World Properties without World Models: Recovering Spatial and Temporal Structure from Co-occurrence Statistics in Static Word Embeddings
Abstract: Recent work interprets the linear recoverability of geographic and temporal variables from LLM hidden states as evidence for world-like internal representations. We test a simpler possibility: that much of the relevant structure is already latent in text itself. Applying the same class of ridge regression probes to static co-occurrence-based embeddings (GloVe and Word2Vec), we find substantial recoverable geographic signal and weaker but reliable temporal signal, with held-out R2 values of 0.71-0.87 for city coordinates and 0.48-0.52 for historical birth years. Semantic-neighbor analyses and targeted subspace ablations show that these signals depend strongly on interpretable lexical gradients, especially country names and climate-related vocabulary. These findings suggest that ordinary word co-occurrence preserves richer spatial, temporal, and environmental structure than is often assumed, revealing a remarkable and underappreciated capacity of simple static embeddings to preserve world-shaped structure from text alone. Linear probe recoverability alone therefore does not establish a representational move beyond text.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “World Properties without World Models”
What’s this paper about?
This paper asks a big question: Do computer LLMs “know” things about the real world (like where cities are or when people lived) because they build internal “world maps,” or because that information is already hidden in the way words appear together in text? The authors test this by using very simple word representations—made only from how often words co-occur in text—and see how much real-world information they can pull out.
What were the researchers trying to find out?
They focused on three easy-to-understand questions:
- Can simple word vectors (made from text alone) predict where cities are on the globe?
- Can they estimate when famous people lived?
- If the answer is yes, is this because certain kinds of words (like country names or climate words) carry that signal?
How did they do it? (Methods in everyday language)
Think of each word (like “Paris” or “Aristotle”) as having a “fingerprint” made from who it hangs out with in sentences. If “Paris” often appears near words like “France,” “Eiffel,” and “capital,” its fingerprint reflects that. Two classic tools do this:
- GloVe and Word2Vec: These turn each word into a 300-number vector based on which words it appears with across lots of text. No context, no fancy layers—just co-occurrence patterns.
Then they tried to read real-world facts from those vectors using a simple technique:
- Linear “probe” (ridge regression): Imagine drawing the best straight line that turns a word’s 300 numbers into a single answer, like “latitude” or “birth year.” Ridge regression is just a careful way of fitting that line so it doesn’t overfit.
What they tested:
- 100 world cities: Predict latitude, longitude, average temperature, year founded, elevation, GDP per person, and population.
- 194 historical figures: Predict birth year, death year, and “midlife” year.
How they checked where the signals come from:
- Word association sweeps: They looked for ordinary words (like “tropical,” “skiing,” “ancient”) that tend to be closer to certain cities or people and asked if those patterns match climate or time.
- “Subspace ablation”: Think of “muting” certain topics in the vectors—like shutting off directions related to country names or climate words—and seeing if predictions get worse. They also compared this to muting random directions to make sure the effect was really about meaning, not just removing information.
What did they find, and why is it important?
Here are the main takeaways:
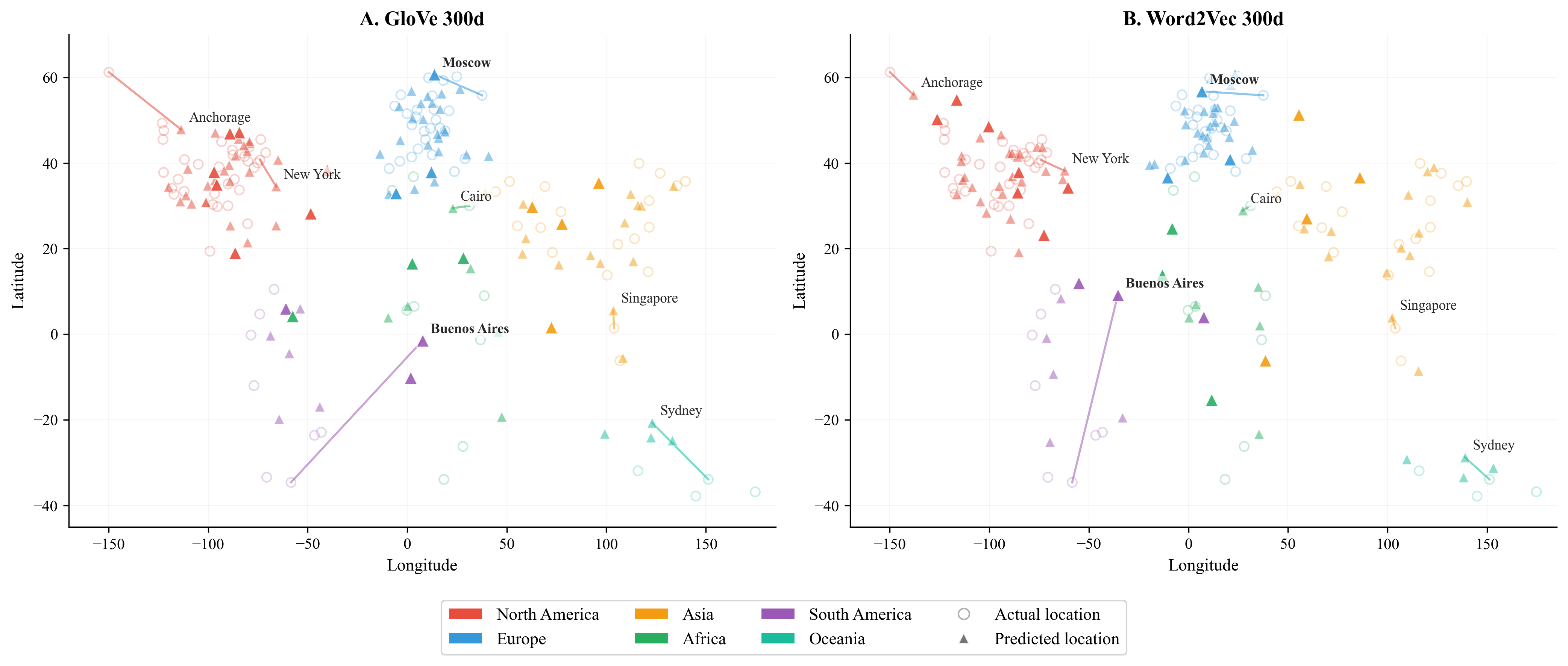
- City locations are surprisingly predictable: From just the co-occurrence-based vectors, they could guess cities’ latitude and longitude quite well. The predictions weren’t perfect, but the global layout (which regions cities belong to) was captured strongly.
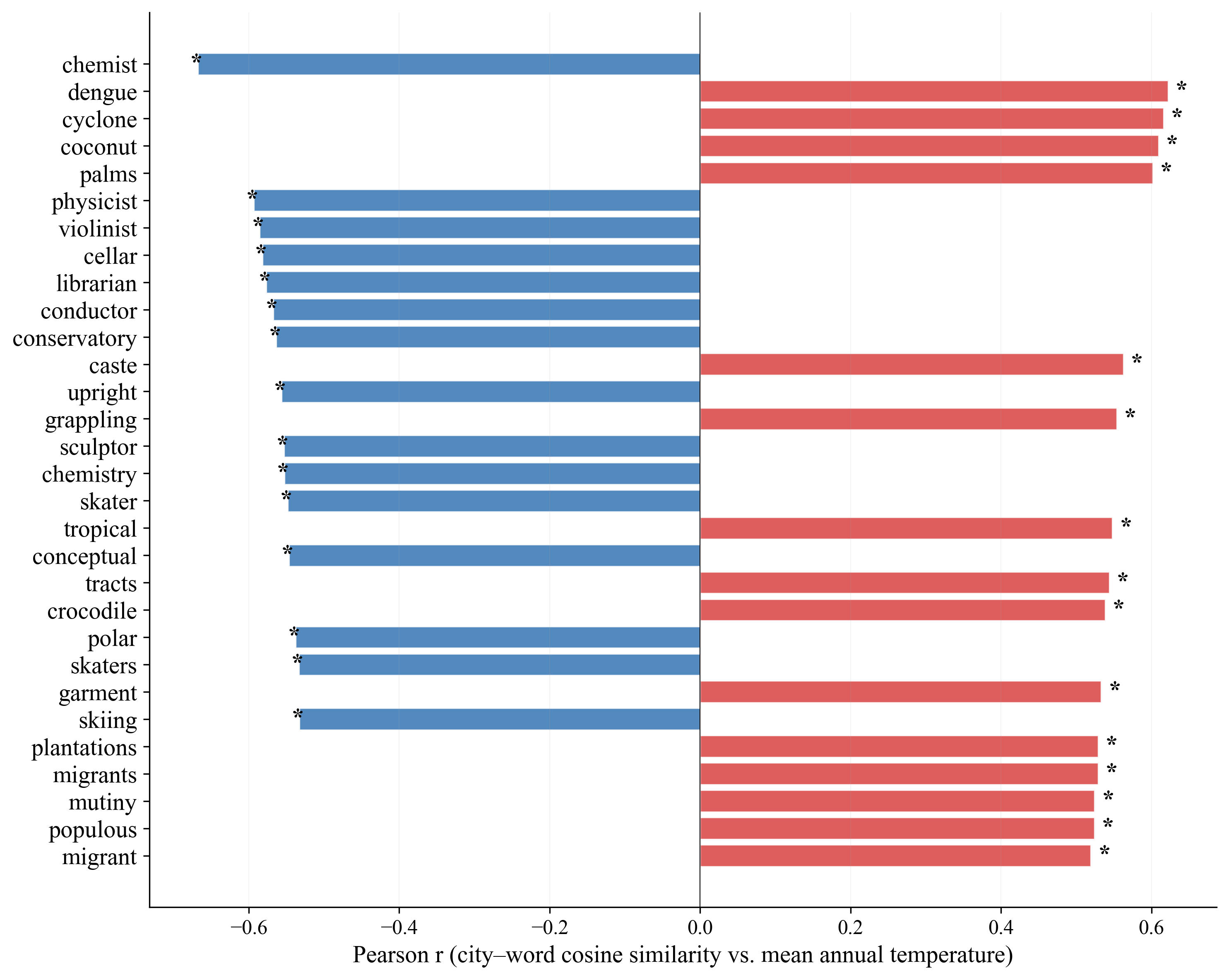
- Temperature is also predictable: The models could predict a city’s average temperature moderately well. Cities closer to words like “tropical,” “coconut,” and “cyclone” tended to be warmer; cities nearer to “skiing,” “polar,” or European-culture words tended to be colder.
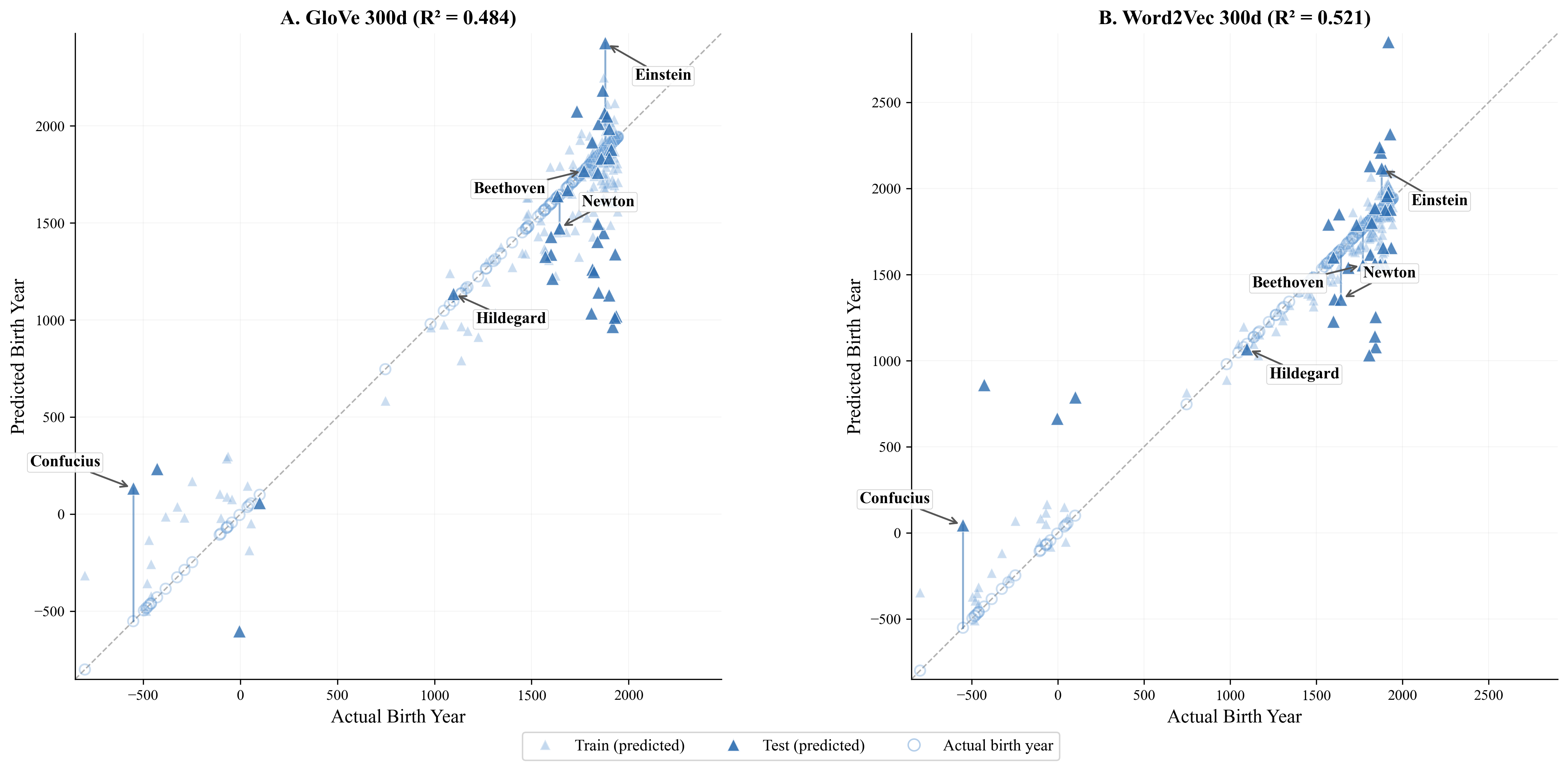
- Historical timing is coarsely predictable: They could tell roughly which era a historical figure belonged to (ancient, medieval, modern), but not the exact year.
- Some things were not predictable: Elevation, GDP per person, and population didn’t come through in a simple linear way. That’s good—it shows the method isn’t just pulling out anything; it works when the text actually reflects the property.
- The signals are carried by meaningful vocabularies: Muting country names or climate-related words made geographic and temperature predictions drop a lot—much more than muting random information. That means specific, understandable word groups carry much of the “map and climate” signal.
Why this matters:
- It shows that a lot of world structure is already present in text: The way people write about places and people naturally reflects geography and history. Models can pick up these patterns without having a built-in “world model.”
- It cautions how we interpret fancy models: Big LLMs can do even better, but this paper shows that simply being able to linearly “read out” space and time doesn’t prove a model has a true, internal world map. Some of that success may just come from text patterns.
What does this mean going forward?
- For researchers: To claim that a model has a real “world model,” we need stronger evidence than linear readouts—like showing more precise, flexible, or compositional understanding than what simple co-occurrence can explain.
- For understanding language and knowledge: Text is rich. It quietly encodes real-world patterns—where places are, what climates they have, and when people lived—because that’s how humans write. Even simple word vectors capture a surprising amount of this.
- For building better AI: Knowing how much comes from text alone helps set a fair baseline and clarifies what extra abilities more advanced models truly add.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unanswered questions that follow from the paper and could guide future research:
- Scale and coverage: How do results change when scaling to thousands of cities and entities (e.g., full GeoNames/DBpedia), including small towns, landmarks, and less-covered regions?
- Geographic resolution: What is the spatial resolution limit of static embeddings (e.g., median km error, within-country ranking accuracy, city-pair distance correlations), and how does error vary locally vs. globally?
- Temporal precision: Can finer-grained temporal information (e.g., decade-level birth years, event timelines) be linearly recovered with larger datasets, better disambiguation, or alternative targets (events, inventions, wars)?
- Cross-continent/region generalization: Does a probe trained on one set of regions (e.g., Europe) generalize to held-out regions (e.g., Africa, Oceania)? Evaluate continent-level leave-one-group-out splits.
- Corpus dependence: How sensitive are the signals to corpus domain, size, and recency (e.g., Wikipedia-only vs. Common Crawl, historical corpora, news vs. fiction)? Quantify performance as a function of training data.
- Model dependence: Do other distributional embeddings (fastText with subword features, SGNS vs. CBOW, SVD on PPMI/SPMI, higher-dimensional models) preserve equal or greater spatial/temporal structure?
- Language and cross-lingual robustness: Do non-English embeddings exhibit similar structure? Do aligned multilingual spaces yield consistent geographic/temporal axes across languages?
- Entity representation quality: How much do results improve with robust entity linking and dedicated entity embeddings (vs. averaging tokens or using ambiguous surface forms)?
- Polysemy and ambiguity: To what extent do homonyms (e.g., “Washington,” “Jordan”) distort recoverability? Test with controlled disambiguation and homonym-free entity sets.
- Out-of-vocabulary handling: How do subword/character-level methods affect coverage and recovery for rare entities and locations with diacritics or transliteration variants?
- Negative controls robustness: Are non-recoverable attributes (e.g., elevation, GDP, population) still unrecoverable with larger, cleaner labels, alternative sources, or domain-specific corpora?
- Alternative targets: Do other spatial/environmental variables (time zone, hemisphere, precipitation, Köppen climate class, coastal vs. inland) show linear recoverability?
- Longitude mechanism: What lexical or co-occurrence features specifically carry longitude (e.g., time-zone terminology, co-mentions with east–west neighbors)? Conduct targeted feature attribution and subspace discovery.
- Probe class boundaries: How much additional signal emerges with controlled nonlinear probes (e.g., shallow MLPs with strict capacity constraints and control tasks) versus linear ones?
- Stronger controls for probing: Add label permutation, randomized target baselines, and complexity-controlled probes to calibrate chance performance and avoid overinterpretation.
- Multiple comparisons in semantic correlations: Vocabulary-wide correlation analyses should apply FDR/BH or Bonferroni corrections; re-run with corrections and report effect-size distributions.
- Subspace ablation methodology: How sensitive are ablation outcomes to subspace dimensionality selection (variance thresholds), PCA vs. other bases, and the number of random subspace controls (100 vs. 10,000)?
- Causal interventions beyond ablation: Train embeddings on corpora with systematically removed or masked categories (e.g., country names, climate words) to test whether signals persist or vanish.
- Corpus-level counterfactuals: Create controlled synthetic corpora that decorrelate climate vocabulary from geography to test causal claims about which lexical gradients produce spatial signals.
- Error analysis: Systematically characterize mispredictions (e.g., Buenos Aires, Sydney) by features like news salience, tourism, ambiguity, language, and data sparsity.
- Bias and confounds: Quantify sociocultural confounds (e.g., “chemist/violinist” correlating with colder cities) and assess to what extent these reflect Western/colonial reporting biases vs. true climatic signals.
- Within-country analyses: Do probes recover intra-country gradients (north–south within Italy, east–west within the U.S.) after controlling for language and culture?
- Domain/time-shift robustness: How do signals change when training on historical-only vs. modern-only corpora, or when probing entities introduced after the corpus time window?
- Evaluation metrics: Report geodesic (km) error, great-circle correlation, and calibration curves for geography; for time, MAE/MSE by era and ordinal-ranking accuracy to complement R2.
- Data quality and label noise: Validate and standardize labels (temperature, founding year) across sources; quantify how label noise impacts recoverability.
- Composite-axis minimality: What is the smallest set of anchor words (beyond cold–warm) that approximates geographic/temporal recovery? Formalize sparse axis discovery procedures.
- Compositionality tests: Can embeddings support composition (e.g., “city near X and on Y coast”) or analogical spatial queries beyond single-attribute decoding?
- OOD generalization: Train on one type of entities (capitals) and test on another (non-capital cities), or train on people and test on events, to probe robustness.
- Matching to LLM settings: Reproduce LLM-scale datasets and entity coverage with static embeddings to more precisely quantify the performance gap and what factors account for it.
- Operationalizing “beyond text”: Define empirical criteria (e.g., compositional generalization, invariance under corpus masking, higher spatial resolution than text baselines) that would constitute evidence for representations exceeding co-occurrence.
- Reproducibility of historical-figure results: The paper reports split stability for cities but not historical figures; replicate stability analyses (multiple seeds/splits) for temporal targets.
- Tokenization and phrase segmentation: Assess how improved phrase mining (e.g., AutoPhrase) or canonicalized geoname forms affect recoverability.
- Alternative dimensionality manipulations: Test whitening, mean-centering, and isotropy adjustments of embeddings to see whether geometry preprocessing alters probe performance.
- Ethical implications: Evaluate downstream risks of inferring geography or socioeconomic proxies from text-derived embeddings and propose mitigation or auditing protocols.
Glossary
- Antonym pair: A pair of words with opposite meanings used to define a semantic contrast or axis. "antonym pairs (e.g., similarity to
cold'' minus similarity towarm'')" - CBOW (Continuous Bag-of-Words): A Word2Vec architecture that predicts a target word from surrounding context words. "The Google News vectors were trained with the continuous bag-of-words (CBOW) architecture with negative sampling."
- Co-occurrence matrix: A matrix whose entries capture how often word pairs appear together in a corpus. "GloVe factorizes a log-bilinear co-occurrence matrix."
- Co-occurrence statistics: Statistical patterns of how words co-occur in text, used to learn embeddings. "Static word embeddings are derived from corpus co-occurrence statistics"
- Composite score: A combined metric formed by combining simpler measures, often to amplify a contrast. "We also construct composite scores by taking the difference in cosine similarity to antonym pairs"
- Constant-mean baseline: A trivial predictor that always predicts the mean of the training targets, used for comparison. "negative test indicates performance worse than a constant-mean baseline"
- Cosine similarity: A similarity measure between vectors based on the cosine of the angle between them. "we compute its cosine similarity to each of the 86 city embeddings"
- Cross-validation: A procedure for selecting hyperparameters by training/validating on different data folds. "We select via 5-fold cross-validation on the training set"
- Demonym: A word that denotes the residents of a place (e.g., “Parisian”). "filtering out proper nouns, city and country names, demonyms, and words shorter than four characters"
- Dimensionality reduction: Techniques for reducing the number of variables in data while preserving structure. "not a consequence of generic dimensionality reduction"
- Distributional semantics: An approach to meaning where words are represented by their distributional contexts. "Distributional semantics and worldly structure."
- Hidden-state dynamics: Temporal or layer-wise changes in internal activations of a model across processing steps. "no contextual processing, no layered abstraction, and no hidden-state dynamics"
- Lexical gradient: A systematic variation in word usage that forms a continuous semantic trend. "depend strongly on interpretable lexical gradients"
- Linear decodability: The ability to recover a variable from representations using a linear mapping. "prior claims of world-model structure relied on linear decodability"
- Linear probe: A simple linear model used to test what information is present in representations. "train linear and MLP probes on Llama-2 hidden states"
- Log-bilinear co-occurrence matrix: A co-occurrence matrix formed or weighted in log-bilinear form for factorization. "GloVe factorizes a log-bilinear co-occurrence matrix."
- Log transform: Applying a logarithm to data to stabilize variance or normalize distributions. "GDP and population are log-transformed before probing."
- Matrix factorization: Decomposing a matrix into a product of simpler matrices to reveal latent structure. "\citet{levy2014neural} proved that Word2Vec's skip-gram with negative sampling is implicitly factorizing a shifted pointwise mutual information (SPMI) matrix"
- Mean absolute error (MAE): The average absolute difference between predictions and true values. "with mean absolute errors of 338--364 years."
- Negative control: A test target expected not to yield signal, used to validate selectivity of methods. "As negative controls, elevation, GDP per capita, and population yield low or negative test "
- Negative sampling: A training technique where non-observed pairs are sampled as negative examples for efficiency. "The Google News vectors were trained with the continuous bag-of-words (CBOW) architecture with negative sampling."
- Orthonormal subspace: A subspace spanned by orthonormal vectors (mutually orthogonal, unit length). "random orthonormal subspaces of the same dimensionality"
- Pearson correlation coefficient (Pearson r): A measure of linear correlation between two variables. "correlate with the cities' actual mean annual temperatures (Pearson )"
- Principal component analysis (PCA): A method to find orthogonal directions (components) capturing maximal variance. "Compute the principal subspace they span via PCA"
- Principal subspace: The subspace spanned by the leading principal components capturing most variance. "Compute the principal subspace they span via PCA"
- Projection (in embedding space): Mapping a vector onto a subspace, often to remove or isolate components. "Project each city embedding onto this subspace and subtract the projection"
- Regularization parameter (λ): A hyperparameter controlling the strength of regularization to prevent overfitting. "and is the regularization parameter."
- Ridge regression: A linear regression with L2 regularization on coefficients. "All probes are ridge regression models"
- Semantic axis: A continuous direction in embedding space capturing a specific semantic contrast. "functions as a semantic axis defined by the proximity of city names to descriptors such as dengue and tropical"
- Semantic-neighbor analysis: Examining nearest neighbors or similarity patterns to interpret semantic structure. "Semantic-neighbor analyses and targeted subspace ablations show that these signals depend strongly on interpretable lexical gradients"
- Shifted pointwise mutual information (SPMI): PMI shifted by a constant, whose matrix is implicitly factorized by SGNS. "implicitly factorizing a shifted pointwise mutual information (SPMI) matrix"
- Skip-gram with negative sampling: A Word2Vec training objective predicting context words for a target, trained with negative sampling. "Word2Vec's skip-gram with negative sampling is implicitly factorizing a shifted pointwise mutual information (SPMI) matrix"
- Subspace ablation: Removing components of embeddings along specific semantic directions to test their functional role. "we perform subspace ablation experiments on GloVe embeddings."
- Train/test split: Partitioning data into separate sets for training and evaluating model performance. "Data are split 80/20 into train/test sets with a fixed random seed."
- Z-score: A standardized score indicating how many standard deviations a value is from the mean. "reporting -scores"
Practical Applications
Below is an overview of practical, real-world applications that follow from the paper’s findings and methods. Each item notes sectors, potential tools/products/workflows, and assumptions/dependencies that affect feasibility.
Immediate Applications
- Lightweight geotagging from text via static embeddings
- Sector(s): software, GIS, journalism, advertising
- What: Infer approximate latitude/longitude for city/entity mentions in text using GloVe/Word2Vec + ridge regression, producing quick map placements when metadata is missing.
- Tools/workflows: Pretrained embeddings, off-the-shelf ridge probe, “text-to-map” pipeline (NER → embedding lookup/phrase averaging → probe → GIS visualization).
- Assumptions/dependencies: Coverage of entity names in the embedding vocabulary; coarse accuracy (city-level, not street-level); ambiguity for homonyms and multiword entities; corpus biases inherited by embeddings.
- Era tagging for historical/person entities
- Sector(s): digital humanities, archives, education
- What: Estimate coarse historical era (e.g., ancient/medieval/modern) for names in corpora to enrich catalog metadata, search, and timeline visualizations.
- Tools/workflows: Ridge probe on static embeddings; simple antonym composite (e.g., “modern”–“ancient”) as a fast heuristic; integration with NER.
- Assumptions/dependencies: Coarse granularity (MAE ~300+ years); surname-based ambiguity; Western-centric corpus biases; requires human-in-the-loop for curation.
- Climate signature estimation from text
- Sector(s): travel, public health communication, energy marketing
- What: Approximate mean annual temperature or climate class for city mentions to inform travel recommendations, broad climate awareness in content, and high-level disease/climate communication (e.g., dengue/tropical associations).
- Tools/workflows: Cold–warm composite scores; climate vocabulary gradients; ridge probe; “text-to-climate” dashboards.
- Assumptions/dependencies: Coarse estimates; vulnerable to sociocultural and corpus biases; not suitable for microclimate or safety-critical decisions.
- Baseline-probing for interpretability claims
- Sector(s): academia, AI governance
- What: Use static-embedding baselines to contextualize claims that LLMs learn “world models,” ensuring linear decodability results exceed what is latent in co-occurrence alone.
- Tools/workflows: Ridge probes; matched datasets; report static-embedding baselines alongside LLM probes; semantic subspace ablation controls.
- Assumptions/dependencies: Comparable datasets are needed for fair baselines; results sensitive to corpus choice and entity coverage.
- Dataset auditing for geographic/temporal leakage
- Sector(s): ML engineering, privacy/compliance, policy
- What: Detect whether labels are inadvertently predictable from textual co-occurrence (e.g., geography/climate proxies) to prevent leakage and unfair advantages in benchmarks.
- Tools/workflows: Semantic subspace identification (country/climate terms), ablation versus random controls, R² drop analysis.
- Assumptions/dependencies: Curated word lists for subspaces; careful interpretation to avoid over-attributing causality; reproducible splits and controls.
- Feature engineering in low-resource pipelines
- Sector(s): software, startups, NGOs
- What: Add approximate geo/era features for downstream models when structured attributes are missing (e.g., clustering documents by inferred region).
- Tools/workflows: Embedding-derived proxies; calibration with small labeled sets; light regularization.
- Assumptions/dependencies: Risk of bias amplification and label leakage; features are coarse and must be validated for each domain.
- Entity disambiguation heuristics
- Sector(s): search, knowledge bases
- What: Use predicted coordinates/era to help distinguish homonymous entities (e.g., “Paris” the city vs. person) in knowledge graph linking and search.
- Tools/workflows: Combined NER + probe; heuristic filters using predicted geo/temporal proximity; human review for edge cases.
- Assumptions/dependencies: Incomplete disambiguation for sparse or ambiguous mentions; depends on high-quality NER and phrase handling.
- Education and outreach demos
- Sector(s): education, public communication
- What: Interactive tools to teach distributional semantics and interpretability (e.g., “co-occurrence maps,” “era sliders,” semantic ablation effects).
- Tools/workflows: Simple visualizations of probe predictions and subspace ablations; classroom notebooks.
- Assumptions/dependencies: Educational framing to emphasize limitations (coarse predictions, biases).
- Open-source “CoOccur-GeoTime” utility
- Sector(s): software
- What: A Python package that provides text-to-geo/era inference, semantic subspace audit, and composite-score baselines.
- Tools/workflows: spaCy/Stanza NER integration; GloVe/Word2Vec loaders; ridge regression; GIS export.
- Assumptions/dependencies: Licensing and distribution of embeddings; documentation on ethical use and limitations.
- Content localization and recommendation
- Sector(s): advertising, media platforms
- What: Tailor content by inferred region/climate themes from text when explicit location metadata is absent.
- Tools/workflows: Geo/climate proxies from embeddings; lightweight personalization rules.
- Assumptions/dependencies: Privacy and ethical concerns; coarse inference may mis-target users; avoid sensitive attribute inference.
Long-Term Applications
- Standardized probing benchmarks with distributional baselines
- Sector(s): academia, policy
- What: Community benchmarks that require reporting static-embedding baselines and interpretability controls (e.g., subspace ablations) alongside LLM probes.
- Tools/workflows: Matched datasets across models; evaluation templates; repositories.
- Assumptions/dependencies: Broad adoption; consensus on probe families and controls; continuous maintenance.
- Context-aware entity embeddings for finer geo/time resolution
- Sector(s): software, search, knowledge graphs
- What: Build phrase- and context-sensitive entity representations that reduce ambiguity and improve prediction granularity while retaining interpretability via subspace analysis.
- Tools/workflows: Phrase embeddings; contextual pooling; alignment with curated KBs; hybrid probes.
- Assumptions/dependencies: Larger corpora; robust phrase mining; careful evaluation to avoid overfitting.
- GIS–NLP integrated pipelines for corpus-driven mapping
- Sector(s): journalism, intelligence, humanitarian analysis
- What: Scalable systems that map global textual narratives into spatial/temporal layers (e.g., climate/disaster discourse, era-specific narratives).
- Tools/workflows: Entity extraction → embedding/probes → geospatial layers → validation with external datasets.
- Assumptions/dependencies: Ethics and safety reviews; data bias assessment; human analyst oversight.
- Bias mitigation via controllable semantic subspace manipulation
- Sector(s): finance, hiring, healthcare
- What: Use semantic subspace identification/ablation to audit and, where appropriate, dampen geography- or climate-linked spurious correlations in downstream models.
- Tools/workflows: Subspace discovery; differential performance testing; governance dashboards.
- Assumptions/dependencies: Reliable word-category lists; risk of removing useful signal; domain-specific validation.
- Cross-lingual extensions
- Sector(s): global products, multilingual research
- What: Apply the approach to multiple languages to recover geo/temporal structure across diverse corpora and compare cultural encoding of space/time.
- Tools/workflows: Multilingual embeddings; language-specific semantic categories; cross-lingual alignment.
- Assumptions/dependencies: Quality and coverage of non-English corpora; differences in naming conventions and lexical resources.
- Knowledge base augmentation with human-in-the-loop verification
- Sector(s): cultural heritage, libraries, enterprise KBs
- What: Populate missing geotags/eras for entities using probe outputs, then verify and correct via expert review.
- Tools/workflows: Batch inference; confidence thresholds; annotation workflows.
- Assumptions/dependencies: Acceptance of coarse predictions; annotation capacity; provenance tracking.
- Environmental and development analysis from text
- Sector(s): policy analysis, NGOs
- What: Use text-derived climate/geography proxies in regions with limited structured data to prioritize qualitative assessments before investing in field data collection.
- Tools/workflows: Corpus ingestion; climate proxy mapping; triangulation with satellite or public datasets.
- Assumptions/dependencies: High uncertainty; must be combined with external data; risk of bias from corpus coverage.
- New interpretability standards for “world model” claims
- Sector(s): policy, AI governance
- What: Certification frameworks where claims of world-structured internal representations must beat strong static baselines and demonstrate compositional/generalization criteria beyond linear decodability.
- Tools/workflows: Audit protocols; threshold performance criteria; reproducibility checks.
- Assumptions/dependencies: Community buy-in; regulatory engagement; clear definitions of “beyond text.”
- Probes beyond linear readouts to test compositional spatial/temporal reasoning
- Sector(s): research
- What: Design tasks and probes that require nontrivial composition (e.g., spatial relations, temporal arithmetic) to distinguish LLM representations from co-occurrence baselines.
- Tools/workflows: Challenge datasets; nonlinear, constrained probes; behavioral generalization tests.
- Assumptions/dependencies: Careful control against shortcut learning; open datasets and leaderboards.
- Ethical guardrails for location/era inference
- Sector(s): policy, platform governance
- What: Guidelines that govern when and how coarse geo/era inference may be used (e.g., ban sensitive targeting, require disclosures).
- Tools/workflows: Impact assessments; transparency statements; opt-out mechanisms.
- Assumptions/dependencies: Legal compliance; stakeholder engagement; monitoring for misuse.
These applications rely on the paper’s core insights: static co-occurrence-based embeddings already encode recoverable spatial, temporal, and environmental structure; semantic subspaces (e.g., country names, climate vocabulary) carry much of the signal; and linear probe decodability alone is insufficient evidence of “world models.” As such, immediate uses favor lightweight, coarse inference and auditing, while long-term uses focus on standardization, bias mitigation, richer context-aware models, and governance.
Collections
Sign up for free to add this paper to one or more collections.