DVD: Deterministic Video Depth Estimation with Generative Priors
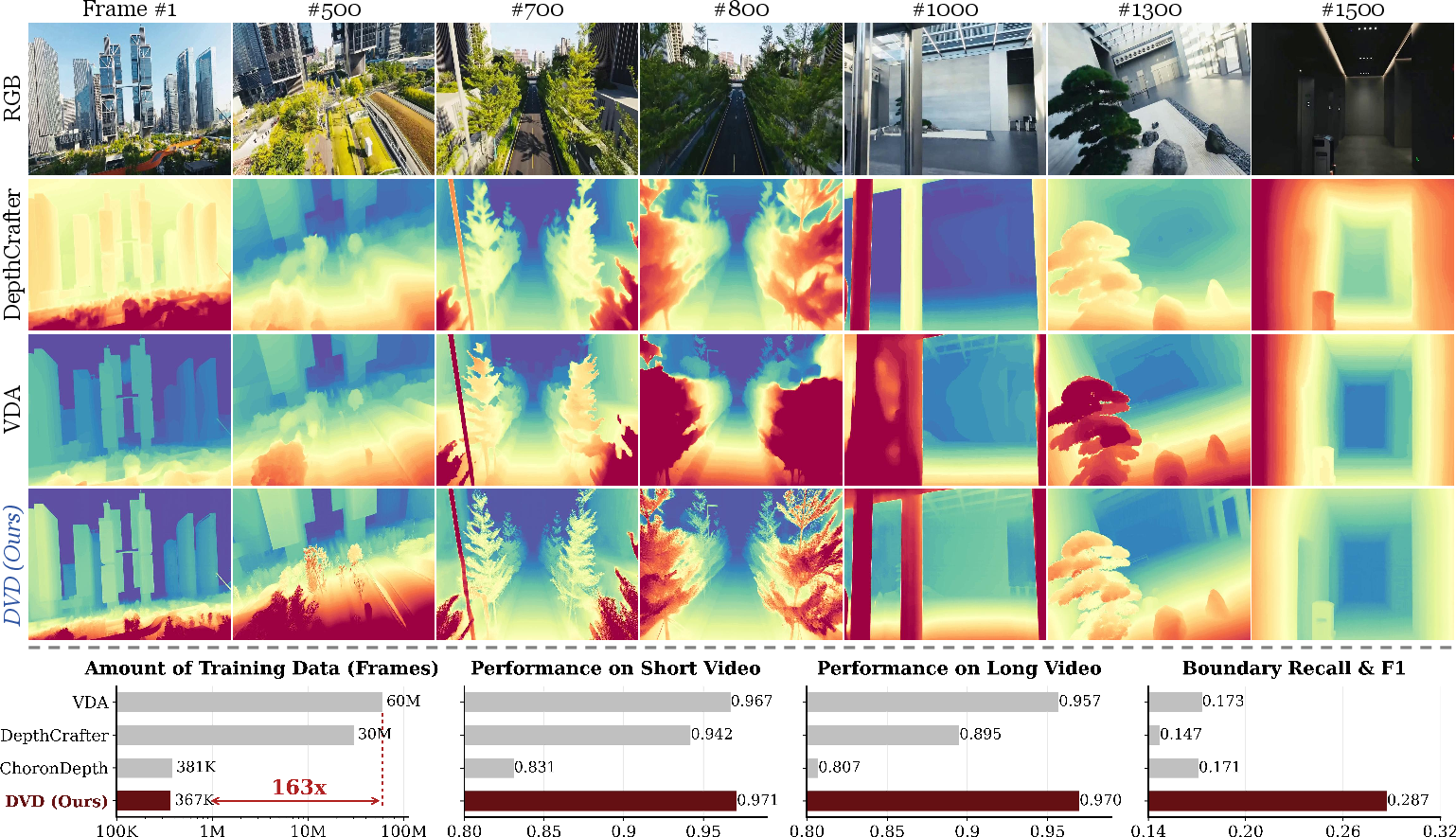
Abstract: Existing video depth estimation faces a fundamental trade-off: generative models suffer from stochastic geometric hallucinations and scale drift, while discriminative models demand massive labeled datasets to resolve semantic ambiguities. To break this impasse, we present DVD, the first framework to deterministically adapt pre-trained video diffusion models into single-pass depth regressors. Specifically, DVD features three core designs: (i) repurposing the diffusion timestep as a structural anchor to balance global stability with high-frequency details; (ii) latent manifold rectification (LMR) to mitigate regression-induced over-smoothing, enforcing differential constraints to restore sharp boundaries and coherent motion; and (iii) global affine coherence, an inherent property bounding inter-window divergence, which enables seamless long-video inference without requiring complex temporal alignment. Extensive experiments demonstrate that DVD achieves state-of-the-art zero-shot performance across benchmarks. Furthermore, DVD successfully unlocks the profound geometric priors implicit in video foundation models using 163x less task-specific data than leading baselines. Notably, we fully release our pipeline, providing the whole training suite for SOTA video depth estimation to benefit the open-source community.
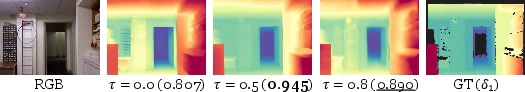


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper is about teaching computers to understand how far away things are in a video—called “depth estimation.” That’s important for robots, self-driving cars, AR/VR, and making 3D maps from everyday videos. The authors introduce a new way to get stable, accurate depth from videos by turning a powerful video “generative” model (a model that normally creates or edits videos) into a fast, predictable “regressor” (a model that directly outputs numbers—in this case, depth). They call their approach a deterministic video depth system, which means it gives the same result every time for the same input.
Key questions the paper asks
- Can we combine the strong world understanding of generative video models with the stability and speed of direct prediction models?
- Can we do this without needing enormous amounts of labeled training data?
- Can we keep depth consistent across long videos, not just a few frames?
How did they do it? (Methods explained simply)
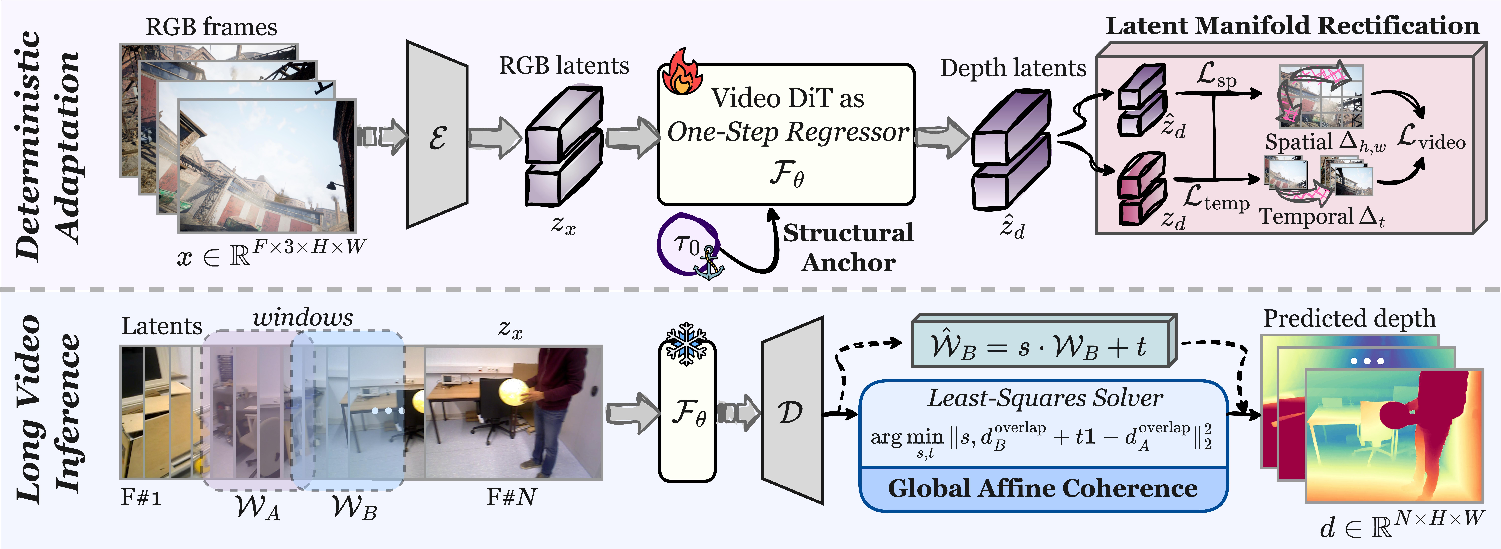
To make this work, the authors build on a large, pre-trained video diffusion model (a type of generative model that’s very good at video structure and motion). Then they modify it so it predicts depth in one step, consistently, instead of “sampling” many times like a typical generator.
They introduce three key ideas:
- Timestep as a structural anchor:
- Analogy: Imagine a camera’s focus knob. Turn it one way and you get a smooth overall picture (stable but less detailed). Turn it the other way and you see crisp details (but it may be less stable). Diffusion models have an internal “timestep” that acts a bit like this knob.
- What they do: Instead of letting this timestep change, they fix it at a sweet spot in the middle. This “anchor” helps the model balance global stability (no wobble or drift) and sharp details (clear edges).
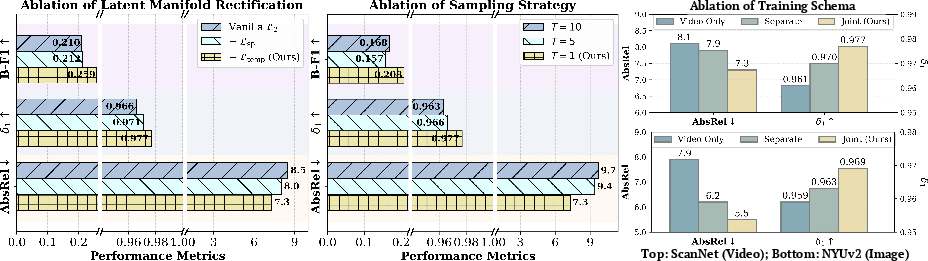
- Latent Manifold Rectification (LMR):
- Problem: When a model tries to average many possible answers (for tricky, blurry, or low-texture areas), it often “smooths out” edges and motion—like smudging a pencil drawing until lines fade. This is called “mean collapse.”
- What they do: They add simple checks that encourage the model to match how edges change in space and how things move over time in its hidden features (the “latent” space). Think of it as asking the model to preserve sharp outlines and consistent motion from frame to frame. These checks don’t add extra heavy parts to the model—they’re just smarter training rules.
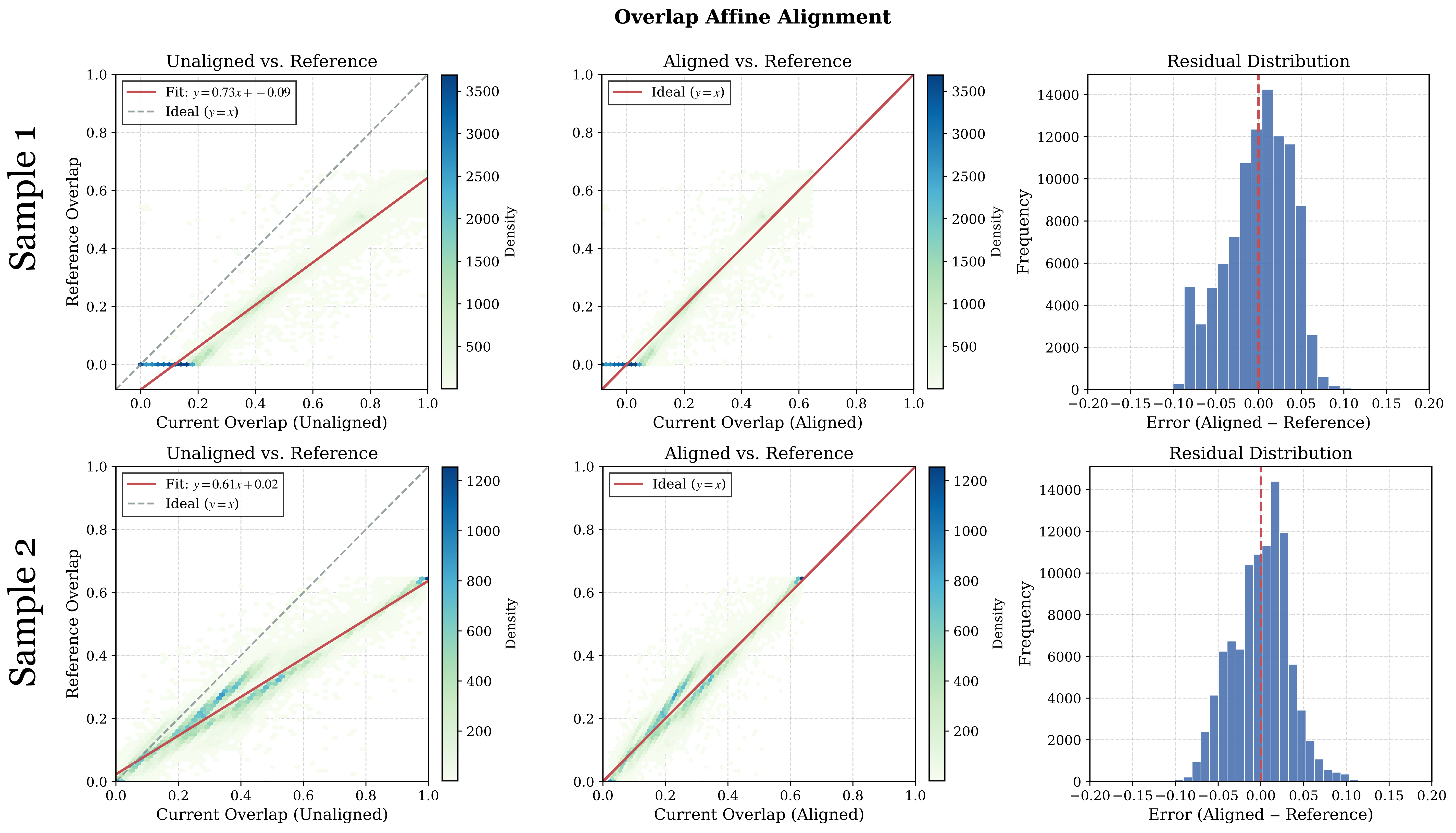
- Global affine coherence for long videos:
- Problem: Long videos must be processed in chunks (windows) to fit in memory. Different chunks can come out at slightly different “scales,” causing flickers or jumps when you stitch them together.
- What they found: In their system, the differences between chunks are mostly simple “scale and shift” changes—like the volume or brightness being a bit off.
- What they do: They fix each new chunk by matching it to the previous one using a quick, math-based adjustment (just scaling and shifting), using the overlapping frames between chunks. This avoids complicated alignment tricks and keeps the whole video consistent.
They also train on both images and videos together. Images help keep per-frame details sharp; videos help keep motion smooth and consistent.
Main results: What did they find and why it’s important?
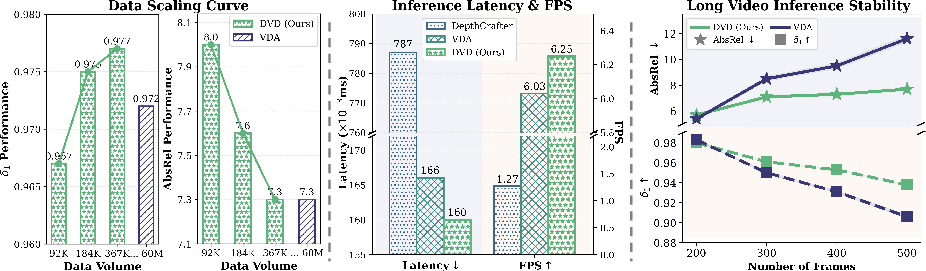
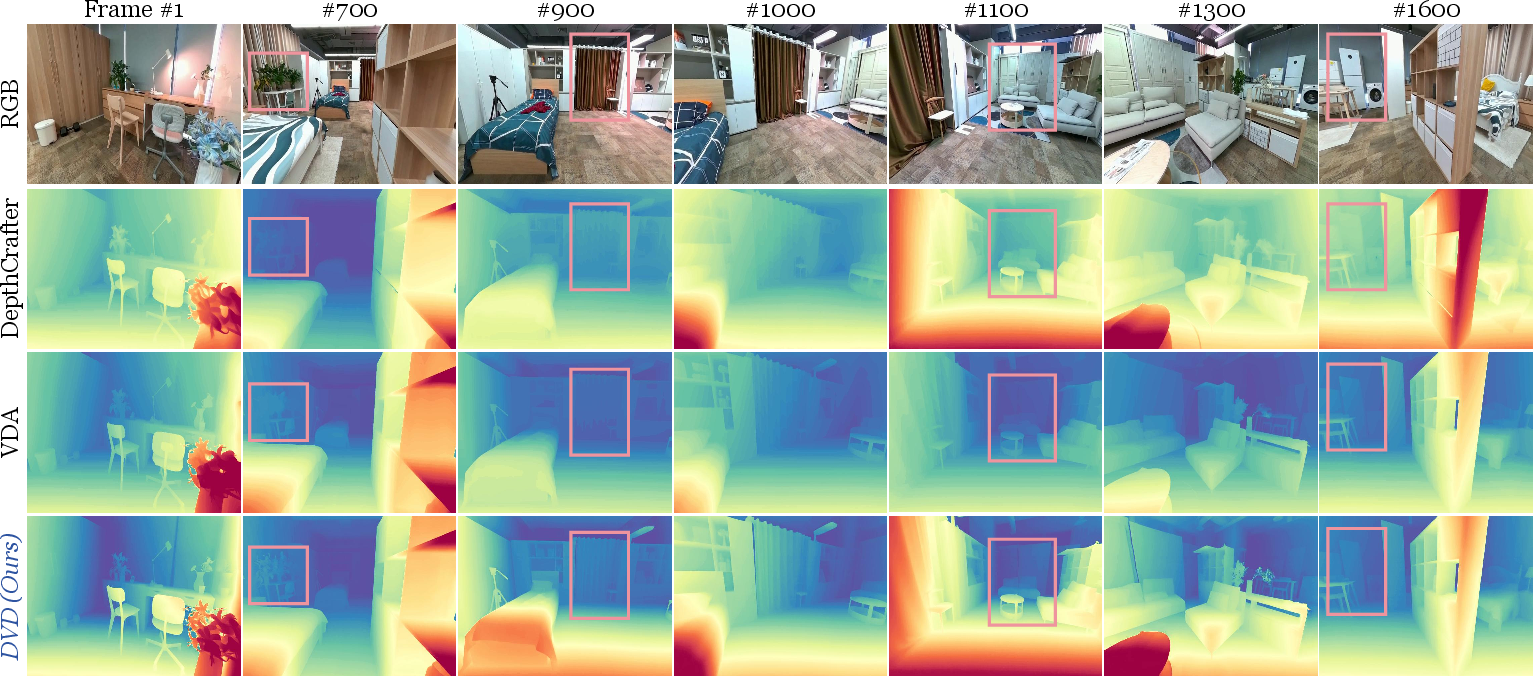
- Better accuracy and stability:
- Across several standard datasets (like KITTI, ScanNet, and Bonn), their method reached or beat state-of-the-art performance in “zero-shot” tests (meaning no extra fine-tuning on those datasets).
- It produced sharper boundaries and more consistent motion than both:
- Generative methods (which can “hallucinate” geometry and drift over time), and
- Traditional direct-prediction methods (which can misread textures or blur as depth edges).
- Much less training data:
- Their system achieved strong results using about 160 times less task-specific training data than a leading baseline. That’s a big deal—collecting and labeling depth data for videos is expensive and slow.
- Fast and practical:
- Because it predicts depth in one step (deterministic regression), it runs with speed similar to efficient direct methods and much faster than multi-step generative sampling.
- It stays stable over long videos thanks to the simple “scale-and-shift” alignment between overlapping chunks.
Why it matters: These results show you can get the best of both worlds—rich understanding from generative models plus the reliability and speed of direct prediction—without huge training sets.
What’s the impact?
- More accessible 3D understanding: With less data and simpler alignment, more teams (including open-source communities) can build solid video depth tools.
- Better long-form applications: Drones, mobile robots, and AR devices often run for minutes or hours. Consistent depth over long videos helps them navigate, map, and interact with the world more safely and smoothly.
- Strong foundation for future 3D/4D tasks: Stable, accurate video depth is a building block for 3D reconstruction, motion analysis, and realistic scene editing.
In short, the paper shows a practical, efficient way to turn a “creative” video model into a dependable depth tool—one that’s sharp, steady, and data-efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances deterministic video depth estimation with generative priors, but leaves several aspects underexplored. The list below highlights concrete gaps to guide follow-up research:
- Theoretical grounding for the “timestep as structural anchor”
- No formal analysis of why a fixed reliably balances global stability and detail across domains; the spectral/SNR explanation remains empirical.
- Unclear whether the observed trade-off holds across different diffusion backbones and VAE designs; no cross-backbone generalization study.
- Fixed, global timestep conditioning
- The method uses a constant (mid-range) for all scenes/videos; no mechanism to adapt per-scene, per-shot, or per-frame, despite strong sensitivity (especially outdoors).
- Open question: can be learned or dynamically scheduled based on scene content, motion, or uncertainty?
- Latent Manifold Rectification (LMR) design assumptions
- LMR uses first-order spatial/temporal finite differences without occlusion awareness; it may penalize legitimate inter-frame changes due to disocclusions or fast motion.
- No evaluation of LMR’s robustness to depth noise (e.g., reflective/transparent surfaces) or to compression artifacts.
- Choice and tuning of LMR weights () are not specified; sensitivity and generalization of these hyperparameters remain unknown.
- Lack of comparison to alternative edge/temporal regularizers (e.g., robust gradients, learned boundary-aware losses, optical-flow–aware losses).
- “Global affine coherence” assumption for long-video stitching
- The claim that inter-window discrepancies are globally affine is empirical; no theoretical justification or clear boundary conditions beyond a brief appendix mention.
- Potential failure modes are underexplored: low-overlap windows, exposure or normalization shifts, highly non-stationary content, or strong non-linearities in the VAE decoder.
- Cumulative drift over very long sequences not studied; current approach aligns only adjacent windows and lacks loop-closure or global consistency enforcement.
- Metric depth and camera intrinsics
- The method focuses on relative depth with affine alignment; no mechanism for metric scale recovery or handling varying intrinsics (focal length, zoom, rolling shutter).
- No evaluation on metric depth benchmarks or integration of intrinsics tokens/priors; unclear how to deploy in robotics/AR where metric accuracy is required.
- VAE choice and cross-modal latent space
- The frozen VAE was trained on RGB; encoding depth into the same latent without adaptation may be suboptimal and introduce non-linear distortions.
- No comparison to depth-aware VAEs, cross-modal VAEs, or decoders calibrated for linear depth intensities; the impact of decoder non-linearities on depth values is not quantified.
- Determinism without uncertainty
- Deterministic outputs eliminate sampling noise but discard uncertainty estimates; no confidence maps or uncertainty calibration are provided.
- Open question: how to quantify and propagate epistemic/aleatoric uncertainty for safety-critical applications?
- Synthetic-to-real generalization and coverage of edge cases
- Training uses only synthetic datasets (TartanAir, Virtual KITTI, Hypersim), risking domain gap; no domain adaptation or self-supervisory strategies are explored.
- Robustness under adverse conditions (night, weather, motion blur, rolling shutter, sensor noise), non-Lambertian materials, and non-rigid dynamics is untested.
- The approach underperforms on Sintel; failure analysis for stylized/CG domains and strategies for style/domain generalization are missing.
- Temporal consistency and dynamic scenes
- Temporal loss assumes simple frame differencing; no explicit handling of independently moving objects, occlusion masks, or motion segmentation.
- Open question: can integrating motion cues (optical flow, scene flow, or learned temporal attention) improve temporal rectification without reintroducing generative stochasticity?
- Data efficiency vs. label dependency
- Despite strong data efficiency, the method still relies on labeled depth for videos; no exploration of self-supervised, semi-supervised, or pseudo-labeling regimes to further reduce labels.
- How does LMR perform with noisy or sparse labels (e.g., from SfM/SLAM or LiDAR projections)?
- Sliding-window design choices
- No ablation of window size, stride, overlap ratio, or blending strategies and their effect on stability and accuracy.
- Real-time streaming constraints (minimal overlap, latency budgets) are not systematically evaluated.
- Scalability and deployment constraints
- The backbone is a 1.3B parameter video DiT; memory/latency on edge devices or at 4K/longer sequences is not characterized.
- No analysis of resolution–speed–accuracy trade-offs, memory footprint, or batching strategies for practical deployments.
- Broader evaluation and benchmarks
- Evaluation focuses on a subset of datasets; coverage of outdoor, indoor, long-horizon, and challenging conditions is incomplete.
- Boundary metrics are reported, but geometric consistency metrics (e.g., scale stability over hours, loop consistency) and downstream task performance (3D reconstruction, tracking, SLAM) are not assessed.
- Integration with geometric priors
- The method does not incorporate multi-view geometry constraints (e.g., epipolar consistency, differentiable warping) that could improve metric consistency and robustness.
- Open question: can deterministic adaptation be combined with geometric self-supervision without sacrificing determinism?
- Generality across backbones and training recipes
- Results are shown with WanV2.1; transferability to other video diffusion backbones (e.g., different DiT/flow-matching architectures) and different VAEs is not tested.
- No scaling-law study on backbone size vs. performance vs. data efficiency.
- Reproducibility details
- Several critical hyperparameters and implementation specifics (e.g., LMR weights, exact selection policy, training schedules, windowing parameters) are not fully specified in the main text.
- The “global affine coherence” measurement procedure and its statistical confidence are not detailed; reproducibility of this property across datasets/backbones remains unclear.
- Failure mode taxonomy
- Although failure cases are mentioned in the appendix, the main paper lacks a systematic categorization (e.g., reflective surfaces, textureless regions, fast motion, severe occlusions) and concrete mitigation strategies.
- Multi-task and multi-modal extensions
- The framework targets depth only; leveraging the same generative priors to jointly predict normals, occlusion masks, or semantics (which can reinforce boundaries and temporal coherence) is not explored.
- Fusion with auxiliary modalities (e.g., IMU, event cameras) for improved temporal stability remains an open avenue.
- Frame-rate and intrinsics variability
- Sensitivity to frame-rate changes, variable frame spacing, and camera intrinsics changes over time is not evaluated; streaming scenarios with variable FPS are unaddressed.
Practical Applications
Immediate Applications
Below are deployable use cases that can leverage the paper’s deterministic, single-pass video depth estimation (DVD) today, given the released code and reported performance.
- Bold, temporally-stable depth mattes for video post-production
- Sectors: media/VFX, creator tools, software
- What it enables: High-quality, flicker-free depth layers for relighting, compositing, depth-of-field, rotoscoping, background replacement across long shots without manual frame-by-frame fixes.
- Potential tools/workflows: NLE/Compositor plugins (Premiere/Resolve/After Effects/Nuke); batch depth pass generator using the provided sliding-window affine alignment; depth-aware LUT pipelines.
- Assumptions/dependencies: Relative depth (not absolute scale); performance depends on GPU; very low-texture or fast motion shots can still challenge overlap-based alignment.
- AR video compositing and occlusion handling for mobile content creation
- Sectors: mobile, AR/VR, social media
- What it enables: More stable AR occlusions and depth-aware effects for videos (not just stills), reducing temporal artifacts common in existing solutions.
- Potential tools/workflows: Mobile SDK for depth-per-video clip; app-side postprocess using the LMR-enhanced maps; integration into TikTok/Snap/Instagram effect pipelines.
- Assumptions/dependencies: On-device acceleration or efficient server-side batching; model size may require distillation/quantization for phones.
- Monocular robot navigation in GPS-denied or cluttered indoor spaces
- Sectors: robotics, logistics, warehousing
- What it enables: Deterministic, flicker-resistant depth streams that improve obstacle detection and local planning from a single RGB camera; long-horizon runs via affine-aligned sliding windows.
- Potential tools/workflows: ROS node publishing depth; fuse with VIO/SLAM for scale recovery; boundary-aware costmaps using sharper edges from LMR.
- Assumptions/dependencies: Relative depth requires scale from wheel odometry/IMU/LiDAR when metric accuracy is needed; domain gaps in extreme lighting or texture-poor environments.
- Drone-based inspection and documentation (relative depth)
- Sectors: AEC (architecture/engineering/construction), energy, utilities, insurance
- What it enables: Stable relative depth for structure inspection videos (facades, towers, lines) to enhance crack detection, clearance assessment, and defect triage with fewer flicker artifacts.
- Potential tools/workflows: Flight logs + video depth + GPS/IMU for scale alignment; temporal outlier suppression via LMR; automated report snapshots keyed by depth anomalies.
- Assumptions/dependencies: Metric scale needs GPS/IMU or fiducials; feature-poor surfaces can degrade overlap-based affine calibration.
- Faster bootstrapping of 3D reconstruction pipelines (SfM/SLAM/GS/NeRF)
- Sectors: mapping, robotics, 3D graphics
- What it enables: Use stable per-frame depth priors to seed or regularize multi-view geometry optimization, reducing convergence time and failure rates.
- Potential tools/workflows: Depth-initialized bundle adjustment; confidence-aware fusion into TSDF/point clouds; better masks/priors for Gaussian Splatting or NeRF training.
- Assumptions/dependencies: Relative depth must be reconciled across views; downstream solver still needed for metric consistency.
- Depth pseudo-labeling to reduce annotation cost
- Sectors: academia, industry R&D, data ops
- What it enables: High-quality pseudo-labels for depth to pretrain/fine-tune task models with 163× less task-specific labeled data than prior baselines.
- Potential tools/workflows: Weak supervision pipelines; active learning with uncertainty heuristics; curriculum training mixing synthetic and pseudo-labeled real footage.
- Assumptions/dependencies: Domain shift management; quality checks at boundaries and low-texture regions.
- Stability-first depth for safety monitoring without metric requirements
- Sectors: retail analytics, security, event operations
- What it enables: People/object distance ranking, occupancy zoning, near/far gating where relative depth suffices; improved temporal stability reduces false triggers.
- Potential tools/workflows: Multi-camera analytics using relative depth maps; time-based trend dashboards; privacy-preserving analytics (no identity tracking).
- Assumptions/dependencies: Not a replacement for calibrated metric sensing when absolute distances are required.
- Video conferencing and streaming: better depth-of-field and background effects
- Sectors: communications, consumer software
- What it enables: Cleaner portrait segmentation and depth-of-field for recorded talks, lectures, and product videos with fewer flicker artifacts across long takes.
- Potential tools/workflows: Postproduction filter pass; creator app feature for “cinematic” depth blur; LMR-enhanced edge refinement.
- Assumptions/dependencies: Throughput considerations for live applications; background consistency still benefits from stable lighting.
- Lightweight long-video alignment workflow (no heavy temporal modules)
- Sectors: software infrastructure, platforms
- What it enables: Parameter-free, least-squares scale-shift alignment for adjacent windows using overlap, making long-run processing simple and robust.
- Potential tools/workflows: Drop-in module to standardize depth scale across segments in media pipelines; canonical re-scaling step before analytics/3D fusion.
- Assumptions/dependencies: Requires sufficient variance in overlap regions; degenerate overlaps (blank walls) can destabilize scale estimation.
- Reproducible research baseline and teaching resource
- Sectors: academia, education
- What it enables: Open, end-to-end pipeline for deterministic adaptation of video diffusion models to depth, enabling labs to reproduce SOTA with modest compute.
- Potential tools/workflows: Coursework labs on deterministic adaptation, LMR ablations, and long-video inference; benchmarks for boundary metrics (B-F1).
- Assumptions/dependencies: Access to pretrained video DiT/3D-VAE backbones and their licenses; GPU availability for class-scale projects.
- Lower-footprint model development policy pilots
- Sectors: policy, sustainability, research governance
- What it enables: Demonstrate reduced energy/data requirements for competitive performance; inform procurement and funding criteria emphasizing data efficiency.
- Potential tools/workflows: Carbon accounting dashboards; reproducibility checklists referencing released training suite; model cards highlighting data savings.
- Assumptions/dependencies: Transparent reporting of training runs and hardware; agreement on evaluation standards across institutions.
Long-Term Applications
These applications are feasible with additional research, engineering, or domain adaptation (e.g., metric scaling, real-time constraints, hardware integration, safety certification).
- Camera-only redundancy and fallback for ADAS/AV perception
- Sectors: automotive, mobility
- What it can become: Deterministic, stable video depth in adverse LiDAR or radar conditions, enabling redundancy for near-field depth understanding and scene layering.
- Path to product: Fuse with VIO/IMU for metric scale and ego-motion; uncertainty modeling; safety case and validation on closed-track/real-world fleets.
- Assumptions/dependencies: Rigorous calibration, ODD-specific tuning, ISO 26262-aligned verification; corner-case robustness in weather/night/glare.
- On-device XR headsets: real-time, video-consistent depth for room-scale mapping
- Sectors: AR/VR/MR, consumer hardware
- What it can become: Smooth occlusions, persistent anchors, and stable scene meshes updated from a monocular RGB camera when depth sensors are absent or degraded.
- Path to product: Model distillation/quantization, 3D-VAE acceleration, temporal tiling on-device; hardware DSP/NPU kernels for DiT blocks.
- Assumptions/dependencies: Power and thermal constraints; motion-to-photon latency limits; privacy and offline operation.
- City-scale monocular mapping and digital twins
- Sectors: smart cities, infrastructure, logistics
- What it can become: Fleet video → depth priors → fused 3D twins, updated frequently at lower cost than full active-sensor fleets.
- Path to product: Global metric alignment using GNSS/IMU/fiducials; map consistency checks; scalable pipelines with automatic affine normalization per segment.
- Assumptions/dependencies: Data governance, privacy compliance, and domain shift handling (weather/seasonal changes).
- Endoscopic and surgical video depth for navigation and guidance
- Sectors: healthcare, medical robotics
- What it can become: Stable intraoperative depth for tissue surface understanding, tool tracking, and AR overlays.
- Path to product: Domain adaptation with medical datasets; metric calibration using known instrument dimensions; regulatory validation (e.g., FDA/CE).
- Assumptions/dependencies: Strict safety, real-time latency, tissue-specific appearance variations.
- Depth-aware manipulation and grasping with sharp boundary cues
- Sectors: industrial automation, warehousing, domestic robotics
- What it can become: Improved grasp point planning on thin or glossy objects using cleaner edges and reduced temporal jitter.
- Path to product: Closed-loop controllers that exploit LMR-enhanced boundaries; fusion with tactile/force sensing for robustness.
- Assumptions/dependencies: Metric scale recovery, robust handling of motion blur and transparent/reflective surfaces.
- Depth-regularized foundation models for 4D scene understanding
- Sectors: AI platforms, simulation
- What it can become: Use deterministic depth priors to supervise or regularize models of optical flow, scene flow, surface normals, and 4D generative models.
- Path to product: Multi-task adaptation of video diffusion backbones; joint objectives combining LMR with geometric constraints.
- Assumptions/dependencies: Training stability in multi-task settings; careful loss balancing and evaluation protocols.
- Broadcast and sports analytics with depth-aware overlays
- Sectors: media, sports tech
- What it can become: Accurate virtual lines, AR graphics, and spatial player analytics with consistent depth across long broadcasts.
- Path to product: Camera calibration for metric scale and field dimensions; realtime inference on OB vans or cloud edges.
- Assumptions/dependencies: Tight latency budgets; variable lighting/weather; lens changes requiring re-calibration.
- Privacy-preserving in-store analytics with depth-only telemetry
- Sectors: retail, security, policy
- What it can become: Anonymized depth fields for counting, zone occupancy, and flow, avoiding identity tracking.
- Path to product: On-prem processing; publish-only aggregate depth-derived statistics; policy frameworks endorsing depth-first analytics.
- Assumptions/dependencies: Clear standards for privacy guarantees; resilience to occlusions and crowded scenes.
- Consumer capture → 3D asset creation pipelines
- Sectors: e-commerce, gaming, virtual production
- What it can become: Turn phone videos into consistent depth sequences that accelerate meshing/GS/NeRF to create product or environment assets.
- Path to product: One-click asset builder apps; automatic scale estimation via known references (checkerboards, AR markers).
- Assumptions/dependencies: Robustness to handheld motion; device diversity; automated quality checks.
- Standardized evaluation policies for long-video depth
- Sectors: standards, policy, research
- What it can become: Benchmarks and procurement criteria emphasizing temporal stability, boundary sharpness, data efficiency, and energy usage.
- Path to product: Open datasets and leaderboards with long-horizon metrics; carbon/compute reporting; reproducibility checklists.
- Assumptions/dependencies: Community buy-in; maintenance and governance of benchmarks.
- ISP and camera firmware integration for depth-aware capture
- Sectors: mobile, imaging
- What it can become: Firmware that outputs a stabilized relative depth stream for downstream camera features (AF/AE/AWB, bokeh, HDR compositing).
- Path to product: Tiny-model distillation; incremental ISP hooks; hardware-friendly DiT variants.
- Assumptions/dependencies: Vendor cooperation; silicon constraints; extensive validation across scenes and lenses.
- Automated inspection and maintenance planning in utilities
- Sectors: energy, transportation
- What it can become: Persistent, depth-derived 3D change maps for infrastructure (e.g., sag in lines, vegetation encroachment) from repeated monocular surveys.
- Path to product: Time-series alignment with affine normalization; alert thresholds on depth deltas; integration with asset management systems.
- Assumptions/dependencies: Calibration and scale from IMU/GNSS; seasonal and lighting variability handling.
Cross-cutting assumptions and dependencies
- Relative depth vs. metric depth: The method is intrinsically affine up to scale and shift. Metric applications require external calibration (IMU, stereo, LiDAR, known object sizes) or additional learning for absolute scaling.
- Overlap alignment stability: The sliding-window affine solver assumes non-degenerate overlaps (sufficient variance). Textureless overlaps can degrade scale estimation.
- Model size and runtime: The reported backbone (~1.3B) may be heavy for edge devices; real-time use cases likely need distillation, quantization, or hardware acceleration.
- Domain shift: Medical, aerial, nighttime, adverse weather, or transparent/reflective surfaces will need domain adaptation and careful validation.
- Licensing and data governance: Use of pretrained backbones (e.g., Wan) and synthetic datasets must respect licensing; policy use cases benefit from transparent compute/data reporting.
- Safety and certification: Automotive/medical/industrial deployments require rigorous verification, uncertainty estimation, monitoring, and fail-safe design beyond raw accuracy.
Glossary
- Absolute relative error (AbsRel): A common depth-estimation metric measuring the average absolute difference between predicted and true depth normalized by the true depth. "We report standard metrics including absolute relative error (AbsRel) and threshold accuracy ()"
- Affine-alignment: A post-processing strategy that aligns predictions between overlapping windows using a global scale and shift. "enables a seamless, affine-alignment sliding-window inference strategy for long-duration videos"
- Aleatoric variance: Data-driven randomness in predictions due to inherent uncertainty, often amplified by stochastic processes. "iterative stochastic sampling introduces aleatoric variance that manifests as geometric hallucinations"
- Boundary F1-Score (B-F1): A metric evaluating the precision-recall trade-off of predicted depth edges to assess boundary sharpness. "boundary F1-Score~(B-F1)"
- Closed-form solution: An exact, non-iterative formula to compute parameters directly. "This yields a deterministic closed-form solution:"
- Conditional expectation: The expected value of a target variable conditioned on the input, to which naive regressors often collapse. "drives the predictor toward the conditional expectation "
- Delta-1 accuracy (δ1): The percentage of pixels where predicted depth is within a fixed multiplicative threshold of ground truth. "threshold accuracy ()"
- Deterministic adaptation: Re-purposing a stochastic generative model to make single-pass, non-random predictions for a specific task. "pioneers the deterministic adaptation of pre-trained video diffusion models"
- Deterministic regressor: A model that outputs fixed predictions for a given input without stochastic sampling. "repurposing video generation models into deterministic regressors"
- Differential constraints: Loss terms that enforce consistency of spatial and temporal derivatives to preserve structure and motion. "enforcing differential constraints to restore sharp boundaries and coherent motion"
- Diffusion priors: Learned generative knowledge embedded in diffusion models about natural images or videos. "spectral bias inherent in the pre-trained diffusion priors"
- Diffusion transformer (DiT): A transformer-based architecture tailored for diffusion modeling in images/videos. "diffusion transformers (DiT)"
- Finite differences: Discrete approximations of derivatives used to compute gradients in space or time. "using finite differences "
- Flow matching: A training paradigm aligning model velocity fields with data transport, used in modern diffusion methods. "continuous flow matching \citep{lipman2022flow}"
- Geometric hallucination: Visually plausible but incorrect depth structure produced by generative methods. "geometric hallucination"
- Global affine coherence: The property that inter-window prediction differences can be modeled by a global scale and shift. "global affine coherence"
- Latent flow: Temporal differences between consecutive latent frames capturing motion dynamics. "Temporal Rectification (Latent Flow)."
- Latent manifold: The lower-dimensional feature space produced by an encoder where RGB and depth representations reside. "we operate within a compressed latent manifold."
- Latent Manifold Rectification (LMR): A supervision technique aligning latent spatial and temporal differentials to prevent over-smoothing. "latent manifold rectification (LMR)"
- Least-squares objective: An optimization objective minimizing the squared error to estimate parameters like scale and shift. "least-squares objective"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method for large models. "fine-tuned via LoRA"
- Mean collapse: The tendency of regression models to average over multiple plausible solutions, losing sharp details. "LMR mitigates mean collapse."
- Ordinary differential equation (ODE): A differential equation describing continuous changes; used to sample trajectories in diffusion. "ordinary differential equation (ODE)"
- Rectified flow (RF): A flow-based diffusion formulation where the model predicts velocity along a linear interpolation between data and noise. "rectified flow (RF)"
- Scale drift: Gradual inconsistency in predicted depth scales across time or windows. "scale drift"
- Scale–shift transformation: A linear transformation using a global multiplicative factor and additive bias to align predictions. "scale-shift transformation"
- Signal-to-noise ratio (SNR): A measure of signal strength relative to noise, controlled by the diffusion timestep during training. "signal-to-noise ratio (SNR)"
- Sinusoidal basis: A fixed set of sine and cosine functions used to embed continuous variables like time. "a fixed sinusoidal basis"
- Single-pass deterministic mapping: Producing a task output in one forward pass without iterative sampling. "executes a single-pass deterministic mapping to predict the depth latent"
- Sliding-window inference: Processing long sequences by moving a window over frames due to memory constraints. "sliding-window inference"
- Spectral bias: A model’s preference to learn low-frequency (smooth) components before high-frequency details. "spectral bias inherent in the pre-trained diffusion priors"
- Spatio-temporal priors: Learned knowledge about spatial structures and their temporal evolution in videos. "rich spatio-temporal priors"
- Stochastic sampling: Randomized iterative generation procedures used by diffusion models. "stochastic sampling introduces temporal uncertainties"
- Structural anchor: A conditioning signal (timestep) that fixes the model’s operating regime between global stability and local detail. "repurposing the diffusion timestep as a structural anchor"
- Temporal coherence: Consistent geometry over time without flicker or drift. "state-of-the-art zero-shot geometric fidelity and temporal coherence"
- Timestep embedding: A vector representation of the diffusion time variable used to condition the network. "Cosine similarity matrix of timestep embeddings (, stride $0.1$)."
- Variational autoencoder (VAE): A generative encoder–decoder model that maps data to and from a compressed latent space. "variational autoencoder (VAE)"
- Velocity field: The vector field indicating the direction and speed of change in latent space along the diffusion path. "predict the velocity field"
- Video foundation models: Large pre-trained video generative models encoding broad world knowledge. "video foundation models"
- World simulators: Foundation models that can synthesize realistic dynamics and 3D-consistent scenes. "effectively function as world simulators"
- Zero-shot: Evaluating on unseen datasets without task-specific fine-tuning. "state-of-the-art zero-shot video depth estimation."
Collections
Sign up for free to add this paper to one or more collections.