3D-Aware Implicit Motion Control for View-Adaptive Human Video Generation
Abstract: Existing methods for human motion control in video generation typically rely on either 2D poses or explicit 3D parametric models (e.g., SMPL) as control signals. However, 2D poses rigidly bind motion to the driving viewpoint, precluding novel-view synthesis. Explicit 3D models, though structurally informative, suffer from inherent inaccuracies (e.g., depth ambiguity and inaccurate dynamics) which, when used as a strong constraint, override the powerful intrinsic 3D awareness of large-scale video generators. In this work, we revisit motion control from a 3D-aware perspective, advocating for an implicit, view-agnostic motion representation that naturally aligns with the generator's spatial priors rather than depending on externally reconstructed constraints. We introduce 3DiMo, which jointly trains a motion encoder with a pretrained video generator to distill driving frames into compact, view-agnostic motion tokens, injected semantically via cross-attention. To foster 3D awareness, we train with view-rich supervision (i.e., single-view, multi-view, and moving-camera videos), forcing motion consistency across diverse viewpoints. Additionally, we use auxiliary geometric supervision that leverages SMPL only for early initialization and is annealed to zero, enabling the model to transition from external 3D guidance to learning genuine 3D spatial motion understanding from the data and the generator's priors. Experiments confirm that 3DiMo faithfully reproduces driving motions with flexible, text-driven camera control, significantly surpassing existing methods in both motion fidelity and visual quality.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “3D-Aware Implicit Motion Control for View-Adaptive Human Video Generation”
Overview: What is this paper about?
This paper is about making better human videos where a person in a picture is animated to move like someone in a “driving” video. The key twist: the camera angle can change freely (like a movie camera moving around), and the movement still looks right in 3D. Instead of using 2D stick-figure poses or a fixed 3D model that can be wrong, the authors teach a video generator to understand motion in a more natural, “implicit” 3D way.
Key goals and questions
To make the ideas clear, here’s what the researchers set out to do:
- Capture true 3D motion from ordinary 2D videos, so the motion stays correct even when the camera view changes.
- Keep camera control separate and flexible, guided by simple text instructions (like “pan left” or “side view”).
- Avoid depending too much on rigid 3D models (like SMPL) that can guess depth incorrectly.
- Train the motion understanding and the video generator together so they “think” about motion in the same way.
How it works: methods explained simply
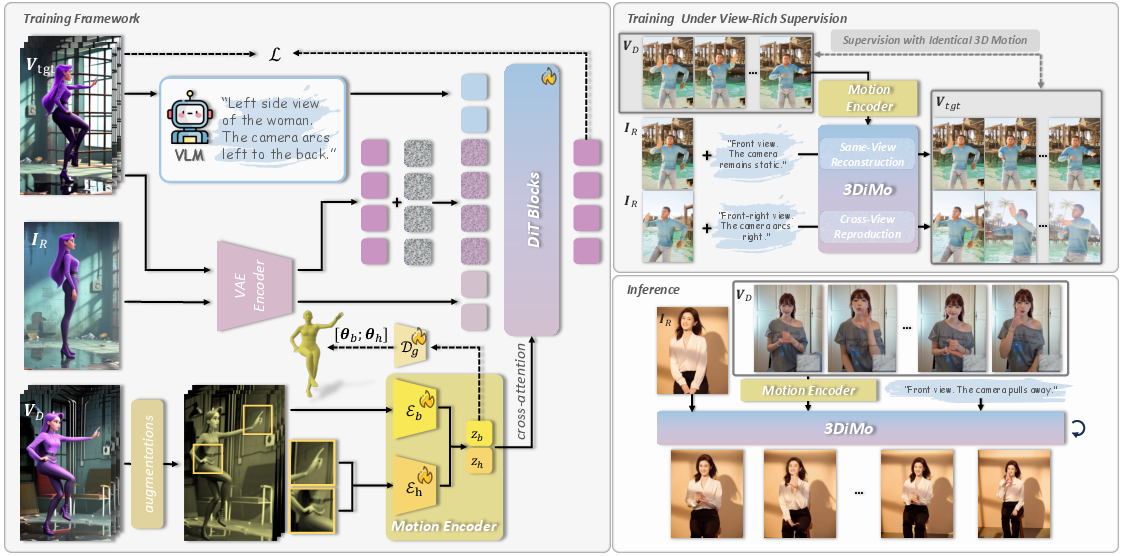
Think of the system like a filmmaking team with three main parts:
- The video generator (the “director” and “camera”)
- It’s a powerful AI video model (a diffusion model with a Transformer, often called DiT).
- It already has a good sense of 3D: it can follow text instructions about how the camera should move.
- It turns a reference image into a video and can listen to motion cues and text prompts.
- The motion encoder (the “choreographer”)
- It watches the driving video and creates a small set of “motion tokens” (think of them as a compact motion fingerprint).
- These tokens are designed to ignore the exact viewpoint of the driving clip (they don’t store the 2D layout) and instead capture the essence of the movement in 3D.
- To help it learn viewpoint-free motion, the driving frames are randomly warped a bit (like changing perspective), forcing the encoder to focus on real motion, not just how things look from one angle.
- There are two encoders: one for the whole body and one for hands (because hands need extra detail).
- Motion-to-video connection (the “communication line”)
- The motion tokens are injected into the video generator using cross-attention.
- Cross-attention is like giving the generator focused hints about motion without pinning it to a fixed 2D map. It lets the generator “refer to” the motion while still deciding how to place things in 3D space.
- Camera control comes from the text prompt (for example: “side view,” “zoom in,” “orbit around”). Because motion and camera are separate, you can change the view while keeping the same movement.
Training strategy (the “coaching plan”)
- View-rich supervision: They train on a mix of videos:
- Single-view clips (a lot of diverse motions),
- Multi-view captures (the same motion from different cameras),
- Moving-camera videos (the same motion while the camera moves).
- This forces the system to learn motion that stays consistent across viewpoints—true 3D understanding—rather than just memorizing a single angle.
- Early “training wheels” using SMPL/MANO (3D body/hand models): At the start, they lightly guide the motion encoder to align with rough 3D pose estimates. Then they gradually fade this guidance to zero (this fading is called “annealing”). The goal is to get the benefits of a good start without becoming dependent on a model that often guesses depth wrong.
- End-to-end joint training: The motion encoder and the generator are trained together so their “ideas” about motion line up.
Main results and why they matter
What did they find?
- Better motion quality: The system reproduces the movement from the driving video very accurately while staying physically plausible in 3D (limbs don’t mix up front/back, contacts like a hand on a hip stay correct across views).
- Flexible camera control: You can change the viewpoint and camera motion using text prompts, and the motion still looks right.
- Stronger realism: Compared to methods that use 2D poses or fixed 3D models like SMPL, this approach scores better on popular video quality measures and in user studies (people rated it more natural and more 3D-plausible).
- Ablation studies (turning parts off to test their impact) show:
- Removing view-rich training weakens 3D understanding.
- Replacing cross-attention with a simpler connection hurts motion control.
- Skipping the early geometric guidance makes training unstable.
- Dropping the hand encoder loses fine hand movements.
Why it matters:
- It proves that large video generators already have useful 3D “priors” (built-in knowledge). If you feed them motion in the right form (implicit tokens), they can produce better 3D-consistent videos than when forced to follow imperfect external 3D models.
What this could mean for the future
This approach could make animation and video production easier and more flexible:
- Filmmaking and social media: Animate a character with someone else’s dance or action, then freely “move the camera” to get cinematic shots.
- Games and virtual worlds: Create believable character motion from simple video references without complex motion-capture setups.
- Education and creative tools: Let creators and students explore motion and camera choices using simple text prompts.
- Research: Encourages learning motion as an implicit 3D concept, not just 2D stick figures or rigid parametric meshes. The authors also plan to release part of their view-rich dataset, which can help others build on this idea.
In short: The paper shows a new, smarter way to control human motion in generated videos—one that respects the true 3D nature of movement and keeps the camera free to go wherever the director (or the text prompt) wants.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper and can guide future research:
- Quantifying 3D awareness: No metrics directly evaluate 3D motion fidelity (e.g., cross-view pose consistency, depth-order correctness, inter-limb/limb–object contact preservation, or 3D trajectory accuracy). Establishing standardized 3D evaluation protocols is needed.
- Camera control fidelity: The paper does not quantitatively measure how accurately text prompts induce desired camera trajectories (e.g., comparing predicted camera paths to ground-truth calibrated trajectories in multi-view/moving-camera datasets).
- Dependence on the pretrained generator: The approach leans heavily on a proprietary DiT-based backbone with “intrinsic 3D priors.” It remains unclear how 3DiMo performs with smaller or open-source backbones and how much benefit comes from the motion encoder vs. the backbone’s priors.
- Reproducibility and implementation detail gaps: Key details about the generator (architecture variants, training recipes, pretraining data/scale, exact tokenizer interfaces) are insufficient for independent replication. Clarifying these is necessary for fair, reproducible comparisons.
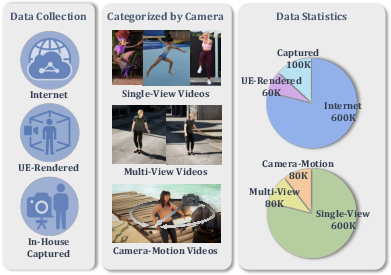
- Data composition, scale, and balance: The exact quantities, distributions, and domain balance across internet, synthetic UE5, and real multi-view sources are not reported. The minimal necessary fraction of view-rich data to elicit 3D awareness is unknown.
- Dataset release scope and licensing: Only a “subset” is planned for release with unclear coverage (multi-view/moving-camera components, annotations, licensing). This limits community verification and benchmarking.
- Annotation quality of camera prompts: Camera-view/motion text annotations derived via Qwen2.5‑VL may be noisy. No analysis quantifies annotation accuracy or its impact on camera control reliability.
- Robustness to occlusion and challenging conditions: Behavior under severe occlusions, motion blur, extreme viewpoints (e.g., top-down), fast or highly non-periodic motions, and cluttered scenes is not evaluated.
- Multi-person scenarios: The method targets single-person control; handling multi-person driving videos (selection, disambiguation, interaction) and group motion synchronization is left unexplored.
- Object and environment interactions: There is no control or evaluation for human–object or human–environment interactions (grasping, contact, support surfaces), despite claims of improved physical plausibility.
- Physical plausibility metrics: Foot–ground contact, foot-skate/slip, balance, self-collision, and momentum conservation are not explicitly measured; adding physics-oriented metrics and constraints would substantiate plausibility claims.
- Hand and face granularity: While a hand encoder is included, there is no quantitative hand pose evaluation (e.g., MPJPE/AUC for finger joints) or modeling of facial expressions/gaze; object manipulation and bimanual coordination remain open.
- Identity leakage and disentanglement: Appearance augmentations are used to avoid leakage, but no test quantifies leakage risk or disentanglement quality (motion vs. appearance vs. viewpoint). Formal analyses or recovery experiments are missing.
- Token design choices: The number of latent motion tokens (K=5), token dimensionality, and temporal resolution are heuristic. The capacity–performance trade-off, variable-length tokens, or adaptive tokenization strategies are not studied.
- Conditioning mechanism scope: Only cross-attention is evaluated (vs. one alternative). The optimal injection layer(s), gating strategies, attention routing, and the effect of multi-level conditioning remain underexplored.
- Explicit camera disentanglement: The approach relies on text-driven camera control without explicit camera tokens or calibrated camera parameters. Whether mild explicit camera modeling would improve disentanglement and controllability is an open question.
- Background–subject disentanglement: Fail cases where camera motion affects only the background (subject stays front-facing) suggest residual entanglement. Methods to better separate subject motion, camera motion, and background dynamics are needed.
- Long-horizon generation: Training/evaluation uses 121-frame clips; scalability to much longer videos and analysis of drift, identity consistency, and motion stability over long horizons remain open.
- Cross-identity retargeting limits: The method’s behavior under large body-shape/clothing disparities (e.g., extreme proportions, loose garments, hair dynamics) is not analyzed; garment–body interaction remains a gap.
- Aux. SMPL/MANO supervision bias: Early supervision could bake in reconstruction biases (depth tilt, contact errors). Alternatives (e.g., multi-view consistency losses, monocular depth/flow/geometric self-supervision) and schedules that minimize bias while stabilizing training warrant investigation.
- Evaluation under moving-camera conditions: Because baselines lack camera control, most metrics are reported under static prompts. A dedicated benchmark with moving-camera ground truth is needed to fairly validate view-adaptive control.
- Generalization to out-of-domain motions: The method’s performance on highly novel actions (e.g., acrobatics, martial arts), non-human subjects (children, animals), or stylized motions is untested.
- Efficiency and deployment: Training/inference cost, memory footprint, latency, and potential for real-time applications are not reported; methods for model distillation or token compression could enable practical deployment.
- Safety, consent, and bias: The paper does not address ethical considerations (consent for internet videos, demographic/identity bias, potential misuse for deepfakes). Dataset audits and safeguards are needed.
- Benchmarking standards: The field lacks standard datasets and metrics for 3D-aware motion control with view-adaptive generation; establishing common benchmarks would enable rigorous, comparable evaluations.
Glossary
- Ablation study: A methodical removal or alteration of components to assess their impact on performance. "Ablation Study and Analysis"
- Annealing: Gradually reducing a loss weight or constraint during training to ease optimization. "is annealed to zero"
- Auxiliary geometric supervision: Additional training signals derived from geometry (e.g., 3D poses) used to guide learning. "we introduce auxiliary geometric supervision to facilitate motion representation learning"
- Camera-space joint trajectories: 3D joint paths expressed in the camera’s coordinate frame for explicit control. "mapped as camera-space joint trajectories for explicit 3D control"
- Camera trajectories: The path and orientation changes of a virtual or real camera over time. "camera trajectories"
- Causal 3D VAE: A video autoencoder that compresses sequences with temporal causality in three dimensions. "utilizing a causal 3D VAE for video compression"
- Channel concatenation: A conditioning mechanism that fuses features by stacking along the channel dimension. "We replace cross-attention with channel concatenation"
- Cross-attention: An attention mechanism allowing one set of tokens to attend to another for conditioning. "injected semantically via cross-attention"
- Cross-modal interaction: Information exchange between different modalities (e.g., text, image, motion) within a model. "facilitating cross-modal interaction"
- Cross-view motion reproduction: Supervising generation to reproduce the same motion from different viewpoints. "cross-view motion reproduction"
- Depth ambiguities: Uncertainties in estimating depth from 2D observations leading to geometrically inconsistent interpretations. "suffer from depth ambiguities"
- DiT-based video generator: A diffusion-transformer architecture specialized for video synthesis. "an DiT-based video generator"
- Domain gaps: Differences in data distributions that cause models trained on one domain to perform poorly on another. "despite potential domain gaps from real-world videos"
- Feed-Forward Networks (FFN): The MLP sublayers within transformer blocks that process token representations. "Feed-Forward Networks (FFN)"
- Flow-based diffusion process: A training procedure that views diffusion as learning flows transforming noise into data. "we adopt a flow-based diffusion process"
- Fréchet Inception Distance (FID): A metric comparing feature distributions of real and generated images for quality assessment. "PSNR, SSIM, LPIPS, and FID"
- Fréchet Video Distance (FVD): A metric evaluating the realism and temporal coherence of generated videos. "and adopt FVD to evaluate the overall video fidelity"
- Identity leakage: Unintended transfer of identity-specific appearance from driving videos into generated outputs. "to prevent identity leakage from the driving frames"
- Latent Diffusion Model (LDM): A diffusion model operating in a compressed latent space for efficient generation. "Latent Diffusion Models (LDMs)"
- Likert scale: A psychometric scale for subjective ratings, often 5 points from low to high agreement. "a 5-point Likert scale"
- MANO: A parametric 3D hand model with pose and shape parameters for articulated hand representation. "MANO"
- Mean Opinion Score (MOS): An average human rating used to evaluate perceived quality. "results of MOS with 95% confidence intervals"
- Novel-view synthesis: Generating images or videos of a scene from viewpoints not present in the input data. "precluding novel-view synthesis"
- Parametric 3D human model: A mesh-based human representation defined by low-dimensional pose and shape parameters. "Parametric 3D Human Model."
- Patchified: The process of splitting images into patches to create tokens for transformer encoders. "Each driving frame is patchified into visual tokens"
- Pseudo ground-truth annotations: Automatically estimated labels used as approximations of true annotations for supervision. "using pseudo ground-truth annotations"
- Random perspective transformations: Viewpoint-altering augmentations applied to images to promote view invariance. "random perspective transformations"
- Self-attention: A mechanism enabling tokens within a sequence to attend to each other to capture dependencies. "full self-attention"
- Semantic bottleneck: A compressed representation that suppresses spatial details to force high-level semantic encoding. "we enforce a semantic bottleneck"
- SMPL: A skinned, parametric 3D body model defining human mesh via pose and shape parameters. "SMPL"
- SMPL-X: An extension of SMPL that jointly models body, hands, and face for expressive capture. "SMPL-X"
- Text-guided camera control: Steering camera motion or viewpoint using natural language prompts. "text-guided camera control"
- Tokenizer (Transformer-based 1D tokenizer): A module that converts inputs into compact token sequences for transformers. "Transformer-based 1D tokenizer"
- View-agnostic: Independent of the specific camera viewpoint; consistent across different views. "view-agnostic"
- View-rich supervision: Training signals drawn from datasets with diverse viewpoints and camera motions to learn 3D consistency. "view-rich supervision"
- v-prediction objective: A diffusion training target where the model predicts a velocity-like quantity instead of noise. "optimized using a v-prediction objective"
Practical Applications
Overview
This paper introduces 3DiMo, an end-to-end framework that extracts view-agnostic, implicit “motion tokens” from ordinary 2D videos and conditions a pretrained DiT-based video generator to produce human videos with faithful motion and flexible, text-guided camera control. Unlike 2D pose or explicit SMPL conditioning, 3DiMo avoids binding motion to a single viewpoint and reduces reconstruction biases by leveraging the generator’s intrinsic 3D priors, trained with view-rich supervision (single-view, multi-view, moving-camera data) and annealed auxiliary geometric guidance.
Below are practical applications derived from the method’s capabilities, grouped by deployment horizon. Each item notes sectors, concrete tools/products/workflows, and key assumptions/dependencies affecting feasibility.
Immediate Applications
The following can be deployed with current capabilities of large video diffusion models and the 3DiMo pipeline.
- Content creation and post-production acceleration
- Sectors: media/entertainment, advertising, social media, creator economy, gaming
- What: Animate a reference character (actor photo, brand mascot, game avatar) with motion extracted from a driving clip; alter or “reshoot” with text-prompted camera moves (e.g., dolly-in, orbit, over-the-shoulder).
- Tools/workflows:
- “Motion-from-video” plug-ins for NLE/VFX tools (Premiere, After Effects, DaVinci Resolve, Blender, Unreal Engine) that accept a reference frame, a driving clip, and a camera-language prompt.
- SaaS or API that outputs shots/cinematics from a single take: upload a dance clip, generate multi-view versions or cinematic variants.
- VTuber/streamer tool to drive stylized avatars from webcam videos while controlling virtual camera via text.
- Assumptions/dependencies:
- Access to a high-quality pretrained DiT video generator with text-driven camera control.
- Rights/consent for identity and motion transfer; safety guardrails to mitigate deepfake misuse.
- GPU resources; latency may limit real-time use.
- Low-cost “mocap-lite” for indie studios and prosumers
- Sectors: indie filmmaking, previs, game dev, virtual production
- What: Replace conventional markerless/marker-based mocap for previs and blocking by extracting robust motion from 2D videos (single or moving camera), with view-independent reenactment and camera relighting via text.
- Tools/workflows:
- Previz tool that imports a single phone-shot rehearsal and outputs multi-angle previews; shot planning via camera-language prompts.
- Game prototyping tool for NPC/cutscene motion from reference clips without rigging/SMPL fitting.
- Assumptions/dependencies:
- Motion is implicit and not guaranteed to be metrically accurate for physics; suitable for visual/as-if plausibility, not precise kinematics.
- Scene/occlusion complexity can affect fidelity; hand gestures benefit from dedicated hand encoder in the pipeline.
- Social/video apps and UGC augmentation
- Sectors: mobile apps, social platforms
- What: “Animate me” features: users drive a portrait or avatar with any public clip; generate multi-angle edits; stylize backgrounds while keeping motion.
- Tools/workflows:
- Mobile app with presets: “turntable shot,” “dynamic orbit,” “slow push-in,” applied via text prompts.
- Batch creation for marketers/influencers: one performance → many camera-angle variants for A/B testing.
- Assumptions/dependencies:
- On-device models likely too heavy; rely on cloud inference.
- Content provenance/watermarking advisable.
- Rapid localization and creative adaptation
- Sectors: advertising, e-commerce, education
- What: Reuse motion across regions/brands by swapping reference identity while retaining choreography and allowing cultural camera styles via prompts.
- Tools/workflows:
- Campaign asset generator: same motion, different talent/wardrobe, camera tone (“handheld close-up,” “wide crane”).
- Assumptions/dependencies:
- Brand safety and consent for identity substitution; ensure no identity leakage from driving frames.
- Academic benchmarking and dataset tooling
- Sectors: academia, R&D
- What: Study/view-adaptive motion control and 3D-awareness without explicit 3D labels; generate multi-view training data for action recognition/pose estimation.
- Tools/workflows:
- Release of view-rich subsets for cross-view supervision and evaluation.
- Baseline scripts for cross-view reproduction metrics (FVD/FID under camera changes).
- Assumptions/dependencies:
- Dataset licensing; consistent evaluation protocols.
- Accessibility and communication aids (non-clinical)
- Sectors: education, public sector, nonprofits
- What: Create variants of instructional or sign-language-style videos with different camera angles to improve visibility and engagement.
- Tools/workflows:
- Teacher/creator tools for multi-angle re-edits without reshooting.
- Assumptions/dependencies:
- Not a substitute for certified sign-language interpretation; review for accuracy and representation.
Long-Term Applications
These require further research, scaling, integration, or assurances (e.g., metric 3D fidelity, real-time constraints, safety).
- Real-time telepresence and XR avatars with free camera control
- Sectors: AR/VR, enterprise collaboration, live events
- What: Drive photoreal avatars from standard cameras while spectators/participants control viewpoints; improve immersion without multiview capture rigs.
- Tools/workflows:
- Low-latency motion-token encoders plus fast diffusion/flow matching or distilled generators.
- Integration with game engines (Unreal, Unity) for live virtual production.
- Assumptions/dependencies:
- Significant model distillation/acceleration; stable temporal consistency at low latency; reliable identity preservation; robust to occlusions.
- Training data engine for embodied AI and robotics
- Sectors: robotics, simulation, autonomous systems
- What: Generate diverse, view-consistent human motion videos to pretrain imitation learning, affordance, or intent prediction models; augment rare behaviors.
- Tools/workflows:
- Synthetic multi-view motion banks conditioned on task prompts; domain-randomized backgrounds/cameras.
- Coupling with pose/mesh recovery to produce pseudo-3D labels from more 3D-aware videos.
- Assumptions/dependencies:
- Need tighter alignment with physics and contact; validation that implicit 3D is sufficient for policy learning.
- Sports analytics and coaching from broadcast videos
- Sectors: sports tech, biomechanics
- What: Reconstruct view-adaptive motions from single-camera footage for tactic analysis; generate alternative viewpoints for review.
- Tools/workflows:
- Analyst dashboards to scrub motion with virtual camera; athlete motion libraries for playbooks.
- Assumptions/dependencies:
- Requires higher metric accuracy, calibrated scaling, and contact fidelity; integration with multi-sensor data or SMPL refinement.
- Clinical and wellness applications (e.g., rehab, gait analysis)
- Sectors: healthcare, digital health
- What: Remote assessments with viewpoint-normalized visualization; patient motion comparison over time.
- Tools/workflows:
- Clinician tools to standardize viewpoint in home-captured videos; compliance feedback.
- Assumptions/dependencies:
- Regulatory approval; rigorous validation for accuracy, repeatability, and bias; privacy/security compliance; likely need explicit 3D parameter outputs.
- Cinematic AI directors and shot-planning assistants
- Sectors: film/TV, virtual production
- What: Turn a rehearsal take into full shot lists with camera-language prompts; iterate blocking and coverage without re-staging actors.
- Tools/workflows:
- “Shot language → text prompt” libraries; integration with scheduling and asset management.
- Assumptions/dependencies:
- Creative control over determinism and continuity; better promptability and predictable camera behavior.
- Personalized education and training content at scale
- Sectors: education, corporate training
- What: Generate instructor or avatar demos that preserve expert motion while adapting camera angles per learner preference or device.
- Tools/workflows:
- LMS plug-ins that remix instructor videos into multiple camera variants automatically.
- Assumptions/dependencies:
- Pedagogical oversight; safeguards against misrepresentation; consent from instructors.
- Fashion and virtual try-on with motion
- Sectors: e-commerce, fashion tech
- What: Apply motion from runway or UGC to product-specific reference images for dynamic try-on videos; multi-angle merchandising.
- Tools/workflows:
- Product pipeline connecting catalog images → animated multi-view videos; styling and camera presets.
- Assumptions/dependencies:
- Garment-body interactions and cloth dynamics remain approximated; may require hybrid physics or garment-specific modules.
- Provenance, watermarking, and policy frameworks for motion transfer
- Sectors: policy, standards, platforms
- What: Establish consent frameworks and traceability for motion and identity reuse; motion-token watermarking and usage logs.
- Tools/workflows:
- C2PA-like extensions for motion provenance; platform-side detectors tuned to 3DiMo-style artifacts.
- Assumptions/dependencies:
- Cross-industry coordination; standardized metadata; minimal impact on creator workflows.
Cross-Cutting Assumptions and Dependencies
- Model and data availability
- Requires access to a capable pretrained DiT video generator with robust 3D priors and text-driven camera control; licensing and compute costs are non-trivial.
- View-rich datasets (multi-view/moving camera) improve 3D awareness; domain gaps between synthetic and real video must be managed.
- Quality and limitations
- Geometry is implicit; results are visually and spatially plausible but not guaranteed to be metrically accurate or physically consistent (contacts, forces).
- Text-guided camera control can be non-deterministic; shot reproducibility may need additional controls.
- Fine-grained hands and intricate interactions depend on dedicated encoders and sufficient data.
- Safety, ethics, and legal
- Motion and identity consent are distinct; policy tooling should respect both. Strong need for watermarking, disclosure, and moderation to mitigate deepfake misuse.
- Bias and fairness audits are necessary, especially for health/sports applications.
- Engineering and integration
- Real-time use requires model distillation/acceleration and memory optimization.
- Production integration benefits from APIs, editor plug-ins, and consistent I/O formats (e.g., latent tokens, prompt templates).
- For downstream 3D workflows, optional export to parametric formats (e.g., SMPL refinement) may be needed despite the model’s implicit nature.
Collections
Sign up for free to add this paper to one or more collections.