- The paper introduces SemLoco, embedding semantic information directly into RL controllers to enhance foothold safety and obstacle avoidance.
- It employs a hybrid perception system that fuses geometric and semantic cues with a two-stage reinforcement learning curriculum to refine locomotion.
- Experiments demonstrate up to a 95% reduction in step collisions and near-perfect survival rates in dense obstacle settings.
SemLoco: Semantic-Aware Locomotion for Legged Robots in Cluttered Environments
Motivation and Problem Statement
The SemLoco framework addresses the critical limitations of current quadruped locomotion controllers when deployed in densely cluttered, human-centric environments. Existing algorithms either rely exclusively on geometric proxies in elevation maps or apply semantic constraints only at path planning levels, resulting in frequent missteps onto low-lying obstacles such as cables or fragile devices. This failure stems from the disconnect between high-level semantic perception and low-level, high-frequency motor control. SemLoco directly embeds semantic information into the RL-based controller, allowing explicit pixel-wise foothold safety inference and precise gait adaptation for obstacle avoidance.
SemLoco Framework Architecture
SemLoco utilizes a hybrid pipeline with both geometric and semantic perception for low-level control. The policy is trained via a two-stage RL curriculum progressing from virtual (soft) to rigid (hard) constraints. Observations fuse proprioceptive state, exteroceptive elevation, and semantic maps. The neural architecture combines CNN feature extraction from maps and MLPs for actor/critic, with a supervised velocity estimator supporting end-to-end base tracking.
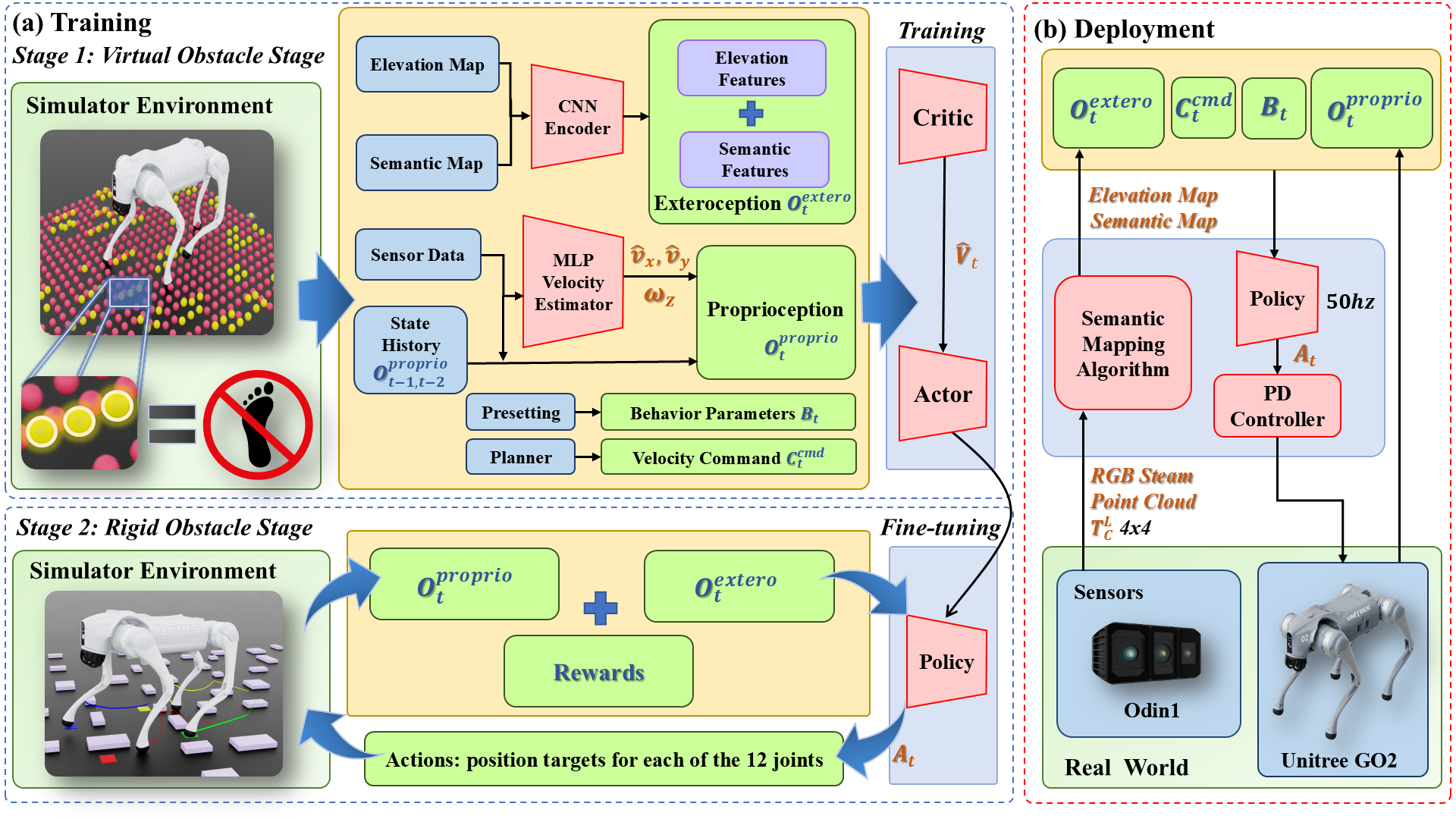
Figure 1: SemLoco pipeline showing two-stage RL training with virtual and rigid obstacles and real-world deployment using a semantic segmentation module (Odin1) for perception fusion.
During training, simulated environments use virtual obstacles for initial policy acquisition, followed by fine-tuning in environments with rigid obstacles to reinforce physical avoidance capabilities. Real-world deployment leverages the Odin1 spatial memory module for real-time semantic map fusion and low-latency control.
SemLoco introduces a semantic-aware Raibert heuristic for foothold selection. Nominal footholds are calculated using kinematic priors and refined via local search grids centered on the Raibert point, leveraging semantic traversability scores. Candidate footholds are penalized using a composite cost function involving deviation from the nominal point and collision with semantic hazards, with punitive weights favoring safe placement.
Rewards combine primary objectives of velocity tracking and semantic-aware foothold tracking, enforced via exponential auxiliary penalties. The ReLU clearance penalty ensures flexible leg swing elevation, favoring minimum safe clearance during cluttered traversal rather than rigid trajectory adherence, mitigating toe-stubbing risk under physical constraints.
Two-Stage Reinforcement Learning Curriculum
The two-stage curriculum resolves the exploration versus safety dilemma inherent in dense obstacle navigation. In stage one, policy learns spatial semantic mapping without risk from virtual objects, forming robust perception-motor coordination. In stage two, rigid obstacles are introduced, enabling physical constraint learning and adaptation to real-world friction, collision, and proprioceptive noise. Velocity and obstacle density curricula encourage progressive adaptation, avoiding premature convergence to conservative, unsafe policies.

Figure 2: Virtual semantic elevation map, illustrating traversability coding and obstacle elevations for the curriculum.



Figure 3: Examples of obstacle density curricula, illustrating incremental complexity in training environments.
Experimental Analysis and Quantitative Evaluation
Experiments assess SemLoco against blind and ablative baselines in Isaac Sim and real-world cluttered settings. Primary metrics are average distance to failure, success rate, and step collision rate across variable obstacle densities. SemLoco achieves near-perfect survival (distance > 9 m, success > 82% at maximum density), with step collision rates reduced by up to 95% relative to blind baselines. Ablation studies highlight the necessity of virtual obstacle stage for spatial exploration, ReLU clearance penalties for robust clearance, and semantic map input for precise avoidance, as strict geometric methods fail in scenarios with ambiguous or noisy elevation data.

Figure 4: Performance contrast among different policies in real world, demonstrating reduced collisions and improved survival with full SemLoco pipeline.
Real-world deployments validate semantic disentanglement: elevation-only methods fail to distinguish low-profile hazards under sensor noise, while semantic maps enable proactive adjustments in stride and swing trajectories, preventing object damage and robot instability.
Implications, Limitations, and Future Directions
SemLoco provides a robust paradigm for foot-level semantic reasoning in legged locomotion, facilitating precise navigation in environments with diverse, fragile, or ambiguous obstacles. The explicit integration of semantic traversability into low-level control bridges the gap between vision-driven perception and motor execution, supporting real-world deployment in domestic, industrial, and service robotics.
However, limitations persist. Extreme asymmetric foothold placements can induce undesirable yaw drift and approach kinematic singularities. Hardware constraints affect tracking bandwidth, occasionally resulting in toe-stubbing. The semantic simulation environment, currently restricted to simplified shapes, imparts a sim-to-real gap, limiting fidelity and generalization. Compression of semantics into a singular fragility cost omits complex open-vocabulary interaction semantics required for broader applications.
Future research will explore enhanced semantic simulators, open-vocabulary Vision-Language-Action (VLA) models, and generalization across unseen object types and clutter distributions, expanding semantic-aware locomotion's applicability to unconstrained real-world settings while retaining low-latency foot-level control.
Conclusion
SemLoco demonstrates that explicit semantic information, tightly integrated into RL-based low-level locomotion controllers, substantially improves precision and safety in dense, cluttered environments. By bridging high-level semantic perception with low-level motor execution, the framework reduces collision rates and increases traversal success, outperforming geometric and blind baselines. The two-stage RL curriculum, semantic-aware foothold planning, and flexible clearance constraints are indispensable for robust real-world deployment. Further advancements in high-fidelity semantic simulation and open-vocabulary reasoning promise to extend this capability to increasingly diverse and challenging environments.
(2603.02657)