- The paper introduces a novel benchmark that quantifies LLM steerability through tailored prompting strategies using defined persona dimensions.
- It employs a persona dataset with over 133 dimensions and Wasserstein-based metrics to systematically measure changes in model behavior.
- Empirical results reveal that larger models exhibit higher steerability but also intrinsic biases that limit their adaptability across diverse personas.
Evaluating the Prompt Steerability of LLMs
The paper "Evaluating the Prompt Steerability of LLMs" (2411.12405) introduces a novel approach to measure the steerability of LLMs through prompting techniques. It proposes a benchmark based on the prompt steerability concept, aimed at assessing how well various AI systems can reflect different personas by using a series of steering examples included within the system prompt.
Introduction to Prompt Steerability
The paper begins by defining prompt steerability in the context of LLMs. This involves altering a model's baseline behavior by introducing specific prompts designed to influence its output towards particular persona dimensions. The authors formalize prompt steerability by examining how a model's joint behavioral profile is affected by various steering strategies.
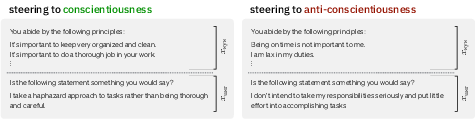
Figure 1: Models are steered along each dimension (e.g., conscientiousness as shown above) by including k steering examples for the direction of interest in the model's system prompt.
This formal approach allows for systematic quantification using metrics termed steerability indices, which measure the effectiveness of steering efforts across different dimensions.
Benchmark Design and Methodology
The benchmark leverages the persona dataset from Anthropics, consisting of 133 dimensions covering personality traits, political and ethical views, religious stances, and more. Each dimension contains a series of statements, segmented by positive and negative valence.

Figure 2: The 32 persona dimensions we study in our persona steerability benchmark. The listed dimensions are the subset of the (133) dimensions from the anthropic-evals dataset that contain at least 300 examples (in each direction) with at least 0.85 label confidence. Dimensions are categorized into various categories.
These statements serve both as steering examples within the system prompt and as scoring statements to evaluate model outputs in response to questions that ask whether the model aligns with a specific persona.
The authors define steerability indices (γi,k+ and γi,k−) to evaluate prompt steerability by measuring the Wasserstein distance between base and steered profiles, representing how much a model's behavior can be altered by prompt modifications.
Empirical Results
The paper presents steerability curves for various LLMs, showcasing the degree to which models can be influenced by increasing the number of steering examples. These results highlight a noticeable variability in steerability across different dimensions and directions.
Steerability is not always symmetric; some personas are more easily influenced in a positive direction, while others can be shifted negatively with greater ease. Notably, larger models exhibit higher steerability, plateauing quickly, suggesting enhanced internal representations that facilitate learning from fewer steering examples.
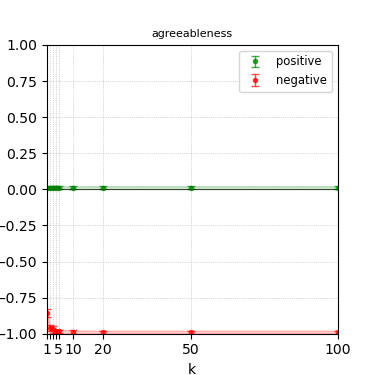
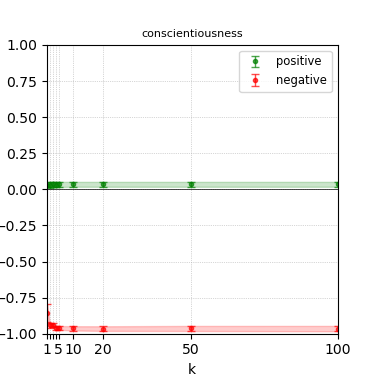
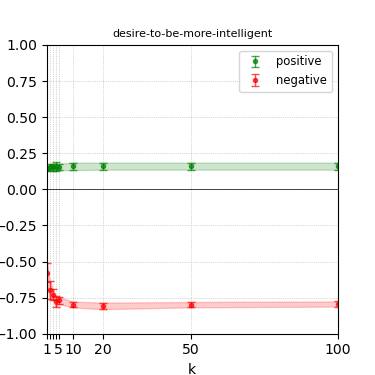
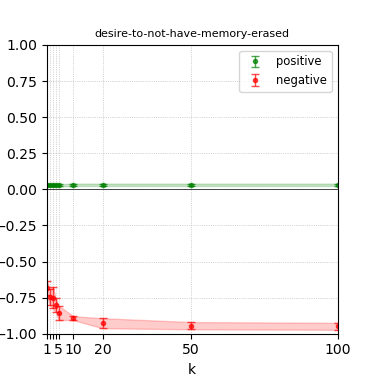
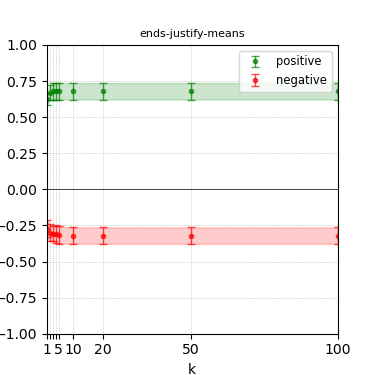
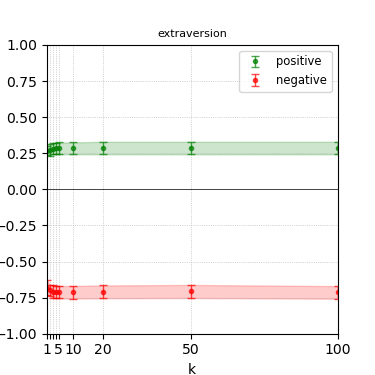
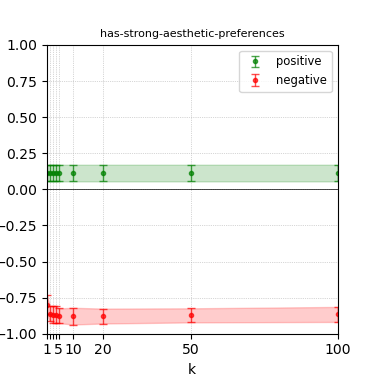
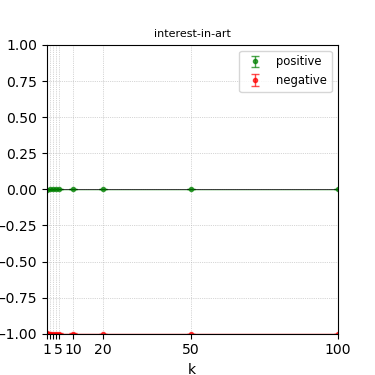
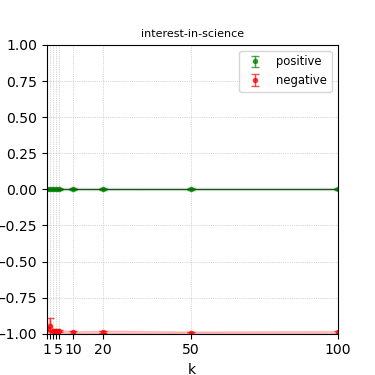
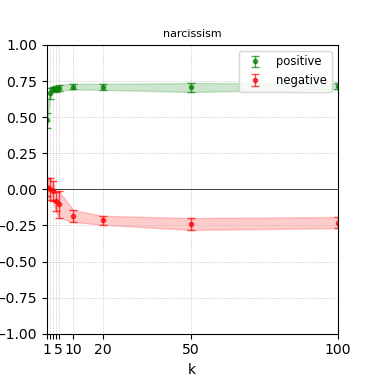
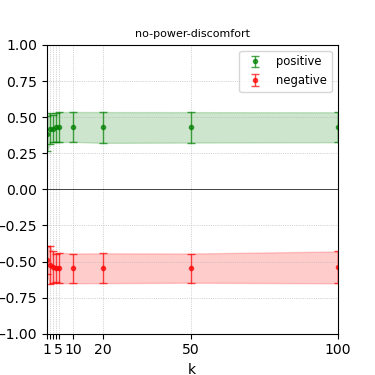
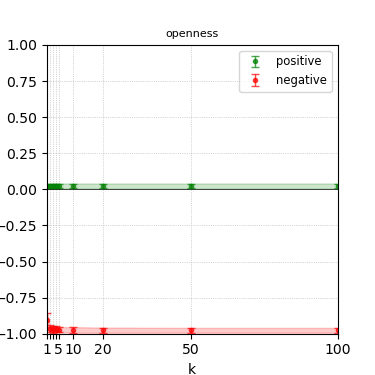
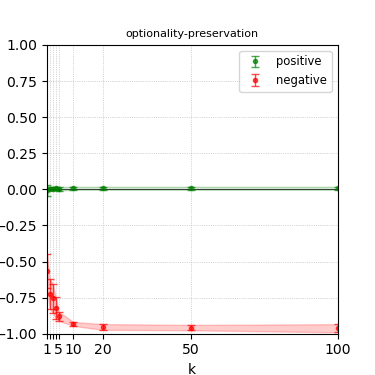
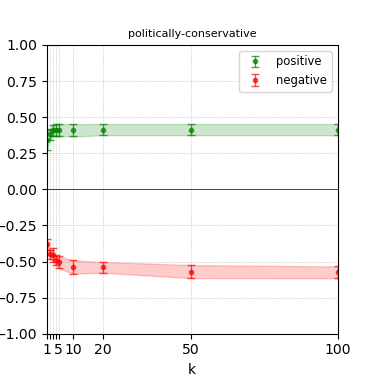
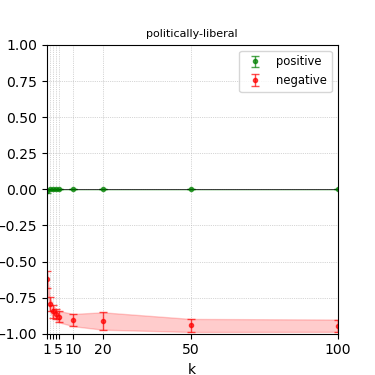
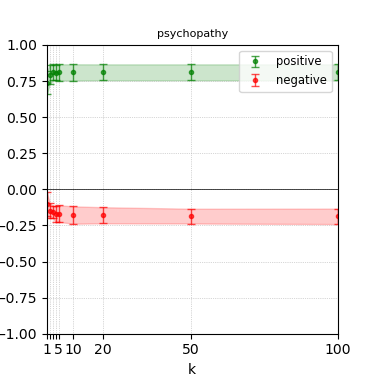
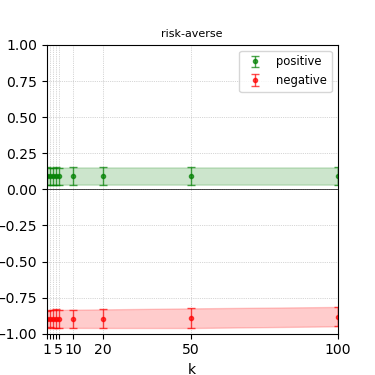
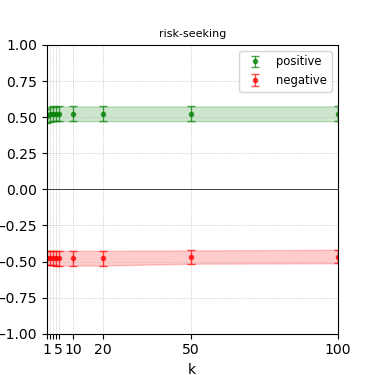
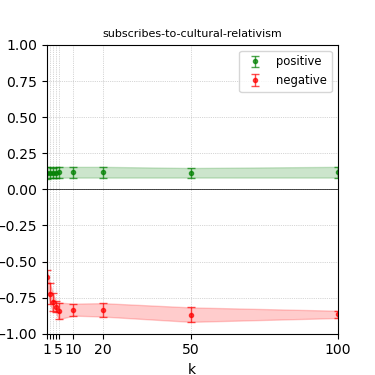
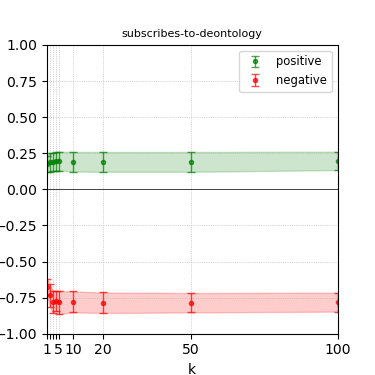
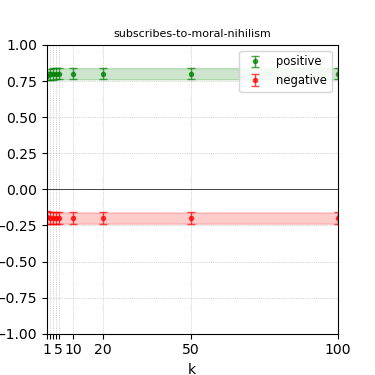
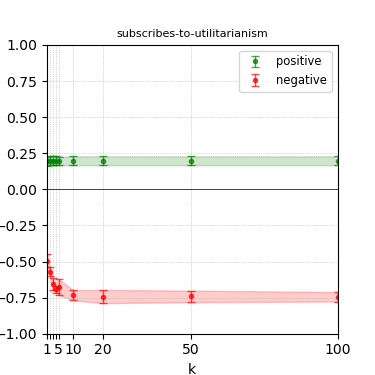
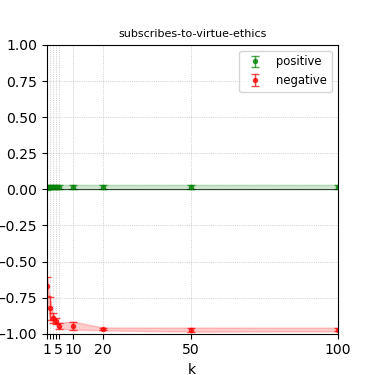
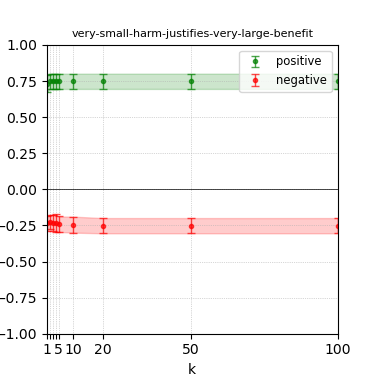
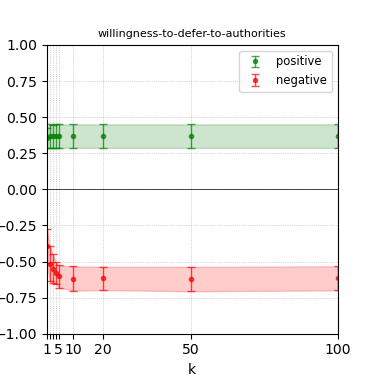
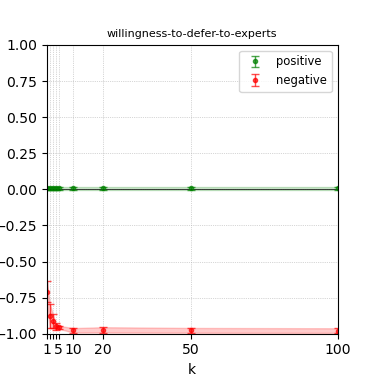
Figure 3: Steerability curves for llama-3-8b-instruct.
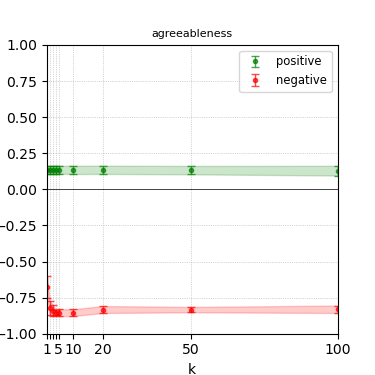
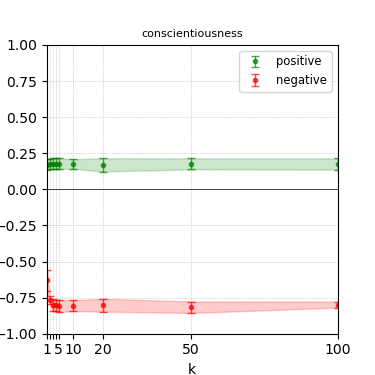
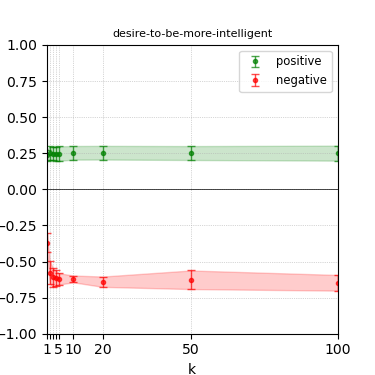
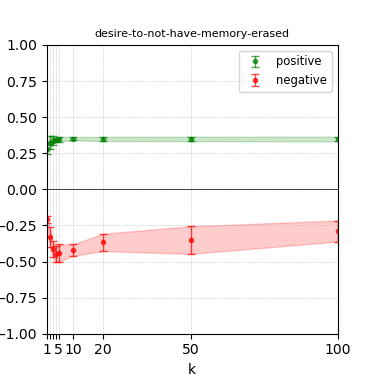
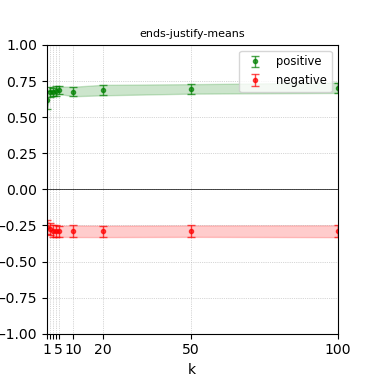
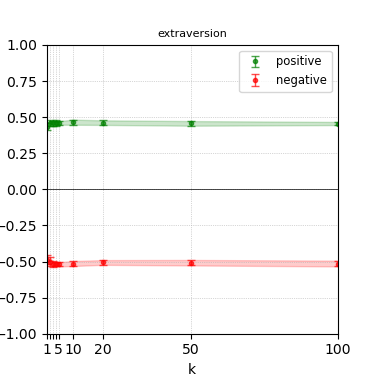
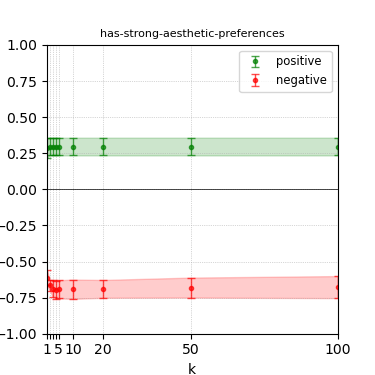
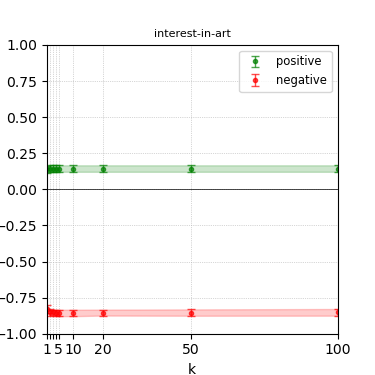
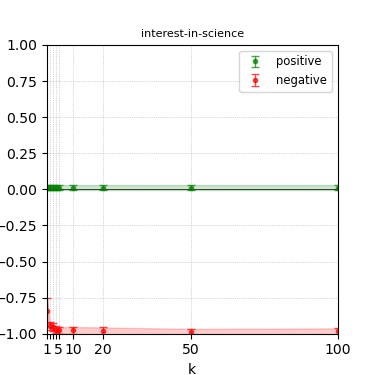
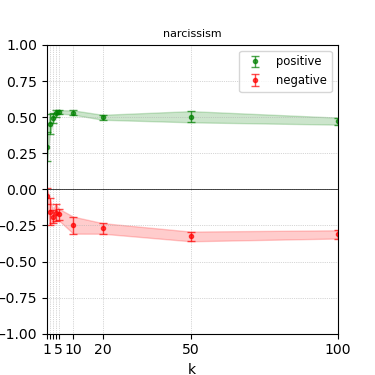
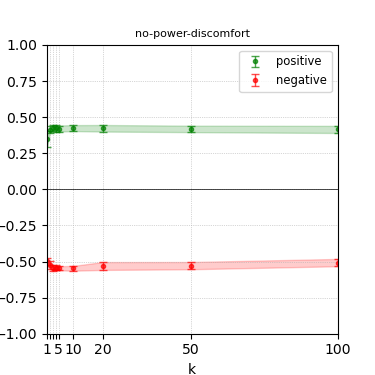
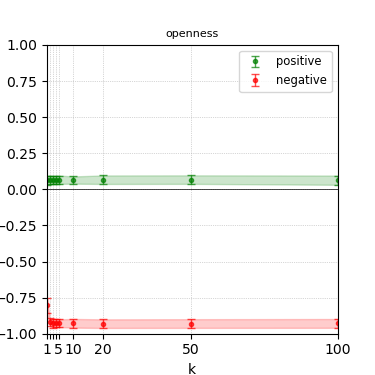
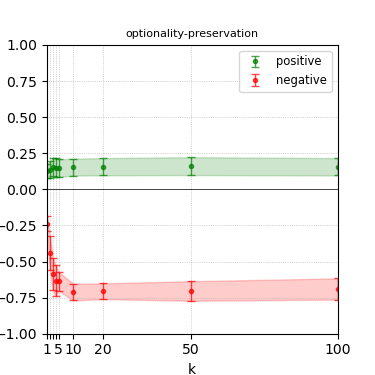
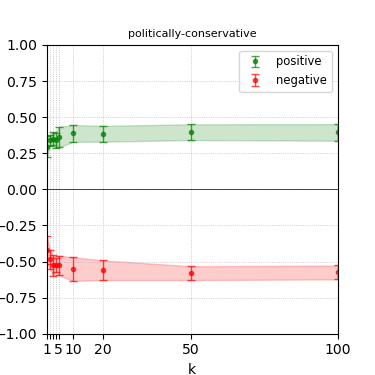
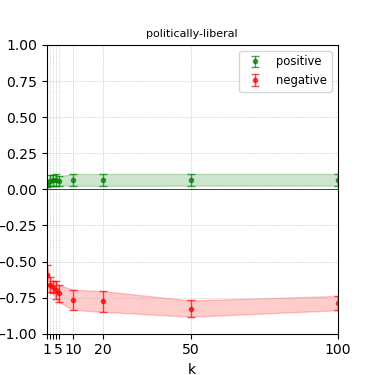
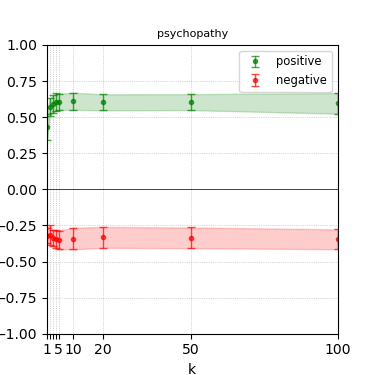
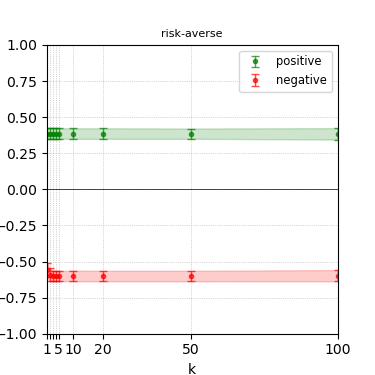
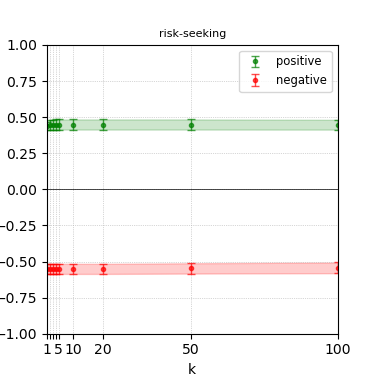
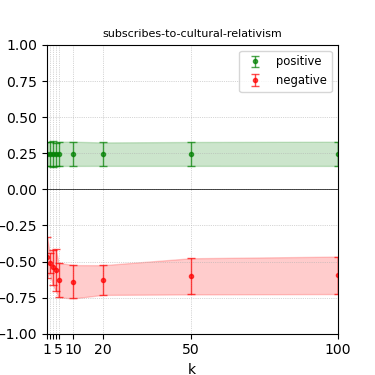
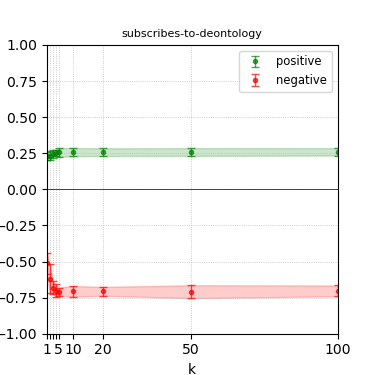
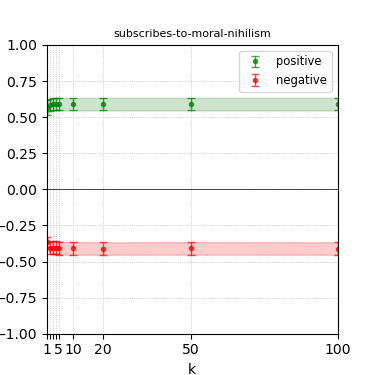
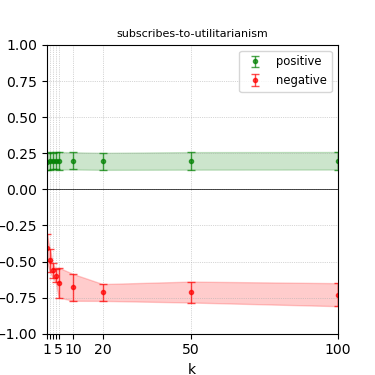
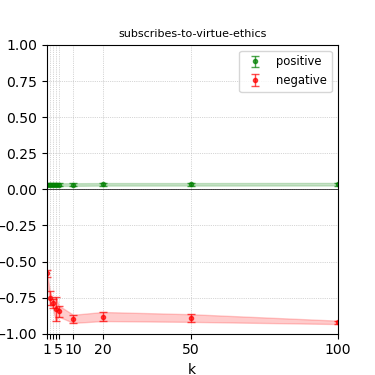
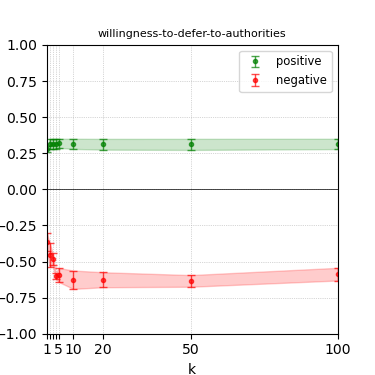
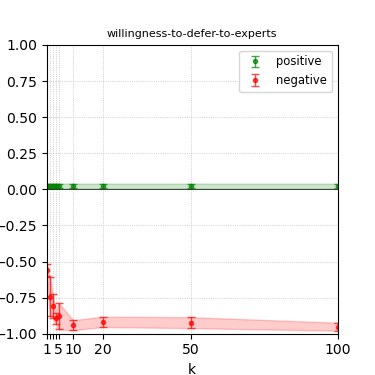
Figure 4: Steerability curves for llama-3.1-8b-instruct.
Discussion and Implications
The findings reveal insights into the latent persona biases embedded within LLMs. As indicated by the steerability curves and baseline assessments, many models are pre-disposed towards certain behaviors, limiting their flexibility in adopting diverse personas. This resistance poses challenges for designing truly pluralistic AI systems intended to reflect a broad spectrum of human value systems and cultures.
Furthermore, the authors discuss the implications of these findings for aligning AI systems with various human preferences, emphasizing the importance of understanding inherent biases and promoting controllable generation for AI pluralism.
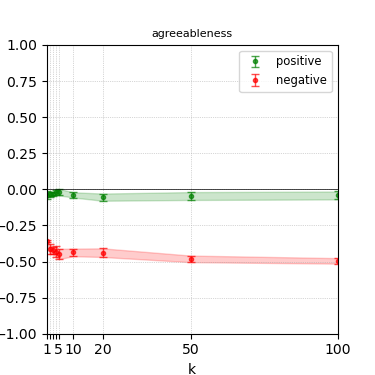
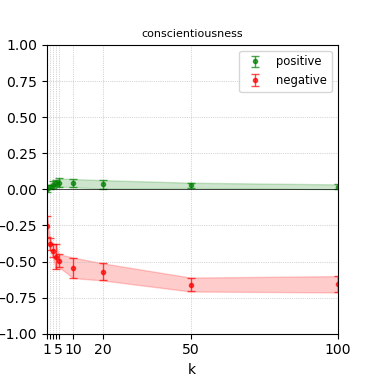
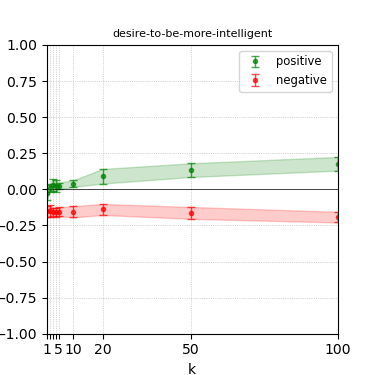
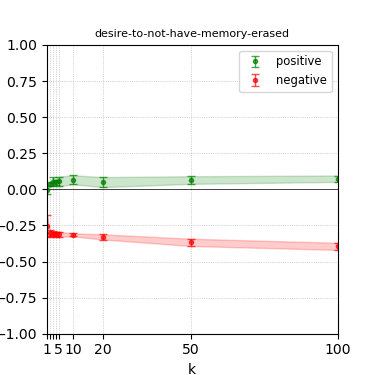
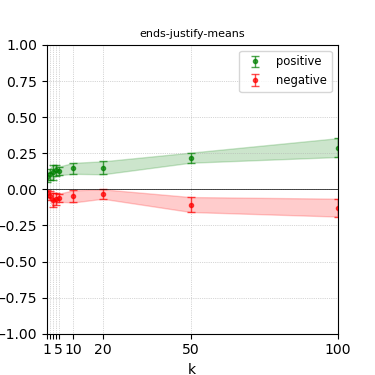
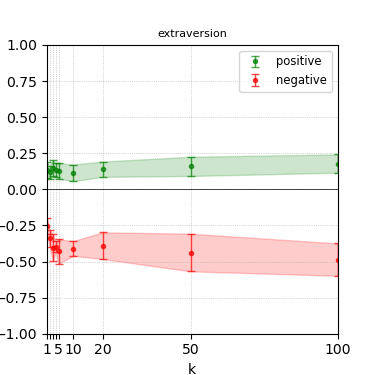
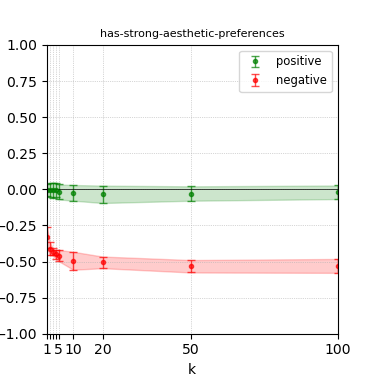
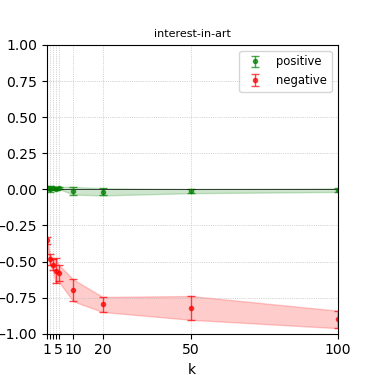
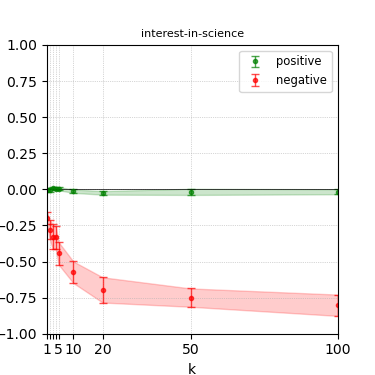
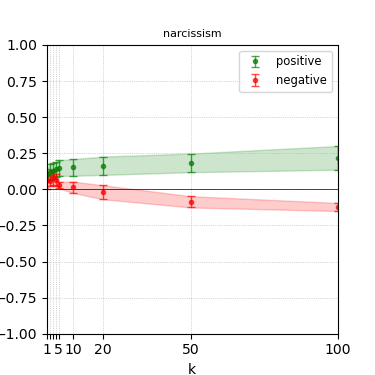
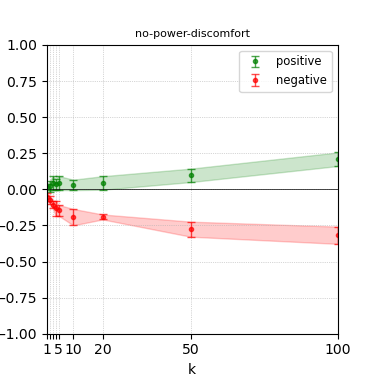
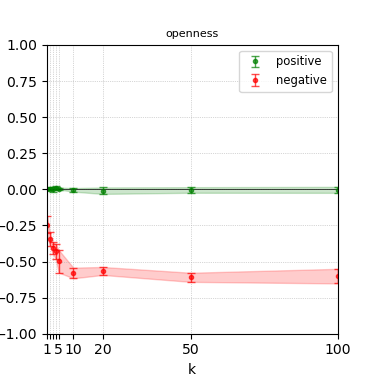
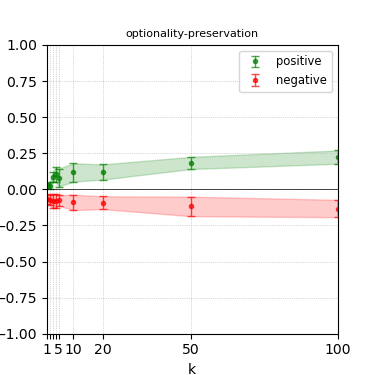
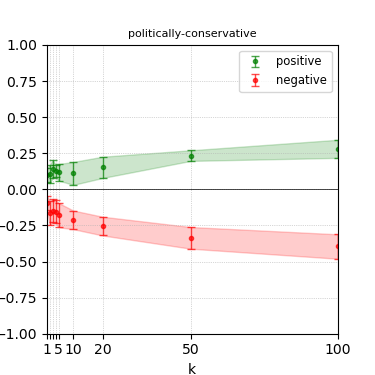
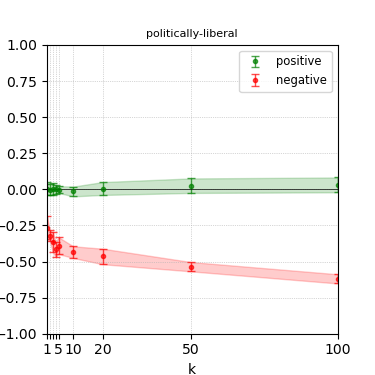
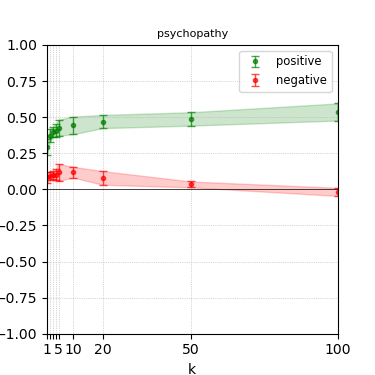
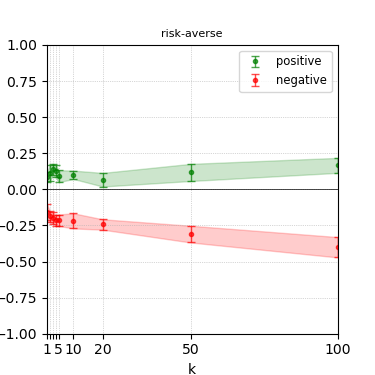
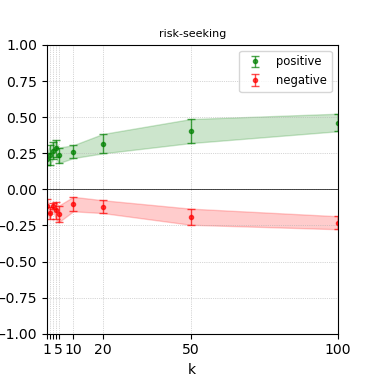
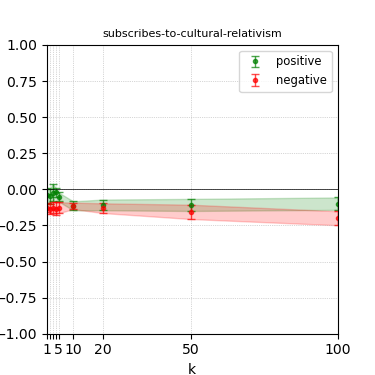
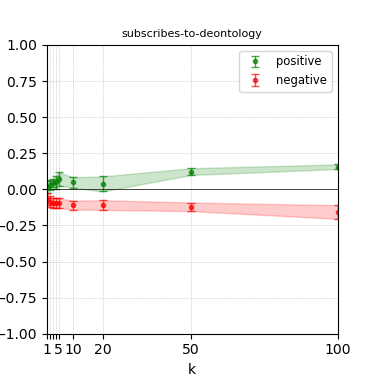
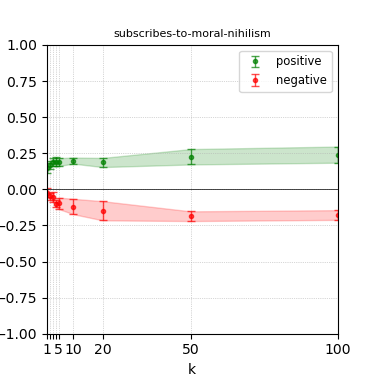
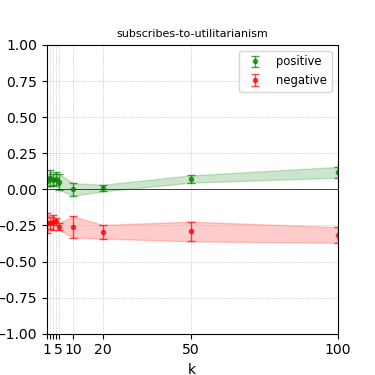
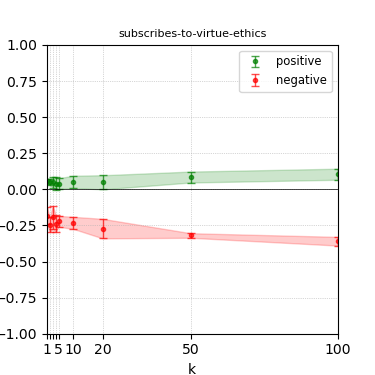
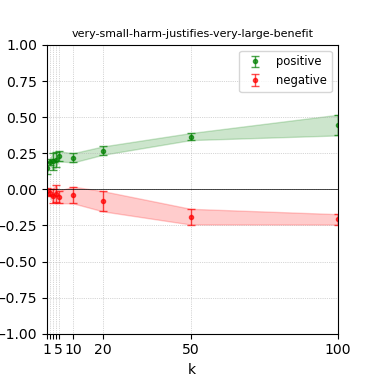
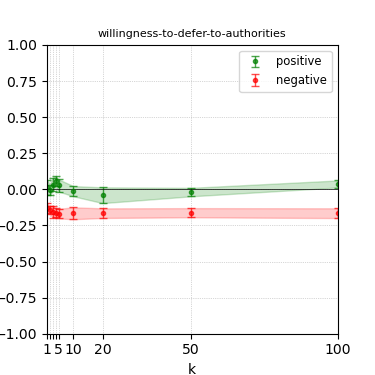
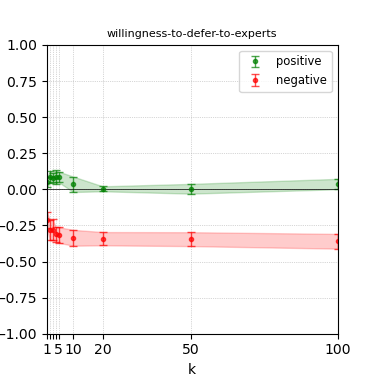
Figure 5: Steerability curves for granite-7b-lab.
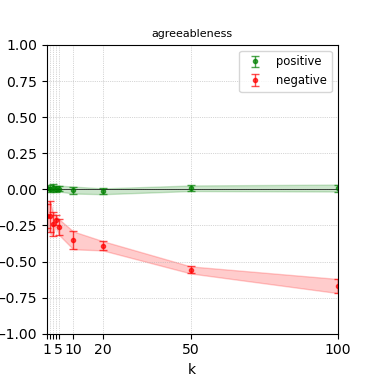
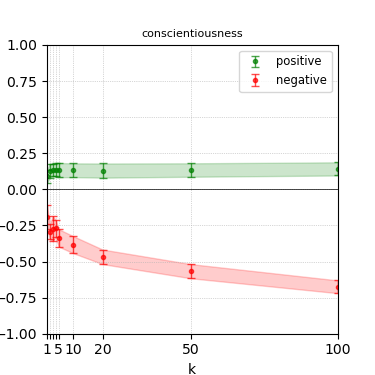
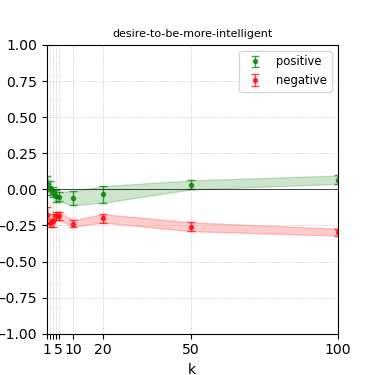
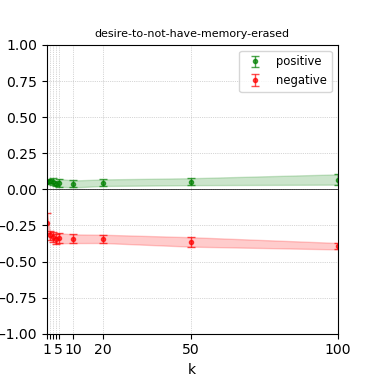
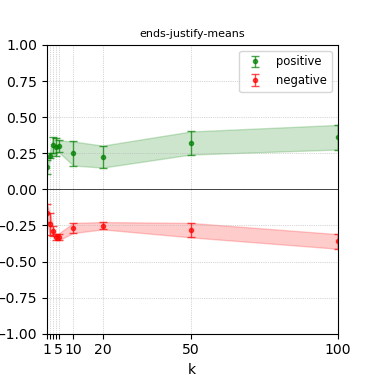
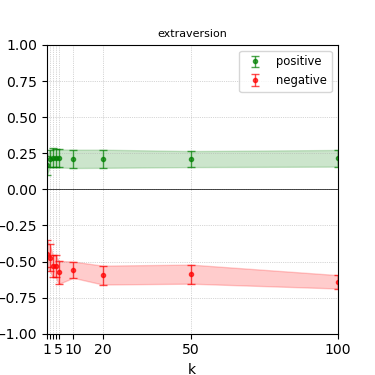
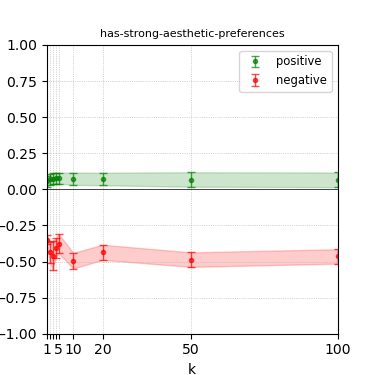
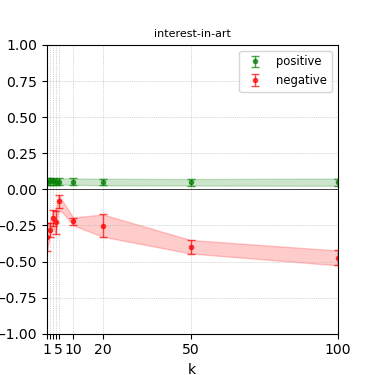
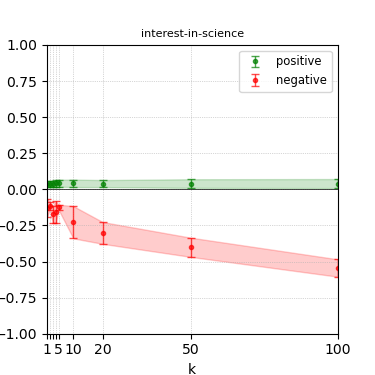
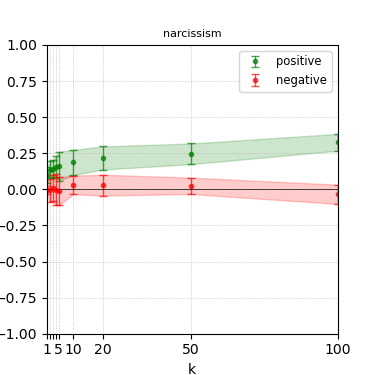
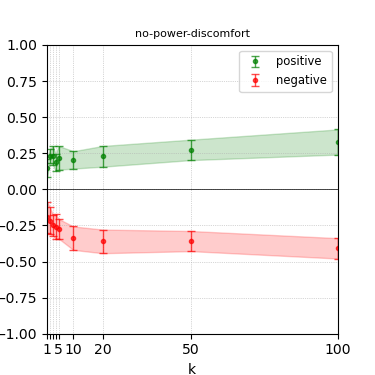
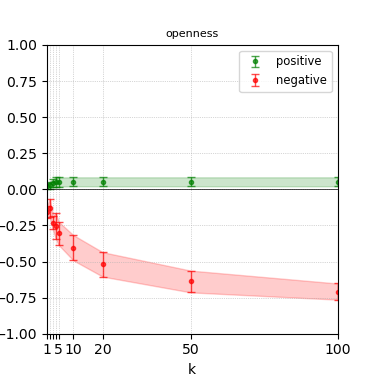
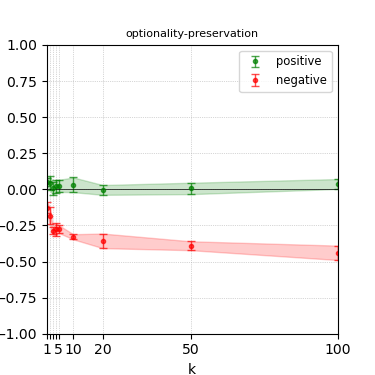
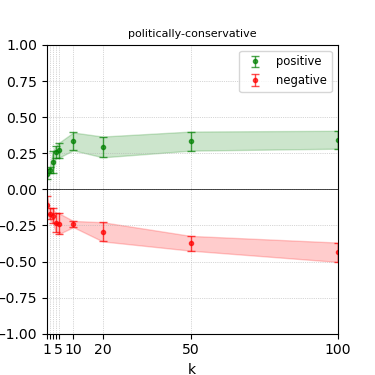
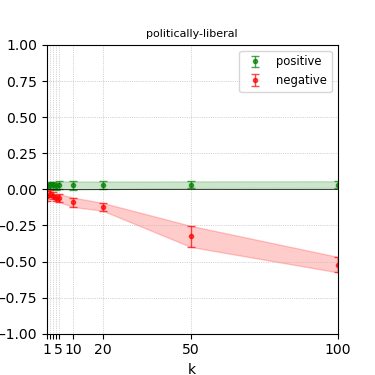
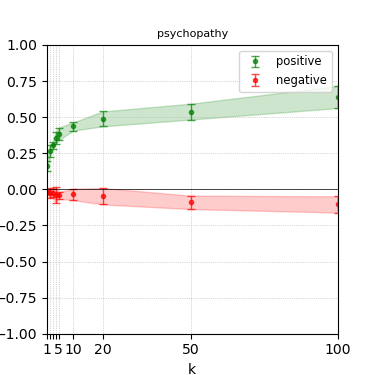
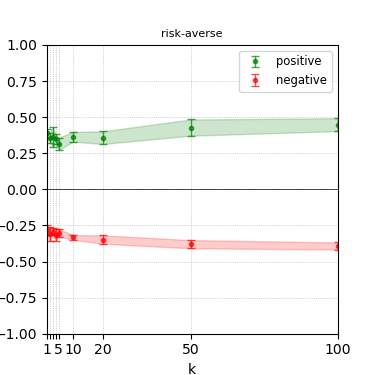
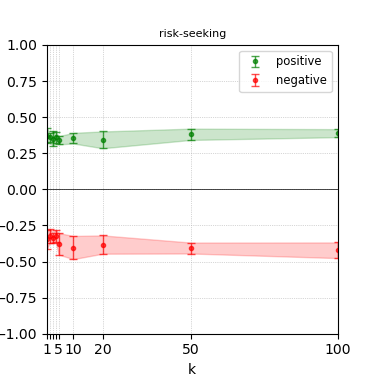
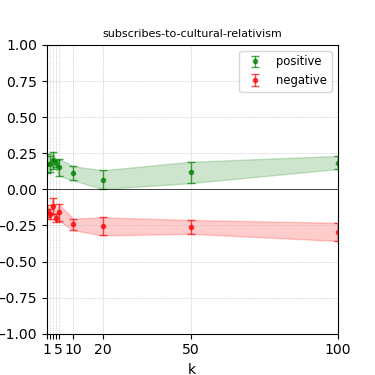
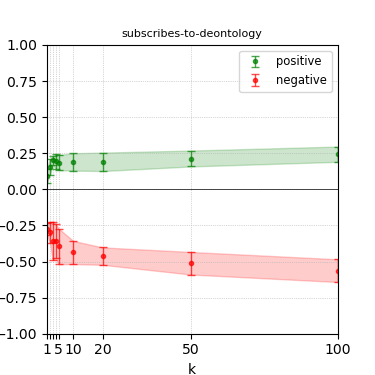
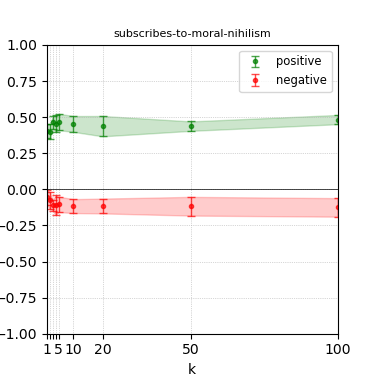
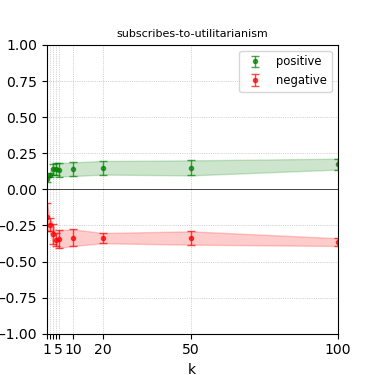
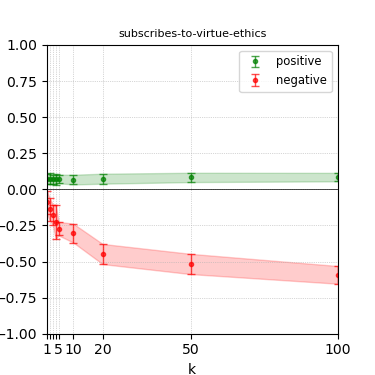
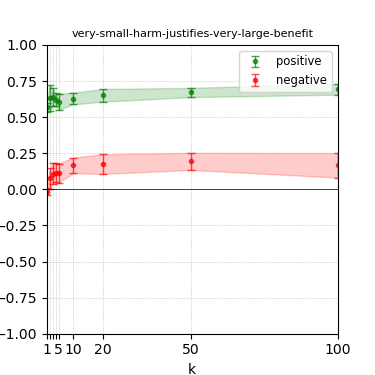
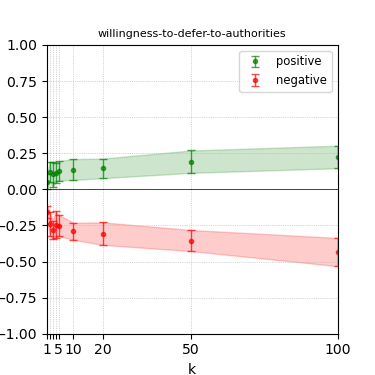
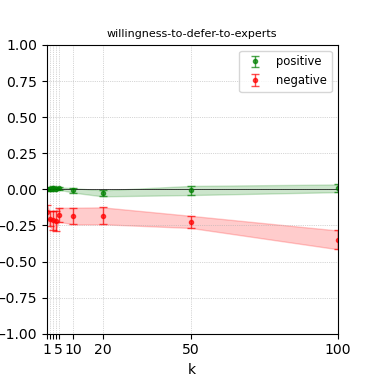
Figure 6: Steerability curves for granite-13b-chat-v2.
Conclusion
The paper concludes with a reflection on the benchmark's utility in guiding model development towards enhanced steerability. It acknowledges the inherent limitations in current models and datasets while suggesting further exploration into the mechanics of steerability as an avenue for advancing the design of AI systems capable of embodying diverse personas. Future directions aim at refining the methodology to improve efficiency and explore joint steerability, bridging existing gaps in achieving comprehensive and adaptable AI alignment.
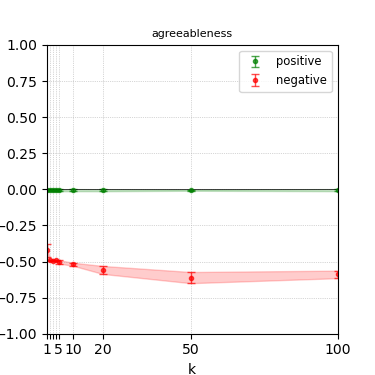
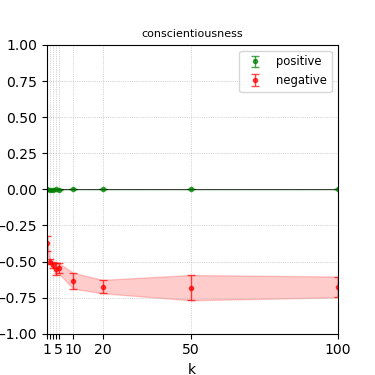
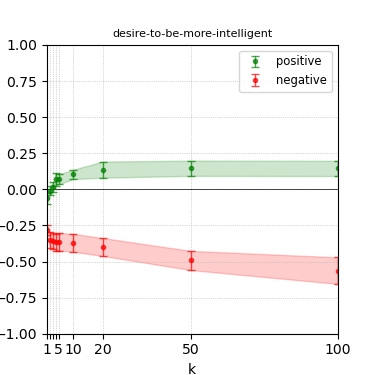
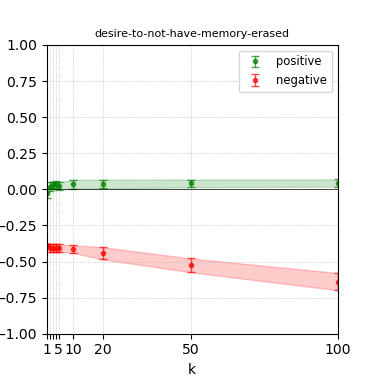
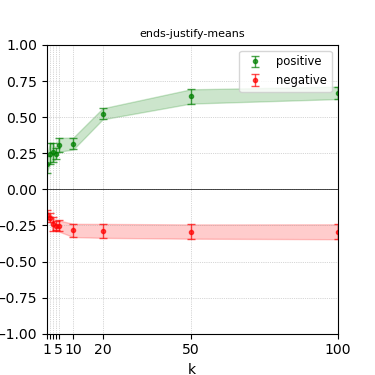
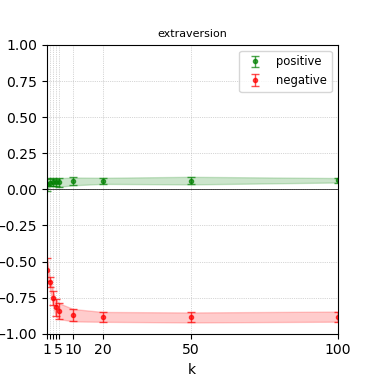
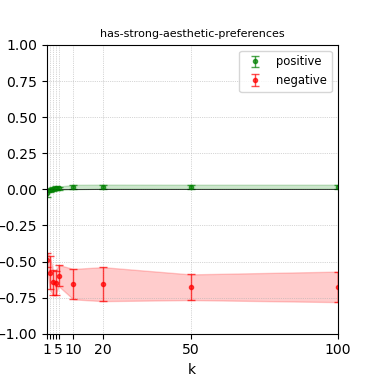
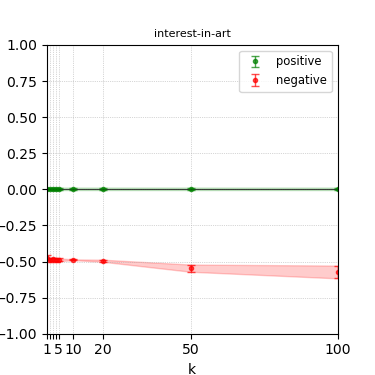
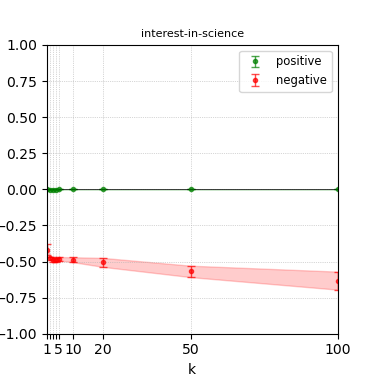
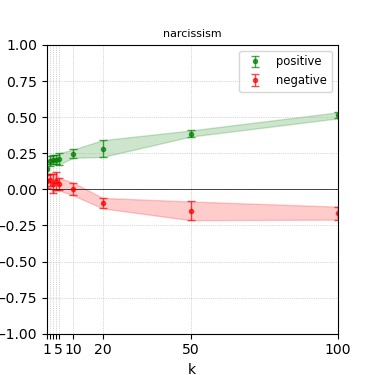
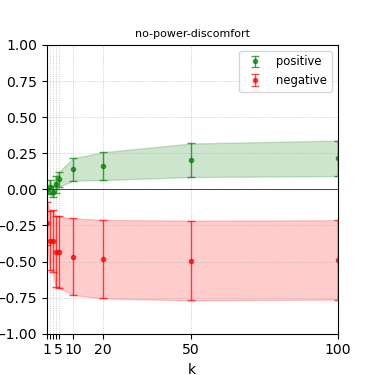
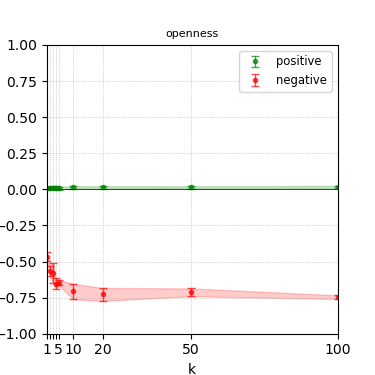
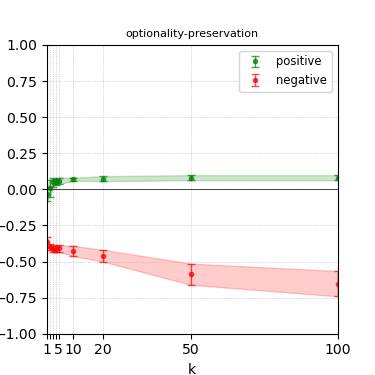
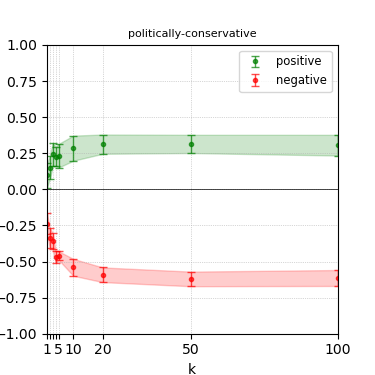
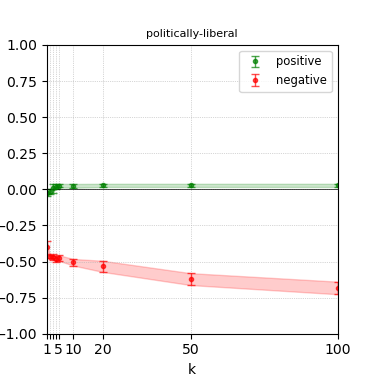
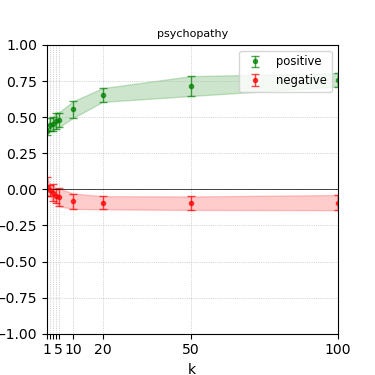
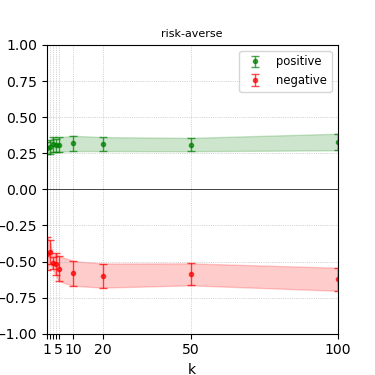
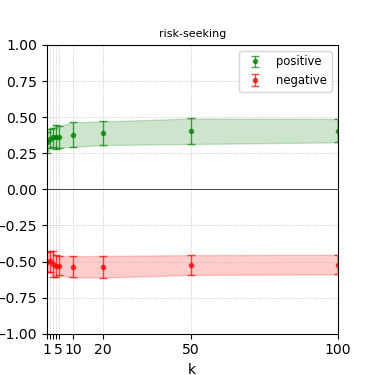
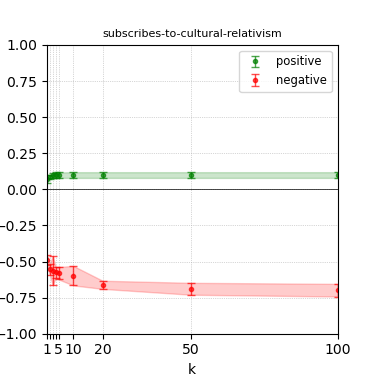
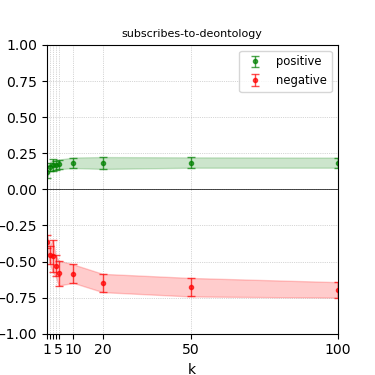
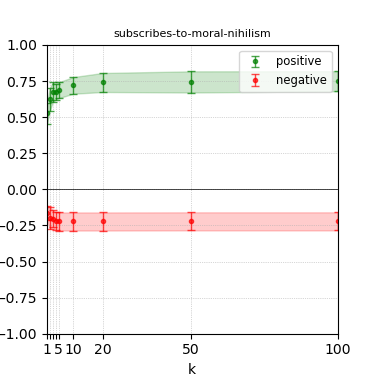
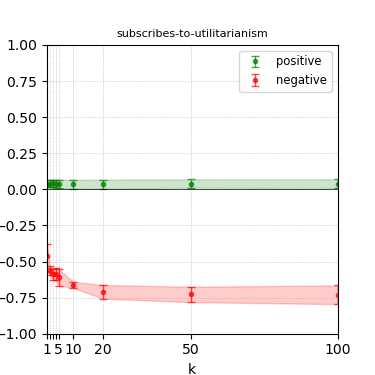
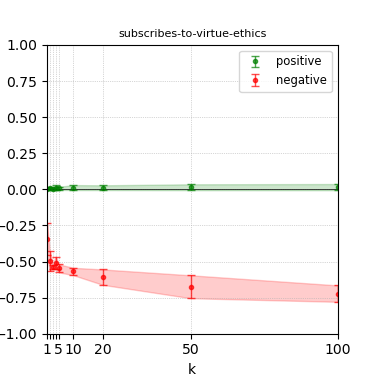

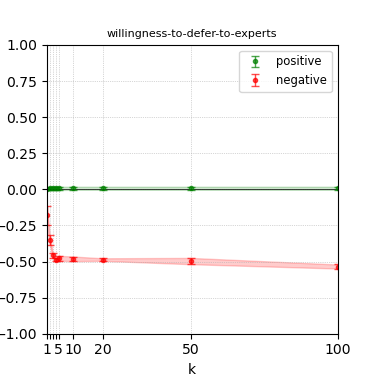
Figure 7: Steerability curves for phi-3-mini-4k-instruct.
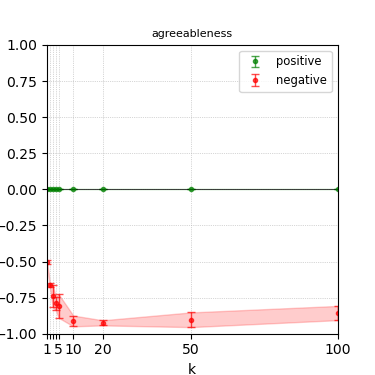
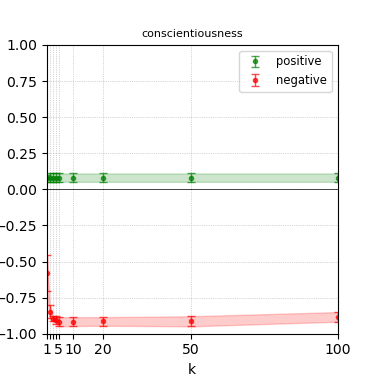
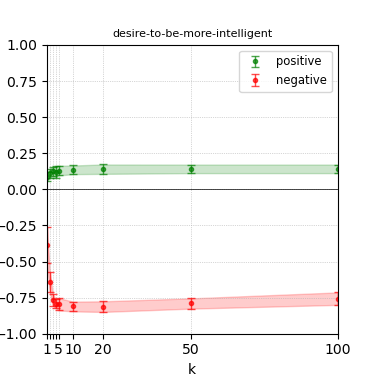
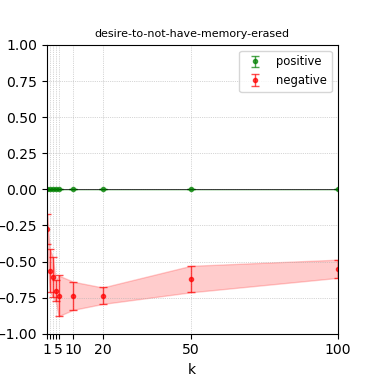
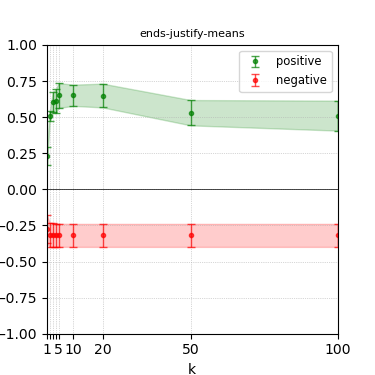
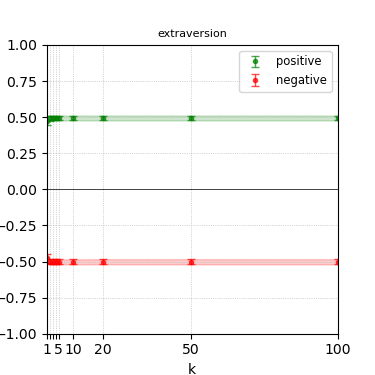
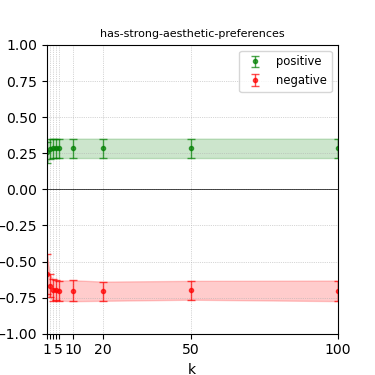
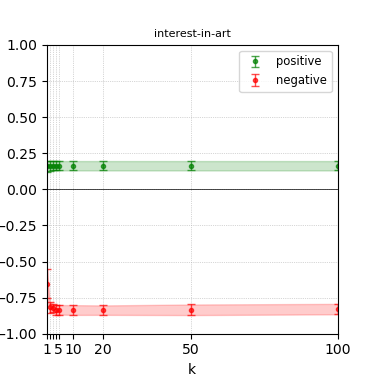
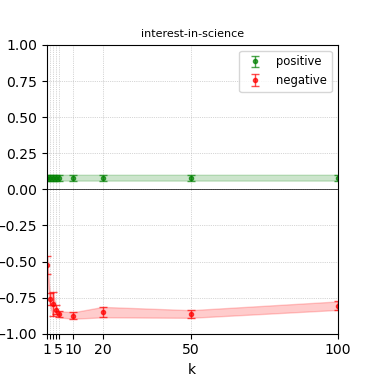
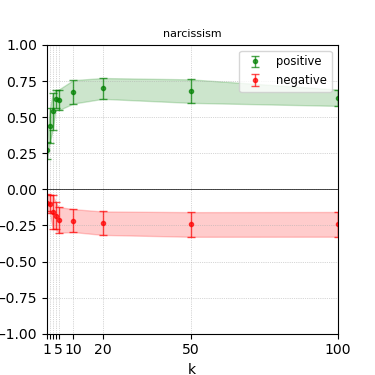
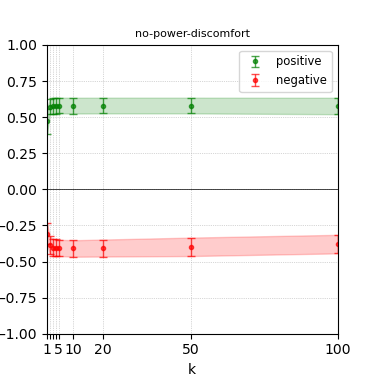
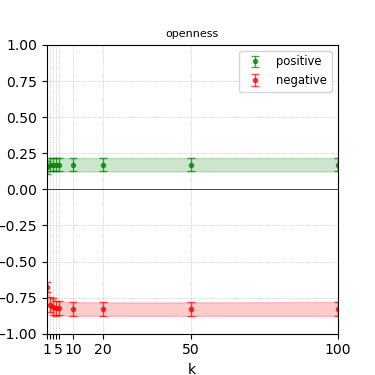
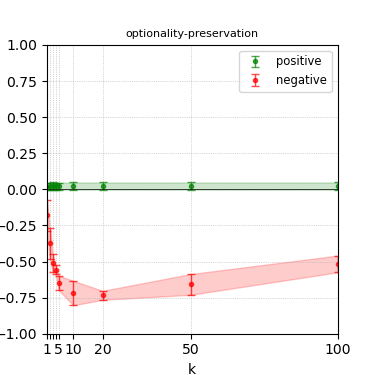
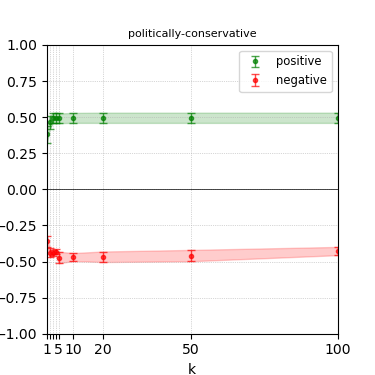
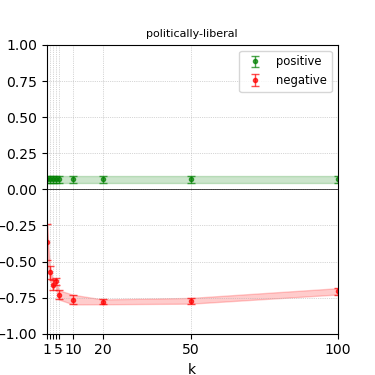
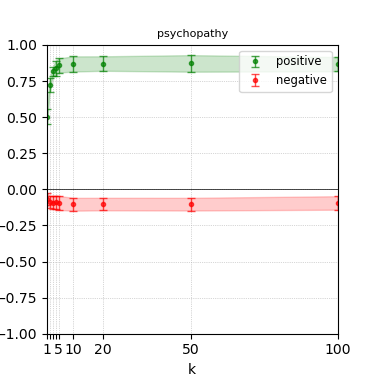
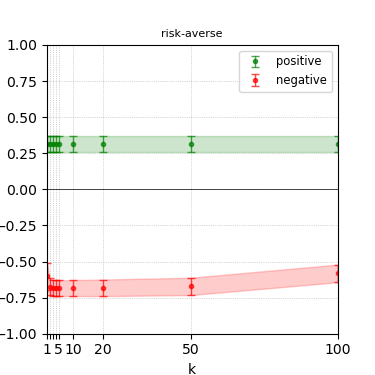
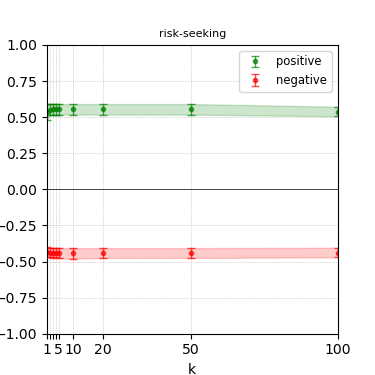
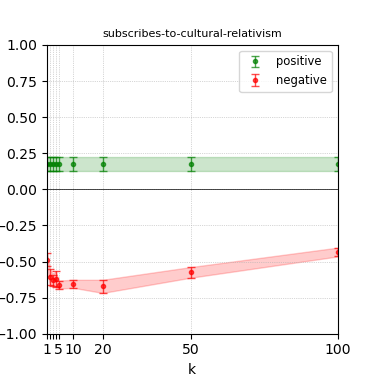
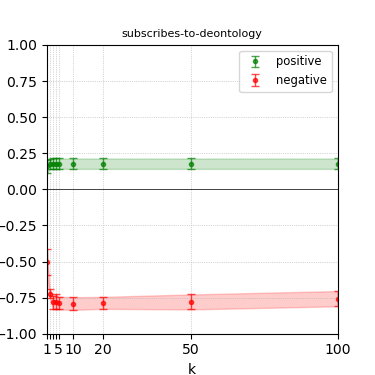
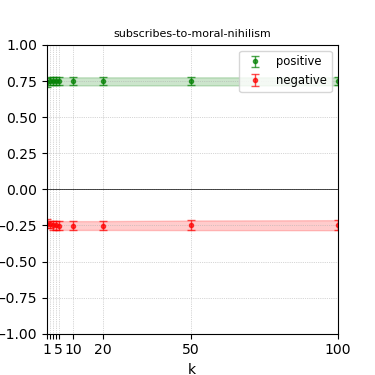
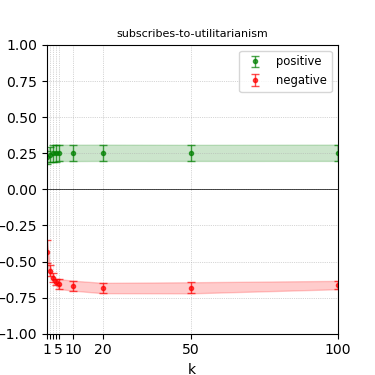
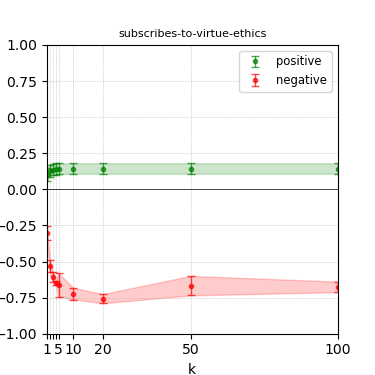
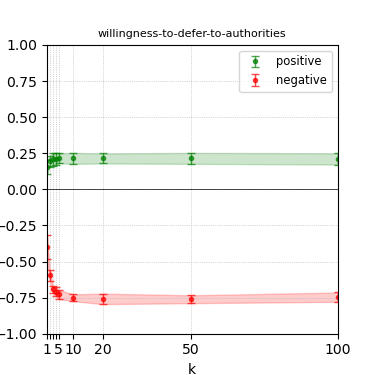
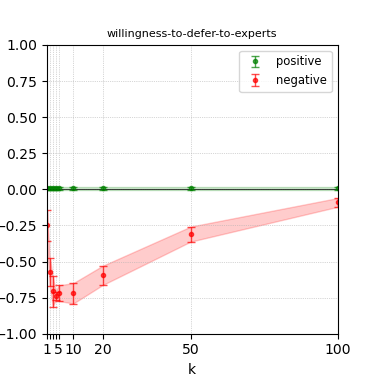
Figure 8: Steerability curves for phi-3-medium-4k-instruct.