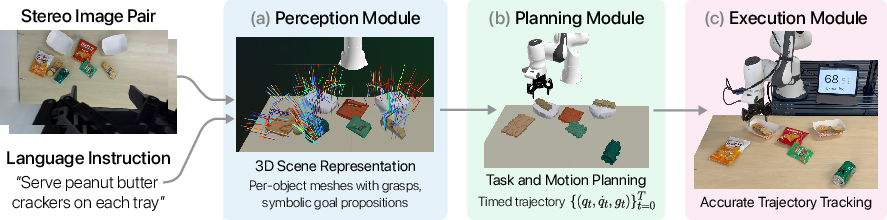
TiPToP: A Modular Open-Vocabulary Planning System for Robotic Manipulation
Abstract: We present TiPToP, an extensible modular system that combines pretrained vision foundation models with an existing Task and Motion Planner (TAMP) to solve multi-step manipulation tasks directly from input RGB images and natural-language instructions. Our system aims to be simple and easy-to-use: it can be installed and run on a standard DROID setup in under one hour and adapted to new embodiments with minimal effort. We evaluate TiPToP -- which requires zero robot data -- over 28 tabletop manipulation tasks in simulation and the real world and find it matches or outperforms $π_{0.5}\text{-DROID}$, a vision-language-action (VLA) model fine-tuned on 350 hours of embodiment-specific demonstrations. TiPToP's modular architecture enables us to analyze the system's failure modes at the component level. We analyze results from an evaluation of 173 trials and identify directions for improvement. We release TiPToP open-source to further research on modular manipulation systems and tighter integration between learning and planning. Project website and code: https://tiptop-robot.github.io




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
The paper introduces TiPToP, a robot system that can understand a natural-language instruction (like “put the crackers on each tray”), look at camera images of a table, and plan a step-by-step way to move objects to complete the task. It’s designed to “just work” without special training data for each robot, and to be easy to install and adapt to different robot arms.
What the researchers wanted to find out
They asked three simple questions:
- How well can TiPToP do everyday, multi-step robot tasks from plain language, compared to a powerful learned system that needs lots of training?
- How fast is TiPToP at finishing tasks?
- When TiPToP fails, why does it fail?
How TiPToP works (in everyday language)
TiPToP has three main parts: seeing, planning, and doing.
1) Seeing (Perception)
The robot starts with two images from a small camera on its wrist (like your two eyes). From these, it:
- Builds 3D: It uses a “stereo depth” model that turns the two images into a 3D “point cloud,” which is like a sculpture made of tiny dots showing where surfaces are in space.
- Finds objects and their names: It asks a vision-and-LLM (a very smart image+text AI) to draw boxes around objects in the picture and label them (e.g., “peanut butter crackers,” “tray”). It also turns the instruction (“put crackers on each tray”) into a clear goal the planner can use, like “On(crackers, tray).”
- Outlines shapes: It uses a segmentation tool (think: coloring inside the lines) to get each object’s exact outline in the image.
- Suggests grasps: It proposes many possible ways the robot could grab items in 3D.
Finally, it combines all this to make simple 3D shapes for each object (like a shrink-wrap around the object) and attaches the best candidate grasps to each object.
Key ideas explained:
- Stereo depth: like how your two eyes help you sense distance.
- Point cloud: a 3D map made of many dots.
- Segmentation: coloring the exact pixels of an object.
- Vision-LLM (VLM): an AI that can look at a picture and understand a text instruction.
- Grasp candidates: different hand positions the robot could use to pick something up.
2) Planning (Thinking ahead)
TiPToP uses a method called Task and Motion Planning (TAMP). Think of it like writing a recipe (“pick up crackers,” “move to tray,” “place”) and also checking if each step is physically possible (no bumps, reachable by the arm, stable placements). It:
- Lists possible action sequences (like different recipes to reach the goal).
- Makes many quick guesses for the exact details (where to grab, where to place) and improves them using fast math on a graphics card (GPU), like having hundreds of assistants testing ideas in parallel.
- Finds a smooth, collision-free path for the arm to follow.
Key ideas explained:
- TAMP: planning the high-level steps and the detailed arm motions together.
- GPU acceleration: using powerful parallel processors to try many options fast.
3) Doing (Execution)
The robot then follows the planned path like a choreographed dance, sending joint motions to the arm and opening/closing the gripper at the right times.
Note: TiPToP currently executes “open-loop,” which means it doesn’t look again while moving. It trusts the plan and doesn’t adjust mid-action. That’s fast, but if something slips, it won’t correct itself unless you re-run the whole step.
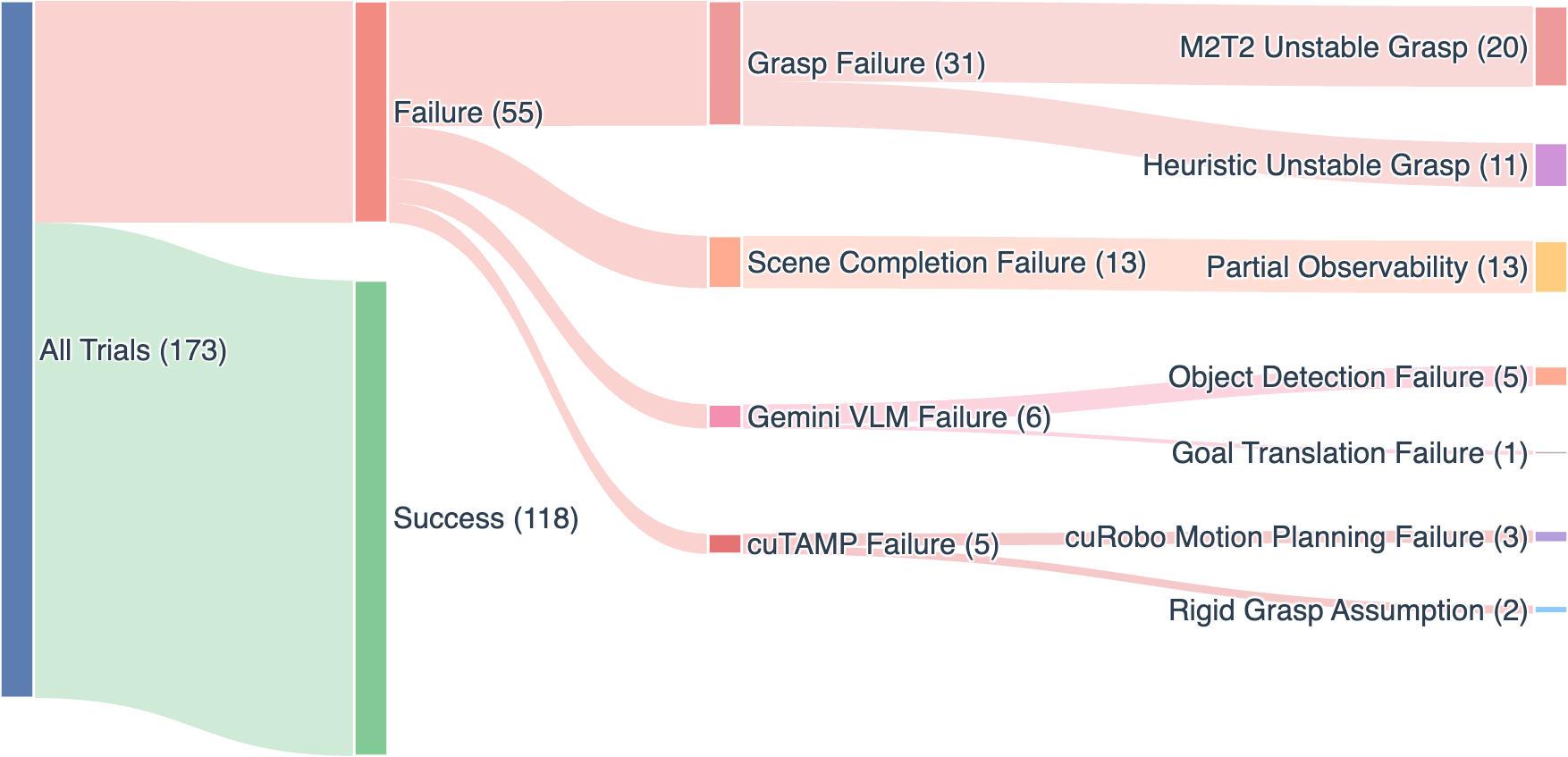
What they found and why it matters
They tested TiPToP on 28 tabletop tasks both in simulation and on real robots (Franka, UR5e, WidowX), running 165 trials in total, and compared it to a strong learned system called π₀.₅-DROID that was trained on 350 hours of robot demonstrations.
Main results:
- Success: TiPToP matched or beat the trained system overall, especially on:
- Tasks with many distractor objects (it picked the right item among many).
- Tasks with tricky language (like “largest toy” or “matching plate”).
- Multi-step tasks (like moving something out of the way first, then placing).
- Speed: It usually finished tasks faster, often about half the time on simple tasks. Planning the whole path up front made execution quick and purposeful.
- Easy setup: It can be installed in under an hour on common setups and adapted to new robot arms with modest effort. No new robot-specific training data is needed.
Where it struggled:
- Grasping: Most failures were from missed or unstable grasps. Because it doesn’t re-check during motion, it can’t retry automatically.
- Shape approximations: It uses simple “shrink-wrap” shapes (convex hulls) for objects from one camera view. This can be wrong for bendy or concave shapes (like bananas), causing planning or collision mistakes.
- Tiny objects: Very small items are hard to pick reliably in a single try.
Why this is important:
- It shows that smart “modules” (seeing + planning) built from general-purpose AI models can rival systems that need lots of robot training data.
- The system is modular, so each part can be swapped or upgraded as better AI tools appear (better depth, better grasping, better language understanding, faster planners).
- It’s open-source, making it easier for others to build on and compare with.
What this could lead to next
The authors suggest practical upgrades that a team could add over time:
- Look-and-replan: After each step, look again and fix mistakes (e.g., retry a slipped grasp).
- See from more angles: Use more cameras or move the camera first to get better 3D shapes.
- Better object shapes: Use new “shape completion” tools that guess a full 3D shape from limited views.
- Mix “thinking” with “reacting”: Combine TiPToP’s careful planning with reactive learned skills (like a learned grabber that can adjust mid-move) to get the best of both worlds.
In simple terms, TiPToP is like a careful organizer: it looks, understands, plans a detailed sequence, and executes smoothly. With a bit more “street smarts” during execution—like checking and adjusting on the fly—it could become even more reliable for real-world chores.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide actionable follow-up work.
- Closed-loop execution and recovery: add execution monitors (vision/tactile/force) to detect grasp/placement failure, support grasp retries, mid-trajectory corrections, and step-wise replan; quantify recovery gains versus open-loop execution.
- Multi-view and active perception: plan next-best-view(s) or fuse multiple static cameras to reduce occlusions and improve geometry; evaluate improvements in grasp success and collision rates.
- Shape reconstruction beyond convex hulls: replace single-view convex hulls with learned 3D completion or implicit meshes; benchmark collision false positives/negatives and placement stability versus ground-truth meshes.
- Uncertainty-aware (belief-space) TAMP: propagate uncertainty from detection, segmentation, and depth into grasp/placement and collision constraints; evaluate robust plans and information-gathering actions.
- Richer symbolic predicates and language grounding: systematically extend beyond On(a,b) to In/Inside/Under/LeftOf/Clear/ContainedIn/Open/Close/Containment/Stacking; support quantifiers and counts (each/exactly-N); validate predicate correctness against the scene.
- Learning preconditions/effects for new skills: automatically infer abstract models for skills (e.g., wiping, pushing) from data; verify that learned models enable correct plan sequencing under TAMP.
- Integrating reactive learned skills: define interfaces for invoking VLA or visuomotor policies as feedback-controlled primitives within plans; specify/learn their preconditions/effects and handoff logic.
- Grasp robustness and selection: add collision-aware grasp filtering, grasp-quality simulation, and multi-attempt strategies; incorporate tactile/force feedback; support diverse grippers (suction, multi-finger) and evaluate cross-gripper generalization.
- Small-object manipulation: develop specialized sensing (higher-res, macro depth) and grasp strategies for tiny or low-profile items; quantify improvements on AirPods/cashew-like tasks.
- Slip detection and compliant control: use F/T and finger position signals to detect incipient slip; modulate grip force, regrasp, or adjust trajectories; evaluate reduction in transport losses.
- Dynamic and human-in-the-loop environments: support online replanning under moving obstacles/humans; characterize latency/throughput required for safe, responsive behavior.
- Explicit obstruction reasoning: add pre-grasp approach/visibility analysis and clearance tests to decide when to move obstructions, rather than relying on optimization failures to reveal the need.
- Automatic capture-pose selection: plan a wrist-camera pose (or sequence) to maximize task-relevant coverage given kinematics and occlusions; measure impact versus a fixed capture pose.
- Cross-embodiment scaling: test on a wider range of arms and grippers; quantify porting effort, performance variability, and required controller tuning across embodiments.
- Compute footprint and deployment constraints: profile runtime, GPU memory, and latency per module (depth, VLM, TAMP) across hardware; demonstrate feasibility on on-robot compute and cloud-free settings.
- Reliance on proprietary VLMs: evaluate open/local VLM alternatives for detection/grounding (accuracy, latency, cost); study robustness to prompt sensitivity and model/version drift; design fallbacks when VLM calls fail.
- Calibration robustness: analyze sensitivity to camera intrinsics/extrinsics error and joint encoder drift; add auto-calibration/online refinement; quantify downstream effects on grasp/placement success.
- Physical property uncertainty: incorporate estimates of mass, friction, and contact geometry into stability constraints; learn/update these online; measure impact on stacking and “on vs in” semantics.
- Motion planning in heavy clutter: characterize cuRobo failure modes/timeouts; add fallback planners or learned guidance; set adaptive time budgets and multi-seed strategies.
- Plan skeleton scalability: study complexity and pruning when objects/tasks scale; add heuristic or learned skeleton proposal/guidance; report worst-case and average enumeration costs.
- Broader, standardized evaluation: benchmark on established suites (e.g., RLBench, BEHAVIOR, ManiSkill, CALVIN) and compare to additional baselines (PDDLStream, VoxPoser, OWL-TAMP, LLM3); report confidence intervals and statistical significance.
- Task diversity beyond tabletop pick-and-place: add primitives and evaluations for articulated-object manipulation, tool use, nonprehensile actions (pushing, sliding), deformables/cables, and long-horizon mobile manipulation.
- Semantic verification at execution: after acting, re-check that goals are satisfied (e.g., on vs in/inside) with perception; trigger corrective actions if semantic predicates are not met.
- End-to-end error propagation: quantify how detection/segmentation/depth errors translate into grasp/plan failures; identify the most impactful error sources to prioritize model upgrades.
- Robust segmentation/detection under occlusion and clutter: compare SAM-2 plus box prompts to 3D instance segmentation and open-vocabulary detectors; evaluate small-object and heavy-occlusion regimes.
- Fairness and controls in comparisons: control for sensor differences (stereo vs monocular, external cameras), timing protocols, and idling; run matched-sensing ablations to isolate architectural effects.
- Safety analysis and constraints: integrate human-safe force/velocity limits and forbidden zones into planning and control; add formal monitors/guarantees for collision avoidance during execution.
- Learning from failures: turn logged execution failures into improvements (grasp priors, shape priors, predicate reliability); study online adaptation without embodiment-specific demonstrations.
- Persistent world models: maintain object identities and states across tasks/episodes to enable multi-step projects, inventory tracking, and long-horizon goal fulfillment.
Practical Applications
Practical Applications Derived from the Paper
Below are actionable, real-world applications grounded in TiPToP’s findings, methods, and innovations, grouped by deployment horizon. Each item identifies sectors, concrete use cases, potential tools/workflows, and key assumptions or dependencies that impact feasibility.
Immediate Applications
- Industry — Light manufacturing, kitting, and assembly
- Use cases:
- Language-driven kitting and packing: “Put one of each item on each tray/bay,” “Pack pods onto tray,” “Place X on Y while avoiding obstacles.”
- Distractor-rich pick-and-place on changing SKUs without retraining (e.g., small-batch, high-mix lines).
- Obstruction-aware manipulation (moving a blocking item to access a target).
- Tools/workflows:
- “Semantic workcell” interface that accepts natural-language task templates and images.
- A TiPToP-powered kitting station where operators specify goals in plain English.
- Onboarding workflow: import URDF, calibrate a stereo wrist camera, run built-in cuRobo config, and deploy.
- Assumptions/dependencies:
- Static or quasi-static scenes; single-view stereo capture at t=0; open-loop execution.
- Requires GPU (CUDA) and wrist-mounted stereo or dual-camera rig; accurate calibration.
- Convex-hull mesh approximation can fail on strongly concave items (e.g., bananas).
- Warehousing and fulfillment
- Use cases:
- Bin sorting and order consolidation with open-vocabulary instructions: “Sort blocks by color,” “Place the largest toy onto the purple plate/bin.”
- Distractor rejection in cluttered totes without custom dataset collection.
- Tools/workflows:
- “Natural-language sorter” station using TiPToP as a drop-in inference-time planner for tote-to-bin routing.
- Autogenerated subgoals via VLM-predicated goal grounding for SKU variants.
- Assumptions/dependencies:
- Object sizes compatible with a parallel gripper; single-viewpoint limitations; cloud or local VLM availability.
- Labs and R&D (academia and industry)
- Use cases:
- Out-of-the-box baseline for multi-step tabletop manipulation from pixels and language—no robot training data needed.
- Component-level failure auditing and ablations (depth, segmentation, grasps, planning) using TiPToP’s modular stack.
- Cross-embodiment evaluation (e.g., Franka, UR5e, WidowX) with minimal porting effort.
- Tools/workflows:
- Benchmark harness comparing TAMP vs. VLA vs. hybrid methods on semantic/multi-step tasks.
- Dataset generation of successful trajectories for imitation or RL fine-tuning; synthetic tasks in Isaac Sim.
- Assumptions/dependencies:
- GPU for cuTAMP/cuRobo; access to foundation models (SAM-2, FoundationStereo, VLM); correct URDF and collision spheres.
- Service robotics (offices, labs, controlled home-like spaces)
- Use cases:
- Desk/lab tidying with semantic grounding: “Place peanut-butter crackers on each tray,” “Put markers into the cup.”
- Simple wiping/cleaning tasks when extended with the provided Wipe primitive.
- Tools/workflows:
- Operator-in-the-loop language interface to issue episodic tasks; pre-validated plan preview.
- Assumptions/dependencies:
- Limited to tabletop-like, static scenes and open-loop execution; wiping assumes known surface and reachable region.
- Education and training
- Use cases:
- Teaching TAMP, 3D perception, and VLM grounding in robotics courses without large-scale data collection.
- “Skill extension labs” where students add new predicates/operators (e.g., Wipe) over a weekend.
- Tools/workflows:
- Reproducible course assignments in Isaac Sim; plug-and-play lab demos on common arms.
- Assumptions/dependencies:
- Entry-level GPU workstation; institution-friendly licensing for VLMs and vision models.
- Systems integration and prototyping for robotics companies
- Use cases:
- Rapid proof-of-concept demos for prospective customers without collecting demonstrations.
- Wrapping existing industrial grippers/cameras with a language-conditioned TAMP planner.
- Tools/workflows:
- TiPToP adapter kits: embodiment config, camera calibration utilities, controller bridges.
- Pre-flight “plan and simulate” workflow to verify collision-free trajectories before execution.
- Assumptions/dependencies:
- Time-optimal open-loop trajectories require precise joint tracking; impedance control tuning is critical.
- Process quality and safety auditing (policy/assurance)
- Use cases:
- Component-level “explainability” for failures (perception vs. planning vs. control) in acceptance testing and incident reports.
- Tools/workflows:
- Automated logs and Sankey-style dashboards that classify failure modes across trials.
- Assumptions/dependencies:
- Requires standardized task suites and labeling rules for “task progress” vs. “success” metrics.
- Hobbyist and maker ecosystems (daily life)
- Use cases:
- Entry-level manipulation on affordable arms (e.g., Trossen WidowX AI) for household sorting, toy cleanup, and educational projects.
- Tools/workflows:
- Community-contributed predicate libraries and embodiment configs; GUI wizards for calibration.
- Assumptions/dependencies:
- Lighter hardware may limit payload/precision; stereo perception recommended.
Long-Term Applications
- Hybrid reactive-planning robotics across sectors (manufacturing, logistics, service, healthcare)
- Vision:
- Combine TiPToP’s semantic TAMP with closed-loop VLAs as reactive primitives for grasp retries, slippage recovery, and fine manipulation (folding, cable tasks).
- Potential products:
- “TiPToP Hybrid Controller”: a planner that calls VLA-based micro-skills with declarative preconditions/effects.
- Dependencies:
- Robust skill abstractions (learned or engineered); safety guarantees for black-box policies.
- Robust, uncertainty-aware deployment (belief-space TAMP)
- Vision:
- Active perception and information-gathering actions; multi-view shape completion; probabilistic reasoning about grasp and placement uncertainty.
- Potential products:
- “Perception-first planning” module that moves cameras to reduce occlusions before solving.
- Dependencies:
- Extensions of cuTAMP to belief space; faster multi-view depth/shape completion (e.g., SAM-3D-class methods).
- Home assistance and eldercare
- Vision:
- Reliable household tidying, dish/tray preparation, and surface cleaning with semantic grounding and safer, reactive execution.
- Potential products:
- Natural-language caregiver assistant that executes checklists (“Set up the breakfast tray,” “Clear the table”) with plan previews for approval.
- Dependencies:
- Safety certification, reliable human-aware motion, handling of deformable/fragile objects, privacy-first on-device perception/VLMs.
- Hospitals and clinical logistics
- Vision:
- Non-sterile supply handling, sorting, and room turnover support (e.g., placing items on designated trays/carts; wiping non-critical surfaces).
- Potential products:
- “Semantic cart restockers” controlled by nurses via simple sentences.
- Dependencies:
- Infection control, robust ID of medical supplies, rigorous fail-safes, regulatory compliance.
- Retail restocking and backroom operations
- Vision:
- Language-directed put-away and facing: “Place the largest cereal on the top shelf,” “Group by brand/color.”
- Potential products:
- Voice-driven backroom assistants that adapt to changing SKUs without retraining.
- Dependencies:
- Handling of concave, deformable, or reflective packages; extended reach and shelf-aware planning.
- Construction and recycling (material sorting)
- Vision:
- Sorting heterogeneous items by category or attribute without per-class training.
- Potential products:
- Open-vocabulary sorter cells for demolition debris or e-waste triage.
- Dependencies:
- Heavy-duty end-effectors, dust/lighting robustness, multi-view perception, high-throughput constraints.
- Agricultural post-harvest handling
- Vision:
- Gentle pack-and-place by size/grade/color; open-vocabulary sorting (“Place ripe tomatoes into tray B”).
- Potential products:
- On-farm semantic kitting and packing assistants.
- Dependencies:
- Deformable, delicate grasping; humidity/dirt robustness; fast re-planning in dynamic bins.
- Standardization and policy (auditability, certification)
- Vision:
- Module-level transparency as a regulatory asset for certifying autonomy in shared workspaces (traceable failure causes; deterministic planning logs).
- Potential products:
- Compliance toolkits that replay and attribute failures to perception/planning/control components with metrics like Task Progress.
- Dependencies:
- Sector-specific standards for logging, explainability, and human-in-the-loop overrides.
- Commercialization of a modular manipulation SDK
- Vision:
- A supported “TiPToP Pro” offering with:
- Embodiment adapters (Franka, UR, ABB, Fanuc), GUI task editors, plan simulators, and fleet management.
- Predicate and skill marketplaces (community and vendor-contributed).
- Dependencies:
- Long-term support for foundation models (licensing, on-device variants), sustained GPU availability, vendor controller integrations.
- Data generation and simulation-for-learning at scale
- Vision:
- Automated curriculum generation of multi-step, semantic tasks to pretrain or finetune VLAs and grasp networks.
- Potential products:
- “TiPToP Task Forge”: Isaac Sim pipelines that synthesize labeled trajectories and failure taxonomies for training robust policies.
- Dependencies:
- Domain randomization/bridging to real; scalable simulation infrastructure.
- Human-robot interaction with interactive goal refinement
- Vision:
- Robots that ask clarifying questions when VLM grounding is uncertain and update the plan on-the-fly.
- Potential products:
- Conversational plan editors that visualize the TAMP skeleton, allow human edits, and re-optimize in seconds.
- Dependencies:
- Real-time re-planning loop, uncertainty estimates from VLMs, tight latency bounds for mixed-initiative control.
Notes on cross-cutting assumptions and risks:
- Hardware/software requirements: CUDA-capable GPU; accurate camera extrinsics/intrinsics; URDF and controller with precise joint tracking; stereo or dual cameras preferred.
- Perception scope: Single-viewpoint depth and convex hull meshing can misrepresent concave/deformable/reflective objects; multi-view or learned shape completion mitigates this.
- Execution: Current open-loop assumption limits robustness to slips or failed grasps; adding closed-loop retries and re-planning is essential for high reliability.
- Data/privacy/licensing: Some VLMs and models may require cloud access or specific licenses; on-device models may be needed for sensitive environments.
- Safety: Industrial and healthcare deployments require certified safety layers, human-aware motion, and fault detection before executing open-loop plans.
Glossary
- 6-DoF: Six degrees of freedom describing full 3D position and orientation of an object or end-effector. "predict 6-DoF grasp poses from point clouds."
- Belief-space planning: Planning over probability distributions of states to handle uncertainty. "Belief-space planning."
- camera intrinsics: Parameters defining a camera’s internal geometry (focal length, principal point, etc.). "camera intrinsics "
- camera-to-end-effector extrinsics: Rigid transform from the camera frame to the robot’s end-effector frame. "camera-to-end-effector extrinsics"
- Cartesian control: Control in task-space (x, y, z, orientation) rather than joint space. "IK-based Cartesian control."
- convex hull: The smallest convex shape enclosing a set of points; used to approximate object geometry. "compute the convex hull to form a watertight mesh."
- cuRobo: A GPU-accelerated motion planning library for fast trajectory computation. "cuRobo~\citep{sundaralingam2023curobo}, a GPU-accelerated motion planner"
- cuTAMP: A GPU-parallelized Task and Motion Planning algorithm for optimizing discrete and continuous variables. "TiPToP uses cuTAMP~\citep{shen2025cutamp}, a GPU-parallelized Task and Motion Planning algorithm,"
- DROID: A standardized robot hardware/software platform used for benchmarking. "a standard DROID setup"
- FoundationStereo: A foundation model for stereo depth estimation from RGB image pairs. "We use FoundationStereo~\citep{wen2025foundationstereo}, a foundation model for stereo depth estimation,"
- forward kinematics (FK): Computing the pose of the robot’s end-effector from joint angles. "forward kinematics (FK)"
- Gemini Robotics-ER 1.5: A large vision-LLM used for object detection and goal grounding. "Gemini Robotics-ER 1.5~\citep{team2025gemini}, a VLM,"
- grasp generation: Predicting feasible grasp poses for objects from sensor data. "Foundation models for grasp generation~\citep{murali2025graspgen, sundermeyer2021contact, yuan2023m2t2}"
- inverse kinematics: Computing joint angles that achieve a desired end-effector pose. "inverse kinematics."
- IsaacSim: A physics-based simulator for robotics experimentation and development. "IsaacSim~\citep{NVIDIA_ISAAC_SIM}"
- joint impedance controller: A controller that regulates motion by simulating compliance (stiffness/damping) in joint space. "joint impedance controller."
- KDTree: A spatial data structure for efficient nearest-neighbor queries in k-dimensional space. "KDTree~\citep{bentley1975multidimensional}"
- M2T2: A model that predicts ranked 6-DoF grasp poses from point clouds. "We use M2T2~\citep{yuan2023m2t2} to predict ranked 6-DoF grasp poses"
- Motion primitive: A parameterized low-level action (e.g., pick, place) used to compose complex behaviors. "operates primarily over pick-and-place primitives"
- On(a, b): A symbolic predicate specifying that object a should be placed on object or surface b. "( specifies that object should be placed on object or surface )"
- open-loop: Executing a precomputed plan without using feedback during execution. "executed open-loop with no further visual observations."
- Particle Initialization: Sampling initial continuous parameters (grasps, placements, configurations) for optimization in TAMP. "Particle Initialization."
- Particle Optimization: Differentiable refinement of sampled parameters to satisfy constraints in TAMP. "Particle Optimization."
- PDDL: A formal language (Planning Domain Definition Language) for describing planning problems. "PDDL-style symbolic planner"
- PDDLStream: A TAMP framework that augments PDDL planning with sampling-based continuous reasoning. "PDDLStream~\citep{garrett2020pddlstream}"
- plan skeletons: Sequences of abstract actions without bound continuous parameters. "plan skeletons --- sequences of symbolic actions without committed continuous parameters."
- predicate: A symbolic relation over objects used to specify goals/conditions in planning. "a symbolic goal expressed as a conjunction of predicates"
- RANSAC: A robust method for model fitting in noisy data by iteratively sampling consensus sets. "RANSAC~\citep{fischler1981random}"
- SAM: Segment Anything Model for promptable image segmentation. "SAM~\citep{kirillov2023segany}"
- SAM-2: An improved promptable segmentation model for pixel-level masks. "SAM-2~\citep{ravi2024sam2}"
- stereo baseline: The distance between two cameras in a stereo pair used for depth triangulation. "stereo baseline "
- Task and Motion Planning (TAMP): Planning that jointly reasons over discrete actions and continuous motions/constraints. "Task and Motion Planning (TAMP)~\citep{kaelbling2011hierarchical,garrett2021integrated,curtis2022tamp}"
- unprojecting depth: Converting depth pixels into 3D points in camera/world coordinates. "Unprojecting depth to 3D."
- URDF: Unified Robot Description Format, an XML format describing a robot’s kinematics and geometry. "The embodiment must possess a camera, gripper, URDF, and trajectory tracking controller to be supported."
- Vision-Language-Action (VLA): Models that map images and language instructions directly to robot actions. "Vision-Language-Action (VLA) models such as ~\citep{black2025pi05} and OpenVLA~\citep{kim2024openvla} offer an appealing input-output specification"
- Vision-LLM (VLM): Models that jointly process visual inputs and text to perform tasks like grounding and detection. "VLMs~\cite{team2023gemini, deitke2025molmo, bai2025qwen3vltechnicalreport, openai2024gpt4ocard} combine vision and language understanding"
Collections
Sign up for free to add this paper to one or more collections.