- The paper introduces pixel-space diffusion to overcome VAE artifacts, delivering flying-pixel-free depth maps for precise 3D reconstructions.
- The model leverages semantics-prompted diffusion transformers to integrate high-level visual features, enhancing both global structure and fine details.
- Experimental results demonstrate superior zero-shot generalization and edge-aware metrics compared to traditional discriminative and generative methods.
Introduction and Motivation
Monocular depth estimation (MDE) is a critical task for 3D scene understanding, with direct applications in robotics, AR/VR, and autonomous driving. Existing discriminative and generative models have advanced zero-shot generalization and detail recovery, but both paradigms suffer from "flying pixels"—erroneous depth predictions at object boundaries—when depth maps are converted to point clouds. Discriminative models tend to regress mean values at discontinuities, while generative models, typically based on latent diffusion (e.g., Stable Diffusion fine-tuning), introduce artifacts due to VAE compression. The Pixel-Perfect Depth (PPD) framework addresses these limitations by performing diffusion directly in pixel space, eliminating VAE-induced artifacts and enabling the generation of high-fidelity, flying-pixel-free point clouds.

Figure 1: Pixel-Perfect Depth leverages pixel-space diffusion transformers to produce high-quality, flying-pixel-free point clouds, outperforming both discriminative and generative baselines.
Methodology
PPD adopts a flow-matching generative approach, modeling the transformation from Gaussian noise to depth samples via a first-order ODE. The model is trained to predict the velocity field between noisy and clean depth samples, conditioned on the input image. Unlike latent diffusion, the process operates directly on pixel values, allowing precise modeling of depth discontinuities.
To address the optimization challenges of pixel-space diffusion—particularly the difficulty in modeling global semantic structure and fine details—PPD introduces SP-DiT. High-level semantic representations are extracted from pretrained vision foundation models (VFMs) such as DINOv2, VGGT, MAE, and Depth Anything v2. These representations are normalized and fused into the DiT token stream via an MLP and bilinear interpolation, prompting the transformer to preserve global semantic consistency and enhance fine-grained details.
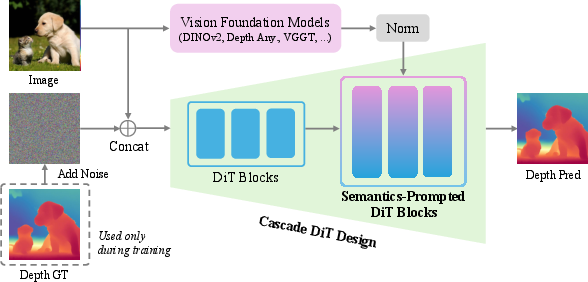
Figure 2: The PPD architecture concatenates the input image with noise for Cascade DiT, while semantic features from VFMs guide the SP-DiT blocks, enabling pixel-space diffusion without VAE.
Cascade DiT Design
PPD employs a coarse-to-fine cascade in the DiT architecture. Early blocks use large patch sizes to efficiently capture global structure with fewer tokens, while later blocks (SP-DiT) operate on smaller patches to refine high-frequency details. This design reduces computational cost and improves both efficiency and accuracy.
Implementation Details
The model uses 24 DiT blocks (12 coarse, 12 fine), with hidden dimension 1024. Depth values are log-normalized and percentile-scaled for robust training across diverse scenes. Training is performed on synthetic datasets (Hypersim, UrbanSyn, UnrealStereo4K, VKITTI, TartanAir) using AdamW, with batch size 4 per GPU.
Experimental Results
Zero-Shot Generalization
PPD demonstrates superior zero-shot performance on five real-world benchmarks (NYUv2, KITTI, ETH3D, ScanNet, DIODE), outperforming all published generative models in AbsRel and δ1 metrics. Notably, PPD achieves these results without relying on pretrained Stable Diffusion priors, instead training from scratch on synthetic data.

Figure 3: PPD preserves fine-grained details and demonstrates robustness on open-world images compared to Depth Anything v2 and MoGe 2.
Edge-Aware Point Cloud Evaluation
PPD introduces an edge-aware Chamfer Distance metric, evaluating point cloud quality at depth discontinuities. On the Hypersim test set, PPD achieves the lowest Chamfer Distance, indicating minimal flying pixels. VAE-based generative models (e.g., Marigold) and discriminative models (e.g., Depth Pro) exhibit significant artifacts, as confirmed by qualitative and quantitative analysis.

Figure 4: PPD produces point clouds with significantly fewer flying pixels in complex scenes compared to Marigold, Depth Anything v2, and Depth Pro.
Ablation Studies
SP-DiT yields up to 78% improvement in AbsRel on NYUv2 over baseline DiT. Cascade DiT further reduces inference time by 30% on RTX 4090 with no loss in accuracy. All tested VFMs boost performance, with Depth Anything v2 encoder providing the best results.

Figure 5: Without SP-DiT, DiT fails to preserve global semantics and fine details; SP-DiT resolves these issues.
Analysis of VAE-Induced Artifacts
Increasing VAE latent dimension (e.g., from 4 to 16 channels) does not eliminate flying pixels at edges, as shown by reconstructing ground truth depth maps with VAEs from SD2 and SD3.5.

Figure 6: VAE compression introduces flying pixels at edges and details, even when reconstructing ground truth depth maps.

Figure 7: Higher latent dimensions in VAEs fail to resolve flying pixel artifacts, confirming the necessity of pixel-space diffusion.
Qualitative Comparisons
PPD outperforms MoGe and REPA in both qualitative and quantitative evaluations, producing cleaner point clouds and more accurate depth at boundaries.

Figure 8: PPD generates point clouds with fewer flying pixels than MoGe, a discriminative baseline.
Efficiency and Lightweight Variants
While PPD's multi-step diffusion is slower than discriminative models, its inference time is comparable to Depth Pro. The lightweight PPD-Small variant achieves substantial speedup with only marginal accuracy loss, making it suitable for real-time applications.
Implications and Future Directions
PPD establishes pixel-space diffusion as a viable alternative to latent diffusion for dense prediction tasks, particularly where geometric fidelity is paramount. The integration of semantic prompts from VFMs into transformer-based diffusion models is shown to be highly effective for both global and local structure preservation. The edge-aware evaluation metric provides a more rigorous assessment of depth estimation quality for downstream 3D applications.
Theoretical implications include the demonstration that VAE compression fundamentally limits the geometric accuracy of generative models for dense prediction. Practically, PPD's architecture is well-suited for deployment in robotics, AR/VR, and content creation pipelines where point cloud quality is critical.
Future work should address temporal consistency for video depth estimation and further accelerate inference via DiT-specific optimizations, such as layer or token-wise caching. Extending SP-DiT to other dense prediction tasks (e.g., surface normals, semantic segmentation) and exploring joint training with metric depth supervision are promising directions.
Conclusion
Pixel-Perfect Depth with Semantics-Prompted Diffusion Transformers presents a robust solution to the flying pixel problem in monocular depth estimation by leveraging pixel-space diffusion and semantic prompting. The framework achieves state-of-the-art performance in both standard and edge-aware evaluations, demonstrating the limitations of VAE-based generative models and the efficacy of transformer-based pixel-space diffusion. The approach is extensible to other dense prediction tasks and sets a new standard for geometric fidelity in depth estimation.