- The paper provides an exact closed-form analysis demonstrating that the U-shaped retrieval and gradient profile is an inherent result of causal masking and residual paths.
- It details a precise mathematical framework using Cesàro matrices that decouples positional effects from training data and positional encodings.
- Empirical validations on models like GPT-2 and Qwen2 confirm the theory, revealing persistent middle-context suppression despite optimizer adjustments.
Introduction
The paper "Lost in the Middle at Birth: An Exact Theory of Transformer Position Bias" (2603.10123) provides a rigorous analytical framework for the ubiquitous "Lost in the Middle" position bias observed in decoder-only transformer architectures. The author establishes that the characteristic U-shaped retrieval and gradient profile, where information at the beginning and end of the sequence is accessible but the center is severely suppressed, emerges intrinsically from the interaction of causal masking and residual connections—entirely independent of training, data, or positional encodings such as RoPE. This result decisively refutes the prevailing view that the U-shape is merely an artifact induced primarily by learned Softmax parameters or the specifics of positional encodings.
Structural Decomposition
The analysis strips the transformer to its essential position-routing ingredients: the lower-triangular causal attention mask and the identity-based residual path. The principal tool is the Cesàro matrix (M), which, via uniform causal averaging, precisely captures the routing topology at initialization (before any data-dependent learning). With attention-only, gradient signals and information compound combinatorially toward the first tokens (primacy); with the addition of a direct residual stream, the final token always has an undiluted route to the output (recency).
Mathematical Results
Let N=(1−α)I+αM be the residual mixing matrix. The explicit closed-form equation for the influence of input position j on the output at position L after H layers is given in the discrete case, and in the large-L continuum limit, yields:
ρH(M)(x)=(H−1)!1(ln1/x)H−1
for pure causal masking (primacy tail), and
ρH(N)(x)=(1−α)Hδ(1−x)+r=1∑H(rH)αr(1−α)H−r(r−1)!1(lnx1)r−1
for causal masking with residual connections, where δ is the Dirac delta (recency anchor).
Empirical Validation Across Architectures
The theory is validated empirically using randomly initialized Qwen2-0.5B and classic GPT-2 models. The measured input-output Jacobian norm across positions recapitulates the predicted U-shaped topology: a logarithmically diverging primacy effect, a sharp O(1) recency anchor, and a factorial dead zone in the center. Quantitatively, the Spearman correlation between theory and measured Jacobian is ρ=0.99, and Wasserstein distance W=0.02.
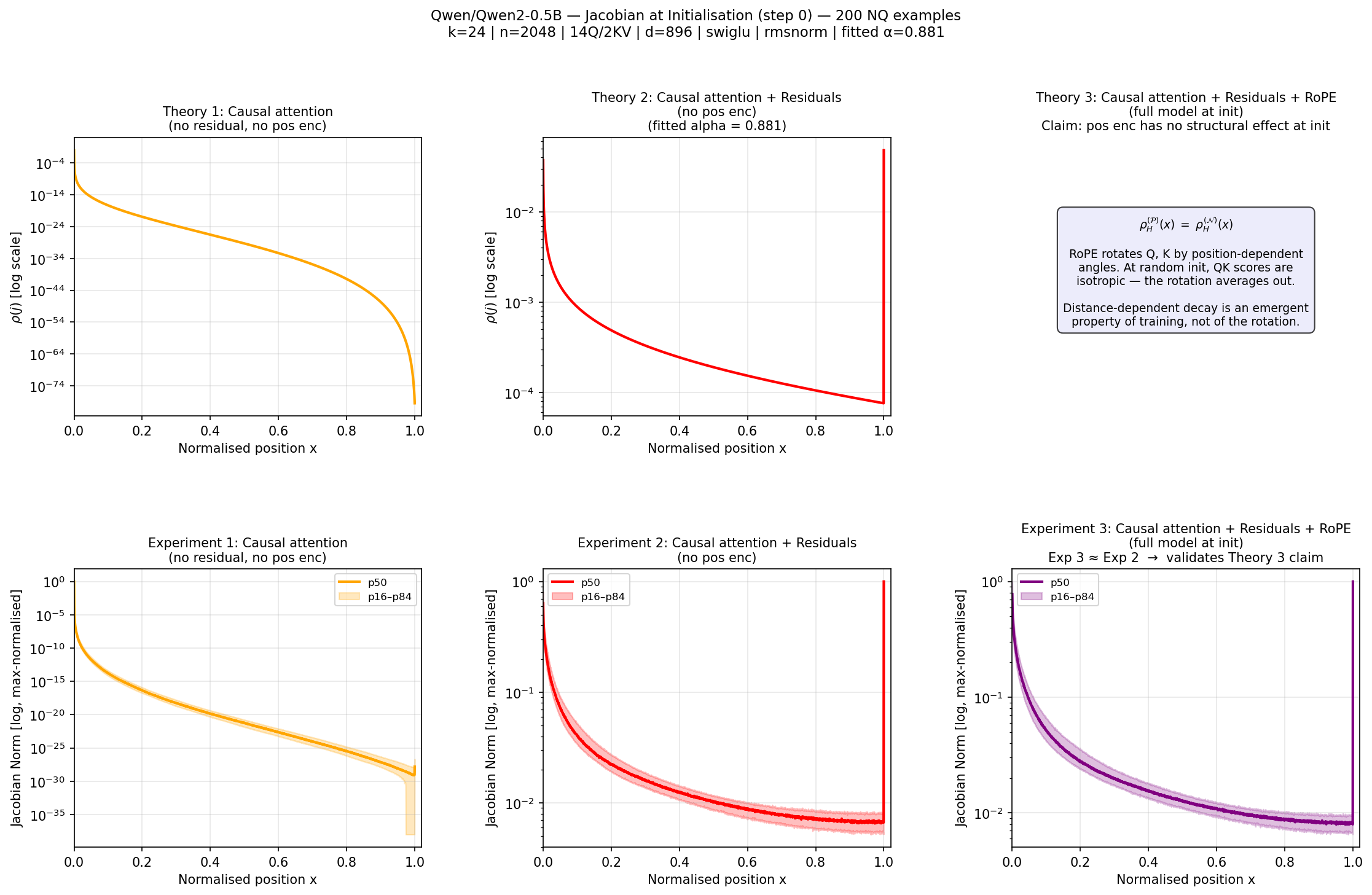
Figure 1: Theoretical and empirical validation of the Jacobian U-shape at initialization in Qwen2-0.5B, demonstrating the irrelevance of RoPE to the architectural baseline.
Universality and RoPE-Independence
It is explicitly shown, both analytically and empirically, that altering or removing RoPE positional encodings does not affect the baseline topology at initialization. Identical U-shapes are observed with and without RoPE. For GPT-2, which uses absolute positional encodings, the same invariant structure is found.
Evolution During Training
Training on large text corpora for both Qwen2 and GPT-2 fails to alter the macroscopic shape of the U-curve; the middle-context suppression persists. While localized attention spikes can emerge at document boundaries—learned routing adapting to content structure—the topological dead zone is not eliminated.
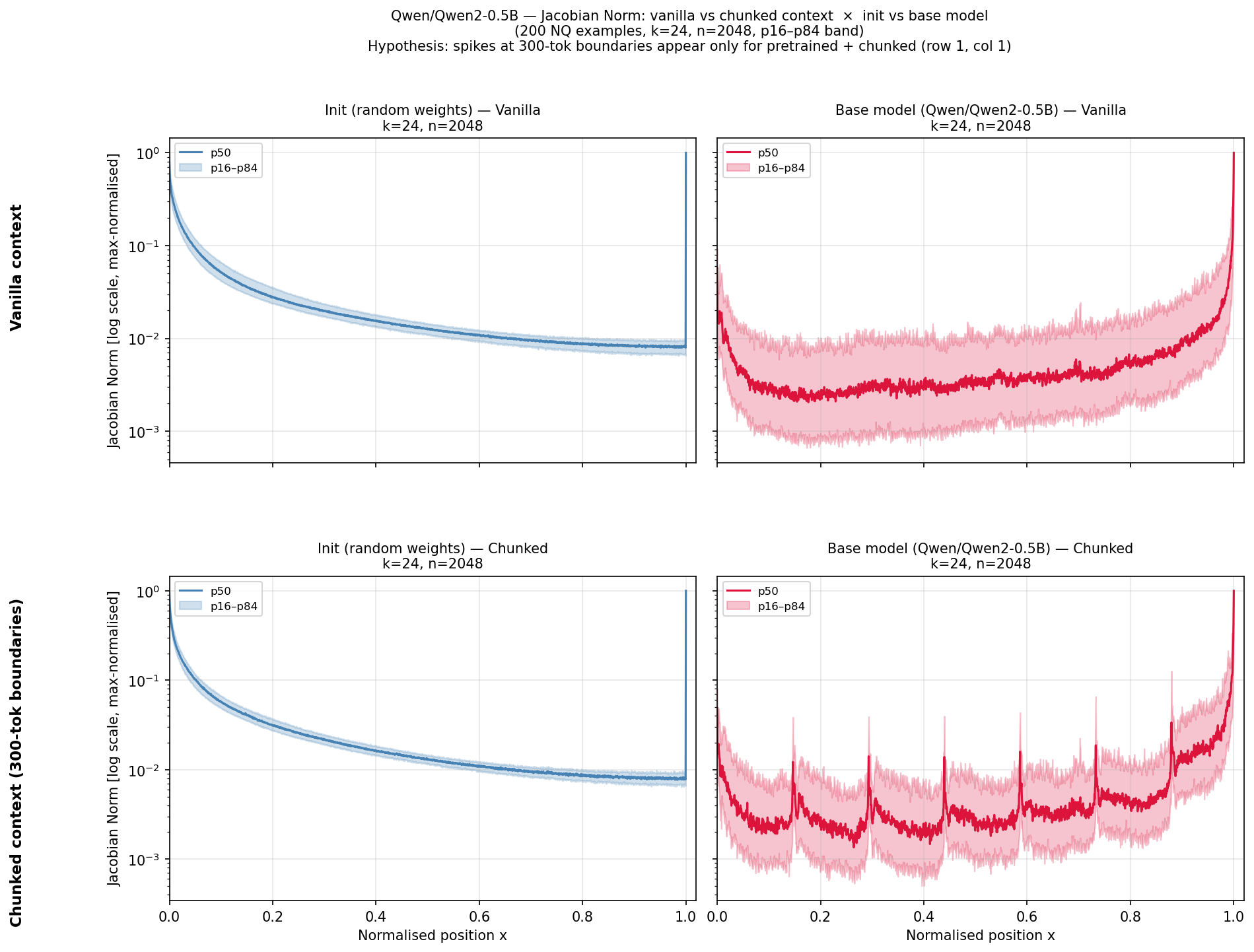
Figure 2: Comparison of Jacobian norms at initialization and after pretraining in Qwen2, showing architectural persistence of the U-shape and emergence of localized spikes at content boundaries.
Dynamics During Early Optimization
A controlled micro-training experiment demonstrates that while the optimizer rapidly learns to spike attention around boundaries and makes task-driven adjustments, the depth and width of the central "dead zone" remain essentially unchanged. The forward signal and the backward gradient used for optimization are both attenuated in the middle, resulting in effectively lower "learning rates" for middle-context positions.
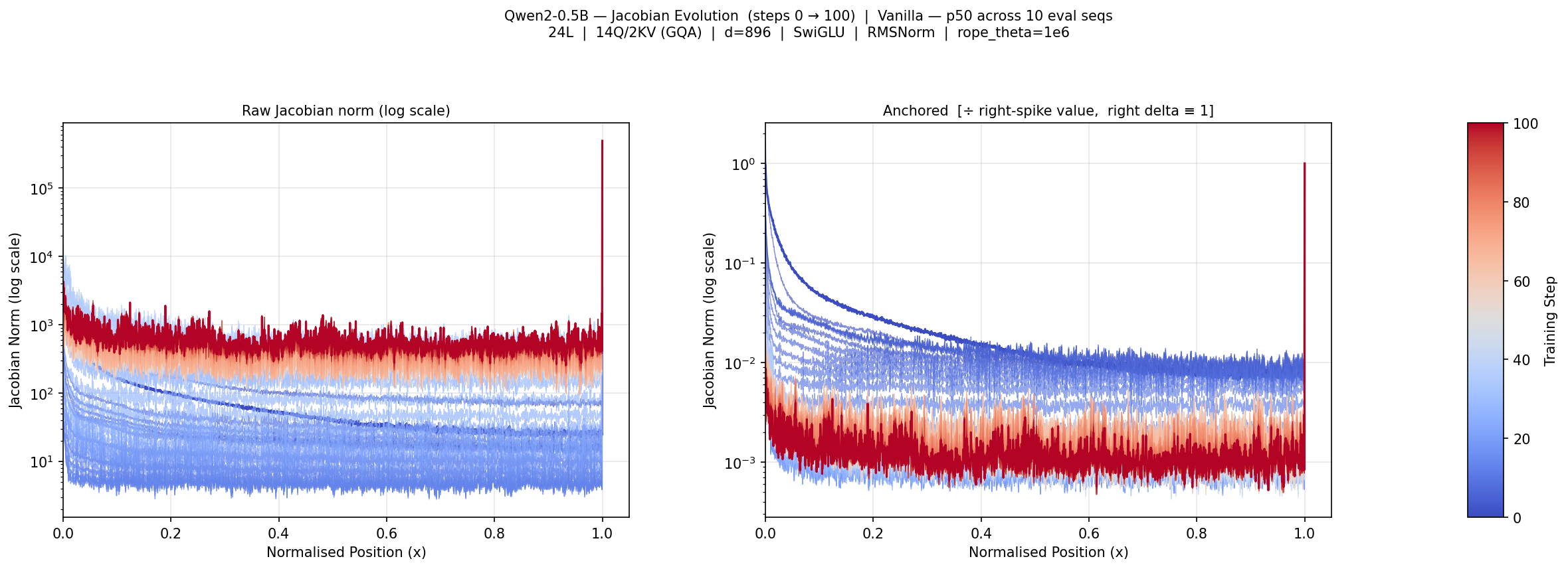
Figure 3: Evolution of the Jacobian topology across 100 gradient steps. Middle-context suppression deepens, confirming optimizer reliance on geometric extremes.
Theoretical and Practical Implications
Architectural Baseline and Its Consequences
The work establishes the U-shape as a topological birthright of causal decoder-only transformers. The depth-induced combinatorial compounding (primacy) and the Dirac measure from residuals (recency) are mathematically inevitable. Middle-context suppression is not a mere consequence of RoPE distance decay but a result of factorially diluted signal paths in the core toplogy.
Classic strategies—such as flattening positional encodings or simply "training longer"—are insufficient to mitigate the dead zone. Attempts to overcome this baseline must instead focus on explicitly penalizing or reweighting middle-context gradient flow, potentially through curriculum learning, position-dependent losses, or data over-sampling for mid-sequence retrieval. The closed-form calculus presented elucidates the magnitude of the geometric headwind such approaches must confront.
Directions for Future Research
- Investigate non-standard objectives that apply direct pressure to increase gradient and attention flow through the central context.
- Study architectures or modifications (e.g., non-causal attention, explicit memory routing) that break the strict stratification imposed by the Cesàro-residual topology.
- Extend input-output Jacobian norm analyses to open-source models with longer contexts and alternative attention mechanisms.
Conclusion
This work delivers the exact mathematical foundation for position-dependent influence in deep autoregressive transformers, decisively attributing the "Lost in the Middle" U-shaped bias to core architectural design—causal masking plus residual connections—rather than training artifacts or positional encoding specifics. Empirical results across architectures confirm the analytical predictions, necessitating a conceptual shift in mitigation strategies for long-context retrieval degradation.
Efforts to overcome middle-context suppression must now explicitly target the architectural geometric baseline, armed with precise quantitative characterizations of the challenge at hand.