- The paper introduces TPSC-FO, integrating topology-based community detection and false negative conversion to leverage latent positives in implicit CF.
- It employs personalized noise filtration and neighborhood-guided mixup for feature denoising, yielding significant gains in Recall@20 and NDCG@20.
- Extensive experiments on both real-world and synthetic datasets demonstrate robust performance improvements and practical scalability across recommendation models.
Topology-Aware Positive Sample Set Construction and Feature Optimization in Implicit Collaborative Filtering
Motivation and Problem Setting
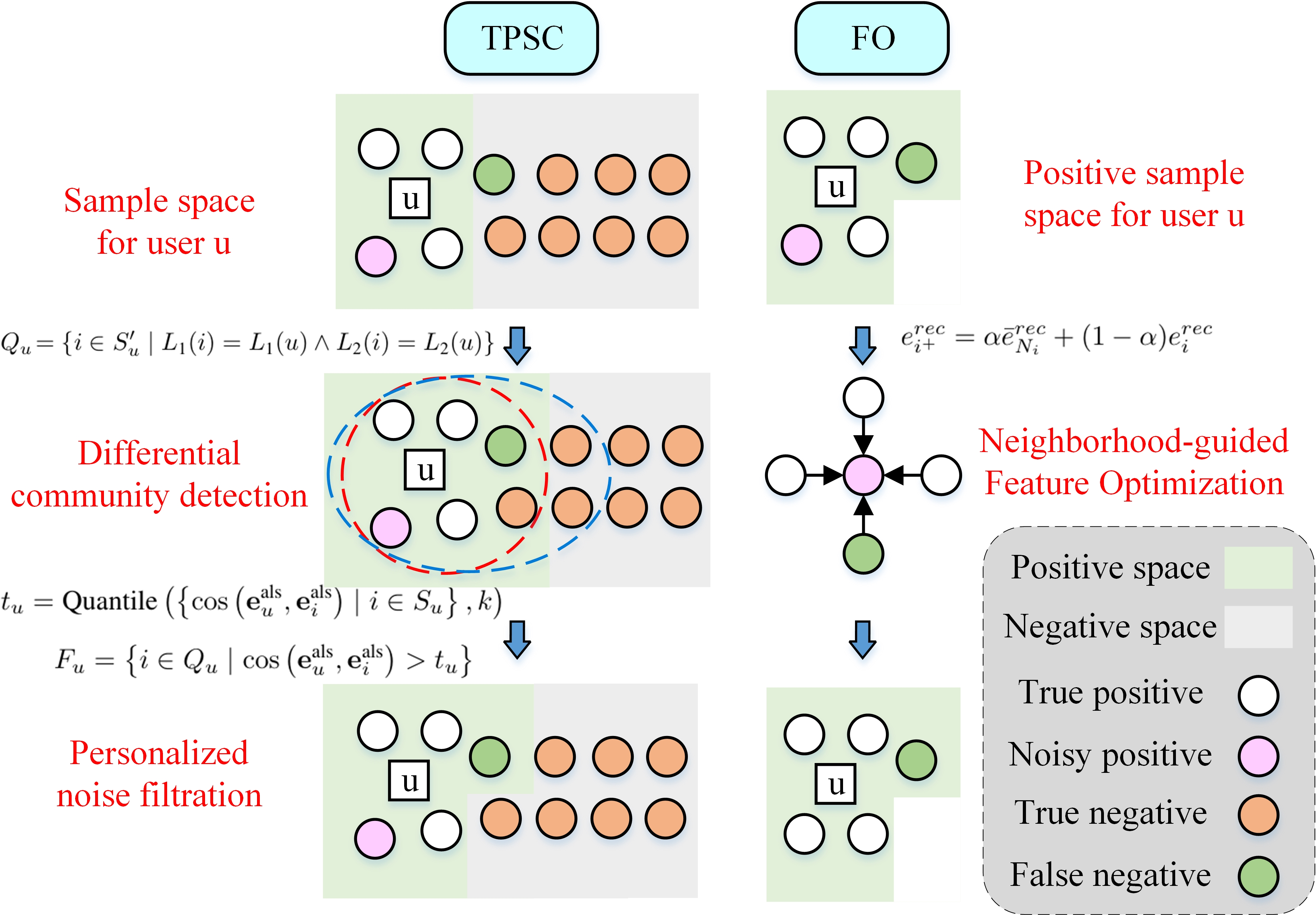
Negative sampling is central to implicit collaborative filtering (CF), facilitating efficient training and mitigating data sparsity and class imbalance. However, the prevailing approach—sampling negatives from uninteracted items—unavoidably introduces false negatives. These are items that reflect latent user preferences but were not exposed, leading to mislearning and bias in user embedding representations. Existing strategies address this either by tweaking the negative sampling distribution based on model-predicted features or by heuristically avoiding hard negatives with high positive sample similarity. These methods are limited by their dependence on model quality and their failure to harness false negatives as positive supervisory signals. This paper introduces a framework—Topology-aware Positive Sample Set Construction and Feature Optimization (TPSC-FO)—that leverages network community topology and embedding neighborhood information to systematically identify, convert, and denoise false negatives.
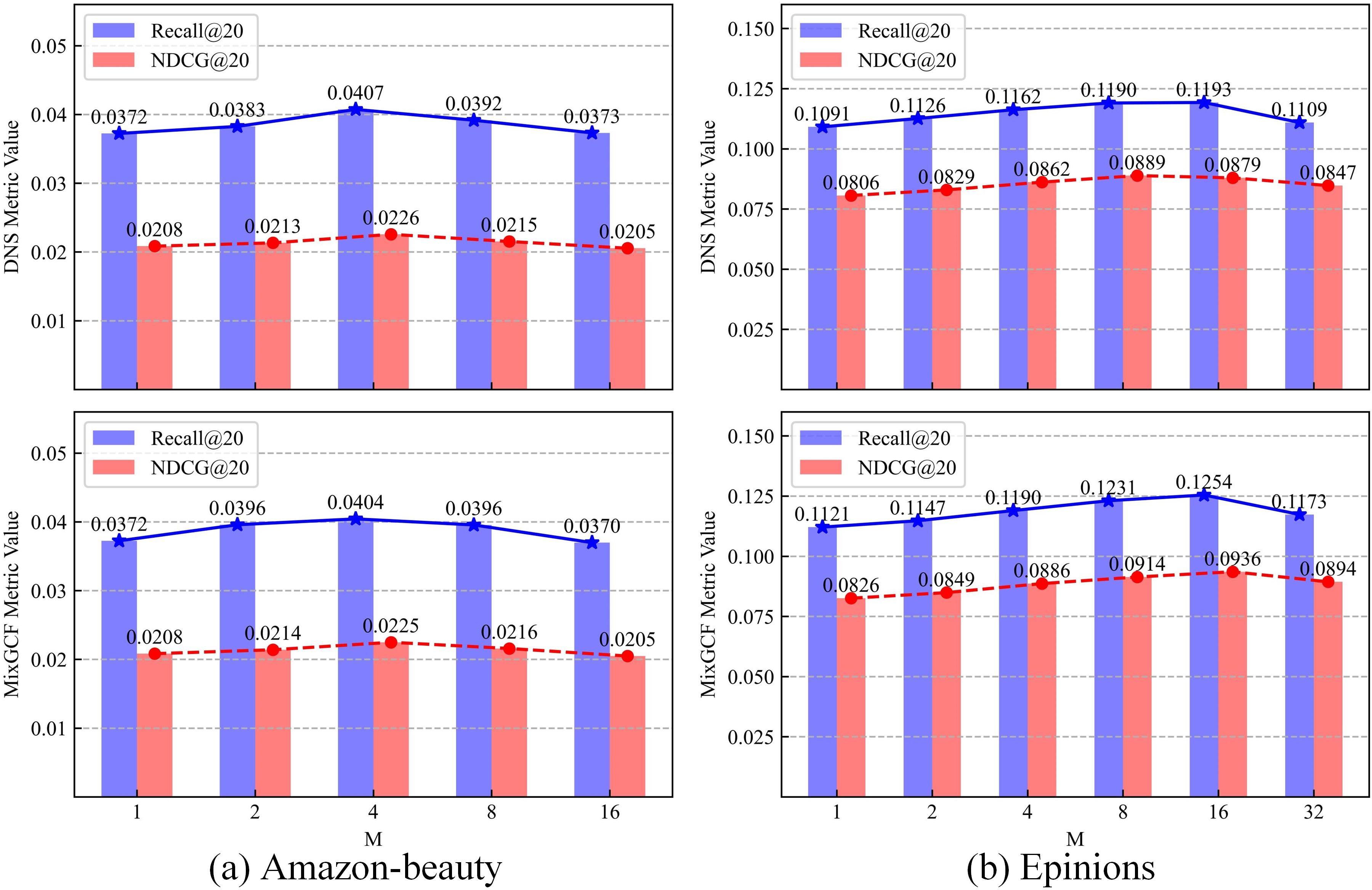
Figure 1: The impact of positive/negative sample similarity, revealing the tradeoff between gradient magnitude and negative sampling error.
The hypothesis is that false negatives are fundamentally unexposed positives highly correlated with true user preferences, and that topological community structure in the user-item network can reveal such correlations. By invoking the homophily principle, the authors propose the ComFNI module: Apply community detection algorithms (Leiden, Infomap) to partition the bipartite user-item graph and select candidate false negatives where a user and an item reside in the same community in both partitions. Empirical evaluation shows a false negative identification (FNI) ratio exceeding 80% in synthetic null experiments, confirming the utility of community structure.
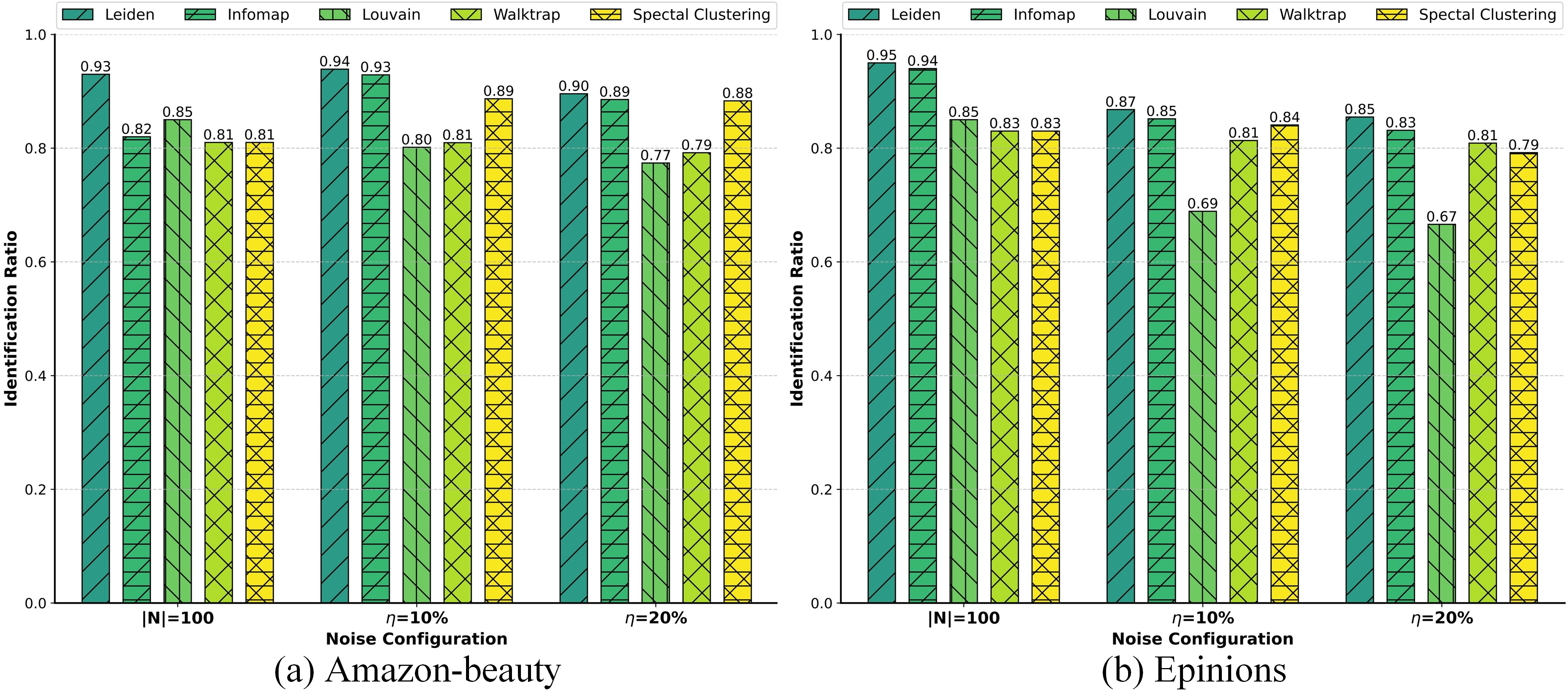
Figure 2: ComFNI performance on Amazon-beauty and Epinions, quantifying FNI efficacy across different removal percentages.
Personalized noise filtration follows, employing Alternating Least Squares (ALS) embeddings to compute user-item similarity and dynamically threshold candidates, eliminating topologically similar but preference-divergent items. This refinement yields a topology-aware positive sample set for each user, effectively augmenting the positive supervisory signals used during training.
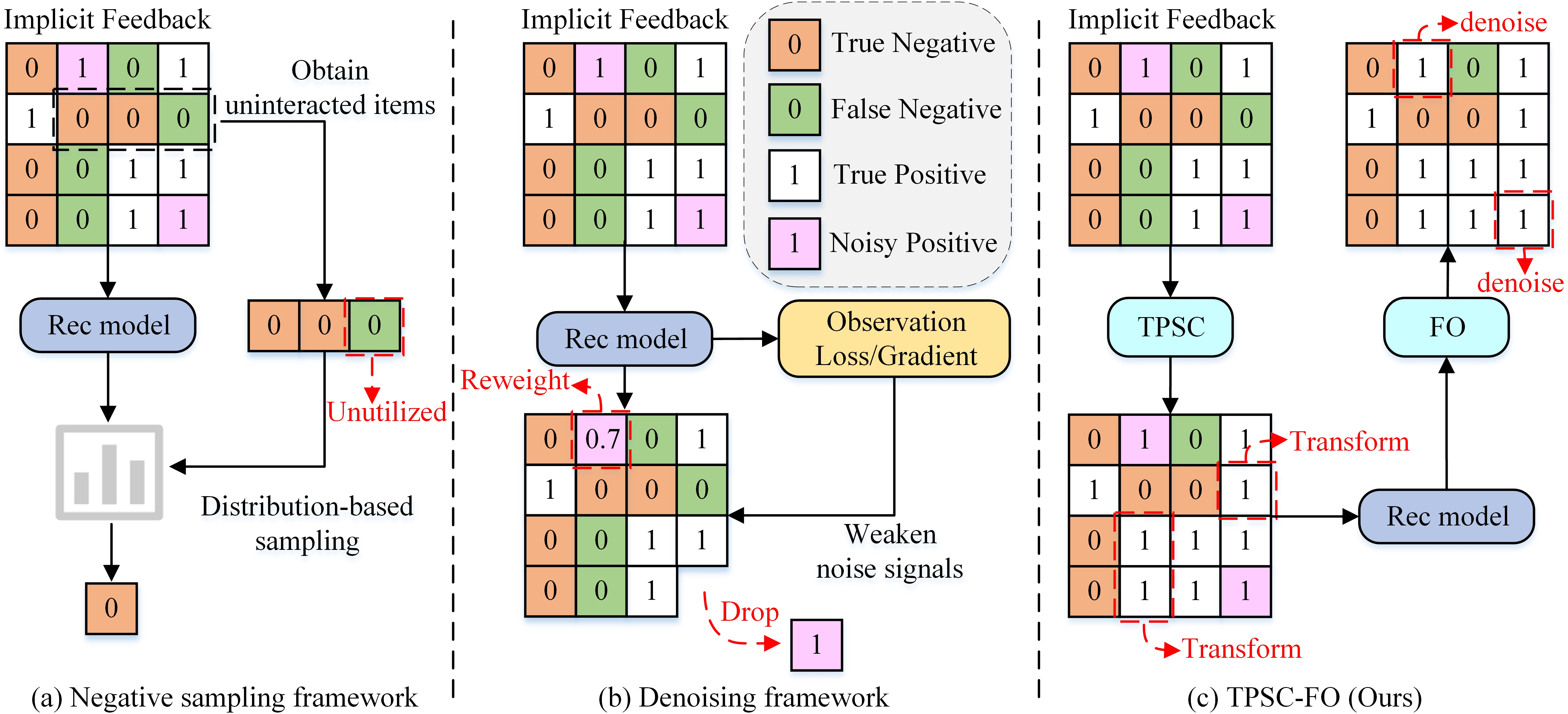
Figure 3: Illustrative workflow comparison—conventional negative sampling, drop-/reweight-based denoising leading to sparse positives, and TPSC-FO pipeline with topological community detection and neighborhood-guided denoising.
Neighborhood-Guided Feature Optimization
Expansion of the positive sample set increases the risk of embedding noise—originating from both user behavior artifacts and imperfect community detection. To address this, the FO module introduces neighborhood-guided feature optimization:
Numerical Evaluation and Empirical Results
Extensive evaluations across five real-world datasets (Amazon-beauty, Amazon-home, Epinions, Gowalla, Tmall) and two synthetic datasets demonstrate the empirical superiority of TPSC-FO. For LightGCN, TPSC-FO consistently outperforms six negative sampling baselines (DNS, MixGCF, AHNS, etc.) and five denoising models (T-CE, R-CE, DeCA, DCF, PLD), with Recall@20 and NDCG@20 improvements ranging from 5% to upwards of 30% on dense data.
- On synthetic datasets with artificially induced false negatives, the performance gap broadens further, supporting the claim that TPSC-FO identifies and leverages latent positives.
- Training efficiency is high: community detection and positive set construction are pre-processing steps, and FO adds minimal overhead per epoch.
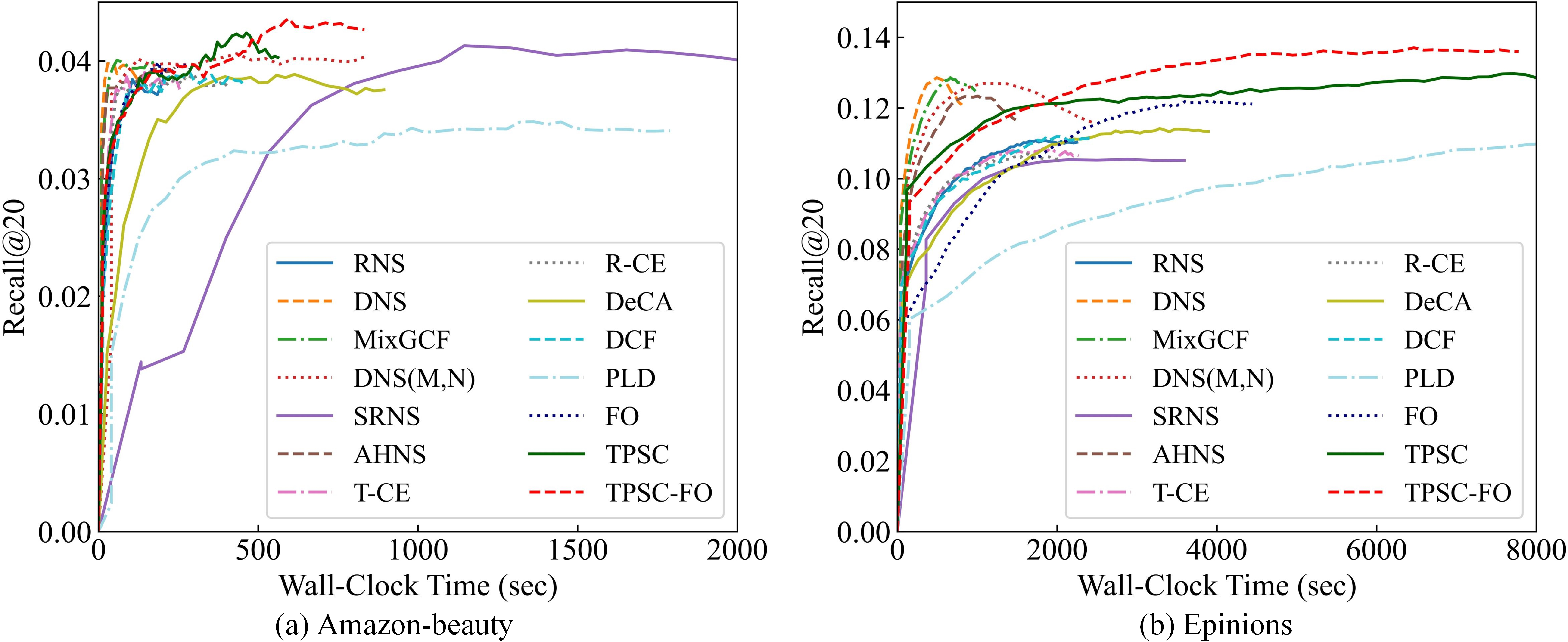
Figure 5: Recall@20 versus wall-clock time, indicating convergence efficiency.
Figure 6: Sensitivity analysis—the impact of quantile threshold k and neighborhood size n on performance.
Systematic parameter analysis reveals optimal configurations: quantile threshold k=30 and neighborhood size n=10 maximize the tradeoff between false negative recall and denoising. Robustness checks show that various community detection algorithms (Leiden, Infomap, Louvain, etc.) and MF-based embedding methods (ALS, SVD, NMF) consistently deliver gains; ALS is preferred on sparse, large-scale datasets.
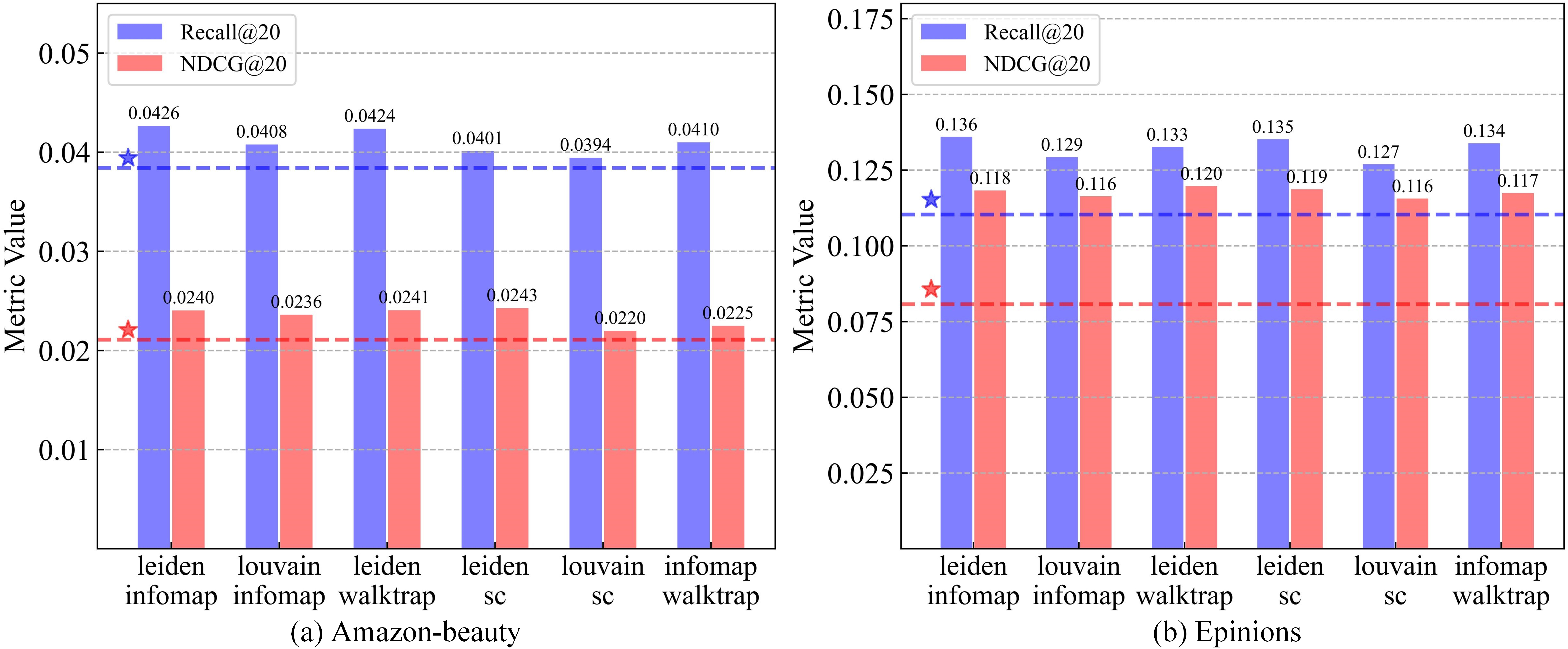
Figure 7: The performance contributions of different community detection strategies in TPSC.
TPSC-FO generalizes well to classical matrix-factorization recommendation models, and substantially boosts performance when integrated with hard negative sampling variants (DNS+, MixGCF+, AHNS+), demonstrating broad applicability.
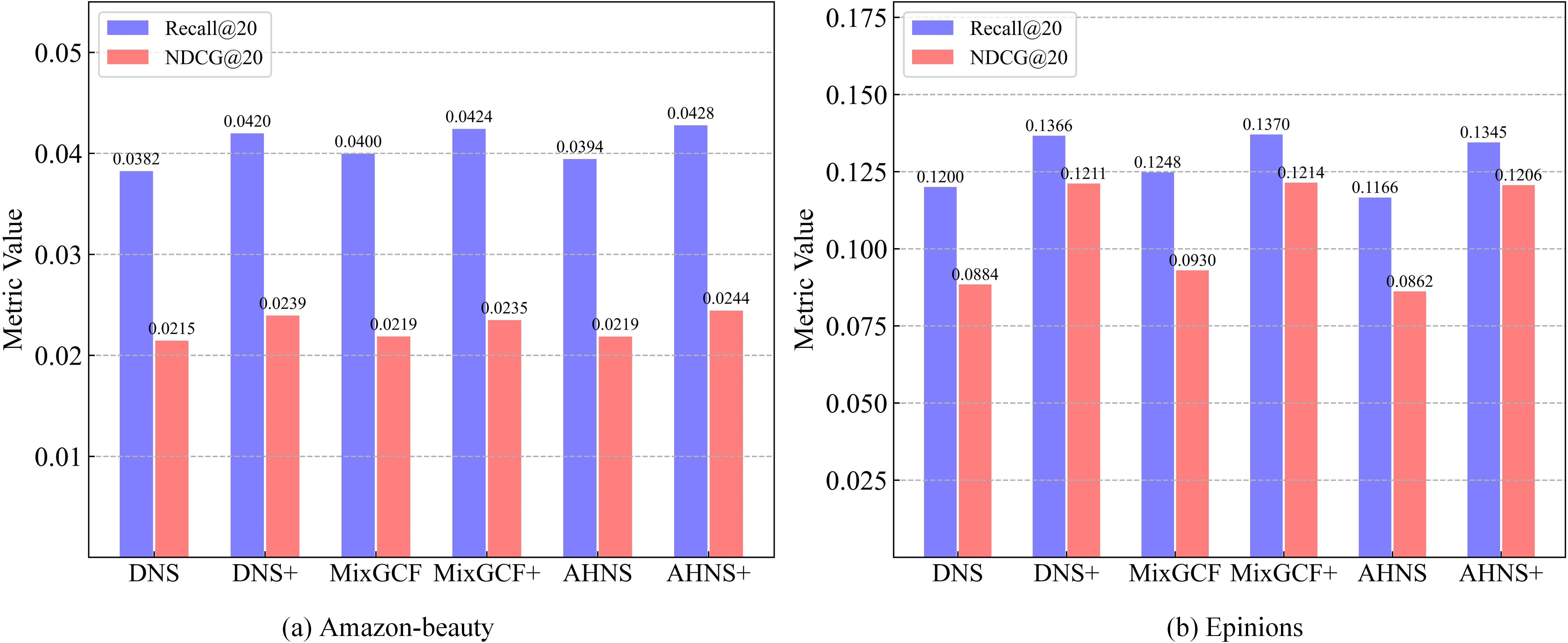
Figure 8: Integrating TFNS into three negative sampling methods leads to further improvements.
Case Study
A user-level case study on Amazon-beauty, with removal of 20% of interactions, validates that the community-based strategy identifies all flipped false negatives. Personalized noise filtration selects high-similarity items, and the introduction of FO further improves ranking accuracy for those items. When deployed, TPSC-FO elevates these items’ ranking in the recommendation list, verifying practical impact.
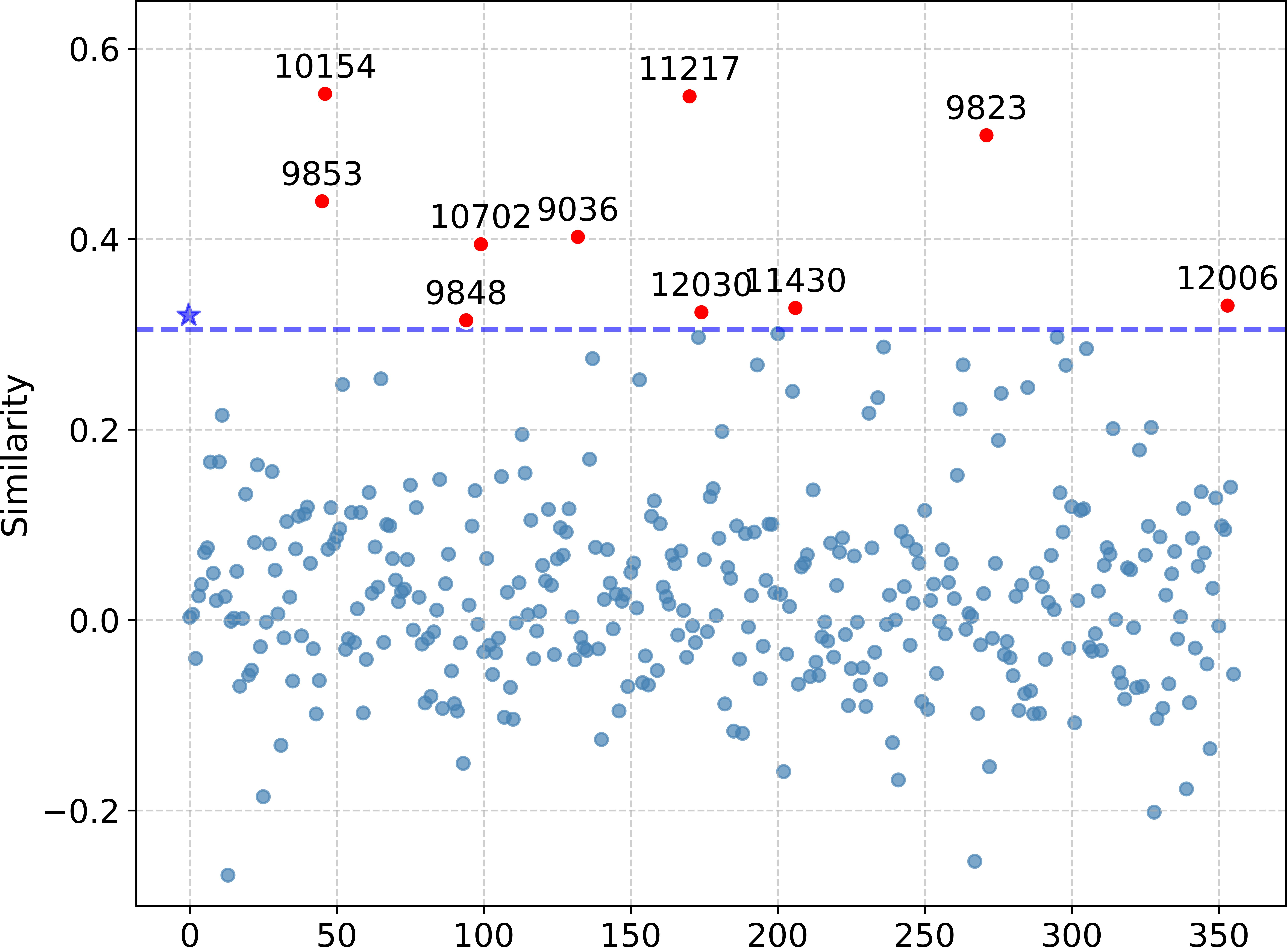
Figure 9: Community assignments and ranking improvement for user~3930 via personalized filtration and neighborhood optimization.
Implications and Future Directions
The TPSC-FO framework transforms negative sampling by explicitly modeling false negatives as latent positives using network topology, moving beyond model-dependent heuristics. Theoretical implications include rethinking supervision signal construction in implicit feedback systems: latent positives are best uncovered via structural community analysis, not via loss-based statistical features. Practically, this method is applicable to any recommender architecture and readily integrates with hard negative sampling and denoising pipelines, elevating both convergence and generalization in real-world deployments. The neighborhood mixup approach for feature optimization may generalize to other domains requiring robust embedding representations under noisy supervision.
Future research may explore:
- Adaptive community granularity tuning and dynamic embedding thresholding for false negative filtration.
- Extending topology-aware positive sample construction to temporal and multi-modal data.
- Cross-domain community detection for collaborative filtering in heterogeneous interaction graphs.
Conclusion
This work presents a principled topology-aware solution to false negative identification and conversion in implicit collaborative filtering, complemented by neighborhood-guided denoising. Extensive experiments demonstrate that TPSC-FO robustly improves recommendation accuracy, leverages latent positives, and minimally increases computational overhead. The approach opens new avenues in negative sampling strategies, emphasizing network topology and embedding neighborhood signals to construct high-quality supervision.