- The paper demonstrates that VLMs perform near random chance on entity tracking tasks when visual shortcuts are removed via VET-Bench.
- It establishes that transformer architectures are theoretically limited (NC¹-complete for k ≥ 5), impeding robust spatiotemporal reasoning.
- The proposed SGCoT paradigm, which uses explicit chain-of-thought reasoning, achieves over 90% accuracy, highlighting its potential for future VLMs.
Spatiotemporal Bottlenecks in Vision-LLMs: An Analysis via the Shell Game
Introduction and Motivation
Human cognition is marked by robust visual entity tracking—the ability to maintain correspondence between indistinguishable objects across occlusion and motion. In contrast, contemporary Vision-LLMs (VLMs), despite impressive advances in general video understanding, display fundamental deficits in this fine-grained spatiotemporal perception. The paper "Can Vision-LLMs Solve the Shell Game?" (2603.08436) systematically dissects these deficits using synthetic diagnostics, theoretical analysis, and architectural mitigation strategies.
The authors argue that, in current video benchmarks, the apparent competence of VLMs at tracking tasks is confounded by visual shortcuts—static frame-level cues or distinctive object appearances—which enable models to bypass genuine reasoning over temporal dynamics. When such shortcuts are obviated, VLMs' entity-tracking abilities are revealed as severely limited.
The VET-Bench Diagnostic: Eliminating Frame-Level Shortcuts
To rigorously evaluate visual entity tracking, the authors introduce VET-Bench, a synthetic benchmark explicitly designed to remove appearance-based cues. Objects are rendered physically and visually identical; task success demands tracking based solely on spatiotemporal continuity through video frames.

Figure 1: Overview of VET-Bench.
Key aspects of VET-Bench's design include:
- Fully synthetic data generation (similar in spirit to CLEVR/CATER pipelines), enabling precise control over object count, swap count, textures, and camera viewpoints, eliminating dataset bias and enabling unlimited task variation.
- Two canonical shell-game settings: "cups game" (track a hidden object under identical cups) and "cards game" (track a face-down card through shuffles and flips).
- Strict continuity constraints, ensuring that object displacement per frame is low enough to guarantee unambiguous tracking absent of occlusion aliasing.
- No single frame—nor any swap operation annotation—provides disambiguating information; entities are indistinguishable except via their temporal trajectories.
Empirical Evaluation: VLMs Collapse to Random-Guessing
A comprehensive suite of SOTA proprietary and open VLMs (e.g., Gemini-3-Pro, Qwen3-VL, GLM-4.6V-Flash, PerceptionLM, Molmo2) was evaluated on VET-Bench. The results are consistent: all models perform at or near random chance on tasks requiring actual entity tracking, regardless of model scale, video sampling rate, or reasoning prompt configuration.
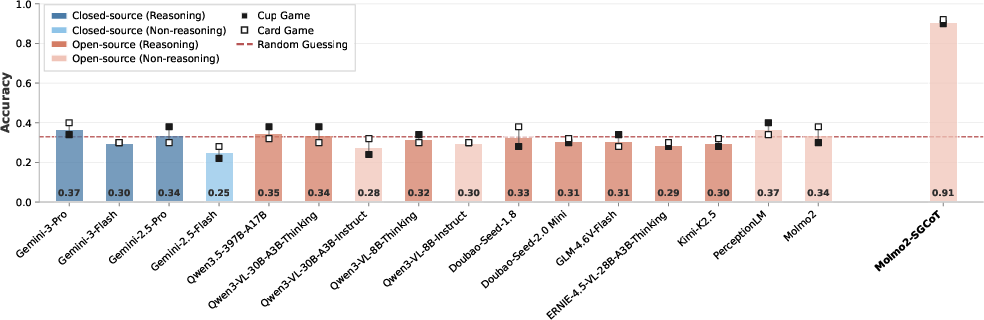
Figure 2: All evaluated VLMs perform near random chance on VET-Bench, with only Molmo2-SGCoT (a fine-tuned variant using spatiotemporal grounded chain-of-thought) exceeding 90%.
Qualitative error analyses reveal three principal failure modes:
- Direct Answer Guessing: Models bypass reasoning or chain-of-thought, submitting a final answer consistent with chance.
- Coarse Semantic Description: Some models provide plausible-sounding event summaries but lack fine-grained entity correspondence, rendering predictions random.
- Hallucinated Reasoning: Advanced VLMs, when prompted for reasoning, generate linguistically and logically coherent swap sequences that are visually incorrect, as evidenced by misidentified or phantom swaps.
Furthermore, performance degrades sharply with just a single swap and never recovers as task complexity (swap or object count) increases.
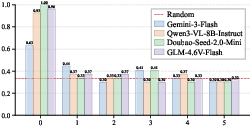
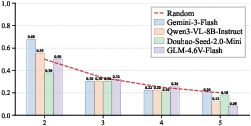
Figure 3: Performance degrades as swap count increases, converging to random chance rapidly.
Benchmark Comparison: Revealing Shortcut Reliance
Analysis of popular "shell game" benchmark datasets (e.g., Perception Test, VideoReasonBench) demonstrates that prior evaluations substantially overestimate VLMs' entity-tracking capabilities due to shortcut exploits:
- Appearance Cues: In Perception Test, transparent or distinctive cups/cards allow trivial frame-based solution strategies.
- Swap Annotations: VideoReasonBench overlays explicit swap cues (e.g., arrows), collapsing tracking into a static token-matching task rather than dynamic reasoning.
Applying rigorous filtering to Perception Test (limiting to identical, opaque cups and excluding non-shuffling cases) yields a marked drop in VLM accuracy—to baseline—mirroring VET-Bench findings.


Figure 4: Example frames from videos involving distinct cups in the Perception Test. Visual shortcut cues allow appearance-based problem solving, bypassing entity tracking.


Figure 5: Example frames from videos involving transparent cups, similarly undermining the requirement for temporal reasoning.


Figure 6: Visual shortcuts in real-world data—frames explicitly reveal the answer without requiring temporal tracking.
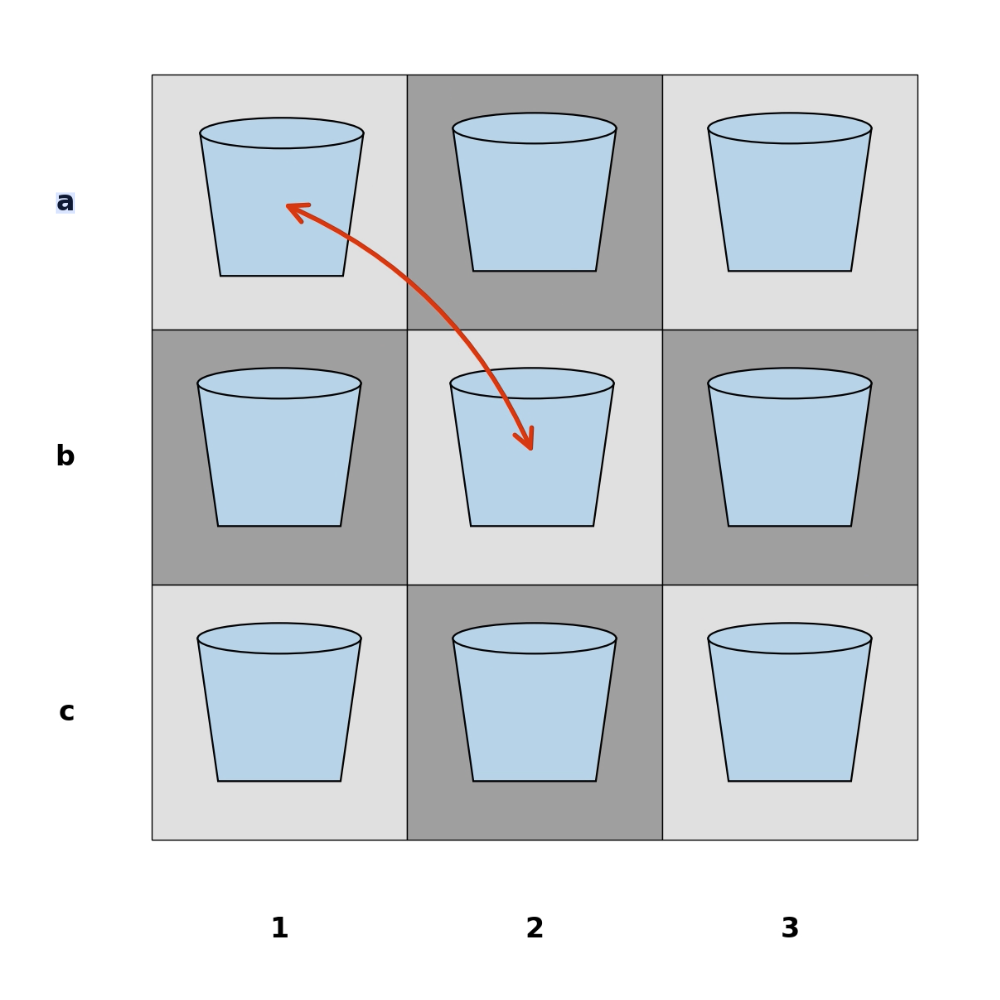

Figure 7: VideoReasonBench provides frame-level swap cues (arrows, left), absent in VET-Bench (right), thus failing to isolate genuine spatiotemporal reasoning.
A key theoretical contribution is the proof that visual entity tracking for k≥5 indistinguishable objects on the grid is NC¹-complete. This situates the problem at a level of circuit complexity that fixed-depth transformer architectures cannot, in principle, solve over sequences of arbitrary length without intermediate computation.
Key points of the analysis:
- Tracking the permutation of k objects after T arbitrary transpositions (swaps) is reducible to the word problem for the symmetric group Sk, known to be NC¹-complete for k≥5.
- Transformers of bounded depth are strictly less expressive (TC⁰; i.e., limited to problems solvable by constant-depth majority circuits) and thus insufficient for representing or learning state-tracking tasks unless augmented by explicit intermediate-state supervision or chain-of-thought (CoT) reasoning [merrill2024illusion, li2024chain, huang2025transformers].
- Empirical training of transformers (Qwen2.5-VL-3B-Instruct) with direct-answer supervision does not overcome this limitation—the loss quickly plateaus at random-guessing levels despite sufficient training epochs, paralleling classic failures to learn parity.
Spatiotemporal Grounded Chain-of-Thought (SGCoT): Overcoming Perceptual Bottlenecks
The authors propose and validate Spatiotemporal Grounded Chain-of-Thought (SGCoT): requiring the model to explicitly generate entity trajectories as an ordered collection of spatial coordinates indexed by timestamps—prior to giving the final answer.
SGCoT implementation involves:
- Utilizing the native object-tracking capabilities of Molmo2, which outputs per-frame coordinates for object identities.
- Fine-tuning Molmo2 (Molmo2-SGCoT) on synthetic text-only samples that scaffold object tracking as an explicit reasoning step, but supervising only the final answer via lightweight QLoRA parameter updates.
- Prompting in the QA phase to elicit explicit spatial chain-of-thought, leveraging the generated trajectory to support or directly produce the answer.
This approach demonstrates state-of-the-art accuracy exceeding 90% on VET-Bench, with rapid, data-efficient training (one epoch, 300 samples, single GPU, <3 minutes)—substantially outperforming all tested baselines.
Analysis of the SGCoT Paradigm
SGCoT's success is linked to:
- Fine-grained, temporally aligned state representation: Discrete trajectories capture all event transitions at sufficient resolution, avoiding the temporal misalignment and underspecification endemic to coarse or purely linguistic CoTs.
- Robustness to sequence length and complexity: Explicit tracking scales with task difficulty, as the intermediate state at each timestamp provides a direct path to the answer.
- Interpretability and Error Localization: Mistakes in SGCoT outputs manifest as detectable spatial "jumps" or inconsistencies, improving model transparency and failure diagnosis.
Remaining failure cases for SGCoT are localized primarily to perception-stage errors (identity confusion among visually identical entities), especially under conditions of fast swaps or near-overlap, but are dramatically reduced compared to non-tracking approaches.
Practical and Theoretical Implications
- Benchmark Recommendations: Diagnostic benchmarks must excise static frame-level shortcuts to truly evaluate VLMs' spatiotemporal grounding and reasoning.
- Architecture/Training Design: Without explicit intermediate computations, transformer-based VLMs are fundamentally ill-equipped to solve rich spatiotemporal state-tracking tasks, a limitation that must be addressed via architectural modifications (e.g., chained reasoning, explicit persistent memory) or sophisticated supervision regimens (e.g., annotated CoT).
- Future Directions: Extending SGCoT to real-world videos with occlusion, ambiguous referring expressions, localization noise, or physical interactions (e.g., agentic manipulation) is an important future direction; integration with world-modeling priors and causal reasoning remains a critical open problem.
Conclusion
The investigation presented in this paper provides a rigorous, multifaceted diagnosis of visual entity tracking bottlenecks in current VLMs. By developing VET-Bench and removing visual shortcuts, the authors expose the stark limitations of SOTA models, theoretically anchoring these deficits in expressivity gaps of transformer architectures. The proposed SGCoT paradigm effectively bridges this gap, demonstrating that with appropriate intermediate state reasoning, VLMs can approach human-level entity tracking in constrained synthetic domains. These findings carry significant implications for the design and evaluation of next-generation video-language systems, especially for applications in embodied AI and interactive agents requiring robust, compositional state tracking over high-dimensional perceptual streams.