GPSBench: Do Large Language Models Understand GPS Coordinates?
Abstract: LLMs are increasingly deployed in applications that interact with the physical world, such as navigation, robotics, or mapping, making robust geospatial reasoning a critical capability. Despite that, LLMs' ability to reason about GPS coordinates and real-world geography remains underexplored. We introduce GPSBench, a dataset of 57,800 samples across 17 tasks for evaluating geospatial reasoning in LLMs, spanning geometric coordinate operations (e.g., distance and bearing computation) and reasoning that integrates coordinates with world knowledge. Focusing on intrinsic model capabilities rather than tool use, we evaluate 14 state-of-the-art LLMs and find that GPS reasoning remains challenging, with substantial variation across tasks: models are generally more reliable at real-world geographic reasoning than at geometric computations. Geographic knowledge degrades hierarchically, with strong country-level performance but weak city-level localization, while robustness to coordinate noise suggests genuine coordinate understanding rather than memorization. We further show that GPS-coordinate augmentation can improve in downstream geospatial tasks, and that finetuning induces trade-offs between gains in geometric computation and degradation in world knowledge. Our dataset and reproducible code are available at https://github.com/joey234/gpsbench
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces GPSBench, a big set of tests designed to check if AI LLMs can understand and reason with GPS coordinates—the latitude and longitude numbers that tell you where places are on Earth. The goal is to see whether these models can do both math with coordinates (like distances and directions) and real-world geography (like figuring out which city a coordinate points to).
Key Questions the Paper Tries to Answer
The researchers focus on five simple questions:
- Can AI models correctly solve GPS math (like distance, direction, or converting between coordinate formats)?
- Are they better at general geography (like country and city facts) than at precise coordinate math?
- Do they truly understand coordinates, or are they just memorizing examples?
- Does adding exact coordinates to regular map questions help performance?
- Does training (finetuning) and making models bigger improve their GPS skills, and what trade-offs appear?
How the Researchers Tested the Models
Think of GPSBench like a 17-event “decathlon” for map thinking, with 57,800 questions built from a global city database (GeoNames). The tests are split into two tracks:
- Pure GPS (math-only): Tasks that use coordinates without needing world facts, such as:
- Distance on a globe (the shortest path over Earth’s surface)
- Bearing (the compass direction from one point to another)
- Converting formats (like degrees-minutes-seconds to decimal)
- Transforming between map systems (like UTM)
- Finding midpoints along a route on a sphere
- Measuring areas of shapes on the globe
- Applied geography (knowledge + coordinates): Tasks that mix map facts with coordinates, such as:
- Identifying the city at a given latitude/longitude
- Deciding which place is closest
- Saying whether one city is north/south/east/west of another
- Grouping cities by continent
- Spotting outliers in a set of cities
To keep the test fair, the models were not allowed to use external tools (like Google Maps). The researchers measured:
- Accuracy for multiple choice
- How close number answers were to the correct value (using a simple error measure)
They evaluated 14 modern AI models and compared performance across tasks and regions.
Helpful Analogies for Technical Ideas
- GPS coordinates are like a “grid address” for places on Earth: latitude (how far north/south) and longitude (how far east/west).
- Bearing is like pointing a compass from one city to another (e.g., “northeast”).
- Distance on Earth uses “curved surface” math, because Earth is roughly a sphere—imagine measuring the shortest path across a ball, not a flat map.
- Coordinate transformation is like switching between different map styles or grids.
What They Found and Why It Matters
Here are the main takeaways:
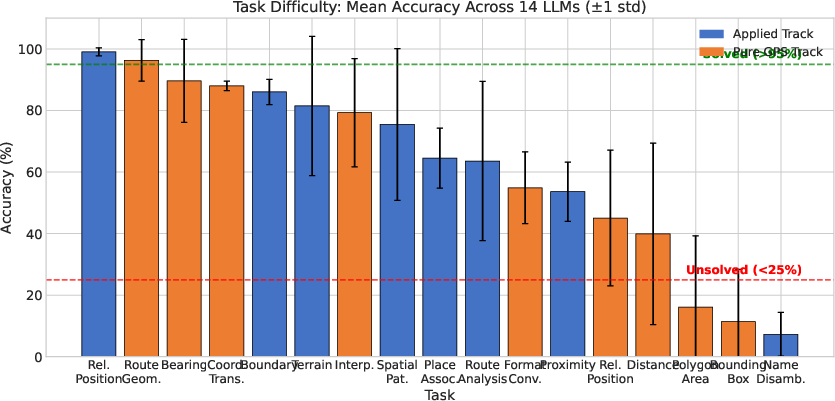
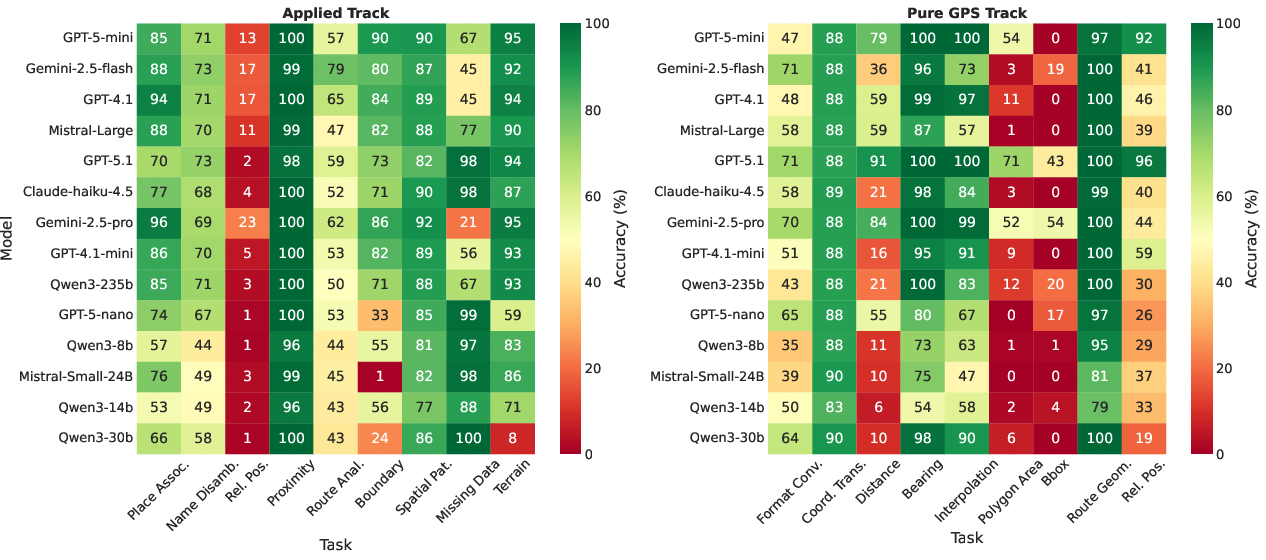
- Models handle big-picture geography better than precise math:
- Many models are good at country-level facts (like knowing a coordinate is in France) but weak at exact city identification.
- Pure math tasks that involve “spherical geometry” (the globe’s curved surface) are often hard, especially area and midpoints.
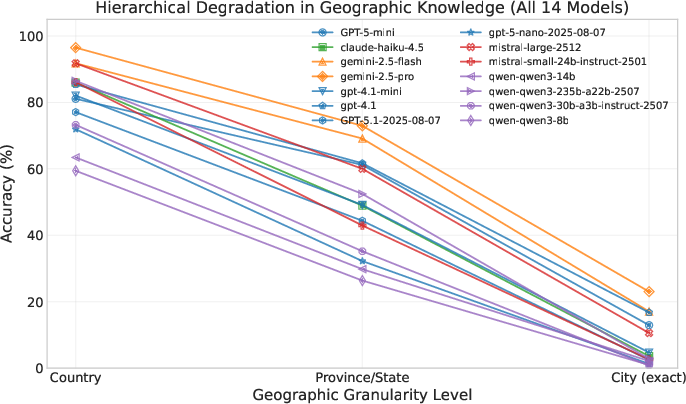
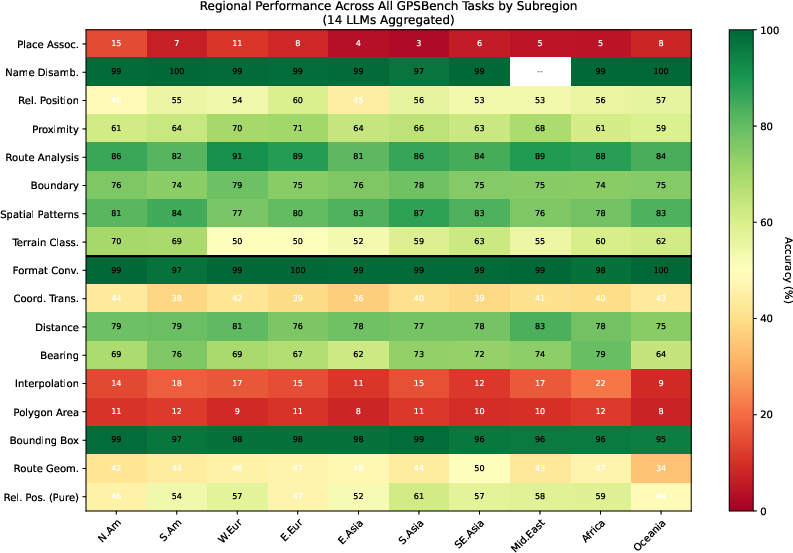
- Geography knowledge drops as you zoom in:
- Country-level: fairly strong.
- State/province-level: weaker.
- City-level: often very poor (below 25% accuracy).
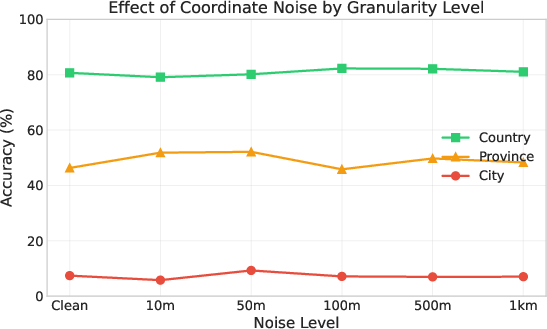
- Models aren’t just memorizing coordinate-to-city pairs:
- When the researchers added small amounts of “noise” (tiny changes) to coordinates, performance stayed steady. This suggests models use general geographic understanding instead of exact memorization.
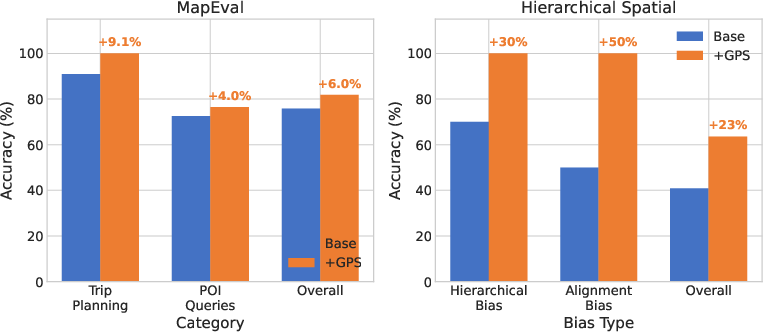
- Adding GPS coordinates to other map questions helps:
- When regular map tasks included precise coordinates, models improved—especially on questions about directions and distances (up to about +23% on some tests).
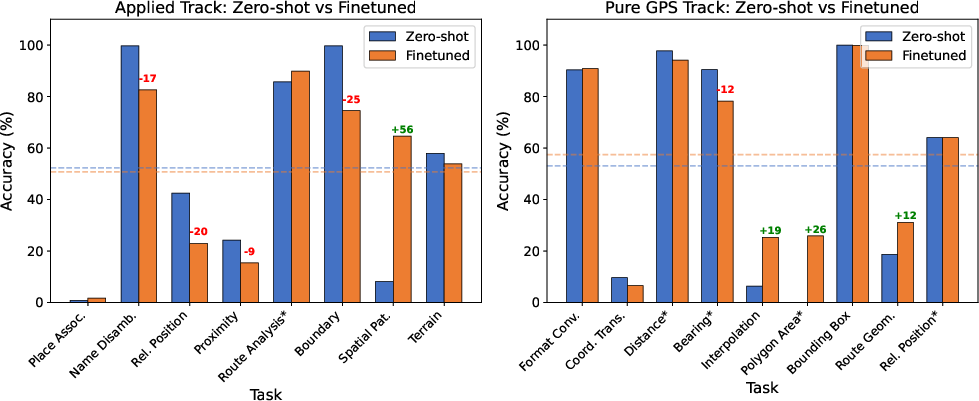
- Training brings trade-offs:
- Finetuning a model on GPSBench improved its math on coordinates but hurt its world knowledge (like recognizing places). In short: getting better at math sometimes made it worse at geography facts.
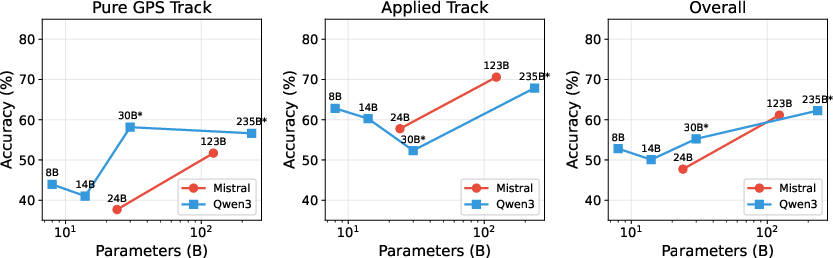
- Bigger models help:
- As model size increased, performance generally improved on both math and geography.
These findings matter because many apps—navigation, travel planning, emergencies—need trustworthy GPS reasoning. Knowing where models are strong and weak helps developers decide when they can rely on the model alone and when they should add tools (like a map API).
Implications and Impact
- For real-world use: If you need precise city-level answers from coordinates, don’t rely on an LLM by itself—use mapping tools or extra data. For general country-level reasoning or rough directions, LLMs are often fine.
- For improving models: Training should balance math skills (coordinates on a sphere) with real-world knowledge so one doesn’t hurt the other. Adding coordinates to prompts can simplify many tasks.
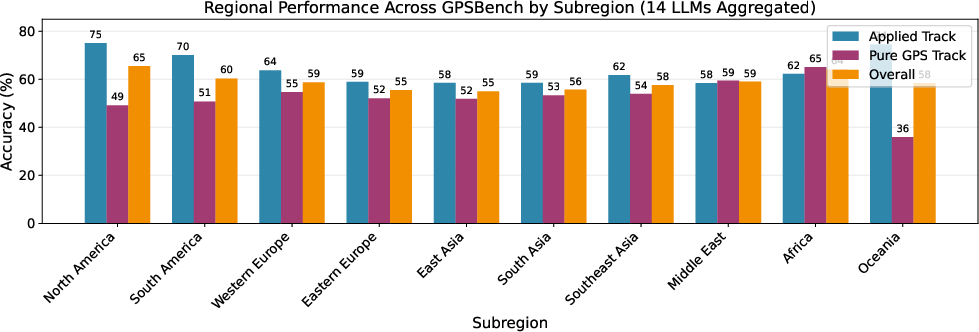
- For fairness: The models tend to be better in regions that are well represented in training data (like North America), so extra care is needed for underrepresented areas.
- For future research: Combining LLMs with geospatial tools (maps, GIS) and smart training methods could produce more reliable, globally fair geographic reasoning.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing or underexplored based on the paper.
- Multimodality gap: The benchmark and analyses are text-only. It remains unknown how multimodal models (maps, satellite, street-view) perform on the same tasks and whether visual inputs mitigate failures in fine-grained localization or spherical geometry.
- Language coverage: All prompts are in English. It is unclear how cross-lingual prompts (non-Latin scripts, transliterations, local place names) affect geospatial reasoning and whether language choice interacts with regional bias.
- World-to-geometry transfer: The paper observes trade-offs between geometric computation and world knowledge after finetuning, but does not test methods (e.g., multi-task curricula, adapters, LoRA, elastic weight consolidation, parameter-efficient continual learning) that might preserve both.
- Tool- and CoT-effects: Zero-shot, tool-free prompting may underestimate achievable performance. The impact of chain-of-thought, program-aided reasoning, geodesy toolcalls, or retrieval-augmented generation on GPSBench scores is unmeasured.
- Ellipsoidal geodesy vs spherical approximation: Ground truth uses a spherical Earth ( km). It is unknown whether switching to ellipsoidal geodesics (e.g., Karney/Vincenty) materially changes task difficulty, error rankings, or model ordering on distance, bearing, area.
- Edge-case geodesy: The benchmark does not explicitly stress-test pathological cases (antipodal/near-antipodal pairs, near poles, International Date Line crossings, UTM zone boundaries, extreme latitudes/longitudes). Model behavior on these edge cases is unknown.
- Spatial resolution beyond cities: Cities are treated as points and only cities ≥15k population are included. The paper leaves untested sub-city granularity (neighborhoods, POIs), rural/locality coverage, and building-level or address-level geocoding.
- Hierarchical scoring and partial credit: Current Place Association scoring treats near-miss (adjacent city, suburb) as incorrect. A graded, distance-aware or administrative-hierarchy-aware metric is not explored but could reveal fine-grained competence.
- Robustness beyond Place Association: Noise-robustness is measured only for Place Association and up to ~1 km. It is unknown how other tasks (bearing, proximity, route analysis) degrade under coordinate noise at larger scales (1–50 km) and with systematic biases (quantized GPS, truncated decimals).
- Coordinate formatting diversity: The benchmark tests format conversion but does not probe Place Association under diverse coordinate notations (DMS vs decimal, hemisphere letters, thousand separators, mixed precision), negative-zero cases, or swapped lat–lon orders.
- CRS and projection generality: Only WGS84→UTM/Web Mercator conversions are evaluated. The extent to which models handle other CRSs/projections (e.g., EPSG variants, local datums, MGRS, State Plane) and projection edge cases is unassessed.
- 3D/topographic reasoning: Tasks are 2D. Elevation, slope, vertical datum, topographic distance vs geodesic distance, and terrain-informed routes remain unexplored.
- Temporal/geoversioning effects: Place boundaries, names, and administrative divisions change over time. The benchmark does not test temporal geospatial knowledge (e.g., historical borders, renamed cities) or how LLM knowledge cutoffs interact with geotemporal correctness.
- Regional bias diagnosis: The paper reports subregional disparities but does not disentangle causes (training data language, web coverage, city prominence). Controlled studies varying language, population, and web visibility are needed to isolate bias drivers.
- Calibration and uncertainty: The benchmark records only accuracy/1−MAPE. Confidence calibration (e.g., probabilistic outputs, abstention) and whether models know when they don’t know remain unmeasured.
- Compositional geospatial reasoning: GPSBench mostly isolates skills. Unclear is how models handle compositions (e.g., “interpolate a point, then compute its bearing to C;” or multi-leg route analyses) and whether errors compound across steps.
- Memory vs reasoning: Noise experiments suggest limited memorization, but only for small perturbations and single-probe formats. Broader anti-memorization probes (format randomization, adversarial rounding, unseen-coordinate templates, withheld regions) are not conducted.
- Statistical rigor: Improvements (e.g., with GPS augmentation) are shown on small subsets (MapEval n=66) without significance testing or power analysis. Robustness of reported gains is uncertain.
- Downstream augmentation validity: For MapEval/Hierarchical Spatial, adding coordinates helps, but the mechanism is untested. Ablations with random/mismatched coordinates and equivalent-length neutral text would clarify whether gains come from numeric cues or true geodesic computation.
- Safety-critical evaluation: The benchmark does not assess failure modes relevant to safety (e.g., erroneous directions in emergencies, maritime/aviation navigation constraints), nor cost-sensitive metrics where small local errors have large real-world consequences.
- Dataset coverage and licensing constraints: GeoNames population filtering skews urban; maritime, polar, deserts are absent. Re-creating downstream experiments requires proprietary geocoding (Google Maps), limiting reproducibility and potentially introducing API-induced biases.
- Scaling laws and limits: Scaling helps, but the shape of scaling curves, task-specific saturation, and parameter-efficiency trade-offs are not quantified (e.g., power-law fits, compute–data–performance regimes for geospatial skills).
- Error taxonomy and interpretability: Qualitative errors are mentioned, but a structured taxonomy (formula misuse vs numeric slip vs bias) and interpretability analyses (e.g., probing latent spatial representations, attention to coordinates vs place tokens) are missing.
- Fairness at fine granularity: City-level performance is uniformly low; the paper does not measure whether errors disproportionately affect specific countries, linguistic groups, or low-resource regions at the city scale.
- Generalization beyond GeoNames: It is unknown how models trained/evaluated on GPSBench generalize to other gazetteers (OpenStreetMap, Geonames minor entities), different place typologies (villages, natural features), or out-of-distribution coordinates.
- Training data interventions: The paper does not test whether targeted pretraining (geodesy texts, open gazetteers), synthetic geospatial curricula, or instruction tuning with step-by-step geodesic derivations improve both Pure GPS and Applied tasks without trade-offs.
- Interaction with planning/optimization: Real navigation involves constraints and objectives (traffic, safety, scenic routes). The benchmark does not assess whether LLMs can integrate GPS reasoning with multi-criteria route planning or constraint satisfaction.
- Evaluation of algorithmic outputs: For tasks like Ramer–Douglas–Peucker simplification, the benchmark checks indices retained but not stability under different ε values or path shapes; sensitivity analyses and parameter-sweep robustness are not reported.
- Open-source baselines and reproducibility scope: While code is provided, replicating all results across 14 proprietary models may be infeasible. A standardized, fully open baseline suite (models + seeds + environments) is not specified.
- Human upper bounds and annotation: There is no human performance baseline or inter-annotator agreement analysis on tasks where answers may be ambiguous (e.g., boundary adjacency), leaving practical difficulty uncalibrated.
Practical Applications
Immediate Applications
The following items can be deployed now using GPSBench’s dataset, findings, and workflows, with minimal additional research. Each item includes sector(s), potential tools/products/workflows, and key assumptions/dependencies.
- Geospatial QA and certification for LLM-powered products
- Sectors: software, GIS, navigation, travel
- Tools/workflows: integrate GPSBench into CI/CD; gate releases on task-level thresholds (e.g., force external tools for “unsolved” tasks like polygon area and place association); track Applied vs Pure GPS gaps per model family
- Assumptions/dependencies: access to benchmark repository; acceptance that zero-shot, English-only evaluation approximates production use; organizational capacity to enforce quality gates
- Prompt-level GPS augmentation to boost spatial reasoning
- Sectors: mapping apps, travel planning, education, customer support
- Tools/workflows: NER/Geoparsing → geocode place names → append coordinates to prompts (as in MapEval and Hierarchical Spatial) → ask LLM to compute distances/directions
- Assumptions/dependencies: reliable geocoding API (Google Maps, OSM/Nominatim); handling rate limits and privacy; standardized coordinate formatting (WGS84)
- Granularity-aware confidence and fallback routing
- Sectors: navigation, emergency dispatch, logistics
- Tools/workflows: use hierarchical degradation findings to set confidence thresholds (high confidence at country-level; low at city-level); automatically route city-level localization to deterministic geodetic/places APIs
- Assumptions/dependencies: task classifier; fallbacks integrated (e.g., GeographicLib, OSRM); defined SLAs for safety-critical cases
- Region-aware bias monitoring and risk flags
- Sectors: platform operations, policy/compliance, international products
- Tools/workflows: dashboards that track accuracy by subregion (e.g., weaker Applied performance in East Asia/Middle East); trigger additional validation or tool-use when operating in underrepresented regions
- Assumptions/dependencies: representative test data per market; local review processes; acknowledgment of GeoNames’ urban skew
- Hybrid guardrails for spherical geometry
- Sectors: robotics, GIS analysis, fleet/logistics, energy planning
- Tools/workflows: route distance, bearing, interpolation, polygon area to trusted libraries (Haversine, GeographicLib); let LLM handle narrative/intent; enforce “library-first” for brittle Pure GPS tasks
- Assumptions/dependencies: latency tolerance for library calls; robust task routing; consistent units/precision across modules
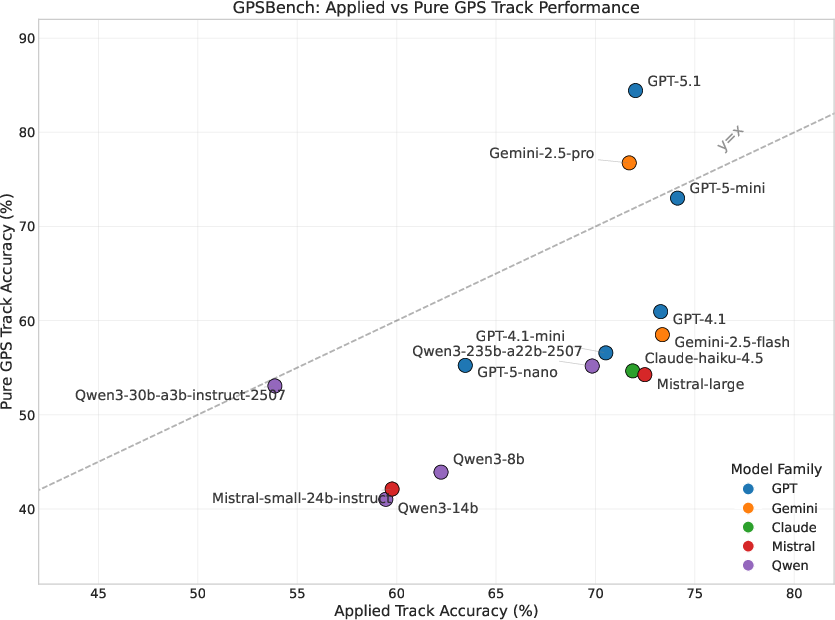
- Model selection and routing based on capability profiles
- Sectors: product management, MLOps
- Tools/workflows: prefer GPT-5.1/Gemini-2.5-Pro for Pure GPS computations; route world-knowledge tasks to Gemini-2.5-Flash/GPT-5-mini; multi-model orchestration using per-task leaderboards
- Assumptions/dependencies: cost/access to proprietary models; model availability and quotas; version tracking
- Spatial-RAG-lite: coordinate-aware retrieval augmentation
- Sectors: search, Q&A, enterprise support
- Tools/workflows: attach coordinates to entities in retrieval snippets; index spatial fields; let LLM compare numeric lat/lon instead of textual heuristics
- Assumptions/dependencies: schema support for coordinates; geocoding during ingestion; vector/relational store with spatial indexing
- Developer unit tests for map UX and helpdesk workflows
- Sectors: software/GIS support
- Tools/workflows: create GPSBench-derived unit tests for “relative position,” “bounding box center,” and “name disambiguation”; instrument regressions in releases
- Assumptions/dependencies: test harness integration; coverage for target geographies
- End-user transparency and safety messages
- Sectors: consumer apps, travel, education
- Tools/workflows: display precision notices (e.g., “country-level confidence high; city-level low—using external map service for exact location”); show coordinates used in answers
- Assumptions/dependencies: UX capacity; legal/privacy reviews; configurable confidence thresholds
- Academic use: controlled studies of spatial cognition in LLMs
- Sectors: academia
- Tools/workflows: use GPSBench to probe landmark/route/survey knowledge types; replicate noise robustness and missing-data probes; compare training strategies
- Assumptions/dependencies: compute resources; English-only prompts; licensing for GeoNames-derived samples
Long-Term Applications
The following items require further research, scaling, data integration, or productization to reach production-grade reliability.
- Continual learning that preserves world knowledge while boosting geodetic computation
- Sectors: AI model development, MLOps
- Tools/workflows: multi-objective finetuning (adapters/LoRA), elastic weight consolidation, rehearsal on world-knowledge datasets; monitor trade-offs highlighted by GPSBench (Pure GPS gains vs Applied degradation)
- Assumptions/dependencies: access to model weights; training infrastructure; evaluation pipelines to detect regressions
- Multimodal geospatial LLMs (maps, satellite, street-view)
- Sectors: robotics, urban planning, environmental monitoring, defense/emergency response
- Tools/workflows: integrate raster/vector map inputs; learn spherical geometry with visual context; couple textual reasoning with spatial layers
- Assumptions/dependencies: large, licensed geospatial corpora (satellite, OSM, street-view); GPUs; careful privacy/ethics governance
- Spatial-RAG systems with coordinate-indexed knowledge bases
- Sectors: logistics, emergency management, mobility, tourism
- Tools/workflows: build spatially-indexed retrieval (R-trees/quadtrees) and attach region metadata; retrieve by coordinate proximity; let LLM fuse retrieved facts with numeric computations
- Assumptions/dependencies: high-quality POI and administrative boundary data; consistent coordinate reference systems; operationalized data refresh
- Standardized procurement and compliance benchmarks for location-sensitive AI
- Sectors: public sector, regulated industries
- Tools/workflows: mandate GPSBench-like evaluation in vendor selection; minimum thresholds per task/granularity/region; require tool-augmented fallback for “unsolved” tiers
- Assumptions/dependencies: policy consensus; test availability across languages; versioned benchmark governance
- Fairness auditing and mitigation for geospatial bias
- Sectors: policy, ethics, platform governance
- Tools/workflows: regular audits across subregions; targeted data augmentation for underperforming regions; fairness-aware routing (prefer tool-use where bias is high)
- Assumptions/dependencies: culturally/linguistically diverse datasets; organizational commitment; public reporting standards
- Robust geospatial copilots for professional GIS and planning
- Sectors: urban planning, environmental impact assessment, energy siting
- Tools/workflows: task routers that combine LLMs for narrative synthesis with deterministic spatial computation for metrics (areas, buffers, routes); scenario planning with explicit coordinate inputs
- Assumptions/dependencies: integration with GIS stacks (ArcGIS/QGIS); domain ontologies; audit trails
- Autonomous and semi-autonomous robotics with global spatial reasoning
- Sectors: drones, maritime, field robotics
- Tools/workflows: high-level instruction parsing (LLM) + geodetic planning modules; validate bearings/interpolations with libraries; fallback to map-based planners
- Assumptions/dependencies: robust sensor fusion; safety certification; real-time constraints
- Disaster response decision support with coordinate-first workflows
- Sectors: emergency response, humanitarian logistics
- Tools/workflows: ingest GPS from field teams; route triage and resource allocation via deterministic spatial computations; LLMs summarize plans and constraints
- Assumptions/dependencies: reliable connectivity or offline data packs; strong validation; operator training
- Synthetic data and curriculum design to improve city-level place association
- Sectors: AI training, geocoding
- Tools/workflows: generate dense coordinate-to-city pairs, hard negatives with near-adjacent cities, multilingual variants; train with contrastive objectives
- Assumptions/dependencies: licensing for base gazetteers; avoidance of memorization-only shortcuts; multilingual coverage
- Cross-lingual and rural-focused extensions of GPSBench
- Sectors: academia, global product teams
- Tools/workflows: create benchmarks beyond English; expand rural and non-urban coverage; include maritime/polar/desert tasks and building-level reasoning
- Assumptions/dependencies: data acquisition; annotation; broader geodetic models (ellipsoidal precision)
Common Assumptions and Dependencies Across Applications
- Coordinate systems and precision: WGS84; spherical approximations may be insufficient for high-precision tasks (ellipsoidal models recommended for meter-level accuracy).
- Data coverage and bias: GeoNames and similar sources skew urban; underrepresented regions need augmentation; evaluate regional biases before deployment.
- Tool routing: Many brittle Pure GPS tasks should be handled by geodetic libraries; build reliable task classifiers and fallbacks.
- Privacy and offline constraints: Some deployments cannot use external APIs; prepare local geocoding and computation modules.
- Language and modality: Current benchmarks are English-only and text-only; extending to multilingual and multimodal settings will change capability profiles.
- Model access and costs: Proprietary models with stronger geometry skills may be expensive or restricted; plan for multi-model orchestration or open-weight alternatives.
Glossary
- Allocentric: A world-centered frame of reference independent of the observer, used for map-like spatial representations. "Survey knowledge represents an allocentric, map-like understanding of space"
- Bearing: The compass direction from one location to another, measured in degrees clockwise from north. "Bearing from (49.28, -123.13) to (5.89, 5.68)? 55.2° (NE)"
- Bounding Box: The smallest axis-aligned rectangle (by min/max latitude and longitude) that contains a set of geographic points. "Bounding Box & Center of [(-2.85, 33.08), (21.15, 72.96), (53.60, 24.75), ...]? (7.82, 52.08)"
- Coordinate Interpolation: Finding an intermediate point between two coordinates along a path (on a sphere for geodesy). "Coordinate Interpolation & 50\% along (29.93, 117.95) to (-6.99, 106.55)? (11.53, 111.86)"
- Coordinate Transformation: Converting coordinates between different spatial reference systems or projections. "Coordinate transformations use Universal Transverse Mercator (UTM) and Web Mercator (EPSG:3857)."
- Egocentric: An observer-centered frame of reference tied to the navigator’s perspective and movements. "egocentric knowledge tied to a specific traversal experience"
- EPSG:3857: The EPSG code for the Web Mercator projection widely used in web mapping. "Web Mercator (EPSG:3857)"
- Forward azimuth: The initial compass direction from a start point to a destination along the shortest path on the Earth’s surface. "forward azimuth for bearing"
- Geocoding: Converting place names or addresses into geographic coordinates. "we geocode all place names mentioned in each question using the Google Maps API"
- Geodetic: Relating to Earth’s shape, coordinate systems, and precise spatial computations on the globe. "All ground-truth values use standard geodetic formulae"
- GeoNames: A global geographic database of places and their coordinates and attributes. "All samples are derived from the GeoNames database"
- Geoparsing: Extracting and resolving location references in text to geographic coordinates. "For geoparsing, benchmarks such as LGL \citep{lieberman2010geotagging} and WikToR \citep{gritta2018wikor} evaluate text-to-coordinate mapping."
- Great-circle: The shortest path between two points on a sphere; used for long-distance Earth navigation. "computing great-circle distances"
- Haversine formula: A trigonometric equation for computing great-circle distance between two latitude/longitude points. "Haversine for distance"
- Intercardinal directions: Directions halfway between cardinal points (NE, SE, SW, NW). "intercardinal direction judgments between city pairs"
- Landmark knowledge: Recognition of salient locations without encoding metric relationships or routes. "Landmark knowledge involves the recognition and recall of salient environmental features"
- L'Huilier's theorem: A formula for computing the area of a spherical triangle from its angles. "L'Huilier's theorem for polygon area."
- Mean Absolute Percentage Error (MAPE): An error metric expressing prediction error as a percentage of the true value. "Mean Absolute Percentage Error (MAPE)"
- Ramer–Douglas–Peucker algorithm: A line-simplification method that reduces points in a polyline while preserving shape within a tolerance. "RamerâDouglasâPeucker algorithm (=500m)"
- Route knowledge: Procedural, sequence-based understanding of paths connecting landmarks. "Route knowledge captures ordered sequences of actions or paths that connect landmarks"
- Survey knowledge: A map-like, metric, and relational representation enabling flexible spatial reasoning. "Survey knowledge represents an allocentric, map-like understanding of space"
- Spherical geometry: Geometry on the surface of a sphere, governing distances, areas, and angles on Earth. "complex spherical geometry"
- Spherical linear interpolation: Interpolation along the great-circle arc between two points on a sphere (SLERP). "spherical linear interpolation for intermediate points"
- Spherical polygon area: The area of a polygon drawn on a sphere, computed using spherical trigonometry. "spherical polygon areas"
- Universal Transverse Mercator (UTM): A global map projection and grid system dividing the world into zones for metric coordinates. "Universal Transverse Mercator (UTM)"
- Web Mercator: A map projection commonly used in web mapping platforms, approximating Mercator on a sphere. "Web Mercator (EPSG:3857)"
- WGS84 ellipsoid: The standard Earth datum defining the reference ellipsoid for GPS coordinates. "WGS84 ellipsoid approximated as a sphere (~km)"
Collections
Sign up for free to add this paper to one or more collections.