- The paper introduces an offline pipeline that textualizes visual signals into detailed captions and refines pseudo-CoT rationales for efficient multimodal recommendation.
- It integrates GRPO optimization with strict filtering of high-confidence reasoning traces, leading to performance gains up to 15.82% on key metrics.
- Empirical evaluations on diverse datasets demonstrate enhanced model stability, reduced shortcut learning, and practical scalability for large candidate sets.
MLLMRec-R1: Advancing Multimodal Sequential Recommendation via Incentivized Reasoning in LLMs
Introduction and Motivation
The paper addresses the inherent bottlenecks in multimodal sequential recommendation (MSR) when leveraging Multimodal LLMs (MLLMs) with Group Relative Policy Optimization (GRPO). Traditional architectures for MSR demand the joint encoding of numerous visual tokens, leading to substantial compute and latency, especially as the history length and candidate set size increase. Critically, despite this expense, the expected gains over text-only LLMs often remain marginal (Figure 1).
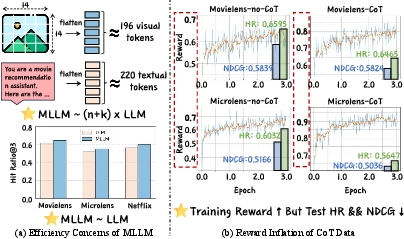
Figure 1: (a) Visual tokens make compute grow with history length and candidate set size, yet often yield limited gains over LLMs, revealing an efficiency bottleneck. (b) Some CoT data may boost training reward scores but hurt test performance, revealing shortcut learning and poor generalization.
Additionally, existing Chain-of-Thought (CoT) supervision frameworks exhibit reward inflation—models achieve high training rewards that do not translate to improved test-time ranking, enabling shortcut learning and undermining generalization. The central contributions focus on optimizing both efficiency and stability in MSR pipelines by textualizing multimodal content offline and constructing filtered multimodal CoT datasets, thereby controlling spurious signals and augmenting generalization.
Multimodal CoT Compression Pipeline
MLLMRec-R1 introduces an offline pipeline for compressing visual signals into fine-grained textual captions via an MLLM, thus eliminating the overhead of visual-token computation while preserving cross-modal semantics for downstream tasks. Structured pseudo-CoT rationales are generated from interaction histories, revealing grounded multimodal cues in text form. These are further refined using a text-only reasoning model (DeepSeek-R1), establishing high-quality supervision for GRPO without target-item leakage or label contamination (Figure 2).
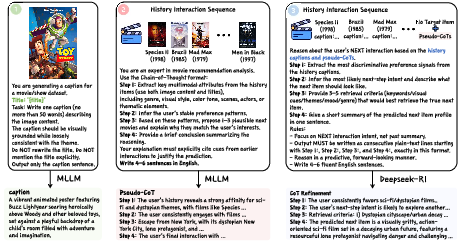
Figure 2: Multimodal CoT construction pipeline—caption generation, pseudo-CoT construction, and CoT refinement enable efficient, target-free multimodal supervision.
Empirical ablations confirm that removing any stage (caption, pseudo-CoT, or refinement) results in significant degradation, implicating the necessity of each component for robust multimodal reasoning and preference modeling.
Mixed-Grained Data Augmentation and Filtering
To combat reward inflation and shortcut learning, the proposed framework injects only high-confidence CoT samples into the training set, mixing them with standard, no-CoT prompts at a low ratio. Quality is assured via two metrics:
- Modality Consistency: Scores alignment between title and image embeddings.
- Prediction Consistency: Assesses the accuracy of the refined CoT profile relative to the target item.
Low-score samples are filtered out, and mixing ratio p is tuned (typically $0.1$ for SFT, $0.05$ for GRPO) for optimal stability and generalization (Figure 3).

Figure 3: Modality consistency and prediction consistency scores govern filtered augmentation in the instruction data, blending high-confidence CoT with standard prompts.
This selective augmentation maintains generalization under GRPO and avoids performance inflation from noisy or spurious reasoning signals.
GRPO Optimization and Lightweight Reward Rules
GRPO post-training is applied after initial SFT fine-tuning, activating reasoning traces across a fixed instruction template. GRPO uses group-wise sampling per context, calculating relative advantage and imposing stability via KL to reference policy (DeepSeek-R1). The reward function is explicitly decomposed (Figure 4):
This structure ensures consistent and aligned optimization towards top-ranked, semantically matched recommendations.
Empirical Evaluation and Numerical Analysis
Extensive experiments on MovieLens-1M, MicroLens, and Netflix datasets substantiate statistically significant performance gains: MLLMRec-R1 outperforms all baselines with relative improvements up to 15.82% on NG@3 and similar gains on HR@3 across all datasets. Radar chart evaluations further highlight that CoT refinement elevates data quality in modality consistency, prediction consistency, signal density, leakage risk, and coverage hardness—outscoring pseudo-CoT across annotators (GPT-5.2, Claude-4.5, humans) (Figure 5).
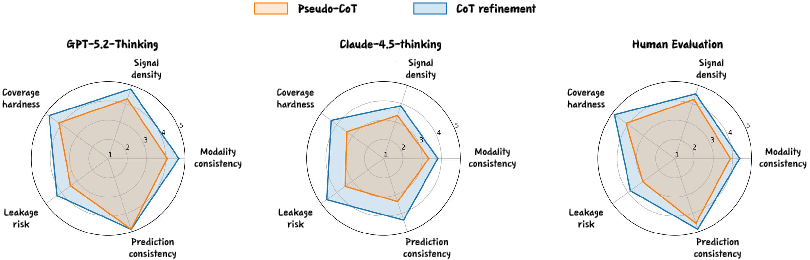
Figure 5: CoT refinement yields higher scores over pseudo-CoT on five data-quality dimensions in both automated and human evaluations.
Model scale analyses reveal that larger Qwen3-VL backbones consistently deliver higher ranking metrics, corroborating necessity for scale in leveraging multimodal CoT supervision (Figure 6). Hyperparameter sensitivity confirms improvements from higher group sizes G, moderate KL β, and careful filtering ratios p (Figure 7).
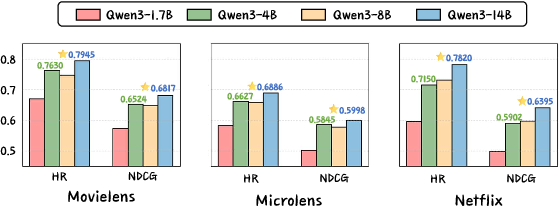
Figure 6: Larger Qwen3-VL backbones significantly improve HR@3 and NDCG@3 across datasets.
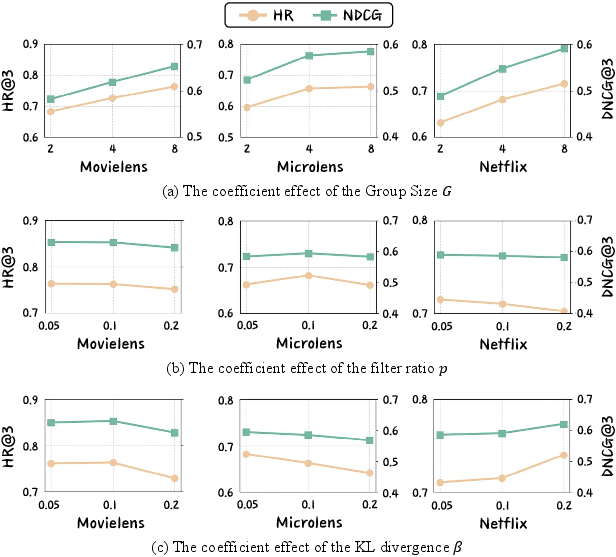
Figure 7: Hyperparameter studies reveal clear impacts of group size, filtering ratio, and KL coefficient on HR and NDCG metrics.
Reward convergence is rapid within 0.2–0.5 epoch, stabilizing after 2–3 epochs with higher reward plateaus on MovieLens and MicroLens (Figure 8).
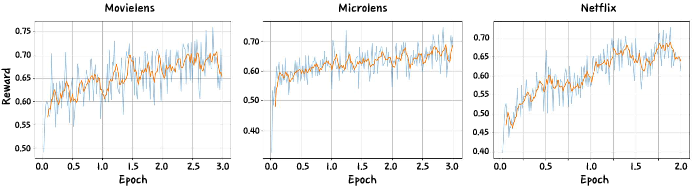
Figure 8: GRPO-based training reward curves on benchmark datasets show rapid early convergence and stable late-stage plateaus.
Case studies further evidence reduction in shortcut reliance and stronger alignment with fine-grained multimodal preferences (Figure 9).

Figure 9: Multimodal CoT reasoning improves within-group distinction and target ranking in MovieLens sequence test cases.
Implications and Future Research Directions
MLLMRec-R1 demonstrates that combining offline textualization of multimodal signals with filtered CoT data and lightweight GRPO reward design yields scalable, stable improvements in preference modeling for sequential recommendation. The approach manages efficiency bottlenecks and generalization failures inherent in naive multimodal LLM architectures. The framework offers practical tractability for large candidate sets and long interaction histories.
Theoretical implications include the utility of modality consistency and prediction consistency as fundamental data quality metrics. Observed gains validate the role of targeted CoT supervision and groupwise RL signal aggregation in incentivizing deep reasoning. The results motivate further exploration of adaptive filtering, automatic leakage-risk assessment, and model-scale selection.
Practically, the research unlocks efficient deployment of multimodal recommender systems in resource-constrained environments, avoiding the exponential compute of visual-token pipelines. The methodology is directly extensible to other cross-modal reasoning domains (e.g., visual question answering, entity recognition) and can inform future reinforcement-learning post-training paradigms for MLLMs.
Future work should investigate more robust reward structures beyond format and hit checks, adaptive augmentation ratios, and transferability to domains with heterogeneous modalities (audio, video, text). Integration with retrieval-augmented generation and automatic CoT quality evaluators also represents promising directions.
Conclusion
MLLMRec-R1 sets a new state-of-the-art for multimodal sequential recommendation with significant quantitative and qualitative improvements over both LLM- and MLLM-based architectures. By textualizing multimodal evidence, constructing high-quality CoT supervision, and employing mixed-grained augmentation with GRPO-based optimization, the framework achieves superior alignment, ranking, and generalization. The approach offers both algorithmic efficiency and practical scalability, with broad implications for the design of robust, reasoning-driven recommender systems in multimodal domains (2603.06243).