- The paper introduces HMRMamba, a dual-stage, dual-scan SSM framework that fuses geometry and motion cues for robust 3D human mesh recovery.
- It overcomes traditional limitations by integrating spatial and temporal modeling, achieving state-of-the-art performance on benchmarks like 3DPW, MPI-INF-3DHP, and Human3.6M.
- The architecture employs efficient loss functions and optimization techniques to ensure anatomical plausibility and temporal consistency under challenging conditions.
Geometry-Aware and Motion-Guided Video Human Mesh Recovery with HMRMamba
Introduction
This essay presents a thorough technical overview and analysis of "Towards Geometry-Aware and Motion-Guided Video Human Mesh Recovery" (2601.21376). The paper introduces HMRMamba, a video-based monocular human mesh recovery framework that leverages the sequence modeling power of Structured State Space Models (SSMs), specifically the Mamba family, to overcome long-standing issues related to anchor reliability and temporal plausibility in the HMR pipeline.
Limitations of Existing Video HMR Architectures
Contemporary video-based HMR methods predominantly follow a two-stage paradigm: first, they estimate intermediate 3D pose anchors using 2D pose lifting, and subsequently refine SMPL mesh parameters via video features. However, these approaches are hindered by two principal limitations:
- Imperfect 3D Anchors: The 2D-to-3D lifting modules generally lack strong geometric grounding from image cues, leading to erroneous skeletal predictions that affect subsequent mesh recovery, especially under occlusion and ambiguous postures.
- Inadequate Kinematic and Temporal Modeling: Deep models often neglect explicit spatiotemporal or anatomical constraints, resulting in shape inconsistencies, temporally incoherent meshes, and implausible articulation.
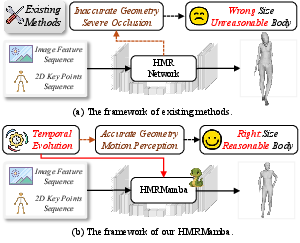
Figure 1: Conceptual comparison of HMR pipelines. (a) Prior works suffer from inconsistent geometry and poor occlusion handling. (b) HMRMamba employs temporally-evolving geometry and kinematics for robust mesh recovery.
HMRMamba Architecture
HMRMamba proposes a two-stage system that comprehensively addresses both geometric grounding and kinematic modeling.
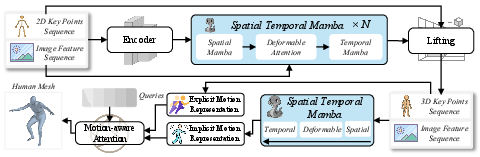
Figure 2: The two-stage HMRMamba pipeline: Geometry-Aware Lifting (top) fosters robust 3D poses from image-2D pose coupling; Motion-Guided Reconstruction (bottom) injects kinematic, temporally consistent awareness for final mesh regression.
Geometry-Aware Lifting Module: Dual-Scan STA-Mamba
This module is responsible for fusing detected 2D joint locations with image features and elevating them to 3D space. It introduces the STA-Mamba structure, which uniquely leverages:
- Spatial Mamba: Acts on per-frame basis, refining intra-frame joint relationships for anatomical plausibility.
- Deformable Attention Fusion: Aligns image features with key body points, allowing the network to focus on occlusion-prone or ambiguous joints.
- Temporal Mamba: Models inter-frame 3D joint evolution, enforcing motion smoothness and minimizing temporal ambiguity.
Both spatial and temporal modeling blocks are instantiated as Dual-Scan Mamba Blocks.
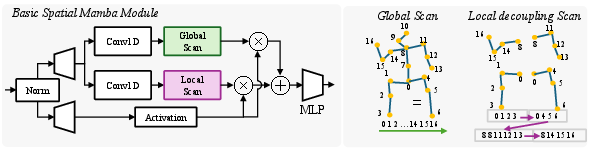
Figure 3: The Dual-Scan Mamba Block: Global scan for long-range context, local (kinematic) scan for anatomical structure; fusion generates robust joint encoding.
Dual-Scan Mechanism
Unlike typical sequential processing, the dual-scan block performs both a:
- Global Scan: Linear traversal (joint index or time) for holistic long-term dependencies.
- Local/Kinematic Scan: Traverses the human kinematic tree (e.g., torso to wrist, hip to foot) to explicitly encode physical structure and constraints.
These features are fused via element-wise operations, supporting both coherence and anatomical realism.
Motion-Guided Reconstruction Network
To move beyond framewise mesh parameter inference, HMRMamba’s second stage aggregates the full 3D joint sequence over time, extracting:
- Explicit Motion (Velocity): Frame-to-frame 3D joint displacement encodes instantaneous motion.
- Implicit Motion: Corrected visual features based on pose dynamics encode latent pose information.
A motion-aware attention mechanism computes the correlation between visual evidence and pose-driven motion descriptors, robustly regressing the SMPL mesh vertices. This conditioning is particularly advantageous in scenarios with occlusion, rapid articulation, or visual ambiguity.
Loss Functions and Optimization Details
Mesh recovery is supervised by a composite loss combining 3D/2D joint alignment, vertex positions, velocity smoothness, surface normal, and edge consistency. Training is conducted with large-batch Adam and staged optimization, using well-established backbones for image and 2D pose feature extraction. These choices promote a favorable balance between spatial detail, temporal smoothness, and computational efficiency.
Empirical Evaluation
Quantitative Analysis
HMRMamba sets a new state-of-the-art on 3DPW, MPI-INF-3DHP, and Human3.6M under all canonical metrics (MPJPE, PA-MPJPE, MPVPE, Accel):
- 3DPW: Achieves MPJPE of 66.9 mm, outperforming ARTS (67.7 mm) and PMCE (69.5 mm).
- MPI-INF-3DHP: Achieves MPJPE of 70.1 mm, surpassing prior SOTA by a substantial margin.
- Human3.6M: Achieves MPJPE of 51.2 mm and Accel of 3.1 mm/s², uniformly exceeding all published baseline results.
The framework also improves parameter count and computational cost over previous Transformer- and GCN-based SOTA, e.g., 22% fewer parameters than PMCE and faster inference with equal or better accuracy.
Qualitative and Occlusion Robustness





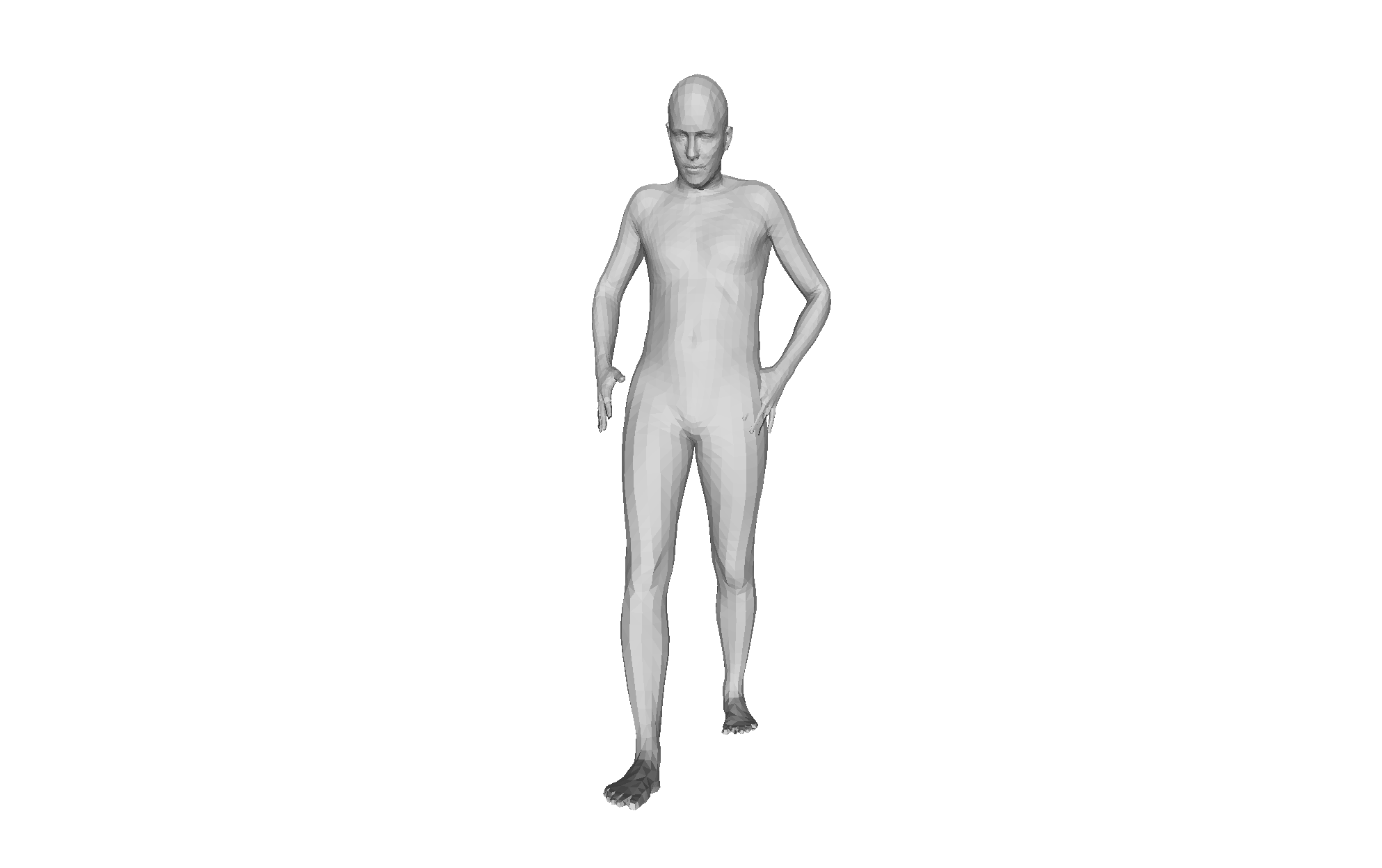
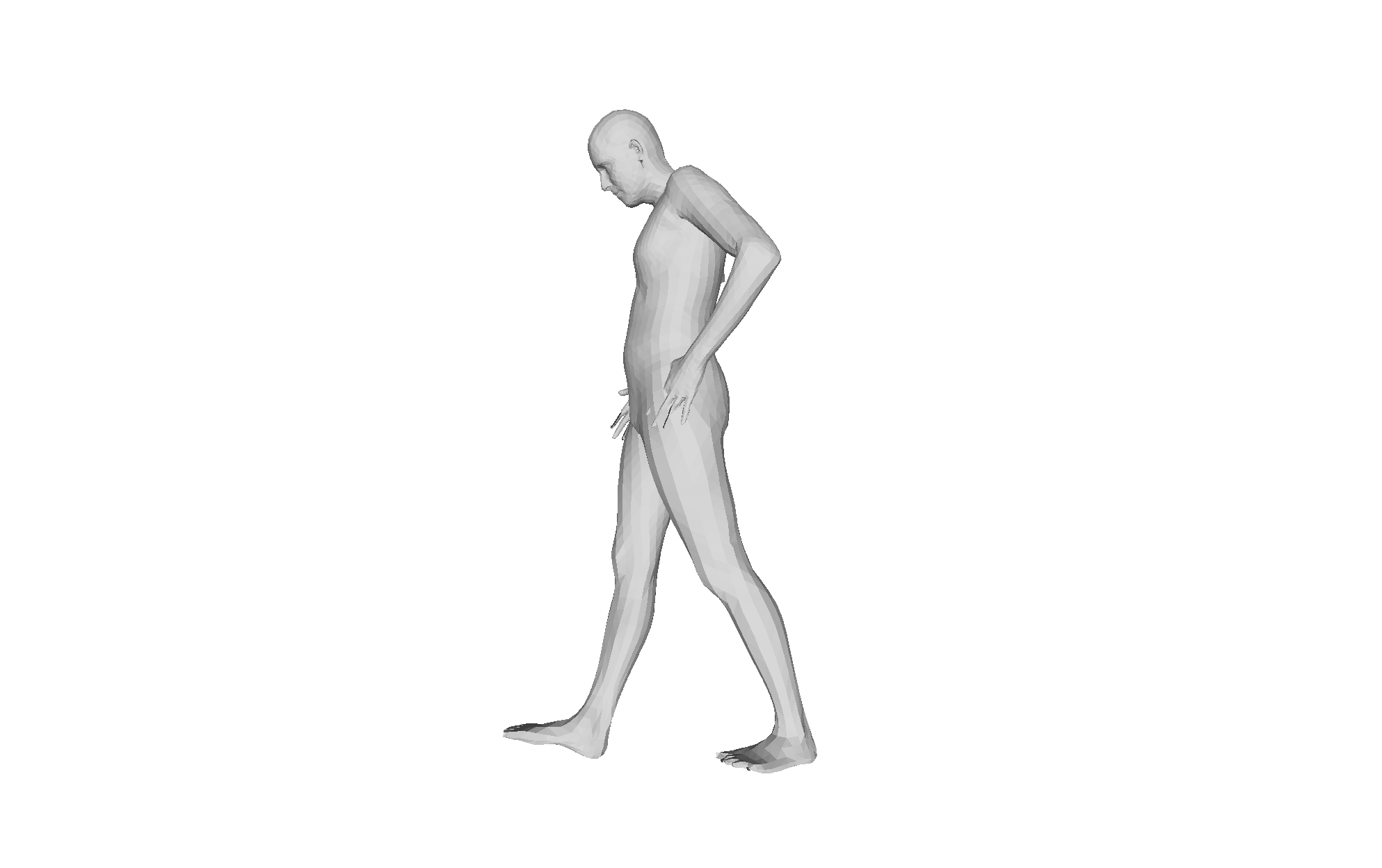
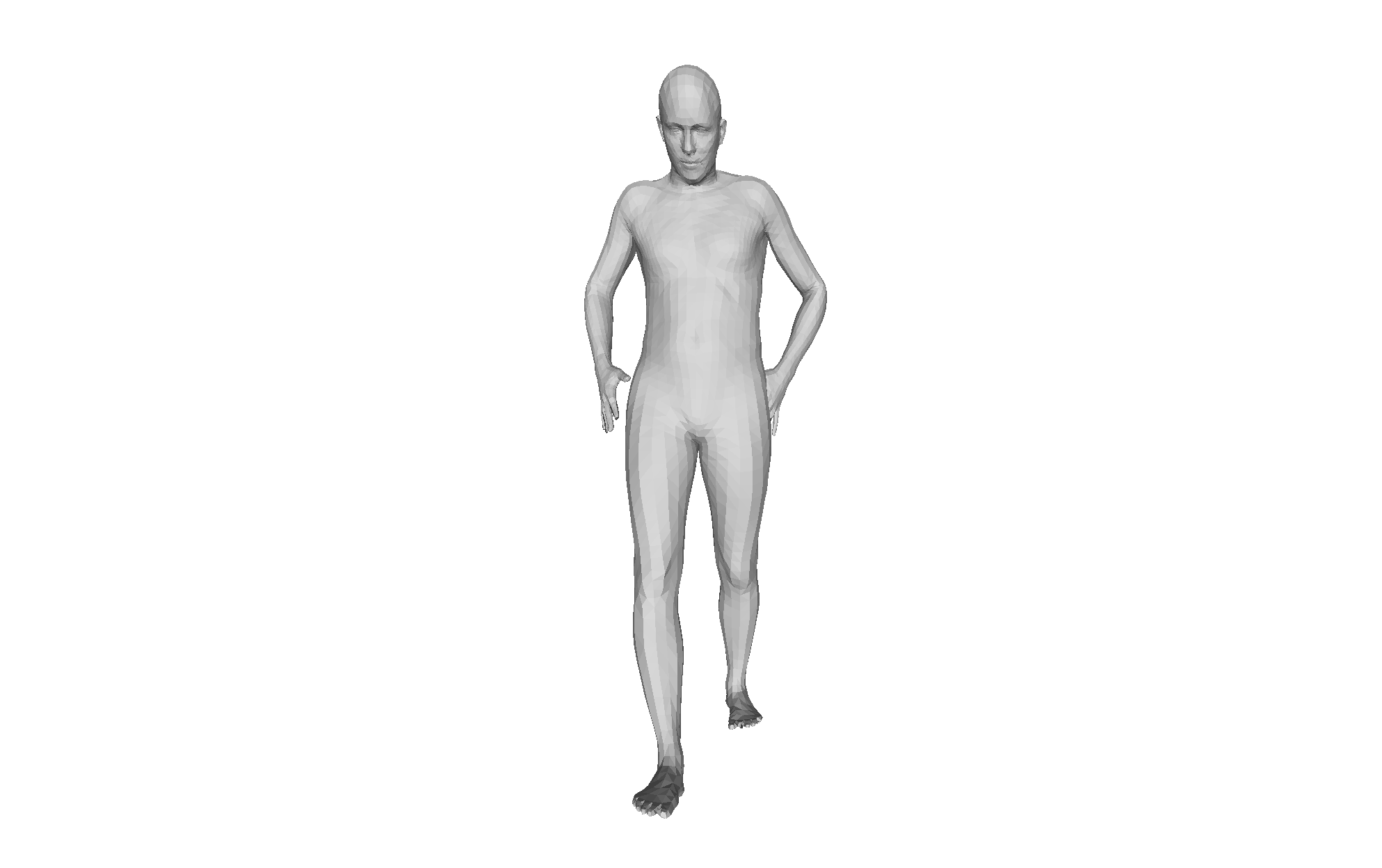
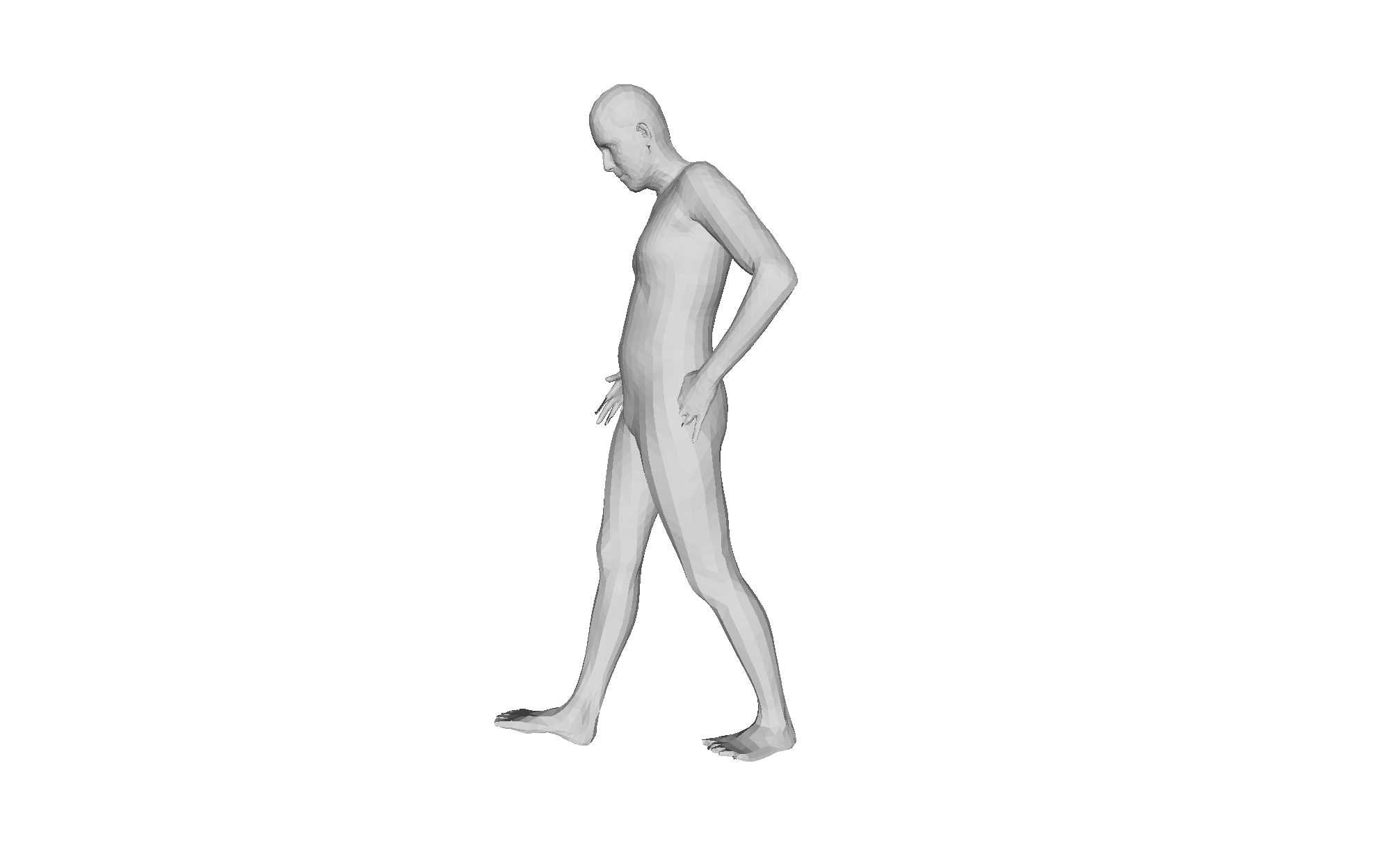

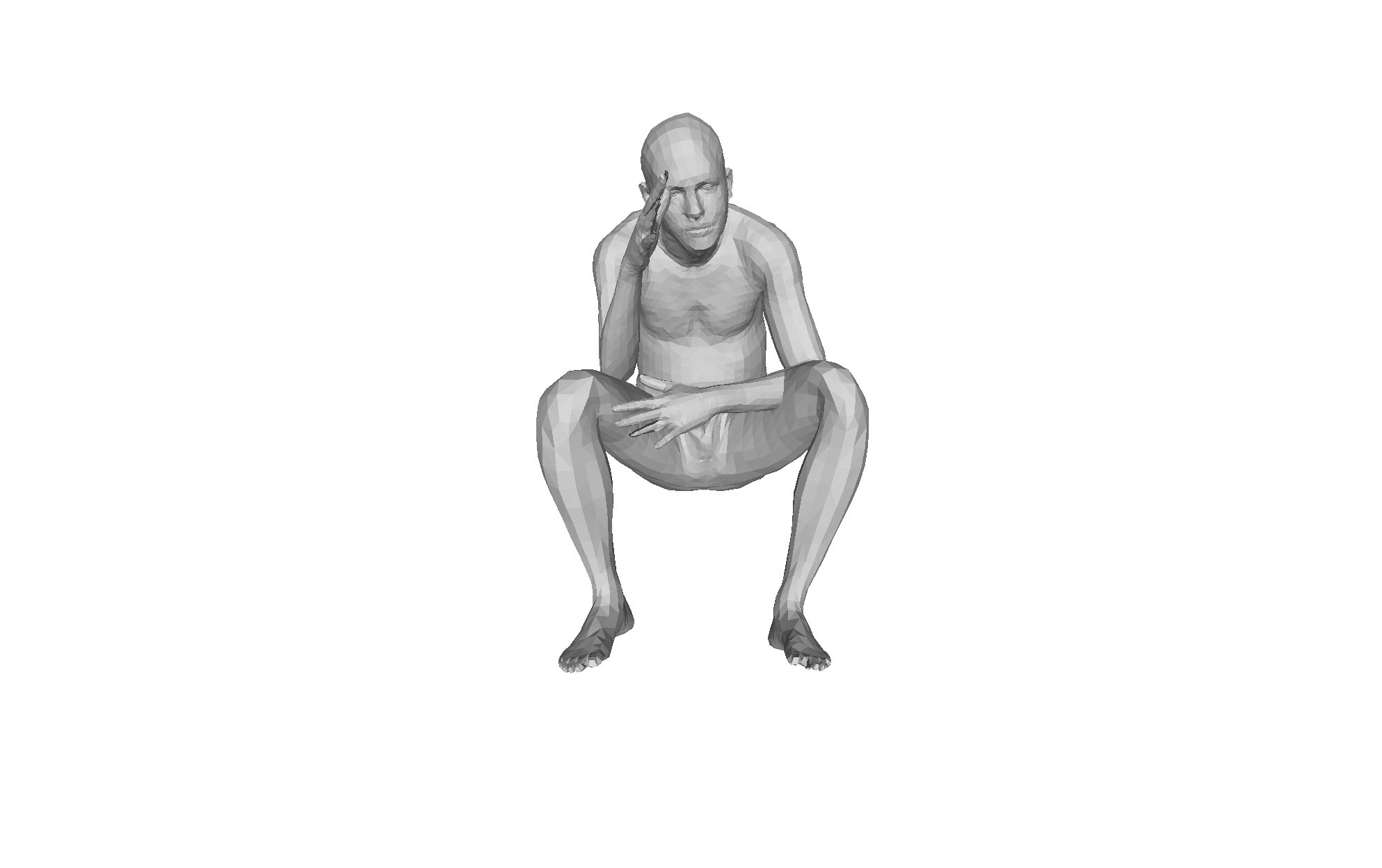

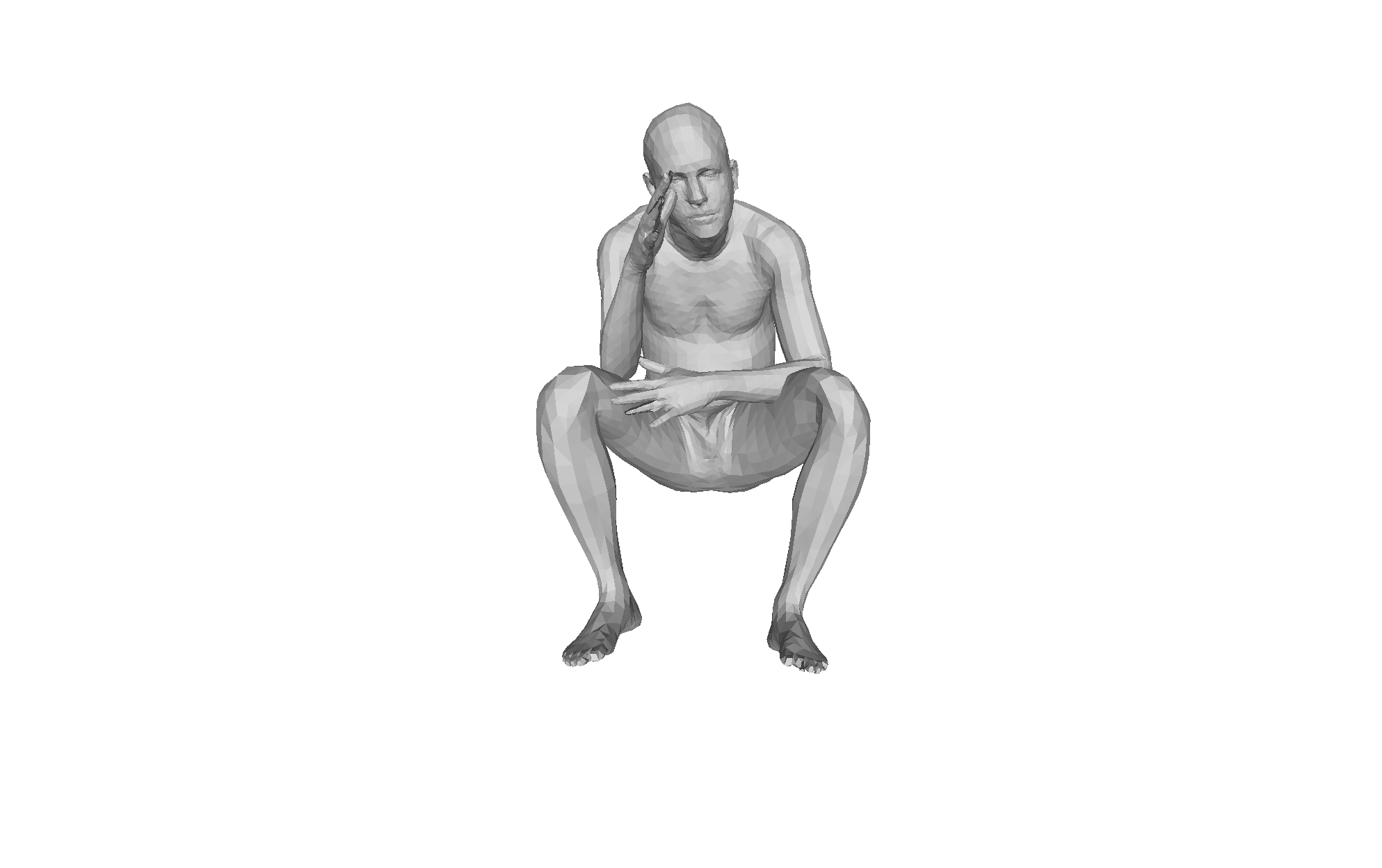






Figure 4: Qualitative HMRMamba results under challenging occlusion; recovery is anatomically plausible and temporally stable from diverse viewpoints.
Qualitative analysis demonstrates consistent mesh recovery under severe occlusion and motion blur, with the dual-scan design maintaining plausible geometry where frame-based methods fail.
Ablation Studies
- 2D Pose Detector Robustness: The geometry-aware lifting consistently improves mesh results even with noisy or lower-accuracy 2D pose estimates, evidencing resilience to typical detection errors.
- Component Efficacy: Both explicit and implicit motion branches contribute to accuracy and motion smoothness.
- Efficiency: The dual-scan Mamba yields improved accuracy with minimal FLOP overhead relative to vanilla Mamba, outperforming Transformers and hybrid GCNs in efficiency-accuracy tradeoff.
Implications and Outlook
Practical Implications
The paper substantiates the proposition that SSM-based architectures—specifically, dual-scan Mamba—advance HMR accuracy, anatomical plausibility, and efficiency in real-world settings. The advances in anchor reliability and kinematic modeling are especially salient for downstream applications such as HCI, AR/VR telepresence, and robotics, where actionable, temporally consistent 3D human meshes are mission-critical.
Theoretical Implications
By formalizing mesh recovery as a global-local sequence modeling task and integrating explicit anatomical priors within SSMs, the framework bridges a key representational gap between 2D pose, 3D skeleton, and surface mesh. It highlights the importance of jointly optimizing visual, kinematic, and motion cues, and demonstrates that Mamba architectures offer an alternative to Transformers for dense video analysis domains.
Prospects for Future Work
The demonstrated gains suggest potential in scaling SSM-based approaches to broader multi-human, multi-view, or category-level mesh recovery problems. Integration with learned geometric priors (e.g., via diffusion or variational models) or extension to non-parametric surface representations could further extend applicability. The strong efficiency profile supports deployment in resource-constrained environments, fostering wider adoption in edge-based perception systems.
Conclusion
HMRMamba (2601.21376) introduces a paradigm shift in video human mesh recovery by embedding dual-scan, geometry-aware, and motion-guided SSM modules within the estimation pipeline. Comprehensive empirical validation shows that it yields state-of-the-art accuracy and temporal consistency, robustly overcoming the limitations of prior anchor-based and Transformer-centric methods. The dual-scan Mamba strategy sets a compelling direction for further research on anatomically plausible, efficient, video-level 3D human mesh recovery.

