- The paper's primary contribution is using a state transition adapter to model sequential video states, significantly reducing state and identity errors.
- It employs a dual-path mechanism integrating an instruction-conditioned MLP and temporal cross-attention with residual updates on frozen video-language backbones.
- Empirical results show retrieval accuracy improvements (e.g., from 36.75% to 71.68%) and enhanced identity consistency, demonstrating the model’s practical impact.
CAST: Modeling Visual State Transitions for Consistent Video Retrieval
Motivation and Problem Definition
Conventional video retrieval systems primarily operate using context-agnostic encoders that focus on maximizing local semantic similarity between a query and video candidates. This protocol, while scalable, neglects temporally dependent cues critical for constructing coherent narratives, particularly in procedural domains (e.g., cooking videos, instructional sequences) where state and identity consistency is essential. Standard benchmarks and retrieval models frequently yield “State Errors” (selecting an incorrect procedural step) and “Identity Errors” (switching actors or environments abruptly), resulting in fragmented or causally implausible clip assemblies.
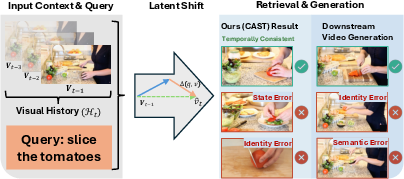
Figure 1: Standard context-agnostic retrieval yields state and identity errors, while CAST predicts causally plausible continuations by modeling state transitions.
To rigorously evaluate the challenge, the authors formalize the Consistent Video Retrieval (CVR) task. In contrast to standard retrieval, CVR introduces negative candidates that are either temporally misaligned (State Negatives) or visually inconsistent (Identity Negatives), given the same procedural context. The diagnostic CVR benchmark encompasses YouCook2, COIN, and CrossTask datasets, with precisely designed negative pools providing fine-grained assessment of state and identity consistency.
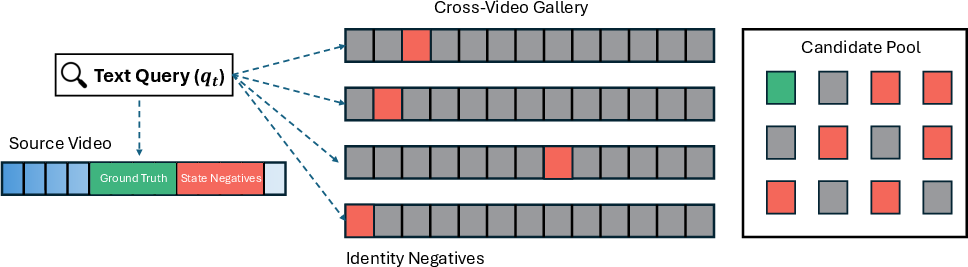
Figure 2: CVR protocol defines state and identity negatives, enabling diagnosis of failures beyond semantic matching.
CAST Model: Context-Aware State Transition Adapter
The CAST architecture is a lightweight, plug-and-play adapter operating atop frozen pre-trained video-language backbones (e.g., CLIP, InternVideo2, VideoPrism, GME-Qwen2). It observes a sequence of prior video states (visual history) and an instruction query, and predicts a latent embedding corresponding to a causally plausible continuation.
The model computes a residual transition vector Δ conditioned on the current visual state and the instruction, yielding an embedding v^t=ϕ(vt−1+Δ(vt−1,qt,Ht)), where vt−1 is the encoding of the last context clip and Ht aggregates recent history. The transition is decomposed into two complementary pathways: (1) an instruction-conditioned MLP coupling vt−1 and the current query, and (2) a temporal cross-attention mechanism for context history, yielding Δ=Δcond+Δctx.
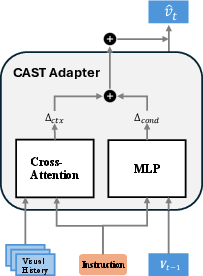
Figure 3: The CAST adapter combines direct state conditioning with history-aware attention for residual transition prediction.
The architecture, by design, injects an inductive bias such that procedural state transitions are modeled explicitly in the embedding space, retaining identity cues via the residual connection. Critically, CAST does not discretize state; rather, it leverages procedural supervision to learn a latent geometry where state is emergent.
Training, Inference, and Diagnostic Protocol
The training uses a type-aware contrastive objective on top of a frozen backbone. For each instance, CAST must score the ground-truth continuation above state and identity negatives, with separate loss terms controlling the emphasis on state (λs) and identity (λi) discrimination. At inference, CAST re-ranks candidate clips by combining: (A) query-text match, (B) visual continuity, and (C) CAST-predicted future-state match, via an ensemble.
A major experimental innovation is in evaluating the model’s capacity to resolve both temporal (state) and visual (identity) ambiguities under controlled negative pools, moving beyond global semantic recall. This protocol exposes the limits of aggregation-based and context-agnostic models, which fail to maintain causal or visual coherence in procedural sequences.
Empirical Analysis
Quantitative Improvements
CAST is evaluated on three benchmarks with diverse video-language backbones. It consistently eclipses context-agnostic (zero-shot) and fusion-based models in both overall retrieval accuracy and in stringent diagnostic measures (State Accuracy and Identity Accuracy). For instance, on the InternVideo2 backbone, accuracy on YouCook2 improves from 36.75% (zero-shot) to 71.68% (+CAST), with similar patterns across VideoPrism and multimodal embedding models. Identity consistency, as measured by performance against hard negatives, also increases from approximately 30% to over 69–78%, indicating robust continuity.
Qualitative Results
Qualitative analysis reveals that context-agnostic retrieval selects semantically relevant clips that are temporally or visually inconsistent, while CAST reliably selects the correct continuation by modeling procedural state transitions.

Figure 4: Context-agnostic retrieval confuses state or identity, while CAST retrieves the causally plausible next step.
Breakdown by Error Type
A detailed breakdown shows CAST yields identity-consistent outcomes in 81% of queries, compared to significant errors from a text-only baseline.
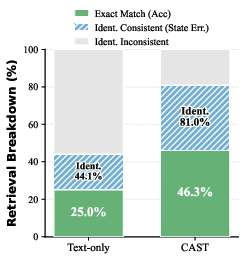
Figure 5: CAST substantially increases the fraction of identity-consistent retrievals over the text-only baseline.
Context Window Ablation
Model performance rises sharply when even a minimal context (L=1) is included, saturating at longer window lengths—supporting that immediate procedural history is most critical for causal prediction.
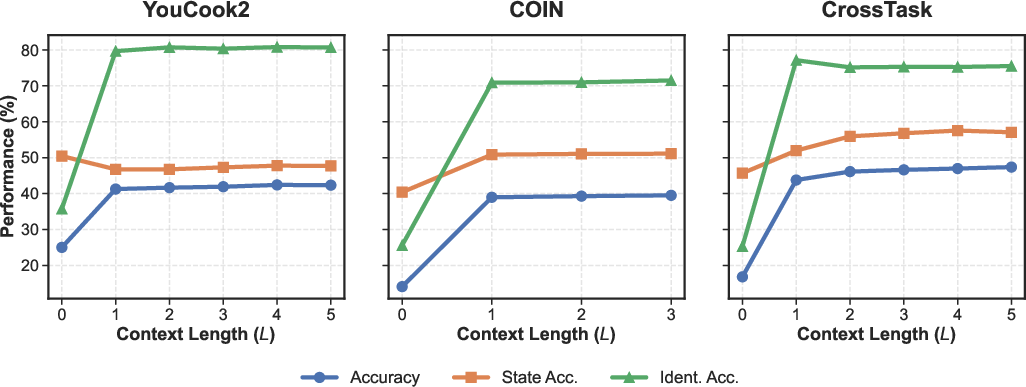
Figure 6: Increasing context window yields diminishing returns beyond L=1; immediate predecessor supplies strong procedural anchor.
Application: Reranking Black-box Video Generation
CAST’s learned transition embedding can be deployed to rerank candidates from black-box generation models (e.g., Veo). In human evaluations on 300 prompts, CAST-reranked outputs are preferred over standard text-matching selections in 55.1% of cases (versus 38.6%), with improvements in both physical plausibility and temporal logic.

Figure 7: CAST reranking promotes more temporally plausible video generation than text-only matching.
The human evaluation protocol provides robust evidence that CAST’s state modeling confers benefits even when underlying video generation is not directly accessible.
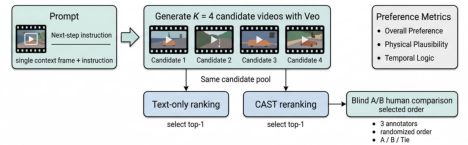
Figure 8: Human A/B protocol for pairwise comparison of CAST vs. text-match reranked generations.
Implications and Future Directions
The CAST framework advances context-aware, causally consistent video understanding by reframing retrieval as a state-conditioned transition modeling problem in latent embedding spaces. The approach is modular, scaling across a spectrum of frozen video-language backbones without retraining the underlying model. Its success signals that injective inductive biases for state evolution are critical for downstream applications including video composition, autonomous agent planning, and instructional video summarization.
The residual update and dual-path transition design could be further optimized by introducing hierarchical or longer-range memory modules for extended procedures, or by regularizing latent transitions to disentangle identity and procedural factors. Adopting CAST for interactive video editing or robotic manipulation tasks could further test its generality in modeling causal sequences.
Conclusion
CAST constitutes a principled, efficient adapter for enforcing temporal and identity continuity in video retrieval under procedural constraints. Through explicit state-transition modeling in latent space, exhaustive diagnostic evaluation, and demonstrated applicability to video generation reranking, CAST provides a robust template for future research focused on causally grounded video understanding and context-aware inference.

