- The paper introduces FireRedTTS-2 as a novel system that generates long-form conversational speech sentence-by-sentence for interactive podcasts and chatbots.
- It leverages a low-frame-rate speech tokenizer and a dual-transformer architecture to enable stable speaker transitions and contextually coherent prosody.
- Experimental results show superior performance in WER, speaker similarity, and naturalness compared to existing dialogue TTS models.
Introduction
FireRedTTS-2 introduces a streaming, multi-speaker text-to-speech (TTS) system designed for long-form conversational speech generation, targeting applications such as podcasts and interactive chatbots. The system addresses limitations in prior dialogue TTS approaches, which typically require the entire dialogue text before synthesis and produce a single, inseparable speech track, resulting in inflexible, non-interactive outputs and issues with speaker transitions and prosody coherence. FireRedTTS-2 leverages a novel low-frame-rate speech tokenizer and a dual-transformer architecture operating on interleaved text–speech sequences, enabling sentence-by-sentence generation, stable speaker switching, and contextually coherent prosody.
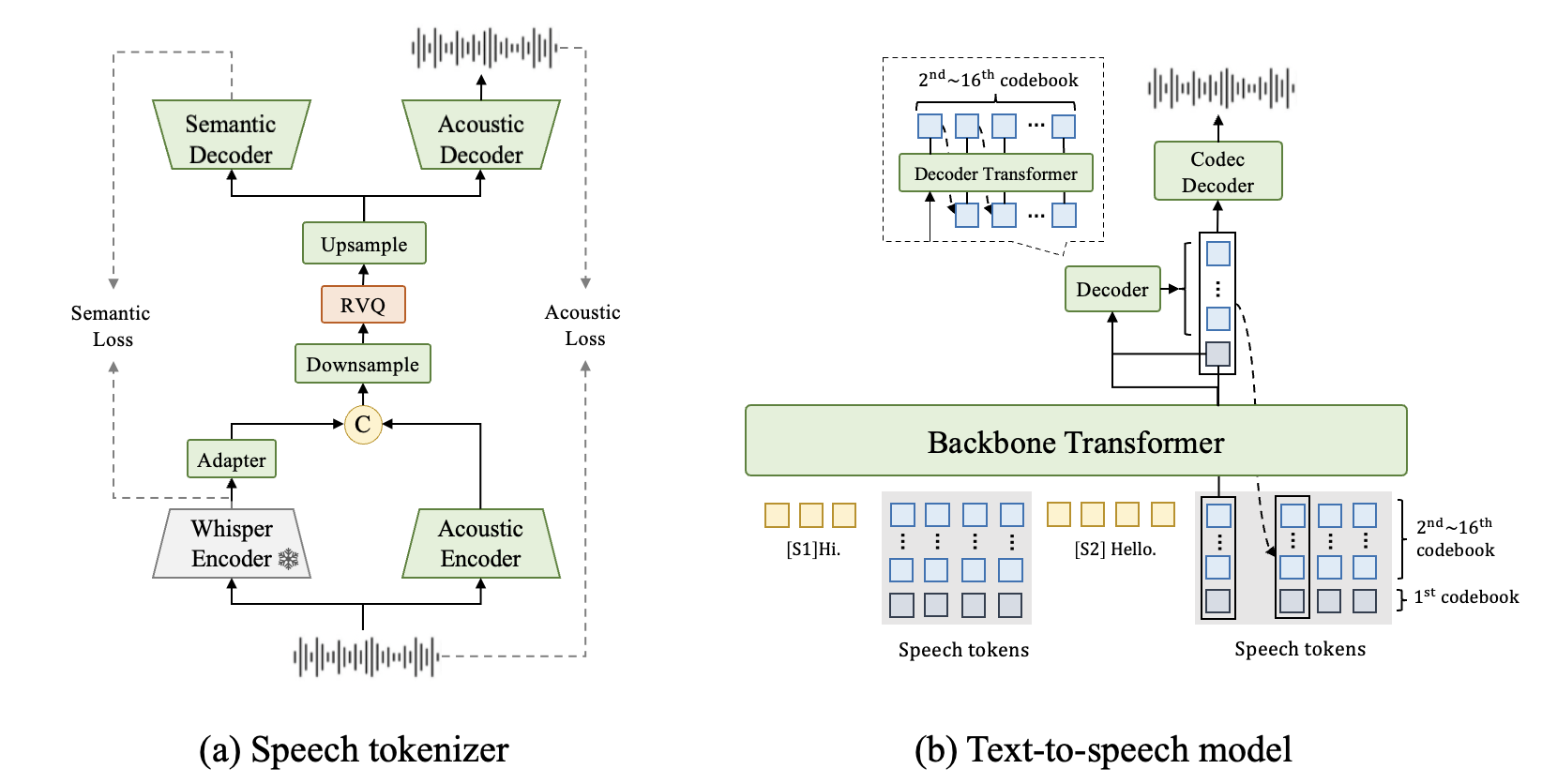
Figure 1: An overview of FireRedTTS-2, including: (a) a new speech tokenizer with a 12.5Hz frame rate and enhanced semantic information, and (b) a text-to-speech model using a dual-transformer architecture with interleaved text–speech input, enabling sentence-by-sentence generation and contextually coherent prosody.
System Architecture
Speech Tokenizer
The FireRedTTS-2 speech tokenizer operates at 12.5Hz, half the frame rate of most open-source tokenizers, which significantly reduces sequence length and computational requirements for long dialogues. Semantic injection and explicit supervision are employed to stabilize text-to-token modeling and improve synthesis reliability. The tokenizer utilizes a pretrained Whisper encoder for semantic feature extraction, which is concatenated with acoustic features from a trainable encoder. Features are downsampled and discretized via a 16-layer residual vector quantizer (RVQ), each with 2048 code entries. Upsampled quantized features are used by a Vocos-based acoustic decoder for waveform reconstruction, supporting both streaming and non-streaming modes.
Training is performed in two stages: initial non-streaming optimization on 500k hours of speech, followed by streaming adaptation on 60k hours of high-fidelity data. The final model supports real-time, high-fidelity streaming generation, making it suitable for interactive applications.
Dual-Transformer Text-to-Speech Model
FireRedTTS-2 models dialogue as an interleaved sequence of speaker-labeled text and corresponding speech tokens, concatenated in chronological order. The dual-transformer architecture consists of a large backbone transformer that predicts first-layer speech tokens and a smaller decoder transformer that generates subsequent token layers, conditioned on both the backbone’s hidden states and the predicted tokens. This design overcomes the limitations of delay-pattern multi-layer token modeling, providing full contextual access at each timestep and reducing first-packet latency.
The model is trained with a composite loss function combining cross-entropy losses for both transformers and an auxiliary text loss for stability. Decoder optimization is performed on a subset of speech segments to improve efficiency. Curriculum training is employed: large-scale monologue pretraining (1.1M hours), post-training on multi-speaker dialogue (300k hours), and supervised fine-tuning for speaker adaptation.
Downstream Applications
Interactive Chat Integration
FireRedTTS-2 is natively compatible with interactive chat frameworks, supporting sentence-by-sentence generation and real-time streaming. Fine-tuning on a small corpus (15 hours) of emotional speech enables the model to infer and adjust emotion and prosody from implicit context, without explicit emotion labels or LLM modifications. This results in dynamic, contextually appropriate emotional responses, enhancing the naturalness of chatbot interactions.
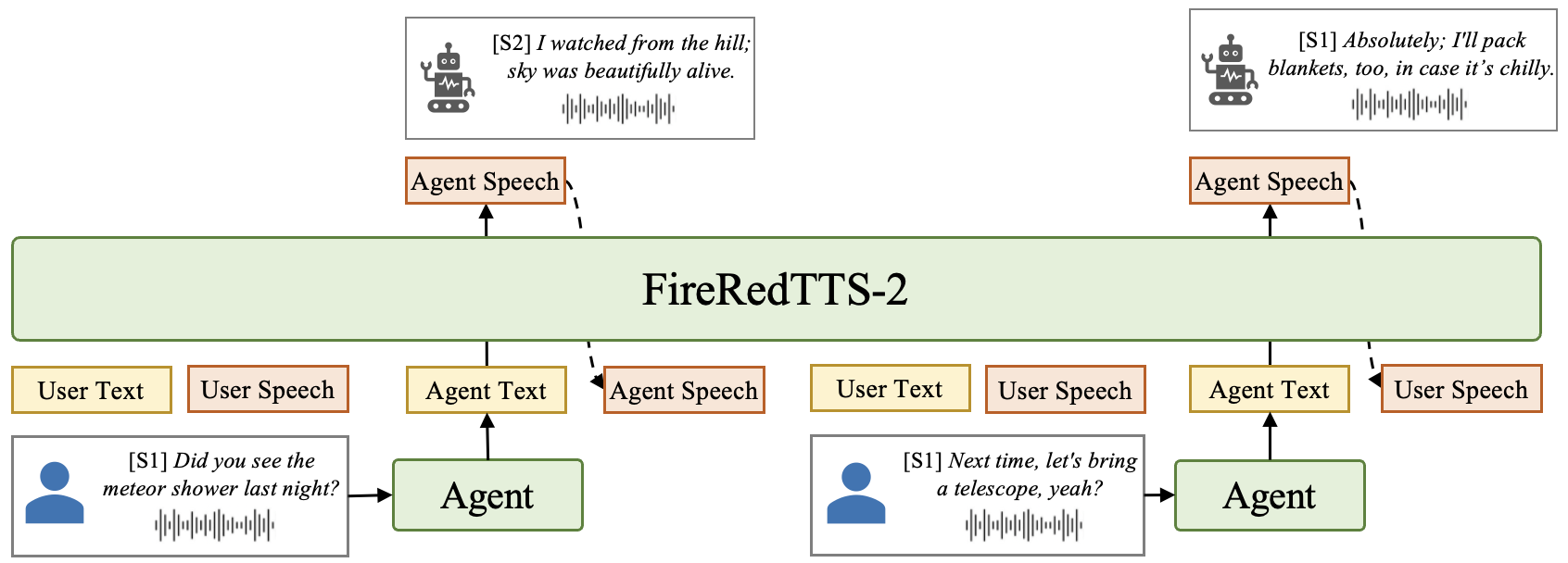
Figure 2: Integration of FireRedTTS-2 into interactive chat scenarios.
Podcast Generation
For podcast synthesis, FireRedTTS-2 generates dialogue speech turn-by-turn, supporting flexible editing and post-processing. Zero-shot podcast generation is achieved by prompting with initial dialogue turns and generating subsequent turns sequentially. The system supports multi-speaker dialogues (up to 4 speakers, 3 minutes) and can be scaled to longer conversations with more speakers via corpus extension. Fine-tuning on 50 hours of podcast data yields stable synthesis, accurate speaker transitions, and prosody matching the hosts’ styles.
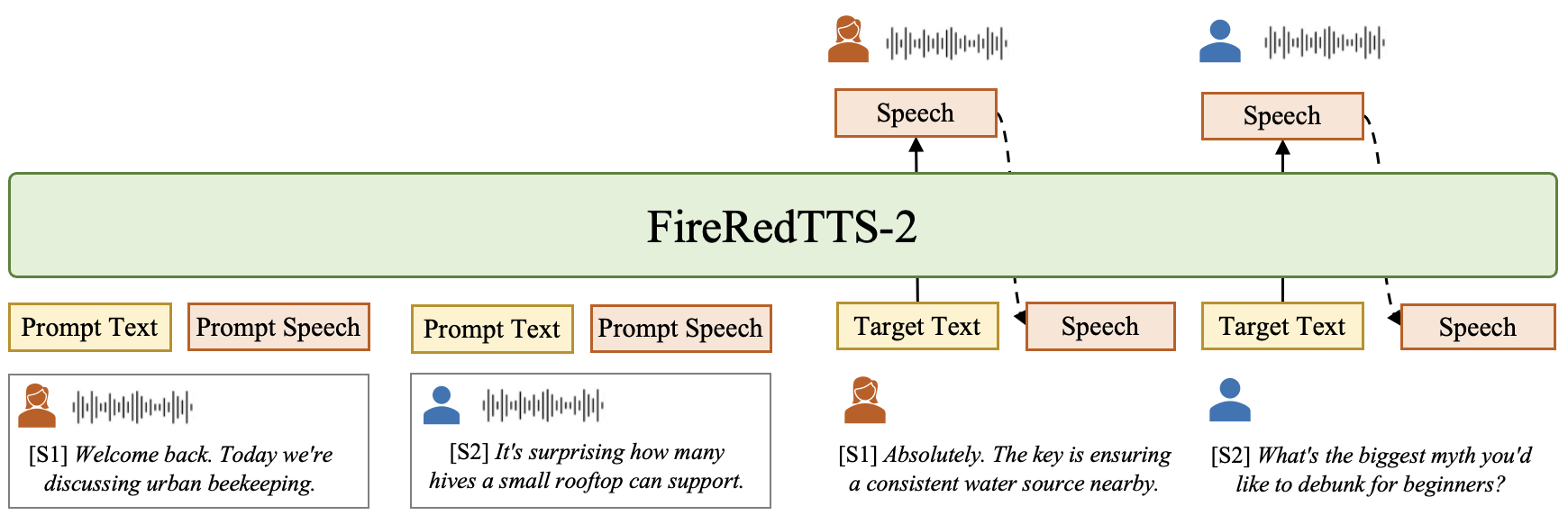
Figure 3: Zero-shot podcast generation of FireRedTTS-2.
Experimental Results
Speech Tokenizer Evaluation
On the LibriSpeech test-clean set, the FireRedTTS-2 tokenizer achieves the lowest WER (2.16%) among semantic-injection tokenizers, and ranks first or second in speaker similarity and speech quality metrics, despite operating at 12.5Hz. The large quantizer and Vocos-based decoder contribute to reduced quantization error and high-fidelity output. The model trails slightly on PESQ and UTMOS compared to systems trained on larger, language-matched corpora, but overall demonstrates robust performance for long-form streaming synthesis.
Voice Cloning
On the Seed-TTS-eval benchmark, FireRedTTS-2 achieves competitive CER (1.14% Mandarin) and WER (1.95% English), closely matching state-of-the-art monologue TTS systems. Speaker similarity is strong in Mandarin, but slightly lower in English, attributed to training data diversity and the absence of dedicated timbre modules. The model’s expressive prosody may also impact objective intelligibility scores.
Interactive Chat Evaluation
Fine-tuned FireRedTTS-2 achieves high emotion control accuracy (76.7–93.3%) across six emotions, demonstrating effective inference of emotional cues from context. This validates the model’s ability to deliver human-like, emotionally expressive chat responses without explicit emotion conditioning.
Podcast Generation
FireRedTTS-2 outperforms MoonCast, ZipVoice-Dialog, and MOSS-TTSD in zero-shot podcast generation, achieving the lowest WER/CER, highest speaker similarity, and lowest MCD on both Mandarin and English test sets. Subjective CMOS scores confirm its superior naturalness and context coherence. Fine-tuning further improves intelligibility (CER 1.66%) and naturalness, with synthesis preferred or indistinguishable from ground truth in 56% of cases.
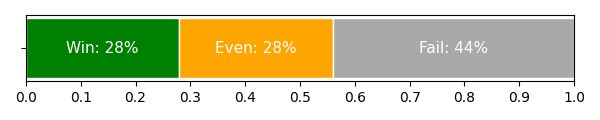
Figure 4: Subjective preference results between FireRedTTS-2 fine-tuned on two podcast speakers and ground truth recordings. "Win": FireRedTTS-2 synthesis is more natural than ground truth dialogue speech; "Even": indistinguishable; "Fail": ground truth is more natural.
Implications and Future Directions
FireRedTTS-2 demonstrates that low-frame-rate, semantically enriched speech tokenization combined with dual-transformer modeling enables scalable, high-quality conversational speech synthesis. The system’s streaming capability and sentence-by-sentence generation are well-suited for real-time interactive applications and long-form content creation. The architecture supports efficient adaptation to new speakers and emotional styles with minimal data, facilitating rapid deployment in diverse scenarios.
Future research may focus on further reducing latency, improving cross-lingual speaker similarity, and extending the system to handle overlapping speech and more complex conversational structures. Integration with multimodal dialogue agents and end-to-end spoken chatbot frameworks is a promising direction, leveraging FireRedTTS-2’s context-aware prosody and flexible generation capabilities.
Conclusion
FireRedTTS-2 advances conversational TTS by combining a low-frame-rate, semantically rich speech tokenizer with a dual-transformer architecture operating on interleaved text–speech sequences. The system delivers stable, natural, and contextually coherent multi-speaker speech, supporting both interactive chat and podcast generation. Experimental results confirm its superiority over existing dialogue TTS systems in intelligibility, speaker-turn reliability, and perceived naturalness, with fine-tuned synthesis matching or surpassing human recordings. FireRedTTS-2 sets a new standard for scalable, real-time conversational speech generation and provides a robust foundation for future dialogue-centric AI applications.

