Reference Architecture of a Quantum-Centric Supercomputer
Abstract: Quantum computers have demonstrated utility in simulating quantum systems beyond brute-force classical approaches. As the community builds on these demonstrations to explore using quantum computing for applied research, algorithms and workflows have emerged that require leveraging both quantum computers and classical high-performance computing (HPC) systems to scale applications, especially in chemistry and materials, beyond what either system can simulate alone. Today, these disparate systems operate in isolation, forcing users to manually orchestrate workloads, coordinate job scheduling, and transfer data between systems -- a cumbersome process that hinders productivity and severely limits rapid algorithmic exploration. These challenges motivate the need for flexible and high-performance Quantum-Centric Supercomputing (QCSC) systems that integrate Quantum Processing Units (QPUs), Graphics Processing Units (GPUs), and Central Processing Units (CPUs) to accelerate discovery of such algorithms across applications. These systems will be co-designed across quantum and classical HPC infrastructure, middleware, and application layers to accelerate the adoption of quantum computing for solving critical computational problems. We envision QCSC evolution through three distinct phases: (1) quantum systems as specialized compute offload engines within existing HPC complexes; (2) heterogeneous quantum and classical HPC systems coupled through advanced middleware, enabling seamless execution of hybrid quantum-classical algorithms; and (3) fully co-designed heterogeneous quantum-HPC systems for hybrid computational workflows. This article presents a reference architecture and roadmap for these QCSC systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explains how to build “quantum‑centric supercomputers” — big computing systems where regular computers (CPUs), graphics chips (GPUs), and quantum chips (QPUs) work together as one team. Today, quantum computers are powerful in special ways but still small and noisy. Classical supercomputers are huge and reliable, but some problems are just too complex for them alone. The paper shows a plan (a “reference architecture” and roadmap) for connecting these two worlds so scientists can solve hard problems in chemistry, materials, optimization, and more, faster and better.
What were the big questions?
The authors focus on a few simple questions:
- How can we combine quantum computers and supercomputers so they feel like one system instead of two separate machines?
- What kinds of problems need this combo approach?
- What pieces (hardware, software, networks) are needed to make the combo fast, reliable, and easy to use?
- How should this evolve over time as quantum chips get better?
How did the authors approach it?
Think of this like planning a new city: you don’t just build roads; you plan neighborhoods, traffic lights, and services so everything works together. The authors:
- Collected real examples where quantum and classical computing already work together (like simulating molecules for drug discovery).
- Noticed common patterns (for example, when fast connections are needed, and when they aren’t).
- Designed a “reference architecture” — a layered plan that says what goes where and how the parts talk.
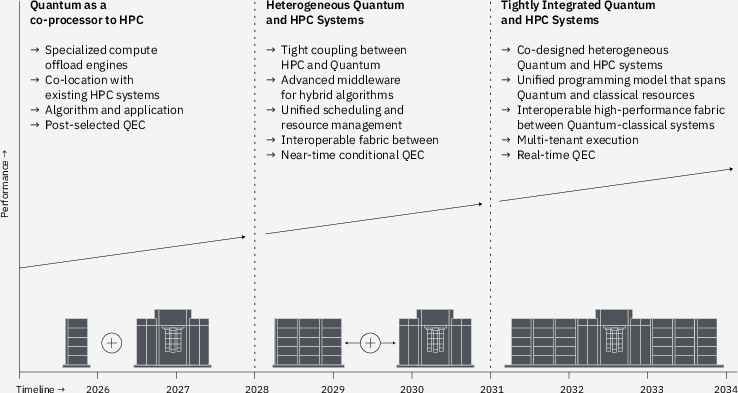
- Laid out a three‑phase roadmap from simple connections today to deep, seamless integration tomorrow.
The three phases (like building up a team)
Here’s how they say the system should evolve:
- Phase 1: Quantum as an “offload” helper. The supercomputer does most work; it sends a special sub‑task to the quantum chip and gets results back (similar to how a CPU sends graphics work to a GPU).
- Phase 2: Tight teamwork. Better software connects quantum and classical machines so they can pass tasks back and forth smoothly during a run.
- Phase 3: Fully co‑designed system. Hardware and software are built from the ground up to work together, with a single way to program both sides.
Timing and distance: how tightly do they need to work together?
The paper defines interaction “speeds” and how close machines should be:
- Batch‑time: Results can wait seconds to hours. Machines can be far apart (like over the cloud). Good for simple hand‑offs.
- Near‑time: Results come back in microseconds to seconds. Machines should be near each other with faster links.
- Real‑time: Replies in microseconds. Needs very fast, local control electronics next to the quantum chip.
In short: the more back‑and‑forth you need during a job, the closer and faster the connection must be.
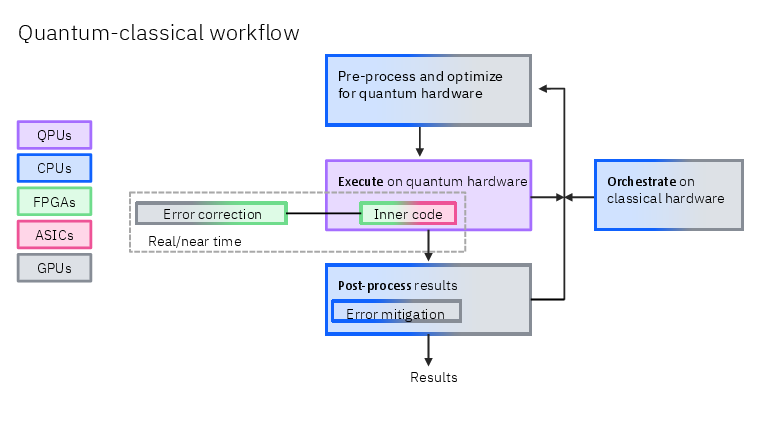
The architecture layers (like floors of a building)
To keep things organized, the system is split into layers:
- Hardware Infrastructure: The machines themselves — quantum processors (QPUs), nearby “scale‑up” classical nodes (CPUs/GPUs/accelerators close to the QPU with fast links), and larger “scale‑out” supercomputers (possibly in the cloud).
- System Orchestration: The “traffic controllers” that schedule jobs and move data between quantum and classical parts.
- Application Middleware: Toolkits and libraries that make it easier to write hybrid programs (for example, error‑mitigation tools).
- Applications: The actual science and engineering workloads (chemistry, optimization, machine learning, simulations).
They also include cross‑cutting concerns like cloud software, monitoring, and security to keep everything safe and manageable.
Real examples (what these systems will actually do)
The paper highlights several use cases to show why integration matters:
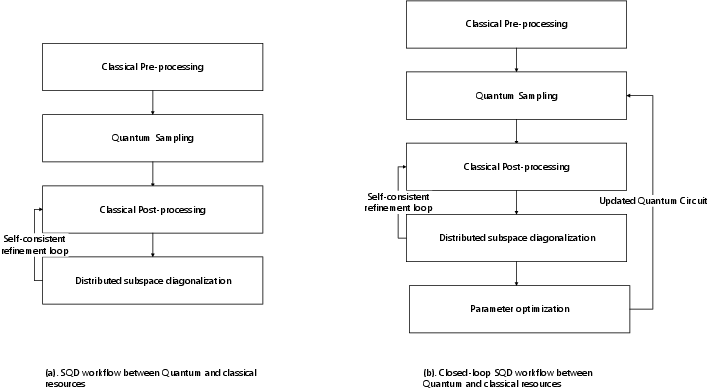
- Chemistry and materials (Sample‑based Quantum Diagonalization, “SQD”): The quantum chip produces samples; the supercomputer crunches them to find ground‑state energies of molecules. This can run in batch mode if you just hand results back once, or become a loop where classical results improve the next quantum run (which benefits from co‑location and faster links).
- Optimization (like routing or scheduling): Quantum sampling can point classical search toward better solutions, speeding up tough problems.
- Quantum machine learning: Quantum chips can create special features or probability distributions that are hard for classical machines, while GPUs handle the heavy training loops.
- Solving differential equations: Quantum methods may help with very hard physics problems (like turbulent flow), combined with classical solvers.
- Error mitigation and error correction: Classical GPUs/CPUs run large tensor‑network or “Pauli propagation” analyses to clean up noisy quantum results, sometimes needing lots of data and fast connections. Future “outer code” error correction may run on nearby GPUs, while extremely fast “inner code” corrections stay next to the QPU in custom electronics.
What did they find or propose?
This is mainly a design and roadmap paper. The key proposals are:
- A clear, three‑phase path from loose to tight integration between quantum and classical computing.
- A layered system design that separates concerns and speeds up development.
- A “Quantum Systems API” boundary so software can control quantum hardware without caring about the fine details inside.
- Two kinds of classical resources:
- Scale‑up (near the QPU, with low‑latency, high‑bandwidth links) for fast, iterative tasks like certain error‑correction research.
- Scale‑out (bigger clusters, possibly remote) for large classical workloads like diagonalization, simulations, and data processing.
- Matching the connection speed and distance to the job: simple jobs can run with cloud‑connected systems; tight feedback loops gain a lot from co‑located machines and faster networks.
Why this is important:
- It turns today’s clumsy, manual back‑and‑forth (submit a quantum job, wait, download data, re‑submit) into smooth, automated workflows.
- It lets each part do what it’s best at: quantum chips for hard quantum sampling/structure, GPUs/CPUs for heavy math and optimization.
- It creates a common plan different teams can follow, speeding progress toward useful, real‑world results.
Why does this matter?
- Faster science: Chemists, material scientists, and engineers can explore bigger molecules and more complex materials sooner.
- Better solutions: Hybrid methods can attack optimization and AI problems that stump classical machines alone.
- More reliable quantum results: Error‑mitigation and future error‑correction pipelines become practical when backed by HPC.
- Practical progress: Instead of waiting for perfect, fault‑tolerant quantum computers, we can get useful work done now by combining today’s quantum chips with strong classical support.
Takeaway: the potential impact
The paper’s message is simple: quantum and classical computing shouldn’t live in separate worlds. By planning how they plug together — from hardware and networks to software and workflows — we can unlock problems that neither could handle alone. This roadmap gives researchers, engineers, and organizations a clear way to build and evolve quantum‑centric supercomputers, speeding up discovery in chemistry, materials, optimization, AI, and beyond.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps the paper leaves unresolved, framed to guide future research and engineering work:
- Quantitative targets by phase: No explicit latency, bandwidth, throughput, utilization, or scale targets per roadmap phase (e.g., near-time latency budgets, minimum GB/s between tiers, acceptable QPU idle fraction), nor measurable KPIs to judge phase readiness.
- Quantum Systems API (QSA) specification: Missing a formal interface definition covering circuit formats (incl. mid-circuit measurement and dynamic control), streaming/partial results, control-flow semantics, error/exception handling, configuration management, calibration access, data schemas (bitstrings, syndromes, metadata), synchronization semantics, and portability across vendors.
- Orchestration/QRMI details: Absent design for co-scheduling across QPUs/CPUs/GPUs (priority, fairness, reservations, advance booking, preemption, backfilling), multi-tenant coordination across independent schedulers (HPC and cloud QPU), deadline-aware scheduling for near-time loops, and checkpoint/restart semantics for hybrid jobs.
- Data movement protocols: No end-to-end spec for transporting large measurement/syndrome streams (RDMA/gRPC/QUIC), zero-copy and memory registration strategies, GPU-direct paths, batching/windowing policies, compression/coding for bitstrings and syndromes, and standardized file/stream formats with embedded provenance.
- Closed-loop across organizational boundaries: Lacks mechanisms to realize iterative quantum-classical loops when the QPU is multi-tenant cloud (e.g., SLAs, advance reservations, “priority windows,” queue draining, temporal isolation) and how to enforce them in practice.
- Security and compliance model: No threat model or concrete controls for inter-tier links (encryption at rest/in flight, HSM/KMS, attestation, confidential computing/TEE use), access control and auditing, data sovereignty/geofencing, and compliance mappings (e.g., pharma IP, export controls).
- Performance modeling and capacity planning: No analytic/simulation models to predict end-to-end runtime, bottlenecks, queuing effects, sampling cost vs classical compute trade-offs, or energy use (roofline-style models for hybrid execution).
- Reliability and resilience: Missing fault models and recovery strategies across QPU/HPC/network (retry/idempotency, exactly-once processing, partial result reconciliation, hybrid checkpointing, consistency guarantees for iterative loops).
- Network architecture: No concrete topology and transport guidance (Ultra Ethernet vs ROCE vs custom), congestion control, time synchronization (PTP/IEEE 1588) for deterministic near-time behavior, NIC offloads, GPU-direct RDMA to QPU gateways, and isolation/firewalling patterns.
- Storage and data lifecycle: Unspecified storage tiers and I/O targets (burst buffers, object vs POSIX, IOPS/throughput targets), streaming vs archival paths, retention/versioning, and reproducible packaging of raw measurements and derived datasets.
- Middleware stack and Tensor Compute Graph: Lacks a defined execution model and IRs spanning QPU/GPU/CPU (e.g., QIR, OpenQASM 3 integration), dynamic control-flow support, automatic partitioning/fusion policies, backpressure handling, and fault-tolerant graph execution across tiers.
- Unified programming model: No language/DSL or API design that composes quantum kernels, classical HPC kernels, and data movement; missing type and effect systems for probabilistic outputs, debug/profiling tooling, unit/integration testing patterns for hybrid workflows.
- Benchmarking and reproducibility: Absent standardized QCSC benchmark suite, datasets, and KPIs across use cases (SQD, error mitigation, QAOA, QML, PDEs), with clear classical baselines and end-to-end accounting (including queueing and data transfer).
- Error mitigation design space: No criteria to select among TEM, Pauli propagation, and hybrid variants; missing adaptive resource-allocation policies (sampling vs classical compute), bias/variance control with uncertainty quantification, and triggers for transitioning from batch-time to near-time mitigation.
- Outer-code QEC research interfaces: Unspecified streaming API and data schemas for syndrome/ancilla telemetry, target data rates, acceptable decode latency envelopes, batching strategies, and integration of trained decoders into production control paths.
- Mapping decoders to accelerators: No kernels/algorithms/throughput targets for GPU/TPU/NPU implementations, memory footprints, training pipelines (datasets, labels, augmentation), and portability across accelerator vendors.
- Transition path to fault tolerance: Unclear partitioning boundary and interfaces between real-time inner codes and near-time outer codes; how research decoders progress toward tighter latency loops; validation and certification steps for integration into control stacks.
- SQD and closed-loop SQD at scale: Missing guidance on when to iterate QPU sampling vs expand classical subspace; required data volumes per iteration, convergence criteria vs compute budget, and co-scheduling policies to prevent QPU or GPU idle time.
- Optimization (QAOA/HUBO): No concrete problem classes/sizes and connectivity constraints where QCSC provides advantage; practical encoding pipelines (HUBO→circuits), warm-start strategies using HPC, and standardized evaluation on industrial datasets.
- PDE workflows: Unspecified coupling strategies between quantum solvers and classical solvers (operator splitting, preconditioners), stability/error control in hybrid time-stepping, mesh adaptivity and data exchange costs, and verification/validation protocols.
- Quantum ML workflows: Missing designs for hybrid training loops (synchronous vs asynchronous), latency tolerance windows, data locality and privacy (including federated or DP options), integration with PyTorch/JAX/XLA, and metrics to isolate quantum representation advantage from classical effects.
- Calibration and experiment scheduling: No policies/APIs to interleave calibrations with production hybrid jobs, impact on long-running closed loops, and predictive maintenance to minimize disruption.
- Observability and telemetry: Absent end-to-end tracing and time-correlated metrics across QPU/control/HPC/network/storage, standardized event schemas, anomaly detection hooks, and SLA reporting for hybrid pipelines.
- Facility engineering constraints: No treatment of power/cooling/vibration/EMI interactions when co-locating cryogenic QPUs with dense GPU racks, nor design patterns for physical layout and isolation.
- Economic and policy models: Lacks TCO and capacity-planning models, cost-aware scheduling, cloud bursting strategies, and economic mechanisms (pricing/reservations) to enable time-coupled multi-tenant closed-loop workloads.
- Standardization and governance: No roadmap for standard bodies/consortia to converge on QSA, measurement/syndrome data formats, calibration telemetry, and provenance standards to ensure cross-vendor interoperability.
Practical Applications
Immediate Applications
The paper’s findings and reference architecture already enable several deployable workflows that integrate quantum resources with classical HPC. The following applications are actionable now, subject to the stated dependencies.
- Electronic structure calculations via sample-based quantum diagonalization (SQD) and variants (SKQD, SqDRIFT)
- Sectors: healthcare (drug discovery), materials/energy (catalysts, battery materials), chemicals
- What to deploy: hybrid pipelines where QPUs generate bitstring samples and HPC nodes perform subspace projection and diagonalization; fragmentation/embedding workflows that assign hardest fragments to the QPU and the remainder to classical solvers
- Tools/products/workflows:
- “Quantum-accelerated electronic structure” services that bundle QPU access, Hamiltonian mapping, sample management, and GPU/CPU diagonalization
- Workflow orchestration integrated with Slurm/LSF/Kubernetes, data staging, and provenance logging
- Error-mitigation post-processing (e.g., configuration recovery, measurement mitigation)
- Assumptions/dependencies: access to cloud or on-prem QPU; circuit sizes up to ~100 qubits with shallow-to-moderate depth; reliable mapping from Hamiltonians to qubits; sufficient HPC capacity for diagonalization; noise-mitigation pipelines in place
- Closed-loop hybrid electronic structure (iterative parameter refinement with co-located QPU+HPC)
- Sectors: healthcare, materials, chemicals (research labs with on-prem resources)
- What to deploy: co-scheduled loops where classical diagonalization updates state parameters that inform the next quantum sampling round
- Tools/products/workflows:
- Quantum-aware co-schedulers that reserve QPU and thousands of HPC nodes concurrently
- Low-latency/high-throughput data paths within a campus/facility (ROCE, Ultra Ethernet, NVQLink)
- Assumptions/dependencies: physical co-location and organizational control over both job queues; network bandwidth/latency sufficient to avoid idle QPU or HPC cycles; data governance for sensitive R&D
- Error-mitigation pipelines embedded in HPC (tensor-network error mitigation, Pauli propagation)
- Sectors: cross-cutting (chemistry, optimization, QML, materials), quantum hardware R&D
- What to deploy: batch-time workflows where quantum execution is paired with GPU/CPU-based noise inversion and light-cone analysis to reduce sampling demands
- Tools/products/workflows:
- GPU-accelerated tensor-network libraries and Pauli-propagation analyzers integrated with experiment orchestration
- “Mitigation-as-a-service” for research groups, providing calibrated, dataset-specific noise inversion
- Assumptions/dependencies: stable noise characterization; scalable classical compute; fast movement of large measurement datasets; potential controlled bias acceptance
- Open-loop quantum error correction (QEC) R&D with offline decoders
- Sectors: hardware vendors, national labs, academia
- What to deploy: high-bandwidth measurement capture to scale-out CPUs/GPUs/TPUs for decoder development without real-time feedback constraints
- Tools/products/workflows:
- “Outer decoder workbench”: syndrome data lakes, decoder benchmarking suites, AI-based decoder training pipelines
- Data connectors from quantum readout to HPC storage/compute
- Assumptions/dependencies: high-throughput links from QPU to HPC; data retention policies; reproducible experiments for training/validation
- Hybrid optimization pilots (QAOA/HUBO with classical warm starts and iterative refinement)
- Sectors: logistics/supply chain, finance (portfolio selection), manufacturing scheduling, energy grid operations (pilots)
- What to deploy: pilot-scale hybrids where quantum samples guide or restart classical solvers on structured instances
- Tools/products/workflows:
- QUBO/HUBO encoders, warm-start frameworks, iterative classical–quantum loops with performance telemetry against strong classical baselines
- Assumptions/dependencies: problem formulations with exploitable structure; moderate-sized instances; careful benchmarking to avoid overclaiming advantage; integration with existing optimization stacks
- Quantum-enhanced kernels and feature maps (QML prototypes)
- Sectors: finance (anomaly detection), cybersecurity, materials informatics, scientific ML
- What to deploy: prototype classifiers/regressors using quantum kernels/feature maps plugged into classical training loops on GPUs/CPUs
- Tools/products/workflows:
- Python SDKs integrating quantum kernels with scikit-learn/PyTorch; hyperparameter search on HPC
- Assumptions/dependencies: small to medium datasets and circuit widths; robust baselining vs. classical kernels; reproducible training with noise-aware embeddings
- Quantum–HPC orchestration and governance in IT operations
- Sectors: enterprise IT, cloud/HPC providers, national facilities
- What to deploy: production-grade connectors that treat QPUs as managed accelerators within HPC schedulers and CI/CD workflows
- Tools/products/workflows:
- Quantum Systems API (QSA) adapters; runtime management interfaces; audit and compliance pipelines; secrets/data vaults; observability dashboards
- Assumptions/dependencies: vendor API stability; role-based access control; data sovereignty policies; training for operators
- Education and workforce development using QCSC patterns
- Sectors: academia, workforce programs, corporate training
- What to deploy: lab courses and mini-testbeds featuring batch-time SQD, mitigation pipelines, and decoder experimentation
- Tools/products/workflows:
- Simulated QPU backends plus limited real QPU credits; reference notebooks; reproducible datasets for decoding/mitigation
- Assumptions/dependencies: program funding; access to shared HPC and quantum credits; curricular materials aligned with realistic workflows
- Near-term policy and procurement actions for quantum–HPC pilots
- Sectors: government, funding agencies, research consortia, standards bodies
- What to deploy: co-located pilot procurements; data/provenance frameworks for hybrid experiments; initial standardization efforts around device/runtime APIs
- Tools/products/workflows:
- Templates for co-scheduling SLAs, data residency rules, and cross-facility workload governance
- Assumptions/dependencies: cross-agency coordination; security classifications; sustainability targets for power and cooling
Long-Term Applications
As QPU scale/quality improves and the architecture advances through Phase 2 (tightly coupled middleware) and Phase 3 (co-designed systems), the following applications become feasible at scale.
- Co-designed quantum-centric supercomputers (Phase 2/3)
- Sectors: national supercomputing centers, cloud/HPC providers, large industrial R&D
- What to enable: unified programming models and middleware for seamless, dynamic partitioning across CPUs/GPUs/Accelerators/QPUs with near-time orchestration
- Tools/products/workflows:
- Standardized QSA and quantum runtime management interfaces; near-time interconnects (ROCE, Ultra Ethernet, NVQLink) with QoS for hybrid loops; quantum-aware schedulers with dynamic resource allocation
- Assumptions/dependencies: industry standards, interoperable APIs, sustained investment in co-location and networking, mature monitoring and security for hybrid stacks
- Fault-tolerant Hamiltonian simulation (e.g., QPE) for high-accuracy chemistry and materials
- Sectors: pharma, specialty chemicals, energy materials, catalysts
- What to enable: routine ground/excited-state energies and reaction pathways beyond classical reach
- Tools/products/workflows:
- End-to-end FT pipelines coupling QPE with classical embedding/fragmentation and HPC post-processing; verified numerics and uncertainty quantification
- Assumptions/dependencies: logical qubits with low error rates, scalable error correction, high circuit depth; substantial HPC for pre/post-processing
- Embedded/fragment-based large-system quantum chemistry at industrial scale
- Sectors: drug discovery (proteins/active sites), heterogeneous catalysis, surface chemistry
- What to enable: automated decomposition of massive systems; QPUs target the hardest fragments while HPC assembles and refines global solutions
- Tools/products/workflows:
- Workflow engines that co-schedule fragment evaluation across many QPU shots and large GPU clusters; adaptive embedding strategies informed by classical–quantum feedback
- Assumptions/dependencies: larger/quieter QPUs; robust error mitigation or FT; scalable diagonalization and tensor workflows
- Industrial-scale combinatorial optimization integrated into enterprise software
- Sectors: logistics (routing, fleet), airlines (crew and slots), energy (unit commitment), finance (risk-aware portfolios)
- What to enable: hybrid solvers that deliver consistent speed/quality improvements on structured, large instances
- Tools/products/workflows:
- HUBO-native encoders; domain-specific warm starts; near-time quantum sampling with classical metaheuristics; APIs embedded into ERP/APS systems
- Assumptions/dependencies: proven advantage versus evolving classical heuristics; stability under operational constraints; governance for model risk
- Quantum–classical PDE and simulation workflows (e.g., Navier–Stokes turbulence, plasma)
- Sectors: aerospace/automotive (CFD), fusion energy, weather/climate modeling
- What to enable: quantum solvers augmenting classical solvers in regimes otherwise out of reach, leveraging polynomial-scaling algorithms for noisy dynamics
- Tools/products/workflows:
- Hybrid solvers that alternate quantum subroutines with GPU-accelerated numerics; near-time orchestration to reduce idle time
- Assumptions/dependencies: maturing quantum algorithms for PDEs with verified accuracy/stability; increased circuit widths/depths; domain validation pipelines
- Scalable quantum machine learning integrated into AI factories
- Sectors: cross-industry AI (materials discovery, cybersecurity analytics, scientific ML)
- What to enable: quantum-enhanced representations and generative models that integrate into large-scale training on GPU/accelerator clusters
- Tools/products/workflows:
- Quantum feature pipelines orchestrated alongside classical training; data-centric noise-aware embeddings; joint hyperparameter optimization
- Assumptions/dependencies: representations that offer non-classical advantage; robust generalization under noise; seamless integration with MLOps
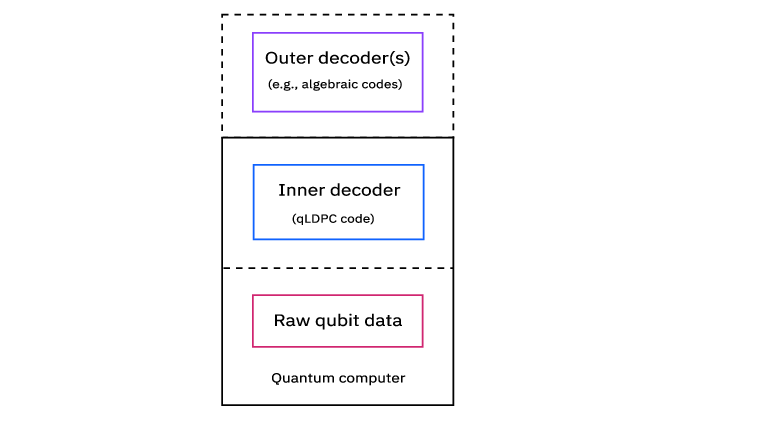
- Hierarchical fault-tolerant QEC with near-time outer-code decoding
- Sectors: quantum cloud providers, hardware manufacturers, national facilities
- What to enable: outer code inference on scale-up GPUs/ASICs with 100 μs–1 ms latency, layered over inner hardware-adapted codes (e.g., qLDPC)
- Tools/products/workflows:
- Decoder accelerators; standardized syndrome streaming; mixed AI/graphical decoders; co-scheduling between inner and outer layers
- Assumptions/dependencies: ultra-low-latency links and deterministic timing; power/cooling for dense classical accelerators; robust standards for syndrome formats
- Near-time, adaptive error mitigation and noise-aware compilation
- Sectors: cross-cutting (chemistry, optimization, QML)
- What to enable: real-time adjustment of circuit parameters, measurement bases, and mitigation weights to maximize throughput/accuracy
- Tools/products/workflows:
- Runtime services that fuse Pauli-propagation insights with experiment control; compiler passes that target light-cone structures and dynamic noise maps
- Assumptions/dependencies: sufficiently stable hardware noise models; control interfaces exposed through QSA; reliable performance telemetry
- Standards, compliance, and cross-border governance for hybrid quantum–HPC
- Sectors: policy/standards bodies, government, multinational R&D
- What to enable: interoperable APIs and SLAs for hybrid jobs, data sovereignty frameworks, carbon accounting for QCSC facilities
- Tools/products/workflows:
- Formal specifications for device/runtime APIs; certification programs for hybrid workload security; green-compute reporting for quantum–HPC data centers
- Assumptions/dependencies: stakeholder consensus; regulatory harmonization; auditable observability stacks
- Societal and daily-life impacts (indirect but material)
- Sectors: public health, transportation, energy, environment
- What to enable: faster drug discovery cycles; improved battery/catalyst materials; more efficient logistics; better grid stability; enhanced weather/climate forecasts
- Tools/products/workflows:
- Industry-embedded hybrid services (e.g., “quantum materials screening” for R&D; “quantum-assisted dispatch” for logistics)
- Assumptions/dependencies: translation of research-grade advantages into production reliability; validation against real-world KPIs; ethical and secure data practices
These applications map directly to the paper’s phased roadmap: immediate benefits arise from batch-time hybrids with loose-to-moderate coupling; mid-to-long-term gains depend on tighter middleware, near-time interconnects, co-scheduling, and ultimately fault-tolerant quantum computation co-designed with classical HPC.
Glossary
- Active qubit reset: A control operation that quickly reinitializes a qubit to a known state during or between circuit executions. "active qubit reset within the latency budget imposed by qubit coherence times."
- AlphaQubit: A machine-learning–based quantum error-correction decoder framework used for high-accuracy decoding. "AI-based decoders (e.g. AlphaQubit~\cite{Bausch2024HighAccuracyDecoding})"
- Batch-time: A loose-coupling computation mode where quantum and classical tasks run with relaxed latency (seconds to hours) via queued jobs. "Batch-time: Computational interactions where quantum and classical systems operate with relaxed latency requirements (seconds to hours)."
- Co-designed: Jointly designed across quantum and classical components to optimize overall performance and integration. "These systems will be co-designed across quantum and classical HPC infrastructure, middleware, and application layers"
- Coherence time: The duration over which a qubit maintains its quantum state without significant decoherence. "respond within the coherence time of the quantum processor"
- Concatenated quantum codes: A hierarchical coding scheme where quantum codes are nested to suppress logical errors. "builds on the original theory of concatenated quantum codes"
- Configuration recovery: A classical post-processing step that adjusts noisy samples to satisfy conserved quantities (e.g., particle number). "Samples with incorrect hamming weights due to noise undergo configuration recovery to restore the correct hamming weight"
- Coupled-cluster (CCSD): A high-accuracy method in quantum chemistry for electron correlation, here cited as a classical baseline. "traditional classical full configuration interaction methods (e.g., CCSD, HF)"
- Density matrix renormalization group (DMRG): A tensor-network technique for simulating quantum many-body systems, often used in classical substeps. "Tensor network methods, density matrix renormalization group (DMRG) calculations, coupled-cluster calculations, and Monte Carlos sampling are examples of simulation work"
- Diagonalization: Solving for eigenvalues/eigenvectors of a matrix; used to obtain energy spectra in a chosen subspace. "subspace projection and diagonalization of the Hamiltonian in the selected determinant basis"
- Dynamic circuits: Quantum circuits that include mid-circuit measurements and classically conditioned operations. "large-scale dynamic circuits with mid-circuit measurement and conditional logic"
- Embedding techniques (computational chemistry): Methods that partition a system into fragments to mix high- and low-accuracy treatments efficiently. "embedding techniques from computational chemistry decompose a complex system into smaller fragments"
- Error detection checks: Procedures that flag errors (without necessarily correcting them) using structured measurements across space and time. "error detection checks like spacetime codes"
- Error mitigation: Techniques that reduce the impact of noise on computed observables without full error correction. "quantum error mitigation~\cite{Temme_2017,Li_2017}"
- Fault-tolerant: A regime where error-correction enables reliable long computations despite physical noise. "before the maturity of fault tolerant quantum error correction"
- Feature maps: Transformations that encode classical data into (quantum) feature spaces for learning tasks. "feature maps, kernels, and generative models"
- Generative models: Models that learn to sample from complex distributions, here implemented with quantum resources. "feature maps, kernels, and generative models"
- Gross code framework: An IBM-proposed architecture/framework for implementing scalable qLDPC-style quantum error-correcting codes. "IBM architectural proposals such as the Gross code framework and related implementations"
- Hamiltonian: An operator representing the total energy of a system; central to quantum simulation and eigenvalue problems. "estimation of low-energy spectra of many-body Hamiltonians"
- Hamming weight: The number of 1s in a bitstring; used to enforce electron number constraints in sampled configurations. "Partitions the samples into two groups based on hamming weight"
- HHL (Harrow–Hassidim–Lloyd algorithm): A quantum algorithm for solving systems of linear equations. "Quantum algorithms using HHL to solve discretized PDE/ODE"
- Hierarchical error correction: A layered approach to QEC with fast inner codes and slower, inference-rich outer codes. "Fault-tolerant quantum computing will likely rely on hierarchical error correction"
- Higher-order binary optimization (HUBO): Optimization problems with polynomial (beyond quadratic) objective terms. "higher-order binary optimization (HUBO)"
- Inner code: The fast, hardware-adapted QEC layer that stabilizes physical qubits in real time. "The inner code operates directly on physical qubits and must respond on hardware timescales."
- Iterative refinement: A looped process that improves solutions by repeatedly updating parameters based on intermediate results. "and iterative refinement~\cite{bravyi2020variational}"
- Kernel methods (quantum): Algorithms that use quantum-constructed kernels for classification or regression. "results from quantum kernel methods provide evidence that quantum representations can capture structure"
- Krylov (Sample-based Krylov Quantum Diagonalization, SKQD): An SQD variant that constructs structured subspaces for improved ground-state estimation. "Sample-based Krylov Quantum Diagonalization (SKQD)"
- Light cone (of observable sensitivity): The circuit region influencing a given observable, used to focus mitigation resources efficiently. "defining a shaded light cone of observable sensitivity"
- Low-density parity-check (LDPC) codes (quantum LDPC/qLDPC): Sparse-graph quantum error-correcting codes enabling scalable decoding. "quantum low-density parity check (LDPC) codes"
- Magic state production: The preparation of special non-stabilizer states required for universal fault-tolerant quantum computation. "magic state production"
- Mid-circuit measurement: Measuring qubits during a circuit, enabling conditional operations and dynamic feedback. "mid-circuit measurement"
- Multi-objective optimization: Optimization with several objectives that may trade off against each other. "extensions to multi-objective optimization"
- Multi-product formulas: Techniques combining multiple approximate evolutions to suppress Trotter error in time evolution. "multi-product formulas"
- Navier Stokes equation: Fundamental PDEs governing fluid flow; used here as a target for quantum-enhanced solvers. "solving the Navier Stokes equation for simulating turbulent flow"
- Near-time: A moderate-latency (tens of microseconds to seconds) interaction mode supporting iterative quantum–classical loops. "Near-time: Computational interactions where quantum and classical systems exchange data with moderate latency (tens of microseconds to seconds)"
- NVQLink: A proposed low-latency interconnect for tight coupling between quantum systems and nearby accelerators. "NVQLink~\cite{nvqlink}"
- Outer code: The higher-level QEC layer operating on logical qubits, enabling deeper inference with looser latency constraints. "an outer code can then operate on the logical qubits produced by the inner layer"
- Pauli noise channels: Noise processes expressible as stochastic Pauli operations; useful for mitigation and analysis. "forward-propagate near-identity Pauli noise channels"
- Pauli propagation: Classical techniques that track how Pauli operators (or errors) evolve through a circuit to estimate observables. "Pauli propagation methods"
- Quadratic unconstrained binary optimization (QUBO): A standard formulation for mapping combinatorial problems to binary quadratic forms. "quadratic unconstrained binary optimization (QUBO)"
- Quantum Approximate Optimization Algorithm (QAOA): A variational quantum algorithm for combinatorial optimization. "Quantum optimization algorithms such as QAOA~\cite{farhi2014qaoa}"
- Quantum-Centric Supercomputing (QCSC): An architecture that tightly integrates QPUs with HPC resources through co-designed stacks. "Quantum-Centric Supercomputing (QCSC) systems~\cite{qcsc} represent this convergence"
- Quantum embedding techniques: Methods mapping data or problems into quantum representations that enhance learnability or performance. "recent advances in quantum embedding techniques are expanding the space of representations"
- Quantum error correction (QEC): Methods that protect quantum information using redundancy and decoding to correct errors. "quantum error correction~\cite{PhysRevA.52.R2493,PhysRevLett.77.793,Terhal_2015}"
- Quantum phase estimation (QPE): A quantum algorithm for estimating eigenvalues (phases) of unitary operators. "quantum phase estimation (QPE) is a standard approach for this problem"
- Quantum Processing Unit (QPU): A quantum processor that executes quantum circuits and measurements. "Quantum Processing Units (QPUs)"
- Quantum Systems API (QSA): A programmatic interface exposing quantum system capabilities to higher layers of the stack. "Quantum Systems API (QSA)"
- Real-time: A microsecond-scale, tightly coupled mode requiring deterministic response within qubit coherence times. "Real-time: Computational interactions where quantum and classical systems exchange data with minimal latency (typically microseconds)"
- Representation learning: Learning useful data representations; here, possibly enhanced by quantum feature constructions. "representation learning"
- RDMA over Converged Ethernet (ROCE): A low-latency, high-throughput network protocol enabling direct memory access across systems. "RDMA over Converged Ethernet (ROCE)~\cite{ibta_roce_2025}"
- Sample-based Krylov Quantum Diagonalization (SKQD): See Krylov entry; a structured SQD extension used for impurity models. "Sample-based Krylov Quantum Diagonalization (SKQD)~\cite{yu2025quantum}"
- Sample-based Quantum Diagonalization (SQD): A hybrid algorithm using quantum sampling and classical diagonalization for ground-state estimation. "Sample-based Quantum Diagonalization (SQD) is one such approach"
- Slater determinants: Antisymmetrized many-electron basis states used in electronic structure theory. "bitstring samples representing electronic configurations (Slater determinants)."
- Spacetime checks: Error-detection constructs spanning both spatial and temporal circuit dimensions to catch correlated errors. "spacetime checks"
- Spatial coupling: The degree of physical proximity and bandwidth between quantum and classical resources. "Spatial coupling: The degree of physical proximity and interconnection bandwidth required between quantum and classical computing resources."
- Stabilizer rounds: Repeated measurements of stabilizers in QEC cycles to extract error syndromes. "static stabilizer rounds"
- Subspace projection: Restricting a problem to a lower-dimensional subspace spanned by selected basis vectors (e.g., determinants). "Executes subspace projection and diagonalization of the Hamiltonian"
- Tensor Compute Graph: A computational graph representation used to embed classical post-processing steps in tensorized workflows. "embedded inside a Tensor Compute Graph (see Section \ref{sec:middleware})"
- Tensor-network contractions: The process of contracting interconnected tensors, central to tensor-network simulations and mitigation. "Tensor-network contractions, Pauli-propagation analysis, and large-scale sampling require substantial CPU and GPU capability"
- Tensor-network error mitigation (TEM): A mitigation approach using tensor-network computations to invert or compensate circuit noise. "tensor-network error mitigation (TEM)"
- Transpiling: Transforming quantum circuits into hardware-native gates and topology while optimizing for constraints. "transpiling and optimizing the circuits"
- Trotterization error: Approximation error from splitting time evolution into discrete steps in product-formula simulations. "suppress Trotterization error in digital time-evolution simulations"
- Ultra Ethernet: A next-generation high-performance networking architecture targeting low latency and high bandwidth. "Ultra Ethernet~\cite{hoefler2025ultraethernetsdesignprinciples}"
- Vlasov equation: A nonlinear PDE describing plasma dynamics; a target for quantum algorithmic linearization. "using quantum algorithms for linearizing the Vlasov equation"
- Warm-start strategies: Initializing optimization with informed guesses to accelerate convergence in hybrid algorithms. "warmâstart strategies~\cite{egger2021warmstart}"
Collections
Sign up for free to add this paper to one or more collections.