- The paper's main contribution is an agent-driven framework that transforms open-vocabulary prompts into physically robust, simulation-ready 3D scenes using iterative critic feedback.
- It integrates adaptive tool orchestration with visual and physics-based critics, achieving over 99.8% object stability and sub-3% collision rates.
- The framework enables scalable scene augmentation for embodied policy learning by generating diverse demonstration datasets for advanced robotic tasks.
SAGE: An Agentic Framework for Scalable, Simulation-Ready 3D Scene Generation for Embodied AI
Introduction and Context
The "SAGE: Scalable Agentic 3D Scene Generation for Embodied AI" (2602.10116) paper introduces an agent-driven framework designed to address the bottleneck of scalable, high-fidelity, and simulation-ready indoor 3D environments for embodied AI research. The framework achieves open-vocabulary scene generation driven by arbitrary user prompts, with tight integration into physics-based simulators to enable the direct deployment of generated scenes for robotic policy learning.
Current 3D scene generation systems exhibit fundamental limitations: rule-based and pipeline methods lack flexibility and have constrained diversity; data-driven generative approaches are limited by closed taxonomies and sparse 3D data, often failing to ensure physical validity or broad task coverage; LLM/VLM-driven systems and agentic frameworks show progress in open-ended generation, but typically lack explicit simulator-in-the-loop validation, resulting in physically implausible and non-simulation-ready outputs. SAGE addresses these by unifying adaptive tool orchestration and self-improving critic-based feedback with embedded physics validation and large-scale data augmentation.
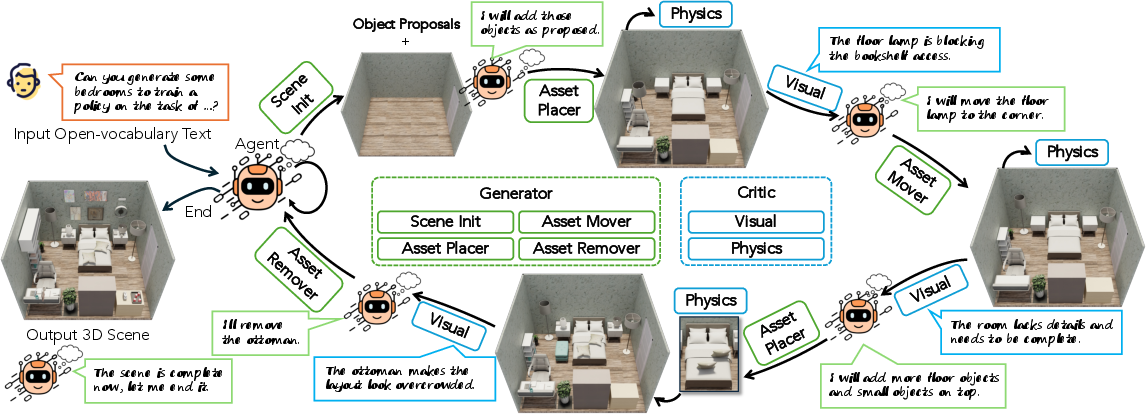
Figure 1: The SAGE framework transforms open-vocabulary prompts into simulation-ready 3D scenes via adaptive tool invocation and iterative critic feedback, supporting scalable generation for embodied AI.
Methodology
Agentic Generation Protocol
SAGE employs a Model Context Protocol (MCP) wherein an agent interacts with a suite of scene generator tools (scene initialization, asset placer, mover, remover) and two critics (visual, physics), each hosted as MCP servers. The agent iteratively constructs and refines the 3D scene, dynamically invoking generators or critics based on current context and multi-view feedback.
- Scene Initializer: Produces an empty 3D room from the given prompt, predicts the object list, assigns estimated physical attributes, and generates textures with MatFuse.
- Asset Placer: Employs text-to-3D (TRELLIS) asset synthesis, LLM-driven placement parsing, VLM-based physical property estimation, and a depth-first search placement planner with collision avoidance.
- Asset Mover/Remover: Supports dynamic modification based on critic guidance.
Adaptive Critic Loop
- Visual Critic: Incorporates multi-view scene images and configuration, leveraging LLM/VLM modules to identify semantic and spatial inconsistencies, missing or ill-placed objects, or stylistic errors, and suggests edits.
- Physics Critic: Integrates Isaac Sim in the scene editing loop, executing physical simulation after every edit and rejecting unstable/colliding configurations, reporting failures, and guiding corrective actions.
This bi-level critic feedback empowers the agent to perform iterative self-correction, achieving plausible and physically robust scenes.
Scalable Scene Augmentation
For embodied AI tasks, SAGE supports systematic multi-level augmentation:
- Object Configuration-Level: Resampling the pose of task-relevant objects.
- Object Category-Level: LLM-based text augmentation and TRELLIS-driven synthesis for appearance and geometry diversity within semantic categories.
- Scene Layout-Level: Regeneration of the background and structural elements, preserving task semantics while supporting wide spatial generalization.
Augmented scenes pass through the physics critic to maintain simulation-readiness.
Action Synthesis and Policy Learning
For tasks like Pick-and-Place and Mobile Manipulation, SAGE automates large-scale demonstration datasets via parallelized motion planning (using M2T2 for grasping and Curobo for IK and collision checking, RRT for navigation). Diffusion Policy models are then trained on RGB-D multi-view streams and generated end-effector trajectories using the Robomimic framework.
Experimental Analysis
Visual and Physical Scene Quality
Quantitative and qualitative evaluations against Holodeck (Yang et al., 2023) and SceneWeaver (Yang et al., 24 Sep 2025) demonstrate SAGE's superior object count, visual realism, semantic completeness, and—most notably—nearly perfect physical stability (>99.8%) with sub-3% collision rates, compared to 50–80% stability and 17–40% collisions for baselines.
(Figure 2)
Figure 2: Scene generation comparison illustrates SAGE's higher object density, visual plausibility, and prompt adherence compared to Holodeck and SceneWeaver.
(Figure 3)
Figure 3: Open-vocabulary generation results from SAGE exhibit strong style control and semantic compliance across diverse prompts, from functional offices to stylized environments.
Ablation confirms that high physical stability and visual quality are only achievable with both critics enabled; omitting either degrades scene fidelity or simulation-compatibility.
Physics Validation
(Figure 4)
Figure 4: Only SAGE maintains object stability post-simulation; baseline outputs exhibit object displacements or toppling, invalidating for downstream robotics.
Dataset and Additional Capabilities
SAGE-10k, a 10k-scene benchmark with 50 room types and 565K unique 3D objects, was released, highlighting the system’s generative scalability. The agentic design enables straightforward extension to multi-room generation, image-conditioned scene synthesis, and articulated object integration.
Impact on Embodied Policy Learning
Scaling curves on Pick-and-Place and Mobile Manipulation demonstrate substantial performance gains with increased scene and demonstration diversity. SAGE-trained policies generalize robustly to previously unseen objects, layouts, and baseline-generated environments, with success rates closely approaching those of privileged planners with full state observability.
(Figure 5)
Figure 5: Policy success rates scale positively with the number of unique demos and objects; SAGE-produced data yields faster convergence and better generalization than baseline data.
Implications and Future Directions
SAGE establishes a new paradigm for 3D scene generation: agentic, critic-driven, simulator-validated, and inherently scalable for real-world robotics and embodied AI. Unlike prior models, every scene is both semantically rich and physically certified, ensuring reliable deployment in policy learning loops.
The agent-based critic framework is modular, allowing future augmentation with richer LLMs/VLMs, advanced physics engines (for deformables or contact fidelity), and additional generative modalities, supporting tasks beyond the pick-place-navigation axis (e.g., tool use, articulated objects). SAGE’s scalable generation loop, coupled with action synthesis, can power online RL and real-to-sim transfer at unprecedented scale.
Additionally, the released SAGE-10k corpus provides a foundation for benchmarking future advances in embodied scene generation and autonomous robot training.
Conclusion
SAGE provides a robust, scalable framework for generating simulation-ready, semantically grounded 3D environments directly from arbitrary user prompts. Its agentic, critic-driven workflow yields state-of-the-art results in both visual plausibility and physical stability, enabling the seamless transition from open vocabulary descriptions to deployable environments for embodied policy learning. The unified framework and public dataset catalyze both theoretical and applied advances in AI-driven scene synthesis and scalable robot learning (2602.10116).