Tracking and Understanding Object Transformations
Abstract: Real-world objects frequently undergo state transformations. From an apple being cut into pieces to a butterfly emerging from its cocoon, tracking through these changes is important for understanding real-world objects and dynamics. However, existing methods often lose track of the target object after transformation, due to significant changes in object appearance. To address this limitation, we introduce the task of Track Any State: tracking objects through transformations while detecting and describing state changes, accompanied by a new benchmark dataset, VOST-TAS. To tackle this problem, we present TubeletGraph, a zero-shot system that recovers missing objects after transformation and maps out how object states are evolving over time. TubeletGraph first identifies potentially overlooked tracks, and determines whether they should be integrated based on semantic and proximity priors. Then, it reasons about the added tracks and generates a state graph describing each observed transformation. TubeletGraph achieves state-of-the-art tracking performance under transformations, while demonstrating deeper understanding of object transformations and promising capabilities in temporal grounding and semantic reasoning for complex object transformations. Code, additional results, and the benchmark dataset are available at https://tubelet-graph.github.io.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers to follow an object in a video even when that object changes shape or looks very different over time. Think of an apple being sliced into pieces or a butterfly coming out of a chrysalis. The authors introduce a new task called “Track Any State,” where a system must:
- keep tracking the object through its transformation, and
- detect and describe what changed, when it changed, and what new pieces or results appeared.
They also create a new dataset for this task and present a new method, called TubeletGraph, to solve it.
What questions are the researchers asking?
The paper focuses on two easy-to-understand questions:
- When an object changes and looks different, how can a computer find and keep tracking it without getting confused or losing it?
- How can the computer explain what changed (for example, “the apple was sliced,” “the foil was pulled out of the box”), and what the end result looks like?
How does their method work?
The method is called TubeletGraph. It has three main ideas. Below, technical words are explained in everyday language:
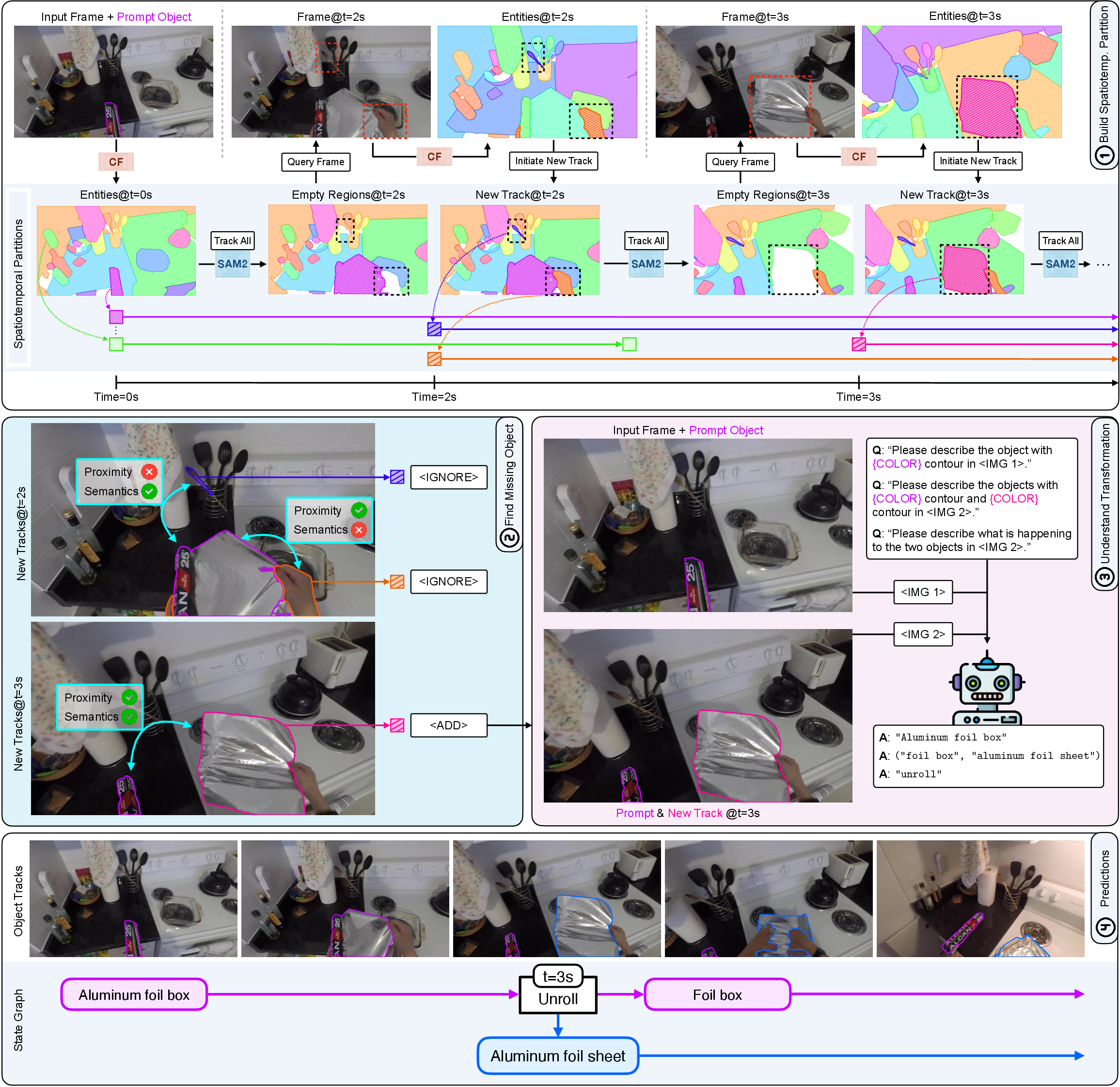
- Break the video into manageable pieces: The system divides the video into many small, trackable regions over space and time, called “tubelets.” A tubelet is like a mini video path that follows one patch or piece through time. This “spatiotemporal partition” reduces the search from “any pixel in any frame” to “which tubelet is the object or its new parts.”
- Analogy: Imagine the video as a giant jigsaw puzzle that changes as you watch. Tubelets are like puzzle pieces that the system keeps an eye on as they move or change.
- Decide which tubelets are actually part of the original object after it changes: The system uses two simple clues:
- Spatial proximity (the “where” clue): Is the new piece near where the original object was? For example, a butterfly appears close to its chrysalis.
- Semantic consistency (the “what” clue): Does the new piece still look like it belongs to the same kind of thing? For example, sliced apple pieces still match the “apple” category more than a human hand would.
- To check “what,” the system uses a model called CLIP, which is like a picture–word dictionary that compares visual features with meanings.
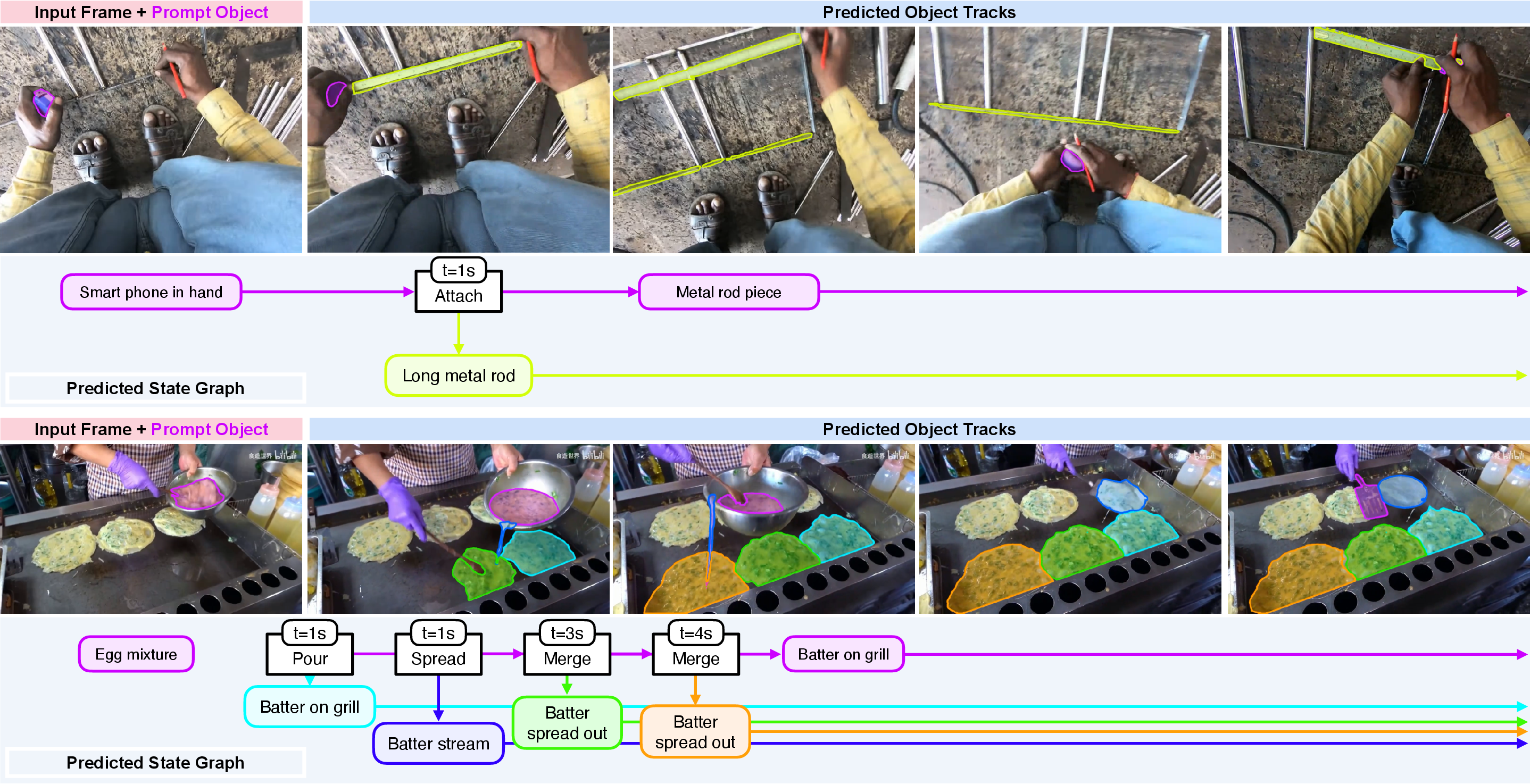
- Describe the change and build a “state graph”: When the system finds new pieces that likely came from the original object, it marks that moment as a transformation and asks a multimodal LLM (like GPT-4) to describe what happened in plain language. Then it builds a “state graph,” which is a simple map showing:
- the time of the change,
- which track(s) were “before” and which were “after,” and
- a short description of the change and the new objects.
- Analogy: A state graph is like a comic strip timeline that labels each major event and shows what the object turned into.
Under the hood, TubeletGraph uses:
- an “entity segmentation” tool (CropFormer) to find regions in frames,
- a strong video tracker (SAM2) to follow those regions over time,
- CLIP for comparing visual meaning,
- and GPT-4 to write short descriptions of the transformations.
All parts are pre-trained, so TubeletGraph works “zero-shot” (without training on this specific task).
What did they find, and why does it matter?
Here are the main results:
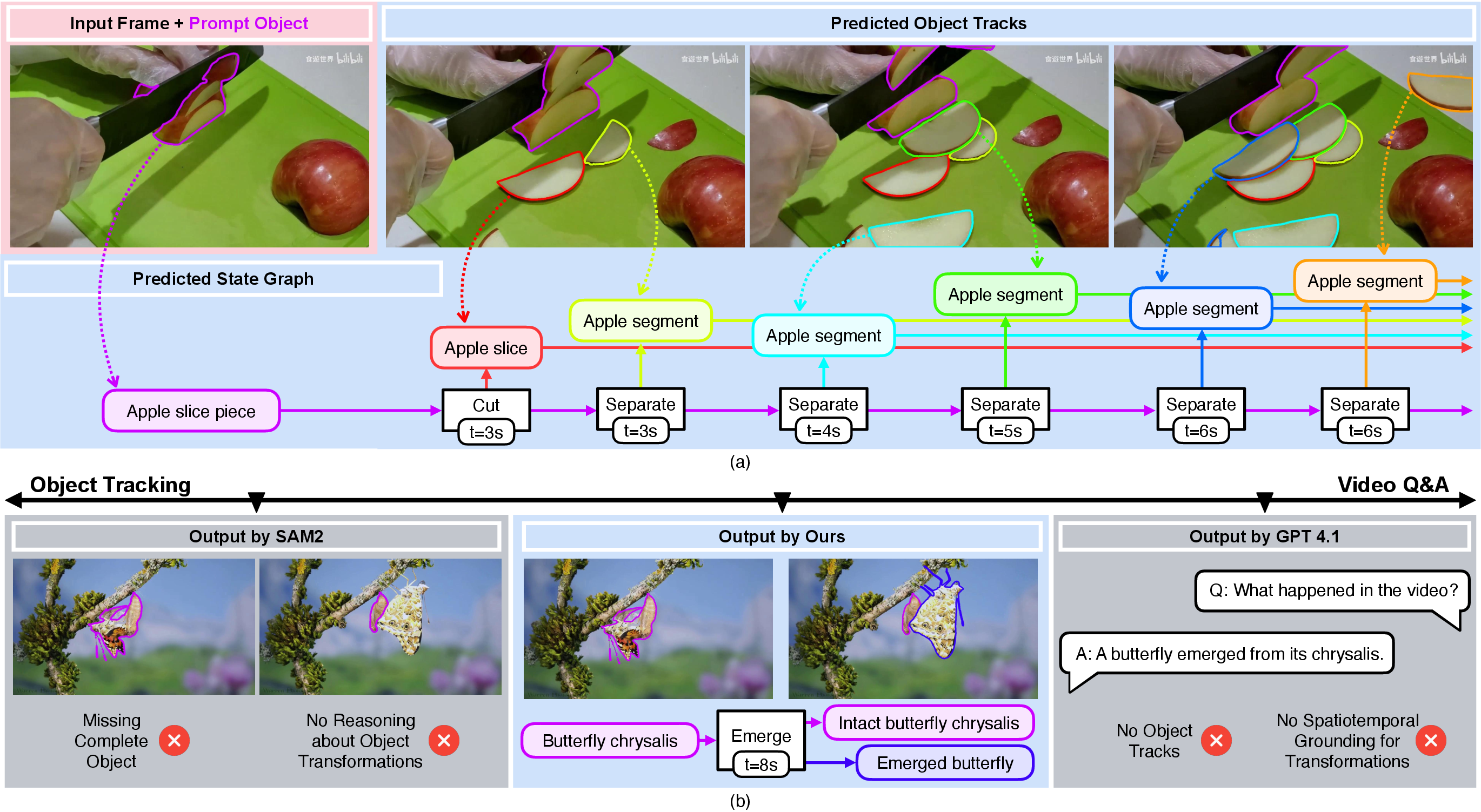
- Better tracking through changes: When objects change a lot (like splitting into parts or looking very different), TubeletGraph recovered more missing pieces and kept tracking them more consistently than other popular trackers.
- Detects and describes transformations: It doesn’t just follow objects—it also detects when a transformation happens and explains it (e.g., “pulling a sheet of foil out of a box” and identifying the new foil sheet).
- New benchmark: They introduce VOST-TAS, a dataset with 57 video instances, 108 transformations, and 293 labeled resulting objects. This helps the research community test future methods on the same task.
- General performance: TubeletGraph performs strongly on challenging transformation datasets (VOST, VSCOS), and stays competitive on standard tracking datasets where objects don’t change much (DAVIS), meaning it adds new skills without breaking the basics.
Why it’s important:
- Real-world tasks often involve change. Robots in kitchens need to know where the sliced pieces went; wildlife monitors must track a butterfly when it appears; video editors and AR apps need clean, grounded object timelines. TubeletGraph moves tracking closer to the way humans understand actions and results over time.
What’s the impact and what are the limitations?
Impact:
- Robotics: Helps robots understand “before” and “after” states so they can plan actions (like cutting, assembling, or sorting).
- Wildlife and science: Helps identify and count animals during life-cycle changes (like metamorphosis).
- Video tools and AR: Enables better editing and scene modeling by mapping what changed and where.
- Training and analysis: Can generate rich labels for recorded videos, useful for learning and auditing tasks.
Limitations:
- Speed: Building and tracking all those tubelets is computationally heavy (around several seconds per frame on a high-end GPU), so it’s not real-time yet.
- Missed transformations: If the object doesn’t visibly change (so the tracker never loses it), the system may not mark a “transformation” event; recall for detecting all transformations is still modest.
- Complex errors: Because the system has several parts, it can be harder to pinpoint exactly which module caused a mistake.
Overall, TubeletGraph shows a promising step toward tracking objects the way people think about them—across changes, with clear explanations of what happened and where.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Transformation detection is passive and tied to recovery events: the system only flags a transformation when a false negative is recovered, missing appearance-preserving or gradual changes; developing proactive event-boundary detectors (e.g., based on appearance change metrics, motion/optical flow, audio cues, and temporal segmentation) is needed to raise recall beyond the current 20.4%.
- Heavy reliance on external, closed and domain-biased components (SAM2.1, CropFormer, CLIP, GPT‑4.1): robustness under domain shift (e.g., wildlife metamorphosis, industrial assembly) is untested; replacing GPT‑4.1 with open VLMs sharply degrades semantic accuracy, indicating a need for integrated, trainable modules or distillation strategies that maintain performance without closed models.
- Heuristic scoring and thresholds: proximity and semantic thresholds are hand-tuned on VOST train and fixed across datasets; learning adaptive, data-driven scoring functions (with calibration and uncertainty estimates) would likely improve generalization and reduce sensitivity to dataset biases.
- Spatial proximity constraint is fragile under large displacements: overlap with SAM2’s candidate masks at appearance time can fail when objects are carried far away or reappear after occlusion; incorporating motion/flow, 3D scene geometry, kinematic constraints, or trajectory-level proximity would address such cases.
- Semantic consistency via masked CLIP features may fail for genuine identity changes: transformations like chrysalis→butterfly alter semantics considerably and may have low CLIP similarity to the precondition; a learned ontology of state changes with category-level priors and attribute-level continuity could better handle legitimate semantic shifts while rejecting distractors.
- Partition quality is bottlenecked by entity segmentation: the approach assumes CropFormer can produce accurate spatial partitions; under-/over-segmentation and translucency/specular materials (e.g., foil, glass) degrade coverage; improving partitioning with multimodal cues, geometry, or adapting segmentation to thin/small parts is needed.
- Arbitrary size cutoff excludes small fragments: ignoring entities smaller than 1/25² of the frame misses crumbs, shavings, droplets, and other realistic transformation byproducts; methods to track and reason about small, thin, and low-contrast entities are required.
- Runtime and scaling: ~7 seconds per frame (RTX A6000) limits long videos and multi-object scenarios; exploring incremental/sparse partitioning, hierarchical coarse-to-fine search, caching, and model compression is necessary for practical deployment on hour-long sequences or multi-camera setups.
- Handling merges and multi-stage transformations is underdeveloped: while the state graph permits sets of pre/post tracks, the pipeline lacks explicit detection of merges, repeated transformations, or overlapping events; algorithms that track many-to-one/one-to-many mappings and multi-step causal chains are needed.
- State graph construction and parsing are brittle: free-form VLM text lacks canonicalization, synonym handling, or a controlled vocabulary; building a formal ontology (verbs, object states, attributes), structured prompting, and robust parsing/matching (with disambiguation and confidence) would improve reliability.
- Temporal grounding is point-like rather than interval-aware: the system marks a single start frame for each recovered object, but transformations extend over intervals; modeling durations and progression (e.g., spatially-progressing changes as in WhereToChange/SPOC) could capture continuous processes and improve temporal recall.
- Evaluation coverage and dataset scope are limited: VOST‑TAS is small (57 instances, 108 transformations), sourced from egocentric kitchen scenarios; broader and denser annotations (including precondition masks, intermediate states, multi-object interactions, and diverse domains like wildlife/manufacturing) are needed to stress-test generalization.
- Metric design needs refinement: verb/object accuracy depends on matching criteria (synonymy, granularity), and overall recall (6.5%) conflates localization and semantic description; standardized ontologies, synonym resolution, and separate calibration-aware metrics would yield more informative assessments.
- Ambiguity and uncertainty are not modeled: the pipeline makes deterministic selections (max similarity/overlap) without confidence scores or probabilistic reasoning; introducing uncertainty estimation and marginal reasoning over candidate tubelets and semantic labels could reduce brittle decisions.
- Occlusion, crowding, and fast motion robustness is not systematically studied: while SAM2 variants target these issues, TubeletGraph’s recovery/filtering under heavy occlusion or crowded scenes remains underexplored; targeted benchmarks and stress tests would clarify failure modes.
- Multi-object, relational, and tool-mediated transformations: the method tracks a single prompted object; many real transformations involve multiple interacting objects (tools, containers, agents) and relational constraints; extending to joint, relational tracking and causal reasoning across multiple entities is an open direction.
- Multimodal cues beyond RGB are unused: audio (cutting, pouring) or text instructions could signal transformations; integrating multimodal event cues may improve boundary detection and semantic grounding.
- Reproducibility and accessibility: dependence on GPT‑4.1 hampers exact reproduction; an open, reproducible alternative with comparable performance and detailed parsing rules would improve community adoption.
- Downstream utility of the state graph is unvalidated: while motivated by robotics/action grounding, using the graph for planning, pre-/post-condition checking, and closed-loop task execution is not demonstrated; controlled robotic benchmarks linking the predicted graph to actionable policies would substantiate impact.
Practical Applications
Immediate Applications
The following applications can be deployed today as offline or batch-processing workflows, leveraging the zero-shot TubeletGraph pipeline (SAM2 + CropFormer + CLIP + GPT-4) and the VOST-TAS benchmark.
- Transformation-aware video annotation and dataset bootstrapping
- Sector(s): Academia, Robotics (R&D), Software/ML tooling
- Tools/Products/Workflows:
- “Transformation Annotator” that auto-generates spatiotemporal masks, event time-stamps, and a state graph from raw video with a single initial mask prompt.
- Batch annotation of robot demonstration videos (e.g., slicing, folding, assembling) to produce training data for manipulation policies.
- Export to COCO/MaskTrack JSON and graph schemas for downstream training; human-in-the-loop validation UI.
- Assumptions/Dependencies:
- Offline GPU compute (≈7 sec/frame reported).
- Access to SAM2, CropFormer, CLIP, and a multimodal LLM (e.g., GPT-4) for descriptions.
- Initial mask prompt provided by an annotator; works best when transformations cause visible appearance changes.
- Transformation markers for non-linear video editing (NLE) and post-production
- Sector(s): Media/Content creation, Software
- Tools/Products/Workflows:
- NLE plugin that auto-inserts timeline markers at transformation boundaries (e.g., “apple cut into slices”), generates per-object tracks, and creates smart selections for mask-based effects.
- “Find transformations” search to jump to specific steps (cut, peel, fold) across long-form videos.
- Assumptions/Dependencies:
- Offline indexing step; not real-time.
- Most effective for clear, visible state changes; user supplies initial object mask.
- Wildlife camera-trap post-processing for metamorphosis and lifecycle events
- Sector(s): Conservation/Wildlife ecology, Policy (environmental monitoring)
- Tools/Products/Workflows:
- Automated discovery of events like “butterfly emerges from chrysalis,” with object tracks before/after.
- Batch analytics over large archives to quantify timing, success rates, or spatial patterns of emergence.
- Assumptions/Dependencies:
- Camera framing and visibility sufficient to see appearance changes.
- Domain shift may require calibration (e.g., species diversity, lighting).
- Manufacturing and compliance video audits (offline)
- Sector(s): Manufacturing, Quality assurance, Policy/Compliance
- Tools/Products/Workflows:
- Post-hoc analysis of recorded shifts to verify that required transformation steps occurred (assemble, seal, package, cut, mix).
- Generates state graphs per SKU/batch with timestamps for compliance logs and exception review.
- Assumptions/Dependencies:
- Works best with fixed camera viewpoints and good visibility.
- Offline pipeline; not designed for real-time alerts.
- Initial mask prompt per tracked part/product or batched per line.
- Procedural content authoring for training and instruction
- Sector(s): Education/Training, Enterprise L&D, AR content creation
- Tools/Products/Workflows:
- Convert how-to videos (lab demos, DIY, cooking) into step-wise state graphs with aligned visual segments.
- Export as step cards with timestamps, object masks, and short natural-language descriptions.
- Assumptions/Dependencies:
- Accurate step detection depends on visible appearance changes; ambiguous steps may need manual edits.
- Requires initial object prompt(s); best as semi-automatic authoring aid.
- Forensic and security video review (post-incident)
- Sector(s): Security, Insurance, Risk assessment
- Tools/Products/Workflows:
- Offline tracing of object state changes (e.g., packaging opened, seal broken) with spatial grounding.
- Summarized event timelines for investigators; supports claims validation.
- Assumptions/Dependencies:
- Ethical and legal use of video data; privacy considerations.
- Reliability may degrade under heavy occlusions or poor image quality.
- Benchmarking and method development using VOST-TAS
- Sector(s): Academia, Research labs
- Tools/Products/Workflows:
- Use VOST-TAS as a standard to evaluate joint tracking+transformation understanding.
- Compare zero-shot methods vs. finetuned baselines; advance temporal localization and semantic description metrics.
- Assumptions/Dependencies:
- Researchers accept the task protocol (initial mask prompt, transformation evaluation criteria).
- Benchmarks emphasize egocentric and household transformations; other domains may need new splits.
- Multi-object batch tracking with tubelet partition amortization
- Sector(s): Software/ML tooling, Robotics (R&D)
- Tools/Products/Workflows:
- Reuse the spatiotemporal partition for multiple objects to amortize compute costs while indexing a video once.
- Produce per-object state graphs in a single pass for large annotation jobs.
- Assumptions/Dependencies:
- Sufficient compute; stable API access to base models (SAM2, CLIP, LLM).
Long-Term Applications
The following require further research, speedups, reliability improvements, domain adaptation, or tighter system integration.
- Real-time transformation-aware perception for manipulation robots
- Sector(s): Robotics (home, kitchen, industrial)
- Tools/Products/Workflows:
- On-robot modules that track tools, materials, and products through cuts, folds, and assemblies; feed state graphs into planners/policies.
- Closed-loop monitoring of pre/post-conditions (e.g., “dough is divided,” “lid sealed”).
- Assumptions/Dependencies:
- Significant acceleration (from ≈7 sec/frame to real-time), robustness to occlusions and distractors, and reduced reliance on large VLMs.
- Broader detection beyond appearance change (touch, force, intent cues).
- Live AR assistants that track task progression and coach users
- Sector(s): AR/VR, Consumer electronics, Education/Training
- Tools/Products/Workflows:
- AR glasses/phone apps that overlay step completion and next actions by tracking object states.
- Dynamic guidance that adapts to deviations (e.g., “slice completed; now sauté”).
- Assumptions/Dependencies:
- Real-time inference on-device or low-latency edge compute; reliable temporal localization for subtle transformations.
- Safety and privacy by design; robust to diverse environments.
- Factory floor real-time monitoring and digital twins
- Sector(s): Manufacturing, Industrial IoT
- Tools/Products/Workflows:
- Integrate transformation tracking into MES/SCADA to update digital twin states (assembled, sealed, tested) in real-time.
- Trigger alerts when mandatory transformations are missing or out-of-order.
- Assumptions/Dependencies:
- Industrial-grade robustness, low false alarms, certified reliability.
- Cross-camera re-identification and multi-view fusion; explainability.
- Surgical step and instrument state tracking
- Sector(s): Healthcare
- Tools/Products/Workflows:
- Track surgical instruments and tissue states across steps, with state graphs for post-op review and training.
- Quality metrics and protocol adherence checks.
- Assumptions/Dependencies:
- Domain adaptation to endoscopic/microscopic views; stringent accuracy/latency and regulatory approval.
- Privacy-preserving deployment and thorough validation.
- Transformation-grounded video QA and explainable assistants
- Sector(s): Software/AI assistants, Education
- Tools/Products/Workflows:
- Integrate state graphs into multimodal QA to answer “what changed, when, and where” with visual grounding.
- Explanations backed by event timelines and masks for transparency.
- Assumptions/Dependencies:
- Improved temporal recall; tighter coupling with VLMs; standardized grounding interfaces.
- Physically consistent generative video editing and synthesis
- Sector(s): Media/Entertainment, Creative tools
- Tools/Products/Workflows:
- Use state graphs to constrain generative edits so that transformations (cut, pour, fold) remain consistent over time and space.
- Automatic retiming or inpainting that preserves object identity across state changes.
- Assumptions/Dependencies:
- Mature coupling between tracking/state graphs and video diffusion models; user controls for semantic constraints.
- Large-scale wildlife and agriculture analytics
- Sector(s): Environmental monitoring, Agriculture
- Tools/Products/Workflows:
- Automated measurement of metamorphosis, growth stages, or harvest transformations from field cameras.
- Population or yield-level metrics derived from aggregated state graphs.
- Assumptions/Dependencies:
- Domain adaptation across species/crops, weather, lighting; ID across long timespans; scalable infrastructure.
- Cargo and asset state monitoring for logistics and safety
- Sector(s): Logistics, Transportation, Safety
- Tools/Products/Workflows:
- Detect and track load/unload, seal breaks, palletization changes; update chain-of-custody records with event evidence.
- Exception handling with grounded video snippets.
- Assumptions/Dependencies:
- Multi-camera, multi-agent scenes; robust performance under occlusion; policy-compliant recording and storage.
- Household autonomy with persistent object understanding
- Sector(s): Consumer robotics, Smart home
- Tools/Products/Workflows:
- Robots that persistently track household items through transformations (folded clothes, chopped vegetables) to maintain accurate world state and plan tasks.
- Assumptions/Dependencies:
- Reliable open-world semantics in clutter, memory over long horizons, edge compute efficiency.
Common Assumptions and Dependencies Across Applications
- Initial mask prompt is required; scalable prompting (e.g., from detection or text query) would improve usability.
- Current system is optimized for offline processing; real-time applications depend on substantial acceleration and engineering.
- Transformation detection is triggered mainly by appearance changes; many domain-specific transformations (e.g., temperature, chemical state without visual change) will need additional sensing or learned cues.
- Semantic reasoning depends on general-purpose vision-LLMs (e.g., GPT-4/CLIP); domain adaptation may be necessary for medical, industrial, or wildlife niches.
- Data governance: recording, processing, and storing video must comply with privacy and regulatory requirements.
- Compute and cost considerations (GPU time, VLM API usage) affect deployment at scale.
Glossary
- action-grounding: linking natural-language descriptions of actions to specific objects and events in video. "action-grounding~\cite{regneri2013grounding, yang2020grounding}"
- augmented reality: technology overlaying digital information onto real-world scenes. "scene modeling for augmented reality~\cite{monst3r}"
- attention-based memory reading: using attention to retrieve relevant past features from memory for consistent tracking. "attention-based memory reading~\cite{xmem, oh2018fast, oh2019video, yang2020collaborative, yang2021associating, cutie}"
- box-level annotations: labels that mark objects with bounding boxes instead of segmentation masks. "DTTO~\cite{wu2024tracking} provides box-level annotations for transforming objects"
- CLIP: a vision-LLM that learns joint image-text representations for zero-shot transfer. "CLIP~\cite{clip} learns visual concepts from natural language captions via contrastive learning."
- constrained tree search: maintaining multiple hypotheses in a restricted search tree to mitigate error accumulation. "SAM2Long~\cite{sam2long} extends SAM2 and addresses error accumulation in long videos by maintaining multiple candidate tracks in a constrained tree search."
- contrastive learning: training method that pulls similar pairs together and pushes dissimilar pairs apart in embedding space. "via contrastive learning."
- CropFormer: an entity segmentation model used to partition frames into regions. "we first adopt an entity segmentation model, CropFormer (CF)~\cite{cropformer}"
- distractor-resolving memory: memory mechanism designed to handle visually similar but irrelevant objects. "DAM4SAM~\cite{dam4sam} introduces a distractor-resolving memory to handle visually similar distractors."
- ego-centric: first-person viewpoint videos capturing interactions and transformations. "ego-centric datasets~\cite{ek100, ego4d}"
- embedding space: continuous vector space where images and texts are represented for similarity and retrieval. "From a shared embedding space for image and text, it enables zero-shot transfer to downstream tasks."
- entity segmentation: pixel-level delineation of distinct entities within an image. "we first adopt an entity segmentation model, CropFormer (CF)~\cite{cropformer}"
- event boundaries: temporal points indicating transitions between meaningful events in a video. "event boundaries~\cite{zacks2007event}"
- FC-CLIP: method for open-vocabulary segmentation using a frozen CLIP backbone. "FC-CLIP~\cite{fcclip} further demonstrates this capability by predicting open-vocabulary segmentation using a frozen CLIP backbones."
- finetuning: adapting a pretrained model to a target dataset/task through additional training. "prior works have mostly relied on appearance similarities via online feature finetuning~\cite{bhat2020learning, caelles2017one, maninis2018video}"
- GPT-4: a multimodal LLM capable of visual and textual reasoning. "multi-modal LLMs such as GPT-4~\cite{gpt4} and Gemini~\cite{team2024gemini} can reason about the visual/textual queries"
- interactive video segmentation: segmentation guided by user prompts to track objects across frames. "extend Segment Anything Model (SAM)~\cite{segmentanything} for interactive video segmentation."
- IoU: Intersection over Union; overlap metric between predicted and ground-truth regions. "IoU "
- mask-pooling: pooling features within a mask to obtain region-specific embeddings. "via mask-pooling~\cite{fcclip}"
- memory-attention mechanisms: attention over temporal memory to establish correspondences across frames. "By incorporating a memory-attention mechanisms, SAM2 enables object tracking by establishing consistent temporal object correspondences."
- motion-based memory selections: selecting memory frames using motion cues to handle complex scenes. "SAMURAI~\cite{samurai} introduces motion-based memory selections to handle crowded scenes with fast-moving or self-occluded objects."
- multi-modal LLMs: LLMs that process both visual and textual inputs for reasoning. "multi-modal LLMs~\cite{gpt4} can reason about the visual/textual queries and generate natural language responses"
- open-vocabulary segmentation: segmentation that recognizes categories beyond a fixed label set using language supervision. "predicting open-vocabulary segmentation using a frozen CLIP backbones."
- open-world localization: locating objects or states without restricting to a predefined category set. "HowToChange~\cite{oscs} focuses on open-world localization of three stages (initial, transitioning, and end states) of object transformation."
- optical flow: estimation of pixel-wise motion across consecutive video frames. "optical flow~\cite{raft}"
- paired t-test: statistical test comparing paired measurements to assess significance of differences. "we obtain p-values of $0.026$ for from a paired t-test"
- phase transitions: changes between states of matter (solid, liquid, gas) undergoing transformation. "extends the focus to objects undergoing phase (gas/liquid/solid) transitions."
- precision-recall tradeoff: balance between correctly identifying positives and avoiding false positives. "we can improve this precision-recall tradeoff."
- pseudo-labels: automatically generated labels used to train models when ground truth is scarce. "For HowToChange~\cite{oscs} and WhereToChange~\cite{spoc}, pseudo-labels are generated from off-the-shelf vision-language systems"
- Segment Anything Model (SAM): a foundation model for prompt-based segmentation in images. "Segment Anything Model (SAM)~\cite{segmentanything}"
- semantic consistency: requirement that candidate tracks align in meaning with the original object's identity. "we introduce a semantic consistency prior that assumes semantic alignment between a candidate entity and the prompt object."
- semantic reasoning: deriving meaningful descriptions and relations from visual data using LLMs. "promising capabilities in temporal grounding and semantic reasoning for complex object transformations."
- spatial proximity: nearness in space used as a prior for associating tracks post-transformation. "we define two requirements that a candidate tubelet in must satisfy to be considered as a missing object: spatial proximity and semantic consistency."
- spatiotemporal grounding: linking transformations to specific locations and times in a video. "providing spatiotemporal grounding for the transformation."
- spatiotemporal partition: division of a video into space-time regions tracked as candidates for retrieval. "a spatiotemporal partition of the video"
- state graph: structured representation of state changes and resulting objects over time. "generates a state graph describing each observed transformation."
- state-of-the-art: best currently achieved performance within a research area. "TubeletGraph achieves state-of-the-art tracking performance under transformations"
- template matching: matching object appearances to templates across frames for tracking. "template matching~\cite{template}"
- temporal boundaries: start and end frames marking where transformations occur. "with temporal boundaries (start/end frames)"
- temporal grounding: identifying when events or state changes happen within a video. "promising capabilities in temporal grounding and semantic reasoning for complex object transformations."
- temporal localization: detecting the correct time interval of an event or transformation. "precision and recall for temporal localization"
- tubelet: short track segment representing an entity's evolution until appearance changes. "This produces a soup of “tubelets”."
- tubelet propagation: extending tubelets forward in time using a tracker. "Replacing SAM2.1~\cite{sam2} with Cutie~\cite{cutie} for tubelet propagation results in a more significant degradation"
- TubeletGraph: the proposed zero-shot framework for tracking and understanding object transformations. "We answer these two questions with TubeletGraph, a novel zero-shot framework for tracking and understanding object transformations in videos."
- Track Any State: task of tracking objects through transformations while detecting and describing state changes. "We call this problem Track Any State."
- VLM: Vision-LLM; model jointly processing visual and textual inputs for reasoning. "demonstrating high-quality VLM reasoning is critical for accurate semantic descriptions."
- vision-language systems: systems integrating visual and textual understanding for tasks. "off-the-shelf vision-language systems"
- VOST-TAS: benchmark dataset annotating transformations and resulting objects for Track Any State. "accompanied by a new benchmark dataset, VOST-TAS."
- zero-shot: performing tasks without task-specific supervised training. "TubeletGraph, a zero-shot system that recovers missing objects after transformation"
Collections
Sign up for free to add this paper to one or more collections.