- The paper presents a novel task-to-scene generation framework integrating large-scale datasets, LLM-based spatial reasoning, and DPO training.
- The methodology employs object list completion, interrelation inference, and scene graph construction to ensure realism and semantic alignment.
- The approach outperforms baselines with metrics like FID=40.3 and ~99% success rate, demonstrating strong generalization and practicality.
Task-Driven Tabletop Scene Generation via 3D Spatial Reasoning: MesaTask
Introduction and Motivation
MesaTask addresses the challenge of generating physically plausible, task-oriented 3D tabletop scenes directly from high-level human instructions. The motivation stems from the need for robust training environments for robotic manipulation, where traditional manual or randomized scene construction methods are insufficient in terms of diversity, realism, and alignment with task semantics. The paper introduces a new formulation—task-to-scene generation—requiring the synthesis of interactive, realistic tabletop layouts that satisfy complex spatial and semantic constraints derived from abstract task descriptions.
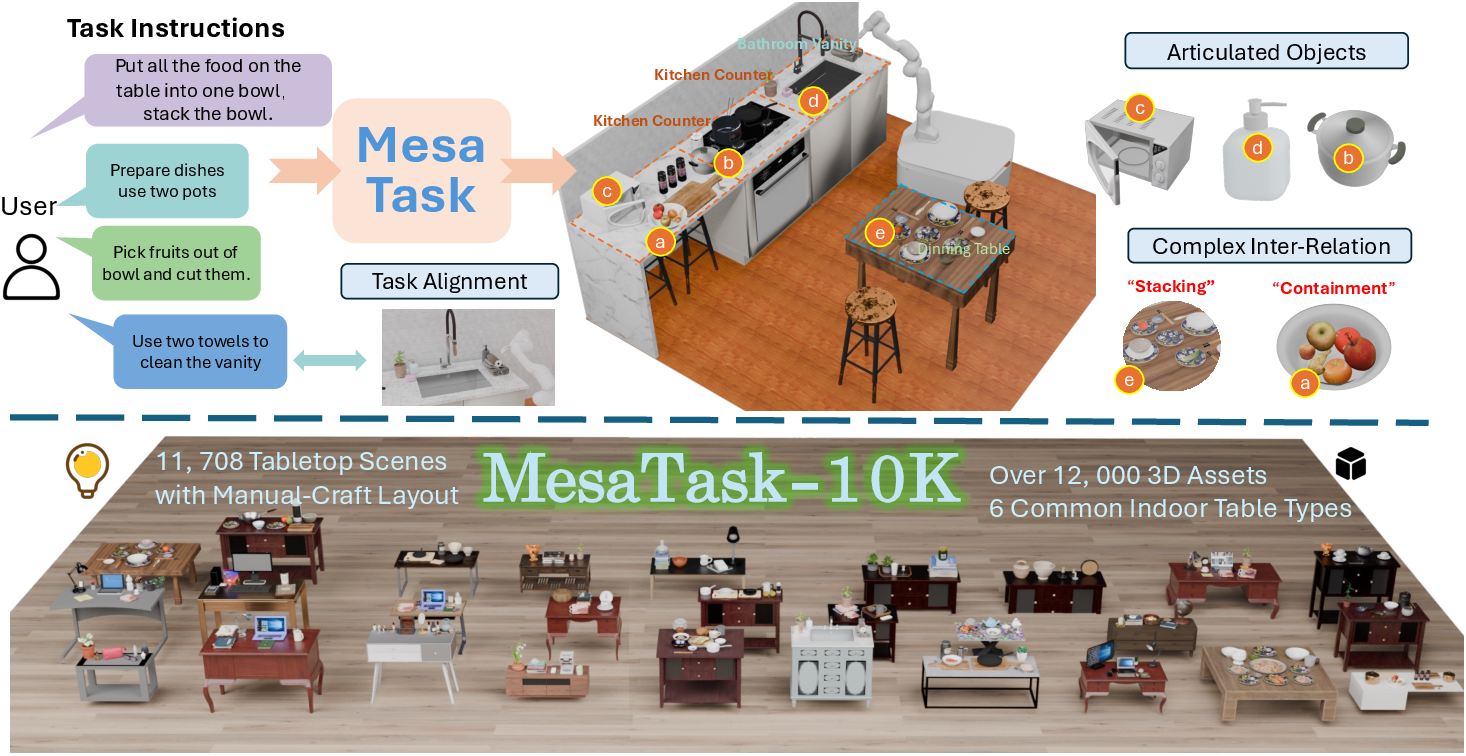
Figure 1: MesaTask generates task-driven 3D tabletop scenes from high-level instructions, leveraging a large-scale dataset and spatial reasoning.
MesaTask-10K Dataset Construction
MesaTask-10K is a large-scale dataset comprising over 10,700 manually refined tabletop scenes, each constructed to ensure realistic object layouts and intricate inter-object relations. The dataset spans six common indoor table types and utilizes a curated library of 12,000+ 3D assets with rich semantic annotations.
The construction pipeline integrates LLMs for scene description generation, text-to-image models for reference image synthesis, and multimodal models for object detection and semantic labeling. Depth estimation and instance segmentation are used to build coarse 3D layouts, which are then refined by expert annotators in Blender to correct occlusions, scale inaccuracies, and spatial implausibilities. Final scenes are validated in IsaacSim to ensure physical plausibility.

Figure 2: MesaTask-10K dataset pipeline: LLM-driven scene description, image synthesis, 3D layout construction, and human refinement.
The dataset features high object diversity (200+ categories), with an average of 15 objects per scene. The top 100 object categories are visualized to demonstrate coverage and frequency.
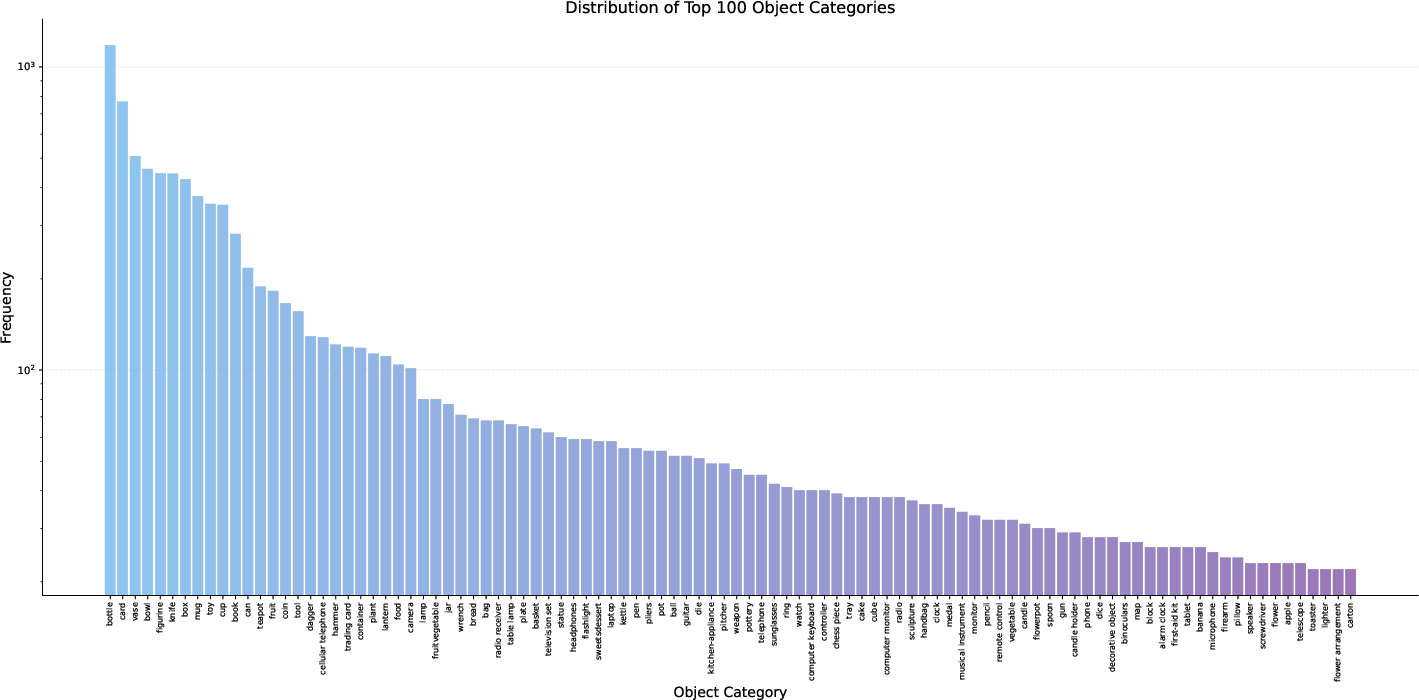
Figure 3: Distribution of the top 100 object categories in MesaTask-10K.
MesaTask Framework: LLM-Based 3D Scene Generation
MesaTask is an LLM-based framework that operationalizes task-to-scene generation through a structured spatial reasoning chain. The process decomposes the mapping from task instructions to 3D layouts into three stages:
- Object List Completion: Infers a comprehensive set of objects required for the task, extending beyond those explicitly mentioned.
- Interrelation Inference: Predicts spatial and functional relationships (e.g., stacking, containment, adjacency) among objects.
- Scene Graph Construction: Builds a structured graph encoding object attributes, positions, orientations (quantized into 8 bins), and interrelations, which guides the final 3D layout synthesis.
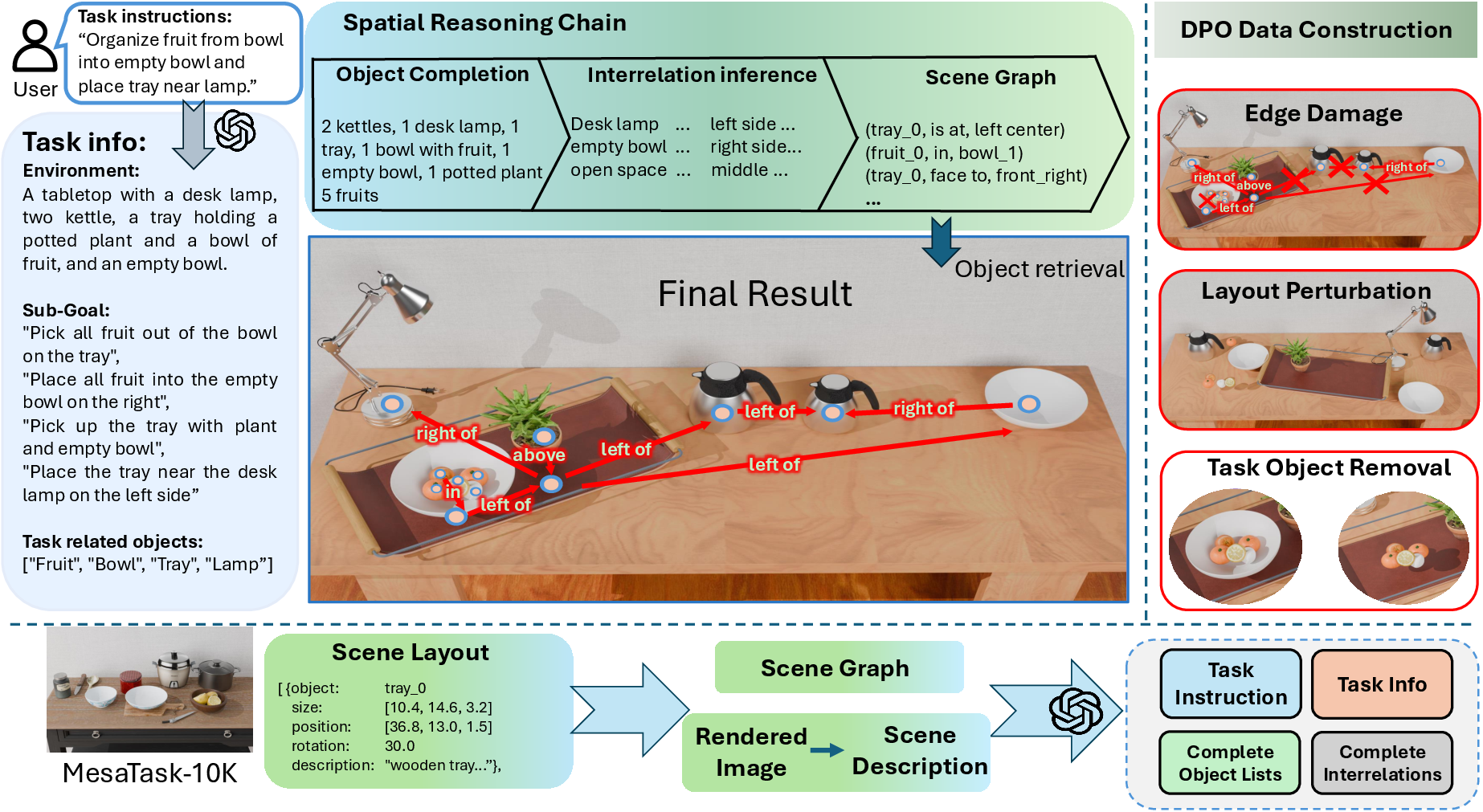
Figure 4: MesaTask framework overview: task-to-scene generation, reasoning data construction, and DPO data construction.
The framework leverages multimodal LLMs for reasoning data construction, generating detailed task information, object lists, and interrelations from scene graphs and rendered images. For training, MesaTask employs supervised fine-tuning (SFT) on reasoning data, followed by Direct Preference Optimization (DPO) to mitigate common failure modes such as object collisions, misaligned relations, and omission of task-relevant objects. DPO training utilizes paired positive (high-quality) and negative (corrupted) layouts to optimize the LLM's policy for scene generation.
Experimental Evaluation
MesaTask is evaluated against closed-source LLMs (GPT-4o) and modular scene generation baselines (Holodeck-table, I-Design-table). Metrics include Fréchet Inception Distance (FID) for realism, success rate for output format correctness, and a multi-dimensional GPT-score assessing task consistency, object size reasonableness, placement plausibility, layout coherence, and object visibility.
MesaTask achieves the highest performance across all metrics, with FID = 40.3, success rate ≈ 99%, and GPT-score avg. = 8.25, outperforming all baselines. The spatial reasoning chain and DPO training yield measurable improvements in scene plausibility and task alignment.
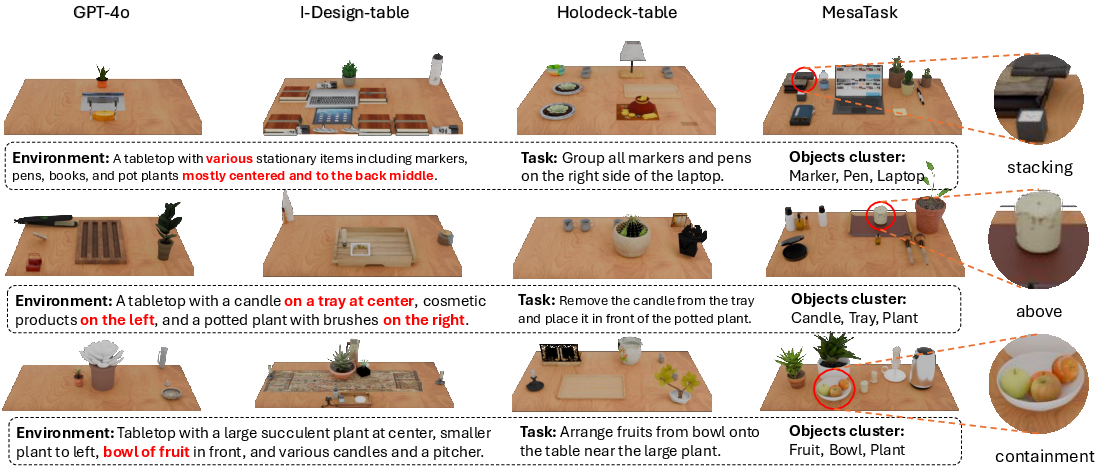
Figure 5: Qualitative comparison: MesaTask exhibits superior realism, alignment, and modeling of complex inter-object relations compared to baselines.
Ablation studies confirm the necessity of both spatial reasoning and DPO; removing either degrades collision rates, object fidelity, and task alignment.

Figure 6: Ablation study: DPO training reduces collision rate, increases object fidelity, and improves task alignment.
Generalization and Robustness
MesaTask demonstrates strong generalization to novel tabletop categories not present in the training set (e.g., nightstands, TV stands, cashier counters), maintaining high success rates and GPT-scores. The framework can synthesize scenes with objects and layouts outside the training distribution, leveraging the LLM's open-vocabulary capabilities.

Figure 7: MesaTask generates realistic scenes for novel tabletop categories, demonstrating generalization beyond training data.
Benchmarking and Comparative Analysis
MesaTask-10K serves as a benchmark for scene generation methods. Comparative experiments with ATISS, DiffuScene, and PhyScene (trained on MesaTask-10K) reveal trade-offs between visual quality and semantic alignment. MesaTask differs fundamentally by generating scenes from task instructions rather than static scene descriptions, enabling open-vocabulary synthesis and superior task-scene alignment.
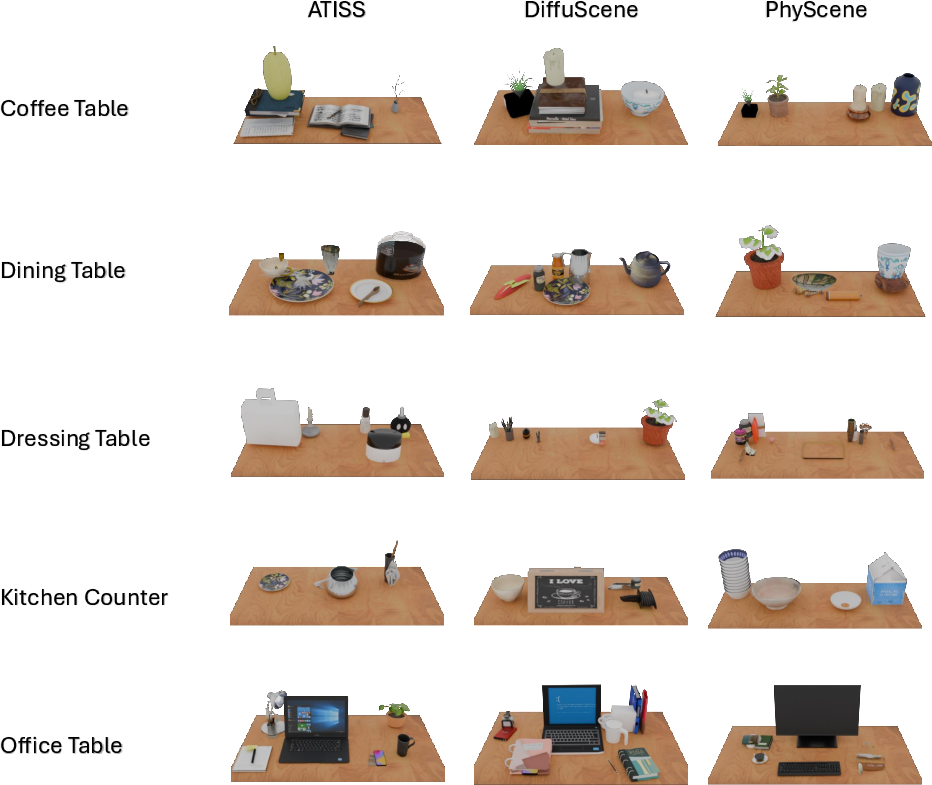
Figure 8: Qualitative results of ATISS, DiffuScene, and PhyScene trained on MesaTask-10K.
Implementation Details
MesaTask is implemented using Qwen3-8b as the base LLM, with full-parameter fine-tuning on 8 A800 GPUs. The asset retrieval process combines SBERT-based text similarity and cosine size similarity, with empirically weighted scoring. Scene graph extraction employs geometric rules for spatial relations, orientation quantization, and grid-based positional encoding. DPO training uses three corruption strategies: geometric perturbation, scene graph corruption, and object removal.
Limitations and Future Directions
MesaTask currently focuses on six indoor table types and relies on 3D object retrieval, limiting diversity to the asset database. Future work will integrate 3D object generation conditioned on bounding boxes to expand object diversity and realism. Extending to broader table types and more complex manipulation tasks is a natural progression.
Conclusion
MesaTask establishes a new paradigm for task-driven 3D tabletop scene generation, combining large-scale dataset construction, structured spatial reasoning, and LLM-based synthesis. The framework achieves state-of-the-art performance in generating physically plausible, semantically aligned scenes from abstract task instructions, with robust generalization and extensibility. MesaTask-10K provides a valuable benchmark for future research in embodied AI, scene synthesis, and robotic policy learning.

Figure 9: Additional qualitative comparisons of task-conditioned scene generation across GPT-4o, I-Design-table, Holodeck-table, and MesaTask.

Figure 10: Additional qualitative results generated by MesaTask, illustrating diverse task-driven scene layouts.

Figure 11: MesaTask qualitative results (continued), showing complex spatial arrangements and inter-object relations.

Figure 12: MesaTask qualitative results (continued), further demonstrating scene diversity and realism.