- The paper proposes Language Movement Primitives (LMPs) that bridge high-level semantic planning with low-level continuous robot control.
- It leverages vision-language models to decompose tasks and parameterize Dynamic Movement Primitives, enabling precise and interpretable motion planning.
- Experimental results show an 80% success rate on 20 tabletop tasks, outperforming baseline methods through structured decomposition and integrated feedback.
Language Movement Primitives: Grounding Foundation Models in Dynamic Robot Control
Introduction
"Language Movement Primitives: Grounding LLMs in Robot Motion" (2602.02839) introduces Language Movement Primitives (LMPs), a hierarchical policy framework unifying high-level vision-LLM (VLM) reasoning with low-level continuous control for zero-shot robotic manipulation. The framework leverages VLMs for semantic scene understanding, task decomposition, and parameterization of Dynamic Movement Primitives (DMPs), thus directly connecting foundation model reasoning with interpretable and stable robot motion. The paper addresses the fundamental disconnect between symbolic, language-conditioned reasoning and the physical actuation demands of manipulation, combining elements from foundation models, neuro-symbolic planning, and control-theoretic primitives.
Figure 1: Overview of the LMP pipeline where user instructions are decomposed, parameterized into DMPs, and tracked by the robot for zero-shot manipulation.
Background and Motivation
High-level VLMs have demonstrated impressive capabilities in parsing environment observations and decomposing tasks semantically. However, these models lack grounding in robotics actuators, leading to proposals that do not map cleanly to robot controllers. Alternatively, robotics foundation models trained on in-domain datasets or via reinforcement learning can issue executable commands, but require substantial task-specific fine-tuning and fail to generalize broadly. Existing hybrid (neuro-symbolic) approaches typically reason over discrete action primitives, imposing bottlenecks for expressive, continuous trajectory generation and impeding adaptation to nuanced manipulation requirements. LMPs aim to generalize across these paradigms by exposing a parameter space—the DMP coefficients—that is both semantically meaningful for the VLM and effective for continuous low-level control.
LMP Architecture and Algorithmic Pipeline
LMP formalizes robot policy as a mapping from language instructions and scene observations to DMP parameters in each degree of freedom. The architecture decomposes into three stages: state summarization, subtask identification, and DMP parameter generation. The process can be summarized as:
- Perceptual Grounding: The robot collects RGB-D observations, segments objects and estimates their 3D poses via open-vocabulary visual classifiers, and auto-generates a textual state description.
- Task Decomposition: The VLM parses the user instruction and state, recursively decomposing the overall task into templated subtasks linked to scene entities.
- DMP Parameterization: For each subtask, the VLM outputs the DMP weights for all operational DOFs, the end-effector goal offsets, and auxiliary parameters, enabling fine-grained trajectory shaping in the continuous domain.
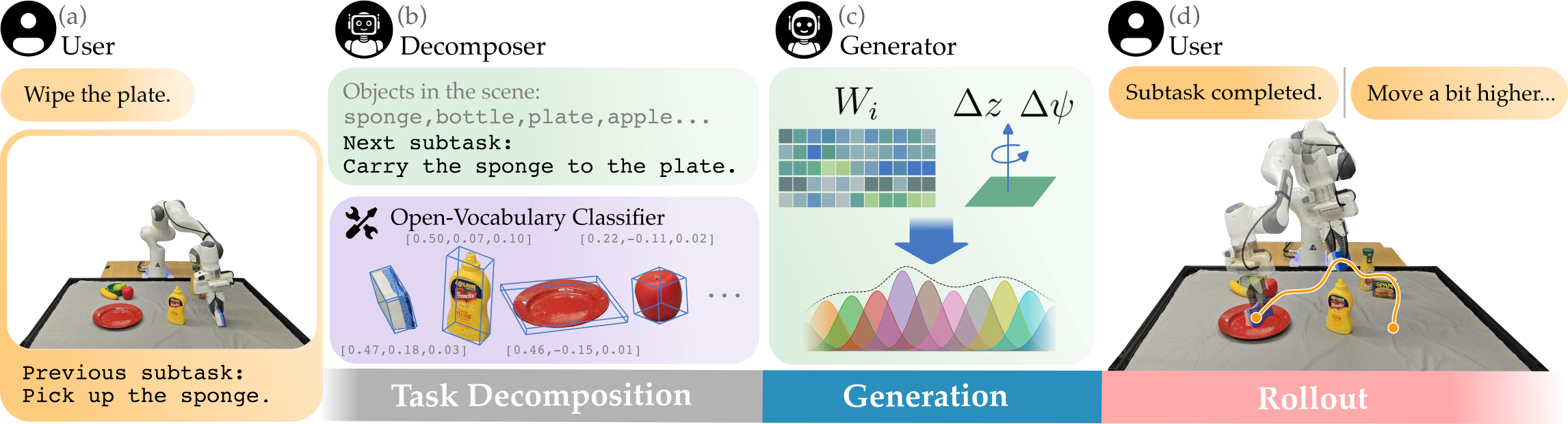
Figure 2: Detailed pipeline of the LMP system, from task description, scene perception, subtask decomposition, DMP generation, to feedback-based correction.
Dynamic Movement Primitives are parameter-efficient representations that guarantee goal convergence and support trajectory shaping via weight vectors associated with a fixed basis expansion. The LMP leverages this structure by having the VLM generate both the basis weights and the terminal goal conditions referenced in Cartesian space. To close the loop, human (or automated) feedback can be introduced after each subtask, allowing iterative correction and update of the policy context—enabling efficient in-context correction on failure.
Experimental Results and Analysis
LMP is evaluated on 20 tabletop manipulation tasks, including pick-and-place, obstacle avoidance, relational reasoning, and inferred multi-stage assembly, using a 7-DoF Franka arm with an external RGB-D sensor. The method is benchmarked against TrajGen [Kwon2024Language], which synthesizes code-based waypoint trajectories from LLMs, and π0.5, a VLA foundation model requiring fine-tuning. LMP achieves 80% overall success rate, compared to 31% and 30% for the foundation model and TrajGen baselines, respectively. This performance gap is sustained across highly semantic tasks (e.g., under-specified instructions, spatial references) and those requiring non-linear trajectory composition (e.g., obstacle-rich manipulation or “wipe the plate” behaviors).

Figure 3: LMP achieves broad coverage of tabletop household manipulation tasks requiring semantic understanding, obstacle awareness, and spatial reasoning.
Ablation studies highlight the importance of both explicit task decomposition and feedback integration in the LMP pipeline. Removal of the judge (feedback) module reduces performance to 69%; eliminating structured decomposition further degrades success to 46%, with joint removal causing a collapse to 27%. Notably, the explicit grounding of subtask templates ensures that the DMP parameterization focuses on achievable motion segments, preventing semantic drift and mismatched abstraction levels.
Failure Modes and Insights
Analysis identifies dominant failure modes: task planning errors, incomplete semantic inference, suboptimal weight generation, premature trajectory convergence, and inadequate feedback utilization. Integration of a module for grounded decomposition and explicit feedback significantly mitigates planning and trajectory errors. In contrast, foundation models or LLM-code generation approaches without DMP grounding often fail in under-specified contexts or when complex, non-linear motion profiles are needed.
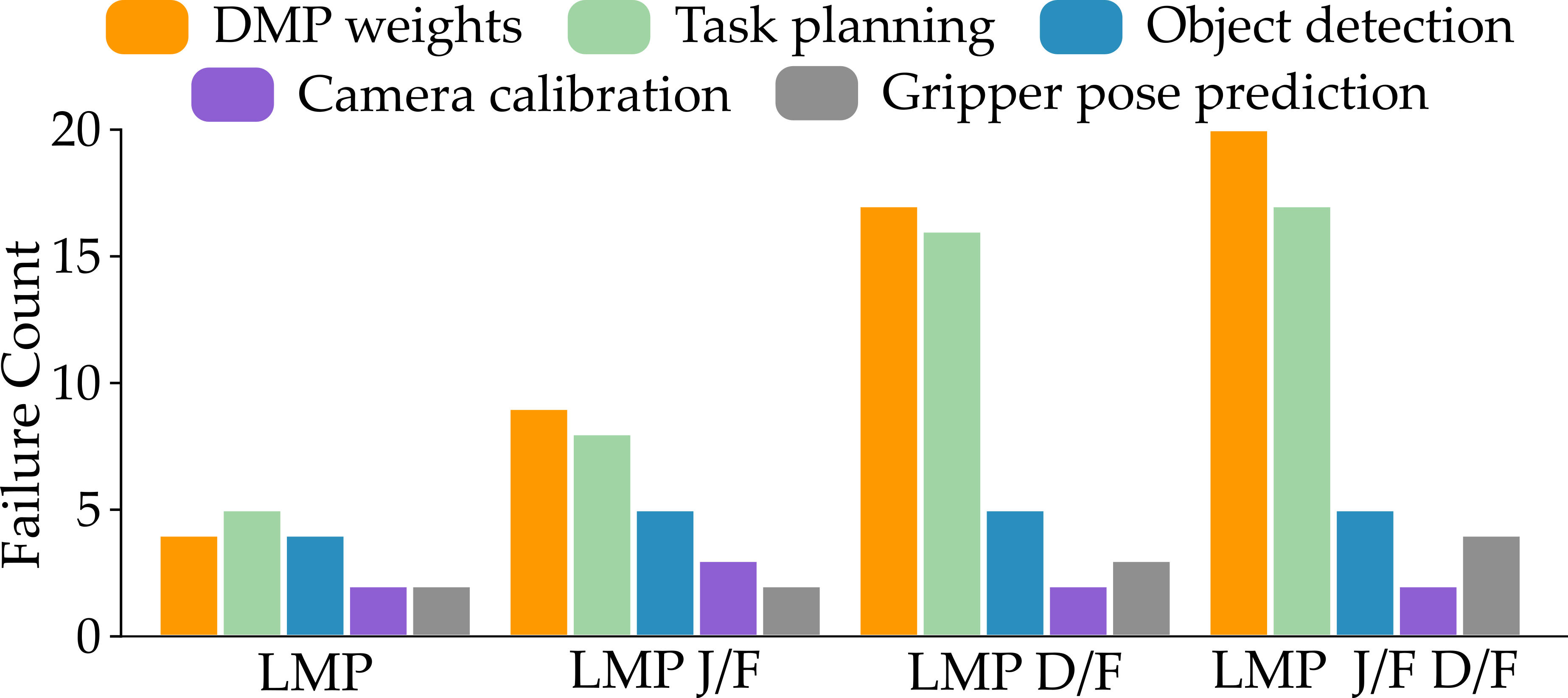
Figure 4: Systematic analysis of failure modes: grounded task decomposition and feedback significantly reduce dominant sources of error in planning and DMP weight generation.
Theoretical and Practical Implications
LMP demonstrates that DMP parameter space is an effective interface for VLMs to specify continuous, robust robot behaviors, bridging the divide between high-level intent and low-level control. By decoupling semantic task planning from motion representation—and exposing a small, interpretable set of parameters—the approach enables the deployment of foundation model capabilities in real-world manipulation without the need for demonstrations or in-domain fine-tuning. Practically, this paradigm supports zero-shot execution of novel tasks, rapid incorporation of user feedback, and adaptation to novel scene topologies. The modular structure also facilitates further extension with alternative VLMs, ontologies, or motion primitives.
Future Research Trajectories
Open challenges remain: the approach assumes the existence of a parameterization that is semantically interpretable and tractable by the VLM, constraining applicability to domains where control-theoretic primitives like DMPs are meaningful. Further, dynamic environments and feedback-latency bottlenecks are not directly addressed; future work will require dynamic modeling and autonomous judge architectures (e.g., VLM-based evaluators). Extending the framework to multi-arm, deformable, or closed-loop force interaction settings will test the generality of the parameter grounding hypothesis.
Conclusion
LMP presents a coherent, empirically validated architecture for language-driven robotic policy, advancing the integration of foundation model reasoning with robust, parameter-efficient continuous control. By introducing DMPs as a grounding medium, LMP achieves substantial improvements over both purely data-driven action models and symbolic neuro-symbolic approaches, without task-specific retraining. These results indicate that semantically structured parameterizations form an effective substrate for general-purpose embodied reasoning—pointing towards scalable, human-in-the-loop, zero-shot robotics.
(2602.02839)

