Test-Time Training with KV Binding Is Secretly Linear Attention
Abstract: Test-time training (TTT) with KV binding as sequence modeling layer is commonly interpreted as a form of online meta-learning that memorizes a key-value mapping at test time. However, our analysis reveals multiple phenomena that contradict this memorization-based interpretation. Motivated by these findings, we revisit the formulation of TTT and show that a broad class of TTT architectures can be expressed as a form of learned linear attention operator. Beyond explaining previously puzzling model behaviors, this perspective yields multiple practical benefits: it enables principled architectural simplifications, admits fully parallel formulations that preserve performance while improving efficiency, and provides a systematic reduction of diverse TTT variants to a standard linear attention form. Overall, our results reframe TTT not as test-time memorization, but as learned linear attention with enhanced representational capacity.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a method called test-time training (TTT) that updates part of a model while it’s being used. Many people think TTT acts like a “memory” that stores pairs of things called keys and values, then later looks them up with queries (like a mini database inside the model). The authors argue that this common idea is wrong. Instead, they show that TTT works like a special kind of attention called linear attention—a fast, efficient way for models to mix information—rather than true memorization.
What questions does the paper ask?
The paper asks:
- Does TTT really “memorize” key–value pairs at test time and retrieve them with queries?
- If not, what is it actually doing under the hood?
- Can we rewrite TTT in a simpler, faster form without losing performance?
How did they study it?
The authors used two approaches:
- Experiments: They tested TTT on different tasks (language modeling, image recognition, and 3D view synthesis) using popular TTT designs (LaCT and ViTTT). They looked for behaviors that would be expected if TTT were truly memorizing—and checked whether those behaviors matched reality.
- Math analysis: They carefully unrolled the internal update steps TTT does and proved that many TTT designs are mathematically equivalent to a linear attention operator. Think of this like opening a machine, tracing the gears, and showing that—even if it looks complex—it’s really just doing a simpler, known operation.
To make the technical parts more accessible:
- Attention with queries, keys, values (Q, K, V): In standard attention, a query looks for similar keys and then uses the matched values. It’s like searching for the best matching note in a notebook.
- Linear attention: A faster version of attention that mixes information in ways that scale more efficiently. It’s less about “looking up” and more about “blending” features smoothly.
- TTT inner loop: A small part of the model (fast weights) gets updated on the fly using a simple objective (like making
f(key)close tovalue). This has been thought of as “memorizing” pairs.
Main findings and why they matter
The authors discovered several “paradoxes” that contradict the memorization story. Here are the key observations, introduced with a sentence and listed for clarity:
The experiments revealed these surprising behaviors:
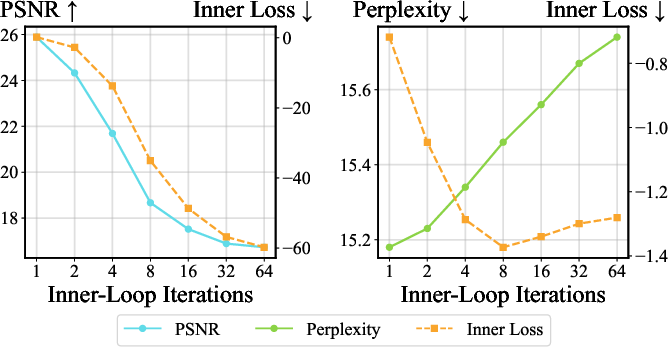
- Making the inner loop fit better (more update steps, lower inner loss) often makes overall performance worse. If it were true memory, better fitting should help, not hurt.
- Switching from gradient descent to gradient ascent (optimizing in the “wrong” direction) keeps performance similar or sometimes improves it. This shouldn’t happen if the goal is to learn accurate key–value mappings.
- Queries and keys don’t live in the same space. Their feature distributions are mismatched, so “querying stored keys” shouldn’t work reliably—but the model still works well.
- Replacing queries with keys changes almost nothing in performance. In standard attention, that would break retrieval; here it doesn’t.
Their theory explains why: the TTT inner loop isn’t storing and retrieving. It’s mixing features in a linear attention-like way. When they unroll the update math (under common conditions like a linear, bias-free last layer), the TTT computations collapse into the standard linear attention form. That means:
- The “memory” is really a running state updated by mixing transformed keys and values.
- Queries don’t need to match keys; they go through a related transform but serve a different role in the mixing.
- Flipping gradient signs (ascent vs. descent) can be absorbed into how values are mixed, so performance doesn’t collapse.
Practical wins:
- Simplify: Many add-ons (weight normalization, per-token learning rates, momentum, special optimizers) are often unnecessary.
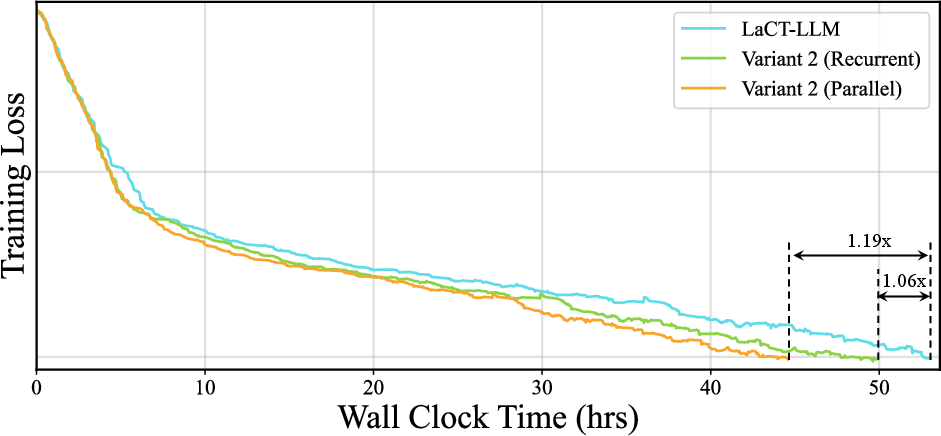
- Speed up: They show a fully parallel version that speeds up attention computation by up to 4× and improves end-to-end training speed (~1.19× in their setup).
- Unify: Different TTT variants (like LaCT and ViTTT) can be rewritten as standard linear attention, which makes them easier to compare and improve.
What’s the takeaway and impact?
This paper reframes how we think about TTT. Instead of “memorizing at test time,” TTT is better understood as learned linear attention—a flexible, efficient way to mix information from past tokens with current ones. This new view:
- Resolves confusing behaviors that contradicted the memory idea.
- Opens the door to simpler designs that are easier to implement and faster to run.
- Helps researchers and engineers reduce TTT complexity without sacrificing performance.
- Suggests that linear attention is a strong foundation for building efficient sequence models.
A small caveat: their proofs rely on the inner loop’s last layer being linear and without bias. Extending these results to more complex endings (like nonlinear or biased layers) is future work. But even within this scope, the impact is significant: TTT isn’t a test-time memory—it's a smart, efficient mixer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues that are either missing, uncertain, or left unexplored in the paper, formulated to be concrete and actionable for future research.
- Formalize the equivalence when the inner-loop’s final layer is nonlinear or includes bias terms, and determine conditions under which the linear-attention reduction still holds.
- Extend the theory to multiple inner-loop steps per token (beyond one-step updates), including a closed-form operator description and error bounds for finite-step approximations.
- Characterize which normalization or reparameterization operations on fast weights (e.g., weight normalization, layer norm, scaling) preserve associativity and parallelizability; identify normalization families that admit prefix-scan implementations.
- Generalize the linear-attention reinterpretation from TTT-KVB to TTT-E2E (inner loop optimized via downstream cross-entropy or task losses), including explicit mappings and failure modes.
- Provide rigorous conditions under which replacing gradient descent with ascent preserves performance across different inner-loop losses (MSE, dot-product, Huber), optimizers (SGD, Adam, RMSProp), and with common practices (gradient clipping, weight decay).
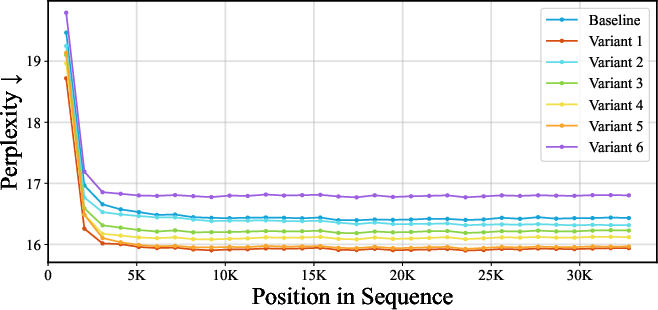
- Quantitatively assess the query–key distributional asymmetry across models, tasks, and layers using robust measures (e.g., MMD, KL divergence of learned feature distributions, cosine similarity histograms), beyond t-SNE visualizations.
- Test the “replace
QwithK” invariance across a broader set of architectures and tasks (e.g., algorithmic reasoning, retrieval QA, code generation), and diagnose where this invariance breaks. - Derive a principled understanding of when and why updating only the last layer (Variant 1) outperforms more complex inner loops; identify the regimes (data, sequence length, task) where deeper inner-loop MLPs are helpful.
- Analyze the role and mechanism of gradient orthogonalization (Muon-style) in LLM performance: when is it beneficial, what representations it promotes, and whether equivalent effects can be achieved with simpler operators.
- Provide theoretical and empirical comparisons of representational capacity between TTT-induced linear attention and modern selective/state-space mechanisms (e.g., Mamba, RWKV, gated/DeltaNet variants), including equivalence classes and separations.
- Investigate whether TTT’s original goal—robust adaptation to distribution shift—still holds under the linear-attention interpretation; design controlled OOD benchmarks and adaptation protocols to test this.
- Establish stability guarantees for the state update
S_t = S_0 + ∑ k_i^⊤ v_i(e.g., norm growth, saturation, exploding/vanishing), and identify stabilization strategies (scaling, damping, learned decay) compatible with parallelization. - Clarify how multi-head and cross-attention layers integrate with the proposed reduction: per-head state semantics, interactions across heads, and extension to cross-modal attention.
- Determine the impact of different inner-loop loss choices (MSE vs. dot-product vs. contrastive) and regularizers (weight decay, L2/L1, spectral penalties) on the effective value vector
ĝ_tand downstream performance. - Provide end-to-end benchmarks on standard long-context LLM suites (e.g., The Pile, FineWeb, RULER diagnostics) and diverse sequence lengths to verify length generalization and recency bias under the simplified linear-attention variants.
- Validate the reported throughput gains across hardware configurations (A100/H100, different memory hierarchies), batch sizes, and sequence lengths; quantify end-to-end versus layer-level speedups and identify bottlenecks.
- Investigate whether per-token learnable learning rates and momentum can be replaced with explicit selective/decay mechanisms (token- or data-dependent) while preserving parallelism; provide mappings to known gated/state-space designs.
- Explore training protocols that directly parameterize and train the simplified linear-attention operator (Variant 6) from scratch, versus distilling from complex TTT models; compare optimization dynamics and sample efficiency.
- Analyze the sensitivity of the linear-attention reduction to initialization of
S_0(i.e.,W_0): learned vs. fixed, per-layer vs. shared, and its spectral properties; provide guidance for stable and performant initialization. - Examine robustness to noisy or adversarial queries and keys under the linear-attention interpretation, including defenses and regularizations tailored to the induced operator.
- Provide formal proofs of equivalence (or counterexamples) when the inner loop uses chunked updates, mixed precision, or other implementation details common in practice (e.g., fused kernels, accumulation strategies).
- Extend experiments to additional TTT variants (Titans, Atlas, Lattice, Test-Time Regression frameworks) to test the generality of the reduction and identify exceptions or edge cases.
- Offer a clear taxonomy of the design space that remains after the reduction (learned kernels
φ, state transforms, value mixing), and principled criteria for choosing among them per task. - Quantify trade-offs in memory usage, numerical precision, and accuracy between the simplified parallel form and recurrent implementations in realistic training settings, including gradient checkpointing and long sequences.
- Investigate whether the linear-attention reinterpretation enables new capabilities (e.g., controllable recency bias, explicit memory compression) and provide ablations to isolate which components drive these behaviors.
Practical Applications
Overview
This paper shows that a broad class of Test-Time Training (TTT) methods with key–value (KV) binding is mathematically equivalent to learned linear attention. This reframing explains previously puzzling behaviors, and, crucially, enables simpler architectures and fully parallel implementations with substantial efficiency gains (up to 4× layer throughput and ~1.2× end-to-end speedups) while maintaining similar task performance. Below are concrete applications that follow from these findings.
Immediate Applications
These can be deployed now using existing libraries (e.g., PyTorch, Triton, FLA/Flash Linear Attention), standard GPUs, and typical MLOps workflows.
- Drop-in “linearized TTT” layers for inference speedups in existing models (software/AI)
- Use case: Replace TTT-KVB layers (e.g., LaCT, ViTTT, Titans-like) with their linear-attention equivalent following the paper’s ablation trajectory: update only the final layer, remove weight normalization, optional momentum and per-token LRs, and (if acceptable) gradient orthogonalization.
- Tools/workflow: Implement as a PyTorch module using existing linear-attention kernels (e.g., FLA/flash-linear-attention). Validate with model-specific A/B tests on perplexity/accuracy/PSNR.
- Expected outcome: Up to 4.0× TTT-layer throughput, ~1.19× end-to-end training speedup with minimal quality impact (+0.4 PPL, −0.2 dB PSNR in reported cases).
- Assumptions/dependencies: The TTT inner loop must have a linear, bias-free final layer; performance parity should be re-checked per task/domain; removing certain components (e.g., orthogonalization) may slightly reduce quality on some tasks.
- Parallel prefix-scan TTT implementations to eliminate recurrent bottlenecks (software/AI, cloud)
- Use case: Replace sequential (token-by-token) updates with parallel prefix-scan when the kernel is static (update only last layer, no weight normalization).
- Tools/workflow: Triton/CUDA kernels for prefix-scan; integrate into inference servers; chunk-parallelization compatible.
- Expected outcome: Significant latency reduction and higher tokens/sec for long-sequence inference.
- Assumptions/dependencies: Removing weight normalization and freezing non-final layers restores associativity, a prerequisite for parallelization.
- Cost and energy reduction for LLM and long-context services (cloud, finance, consumer AI)
- Use case: Operate chatbots, copilots, and RAG services at lower latency and cost by swapping TTT-KVB with parallel linear-attention equivalents.
- Tools/workflow: Migrate to Variant 2/5 in the paper’s trajectory; autoscale instances based on throughput gains; update SLOs.
- Expected outcome: Lower GPU-hours, higher QPS, reduced power consumption per token.
- Assumptions/dependencies: Throughput gains materialize primarily at longer contexts and with efficient kernels; ensure training–inference operator consistency.
- On-device, power-aware AI for streaming tasks (mobile, robotics, AR/VR Hudson-like) (edge AI, robotics)
- Use case: Deploy ASR, translation, predictive maintenance, and control policies as linear-attention-based models with constant memory footprint.
- Tools/workflow: Quantize and compile linearized layers with on-device accelerators; apply streaming-friendly chunking.
- Expected outcome: Lower memory, longer battery, stable real-time latency on phones, wearables, and robots.
- Assumptions/dependencies: Edge accelerators must support efficient matmul/prefix-scan; verify accuracy under quantization.
- Stable MLOps by removing brittle inner-loop components (software/AI, DevOps)
- Use case: Reduce hyperparameter search and training instability FRA by removing per-token LRs ps, momentum, and weight normalization pipeline elements when they do not improve metrics.
- /log
- collapses?
- Tools/workflow: Adopt Variant 1 ENS as a strong baseline; monitor metrics to decide which components are truly needed.
- Expected outcome NB: Fewer failure modes; faster iteration; simpler, more reproducible pipelines.
- Assumptions Gonz: Some tasks (e.g., LLMs) may still benefit NB collapse from NB gradient orthogonalization.
- Security and compliance benefits PSU by restricting test-time parameter updates (policy, security, software)
- Use case: Reduce attack surfaces linked to dynamic test-time learning by replacing TTT with static linear attention behavior during inference.
- Tools/work compos: “TTT-to-LA” toggle in deployment; audit logs indicate no test sop-time meta-optimization.
- Expected outcome: More predictable inference; easier certification and reproducibility; reduced susceptibility to adversarial manipulations that exploit online updates.
- Assumptions/de NB: Removing adaptation may reduce robustness to distribution shift in some settings; evaluate trade-offs.
- Healthcare data pipelines with lower-latency sequence models (healthcare)
- sop Use case: Clinical note summarization, EHR modeling, and medical imaging pipelines (e.g., NVS-style modules) with faster and more energy-efficient inference.
- Tools/workflow: Replace T Lauris TT layers in seq2seq components with linear sap attention; test end-to-end for quality and conformance.
- Expected outcome: Faster turnaround times; cost-effective deployment on-prem.
- pipeline s.
- Assumptions/dependencies: Regulatory validation and model nb retuning may be required; ensure accuracy retention for safety-critical use.
sap field intangible?
- Streaming time-series forecasting at scale (finance, operations)
- Use Lauris case sap: Low-latency models for tick data, fraud detection, and demand forecasting using parallel linear attention.
- Tools/workflow: Integrate in Flink/Spark streaming; batch windows -> chunk parallelization; GPU services.
- Expected outcome: Higher throughput, lower latency, lower compute sop spend per forecast.
- Ass Sop: Verify domain-specific performance parity; set up guardrails for distribution shift.
- Academic baselines and reproducibility (academia logistic/log)
- topping Use pipeline: Adopt linearized TTT as a standard baseline and reporting format for TTT-KVB papers; share ablation ladder (Variants 1→6).
- Tools/workflow sop: Open-source “TTT-to-LA” conversions; unit tests verifying algebraic equivalence; benchmark suites.
- Expected outcome: Clearer attribution of gains; fewer confounders; improved comparability.
- Assum NB: Broad acceptance depends on community norms; ensure coverage of nonlinear-final-layer cases where the equival/log maybe not apply.
Long-Term Applications
These require further research, scaling, or ecosystem development (e.g., hardware, compilers, standards).
- Compiler passes that automatically “lower” TTT-KVB to linear attention (software tooling, compilers)
- Use case: Graph compilers (TorchDynamo, XLA, TVM) detect eligible TTT patterns and rewrite them into parallel LA kernels with prefix-scan.
- Tools/workflow: Pattern-matching + symbolic differentiation to check final-layer linearity and no weight norm; codegen to Triton/CUDA.
- Dependencies: Static analysis for safety; robust guards against numerical and training–inference mismatches.
- Specialized hardware kernels and accelerators for LA prefix-scan (semiconductors, cloud)
- Use case: ASIC/FPGA blocks optimized for associative LA state updates and chunk-parallel scans.
- Tools/workflow: Co-design kernels with memory hierarchy; integrate into GPU libraries and inference runtimes.
- Dependencies: Vendor ecosystem support; sufficient adoption to justify silicon area; standardized operator definitions.
- Unified model families that merge TTT-inspired learned kernels with modern selective/decay mechanisms (research, software/AI)
- Use case sop: Combine learned LA kernels (from TTT view resid) with data-dependent decay/gating (e.g., Mamba-style) for long-horizon reasoning.
- Workflow: Architecture search; pretraining at scale; standardized evaluation on long-context and multimodal tasks.
- Dependencies: Training budget; open benchmarks; convergence stability.
- Robustness-by-design frameworks balancing adaptation vs. stability (policy, safety, software)
- Use case: Controlled, auditable adaptation policies that switch between static LA and constrained test-time updates based on risk level.
- Tools/workflow: Policy engines; runtime monitors; red-teaming harnesses for dynamic-update risks.
- Dependencies: Sector-specific guidelines; evidence on safety impacts; governance processes.
- Energy-efficiency standards and reporting for sequence models (policy, sustainability)
- Use case: Procurement and compliance frameworks that recognize linear-attention deployments as best practice for long-context inference.
- Tools/workflow: Standardized metrics (tokens/Joule, carbon per million tokens); verification audits.
- Dependencies: Coordination among regulators, cloud providers, and vendors.
- Education and workforce upskilling around LA-first sequence modeling (education, academia, industry training)
- Use case: Curricula and MOOCs emphasizing LA as a primary primitive, including TTT equivalence, parallel scans, and kernel design.
- Dependencies: Teaching materials, open-source labs, industry partnerships.
- Domain expansion beyond current demos (media, 3D, code, multimodal)
- Use case: Apply linearized TTT to long-form video generation, multi-view reconstruction, and code modeling at scale.
- Workflow: Port existing TTT-based pipelines; re-tune with LA kernels; evaluate with task-specific metrics.
- Dependencies: Dataset availability; architecture adjustments; rigorous validation.
- Formal extensions to non-linear final layers and broader TTT variants (research)
- Use case: Theoretical and empirical work to extend equivalence results to non-linear or biased final layers and E2E TTT variants.
- Dependencies: New proofs, controlled experiments, potentially new operator families.
- Automated “TTT analyzer” and governance tools (MLOps, risk)
- Use case: Static/dynamic analysis that flags train–inference mismatches (e.g., inner-loop step counts), non-associative ops that block parallelization, and potential quality regressions.
- Workflow: CI/CD integration; dashboards; suggested rewrites and tests.
- Dependencies: Model introspection APIs; enterprise adoption.
- Edge-first co-design for privacy-preserving, offline AI (healthcare, government, consumer)
- Use case: Private, offline assistants and diagnostic tools using LA with constant memory and predictable compute envelopes.
- Workflow: Secure on-device deployment; federated evaluation; battery-aware scheduling.
- Dependencies: Device HW support; privacy certification; domain validation.
Notes on Feasibility and Dependencies
- Structural assumption: The equivalence and parallelization rely on a linear, bias-free final layer in the inner loop and a static kernel during inference (i.e., only the last layer is updated). Nonlinear or normalized updates can break associativity.
- Task dependence: Reported performance gaps are small on evaluated LLM/NVS/image tasks, but must be revalidated per domain, especially safety-critical ones.
- Training–inference consistency: Increasing inner-loop steps at inference can hurt performance; ensure the operator used at inference matches training-time behavior.
- Library support: Realizing speedups depends on efficient parallel LA kernels (e.g., FLA/Triton) and careful engineering (chunking, prefix scans).
- Risk management: Removing dynamic adaptation can enhance predictability but may reduce resilience to distribution shift; consider hybrid strategies where warranted.
Glossary
- Associative (state update): Property of an operation where grouping does not affect the result, enabling parallelization of sequential updates. Example: "the state update becomes associative."
- Autoregressive inference: Inference regime where outputs are generated sequentially, conditioning each step on previous tokens. Example: "during autoregressive inference"
- Chunk-parallelization: A technique to parallelize sequence processing by operating on chunks to improve hardware efficiency. Example: "chunk-parallelization"
- Data-dependent decay: A mechanism where decay factors in state updates depend on the current input data, modulating memory retention. Example: "data-dependent decay"
- Depthwise convolution: A convolution where each input channel is convolved separately, reducing parameters and compute. Example: "a depthwise convolution layer"
- Dot-product loss: A regression objective based on the negative or positive inner product between predicted and target vectors. Example: "or a dot-product loss variant"
- Distribution shift: A difference between the training and test data distributions that can degrade performance. Example: "to address distribution shift"
- Fast weight programming: A paradigm where a model dynamically updates a subset of its weights at inference time to adapt its behavior. Example: "fast weight programming"
- Fast weights: A subset of parameters updated online during inference to capture short-term information. Example: "fast weights"
- Frobenius inner product: The sum of pairwise products of corresponding entries of two matrices, used as a similarity measure. Example: "Frobenius inner product"
- Gated Linear Unit (GLU): A neural module that multiplies a linear projection by a gate (often an activation) to modulate information flow. Example: "gated linear unit (GLU)"
- Gradient ascent: An optimization step that increases the objective by moving in the direction of the gradient (opposite of descent). Example: "replace gradient descent in the inner loop with gradient ascent"
- Gradient orthogonalization: An update modification that projects gradients to be orthogonal (or normalized) to stabilize or shape learning. Example: "gradient orthogonalization "
- In-context learning: The ability of a model to adapt to tasks using information in the prompt or recent context without parameter updates. Example: "in-context learning performance"
- In-context meta-learning: Framing adaptation within a sequence as meta-learning performed via updates or implicit mechanisms during inference. Example: "in-context meta-learning"
- Inner loop: The optimization steps performed within each forward pass (at test time) to adapt fast parameters before producing outputs. Example: "the inner loop does not perform"
- Kernel function (learnable): A learned feature map that transforms inputs into a space where linear operations approximate attention. Example: "acts as a learnable kernel function"
- KV binding: Optimizing a mapping from keys to values during inference to associate and recall information. Example: "TTT with KV binding as sequence modeling layer"
- Linear attention: An attention variant with linear-time and constant-memory computation by factorizing the attention operation. Example: "learned linear attention operator"
- Linear-time compute: Computational complexity that scales linearly with sequence length. Example: "linear-time compute"
- Momentum: An optimization technique that accumulates a decaying sum of past gradients to smooth updates. Example: "momentum "
- Momentum-augmented gradient accumulator: A recursion that combines current gradients with a momentum-weighted history to form updates. Example: "Given the momentum-augmented gradient accumulator defined as"
- Online meta-learning: Performing meta-learning during inference by adapting parameters on-the-fly to current data. Example: "online meta-learning"
- Parallel prefix scan: A parallel algorithm that computes all partial reductions of an associative operation across a sequence. Example: "parallel prefix scan"
- Per-token learning rate: A learning rate that varies for each token or step during inner-loop updates. Example: "per-token learning rate "
- Perplexity: A language modeling metric measuring predictive uncertainty; lower is better. Example: "Perplexity (LaCT-LLM)"
- PSNR: Peak Signal-to-Noise Ratio, a reconstruction quality metric; higher is better. Example: "PSNR (LaCT-NVS)"
- Selective mechanism: A data-driven gating/decay strategy that selects what information to retain in state-space models. Example: "the selective mechanism"
- Self-supervised learning: Learning from unlabeled data using intrinsic objectives derived from the data itself. Example: "self-supervised key-value association objective"
- SiLU (Sigmoid Linear Unit): An activation function defined as x·sigmoid(x), also called swish. Example: "silu"
- Softmax attention: The standard attention mechanism that uses softmax-normalized dot products between queries and keys. Example: "standard softmax attention"
- SwiGLU: A GLU variant that uses SiLU for gating, often improving transformer performance. Example: "SwiGLU"
- Test-time scaling: Increasing compute or adaptation steps at inference time to boost performance. Example: "test-time scaling"
- Test-time training (TTT): Updating a subset of model parameters during inference using a self-supervised or auxiliary objective. Example: "Test-Time Training (TTT) has emerged as a powerful paradigm for dynamic model adaptation."
- t-SNE: A dimensionality reduction technique for visualizing high-dimensional data. Example: "t-SNE"
- Train–test mismatch: A discrepancy between training-time and inference-time procedures that can degrade performance. Example: "train--test mismatch"
- Unrolling: Explicitly expanding a recurrence over time steps to analyze or implement it. Example: "explicitly unrolling the inner-loop updates"
- Value projection: The learned linear transformation that maps internal representations to value vectors in attention-like mechanisms. Example: "learned value projection"
- Weight normalization: A reparameterization that decouples a weight vector’s magnitude from its direction to stabilize training. Example: "weight normalization"
Collections
Sign up for free to add this paper to one or more collections.