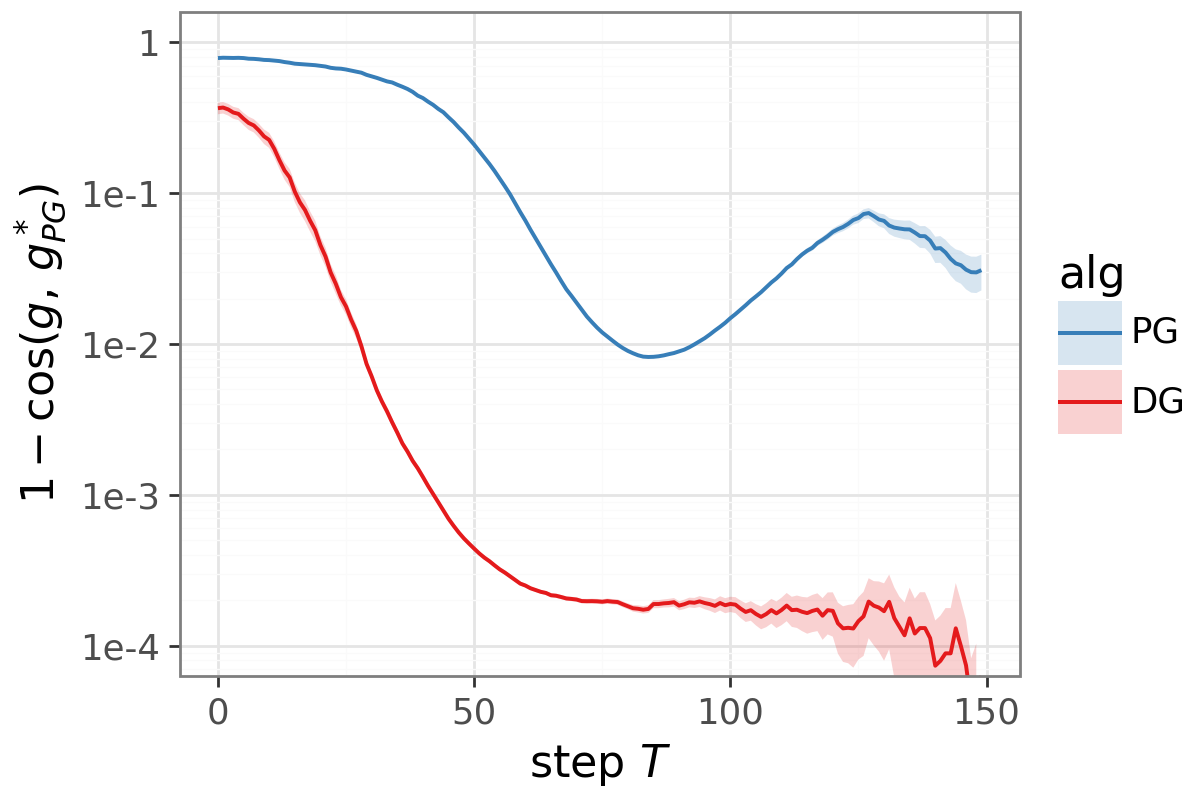
- Simple theory with “bandits” (think: choosing between K slot machines): shows two effects. 1) Within a single situation, DG reduces noisy, off‑direction updates from unlikely bad actions. 2) Across many situations, DG shifts the average update toward a fairer rule that pays more attention to harder cases, not just the easy ones the policy already does well on.
- MNIST as a bandit: Treat digit classification as “guess a label and only see if you’re right.” This tests whether the update points in a better direction without needing full labels.
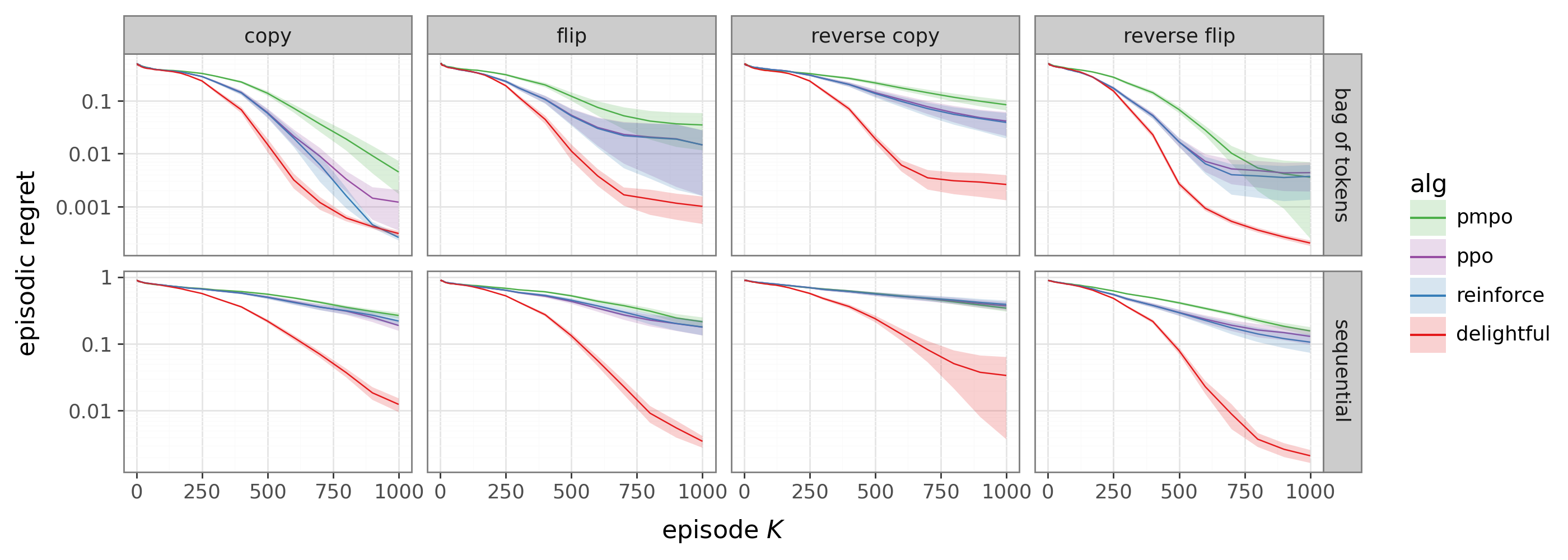
- Token Reversal with Transformers: A sequence task where the model must output the input in reverse. This gets harder as sequences get longer or vocabularies get bigger, so it’s a good test of scaling.
- Continuous control (robot‑like tasks): Tests whether DG works when actions are real‑valued, not just one of a few choices.
What did they find?
Here are the main results and why they matter:
- In theory (bandits):
- DG reduces “variance” within a single decision by turning down the impact of rare bad actions. Translation: fewer random, harmful nudges during learning.
- Across multiple decision contexts (like many images in a batch), DG changes the average update so it pays more attention to harder cases. This isn’t just less noise—it’s a genuinely better direction for long‑term learning, even with infinite data.
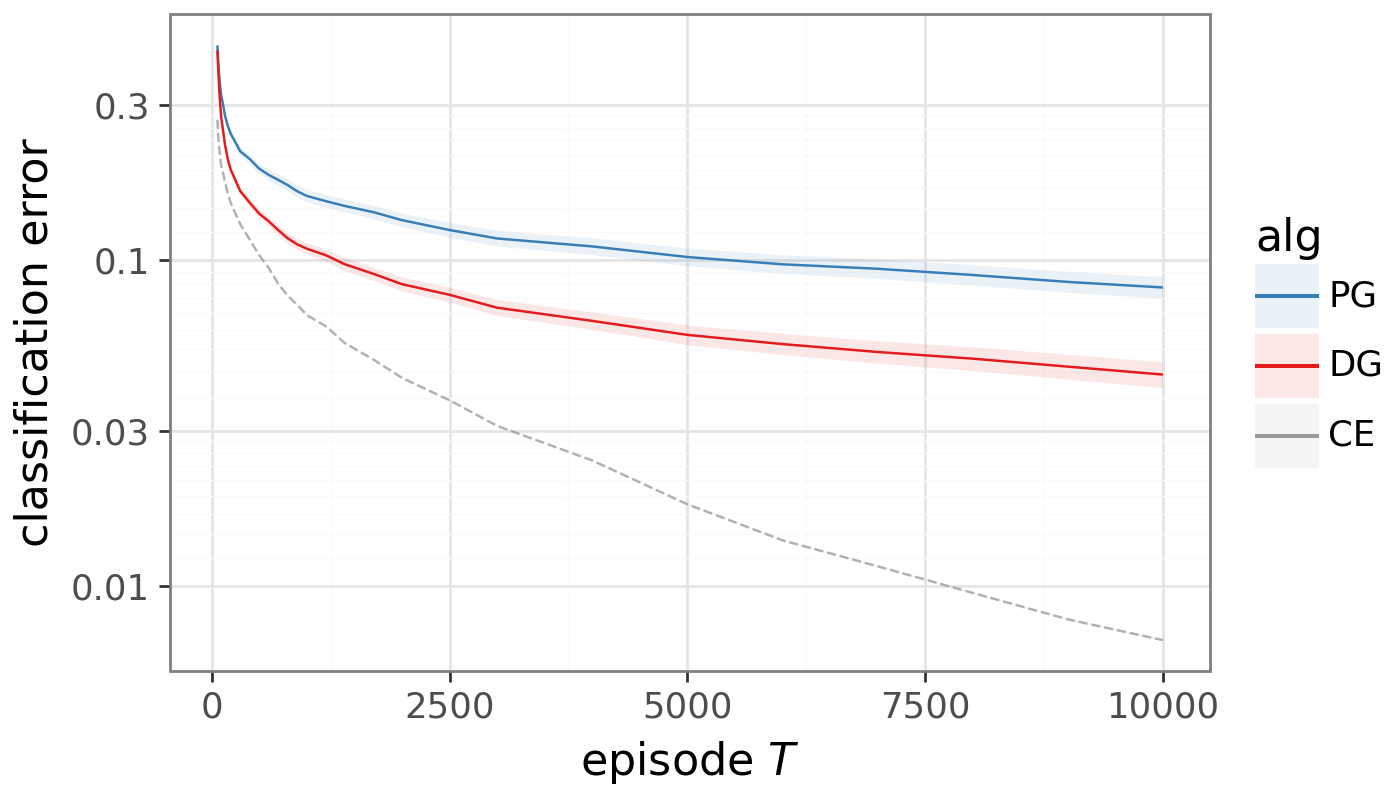
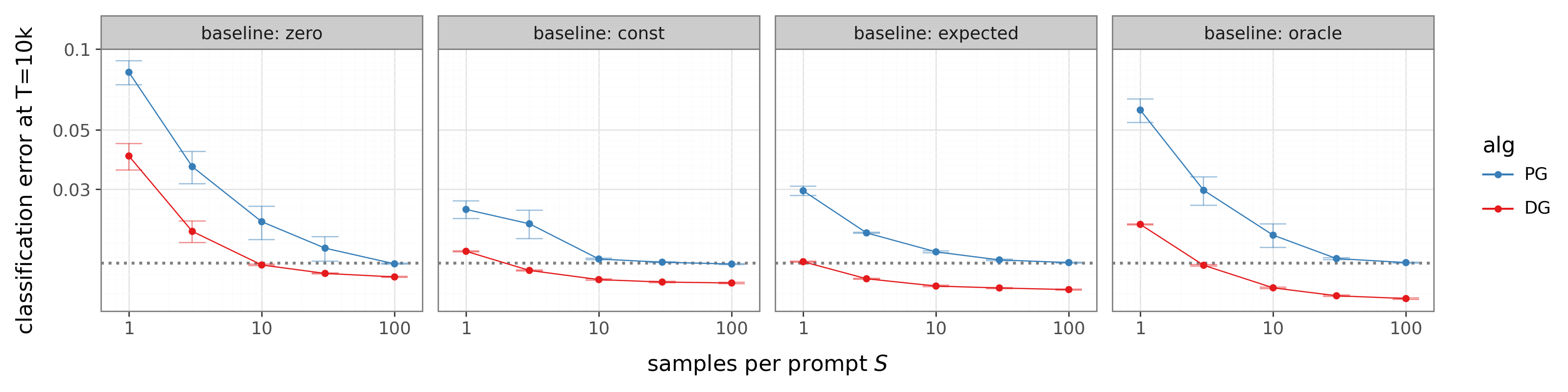
- On MNIST (as a contextual bandit):
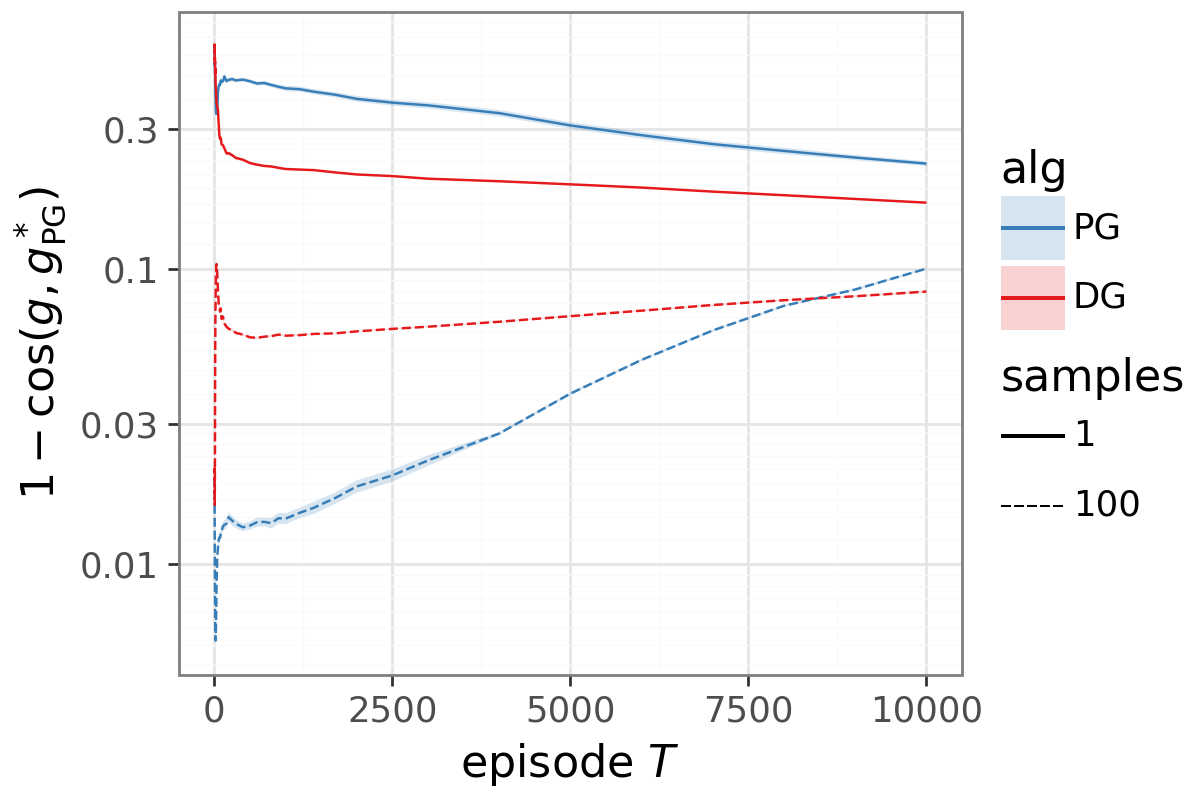
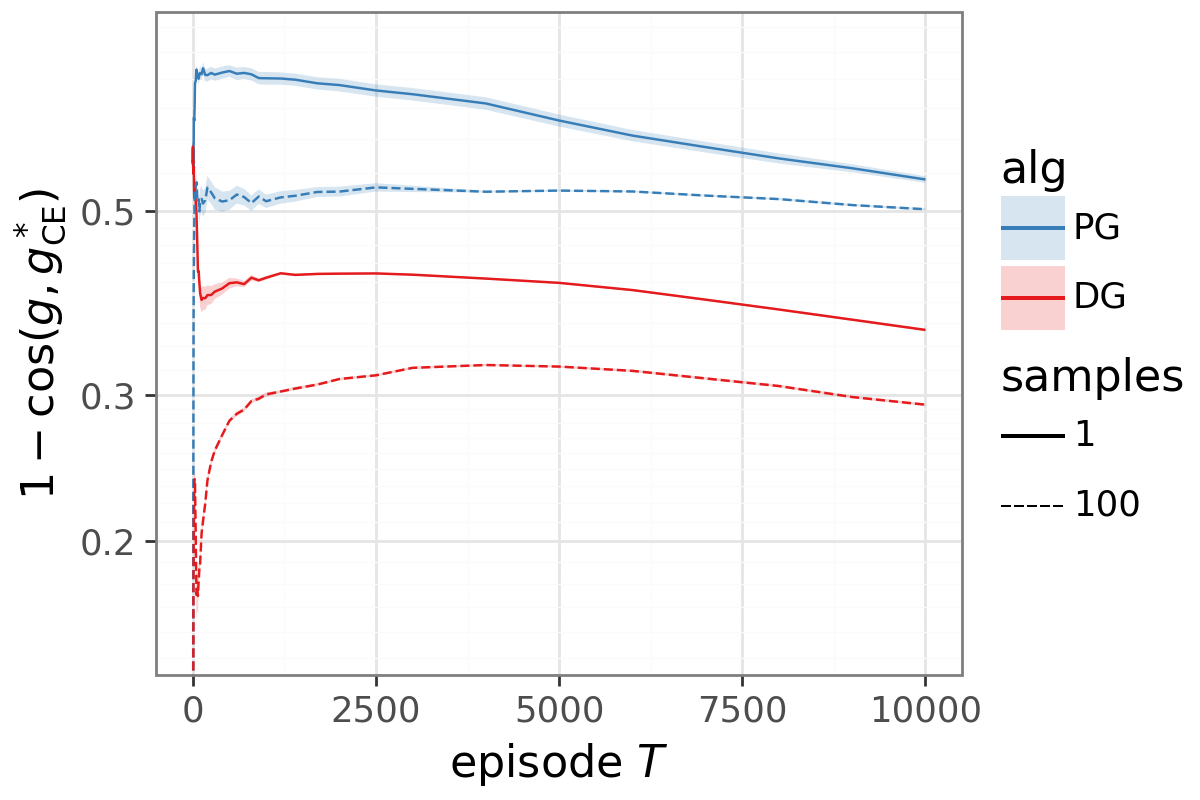
- DG learns faster than standard policy gradient and moves the update direction closer to what supervised learning would do if it had labels.
- The benefit remains even when you average over lots of samples, so it’s not just about reducing noise; the direction itself is improved.
- On Token Reversal (Transformers):
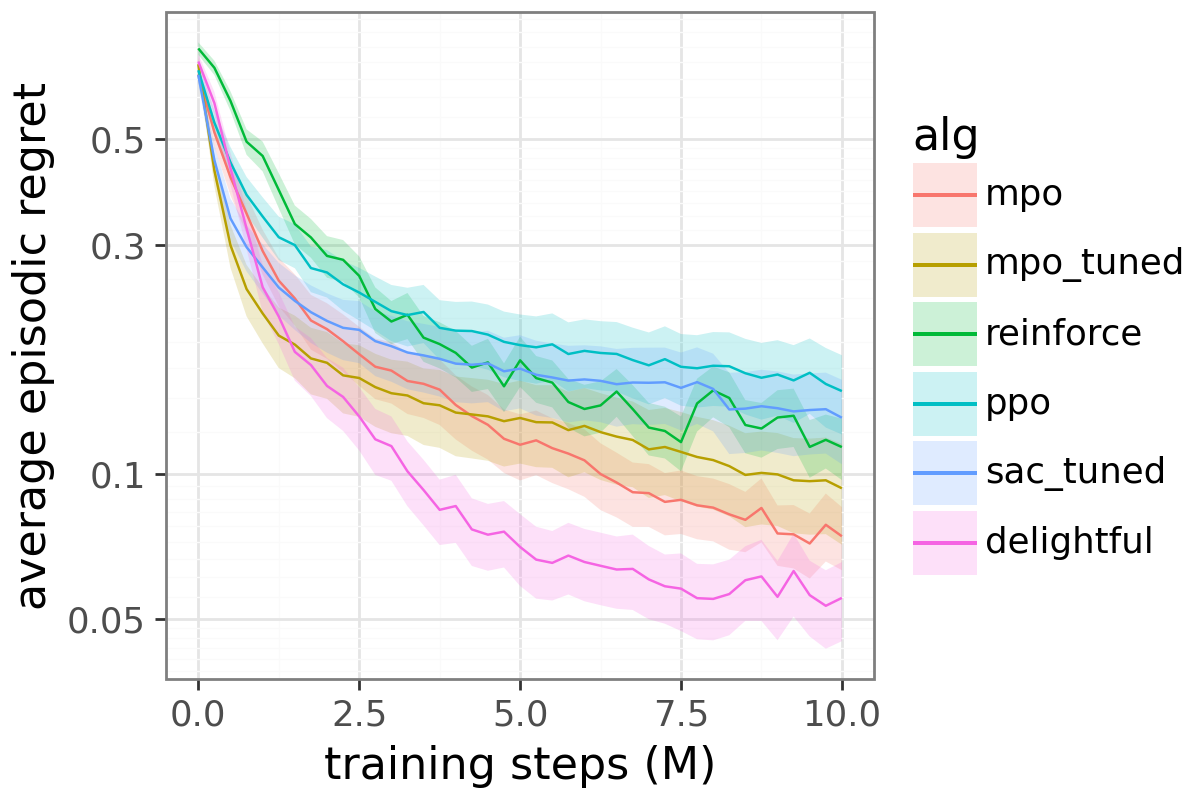
- DG beats REINFORCE, PPO, and advantage‑weighted baselines.
- As the task gets harder (longer sequences, larger vocabularies), DG’s advantage grows. The results show a smaller “scaling exponent,” meaning DG degrades more slowly as the problem becomes more complex.
- On continuous control (DeepMind Control Suite):
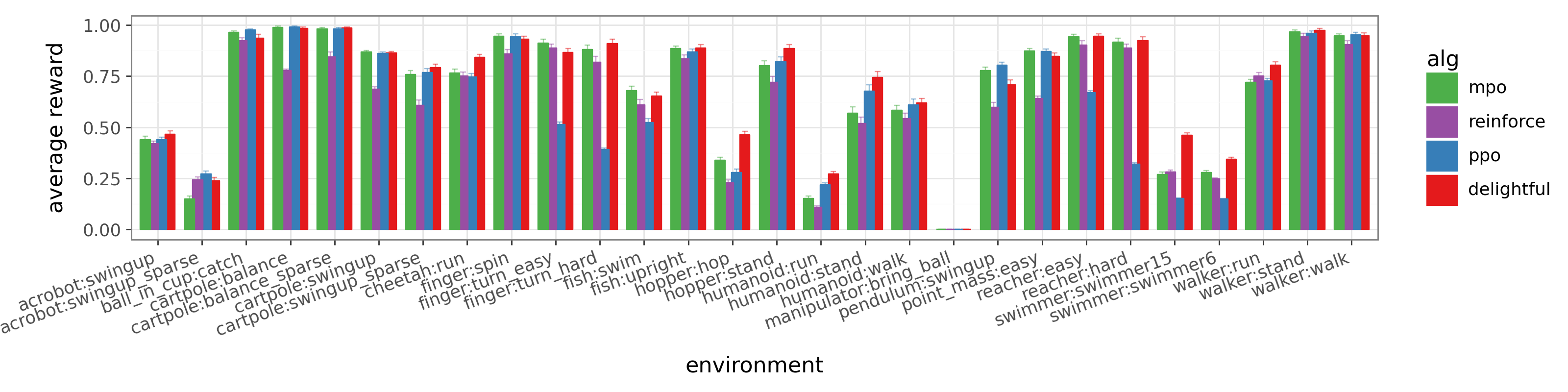
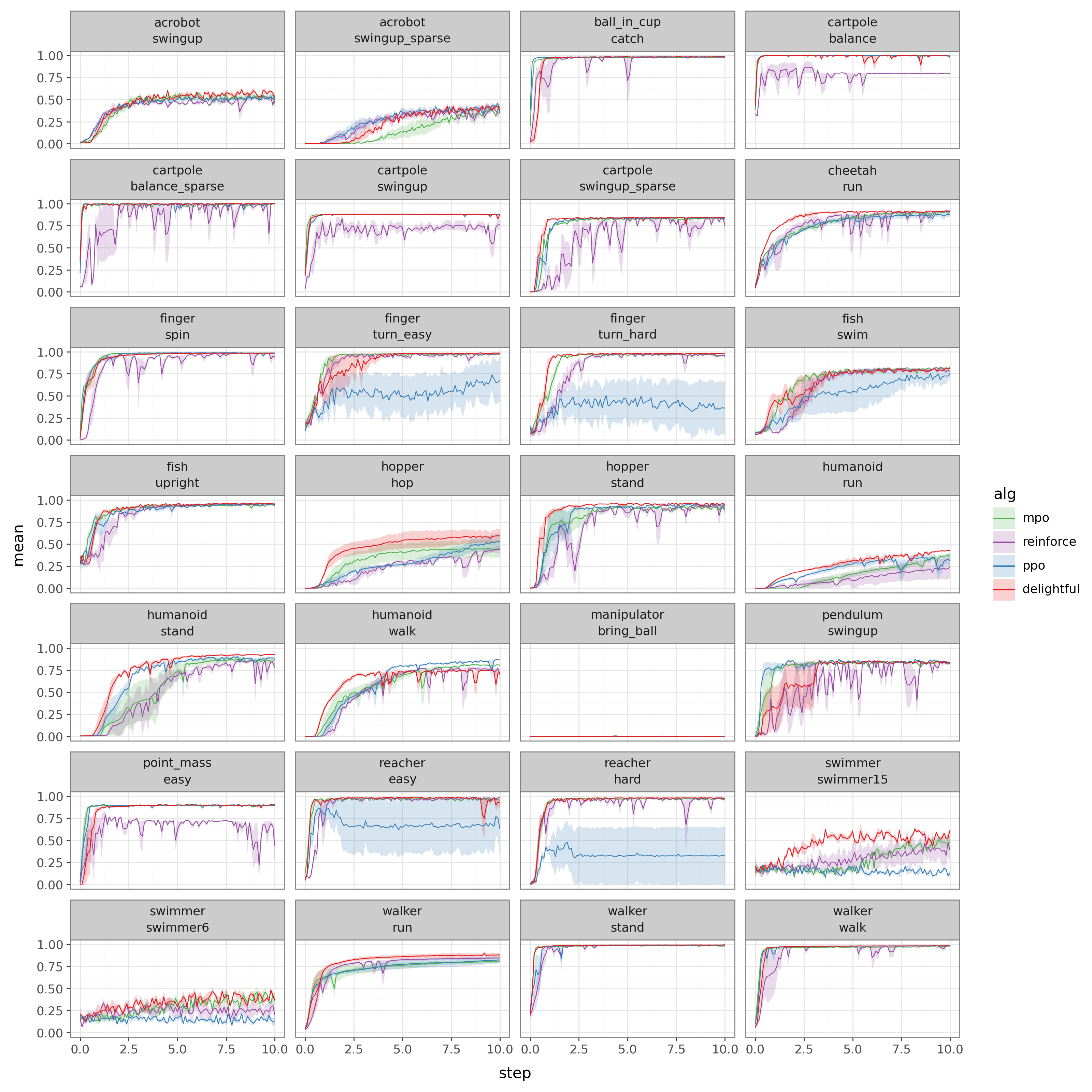
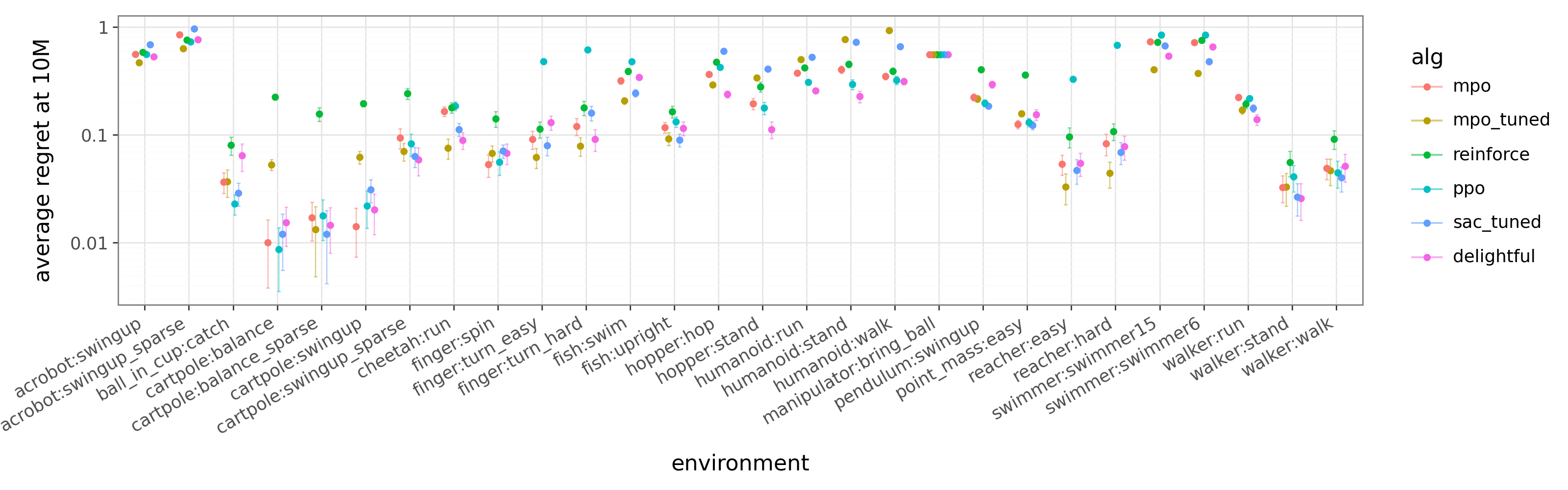
- DG matches or outperforms baselines across many environments, without special tuning.
- It avoids some failures seen in other methods and finds better behaviors in challenging tasks like humanoid running.
Why this matters: A tiny change—multiplying each sample’s gradient by a simple gate—can reduce harmful noise and rebalance learning effort toward harder, more informative cases. That can speed up learning and make it more reliable.
What does this mean going forward?
DG suggests a new default for how we allocate our “learning budget” during training:
- Encourage rare successes strongly so the model explores them more.
- Don’t over‑punish rare failures the model already avoids.
- Stop letting easy, already‑solved cases hog the update just because they succeed often.
Because DG is a drop‑in change and works across images, sequences, and control tasks, it could help in many areas, including training LLMs with human feedback, game‑playing agents, and robots. Open questions include how DG behaves with very sparse rewards, in offline settings, and at much larger scales—but the early signs are promising.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains unclear or unexplored in the paper, written to guide concrete follow‑up research.
Theory and guarantees
- Existence of a global objective: Is DG the (stochastic) gradient of any well-defined surrogate objective ? Derive or rule out such an objective and, if it exists, characterize its stationary points and how they relate to return maximization.
- Convergence guarantees with function approximation: Establish conditions under which DG converges for nonlinear policies with stochastic optimization (e.g., with Adam, gradient clipping), beyond tabular bandits.
- Monotonic improvement and safety: Provide TRPO/PPO‑style monotonic improvement bounds (or counterexamples) for DG updates, including when combined with trust-region constraints.
- Beyond orthogonality/normalized steps: Generalize the tabular directional result (Prop. 2) to realistic settings where per‑context gradients are not orthogonal and step norms are not normalized; bound the angle improvement to the cross-entropy oracle for general and non‑orthogonal .
- Regret and sample complexity: Develop regret/sample‑complexity bounds showing when and by how much DG improves learning speed relative to PG under various reward structures.
- Conditions for harm: Identify regimes where DG degrades performance (e.g., highly misestimated advantages, very low-entropy policies where the sigmoid saturates) and provide formal diagnostics or safeguards.
Method design and hyperparameters
- Temperature tuning and adaptivity: Provide theory or heuristics for selecting/scheduling ; analyze bias–variance trade‑offs induced by , and whether per‑context or per‑task adaptive improves stability/performance.
- Gate shape and alternatives: Compare the sigmoid gate to other monotone gates (e.g., softplus, tanh, piecewise-linear, exponential weighting) theoretically and empirically; characterize when each is preferable.
- Delight definition choices: Evaluate alternatives to (e.g., additive, power‑law, or normalized forms) under controlled conditions and derive when multiplicative delight is optimal.
- Interaction with baselines/critics: Quantify how DG’s bias and variance depend on baseline choice and critic error; provide robustness analyses and bounds under biased, noisy, or stale advantage estimates.
- Gradient norm vs direction in practice: The analysis assumes normalized steps; study how DG’s directional gains translate under common optimizers (Adam, RMSProp) and clipping, and whether additional normalization is beneficial.
Continuous actions and density issues
- Scale invariance of surprisal: Formalize and test DG’s sensitivity to action scaling and parameterization in continuous spaces; design a scale‑invariant surprisal (e.g., via standardized likelihoods, Fisher information, or whitening) with accompanying theory.
- Clipping and whitening: Replace ad‑hoc clipping of log‑densities with principled procedures; provide sensitivity analyses across action ranges and dimensions and study failure modes when densities are ill‑conditioned.
- Reparameterization invariance: Analyze whether DG’s behavior is invariant to common continuous‑control parameterizations (e.g., tanh‑squashed Gaussians) and propose corrections if not.
Off‑policy learning and credit assignment
- Off‑policy DG: Derive a theoretically sound off‑policy variant (importance‑weighted gate and/or coefficient) and characterize the bias/variance trade‑offs relative to on‑policy DG; test with replay-heavy actor–critic methods (DDPG/TD3/SAC).
- Trajectory‑level gating: Investigate sequence‑ or trajectory‑level delight (e.g., gating by episode‑wise surprisal) for sparse/long‑horizon tasks; compare step‑wise vs sequence‑wise gates in terms of credit assignment and stability.
- Interaction with GAE/TD(λ): Analyze how DG composes with generalized advantage estimation and bootstrapped critics in long‑horizon settings; quantify effects on bias, variance, and delay in credit propagation.
Robustness and failure modes
- Exploration effects: By suppressing rare failures, does DG inadvertently diminish learning signals needed to avoid bad actions or reduce exploration in deceptive‑reward tasks? Construct tasks that require strong negative updates and measure DG’s behavior.
- Sensitivity to advantage misestimation: Stress‑test DG under adversarially biased or high‑variance advantage estimates; bound performance degradation and propose robustified gates (e.g., uncertainty‑aware delight).
- Saturation and vanishing updates: Characterize when the sigmoid saturates (large ||) and leads to near‑zero or near‑one gates; propose mechanisms (e.g., temperature schedules, gradient rescaling) to avoid vanishing/exploding effective coefficients.
- Non‑stationarity: Evaluate DG in non‑stationary environments and curriculum settings to test whether rebalancing towards “hard” contexts hinders adaptation when task difficulty shifts.
- Safety/constraints: Assess DG on safety‑critical tasks with constraints; gate amplification of “breakthroughs” could increase unsafe behavior unless paired with constraint‑aware critics or shields.
Empirical scope and reproducibility
- Larger‑scale LLM/RLHF validation: Test DG on large‑scale RLHF or instruction‑tuning setups to verify whether cross‑context reweighting yields consistent gains in human‑preference alignment and sample efficiency.
- Hard‑sparse benchmarks: Evaluate on sparse‑reward control (e.g., robotic manipulation, long‑horizon navigation) and procedurally generated environments to test DG’s purported scaling advantage under genuine sparsity.
- Broader baseline comparisons and hybrids: Combine DG with trust regions (TRPO/PPO‑style), advantage‑weighted regression (AWR/PMPO), or conservative objectives to investigate complementary benefits and trade‑offs.
- Ablations of surprisal source in Transformers: Token‑level vs sequence‑level surprisal gating; assess which granularity better tracks breakthroughs/blunders in autoregressive models.
- Reporting and sensitivity: Provide comprehensive ablations for , clipping ranges, whitened-, advantage baselines, batch size, and optimizer hyperparameters across all domains (not only MNIST).
Interpretability and connections
- Information‑theoretic interpretation: Beyond the local entropy‑regularized gate derivation, develop a global information‑theoretic view (e.g., relationship to rate–distortion, Donsker–Varadhan inequalities, or KL‑constrained optimization) explaining DG’s weighting rule.
- Relation to cross‑entropy and calibration: Formalize when reweighting toward the cross‑entropy oracle increases expected return and when it may conflict with return maximization; analyze dependence on reward scale and miscalibration of policy probabilities.
- Multi‑agent and competitive settings: Explore DG’s effects in self‑play and multi‑agent RL, where reweighting rare successes/failures may affect equilibrium learning dynamics.
Practical Applications
Immediate Applications
The following applications can be deployed with modest engineering effort by swapping standard policy-gradient updates for Delightful Policy Gradient (DG), adding a sigmoid gate on advantage×surprisal and the basic numeric safeguards noted in the paper.
- Sectors: Robotics, Industrial Automation (Continuous Control)
- Use case: Replace REINFORCE/PPO-style actor updates with DG to improve stability and sample efficiency in continuous-control training (e.g., locomotion, manipulation, autonomous equipment).
- Tools/products/workflows: PyTorch/TensorFlow policy-gradient wrapper that multiplies each score term by σ(U·(−log π(a|s))); plugins for RLlib/Acme/CleanRL/Stable-Baselines3; “delight” telemetry (histograms of U, surprisal, gate activations) to monitor learning.
- Assumptions/dependencies: On-policy log-densities available; advantage estimates (e.g., GAE); clip log-densities (e.g., to [−10, 10]) or whiten χ when scales vary; in safety-critical training, verify that suppressing rare failures is acceptable or adjust gate for risk sensitivity.
- Sectors: Recommender Systems, Ads, E-commerce (Contextual Bandits)
- Use case: Bandit optimization for ranking/placement where user clicks or conversions provide evaluative feedback; DG reallocates gradient budget toward “hard” contexts (low success probability) while attenuating noise from rare failures.
- Tools/products/workflows: Bandit learner with DG-weighted policy updates; A/B flight as a drop-in replacement for PG weighting; dashboards showing reweighting across segments to detect over-emphasis on “easy” traffic.
- Assumptions/dependencies: Reliable per-decision log-probabilities; advantage baselines (e.g., per-context expected reward); guardrails to cap negative user impact; privacy/compliance for feedback logging.
- Sectors: Foundation Models, Conversational AI (RLHF/RLAIF)
- Use case: Reinforcement learning from human or AI feedback where advantage comes from a reward model and surprisal from token log-probabilities; DG preserves rare promising generations and suppresses rare poor ones, improving data efficiency on hard prompts.
- Tools/products/workflows: Integration into PPO/GRPO-style RLHF loops (e.g., TRL) by DG-weighting the policy-gradient term; logging of delight per token/sequence to inform prompt curricula.
- Assumptions/dependencies: Reward model quality; on-policy token log-probs; tuning may be minimal (η≈1 worked in the paper), but monitor for mode-collapse/overconfidence.
- Sectors: Vision and Classification with Bandit Feedback (Weak/Partial Labels)
- Use case: Banditized classification or feedback-driven tagging (thumbs-up/down, implicit signals) where labels are unavailable; DG narrows the gap to cross-entropy training without labels by rebalancing across images/contexts.
- Tools/products/workflows: Supervised training loop augmented with DG-based sample weighting using reward-derived advantages and model surprisal; offline diagnostics comparing alignment to CE oracle on held-out labeled data.
- Assumptions/dependencies: Binary/sparse feedback must be available; baselines for advantage (constant/learned); evaluation with labeled data for safety before deployment.
- Sectors: Games, Simulation-Based Training
- Use case: Faster policy learning for agents in strategy, sports, and RTS games; DG mitigates “easy-context dominance” that stalls progress on hard states or tasks.
- Tools/products/workflows: DG actor updates in existing training stacks; curriculum schedules informed by delight statistics (identify states with high surprisal×advantage breakthroughs).
- Assumptions/dependencies: Access to action probabilities and advantage; verify interactions with self-play and opponent sampling.
- Sectors: Education and Personalization (Adaptive Tutoring, Content Sequencing)
- Use case: Bandit-driven personalization where correct/engagement feedback is observed but not full labels; DG directs learning toward students/skills where the model underperforms.
- Tools/products/workflows: DG-weighted policy updates in adaptive sequencing; “hardness” heatmaps from delight to drive human-in-the-loop curriculum design.
- Assumptions/dependencies: Ethical and privacy constraints; bias monitoring so reweighting does not inadvertently reduce exposure for certain groups.
- Sectors: MLOps/Research Tooling
- Use case: Gradient-quality diagnostics and training stability improvements in RL experiments.
- Tools/products/workflows: “Delight dashboard” tracking advantage, surprisal, gate activations, and cosine alignment to oracles on synthetic tasks; unit tests that compare DG vs PG under controlled bandits.
- Assumptions/dependencies: Synthetic benchmarks and ablations to validate configuration before production use.
- Sectors: Operations and Resource Allocation (Online Decision Policies)
- Use case: Routing, pricing, or inventory bandits where infrequent but high-value actions exist; DG emphasizes rare successes and avoids over-optimizing already-easy contexts.
- Tools/products/workflows: DG-enabled policy service with per-decision logging and offline counterfactual evaluation.
- Assumptions/dependencies: Business safeguards for rare negative outcomes; compatibility with existing experimentation frameworks.
Long-Term Applications
These opportunities are promising but require further research, scaling studies, or domain-specific validation (e.g., safety, regulation, offline data).
- Sectors: Foundation Models at Scale (Alignment, Preference Optimization)
- Use case: Redesign preference-optimization objectives (DPO/PMPO/GRPO variants) to include delight-based gating at the token or sequence level, potentially reducing scaling exponents on long-horizon, large-vocabulary generation.
- Tools/products/workflows: DG-augmented preference optimization; adaptive η schedules; hybrid trust-region-plus-DG objectives to preserve stability with large batch sizes.
- Assumptions/dependencies: Convergence guarantees under large-scale optimization; interaction with KL constraints and importance ratios; extensive human evaluation for safety/quality.
- Sectors: Safety-Critical RL (Healthcare, Autonomous Driving, Energy Grid)
- Use case: Risk-aware variants that do not overly suppress rare failures; e.g., asymmetric gates that amplify rare negative-advantage events when they imply safety hazards.
- Tools/products/workflows: “Safety-DG” with calibrated gates or CVaR-weighted advantages; formal verification and simulators-in-the-loop; incident replay with off-policy corrections.
- Assumptions/dependencies: Strong offline evaluation; regulatory approval; robust off-policy treatment (importance sampling or conservative updates).
- Sectors: Fairness and Responsible AI (Policy/Compliance)
- Use case: Reduce “easy-context dominance” that can mirror majority-group dominance; use delight to reallocate gradient budget toward underperforming subpopulations.
- Tools/products/workflows: Training-time reweighting with group-aware auditing; fairness dashboards showing changes in per-group gradient allocation.
- Assumptions/dependencies: Careful definition of “hardness” that is not confounded with sensitive attributes; governance to avoid unintended harm; stakeholder review.
- Sectors: Offline RL and Batch Learning
- Use case: Extend DG to off-policy settings by combining delight with robust importance sampling or conservative policy updates.
- Tools/products/workflows: Off-policy DG estimators with clipped ratios and gate-aware trust regions; replay-buffer prioritization by delight.
- Assumptions/dependencies: Theoretical treatment of bias/variance with off-policy data; stability on real-world datasets with distribution shift.
- Sectors: Multi-Task and Curriculum Learning
- Use case: Use delight to automatically rebalance training across tasks or skills, approximating cross-entropy-like equalization of progress rather than reward-weighted myopic gains.
- Tools/products/workflows: “Auto-balance” schedulers that allocate compute across tasks by aggregated delight; task-level gates and η-tuning.
- Assumptions/dependencies: Reliable per-task advantage signals; avoiding starvation of essential foundational tasks.
- Sectors: Finance (Market Making, Execution, Portfolio RL)
- Use case: Emphasize rare but informative successes (e.g., fills in illiquid regimes) while damping noisy failures in policy updates.
- Tools/products/workflows: Simulation-first with DG; guardrailed deployment with strict risk limits; delight-aware backtesting reports.
- Assumptions/dependencies: Strong risk controls; compliance; handling heavy tails and non-stationarity.
- Sectors: Human-in-the-Loop Systems (Moderation, Search, Assistants)
- Use case: Faster learning from sparse human feedback where promising but rare actions should be propagated; DG can reduce human labeling load by exploiting breakthroughs.
- Tools/products/workflows: Active-learning loops that surface high-delight samples to experts; semi-automatic curricula driven by delight distributions.
- Assumptions/dependencies: Feedback quality; UX constraints; safeguards against reinforcing spurious “breakthroughs.”
- Sectors: Platform and Library Ecosystem
- Use case: Standardize DG as a first-class optimizer option with auto-tuned baselines and diagnostics; provide certified implementations for production.
- Tools/products/workflows: Stable-Baselines3/RLlib/Acme “DGActor” modules; profiling tools for gate saturation; reference suites (bandits, sequence modeling, control) for CI.
- Assumptions/dependencies: Community validation; cross-hardware numerical stability; long-horizon benchmarks to demonstrate scaling trends.
Notes on feasibility and cross-cutting dependencies:
- DG is a drop-in reweighting of the policy-gradient term; compute overhead is minimal (one sigmoid and multiply per sample), but logging surprisal and delight is essential for monitoring.
- Advantages must be well-estimated; poor baselines can negate benefits. Existing techniques (e.g., GAE, learned baselines) apply.
- For continuous actions, log-density scaling matters; clip or whiten as shown in the paper.
- DG changes the expected update direction. This is beneficial for balancing across contexts but may interact with trust-region constraints, off-policy ratios, or safety objectives and should be validated per domain.
- In domains where rare failures are catastrophic, consider risk-sensitive gates or complementary penalties to avoid underweighting safety-critical negatives.
Glossary
- Actor–critic (architecture): A reinforcement learning framework with separate policy (actor) and value (critic) components. "All methods share the same actor--critic architecture, critic algorithm (Retrace~\citep{munos2016safe} with replay), and optimizer; only the policy update rule differs."
- Action density: The probability density function over continuous action spaces defined by a policy. "where the policy defines an action density rather than a discrete distribution."
- Action surprisal: The negative log-probability of a sampled action under the current policy, measuring how unexpected it was. "the product of advantage and action surprisal (negative log probability)."
- Advantage: A centered estimate of action value indicating how much better an action is compared to a baseline. "Standard policy gradients weight each sampled action by advantage alone, regardless of how likely that action was under the current policy."
- Advantage-weighted methods: Algorithms that scale updates by a function of advantage without considering action probability. "advantage-weighted methods~\citep{peng2019advantage,abdolmaleki2024preference} reweight by advantage alone."
- Advantage-Weighted Regression (AWR): An RL method that updates policies by regressing toward actions weighted by their advantages. "AWR~\citep{peng2019advantage} and PMPO~\citep{abdolmaleki2024preference} set for some increasing function of advantage, but remain blind to surprisal."
- Bandit feedback: Feedback that provides only the outcome of chosen actions without full labels, as in bandit settings. "Taken together, these results suggest that DG addresses a core policy-gradient mismatch that appears even in canonical classification under bandit feedback."
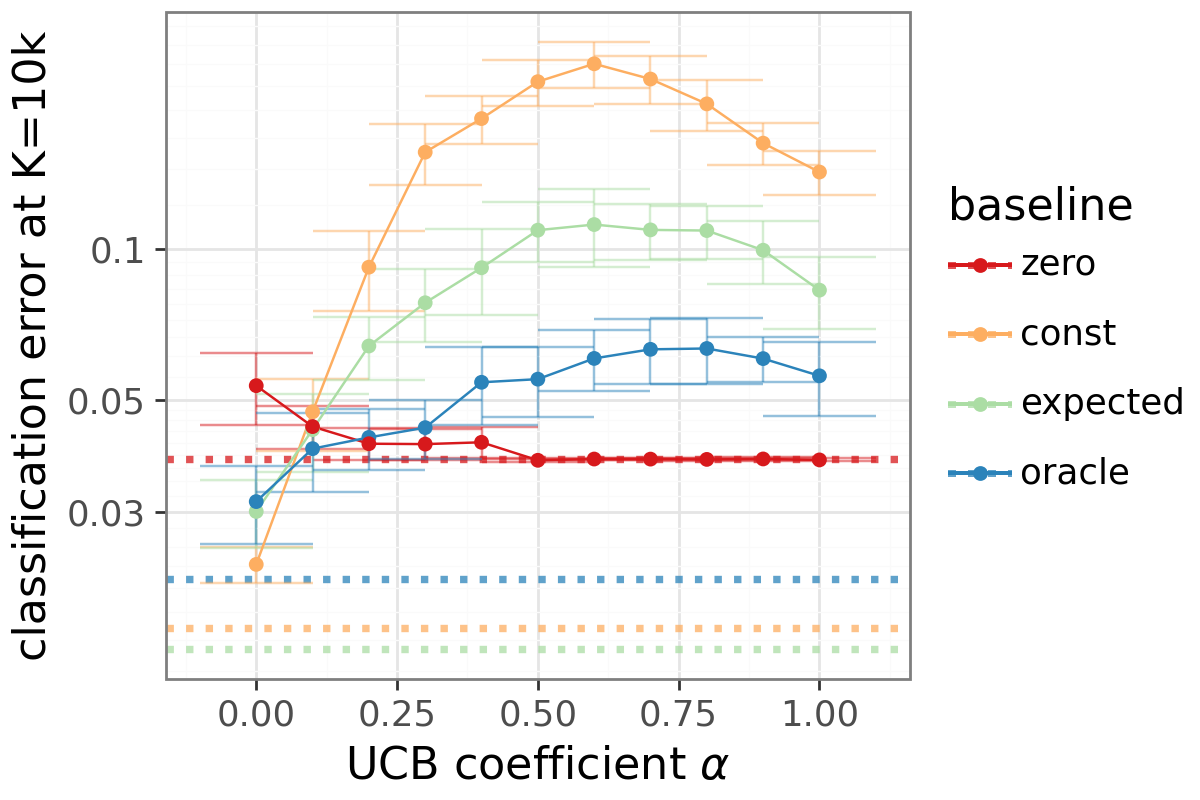
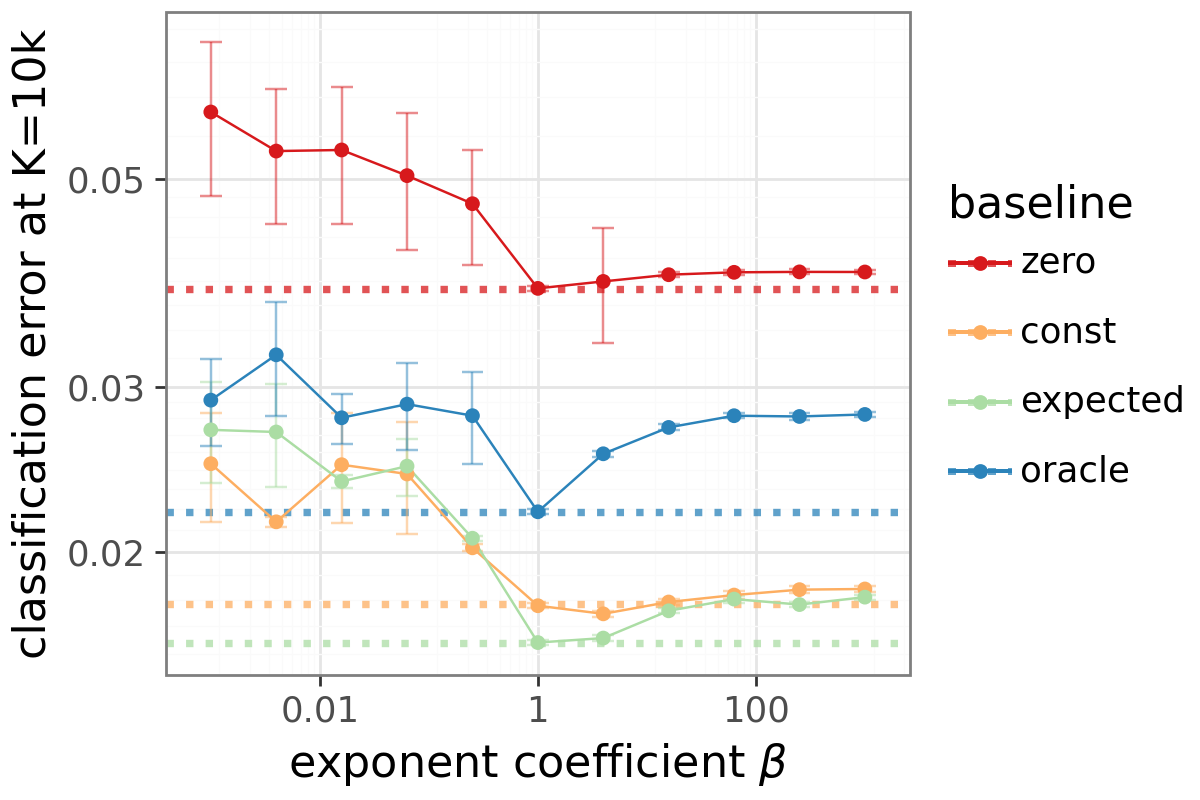
- Baseline (variance-reduction baseline): A reference value subtracted from returns to reduce variance without changing expected gradients. "The advantage takes the form , and we consider four baselines: (zero), (constant), using the agent's own probability estimate (expected), and using the true label probability (oracle)."
- Bias–variance decomposition: Splitting error into components due to systematic bias and sampling variance. "The two mechanisms map onto a bias--variance decomposition."
- Contextual bandit: A bandit problem where action choices depend on observed contexts. "We cast MNIST classification as a one-step contextual bandit."
- Control variate: A technique to reduce estimator variance by incorporating correlated variables with known expectation. "Prior variance-reduction methods (baselines, control variates~\citep{kool2019buy}) reduce variance but leave the expected gradient direction unchanged."
- Cross-entropy: A supervised learning objective that sums negative log-probabilities of correct labels. "we directly confirm both effects and show that DG closes roughly half the gap to supervised cross-entropy"
- Cross-entropy oracle: The gradient direction obtained by treating all contexts equally, as in supervised cross-entropy. "shifts the expected gradient strictly closer to the supervised cross-entropy oracle."
- Delight: The product of advantage and action surprisal used to gate gradient contributions. "We define delight as the product of advantage and action surprisal"
- Delightful Policy Gradient (DG): A policy-gradient variant that gates updates by a sigmoid of delight to amplify rare successes and suppress rare failures. "We introduce the Delightful Policy Gradient (DG), which gates each sampled gradient term by a sigmoid of delight"
- Entropy regularization: Adding an entropy term to an objective to encourage exploration or smoothness. "The sigmoid gate also arises from a local entropy-regularized objective over gate values (Appendix~\ref{app:derivations})."
- Gate (sigmoid gate): A multiplicative factor between 0 and 1 that scales each gradient term based on delight. "The gate is "
- Generalized Advantage Estimation (GAE): A method for reducing variance and bias in advantage estimates using temporal smoothing. "generalized advantage estimation~\citep{schulman2016high}"
- Importance ratios: Ratios of action probabilities under target and behavior policies used in off-policy corrections. "Trust-region methods~\citep{schulman2015trust,schulman2017proximal} clip importance ratios to limit policy change"
- Kelly criterion: A strategy optimizing long-run growth by allocating resources proportionally to edge. "As with the Kelly criterion~\citep{kelly1956new}, greedy single-step optimality does not imply optimal long-run compounding."
- Logit: The unnormalized score whose softmax defines action probabilities. "We parameterize policies by logits , so ."
- Natural policy gradient: A policy-gradient method that preconditions updates using the Fisher information metric. "The natural policy gradient~\citep{kakade2001natural} and its trust-region successors TRPO, PPO~\citep{schulman2015trust,schulman2017proximal}, and GRPO~\citep{shao2024deepseekmath} constrain or precondition the update"
- Normalized step: An update scaled to have fixed norm, emphasizing direction over magnitude. "Under a normalized step with :"
- On-policy: Learning using data generated by the current policy. "At an optimal policy, on-policy advantages vanish, so delight vanishes and optimal policies are stationary points of DG for all "
- Oracle (PG oracle): The expected policy-gradient direction computed using true labels or exact expectations. "Dashed line: error from the exact PG-oracle gradient , PG's best achievable direction."
- Perpendicular variance: Variance of gradient components orthogonal to the true gradient direction. "and for the perpendicular variance."
- PMPO: Preference-based maximum a posteriori policy optimization method. "AWR~\citep{peng2019advantage} and PMPO~\citep{abdolmaleki2024preference} set "
- PPO (Proximal Policy Optimization): A trust-region method that clips policy updates to prevent large deviations. "Empirically, DG outperforms REINFORCE, PPO, and advantage-weighted baselines across MNIST, transformer sequence modeling, and continuous control."
- REINFORCE: A Monte Carlo policy-gradient algorithm using the log-likelihood gradient times returns (or advantages). "Empirically, DG outperforms REINFORCE, PPO, and advantage-weighted baselines across MNIST, transformer sequence modeling, and continuous control."
- Retrace: An off-policy value-estimation algorithm using truncated importance sampling. "All methods share the same actor--critic architecture, critic algorithm (Retrace~\citep{munos2016safe} with replay), and optimizer"
- Score identity: The fact that the expected score under the model is zero, used for variance analyses. "The score identity implies ."
- Score term (log-likelihood gradient): The gradient of the log-policy with respect to parameters, used in policy gradients. "Thus each score term is weighted by advantage alone, regardless of how likely the sampled action was under the current policy."
- Scaling exponent: The exponent characterizing how performance scales with problem size in a power-law relationship. "on Token Reversal, DG exhibits a smaller empirical scaling exponent than all baselines."
- Sigmoid: The logistic function σ(x)=1/(1+e{−x}) used here as a gating function. "for the sigmoid "
- Soft Actor-Critic (SAC): An off-policy RL algorithm optimizing a maximum-entropy objective. "It also remains competitive with highly tuned MPO~\citep{abdolmaleki2018maximum} and SAC~\citep{haarnoja2018soft} despite using no task-specific tuning"
- Surprisal: Information-theoretic measure of event unlikelihood; here, negative log-probability under the policy. "This surprisal is policy-relative: it measures how unlikely the action was under the policy, not how common that action is in the environment."
- Temperature (η): A scalar controlling the sharpness of the sigmoid gate. "The resulting estimator is the Delightful Policy Gradient (DG): one sigmoid, one multiply, and a temperature that we fix to $1$ throughout."
- Temporal credit assignment: Determining which past actions/states are responsible for future rewards in sequential tasks. "We now test the same mechanism in a sequential setting with memory, autoregressive generation, and temporal credit assignment."
- Trust-region methods: Algorithms that constrain policy updates to remain within a small region to maintain stability. "Trust-region methods~\citep{schulman2015trust,schulman2017proximal} clip importance ratios to limit policy change"
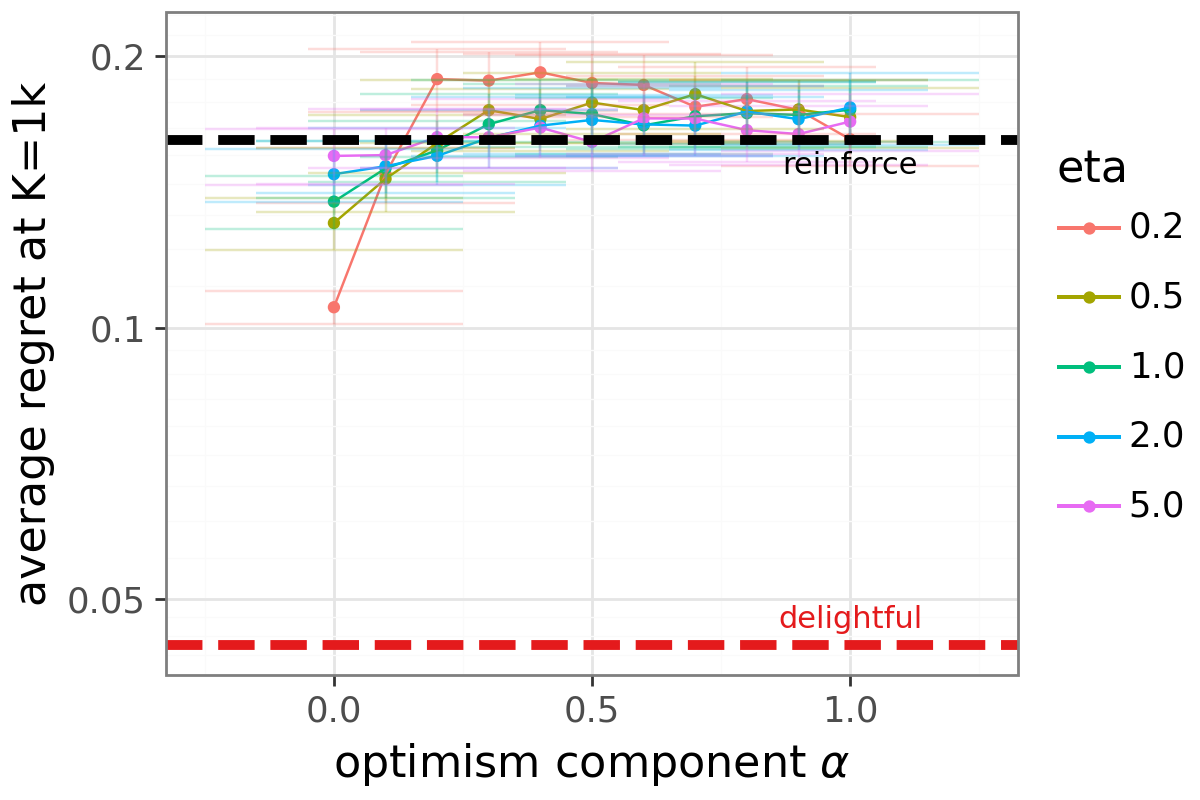
- UCB-style mixtures: Combinations inspired by Upper Confidence Bound methods, balancing exploitation and exploration signals. "UCB-style mixtures improve over REINFORCE but do not match DG (Appendix~\ref{app:scaling_alternative})."
- Variance reduction: Techniques to lower the variability of gradient estimators without changing their expectation. "Prior variance-reduction methods (baselines, control variates~\citep{kool2019buy}) reduce variance but leave the expected gradient direction unchanged."
- Whitening: Normalizing a variable to zero mean and unit variance before further processing. "when action scales vary substantially across dimensions, one can also whiten before gating."
Collections
Sign up for free to add this paper to one or more collections.