Temporal Straightening for Latent Planning
Abstract: Learning good representations is essential for latent planning with world models. While pretrained visual encoders produce strong semantic visual features, they are not tailored to planning and contain information irrelevant -- or even detrimental -- to planning. Inspired by the perceptual straightening hypothesis in human visual processing, we introduce temporal straightening to improve representation learning for latent planning. Using a curvature regularizer that encourages locally straightened latent trajectories, we jointly learn an encoder and a predictor. We show that reducing curvature this way makes the Euclidean distance in latent space a better proxy for the geodesic distance and improves the conditioning of the planning objective. We demonstrate empirically that temporal straightening makes gradient-based planning more stable and yields significantly higher success rates across a suite of goal-reaching tasks.

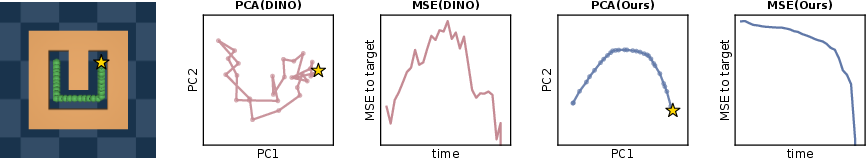


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers to plan better by “seeing” the world in a simpler way. The authors build a world model that turns video frames into a compact code (a “latent space”) and then plans actions in that space to reach a goal. Their key idea, called temporal straightening, makes the hidden paths that the model learns less curvy and more straight, so planning becomes easier, faster, and more reliable.
What questions are the authors trying to answer?
They focus on two simple questions:
- How can we shape a model’s internal “map” of the world so that moving toward a goal looks like a straight, simple path instead of a twisty, confusing one?
- If we do that, will planning with gradients (basically, nudging actions in the right direction step by step) become more stable and succeed more often than before?
How did they do it?
A world model in everyday terms
- Imagine a robot in a maze. It sees images of the maze, and it can take actions (move left, right, up, down).
- Instead of planning directly with raw pixels, the model uses:
- A sensory encoder: turns each image into a short numeric code (the “latent”).
- An action encoder: turns each action into a short code.
- A predictor: guesses the next latent from recent latents and actions.
- Planning then means: simulate ahead in the latent space, and pick the action sequence that gets you closest to the goal latent.
Why not just use a standard visual encoder trained on many images? Those are great for recognizing objects, but they aren’t designed for planning. In planning, you need distances in the code space to match how hard it actually is to move from one state to another (like shortest path length in a maze), not just how similar two images look.
What is “temporal straightening”?
- Picture the robot’s path as a line in the model’s latent space. If that line constantly bends and wiggles, it’s hard to predict and hard to plan along.
- Temporal straightening encourages those latent paths to bend less from one moment to the next, making them locally straighter.
- How do they enforce that? They add a small extra training term that compares the direction of motion between consecutive steps in the latent space. If the direction keeps changing sharply, the model is gently pushed to make it smoother and straighter.
An everyday analogy:
- Euclidean distance is “as the crow flies” (a straight-line distance).
- Geodesic distance is “how far you actually have to walk along roads.”
- In a bad latent space, straight-line distances don’t match how many steps it really takes to get somewhere. After straightening, straight-line distance in the latent space becomes a much better stand-in for the true “number of steps” it takes.
A tiny bit of math intuition (no equations needed)
The authors show that when the model’s transitions are close to “no change unless you act” (meaning each step doesn’t twist the latent much on its own), the planning problem becomes better conditioned. In plain terms, the hill you’re climbing (the loss surface) is smoother and shaped in a way that gradient methods can handle more easily. That means faster and more reliable convergence when optimizing actions.
What did they find?
Here are the main results, explained simply:
- Straighter internal paths: After training with temporal straightening, the model’s hidden paths bend less from one step to the next.
- Better distances: Straight-line distances in the latent space line up much better with true progress toward the goal (like the shortest path in a maze), not just visual similarity.
- Easier optimization: The “landscape” of the planning problem becomes smoother and closer to convex, so gradient-based planners get stuck less often.
- Higher success rates: On several goal-reaching tasks (simple 2D mazes and a pushing task):
- Open-loop planning (plan once, execute) improves by about 20–60%.
- MPC (replanning at each step) improves by about 20–30%.
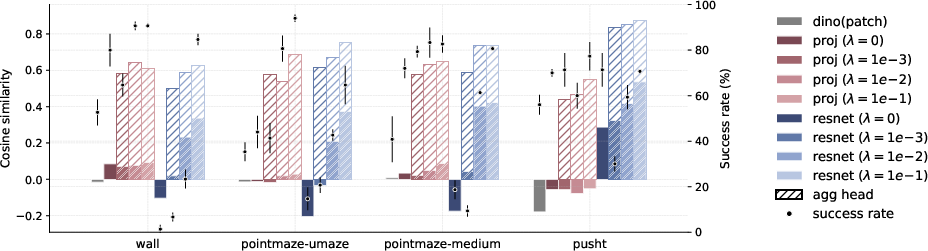
- Works with different encoders: They see gains both when starting from a strong pretrained visual model and when training a new encoder from scratch.
- Not just looks—true dynamics: In a “teleporting” maze (touching a wall moves you across the map), the straightened model plans using the unusual rule correctly, showing it learns how the world changes over time, not just what frames look like.
- Long horizons are still hard, but better: For longer tasks, errors pile up as you predict further ahead, yet straightening still helps compared to the baseline.
Why does this matter?
- Faster, cheaper planning: If distances in a model’s latent space reflect true effort to reach a goal, simple gradient-based planning becomes viable. That can reduce reliance on heavy, search-based methods that are slower and more compute-hungry.
- More reliable control: Robots and agents can plan more directly, following smoother internal routes that better match the real world.
- A general lesson: How you shape a model’s internal representation (its geometry) really matters for planning. Temporal straightening is a simple, general tool to make those representations planning-friendly.
Summary in one sentence
By straightening the model’s hidden paths over time, this paper makes distances in the latent space align with real progress, turning tricky planning problems into smoother ones that gradient methods can solve more easily—leading to faster, more stable, and more successful goal-reaching.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper and could guide future research:
- Theory beyond linear dynamics: extend the conditioning results from linear time-invariant systems to realistic nonlinear predictors by analyzing state/action-dependent Jacobians and higher-order terms.
- Underactuated systems at scale: provide theoretical and empirical analysis for cases with low-dimensional actions (d_a ≪ d), including controllability and conditioning within the reachable subspace across diverse tasks.
- Does straightening actually make A ≈ I? empirically estimate local linearizations (e.g., via Jacobians along trajectories) to validate that the proposed regularizer drives the effective transition matrix toward identity.
- Curvature proxy validity: rigorously quantify when cosine similarity between consecutive latent velocities reliably estimates curvature, especially under variable speeds, non-uniform frame rates, or frame-skipping.
- Sensitivity to temporal discretization: study how frameskip, video frame rate, and action frequency affect curvature estimates and the straightening objective.
- Over-straightening risks: characterize failure modes where strong straightening removes task-relevant curvature (e.g., periodic/rotational dynamics, sharp turns around obstacles), and derive practical guidelines for choosing λ.
- Robust hyperparameterization: perform systematic tuning studies on straightening strength, planner step size, and planning horizon to map the stability/accuracy trade-offs across tasks.
- Geodesic-faithfulness metrics: replace qualitative heatmaps with quantitative measures (e.g., rank correlations or calibration curves) between latent Euclidean distances and true shortest-path/geodesic distances.
- Long-horizon compounding errors: develop mechanisms (e.g., uncertainty-aware rollouts, consistency regularization, trajectory smoothing) that mitigate prediction drift over long horizons where the current method still struggles.
- Generality to stochastic/partially observable settings: assess performance and stability under observation noise, stochastic dynamics, and partial observability, and explore how straightening interacts with belief-state estimation.
- Real-world scalability: evaluate on higher-dimensional, contact-rich robotic domains with real sensor noise and complex visuals to test transfer beyond 2D navigation and PushT.
- Compute and latency benchmarks: report training overhead from straightening and test-time planning speedups compared to CEM/MPPI under matched accuracy budgets.
- Comparative planners: systematically compare gradient-based planning with and without straightening against search-based planners using the same world model and cost, including success vs. compute trade-offs.
- Predictive accuracy vs geometry: quantify how straightening affects pure prediction metrics (e.g., rollout error) and clarify trade-offs between prediction fidelity and planning performance.
- Where to apply straightening: test regularizing both encoded observations and model-predicted latents (imagined rollouts), and investigate curriculum schedules (early vs late straightening).
- Alternative geometric regularizers: explore second-difference penalties, discretized curvature norms, path-length regularization, or learned Riemannian metrics that more directly align latent distances with feasible geodesics.
- Interaction with JEPA/contrastive objectives: ablate combining straightening with JEPA, VICReg, BYOL, and contrastive losses to balance invariance, variance, and geometric regularity.
- Anti-collapse guarantees: analyze when stop-gradient suffices to avoid collapse under the joint prediction + straightening objective, and compare against variance/covariance regularizers.
- Backbone choices and fine-tuning: evaluate fine-tuning pretrained encoders (e.g., DINOv2, V-JEPA) vs. training from scratch under straightening, including robustness to domain shift and data efficiency.
- Spatial vs global representations: more thoroughly study when to keep spatial structure vs. collapse to a global vector, how pooling heads should be designed, and which curvature computation (patch-wise vs aggregated) best predicts planning success.
- Goal-cost design: examine alternatives to latent MSE (e.g., learned energy functions, value estimates, distance-to-go approximations) and how straightening interacts with intermediate-state vs terminal-only costs.
- Non-local and discontinuous transitions: beyond Teleported-PointMaze, systematically evaluate environments with discontinuities (contacts, resets, teleportation) to understand when straightening helps or hinders.
- Obstacles and manifold topology: analyze cases where Euclidean latent distance remains misleading due to topological constraints (e.g., narrow passages), and investigate learning latent shortest-path distances or differentiable planners aligned with topology.
- Planner robustness: test advanced optimizers (e.g., LBFGS, Adam, projected gradient) and constraints (action bounds, safety) to see if straightened latents consistently improve convergence and feasibility.
- Data scaling and sample efficiency: characterize how much offline data is needed to learn straightened latents that generalize, including scaling laws relating curvature, dataset size, and planning success.
- Evaluation breadth: report results across more diverse seeds, datasets, and environment variations (textures, distractors, lighting) to assess robustness and reproducibility of straightening effects.
Practical Applications
Practical Applications of “Temporal Straightening for Latent Planning”
The paper introduces a simple, general-purpose regularizer that straightens latent trajectories during world-model training, making Euclidean distances in latent space more faithful to geodesic progress and significantly improving gradient-based planning (both open-loop and MPC). Below are concrete, real-world applications and workflows that leverage these findings.
Immediate Applications
These can be deployed now with current tooling and compute, especially in controlled environments, simulation-to-real pipelines, or short-horizon tasks.
- Robotics: compute-efficient short-horizon planning and MPC
- Sector: Robotics, Manufacturing, Warehousing, Drones
- Use cases:
- Replace or hybridize sampling-based planners (CEM/MPPI) with gradient-based MPC in mobile navigation, bin-picking, pushing/assembly (PushT-like), inspection drones, and AGVs where horizons are short (e.g., 1–2 s).
- On-robot fine-tuning of encoders with straightening for task-specific environments to reduce compute and latency versus search-based planners.
- Tools/workflows:
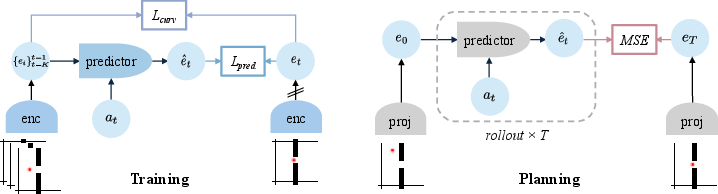
- Train or post-train a JEPA-style world model with the curvature loss L_curv = 1 − cos(v_t, v_{t+1}) on visual latents; use the provided predictor (e.g., ViT with causal masking) and an action encoder; add a learnable pooling head for spatial features.
- Integrate a gradient-based MPC module that optimizes actions through the differentiable dynamics model using terminal and (weighted) intermediate latent distances.
- Monitoring: track cosine similarity of latent velocities and loss-landscape convexity proxies to decide when to fall back to CEM.
- Assumptions/dependencies:
- Requires a differentiable world model and sufficient offline data coverage; performance strongest on short horizons; sim-to-real gap and safety need separate handling; robustness to domain shift is still limited.
- Faster, more stable planning for game AI and simulation agents
- Sector: Gaming, Simulation/Training, AR/VR
- Use cases:
- NPC navigation and skill execution with lower latency and fewer samples.
- Curriculum learning and automated level testing using latent distance maps that better correlate with geodesic distance.
- Tools/workflows:
- Plug-in a straightened-latent world model into existing game engines; use the distance-heatmap diagnostic to verify that latent distances match shortest-path distances.
- Assumptions/dependencies:
- Works best when game visuals are moderately structured and training trajectories cover reachable states; long-horizon compound error remains a constraint.
- Representation diagnostics and dataset curation
- Sector: ML/AI R&D, Academia
- Use cases:
- Use cosine similarity between latent velocities as a metric to select encoders, stop training, or decide pooling/aggregation strategies.
- Generate distance heatmaps to validate that latent distances align with ground-truth geodesics in known environments (e.g., A* grid mazes).
- Tools/workflows:
- “Curvature Monitor” to track average cosine similarity; “Latent Distance Heatmapper” to visualize target-to-state distances; PCA trajectory visualization to debug curvature.
- Assumptions/dependencies:
- Requires access to environment rollouts (reward-free is sufficient); metrics should be computed on representative trajectories to avoid bias.
- Hybrid planner deployment for embedded/edge robotics
- Sector: Edge AI, Consumer Robotics
- Use cases:
- On-device gradient-based planning for robotic vacuums, camera-guided home assistants, and micro-UAVs with fallback to sample-based search if curvature degrades (out-of-distribution events).
- Tools/workflows:
- Export straightened world models to ONNX/TensorRT; low-channel spatial latents (e.g., 14×14×8) for compute-constrained platforms; adaptive planner switching based on curvature thresholds.
- Assumptions/dependencies:
- Requires careful model compression and real-time validation; safety and fail-safes must be layered on top.
- Improved reward shaping and curriculum design in RL-from-observation
- Sector: Robotics, Education/Training Simulators
- Use cases:
- Use straightened latent Euclidean distance as a proxy reward for goal-reaching without dense manual shaping; design curricula by scheduling targets by latent distance.
- Tools/workflows:
- Train RL agents with the latent terminal-distance cost; visualize latent distance contours to select curricula.
- Assumptions/dependencies:
- Assumes the learned latent distance is aligned with geodesic progress in the operating regime; still susceptible to model errors on long horizons.
- Open-source training recipe/library components
- Sector: Software/ML tooling
- Use cases:
- Drop-in regularizer for PyTorch/JAX world-model repos; reference implementations for the pooling head and curvature loss; wrappers for DINOv2 features + projector or ResNet-from-scratch setups.
- Tools/workflows:
- “TemporalStraightening” package: curvature loss module, pooling head variants, JEPA-style predictor with causal attention, MPC with gradient descent.
- Assumptions/dependencies:
- Requires basic JEPA-style training and stop-gradient anti-collapse; tuning λ (regularization strength) by environment is recommended.
- Academic benchmarking and theory replication
- Sector: Academia
- Use cases:
- Extend the linear analysis of Hessian conditioning to controlled nonlinear cases; standardized benchmarks for loss-landscape convexity, controllability Gramian proxies, and planning success under varying curvature.
- Tools/workflows:
- Reproduce Wall/PointMaze/PushT pipelines; systematically vary λ, feature dimensionality, and pooling strategies.
- Assumptions/dependencies:
- Accessible simulators and logging of Jacobian norms; reproducible seed management.
Long-Term Applications
These require further research for robustness, long-horizon reliability, and safety/regulatory compliance, or scaling to large, real-world datasets and heterogeneous sensors.
- Autonomous driving: short-horizon learned planners with straightened latents
- Sector: Transportation
- Use cases:
- Local, reactive maneuver planning (e.g., lane changes, merges, obstacle avoidance) with learned world models where latent distances correlate with progress-to-goal and constraint margins.
- Potential products:
- On-vehicle gradient-based planner module interfacing with BEV encoders and predictive dynamics; curvature-aware safety monitors that trigger classical planners when ill-conditioning is detected.
- Assumptions/dependencies:
- Requires multi-sensor, safety-critical validation; robust handling of rare events and domain shift; certified failover mechanisms.
- Generalist household and industrial robots
- Sector: Robotics, Industrial Automation
- Use cases:
- Multi-task manipulation and navigation with instruction-conditioned world models; straightening to stabilize planning across diverse appliances/tools and layouts.
- Potential products:
- Foundation-model-based world models trained with straightening on large-scale, real-world egocentric video; multi-modal straightened latents (vision + proprioception + language).
- Assumptions/dependencies:
- Scaling JEPA-style training to large, noisy corpora; long-horizon compounding error mitigation (hierarchical planning, re-planning, uncertainty estimation).
- Surgical and medical robotics visual servoing
- Sector: Healthcare
- Use cases:
- Precise instrument navigation and tissue manipulation using straightened visual latents for stable gradient-based control under limited horizons.
- Potential products:
- FDA-grade planning stack with curvature-aware monitors and real-time model checking; simulation-to-OR transfer pipelines.
- Assumptions/dependencies:
- Strict safety/regulatory requirements; domain-specific data, simulation fidelity, and interpretability; robust OOD detection and fail-safes.
- Energy and industrial process control with high-dimensional sensing
- Sector: Energy, Process Industries
- Use cases:
- Use straightening on learned state representations from high-dimensional sensor arrays (e.g., infrared, hyperspectral, acoustic) to improve gradient-based setpoint optimization and MPC stability.
- Potential products:
- Latent planners embedded in digital twins; curvature-regularized representation layers for plant-wide controllers.
- Assumptions/dependencies:
- Demonstrating benefits beyond vision; handling partial observability, constraints, and long horizons; integration with legacy control stacks.
- Finance and operations research analogs
- Sector: Finance, Logistics
- Use cases:
- Apply temporal straightening to learned latent states of time series (portfolios, inventory levels) to condition decision optimization (e.g., rebalancing, routing).
- Potential products:
- Curvature-regularized state estimators for differentiable simulators (market microstructure, supply-chain) with improved gradient-based policy search.
- Assumptions/dependencies:
- Establishing that “straightened” dynamics improve conditioning in non-visual, stochastic domains; rigorous backtesting and risk controls.
- Safety and certification frameworks for learned planners
- Sector: Policy, Standards
- Use cases:
- Define metrics and minimum thresholds for curvature/conditioning as part of deployment checklists for learned control; mandate hybrid (gradient + sampling) planners with curvature-based switching.
- Potential products:
- Standards for logging curvature, controllability proxies, and loss-landscape diagnostics; conformance-testing toolkits.
- Assumptions/dependencies:
- Community consensus on metrics; empirical correlations with safety outcomes; regulatory adoption.
- Multi-modal instruction-following agents with straightened latents
- Sector: Software, Education, Consumer AI
- Use cases:
- Agents that map language instructions and visual context into a straightened latent where gradient-based planning is stable (e.g., AR wayfinding, household task guidance).
- Potential products:
- On-device assistants that plan in straightened latent spaces with intermittent re-planning and uncertainty-aware stopping.
- Assumptions/dependencies:
- Robust language grounding in the latent space; scalable multi-modal training; privacy-preserving on-device inference.
- Scalable toolchain for large-scale straightened JEPA pretraining
- Sector: ML Infrastructure
- Use cases:
- Pretrain world models with explicit straightening at web-scale for robotics/control transfer.
- Potential products:
- Training stacks with curvature-aware schedulers (adaptive λ), distributed monitoring of curvature metrics, and automatic pooling-head selection.
- Assumptions/dependencies:
- Compute and data availability; effective anti-collapse at scale; evaluation suites for long-horizon reliability.
Cross-Cutting Assumptions and Dependencies
- World-model accuracy and coverage: The benefits hinge on a differentiable predictor trained on sufficiently representative (often reward-free) data.
- Horizon length: Gains are strongest for short to medium horizons; long-horizon rollouts remain challenging due to compounding prediction error (mitigate via MPC, hierarchical planning, or uncertainty-aware re-planning).
- Encoder design: Spatially preserved latents with a learnable pooling head often outperform global-only features; low channel counts (e.g., 8) are sufficient and compute-friendly.
- Stability safeguards: Use stop-gradient to prevent collapse; monitor latent curvature; maintain hybrid planner fallbacks.
- Safety and compliance: Safety-critical domains require additional assurance layers, OOD detection, formal verification where possible, and robust failover strategies.
Glossary
- Action encoder: A network that maps actions into a latent embedding used by the dynamics model. "Each action is mapped to a latent action embedding via"
- Causal attention mask: An attention constraint that allows tokens to attend only to past context in time. "We apply a temporal causal attention mask so tokens at time attend only to frames "
- CEM (Cross-Entropy Method): A sampling-based stochastic optimizer commonly used for trajectory optimization in planning. "rely on search-based methods such as CEM~\citep{rubinstein1997optimization} or MPPI~\citep{mppi}"
- Collapse (representation collapse): A failure mode where embeddings become constant, destroying information. "degenerate solutions in which all latent representations collapse to a constant."
- Condition number: The ratio of largest to smallest (nonzero) singular values of a matrix; it governs optimization difficulty and convergence. "effective condition number $\kappa_{\mathrm{eff}(H):=\sigma_{\max}(H)/\sigma_{\min}^+(H)$"
- Controllable subspace: The set of states reachable by some sequence of inputs under the given dynamics. "may be singular outside the controllable subspace."
- Controllability Gramian: A matrix that quantifies how inputs influence state reachability over a finite horizon. "be the finite-horizon controllability Gramian"
- Cosine similarity: The cosine of the angle between vectors; here used to align consecutive latent velocities. "maximize their cosine similarity"
- Curvature regularizer: A loss term penalizing bends in latent trajectories to make them straighter for planning. "Using a curvature regularizer that encourages locally straightened latent trajectories"
- DINO-WM: A world-modeling approach that plans in a frozen pretrained DINO feature space. "DINO-WM~\citep{dinowm} trains task-agnostic predictors and plans directly in frozen DINOv2~\citep{oquab2024dinov2} feature space."
- DINOv2: A self-supervised visual encoder providing strong pretrained features. "While DINOv2 features provide high-quality visual representations, they are not optimized for planning"
- ε-straight transition: A linear transition whose state matrix is within ε of identity, implying near-straight latent evolution. "we call -straight"
- Frameskip: Executing multiple environment steps per model step to shorten effective planning horizon. "we use a frameskip of 5 for all environments."
- Geodesic distance: The shortest path distance along feasible transitions/manifolds rather than straight-line in embedding space. "a better proxy for the geodesic distance"
- Gradient-based planning: Optimizing action sequences by differentiating through the learned dynamics and cost. "temporal straightening makes gradient-based planning more stable"
- Hessian: The matrix of second derivatives of the planning objective; its spectrum controls convergence. "the planning Hessian is"
- Imaginary rollouts: Model-predicted trajectories in latent space used to evaluate and optimize actions. "enable imaginary rollouts for action optimization."
- InfoNCE loss: A contrastive objective that pulls positives together and pushes negatives apart. "through InfoNCE loss~\citep{radford2021learningtransferablevisualmodels}."
- Jacobians: Matrices of first derivatives of vector-valued functions; key for analyzing nonlinear dynamics. "controlling products of state-dependent Jacobians"
- JEPA (Joint-Embedding Predictive Architecture): A predictive self-supervised paradigm that learns representations by forecasting embeddings. "Joint-Embedding Predictive Architecture (JEPA) emerges as a promising paradigm for world models"
- Latent planning: Planning in a learned embedding space rather than pixel/state space. "representation learning for latent planning"
- Latent trajectories: Sequences of latent embeddings over time as the agent evolves. "locally straightened latent trajectories"
- Linear dynamical system: A system whose state update is an affine-linear function of the current state and action. "the effect of straightening in the case of a linear dynamical system"
- Model Predictive Control (MPC): A closed-loop scheme that replans over a receding horizon at every step. "Closed-loop MPC replans at every step"
- MPPI (Model Predictive Path Integral): A sampling-based control algorithm for trajectory optimization under uncertainty. "CEM~\citep{rubinstein1997optimization} or MPPI~\citep{mppi}"
- Open-loop planning: Optimizing a fixed action sequence without replanning during execution. "Open-loop planning optimizes a length- action sequence using the MSE between the terminal embedding and the target embedding as the planning cost."
- Perceptual straightening hypothesis: The idea that biological vision maps videos to straighter internal trajectories. "Inspired by the perceptual straightening hypothesis in human vision"
- Pooling head: A learnable module that aggregates spatial feature maps into a global embedding. "use a learnable pooling head to aggregate spatial features"
- Proprioceptive states: Internal sensor readings (e.g., joint angles) used alongside visual inputs. "proprioceptive states "
- Stop-gradient: An operation that blocks gradient flow through a branch to prevent collapse or trivial solutions. "where denotes the stop-gradient operation"
- Temporal Contrastive Learning: A framework that learns embeddings reflecting temporal relations by contrasting nearby vs. distant frames. "Temporal Contrastive Learning~\citep{sermanet2018timecontrastivenetworksselfsupervisedlearning, tclr, eysenbach2024inference, yang2025memory} is also a popular paradigm for learning representations"
- Temporal straightening: Regularizing latent dynamics to align consecutive velocities and straighten trajectories over time. "we introduce temporal straightening to improve representation learning for latent planning."
- ViT (Vision Transformer): A transformer architecture for images, used here as a dynamics predictor. "We use a ViT~\citep{dosovitskiy2021vit} as the dynamics predictor ."
- VQ-VAE: An autoencoder with vector quantized discrete latents for reconstruction and interpretability. "we train a VQ-VAE~\citep{Oord2017NeuralDR} decoder with a reconstruction loss"
- World model: A learned model of environment dynamics that predicts future states in a latent space for planning. "Our goal is to learn a world model that maps observations to a latent space"
Collections
Sign up for free to add this paper to one or more collections.