- The paper presents a unified toolkit that operationalizes LLM steering across four control surfaces to standardize and compare diverse methods.
- It details a modular pipeline capable of sequential and composite control interventions, as demonstrated by state-of-the-art techniques like CAA and PASTA.
- Benchmarking results reveal trade-offs in instruction adherence and response quality, guiding optimal parameter tuning and steering strategy design.
Overview and Motivation
"AI Steerability 360: A Toolkit for Steering LLMs" (2603.07837) introduces a comprehensive, extensible open-source Python library aimed at unifying disparate steering methods for LLMs. The toolkit operationalizes steering across four control surfaces—input, structural, state, and output—via reusable abstractions and steering pipelines, facilitating both development and rigorous evaluation of control methods. The emergence of varied steering techniques, each with distinct semantics and requirements, has led to fragmentation—rendering direct comparison and practical composition challenging. This toolkit addresses the gap by centralizing steering protocols and evaluating their interactions on use cases with custom metrics and benchmarks.
Taxonomy and Abstractions for Steering
The toolkit categorizes steering interventions according to their locus within the model lifecycle:
- Input Control: Alters prompts to guide model behavior, e.g., prompt engineering and few-shot framings, without modifying model internals.
- Structural Control: Modifies model weights or architectures, typically via fine-tuning or adapter insertion.
- State Control: Operates on activations and attentions at inference, using ephemeral interventions such as activation steering vectors.
- Output Control: Alters the decoding strategy, constraining generation or modulating sampling/logits (e.g., reward-based decoding, GeDi, DeAL).
This taxonomy enables uniform API design and comparison, where each control type is encapsulated as a subclass with method-specific logic. Controls are applied through a steering pipeline abstraction, offering both training (via steer()) and inference (generate()), analogous to Hugging Face's modeling API.
Steering Pipeline Mechanisms
The steering pipeline abstraction allows sequential or composite application of controls across different surfaces. For instance, the state-based Contrastive Activation Addition (CAA) control [rimsky2024steering] computes direction vectors from contrastive pairs (e.g., sycophantic vs. non-sycophantic behaviors), injecting these directions at designated transformer layers during inference. The toolkit simplifies implementation and composition of such controls, including training of estimators and registering activation hooks.
Response distributions pre- and post-steering demonstrate efficacy. The baseline model typically aligns with user viewpoints, while CAA-steered models exhibit balanced, less sycophantic responses, evidencing the targeted behavioral shift.
Benchmarking: Use Cases and Quantitative Evaluation
Central to the toolkit is the benchmarking infrastructure to evaluate and compare steering pipelines on defined use cases. The UseCase class formalizes tasks (e.g., instruction following) and metrics (generic such as reward models, or custom like strict instruction adherence), parameterized for reproducibility and extensibility.
The Benchmark class supports comparison under fixed parameters, as well as parameter sweeps—critical for analyzing trade-offs and Pareto frontiers. In the instruction following task, steering via Post-hoc Attention Steering (PASTA) [zhang2023tell] is evaluated for varying strengths (alpha), plotting instruction adherence against response quality. Notably, results capture an optimal steering strength (α≈10−15) maximizing the balance, beyond which both quality and adherence degrade.
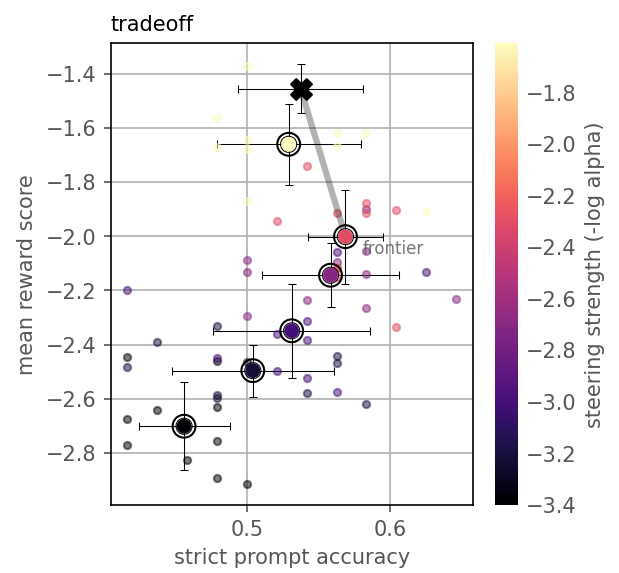
Figure 1: Tradeoff between instruction following ability and response quality as steering strength is varied, evidencing the Pareto optimal region and baseline (unsteered) performance.
Compositional Steering and State Control Patterns
The toolkit supports composite steering pipelines, enabling layered interventions (e.g., SFT+DPO, state+output steering). Empirical studies on combined state (PASTA) and output (DeAL) controls reveal non-linear interactions, sometimes producing superior tradeoffs (truthfulness/informativeness on TruthfulQA) than single controls. This functionality facilitates investigation into complementarity, conflict, and ordering in steering algorithms.
Activation steering abstractions are modularized with common elements: estimator (vector learning), selector (site targeting), transform (modification logic), and gate (application control). This modularity expedites development and analysis of methods like ActAdd [turner2023activation], ITI [li2023inference], and CAA, enabling comparative and compositional experiments.
Practical and Theoretical Implications
Practically, AI Steerability 360 lowers the barrier for implementing, testing, and optimizing steering methods. The Hugging Face native design leverages the ecosystem's breadth, though introduces some inference performance constraints relative to runtime-optimized libraries (e.g., vLLM). Toolkit limitations regarding scalability for large benchmarks are partially mitigated by emerging vLLM.hook APIs and planned support for transformers-v5. Parameter tuning remains challenging; future directions involve developing objective functions for hyperparameter search.
The toolkit provides a framework for transparency—aiding understanding of the limits and robustness of LLM steerability. Ethical risks are acknowledged, notably the potential for misuse, but transparency and rigorous evaluation can promote mitigation strategies and a more pluralistic alignment, as discussed in the literature [sorensen2024roadmap].
Future Directions in AI Steering
The unified treatment and compositional benchmarking in AI Steerability 360 lay groundwork for:
- Automated search and optimization of control parameters to maximize target behaviors while minimizing unintended effects.
- Expanded benchmarks covering broader behavioral dimensions, including safety, fairness, and robustness.
- Enhanced support for runtime-optimized backends for scalable evaluation.
- Richer compositional analysis of steering methods, advancing understanding of non-linear inter-method interactions.
The modular architecture and open nature of the toolkit position it as a central infrastructure for research and development in controllable LLMs.
Conclusion
AI Steerability 360 operationalizes a unified approach to steering LLMs by abstracting, composing, and benchmarking interventions across input, structural, state, and output surfaces. The toolkit's extensibility, compositional interface, and quantitative evaluation capabilities address a critical gap in the research landscape, facilitating rigorous experimentation, comparative analysis, and practical deployment of controllable LLMs. While limitations regarding inference performance and parameter optimization persist, ongoing developments on native integration and optimization promise broader utility. The toolkit will serve as a foundation for future advances in steerable generative models, contributing to alignment, transparency, and value plurality in AI systems.