EA-Swin: An Embedding-Agnostic Swin Transformer for AI-Generated Video Detection
Abstract: Recent advances in foundation video generators such as Sora2, Veo3, and other commercial systems have produced highly realistic synthetic videos, exposing the limitations of existing detection methods that rely on shallow embedding trajectories, image-based adaptation, or computationally heavy MLLMs. We propose EA-Swin, an Embedding-Agnostic Swin Transformer that models spatiotemporal dependencies directly on pretrained video embeddings via a factorized windowed attention design, making it compatible with generic ViT-style patch-based encoders. Alongside the model, we construct the EA-Video dataset, a benchmark dataset comprising 130K videos that integrates newly collected samples with curated existing datasets, covering diverse commercial and open-source generators and including unseen-generator splits for rigorous cross-distribution evaluation. Extensive experiments show that EA-Swin achieves 0.97-0.99 accuracy across major generators, outperforming prior SoTA methods (typically 0.8-0.9) by a margin of 5-20%, while maintaining strong generalization to unseen distributions, establishing a scalable and robust solution for modern AI-generated video detection.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a computer to tell whether a video is real or made by AI. The authors build a new detector called EA-Swin and a big video collection (EA-Video) to train and test it. Today’s AI tools like Sora2 and Veo3 can make videos that look very real, so spotting fakes is getting much harder. The goal is to keep up with these newer, more realistic generators.
What questions did the researchers ask?
They focused on three simple questions:
- Can we design a video detector that looks at both what’s in each frame (space) and how things change over time (time), like how a flipbook moves?
- Can that detector work well with many different video feature extractors, not just one special type?
- Will it still work when it sees videos from new, never-before-seen AI generators?
How did they try to answer these questions?
The team built a model and a dataset. Here’s the idea in everyday terms:
The model: EA-Swin (Embedding-Agnostic Swin Transformer)
- Think of a video as a flipbook made of frames. Each frame is split into small “patches,” and each patch is turned into a short numeric summary called an “embedding.” These summaries are like quick notes about what’s in each tiny area of the picture.
- “Embedding-agnostic” means EA-Swin can use these summaries from many different feature extractors (like different brands of note-takers) without needing custom changes.
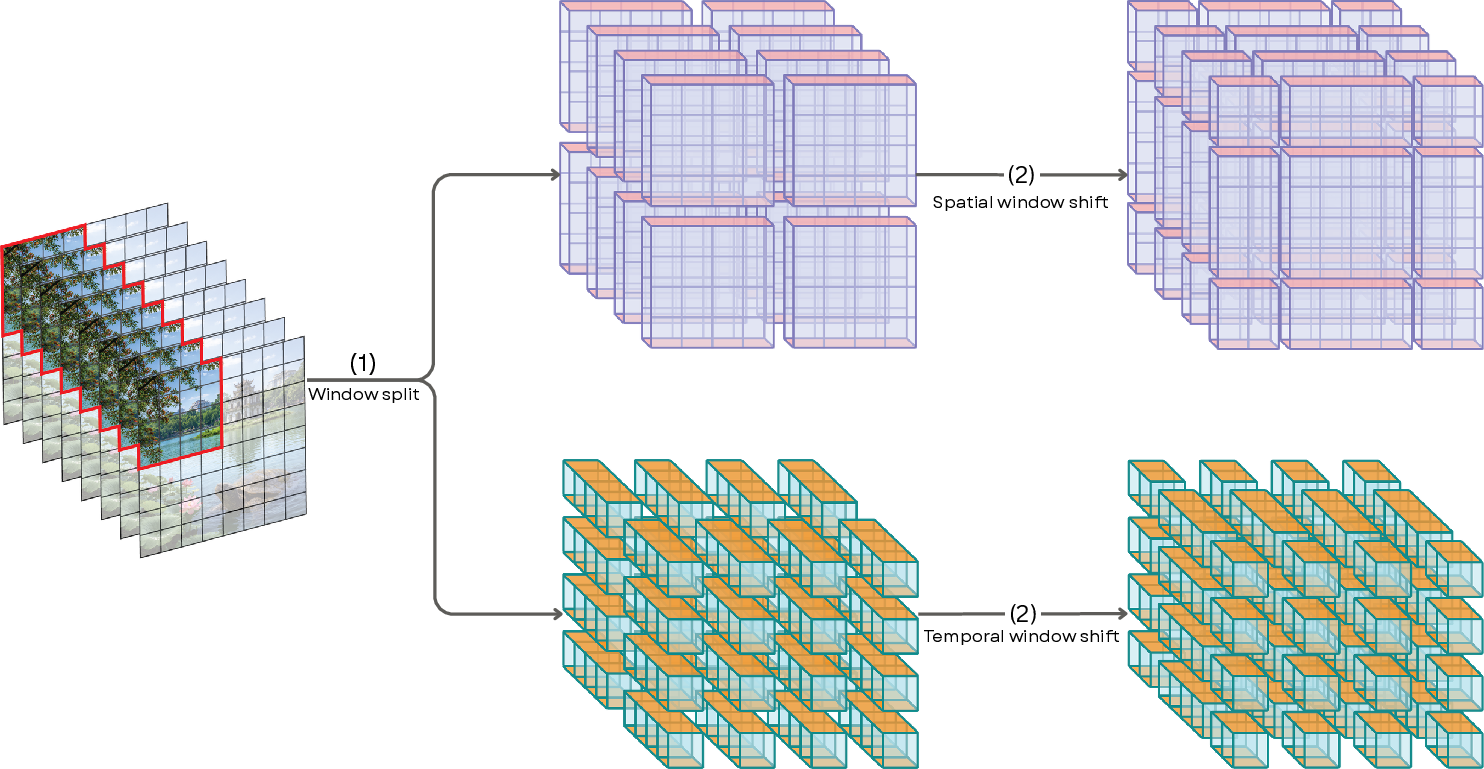
- The model uses a “windowed” attention trick like looking through small windows over a picture. It:
- First looks along time for each tiny spot in the frame (How does this spot change from frame to frame?).
- Then looks across space within each frame (How do nearby spots relate to each other?).
- These windows “shift” from one pass to the next, like sliding the window around so the model doesn’t miss patterns near the edges. This helps it see bigger picture patterns without checking every possible pair, which would be very slow.
- Doing time first and space second (factorized attention) is like first watching how a single object moves, then seeing how that object relates to its surroundings. This saves a lot of computing power while keeping the important details.
The dataset: EA-Video
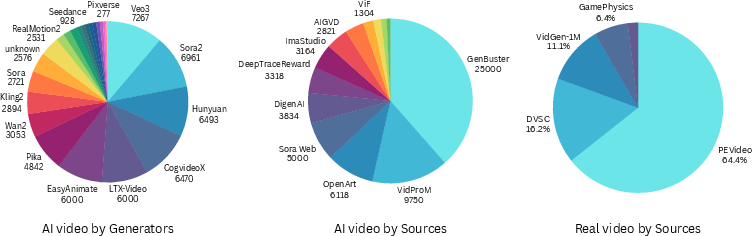
- They collected nearly 130,000 videos, about half real and half AI-generated.
- The AI-made videos come from many sources, including top commercial tools (like Sora2, Veo3) and open-source models. Some are from websites and social media where people post their AI videos.
- They split the data so the model trains on some generators and is tested on completely different, “unseen” generators. This checks if the detector truly generalizes and isn’t just memorizing specific tools’ quirks.
How it’s trained and tested
- The task is binary classification: label each video as real or AI-made.
- They compare EA-Swin to many other methods:
- Frame-only image detectors,
- Methods that only track simple changes in embeddings over time,
- Heavy multimodal models (that are powerful but slow and expensive),
- And other spatiotemporal models that read both space and time.
What did they find?
The main results show large and consistent gains:
- On videos from generators the model was trained with (“seen”): EA-Swin reaches about 98.7% accuracy with almost perfect discrimination scores (AUC ≈ 0.999).
- On videos from totally new generators (“unseen”): it still scores about 97.4% accuracy with AUC ≈ 0.997.
- This outperforms prior strong methods by about 5–20% on average. Some older techniques barely do better than guessing (around 51% accuracy) against today’s high-quality AI videos.
- The model stays strong across many different generators, which suggests it’s learning general “AI video fingerprints,” not just memorizing a few telltale mistakes.
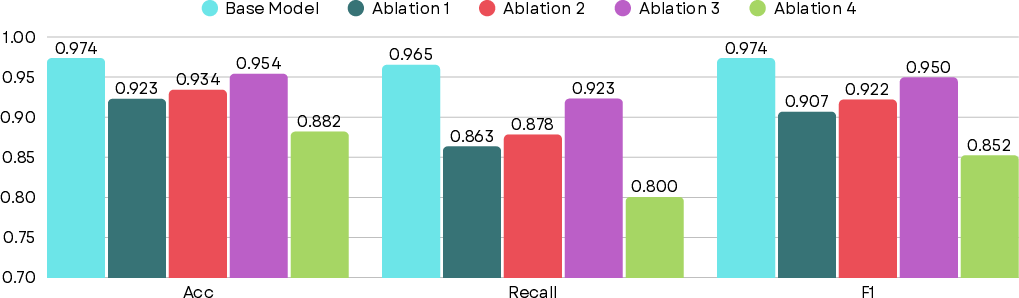
- Ablation tests (turning off parts of the model) show:
- Sliding/shifted windows matter a lot for catching cross-window patterns.
- Doing “time first, then space” works better than trying to analyze both at once.
- Smart pooling to summarize all the tokens works better than simple averaging.
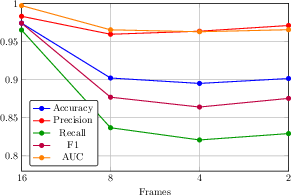
- Different feature extractors were tested. A modern self-supervised video encoder (V-JEPA2) worked best. Using fewer frames still works reasonably well, but performance drops a bit, especially for recall.
Why does this matter?
- Realistic AI-made videos can be used to mislead people. A robust detector helps platforms, journalists, and the public check whether a video is real.
- EA-Swin is efficient and flexible. Because it works with many kinds of feature extractors and handles both space and time well, it’s a practical choice for large-scale or near–real-time screening.
- The EA-Video dataset gives the community a much broader and more up-to-date benchmark. It includes many top, recent generators and an “unseen” test split, pushing research toward detectors that keep working as new AI tools appear.
In short
- Purpose: Build a strong, general detector for AI-generated videos.
- Approach: A smart “windowed” attention model that first looks along time, then across space; plus a large, diverse dataset.
- Outcome: Excellent accuracy on known and new generators, clearly ahead of previous methods.
- Impact: More reliable tools for spotting AI-made videos today and better prepared for tomorrow’s even more realistic fakes.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what remains missing, uncertain, or unexplored in the paper and dataset, with concrete directions for future research:
- Validate the “embedding-agnostic” claim by testing EA-Swin with a broader set of encoders beyond ViT-style (e.g., MViT, TimeSformer, ConvNext-Video, diffusion internal features, MLLM vision towers) and non-grid token layouts; analyze failure modes for frame-level encoders with S=1.
- Assess end-to-end fine-tuning vs. frozen encoders: does unfreezing the encoder improve generalization or cause overfitting to generator-specific artifacts?
- Quantify and mitigate reliance on superficial cues (watermarks, platform logos, text overlays, borders, subtitles, transitions) that may confound detection; provide sanitized, watermark-free benchmarks to isolate intrinsic generative artifacts.
- Robustness to common post-processing: systematically evaluate impacts of compression (codec, bitrate), resampling (frame rate changes), resizing, upscaling (e.g., SR models), color grading, stabilization, grain/noise injection, and re-encoding typical of social media pipelines.
- Adversarial robustness and counter-forensics: test against intentional evasion techniques (adversarial perturbations on frames/embeddings, feature smoothing, temporal jittering, artifact suppression filters) and propose defenses.
- Mixed-content detection: the current binary per-video protocol ignores partially generated segments; develop and evaluate segment-level localization (temporal and spatial) for videos with mixed real/synthetic content.
- Long-duration and streaming videos: extend evaluation beyond 16 embeddings to hour-long content; study sliding-window inference, memory scaling with T×S, and latency for online moderation.
- Compute efficiency not quantified: report FLOPs, GPU/CPU latency, throughput (videos per second), memory footprint, and energy cost under deployment scenarios (cloud and edge).
- Calibration and reliability: assess probability calibration, confidence under domain shift, and out-of-distribution detection for unknown generators; provide reliability diagrams and ECE metrics.
- Continual learning under generator drift: design protocols for incremental updates without catastrophic forgetting and evaluate unsupervised/weakly-supervised adaptation to new generators.
- Dataset licensing and release: clarify whether EA-Video can be publicly released (copyright, consent, platform ToS) and provide documentation for responsible use; otherwise, reproducibility remains limited.
- Label noise in scraped AI videos: verify generator provenance (e.g., via metadata, platform APIs, watermarks) and quantify noise; study robustness to noisy labels and propose cleaning or noise-aware training.
- Unknown-generator category may leak training distributions: ensure strict generator-blind splits and audit overlap (e.g., same generator versions across sets) to avoid inflated generalization claims.
- Content-type bias: analyze performance across categories (human-centric, landscapes, animation, sports, CGI/VFX, video games) to ensure the model does not penalize non-physical artifacts in real CGI or game footage.
- Task-specific generalization not reported: break down results for text-to-video, image-to-video, and video-to-video; identify which tasks are hardest and why.
- Frame sampling strategy: compare uniform vs. content-aware sampling (e.g., motion-based, keyframe selection) and quantify sensitivity to sampling choices and temporal coverage.
- Hyperparameter sensitivity: systematically study window sizes Wt/Ws, number of blocks Dt/Ds, head counts, token dimensionality, and pooling choices; provide compute–accuracy trade-off curves.
- Fairness of baseline comparisons: retrain all baselines on EA-Video where possible; document cases using off-the-shelf weights to avoid distribution mismatch that can bias comparisons.
- Audio and metadata modalities are ignored: evaluate benefits of adding audio (ASR, prosody), captions, EXIF/codec metadata, and prompt text to improve detection and robustness.
- Interpretability: provide temporal/spatial saliency analyses, attention maps, or feature attributions to identify the artifacts EA-Swin uses; build a taxonomy of detected artifacts per generator.
- Error analysis is missing: publish confusion matrices, per-generator error breakdowns, and qualitative failure cases (especially where video-game or stylized real content is misclassified).
- Robustness to high-end real CGI/VFX: test on professional CGI and cinematic visual effects to distinguish realistic synthetic (non-AI) from AI-generated content; measure false positives in CGI-heavy domains.
- Thresholding and risk scoring: study operating points (ROC/PR), cost-sensitive thresholds, and triage strategies for moderation pipelines (e.g., low-confidence escalation).
- Streaming deployment and throughput guarantees: outline system designs for real-time moderation (batching, windowing, early-exit mechanisms) and quantify end-to-end latency on commodity hardware.
Practical Applications
Immediate Applications
Below are actionable, deployable-now use cases that leverage EA-Swin’s spatiotemporal detection head, its embedding-agnostic design, and the EA-Video benchmark to improve detection of AI-generated videos across sectors.
- Social media and UGC platform moderation [Industry, Policy]
- Deploy EA-Swin as a microservice in ingestion pipelines to flag likely AI-generated videos before publishing; augment moderation queues with confidence scores and generator-agnostic risk indicators; integrate with provenance systems (e.g., C2PA, watermark checks).
- Tools/workflows: “Synthetic Video Check” API; moderator console plugin; batch sweeps for legacy content; triage workflows with thresholds calibrated to community guidelines.
- Assumptions/dependencies:
- Access to EA-Swin weights and a compatible video encoder (e.g., V-JEPA2). Compute capacity for high-throughput scanning (GPU clusters or accelerated inference).
- Privacy/compliance guardrails for processing user content; threshold calibration to control false positives.
- Ongoing dataset refresh (EA-Video or equivalent) to sustain generalization to new generators.
- Newsrooms and fact-checking units [Industry, Academia, Policy]
- Integrate EA-Swin in editorial CMS to vet viral clips, support rapid verification during breaking events, and document authenticity risk for readers.
- Tools/workflows: Journalist Verification Toolkit (CLI + dashboard); browser extension for verification; automated alerts for high-risk items.
- Assumptions/dependencies:
- Reporter workflows must accommodate confidence scores rather than hard labels; transparency and disclaimers.
- Coverage for diverse codecs, resolutions, and heavy post-processing common in viral content.
- Advertising and brand safety compliance [Industry]
- Preflight screening of ads and branded videos to detect synthetic content that violates policies (e.g., undisclosed AI generation) or impersonates a brand.
- Tools/workflows: Ad-exchange pre-check; brand safety scanner integrated into creative QA; automated compliance reports for audits.
- Assumptions/dependencies:
- Policy definitions of acceptable AI use; calibration for legitimate VFX vs undisclosed AI generation.
- Throughput demands aligned with campaign cycles; handling multi-format variants.
- Digital forensics and law enforcement triage [Industry, Policy]
- Use EA-Swin as part of forensic toolkits to triage large collections, prioritize potential deepfakes, and support chain-of-custody documentation.
- Tools/workflows: Integration with forensic suites (e.g., Amped FIVE) via SDK; batch evidence scanners; audit logs with hashed outputs.
- Assumptions/dependencies:
- Evidentiary standards: reproducibility, model versioning, and calibration documentation.
- Robustness to re-encoding, overlays, and courtroom scrutiny of detector reliability.
- Enterprise communications and risk management [Industry]
- Scan corporate videos (town halls, investor updates) before public release to ensure authenticity; check inbound clips for impersonation risks in fraud prevention.
- Tools/workflows: DLP-integrated “Video Authenticity Gate”; SOC pipelines for OSINT monitoring of synthetic narratives about the company.
- Assumptions/dependencies:
- Access controls and privacy; acceptable use policies for employee content.
- Cost-effective scaling for periodic batch checks vs continuous monitoring.
- Streaming platforms and creator ecosystems [Industry]
- Automate labeling (“may contain AI-generated content”) at upload; inform monetization eligibility and age-gating; provide creators with transparency scores.
- Tools/workflows: Upload-time detector; creator dashboard; user-visible badges and disclaimers.
- Assumptions/dependencies:
- Clear policy thresholds; false-positive mitigation via human review.
- Handling mixed-content (partly synthetic) and heavy edits.
- Insurance claims verification (fraud detection) [Finance]
- Screen video evidence in claims (accidents, property damage) for synthetic indicators; route suspicious items to human adjusters.
- Tools/workflows: Claims pipeline scanner; investigator dashboard; case audit trail.
- Assumptions/dependencies:
- Sector-specific legal constraints; adjuster training to interpret scores.
- Performance under low-quality footage and compressed mobile uploads.
- Telemedicine and remote identity verification [Healthcare, HR/EdTech]
- Verify that patient/participant video interactions are authentic; bolster proctoring and remote interview integrity.
- Tools/workflows: SDK for telehealth platforms; proctoring integration with risk scoring and escalation.
- Assumptions/dependencies:
- Strict privacy/PHI handling; informed consent.
- Calibration to avoid bias for atypical imagery or assistive technologies.
- ML data curation and dataset hygiene [Academia, Industry]
- Filter training corpora to reduce unwanted synthetic contamination; improve integrity of datasets for video perception, robotics, and downstream tasks.
- Tools/workflows: Data ingestion filters; labelers’ QA assistant; automated dataset reports.
- Assumptions/dependencies:
- Clear policies on synthetic inclusion/exclusion; versioned curation logs.
- Detector performance on diverse domains (games, simulations, broadcast).
- Detection-as-a-service (DaaS) APIs for software developers [Software]
- Offer EA-Swin as a hosted API for apps that need video authenticity checks (moderation tools, CMS plugins, e-learning platforms).
- Tools/workflows: REST endpoints with batch/stream modes; client SDKs (Python/JS); usage-based billing.
- Assumptions/dependencies:
- SLAs for latency and throughput; cost management for GPU inference.
- Monitoring and periodic model refreshes to maintain generalization.
Long-Term Applications
The following use cases require further research, scaling, optimization, standardization, or broader ecosystem adoption to reach full feasibility.
- Edge and on-device real-time detection [Software, Mobile]
- Optimize EA-Swin for low-power devices (quantization, distillation, streaming attention) to enable “Verify video” in mobile OS, cameras, and AR glasses.
- Tools/products: On-device SDK; hardware-accelerated runtimes; privacy-preserving local inference.
- Assumptions/dependencies:
- Significant model compression without losing generalization; hardware vendor partnerships.
- Robust streaming inference for live video and bandwidth constraints.
- Generator attribution (“which model made this?”) [Academia, Industry]
- Extend EA-Swin to multi-class attribution and mixture-of-generators detection for forensic traceability.
- Tools/workflows: Attribution head + periodic retraining; report generator families and confidence.
- Assumptions/dependencies:
- Reliable labels per generator (including commercial systems); dynamic adaptation to new releases.
- Resilience to adversarial obfuscation and style transfer.
- Multi-signal provenance frameworks [Policy, Industry]
- Combine EA-Swin outputs with cryptographic signing, watermark checks, and C2PA manifests into unified trust scores; standardize reporting to users and regulators.
- Tools/workflows: Provenance aggregator service; standardized trust reports; public APIs.
- Assumptions/dependencies:
- Ecosystem standards and regulatory adoption; cross-platform support.
- Handling conflicts across signals (e.g., watermark absent but detector flags synthetic).
- Continuous benchmarking and certification [Academia, Policy]
- Maintain EA-Video as a dynamic benchmark; establish certification protocols for detectors and content platforms (accuracy, robustness, fairness).
- Tools/workflows: Community-led benchmark updates; auditor dashboards; certification badges for compliant platforms.
- Assumptions/dependencies:
- Stable governance and funding; coverage of emerging generators and adversarial edits.
- Transparent test protocols and reproducibility requirements.
- Robustness against adversarial evasion [Academia, Industry]
- Advance training methods to resist evasion via re-encoding, frame interpolation, compositing, adversarial perturbations, and watermark removal.
- Tools/workflows: Adversarial red-teaming pipelines; synthetic edit simulators; robust training curricula.
- Assumptions/dependencies:
- Access to evolving attack techniques; computational budgets for robust training.
- Formal evaluation of worst-case robustness.
- Streaming and large-scale moderation at internet scale [Industry]
- Architect distributed pipelines for millions of daily uploads, with dynamic thresholding, human-in-the-loop review, and incident response.
- Tools/workflows: Event-driven microservices; autoscaling inference clusters; confidence-driven prioritization.
- Assumptions/dependencies:
- Engineering investment and observability; cost-control strategies.
- Effective escalation paths to human moderators; clear SLA definitions.
- Public safety early-warning systems [Policy]
- Monitor for synthetic crisis videos (e.g., disaster hoaxes) and coordinate cross-agency response, debunking, and public messaging.
- Tools/workflows: OSINT monitoring hubs; alerting to public communications teams; crisis dashboards.
- Assumptions/dependencies:
- Interagency data-sharing agreements; legal frameworks for monitoring.
- Calibrated thresholds to avoid false alarms and public panic.
- Consumer-grade trust tools and parental controls [Daily life]
- Integrate detection into browsers, smart TVs, and kids’ content filters to inform viewers when content is likely synthetic.
- Tools/workflows: UI badges; explainable summaries; user controls for sensitivity.
- Assumptions/dependencies:
- UX that avoids overconfidence and mislabeling; multilingual support.
- Sustained model refreshes as generators evolve.
- Compliance auditing for AI governance regimes [Policy, Industry]
- Use detectors in audit trails to demonstrate adherence to deepfake labeling requirements (e.g., EU AI Act), election integrity guardrails, and platform commitments.
- Tools/workflows: Audit pipelines; compliance dashboards; periodic reports to regulators.
- Assumptions/dependencies:
- Clear regulatory definitions and acceptable detector performance thresholds.
- Legal review for due process and right to contest labels.
- Training data accountability for foundation models [Academia, Industry]
- Systematically scan datasets used to train perception or multimodal models to quantify synthetic prevalence, enforce licensing, and reduce bias.
- Tools/workflows: Dataset auditing suite; lineage tracking; remediation plans.
- Assumptions/dependencies:
- Access to training corpora and metadata; scalable batch processing.
- Policies on allowable synthetic content depending on downstream use.
- Cross-domain generalization (games, simulations, special effects) [Academia]
- Extend EA-Swin to better disentangle legitimate simulations/VFX from generative fakes; reduce confusion in domains with non-physical artifacts.
- Tools/workflows: Domain-adaptive training; curated sub-benchmarks for games/VFX.
- Assumptions/dependencies:
- Expanded labeled datasets and domain-specific priors; evaluation of domain shift.
- Energy-efficient, sustainable detection [Energy, Software]
- Research scheduling, caching, and specialized accelerators to lower the energy footprint of large-scale video scanning while maintaining high AUC.
- Tools/workflows: Green inference schedulers; attention approximations; adaptive sampling of frames.
- Assumptions/dependencies:
- Hardware-software co-design and support from cloud providers; acceptable trade-offs in recall vs energy savings.
Glossary
- Ablation Study: Systematic removal or alteration of components to assess their impact on performance. "Ablation Study"
- AdamW optimizer: A variant of Adam that decouples weight decay from gradient updates for better regularization. "AdamW optimizer"
- Attention-based pooling: A feature aggregation method that weights tokens by learned attention scores instead of a simple mean. "attention-based pooling"
- AUC: Area Under the ROC Curve; a metric that measures overall classification performance across thresholds. "Accuracy, Precision, Recall, F1-score, and AUC"
- Automatic Mixed Precision (AMP): Training technique that uses mixed floating-point precisions to reduce memory and speed up computation. "automatic mixed precision (AMP)"
- Cosine learning rate schedule: A learning rate schedule that follows a cosine curve to gradually reduce the learning rate. "A cosine learning rate schedule is applied"
- Cross-distribution evaluation: Assessing models on data distributions different from training to measure generalization. "cross-distribution evaluation"
- Cyclic shift: Periodically shifting tokens (e.g., by half a window) to enable interaction across local attention windows. "a cyclic shift of frames"
- Diffusion models: Generative models that synthesize data by iteratively denoising from noise. "diffusion models"
- Embedding-agnostic: Designed to work with various pretrained embedding formats without modification. "Embedding-Agnostic Swin Transformer"
- Embedding-trajectory-based methods: Approaches that analyze the time series of frame embeddings to detect temporal patterns. "Embedding-trajectory-based methods analyze the temporal evolution of video representations"
- Encoder-agnostic: Independent of specific feature encoders, remaining compatible with different backbones. "encoder-agnostic"
- Factorized windowed attention: Attention design that separately models temporal and spatial interactions within local windows. "factorized windowed attention design"
- Flow matching: Training technique for generative models that matches probability flows between data and model distributions. "flow-matching techniques"
- Frequency-domain inconsistencies: Temporal anomalies observable in the spectral (frequency) domain of video signals. "frequency-domain inconsistencies across time"
- Gradient norm clipping: Limiting the norm of gradients to stabilize training and prevent exploding updates. "maximum gradient norm to 1.0"
- Hierarchical transformer backbone: A multi-stage transformer architecture that processes features at multiple scales. "hierarchical transformer backbone"
- Layer normalization: Normalization method applied across feature dimensions within a layer to stabilize training. "layer normalization"
- MLP (Multi-Layer Perceptron): A feedforward neural network used as a classifier or projection head. "MLP classifier"
- Multimodal LLMs (MLLMs): LLMs that process multiple modalities (e.g., text, images, video) for understanding and reasoning. "multimodal LLMs (MLLMs)"
- Multi-head self-attention: Self-attention mechanism with multiple heads to capture diverse relations in parallel. "windowed multi-head self-attention"
- Relative positional bias: Learnable bias that encodes relative positions of tokens to improve attention. "relative positional bias"
- Residual connections: Skip connections that add inputs to outputs to ease optimization and enable deeper networks. "residual connections"
- Self-supervised spatiotemporal representations: Features learned without labels that capture both spatial and temporal structure. "self-supervised spatiotemporal representations"
- Shifted windows: Attention strategy that shifts local windows to enable cross-window interactions without global attention. "shifted windows"
- Spatiotemporal dependencies: Relationships across space and time that characterize video dynamics. "spatiotemporal dependencies"
- Spatiotemporal window shifting: Strategy that shifts windows along spatial and temporal axes to improve context modeling. "spatiotemporal window shifting strategy"
- Structured state-space module: A component based on state-space models that captures localized spatiotemporal dynamics. "structured state-space module"
- Swin Transformer: A hierarchical transformer that uses shifted window attention for efficient local/global modeling. "Swin Transformer"
- Temporal tubelets: Groups of consecutive frames treated as a unit to form temporally coherent tokens. "temporal tubelets"
- Token aggregation: Pooling per-token features into a single vector representing the entire video. "Token Aggregation and Classification"
- Unseen-generator splits: Test splits containing videos from generators not present in training to assess generalization. "unseen-generator splits"
- V-JEPA2: A self-supervised video encoder that outputs robust spatiotemporal embeddings. "V-JEPA2"
- ViT-style patch-based encoders: Vision Transformers that encode images/videos as sequences of patch tokens. "ViT-style patch-based encoders"
- Weight decay: Regularization that penalizes large weights to improve generalization. "weight decay of 0.05"
- Windowed self-attention: Self-attention restricted to local windows to reduce computation while preserving locality. "windowed self-attention"
Collections
Sign up for free to add this paper to one or more collections.

