Data Kernel Perspective Space Performance Guarantees for Synthetic Data from Transformer Models
Abstract: Scarcity of labeled training data remains the long pole in the tent for building performant language technology and generative AI models. Transformer models -- particularly LLMs -- are increasingly being used to mitigate the data scarcity problem via synthetic data generation. However, because the models are black boxes, the properties of the synthetic data are difficult to predict. In practice it is common for language technology engineers to 'fiddle' with the LLM temperature setting and hope that what comes out the other end improves the downstream model. Faced with this uncertainty, here we propose Data Kernel Perspective Space (DKPS) to provide the foundation for mathematical analysis yielding concrete statistical guarantees for the quality of the outputs of transformer models. We first show the mathematical derivation of DKPS and how it provides performance guarantees. Next we show how DKPS performance guarantees can elucidate performance of a downstream task, such as neural machine translation models or LLMs trained using Contrastive Preference Optimization (CPO). Limitations of the current work and future research are also discussed.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces a simple, math-based way to check the quality of “synthetic data” made by modern AI text models (like LLMs, LLMs). Synthetic data means extra examples created by a model to boost training, especially when real labeled data are scarce. The authors propose a tool called Data Kernel Perspective Space (DKPS). DKPS builds a “map” that helps compare black‑box models and gives statistical guarantees about how stable their outputs are. They show how this helps in machine translation (English→Zulu) and in a training method called Contrastive Preference Optimization (CPO).
The main questions the paper asks
- How can we measure and compare the behavior of black‑box AI models (like LLMs) without seeing their inner workings?
- Can we put guarantees on how much a model’s outputs will vary for a given input?
- When using synthetic data, which choices (like temperature settings, batched vs. repeated queries, in‑sample vs. out‑of‑sample data) make translations more accurate and more stable?
- How does a preference‑based training method (CPO) change bias and variance in model outputs?
How the methods work (in everyday language)
Think of each model as a student, and each input question as a test problem. When you ask the same question multiple times, a model might give slightly different answers (because of randomness, temperature, or sampling). The authors:
- Turn text into numbers: They use a sentence embedding tool (LASER3) to represent each sentence as a point in a high‑dimensional space. You can think of this like placing each sentence at a coordinate on a very large map.
- Shrink the map: Because the map is huge, they use PCA (a common technique) to reduce it to just a few important directions. Imagine looking at the landscape from above and keeping only the most important axes.
- Measure bias and variance:
- Bias: How far, on average, the model’s output is from the human (gold) translation. Think of darts landing consistently off‑center—accurate aim would be low bias.
- Variance: How spread out the outputs are when you ask multiple times. Darts scattered widely have high variance.
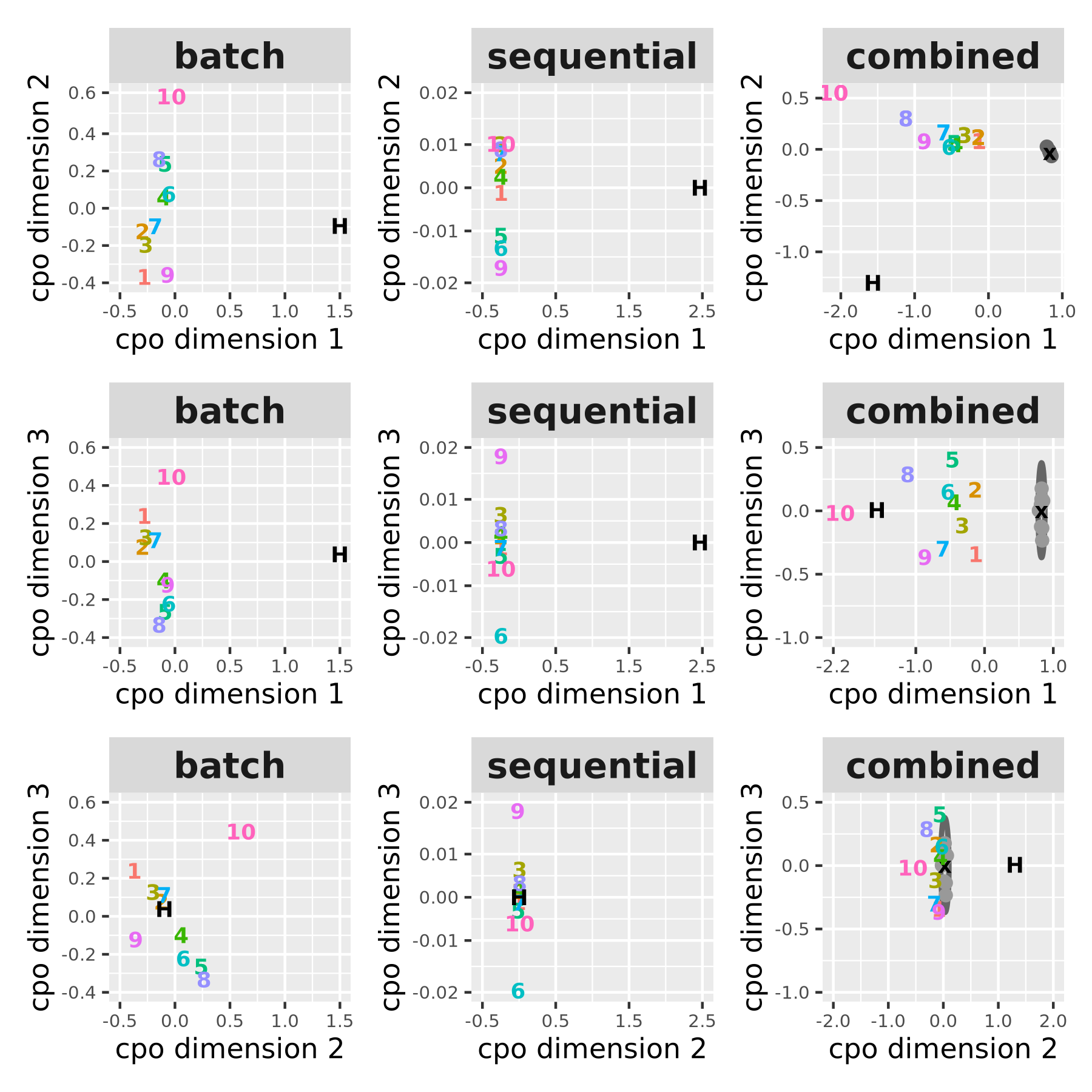
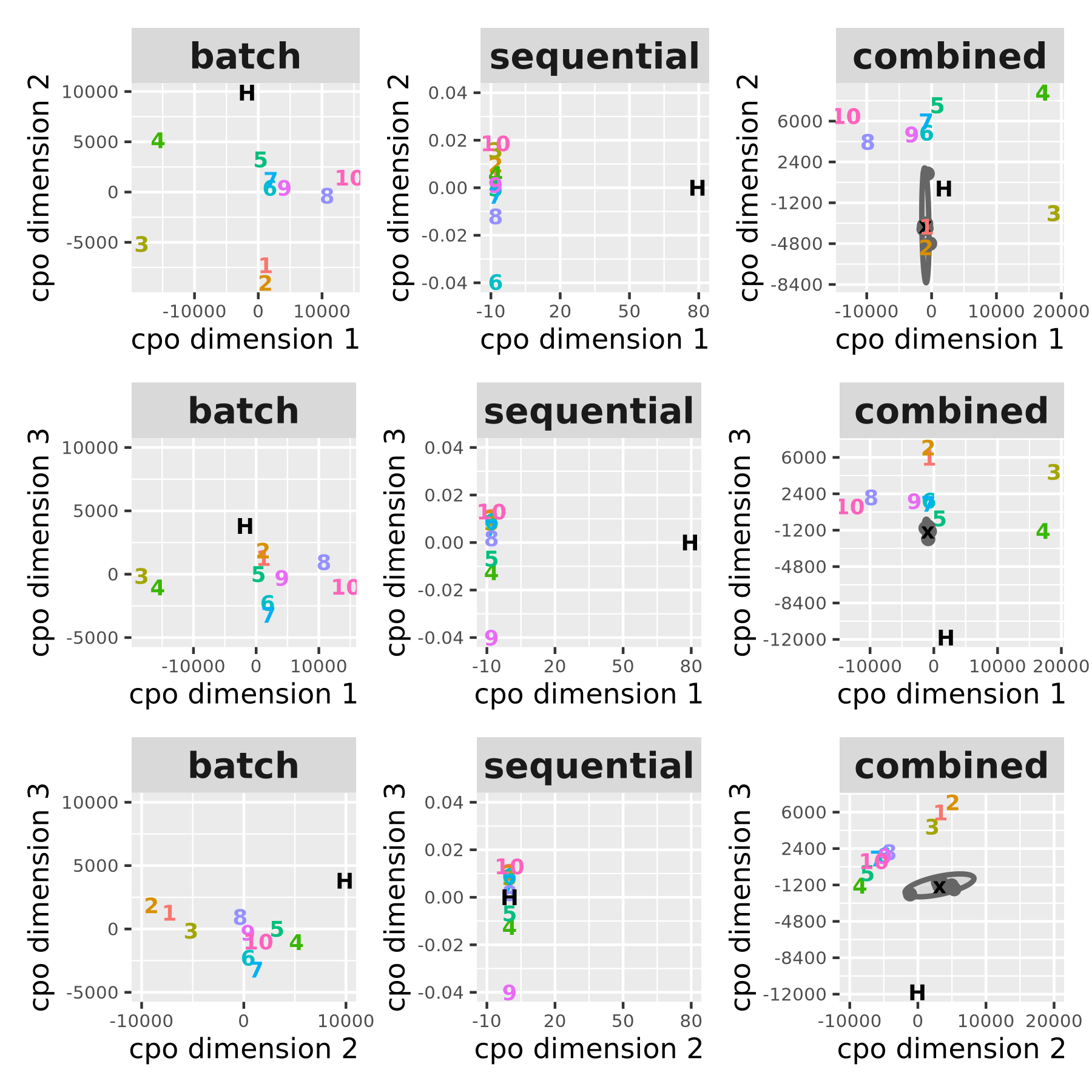
- Build a shared “model map” (DKPS): For a set of questions, they compute how different the models’ average answers are from each other, then use MDS (Multidimensional Scaling) to place all models as points on a low‑dimensional map. If two models behave similarly across many questions, they end up close together. This gives a clear picture of which models are similar, which are different, and along which “directions” they differ (e.g., bias vs. variability).
- Compare different settings:
- Temperature: A knob that makes the model more “creative” (higher temperature → more varied answers).
- Sequential vs. batch:
- Sequential: Ask the same question multiple times and take the best result each time (10 separate tries).
- Batch: Ask once and take the model’s top 10 ranked answers.
- In‑sample vs. out‑of‑sample (OOS): In‑sample questions look like what the model was trained on; OOS are new and different.
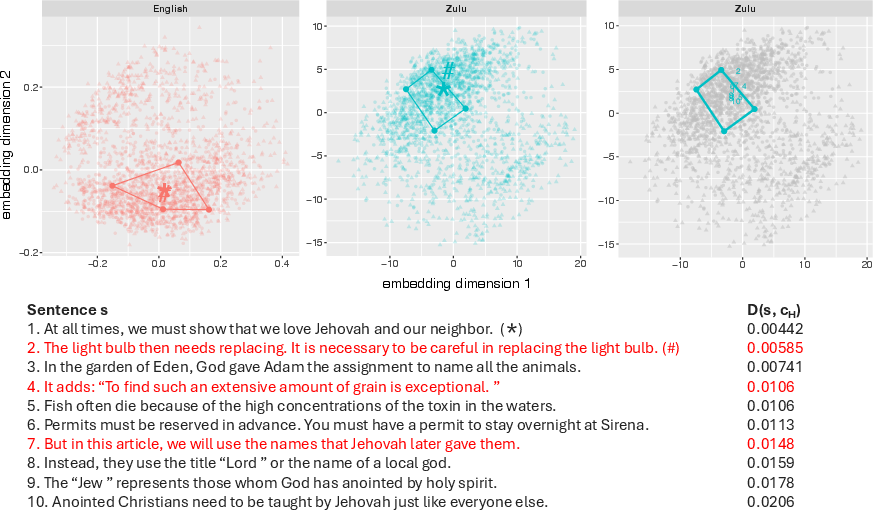
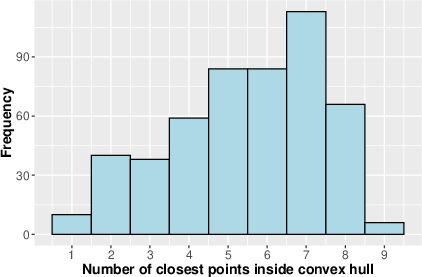
- Simple geometry check: They use a “rubber band” idea (convex hull). Wrap a rubber band around a small set of known English sentences on the map, and around their Zulu translations. If an OOS English sentence lies inside the English rubber band, you’d hope its (synthetic) Zulu translation lies inside the Zulu rubber band too. This tests whether translation roughly preserves relationships between sentences.
- Preference training (CPO): They also study a training method that learns from pairs (a preferred and a less‑preferred output). They use DKPS plus a distance that accounts for spread (Mahalanobis distance) to see how CPO changes bias and variance.
What they found and why it matters
Here are the main results, explained simply:
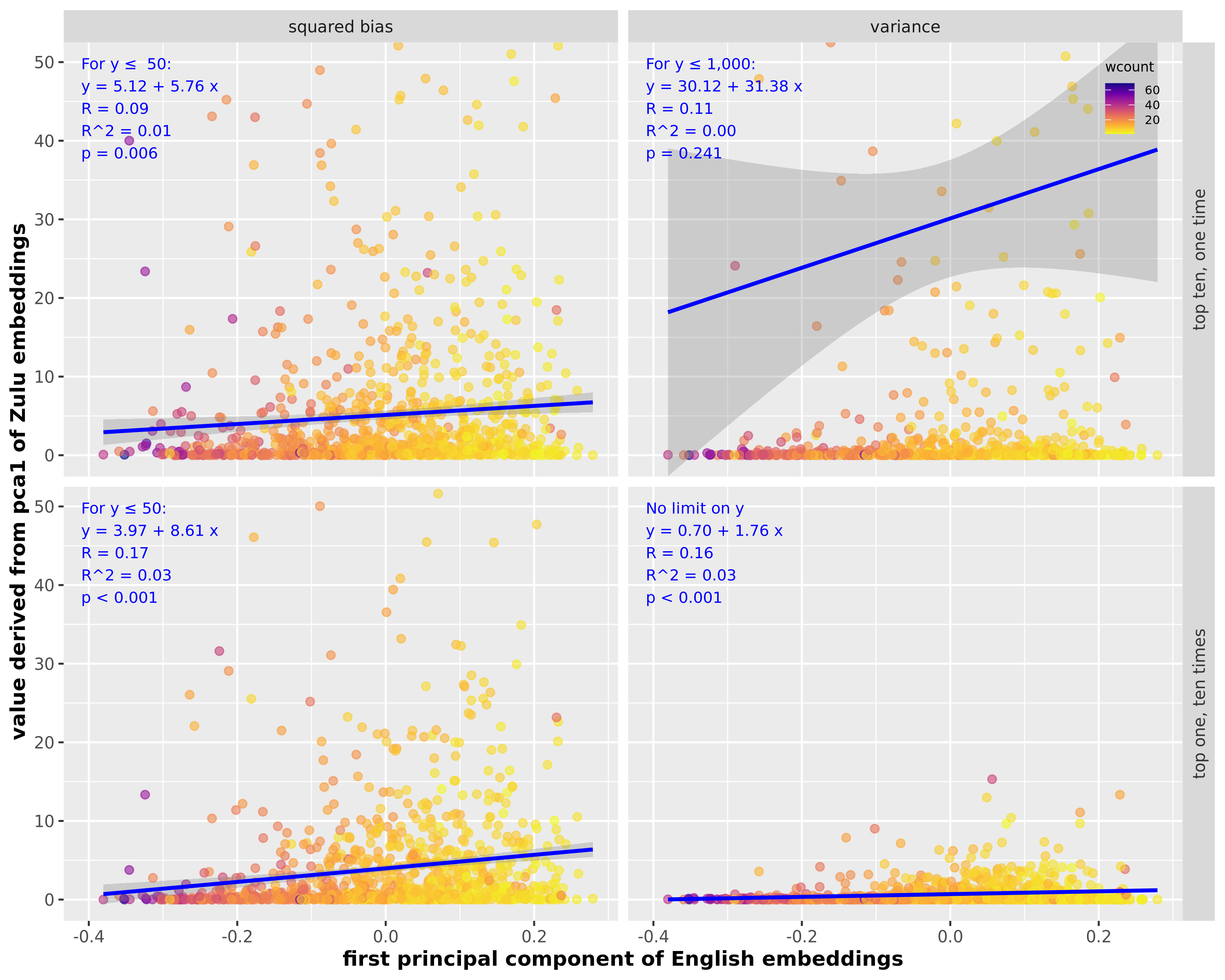
- Temperature and sentence length shape variability:
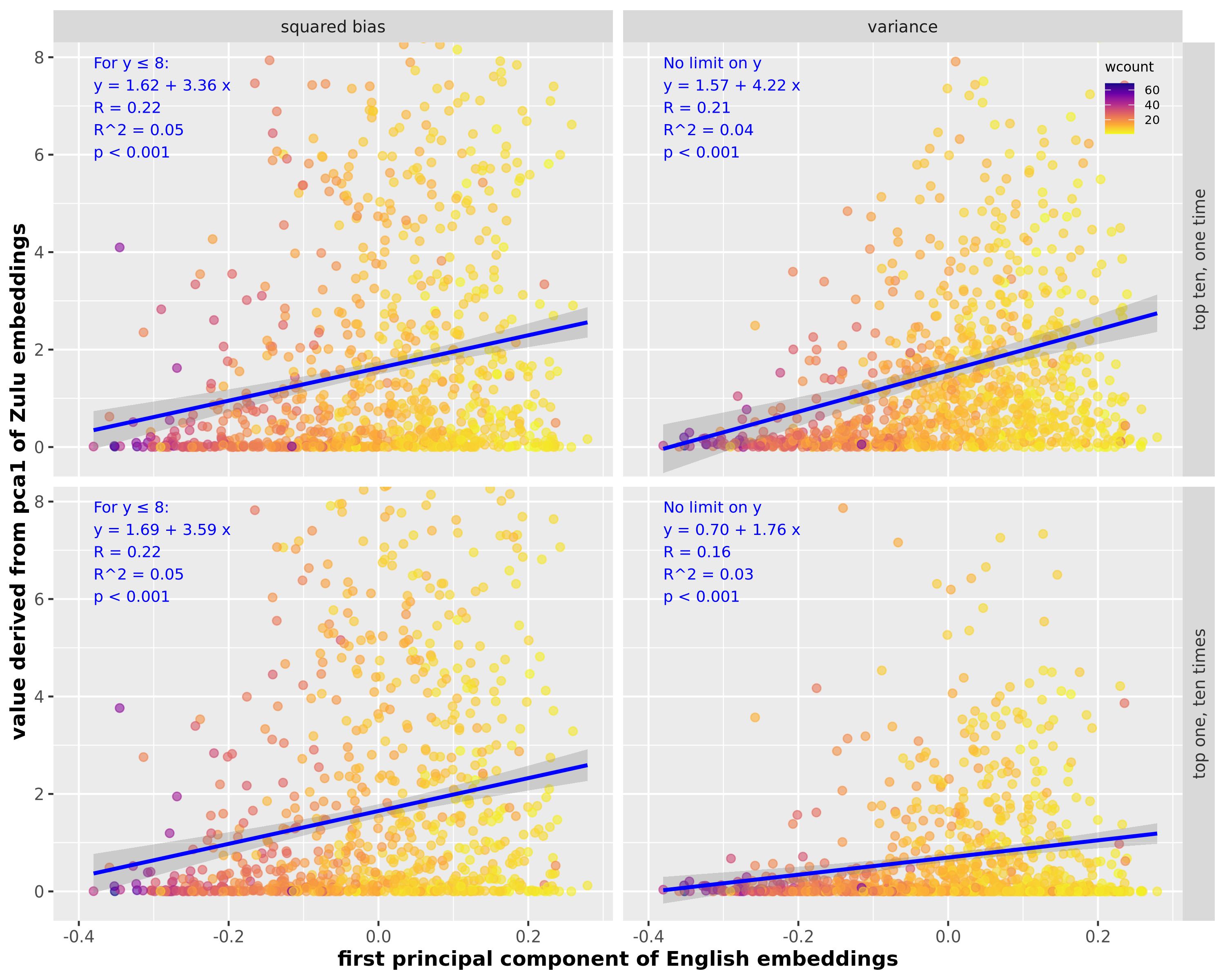
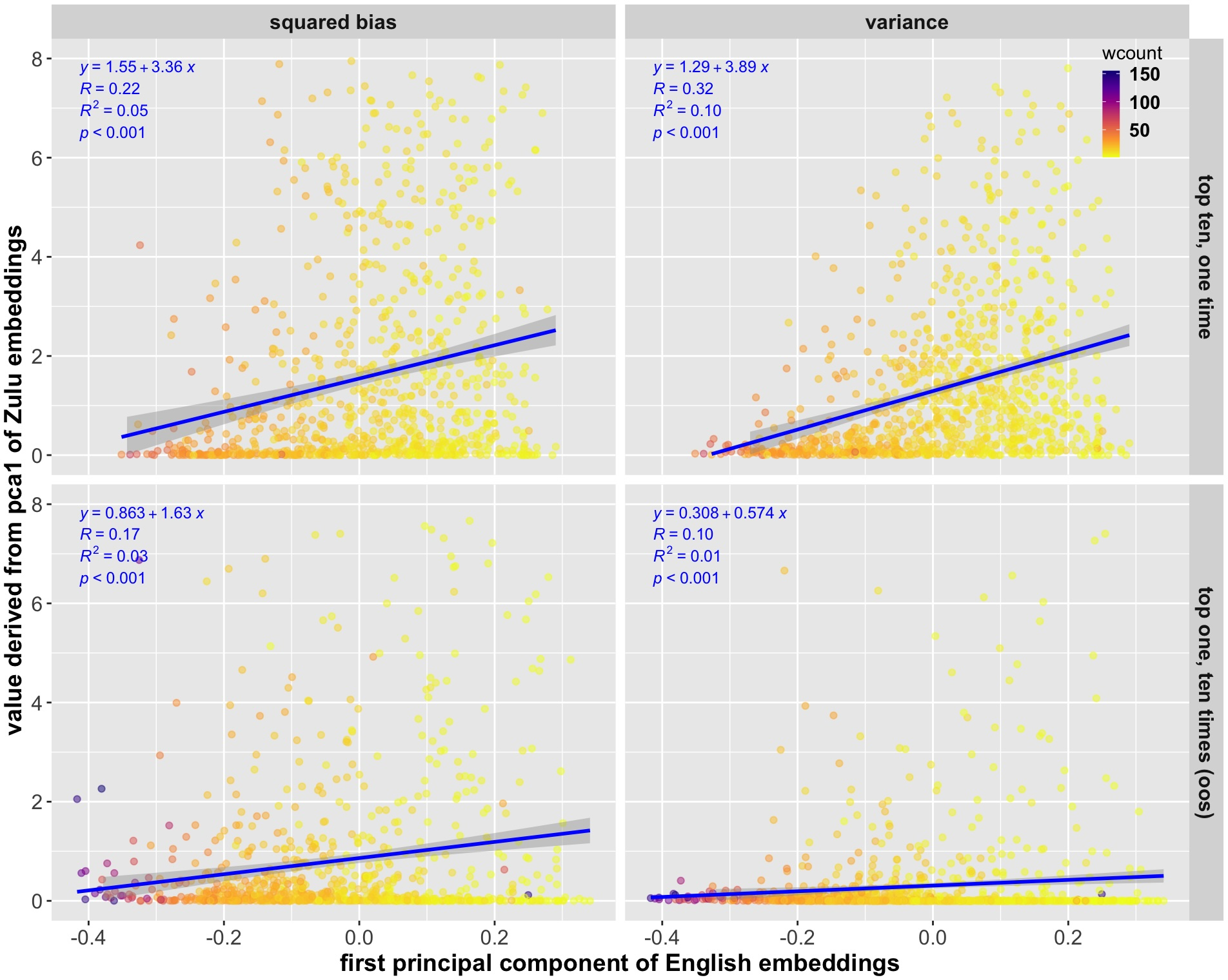
- Higher temperature increases variance (answers vary more).
- Shorter sentences tend to have higher bias and variance; longer sentences are more stable.
- Batch vs. sequential translations:
- Batched top‑10 answers are more variable than 10 separate tries, but not necessarily more biased. In other words, batch increases spread without pushing the average further from human translations.
- DKPS reveals structure: in the “model map,” the first direction often captures bias, while the next directions capture variance. Batched outputs show more spread across multiple directions.
- In‑sample vs. out‑of‑sample:
- In their data, OOS translations often had lower variance—largely because those sentences were longer and training included heuristics that reduce overfitting. This highlights how data composition (like sentence length) affects stability.
- Geometry is partly preserved:
- If an English sentence is close to a known cluster, its Zulu translation often falls in the expected region too. It’s not perfect, but the embedding→translation→embedding pipeline roughly preserves relationships between sentences. This supports smarter selection of synthetic data: pick English sentences whose translations will likely land in “safe” regions.
- Mixing data can help—or contaminate:
- Combining different sets (e.g., in‑sample and OOS) can “de‑bias” the map in some directions and reduce variability, but it can also let the high variance from worse outputs “bleed into” better ones if you’re not careful.
- CPO effects:
- With CPO, the preferred (better) outputs become less variable, while the dispreferred (worse) outputs become more variable—consistent with a tradeoff that emphasizes clear preferences.
- DKPS shows that mixing preferred and dispreferred data can increase the apparent bias/variance of the preferred side if not handled carefully.
Why this matters: Engineers often “fiddle” with settings like temperature or just hope synthetic data helps. DKPS gives a principled way to measure and compare models and settings, even when the model is a black box. It helps predict when synthetic data will help, when it might hurt, and how to select it more safely.
What this could change going forward
- Smarter synthetic data use: DKPS can guide choices about temperature, which sentences to generate, and whether to use batch or sequential outputs—before training a downstream model.
- Better guarantees: Because DKPS compares model behavior across many queries and summarizes it with math, it can provide upper bounds on variability and help ensure quality.
- Safer mixing of data: The “rubber band” test and DKPS maps can help screen synthetic samples that are likely to fit well with human data and avoid samples that distort the training set.
- Broad applicability: Although shown on English→Zulu translation, the approach should carry over to other language tasks (summarization, retrieval, QA) and other training strategies like CPO.
In short
The paper gives a practical, visual, and math‑backed way (DKPS) to understand and control the quality of synthetic data from black‑box AI models. It shows how to spot and balance bias vs. variance, how different generation strategies compare, and how to reduce risk when adding synthetic examples—so future models can be trained more reliably, especially in low‑resource settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Formalize DKPS “performance guarantees”: derive finite-sample concentration bounds and consistency rates for the DKPS embedding (MDS of D) as a function of number of queries m, replicates r, embedding dimension p, and target DKPS dimension d; quantify sample complexity needed for reliable estimation.
- Provide an explicit upper bound on output variance as claimed: specify conditions (e.g., model class, decoding strategy, temperature) under which DKPS yields provable bounds on output dispersion, and validate these bounds empirically.
- Sensitivity to embedding choice g: evaluate DKPS robustness across multilingual sentence encoders (LASER3, LaBSE, mUSE, e5, multilingual BERT, etc.), and quantify how embedding drift or encoder quality affects bias/variance estimates and DKPS geometry.
- Dimension reduction dependence: move beyond PCA; compare linear vs nonlinear or local methods (e.g., kernel PCA, UMAP, t-SNE, Isomap), and develop criteria for optimal dimension selection that balance sample size t, embedding noise, and interpretability.
- Link DKPS geometry to task performance: establish correlations (and causal links) between DKPS distances/bias/variance and downstream MT metrics (BLEU, COMET, chrF) and human judgment; quantify whether DKPS-informed selection actually improves MT model accuracy.
- Query set design: study how the choice of queries {q_i} affects DKPS positions; develop principled query selection strategies (coverage, diversity, active probing) to ensure stable model comparison and generalization to new domains.
- Decoding strategy modeling: explicitly model dependence in batched top-k/beam outputs, assess independence assumptions in sequential sampling, and analyze how decoding strategy (beam width, nucleus/top-p, top-k, temperature T) changes DKPS structure and output variance.
- Temperature–variance relationship: empirically and theoretically characterize how T controls output variability in DKPS, including non-monotonic regimes and task dependence; provide calibration procedures to target desired variance ranges.
- Finite-sample limitations: quantify the impact of low replicate counts (t=10; r=1 in batch) on estimation of μ and Σ; propose variance-stabilized estimators or shrinkage/regularization strategies for DKPS when r is small.
- Multi-model evaluation: extend DKPS beyond one MT system to multiple transformer models (e.g., GPT-family, Mistral, NLLB, Marian) to demonstrate cross-model comparability without access to weights; test whether DKPS separates models in a task-meaningful way.
- Geometry preservation test rigor: replace ad hoc convex-hull checks with rigorous geometric preservation tests (e.g., Procrustes analysis, manifold alignment) and quantify preservation fidelity across domains and languages with statistical power analyses.
- Domain shift control: disentangle sentence length and topical content confounds in in-sample vs out-of-sample comparisons (e.g., religious content near hull center); design controlled OOS sets to isolate geometric effects from domain/content variables.
- Actionable synthetic-data selection: operationalize DKPS for data curation (e.g., convex-hull filtering, margin-based selection, uncertainty thresholds); evaluate whether DKPS-filtered synthetic pairs improve training via back-translation in low-resource MT.
- CPO modeling assumptions: relax the assumption that preference labels z are known; move from Gaussian-mixture toy modeling to actual CPO training with pairwise preferences; compare DKPS effects pre/post CPO and measure real gains in MT quality.
- Bias–variance contamination in mixed training: quantify the “contamination” effect when mixing preferred and dispreferred synthetic data; develop mitigation strategies (reweighting, curriculum, DKPS-guided sampling) and test their efficacy.
- Choice of distance metric: systematically compare Euclidean, cosine, Mahalanobis, and task-aware distances (e.g., BERTScore-based, COMET-space) for DKPS; analyze sensitivity and propose metric selection criteria based on covariance structure and task.
- Handling missing outputs and failures: develop DKPS procedures that gracefully accommodate missing translations/outliers (e.g., robust MDS, imputation, influence diagnostics) and assess their effects on guarantees.
- Reproducibility: provide code, decoding settings (beam size, sampling parameters), data splits, and hyperparameters for DKPS and CPO experiments; include ablations on p, d, m, r to enable replication and sensitivity analysis.
- LASER3 suitability for Zulu: validate the appropriateness of LASER3 for low-resource Bantu languages; assess encoder error rates and the impact of encoder bias on the derived DKPS statistics.
- From DKPS to training objectives: investigate integrating DKPS directly into loss functions (e.g., DKPS-regularized CPO/DPO) to encourage geometrically stable outputs; evaluate whether such regularization reduces variance without inflating bias.
- Theoretical definition and “kernel” role: clarify the “kernel” in DKPS (currently using distance-based MDS); explore kernelized DKPS (e.g., kernel MDS, HSIC-based summaries) and establish when kernel choices improve model discrimination.
- Out-of-sample DKPS validation: perform holdout-based validation to assess DKPS stability across different query subsets and domains; provide confidence intervals for DKPS coordinates and model separations.
- Cross-task generalization: test DKPS beyond MT (ASR, QA, summarization, IR) and across language families; identify task-specific adaptations needed for DKPS guarantees to hold.
- Practical debiasing procedures: replace heuristic sentence-length debiasing with explicit models (e.g., regression on length and content features) and demonstrate reductions in DKPS-estimated bias/variance with downstream performance gains.
Practical Applications
Below is a concise mapping of the paper’s contributions (DKPS formalism, bias/variance characterization, convex-hull geometry checks, and CPO analysis) to practical, real-world applications. Items are grouped by deployment horizon and include sectors, likely tools/workflows, and key assumptions/dependencies.
Immediate Applications
These can be deployed with current tooling (embeddings, PCA/MDS, standard LLM APIs) and the methods demonstrated in the paper.
- Synthetic-data quality assurance (QA) and gating for LLM pipelines
- What to do: Before ingesting synthetic data, compute DKPS distances, per-query bias/variance, and variance upper bounds to gate or weight synthetic samples.
- Sectors: Software/AI, finance (chatbots, report drafting), healthcare (clinical NLP augmentation), government/public sector (document processing), education (content generation).
- Tools/workflows: sentence-transformers or LASER3 embeddings; PCA + SCREE; Frobenius/Mahalanobis distances; classical MDS (scikit-learn); DKPS dashboard integrated in MLOps.
- Assumptions/dependencies: Representative query set; ability to sample multiple outputs per query (r > 1); stable embedding quality; black-box model access to temperature/top-k or n-best; ground-truth or high-quality proxy references for bias estimation.
- Decoding policy and temperature tuning with quantified trade-offs
- What to do: Use DKPS to select between sequential multi-sampling vs top-k batched outputs and to set temperature that meets a variance “budget.”
- Sectors: Software/AI, media/publishing, education (quiz/Q&A generation), product search/copywriting.
- Tools/workflows: Batch vs sequential sampling evaluation; DKPS variance maps by temperature; “variance budget” thresholds.
- Assumptions/dependencies: Access to multiple samples or ranked outputs; stable evaluation prompts; embeddings reflect task-quality differences.
- Back-translation (BT) data selection for machine translation
- What to do: Apply the convex-hull acceptance rule in embedding space: prioritize English sentences whose synthetic translations fall within the convex hull of trusted human translations; filter risky OOS items.
- Sectors: Machine translation, cross-lingual IR, global content localization.
- Tools/workflows: LASER3 or multilingual sentence embeddings; PCA; convex-hull checks and distance-to-hull thresholds; BT pipeline integration (e.g., Sockeye, Marian).
- Assumptions/dependencies: Approximate geometry preservation of translate∘embed; sufficient reference translations to define “trusted” hulls; language coverage in embeddings.
- Length-aware debiasing and variance weighting
- What to do: Reweight or debias synthetic samples using learned bias/variance curves by sentence length (shorter sentences → systematically higher bias/variance).
- Sectors: MT and broader NLP (summarization, QA).
- Tools/workflows: Regression of bias/variance vs length; per-sample weights in training; length-based sampling controls.
- Assumptions/dependencies: Observed monotone relationships in a given domain persist across datasets; availability of per-sample length metadata.
- Vendor/model selection and benchmarking for black-box LLMs
- What to do: Place candidate LLMs into DKPS via a shared query set and pick the one closest to a high-quality reference distribution (lowest DKPS distance) for the target use case.
- Sectors: Enterprise AI procurement, regulated sectors (healthcare, finance, public sector).
- Tools/workflows: Common evaluation prompts; per-vendor DKPS map; model cards enriched with DKPS metrics (variance bounds, distances).
- Assumptions/dependencies: Same queries and embeddings across vendors; multi-sample access; relevant reference outputs.
- OOS monitoring and drift detection for production LLMs
- What to do: Track DKPS coordinates over time to detect drift away from reference distributions; trigger retraining or policy adjustments when thresholds exceed.
- Sectors: Software/AI, finance (reporting), customer support, healthcare documentation.
- Tools/workflows: Control charts on DKPS coordinates; CUSUM/EWMA on DKPS distances; alerting hooks in MLOps.
- Assumptions/dependencies: Stationary embeddings; representative rolling query set; clear baselines.
- CPO/RLHF training hygiene and contamination control
- What to do: Use DKPS with Mahalanobis distances to quantify contamination of preferred (sequential) data by dispreferred (batch) data during CPO; adjust β, sampling ratios, or weights to prevent preferred-model drift.
- Sectors: Foundation model post-training, alignment teams.
- Tools/workflows: CPO training with DKPS-based diagnostics; covariance-aware distance metrics; curriculum design.
- Assumptions/dependencies: Mixture/Gaussian approximations for embeddings; access to preferred/dispreferred splits; stable embeddings under training.
- Synthetic data documentation for compliance and governance
- What to do: Include DKPS-derived variance bounds, DKPS distances to reference, OOS flags, and acceptance thresholds in model cards and procurement SLAs.
- Sectors: Regulated industries (healthcare, finance, public sector), enterprise governance.
- Tools/workflows: DKPS reports attached to datasets/releases; approval gates in data catalogs; audit trails.
- Assumptions/dependencies: Defined thresholds aligned with risk tolerance; reproducible evaluation pipeline.
- Active data acquisition and labeling
- What to do: Prioritize human annotation for queries with high DKPS variance, large DKPS distance to reference, or near/beyond the convex-hull boundary.
- Sectors: MT, IR, dialog systems, domain adaptation.
- Tools/workflows: Uncertainty sampling by DKPS; annotator queues; data curation dashboards.
- Assumptions/dependencies: Annotation budget; embeddings sensitive to task errors.
- Practitioner guidance for daily use (non-research settings)
- What to do: Prefer sequential multi-sampling for higher-quality translations; avoid low-ranked batched candidates for production; flag short sentences as higher-risk; lower temperature to reduce variance.
- Sectors: Everyday translation use, content drafting, SMBs adopting LLMs.
- Tools/workflows: Simple heuristics in UI (e.g., “confidence meter” from length and temperature); user-facing settings presets.
- Assumptions/dependencies: Access to temp/top-k controls; explanatory UI.
Long-Term Applications
These require further research, scaling, standardization, or broader tooling integration.
- DKPS-regularized training objectives
- Vision: Add a penalty or constraint on DKPS distance to a preferred distribution during RLHF/CPO or supervised fine-tuning to keep the model close to a trusted output geometry.
- Sectors: Foundation model training, safety/alignment.
- Dependencies: Differentiable or efficiently approximable DKPS proxy; stable embeddings throughout training; compute overhead management.
- Cross-task and multi-domain generalization
- Vision: Extend DKPS-based guarantees from MT to speech, code generation, IR, summarization, and dialog—including multi-lingual and domain-adapted models.
- Sectors: Speech tech, software engineering tooling, search, customer support.
- Dependencies: High-quality, task-aligned embeddings; per-task query/reference sets; validation that geometry preservation holds.
- Synthetic-data ecosystem governance and standards
- Vision: Industry/consortium-backed “Synthetic Data Health” standards with DKPS thresholds (variance bounds, OOS metrics) for dataset release, procurement, and compliance.
- Sectors: Healthcare, finance, public sector, education.
- Dependencies: Standardized benchmarks and embeddings; third-party auditors; policy adoption and legal frameworks.
- Early-warning systems for model collapse
- Vision: Monitor DKPS signatures to detect self-ingestion and over-reliance on synthetic data (rising DKPS distances, shrinking diversity) and throttle synthetic-to-real ratios.
- Sectors: Foundation model providers, open-source model hubs.
- Dependencies: Robust collapse indicators; data provenance tracking; pipeline instrumentation.
- Provenance inference and synthetic-content detection
- Vision: Use DKPS “geometric signatures” to flag likely LLM-generated content infiltrating training corpora or evaluations.
- Sectors: Data marketplaces, publishers, education integrity, security.
- Dependencies: Distinctive DKPS patterns across generators; resistant to style obfuscation; legal/ethical frameworks.
- Strategic growth of low-resource language corpora
- Vision: For NGOs/governments/industry, use DKPS to identify domain slices where synthetic BT is reliable (inside convex hull) and prioritize human annotation elsewhere.
- Sectors: Localization, humanitarian tech, language preservation.
- Dependencies: Seed references to define “trusted hulls”; cultural/domain coverage; local capacity for annotation.
- Full-fledged DKPS product suite
- Vision: Enterprise tools—DKPS Monitoring Platform, Temperature/Decoding Optimizer, Synthetic Data Gatekeeper API, Vendor Distance Map, Back-Translation Selector.
- Sectors: Enterprise AI platforms, LLMOps tooling vendors.
- Dependencies: Productization, UI/UX, integrations with MLOps stacks (e.g., MLflow, Arize, Weights & Biases).
- Multi-modal DKPS
- Vision: Unify DKPS across text, audio, and images to evaluate cross-modal synthetic data quality and geometry preservation.
- Sectors: Robotics, AR/VR, healthcare imaging plus reports, multimedia search.
- Dependencies: Reliable cross-modal embeddings; standardized multi-modal query sets; scale-efficient computation.
- Theoretical refinements and guarantees
- Vision: Tighter finite-sample bounds for DKPS estimation; guidance on minimal m (queries), r (replicates), and embedding dimension p; robust alternatives to PCA/MDS for non-linear manifolds.
- Sectors: Academia/industry research, standards bodies.
- Dependencies: New theory and empirical validation; reproducible benchmarks.
- Fairness, safety, and compliance diagnostics
- Vision: DKPS analyses stratified by demographic or topical slices to detect disparate variance/bias patterns; use as safeguards before deployment in high-stakes settings.
- Sectors: Healthcare, finance, hiring, public services.
- Dependencies: Access to sensitive attributes or validated proxies; governance for ethical use; fairness-aware embeddings.
- Edge/robotics language interfaces
- Vision: On-device DKPS drift monitors for language-conditioned control or perception modules that rely on synthetic augmentation.
- Sectors: Robotics, IoT, automotive.
- Dependencies: Lightweight embeddings; limited compute and memory; real-time constraints.
Notes on common assumptions and dependencies across applications:
- Embeddings: Choice of g matters; results depend on embedding quality, coverage (language/domain), and stability across time/models.
- Sampling: DKPS requires replicates; APIs must support temperature, nucleus sampling, or top-n outputs.
- References: Bias estimation is strongest with human references; otherwise, use high-quality proxies and interpret conservatively.
- Geometry: Convex-hull heuristics assume partial geometry preservation in translate∘embed; validate per domain.
- Dimension and sample size: Use SCREE plots and simple diagnostics; ensure m and r are sufficient relative to embedding dimension p to avoid overfitting or noisy DKPS.
- Black-box constraints: DKPS is designed for black-box models, but consistent prompts, decoding settings, and query sets are essential for meaningful comparisons.
Glossary
- Back translation (BT): A technique in machine translation where target-to-source translations are used to generate synthetic training data to improve source-to-target performance. "One task where synthetic data have been used to particular advantage is machine translation (MT), through the mechanism of 'back translation' (BT)."
- BLEU: A standard automatic metric for evaluating machine translation quality by comparing candidate translations against reference translations. "incorporating synthetic data via BT is shown to provide substantial machine translation gains; specifically gains of up to thirteen BLEU points \cite{bleu} or 125\%,"
- Contrastive Preference Optimization (CPO): A post-training method that optimizes a model using preference pairs (preferred vs. dispreferred outputs) to improve alignment with desired behavior. "In the above analysis, the estimation of bias and variance and the model comparison are (at least implicitly) based on a maximum likelihood framework for model estimation. To show the flexibility of the DKPS framework, we also consider applying the DKPS machinery in the context of Contrastive Preference Optimization (CPO) \cite{xu2024contrastive}, a leading approach for the post-training of a model."
- Convex hull: The smallest convex set that contains a given set of points; used here to assess geometric preservation between embedded sentence spaces and their translations. "we consider 4 randomly chosen in-sample English sentences (call this set ), and construct their convex hull in PCA space"
- Data Kernel Perspective Space (DKPS): A framework that embeds and compares generative models via distances between mean embeddings of their outputs, enabling statistical guarantees and geometric analysis. "The idea of Data Kernel Perspective Space (DKPS) is to use a collection of queries to summarize and compare our models in Euclidean space as follows."
- Direct Preference Optimization (DPO): A preference-based training objective that CPO builds upon, optimizing models using preferred vs. dispreferred outputs without explicit reward modeling. "CPO is an approach that builds on its predecessor, Direct Preference Optimization (DPO) \cite{dpo}"
- Euclidean distance matrix: A matrix whose entries are pairwise Euclidean distances between points; here, used as input to MDS for model embedding. "As is a Euclidean distance matrix (up to scaling), we can compute "
- Gaussian mixture model: A probabilistic model that represents a distribution as a mixture of Gaussians; used to model preferred and dispreferred translation embeddings with equal weights. "Here we model the data (the sentences in 1-d and 3-d PCA space) using a Gaussian mixture model framework with equal weights"
- LASER3: A multilingual sentence embedding model used to obtain fixed-dimensional vector representations of sentences across languages. "We then use LASER3 \cite{LASER,LASER3} representations (at temperature ; results are shown for ; for other temperatures see Figure \ref{fig:bias_variance} in Appendix \ref{sec:figs}) to embed the English sentence collection, the human translations, and the synthetic translation sets into ."
- Mahalanobis distance: A distance metric that accounts for covariance structure to measure distances between points; used here for DKPS when batch and sequential covariances differ. "Due to the very different covariance structures between the batch and sequential models here, we use Mahalanobis distance as the distance metric for DKPS"
- Maximum likelihood (MLE): A statistical estimation framework that selects parameters maximizing the likelihood of observed data; used as a baseline for bias/variance analysis. "the estimation of bias and variance and the model comparison are (at least implicitly) based on a maximum likelihood framework for model estimation."
- Multidimensional Scaling (MDS): A dimensionality reduction technique that embeds items into a low-dimensional space based on pairwise distances, preserving geometry as much as possible. "we use the machinery of classical Multidimensional Scaling (MDS) \cite{borg2005modern} to get the representation "
- Out-of-sample (OOS): Data not used during training; here, used to study distribution shift and generalization of translations and embeddings. "we will further consider another collection of 1000 sentences of English---with human Zulu translations---from the en-zu model validation set to explore in- versus out-of-sample (OOS) distribution differences"
- Principal component analysis (PCA): A linear dimensionality reduction method that projects data onto directions of maximal variance; used to reduce high-dimensional embeddings for analysis. "we consider using principal component analysis (PCA) \cite{abdi2010principal} to further reduce the dimensionality of the sentence embeddings."
- Reinforcement learning framework: A learning paradigm optimizing behavior through feedback; here, CPO/DPO are framed as RL objectives using preference data. "Like DPO, CPO is a reinforcement learning framework:"
- SCREE plot: A diagnostic plot of eigenvalues (or explained variance) vs. component index, used to choose the number of principal components. "Based on the PCA SCREE plots (see Figure \ref{fig:scree} in Appendix \ref{sec:figs})"
- Sockeye Neural Machine Translation platform: An open-source neural machine translation toolkit used to build the bespoke English–Zulu MT model. "a bespoke English-Zulu MT model built within the Sockeye Neural Machine Translation platform \cite{hieber2017sockeye}."
- Temperature (sampling temperature): A parameter controlling randomness in generative model sampling; higher temperature increases output variability. "In practice it is common for language technology engineers to 'fiddle' with the LLM temperature setting and hope that what comes out the other end improves the downstream model."
Collections
Sign up for free to add this paper to one or more collections.