- The paper introduces the Vision Transformer (ViT) that replaces CNNs with a Transformer-based approach by processing 16x16 image patches.
- It demonstrates state-of-the-art accuracy, achieving 88.55% on ImageNet and 94.55% on CIFAR-100 after extensive pre-training.
- The study highlights how self-attention mechanisms in ViT enhance computational efficiency and scale image recognition tasks effectively.
Introduction
The paper "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" introduces the Vision Transformer (ViT), a novel approach to image recognition that leverages the Transformer architecture, traditionally successful in NLP, for computer vision tasks. This approach bypasses convolutional networks entirely, relying on self-attention mechanisms applied to patches of images to perform classification tasks.
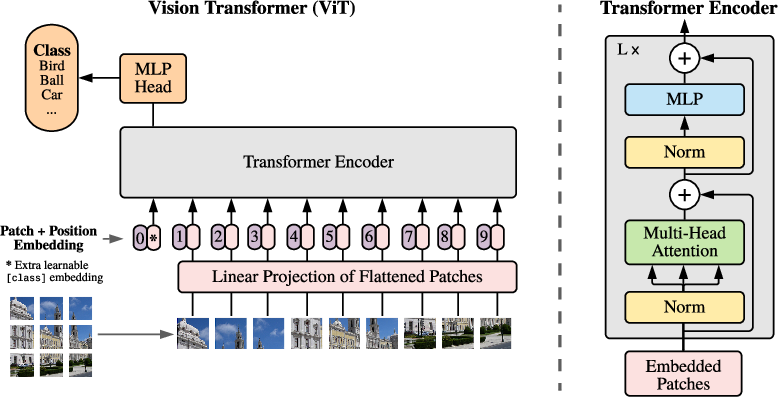
Figure 1: Model overview - splitting an image into fixed-size patches and processing them using a Transformer encoder.
Methodology
Model Architecture
ViT treats images as sequences of flattened patches fed into a Transformer model, resembling its application in NLP. The architecture consists of:
- Image Patching: Images are split into non-overlapping patches of size 16x16 pixels.
- Linear Embedding: Each patch is flattened and linearly embedded into a constant vector size D.
- Sequence Formation: A learnable classification token is prepended, and positional embeddings are added to retain spatial information.
- Transformer Encoder: A standard Transformer encoder processes the sequence, leveraging multi-head self-attention and feedforward layers.
This architecture is depicted in (Figure 1), providing a straightforward yet scalable model design.
Training and Fine-tuning
ViT models require extensive pre-training on large datasets such as ImageNet-21k or JFT-300M. The tasks are then fine-tuned to smaller datasets, showing impressive transfer capabilities. Fine-tuning often involves increasing the resolution, thereby increasing the input sequence length managed by 2D interpolation of position embeddings.
Experimental Results
ViT proves competitive, achieving strong results on multiple datasets. For instance, ViT achieves an 88.55% accuracy on ImageNet and 94.55% on CIFAR-100 when pre-trained on JFT-300M. These results affirm the potential of Transformers in vision when coupled with sufficient pre-training data.
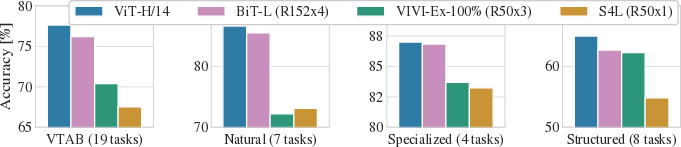
Figure 2: Breakdown of VTAB performance across Natural, Specialized, and Structured task groups.
The Transformer-based approach also scales favorably with increased data size, outperforming equivalent CNN-based models and demonstrating significant gains in computational efficiency (Figure 2).
Attention Insights
An important aspect investigated is how ViT utilizes attention. Analysis reveals that initial layers tend to focus on local patterns, with deeper layers attending to broader image contexts. This flexibility allows ViT to arguably leverage global image context more effectively than traditional CNNs.

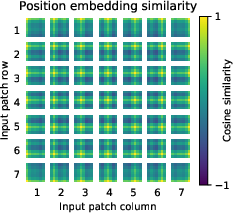
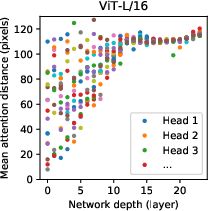
Figure 3: Initial linear embedding and attention distance analysis show the adaptability and extensive reach of ViT’s attention mechanisms.
Self-Supervision
Preliminary attempts at self-supervised learning with ViT showed promise but trailed behind supervised methods, suggesting further exploration is needed to fully harness self-supervised pre-training in vision domains.
Conclusion
ViT showcases the potential to apply Transformer architectures to computer vision tasks, achieving state-of-the-art performance with reduced training costs compared to CNNs. The research opens a pathway for further exploration into applying Transformers across varied vision tasks like object detection and segmentation, particularly with refined self-supervised learning strategies. Future developments should consider scaling up not just the models but optimally leveraging pre-training across diverse datasets for maximal gains.