- The paper reveals that biased sampling distributions significantly impact Identity Preference Optimization effectiveness, potentially leading to policy collapse.
- It shows that integrating on-policy and off-policy data with conservative updates can stabilize iterative alignment dynamics in LLM retraining.
- The research advocates for adaptive, instance-dependent sampling methods to enhance robust alignment and mitigate oscillatory failure modes.
Understanding the Influence of Sampling on LLM Alignment
This essay explores the core insights presented in the paper "How Sampling Shapes LLM Alignment: From One-Shot Optima to Iterative Dynamics," which examines the interplay between sampling strategies and preference alignment in LLMs. The paper critiques existing methods and introduces a theoretical framework for understanding the effects of sampling in both one-shot and iterative alignment settings.
Identity Preference Optimization (IPO) in Sampling Dynamics
The foundational aspect explored is Identity Preference Optimization (IPO), a framework for aligning LLMs with human preferences via pairwise comparison data. The study reveals that while IPO aims to fulfill ranking desiderata, the sampling distribution critically influences its efficacy. Specifically, when sampling is skewed, it can amplify concentration, potentially leading to policy collapse—a situation where the policy becomes overly deterministic with low entropy.
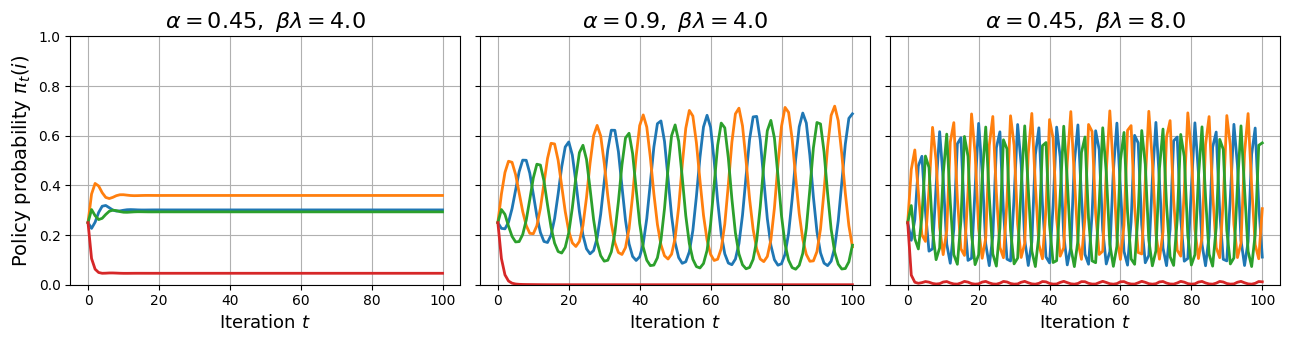
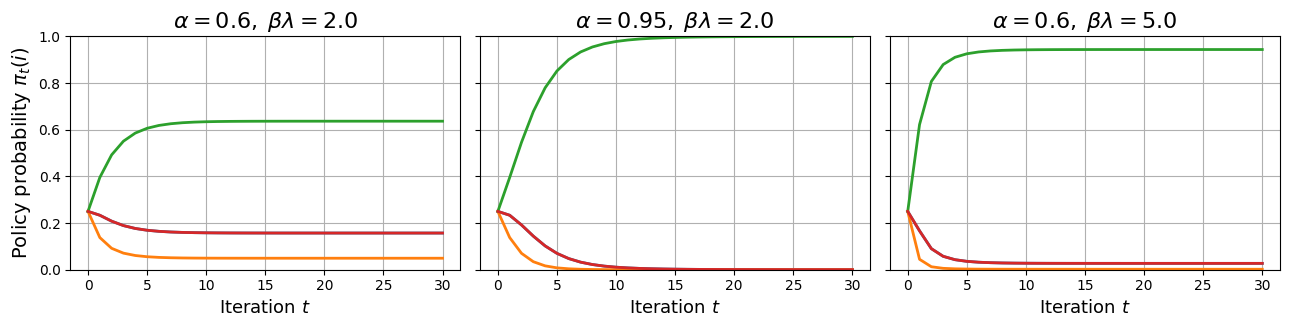
Figure 1: Policy evolution of MRS-IPO on P with a cyclic structure in the first 100 iterations. Compared to the baseline, increasing either α or βλ induces oscillations.
The analysis underscores the double-edged nature of sampling: while instance-dependent sampling can theoretically restore certain social choice properties (e.g., Condorcet and Smith top), fixed sampling often fails these axioms, particularly under cyclic preferences. This suggests a need for adaptable, context-aware sampling strategies to bolster IPO's effectiveness.
Iterative Dynamics and Self-Reinforcing Loops
The paper extends its critique to iterative alignment dynamics, reflective of practical workflows in LLM training, where models are retrained iteratively using preference data generated by the model itself. It finds that these dynamics can lead to persistent oscillations or entropy collapse, especially under cyclic preferences, if updates are aggressive or sampling is heavily on-policy.
Key findings suggest that mixing on-policy and off-policy data, alongside conservative update strategies, can stabilize these dynamics. This insight is critical for designing training protocols resistant to the self-reinforcing failure modes observed in iterative preference alignment loops.
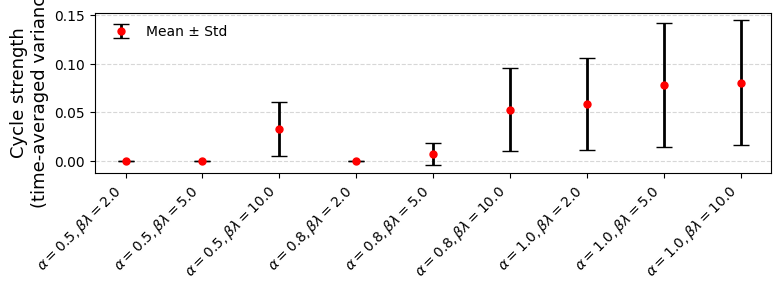
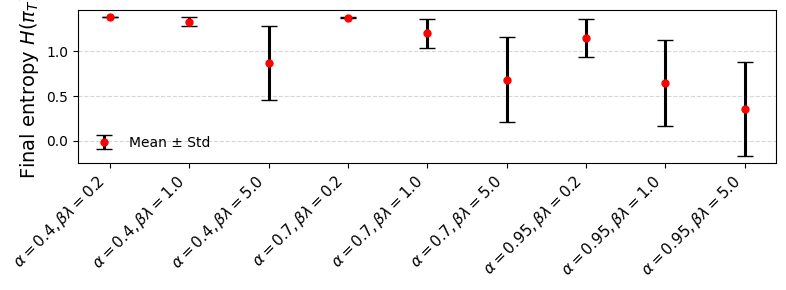
Figure 2: Mean pm standard deviation of time-averaged variance of varies.
Practical Implications and Future Directions
Practically, these observations highlight the necessity for carefully crafted sampling distributions that leverage the natural structure of preference matrices without inducing instabilities. Instance-dependent sampling methods, which adaptively concentrate on responses aligning well with overarching human preferences, are proposed as a solution.
Moving forward, the study advocates for a reimagined approach to preference alignment, treating these systems less as static optimization problems and more like dynamic, stochastic learning environments. Such perspectives could help mitigate the risks of instability and policy collapse, ultimately enabling more robust preference alignment in LLMs.
Conclusion
In summary, the intricate relationship between sampling strategies and preference alignment underscores the need for nuanced approaches in both one-shot and iterative training regimes for LLMs. By understanding and addressing the mechanisms through which sampling influences policy behavior, this research contributes essential insights to the fields of AI safety and interpretability, paving the way for more resilient and aligned AI systems.