When would Vision-Proprioception Policies Fail in Robotic Manipulation?
Abstract: Proprioceptive information is critical for precise servo control by providing real-time robotic states. Its collaboration with vision is highly expected to enhance performances of the manipulation policy in complex tasks. However, recent studies have reported inconsistent observations on the generalization of vision-proprioception policies. In this work, we investigate this by conducting temporally controlled experiments. We found that during task sub-phases that robot's motion transitions, which require target localization, the vision modality of the vision-proprioception policy plays a limited role. Further analysis reveals that the policy naturally gravitates toward concise proprioceptive signals that offer faster loss reduction when training, thereby dominating the optimization and suppressing the learning of the visual modality during motion-transition phases. To alleviate this, we propose the Gradient Adjustment with Phase-guidance (GAP) algorithm that adaptively modulates the optimization of proprioception, enabling dynamic collaboration within the vision-proprioception policy. Specifically, we leverage proprioception to capture robotic states and estimate the probability of each timestep in the trajectory belonging to motion-transition phases. During policy learning, we apply fine-grained adjustment that reduces the magnitude of proprioception's gradient based on estimated probabilities, leading to robust and generalizable vision-proprioception policies. The comprehensive experiments demonstrate GAP is applicable in both simulated and real-world environments, across one-arm and dual-arm setups, and compatible with both conventional and Vision-Language-Action models. We believe this work can offer valuable insights into the development of vision-proprioception policies in robotic manipulation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching robots to use two kinds of “senses” together to do hands-on tasks, like picking up objects or assembling parts:
- Vision: like the robot’s eyes (camera images).
- Proprioception: like the robot’s body sense (its arm positions, angles, and how open the gripper is).
The big goal is to make robots more accurate and more dependable by combining both senses. But the authors noticed something surprising: sometimes adding proprioception actually makes the robot worse at new situations. They explain why that happens and introduce a fix called GAP that helps the two senses work together better.
What questions does the paper ask?
- When and why do policies that use both vision and proprioception fail?
- Why does the vision part sometimes get ignored, even when it’s needed?
- Can we train robots so they use vision more at the right moments and proprioception more at the right moments?
- Does their new training method (GAP) make robots more reliable in many tasks and settings?
How did they study it? (With simple analogies)
Think of a robot doing a task like a person traveling:
- Motion-consistent phases: like cruising straight on a highway. The robot already knows where to go and just needs to keep moving smoothly. Proprioception (body sense) is great here.
- Motion-transition phases: like intersections where you change direction or find a new street. The robot needs to locate the target again (e.g., find the hole to insert a peg). Vision (eyes) matters most here.
The authors ran controlled experiments:
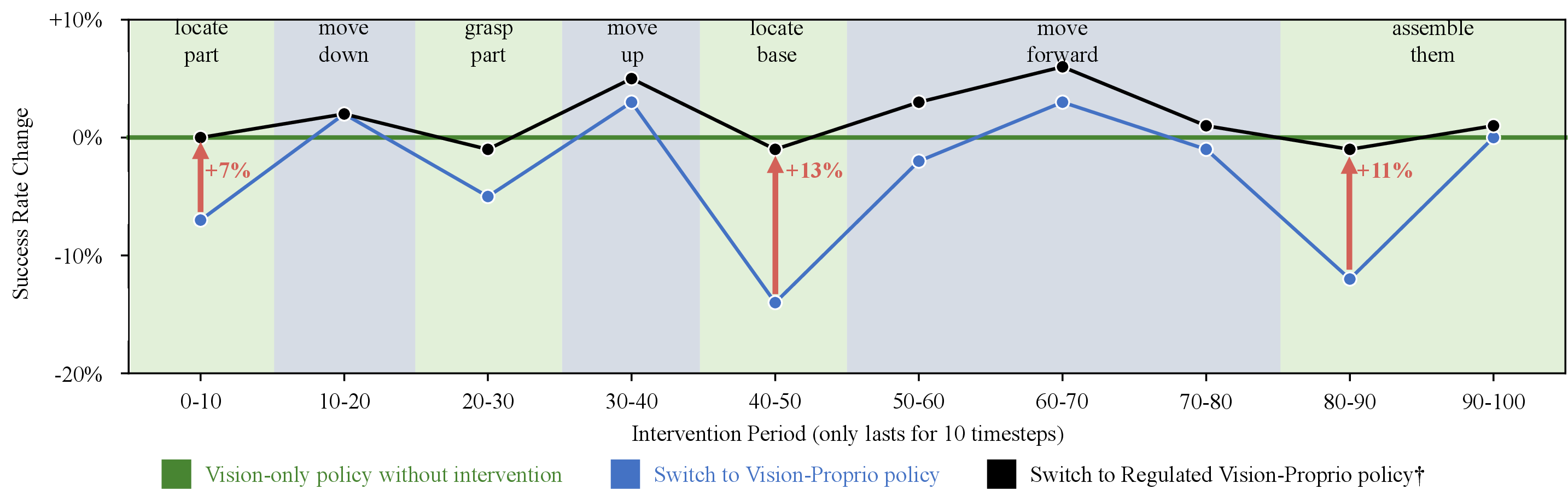
- They took a robot policy that uses only vision and swapped in a vision+proprioception policy for short time windows to see when the swap helps or hurts.
- They found the swap hardly changes anything during “cruising” but hurts during “intersections” (motion transitions)—meaning the vision part inside the combined policy isn’t doing its job when it should.
Why does that happen during training?
- During learning, the robot tries to reduce its error fast. Proprioception is a short, clean signal (numbers like hand position and gripper opening), so it gives quick wins. Vision is messier (pixels) and harder to learn from.
- Result: the learning algorithm “turns up the volume” on proprioception and “turns down” vision, especially during tricky transitions when vision is crucial. Over time, the robot under-learns vision and over-relies on proprioception.
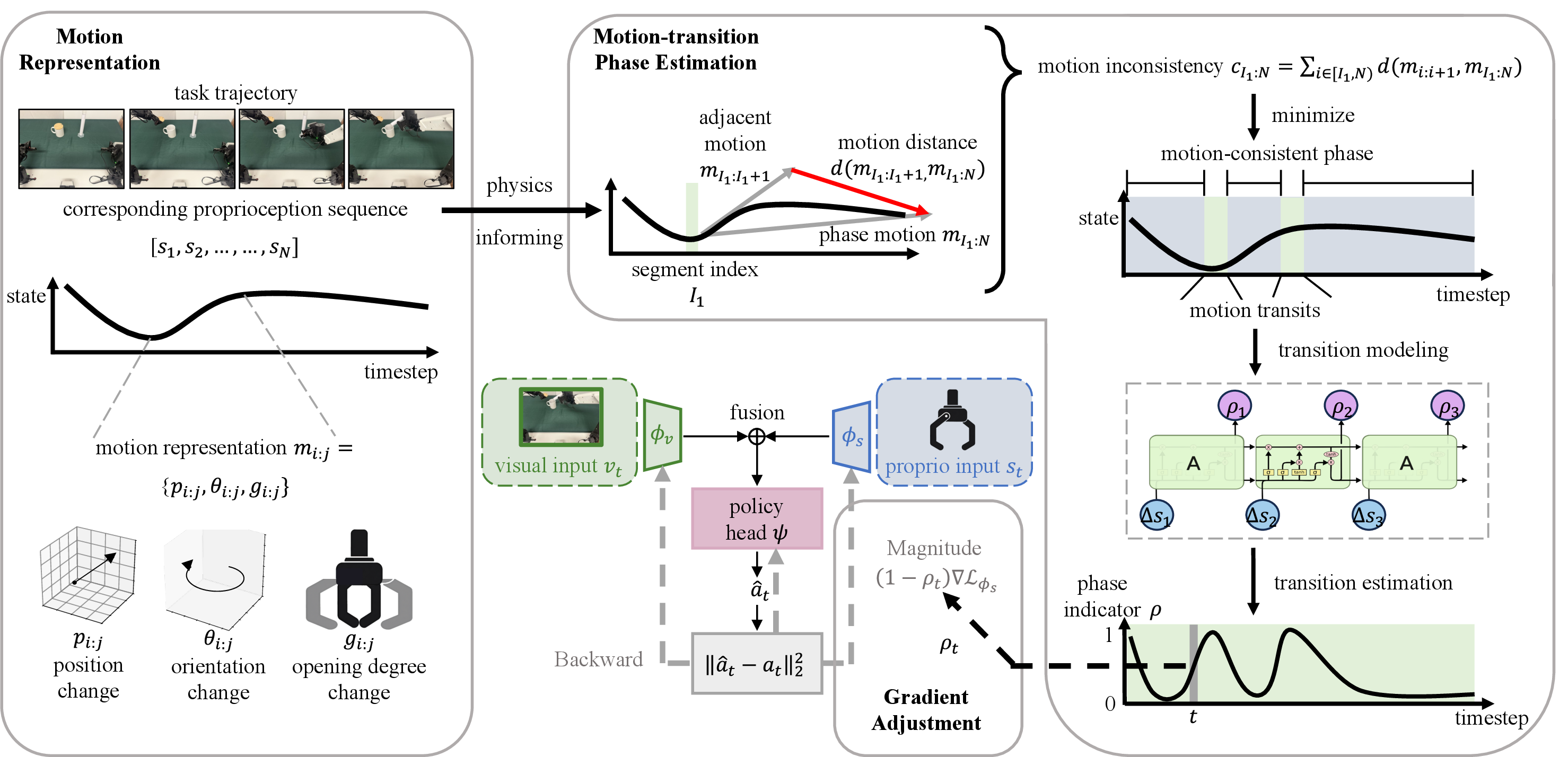
Their solution: GAP (Gradient Adjustment with Phase-guidance)
- Step 1: Find when the robot is likely in a motion-transition.
- They use proprioception to describe motion and split the task into chunks where motion is steady (a simple “change point detection” tool).
- Because transitions are gradual, they add a small time-based model (like an LSTM) to estimate, at each moment, the probability that the robot is in a transition.
- Step 2: Adjust learning at those moments.
- During high-probability transition moments, GAP gently “turns down” how much the robot learns from proprioception (reduces its gradient), so the vision part can “speak up” and learn the visual cues it needs.
- Think of it as a coach saying: “Right now, don’t rely on your calculator—use your eyes and reasoning.” Outside transitions, proprioception can learn at full strength again.
This dynamic coaching helps the two senses collaborate instead of one drowning out the other.
What did they find?
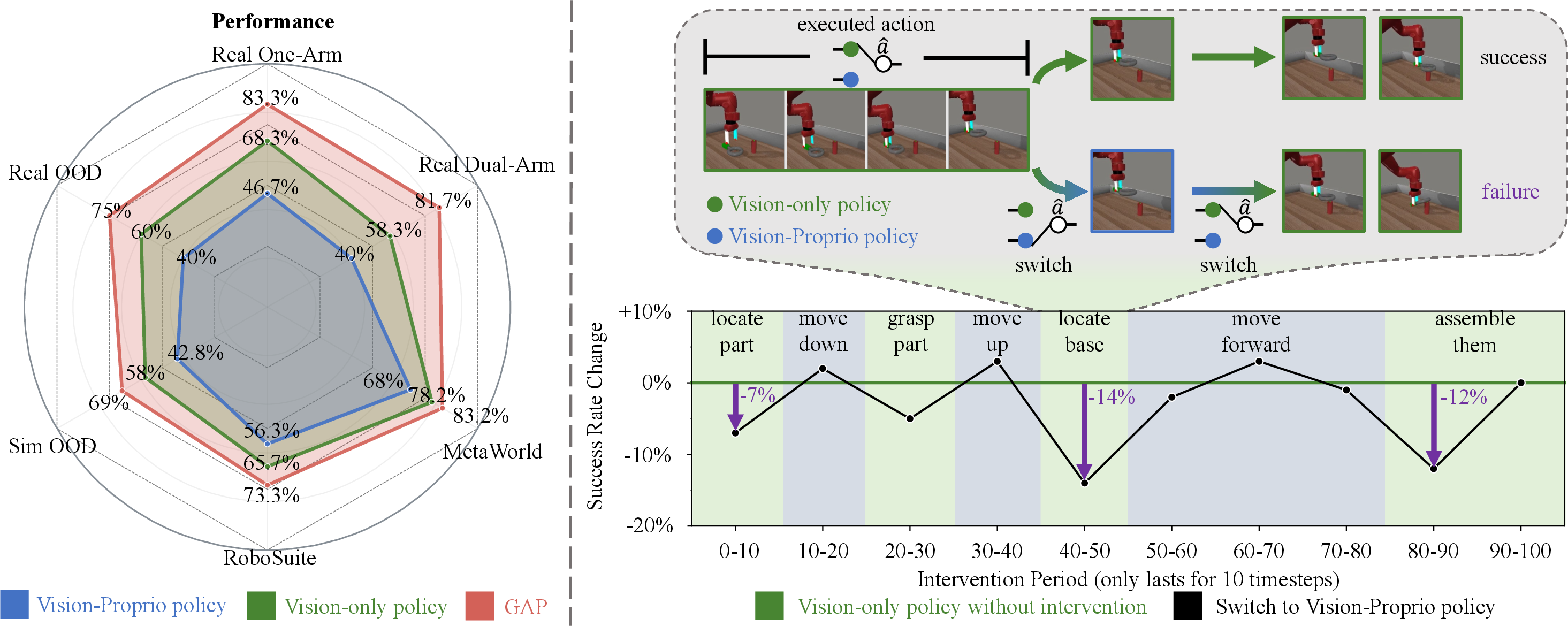
- Without GAP, adding proprioception can make things worse than using vision alone. In one summary figure, vision+proprioception performed about 15.8% worse than vision-only, mainly because the vision part was under-trained for transitions.
- With GAP, the combined policy consistently beats both:
- Vision-only policies
- Standard vision+proprioception policies
- GAP works across:
- Simulators (Meta-World, RoboSuite) and real robots (single-arm and dual-arm tasks)
- Different policy types (MLP, diffusion, transformers)
- Different fusion styles (concatenation, summation, FiLM)
- Vision-Language-Action models (like Octo): previously, adding proprioception often hurt; with GAP, it helped and improved generalization.
- It also improves out-of-distribution performance (new starting positions or layouts), showing the robot learned to actually “look” when it matters.
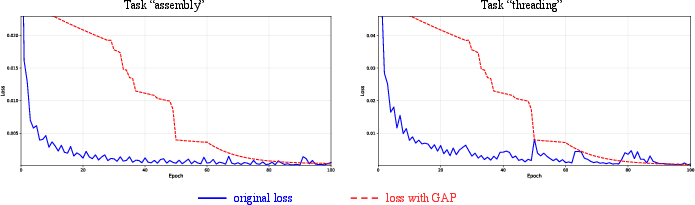
- Training note: with GAP, training may look slower early on (loss goes down more slowly) but ends up better (lower final loss and better real performance).
Why is this important?
Robots need to handle real-world change—different object positions, lighting, or clutter. That requires vision to be strong at the right times, and proprioception to keep movements precise. This paper shows:
- The problem: multimodal learning can accidentally silence vision during the moments it’s most needed.
- The fix: guide training so each sense leads when it should. GAP is a simple, general way to do that.
- The impact: more reliable robots that generalize better, across many tasks and model types—important for moving robot learning from labs into messy real environments.
Key terms explained
- Proprioception: a robot’s “body sense”—joint angles, hand position, and how open/closed the gripper is.
- Motion-consistent phase: a steady movement segment (e.g., moving straight to a target).
- Motion-transition phase: a change in action or goal (e.g., finding the hole, switching from moving to grasping).
- Behavior Cloning: learning by copying recorded expert actions.
- Gradient: the learning signal that tells the model how to adjust its parameters; “turning down the gradient” means letting that part learn more slowly so another part can catch up.
Final takeaway
When robots learn from both vision and proprioception, training can over-favor the easy, clean proprioceptive signals and neglect vision—especially during critical transitions. GAP detects those moments and nudges learning so vision gets the practice it needs. The result is a stronger, more general robot policy across simulations, real robots, and different model families.
Limitation noted by the authors: they trained on a single robot type. Testing how proprioception transfers across different robot bodies is an exciting direction for future work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research:
- Lack of formal theory: No quantitative or theoretical analysis proves the claimed optimization dominance of proprioceptive signals over vision; measure per-modality gradient norms, mutual information with actions, and contribution to loss reduction across phases to substantiate the argument.
- Phase estimation reliability: Motion-transition phase probabilities are trained via LSTM using CPD-derived discrete labels; evaluate the accuracy and robustness of phase estimation, compare against alternative temporal models (e.g., HMMs, Transformers), and assess the impact of misclassification on GAP’s effectiveness.
- Hand-tuned phase features: CPD relies on hand-set weights for position, orientation, and gripper signals (α, β); investigate automatic or learned weighting, sensitivity analysis, and cross-task transferability of these weights.
- Proprioception-only phase cues: Transition detection uses only proprioceptive deltas; test whether adding visual, depth, force/torque, or tactile cues improves phase detection in cases where proprioception changes are minimal or delayed (e.g., pre-contact localization).
- Batch-level modulation: GAP applies gradient scaling using the average phase indicator per mini-batch; study per-sample/per-timestep scaling, temporal weighting within sequences, and the effect of sequence length on training stability and performance.
- Unintended underuse of proprioception: GAP reduces proprioception gradients during transitions; analyze failure cases where this harms tasks with proprioception-critical transitions or ambiguous visuals, and add safeguards (e.g., floor on proprioception gradients, adaptive schedules).
- Optimizer dependence: The update rule is presented for vanilla GD; evaluate behavior with common optimizers (Adam, RMSProp), gradient clipping, weight decay, and mixed-precision training to understand stability and convergence effects.
- No inference-time gating: Phase indicators are only used during training; explore test-time modality gating (e.g., learned attention or MoE routing conditioned on phase) to dynamically weight modalities at inference.
- Generalization breadth: OOD evaluations only vary initial object positions; extend to broader shifts (camera viewpoint, lighting, background clutter, texture changes, partial occlusions, unseen objects/tools, distractors, domain shifts, and real-world sensor drift).
- Sensor robustness: Assess sensitivity to noisy, delayed, or biased proprioceptive and visual measurements; evaluate performance under synchronization jitter, latency, and calibration errors, especially in real-world deployments.
- Multimodal scope: The study excludes tactile/force/torque/depth modalities; quantify whether adding these modalities alleviates the visual subtlety issue during transitions and improves precision in contact-rich tasks.
- Architecture coverage: Only three fusion schemes (Concatenation, Summation, FiLM) are evaluated; compare against gating networks, attention-based fusion, MoE, cross-modal transformers, and adaptive feature selection mechanisms.
- Hyperparameter sensitivity: The effect of GAP’s λ and phase thresholding is only briefly addressed; conduct thorough sensitivity analysis, task-specific tuning strategies, and meta-learning or curriculum schedules for λ.
- Data efficiency: The paper does not quantify sample efficiency; measure how GAP affects data requirements, learning curves, and asymptotic performance relative to baselines.
- Training overhead: No analysis of computational and wall-clock overhead from CPD/LSTM phase estimation and gradient modulation; report costs, scalability with dataset size, and integration complexity in large-scale training.
- Stability and safety: GAP slows initial loss reduction; examine training stability (oscillations, mode collapse), catastrophic forgetting of proprioception, and provide criteria or bounds ensuring safe training dynamics.
- Causal evaluation: The intervention experiment suggests suppression of vision during transitions but lacks causal tests controlling confounders; perform modality ablations, controlled synthetic datasets, and causal inference to isolate modality effects.
- Task diversity and bias: Tasks selected may favor specific modality patterns; expand evaluations to long-horizon hierarchical tasks, deformable objects, multi-object interactions, tool use, and dynamic environments to test modality-temporality assumptions.
- VLA generalization: Octo results are encouraging but limited; test GAP across more VLA models (RT-2, OpenVLA), varied instruction forms, multi-language prompts, and larger-scale datasets to assess generality and scaling behavior.
- Loss functions and action spaces: Analysis assumes MSE for continuous actions; evaluate GAP under other losses (Huber, CE), discrete/parameterized action spaces, and hybrid controllers.
- Embodiment and cross-robot transfer: As noted, policies are trained on a single embodiment; test cross-embodiment transfer (different kinematics, payloads, end-effectors), and whether phase estimation and GAP remain effective across robots.
- Real-world reproducibility: Provide more details on sensor setups, calibration, camera placement, synchronization, and environmental conditions to enable reproducibility and assess robustness across labs.
- Integration with RL/DAgger: GAP is studied under BC; explore application in on-policy RL, offline RL, DAgger, and residual learning, including how phase-aware gradient modulation interacts with exploration/credit assignment.
- Visual representation quality: Visual subtlety is cited as a failure mode; evaluate whether stronger visual encoders (e.g., depth, multi-view, foundation models) or targeted augmentation reduce suppression without GAP.
- Test-time phase detection utility: Investigate if real-time phase detection can trigger adaptive control strategies (e.g., switching controllers, adjusting gains, or selecting sub-policies) to improve execution robustness.
These gaps outline concrete directions to strengthen the method’s theoretical grounding, expand its applicability, and improve robustness across diverse tasks, modalities, and deployment conditions.
Practical Applications
Practical Applications of “When would Vision-Proprioception Policies Fail in Robotic Manipulation?”
Below are actionable use cases derived from the paper’s findings and the GAP algorithm, grouped by their deployability. Each item links to sectors, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
- Robust manipulation training for manufacturing and assembly
- Sectors: robotics, manufacturing, electronics, automotive
- Use cases: insertion and assembly, bin-picking with variable object poses, drawer/door operations, contact-rich operations, rotation-sensitive tasks (e.g., “threading”)
- Tools/workflows: integrate GAP into existing imitation-learning pipelines (BC, diffusion, transformer policies) as a training-time module that (i) segments motion-consistent phases via CPD, (ii) estimates motion-transition probabilities with an LSTM over Δproprioception, and (iii) scales proprioception gradients during training; deploy with PyTorch/JAX as a “GAP optimizer” plugin; no changes at inference
- Assumptions/dependencies: synchronized and calibrated visual and proprioceptive streams (e.g., gripper 6D pose + gripper opening); sufficient expert demonstrations with diverse target positions; tasks with identifiable motion transitions; per-sample/per-step gradient scaling supported in training framework
- Performance recovery when adding proprioception to VLA models
- Sectors: software/robotics, foundation models for control
- Use cases: fine-tuning VLA models (e.g., Octo) where adding proprioception has previously degraded performance; recover and surpass vision-only baselines by applying GAP during fine-tuning
- Tools/workflows: fine-tuning recipe for VLA models with GAP-based gradient modulation; drop-in wrappers for Octo-/RT-/OpenVLA-like training loops; evaluation harness for OOD generalization on object pose shifts
- Assumptions/dependencies: access to model fine-tuning; licensing and compute for large VLA models; consistent proprioception definitions across tasks (6D gripper, gripper aperture or equivalent)
- Dual-arm coordination and handover in logistics and packaging
- Sectors: logistics/warehousing, e-commerce fulfillment
- Use cases: dual-arm handover, bagging/packaging, coordinated object placement with variable handover poses
- Tools/workflows: GAP-enabled training on dual-arm datasets (e.g., Cobot Magic setup), with phase-estimation tuned to bimanual kinematics and synchronized proprioceptive streams
- Assumptions/dependencies: well-synchronized bimanual proprioception; curated demonstrations that capture frequent motion transitions (initiate handover, release, regrasp)
- Service and home robots for routine tasks under occlusions and variability
- Sectors: consumer robotics, hospitality/retail
- Use cases: opening lids, pouring, wiping/sweeping surfaces, pressing buttons; reduce failure in transitions where visual cues are subtle/occluded and object placement is variable
- Tools/workflows: GAP during training on household task datasets; camera placement to maximize informative visuals during transitions; simple on-robot data collection + CPD-based phase tagging for data balancing
- Assumptions/dependencies: modest-quality RGB and accurate proprioception; curated demonstrations inclusive of occlusions and variable object placements; reliable time sync between sensors
- Diagnostics and QA for multimodal policies (modality-temporality testing)
- Sectors: academia, R&D labs, systems integrators
- Use cases: identify when and why policies over-rely on proprioception; quantify modality failure during motion transitions; improve dataset composition and curriculum
- Tools/workflows: implement the paper’s intervention test (swap actions with VP policy over specific 10-step windows) and visualization of transition probabilities ρ; add an OOD test suite that shifts initial object poses
- Assumptions/dependencies: access to replay buffers for intervention; tooling for per-timestep evaluation; consistent phase segmentation (CPD + LSTM)
- Dataset curation and sampling for improved generalization
- Sectors: academia, dataset providers, integrators
- Use cases: phase-aware data balancing that oversamples transition timesteps; automatic labeling of motion-consistent segments and transitions for analysis and training schedules
- Tools/workflows: “CPD+LSTM phase tagger” for automatic transition labels; integration with data loaders to weight/schedule transition-heavy minibatches
- Assumptions/dependencies: sufficient diversity of transitions in recorded demos; robust CPD hyperparameters per robot/task; careful handling of continuous transitions (soft supervision around change points)
- Training more reliable contact-rich policies without runtime cost
- Sectors: robotics, industrial automation
- Use cases: tasks sensitive to precise contact and small visual changes (pressing, slotting, snapping, threading)
- Tools/workflows: apply GAP’s gradient scaling only during training; no added inference latency or hardware requirements; works with concatenation, summation, and FiLM fusion
- Assumptions/dependencies: accurate proprioception capturing micro-motions; training frameworks that support fine-grained gradient control
Long-Term Applications
- Cross-embodiment generalization and transfer
- Sectors: robotics, platform-agnostic control
- Use cases: training VP policies that transfer across robot arms/end-effectors with differing kinematics; cross-robot foundation models that maintain robust transition handling
- Tools/workflows: domain adaptation/meta-learning to learn embodiment-invariant phase estimators and scaling policies; shared proprioception representations
- Assumptions/dependencies: availability of multi-embodiment datasets; standardized proprioception formats; careful alignment of coordinate frames
- Runtime adaptive sensor fusion guided by phase estimation
- Sectors: robotics, autonomous systems
- Use cases: at inference, gate or reweight modality contributions using online phase detectors to emphasize vision in transitions and proprioception during consistent motion; extend to vision-touch-force fusion
- Tools/workflows: lightweight recurrent phase detectors deployed on-robot; runtime feature gating/FiLM reparameterization; safety monitors that enforce vision reliance in high-uncertainty transitions
- Assumptions/dependencies: reliable online transition detection with minimal latency; robustness to sensor noise and real-world disturbances
- Safety-critical domains with strict generalization requirements
- Sectors: healthcare (surgical robots), aerospace/defense, energy infrastructure maintenance
- Use cases: surgical tool handling under occlusions, delicate insertion with small tolerances, inspection/repair tasks with variable contact geometry
- Tools/workflows: GAP-inspired training pipelines plus formal verification/testing targeted at motion transitions; certification testbeds focusing on transition-heavy evaluation
- Assumptions/dependencies: high-fidelity sensing and calibration; rigorous validation and regulatory compliance; extensive expert demonstrations
- Standardization and policy for multimodal robot evaluation
- Sectors: policy/standards bodies, industry consortia
- Use cases: procurement and certification guidelines that include phase-aware OOD tests; benchmarks that report modality robustness and transition performance separately from overall success rate
- Tools/workflows: open test suites implementing intervention experiments, phase metrics (e.g., transition success rate, vision-utilization indices), and OOD distribution shifts
- Assumptions/dependencies: community adoption; consensus on phase definitions/metrics; dataset sharing across vendors
- Foundation VLA training paradigms with adaptive gradient control
- Sectors: software/robotics, AI research
- Use cases: pretraining/fine-tuning generalist policies with phase-aware gradient modulation (vision, proprioception, touch, audio); reduce modality dominance during subtle-cue segments
- Tools/workflows: integrate GAP-like schedules with large-scale multimodal pretraining (e.g., Octo-style architectures); automated hyperparameter search for λ and ρ estimators
- Assumptions/dependencies: large, diverse corpora with accurate timestamps; scalable infrastructure for sample-wise gradient modulation; careful handling of different sensing rates
- Hardware–perception co-design to reduce visual ambiguity in transitions
- Sectors: hardware/sensor vendors, robotics OEMs
- Use cases: camera placement/lighting strategies optimized for transition visibility; end-effector designs that improve observability of critical cues (fiducials, textures)
- Tools/workflows: phase-aware simulation for sensor placement optimization; iterative design loops using transition failure analytics
- Assumptions/dependencies: tight integration between mechanical, electrical, and ML teams; digital twins for design iteration
- Continual and self-improving robots that prioritize transition mistakes
- Sectors: robotics, field operations
- Use cases: robots log and re-train on transition-related failures; on-the-fly adjustment of gradient scaling for rare but critical transition events
- Tools/workflows: continual learning loops with automatic tagging of high-ρ segments and replay prioritization; safe data collection during deployment
- Assumptions/dependencies: mechanisms for safe online learning; robust drift detection; safeguards against catastrophic forgetting
Notes on feasibility:
- GAP is a training-time method with no inference overhead, compatible with common architectures (MLP, diffusion, transformer) and fusion schemes (concatenation, summation, FiLM), and demonstrated on one- and two-arm setups and a VLA model (Octo). Its effectiveness assumes accurate proprioception, synchronized sensing, and tasks with clear motion transitions. Cross-embodiment generalization is not yet established and will require additional research.
Glossary
- Affine Transformation: A linear mapping followed by translation, used to conditionally adjust feature representations. "FiLM applies affine transformations to conditionally adjust features, making it more suitable for tasks requiring modality collaboration."
- Articulated Object Manipulation: Robotic manipulation involving objects with multiple connected parts that move relative to each other. "Our evaluations span multiple policy architectures, including MLP-based, diffusion-based, and transformer-based policies. Further, they cover articulated object manipulation, contact-rich interactions, rotation-sensitive tasks, and soft object manipulation, across both one-arm and dual-arm robotic setups."
- Behavior Cloning (BC): A supervised learning approach that learns policies by imitating expert demonstrations. "The vision-proprioception policy is learned under the Behavior Cloning (BC) paradigm, which can be formulated as the Markov Decision Process (MDP) framework ~\cite{torabi2018behavioral}."
- Cartesian Space: A 3D coordinate system used to represent positions in robotics. "This proprioceptive information consists of the 6D pose of robot's gripper in Cartesian space and orientation, and a continuous value representing the degree of gripper opening, with denoting fully open and denoting fully closed."
- Causal Confusion: Misattribution of causal relationships between inputs and actions during learning. "\cite{octo_2023} suggests it arises from causal confusion between the proprioceptive information and the target actions."
- Change Point Detection (CPD): A method to identify points where statistical properties of a sequence change, used here to segment phases. "To leverage this property for identifying motion-consistent phases, we employ the simple yet effective Change Point Detection (CPD) algorithm~\citep{LIU201372, 2017A}."
- Diffusion Policy: A policy architecture based on diffusion models for action generation. "For experimental results of UNet-based diffusion policies, please refer to Appendix~\ref{sec:diff}."
- Dynamic Fusion: Adaptive combination of multiple sensory modalities over time. "Given this nature of robotic manipulation tasks, recent works have proposed approaches based on dynamic fusion~\cite{pmlr-v205-li23c, he2025foar} and modality selection~\cite{Jiang2025ModalitySA} to improve the performance of multimodal manipulation policies."
- Dynamic Programming: An optimization technique that solves problems by breaking them into subproblems, used to find phase boundaries. "The Change Point Detection algorithm leverages dynamic programming to identify a set of indices that minimize the total cost $\sum_I c_{\tau}_I}$, segmenting the trajectory into motion-consistent phases."
- FiLM: Feature-wise Linear Modulation; a conditioning layer that modulates features using learned affine transformations. "FiLM applies affine transformations to conditionally adjust features, making it more suitable for tasks requiring modality collaboration."
- Gradient Adjustment with Phase-guidance (GAP): An algorithm that modulates proprioceptive gradients during motion transitions to enhance vision-proprioception collaboration. "To alleviate this, we propose the Gradient Adjustment with Phase-guidance (GAP) algorithm that adaptively modulates the optimization of proprioception, enabling dynamic collaboration within the vision-proprioception policy."
- Gradient Descent (GD): An iterative optimization method that updates parameters to minimize loss. "Under Gradient Descent (GD)-based policy learning, the optimization of the vision chunk's parameters is influenced by:"
- Gripper Opening Degree: A scalar value indicating how open the robot gripper is, typically normalized between 0 and 1. "a continuous value representing the degree of gripper opening, with denoting fully open and denoting fully closed."
- Linear Probing: A method to evaluate learned representations by training a simple classifier/regressor on top of frozen features. "The linear-probing experiments that directly evaluate the vision modality are provided in Section~\ref{sec:linear}."
- LSTM: Long Short-Term Memory; a recurrent neural network architecture for modeling temporal dependencies. "we thus employ a temporal network like LSTM to model transition processes."
- Markov Decision Process (MDP): A formal framework for sequential decision-making under uncertainty. "The vision-proprioception policy is learned under the Behavior Cloning (BC) paradigm, which can be formulated as the Markov Decision Process (MDP) framework ~\cite{torabi2018behavioral}."
- Mean Squared Error (MSE): A common loss function measuring the average squared difference between predicted and true values. "In vanilla BC, typically represents the Mean Squared Error (MSE) loss for continuous action spaces, or Cross-Entropy (CE) loss for discrete action spaces."
- Modality Temporality: The phenomenon that the importance of each modality changes over time during task execution. "Extensive prior studies have revealed that the importance of visual and proprioceptive information could change over time within manipulation~\cite{sarlegna2009roles, fengplay, he2025foar}, which referred to as Modality Temporality."
- Motion-Consistent Phases: Periods where robot movement continues in a stable, consistent manner. "Such intervention has minimal impact during \textcolor{mcp}{motion-consistent phases}."
- Motion-Transition Phases: Intervals where robot motion changes and target localization is needed. "It suggests that the vision modality of the vision-proprioception policy fails to take effect during motion-transition phases."
- Out-of-Distribution (OOD): Test scenarios that differ in distribution from the training data. "We further evaluated the generalization of the vision-proprioception policies in out-of-distribution (OOD) scenarios."
- Policy Head: The final network component that maps fused features to action outputs. "These features from two modalities are then concatenated and fed into the policy head ."
- Proprioception: Internal sensing of a robot’s state (e.g., joint positions, gripper pose) enabling precise control. "In recent years, there has been growing interest in introducing proprioception to learning-based manipulation~\cite{levine2016end, cong2022reinforcement, jiang2025robots}."
- R3M: A pretrained model for robust visual representations in robotics. "Specifically, we leverage R3M~\citep{nair2023r3m} to extract universal visual features of this task, and calculate the local entropy of features based on a sliding window covariance, denoted as ."
- Temporal Transformer: A transformer module designed to process sequences over time. "The vision-proprioception policy extracts features from both vision and proprioception modalities using two separate chunks , which consist of an encoder and a temporal transformer, these features are then fused and fed into policy head to predict the action."
- Vision-Language-Action (VLA): Models that integrate visual, linguistic, and action modalities for robotic control. "We further investigate is GAP compatible with Vision-Language-Action (VLA) models."
- Vision-Proprioception Policy: A manipulation policy that jointly uses visual and proprioceptive inputs. "Vision-Proprioception policies perform 15.8\% worse than Vision-only policies."
Collections
Sign up for free to add this paper to one or more collections.