CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
Abstract: LLMs have achieved remarkable success in source code understanding, yet as software systems grow in scale, computational efficiency has become a critical bottleneck. Currently, these models rely on a text-based paradigm that treats source code as a linear sequence of tokens, which leads to a linear increase in context length and associated computational costs. The rapid advancement of Multimodal LLMs (MLLMs) introduces an opportunity to optimize efficiency by representing source code as rendered images. Unlike text, which is difficult to compress without losing semantic meaning, the image modality is inherently suitable for compression. By adjusting resolution, images can be scaled to a fraction of their original token cost while remaining recognizable to vision-capable models. To explore the feasibility of this approach, we conduct the first systematic study on the effectiveness of MLLMs for code understanding. Our experiments reveal that: (1) MLLMs can effectively understand code with substantial token reduction, achieving up to 8x compression; (2) MLLMs can effectively leverage visual cues such as syntax highlighting, improving code completion performance under 4x compression; and (3) Code-understanding tasks like clone detection exhibit exceptional resilience to visual compression, with some compression ratios even slightly outperforming raw text inputs. Our findings highlight both the potential and current limitations of MLLMs in code understanding, which points out a shift toward image-modality code representation as a pathway to more efficient inference.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple, bold question: can AI models understand computer code just by looking at pictures of it, instead of reading the text? The authors test “vision-LLMs” (AIs that can read both images and text) on images of code to see if this trick can save computing power and still work well. They introduce a tool called CodeOCR to turn code into images and study how well different models perform.
What are the main goals or questions?
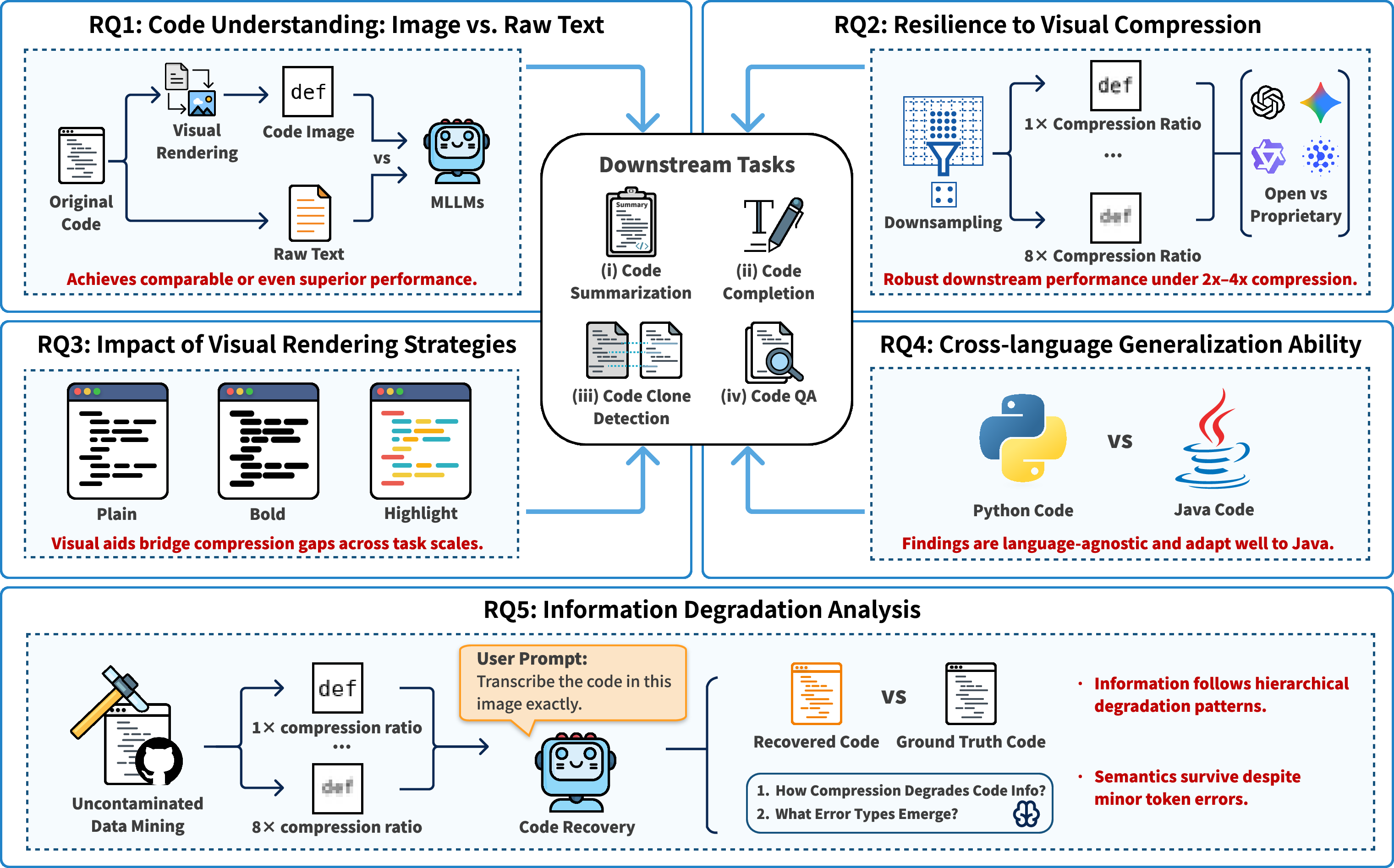
The paper explores five easy-to-understand questions:
- Can AI understand code shown as images as well as it understands normal text?
- If we shrink these code images (to use fewer “tokens,” which means less cost), how much can we compress them before performance drops?
- Do visual hints like syntax highlighting (colored text) or bold letters help the AI understand code images better?
- Does this work for more than one programming language (they test Python and Java)?
- When we compress images, what kinds of mistakes start to happen, and at what compression levels?
How did they do it? (Methods in everyday language)
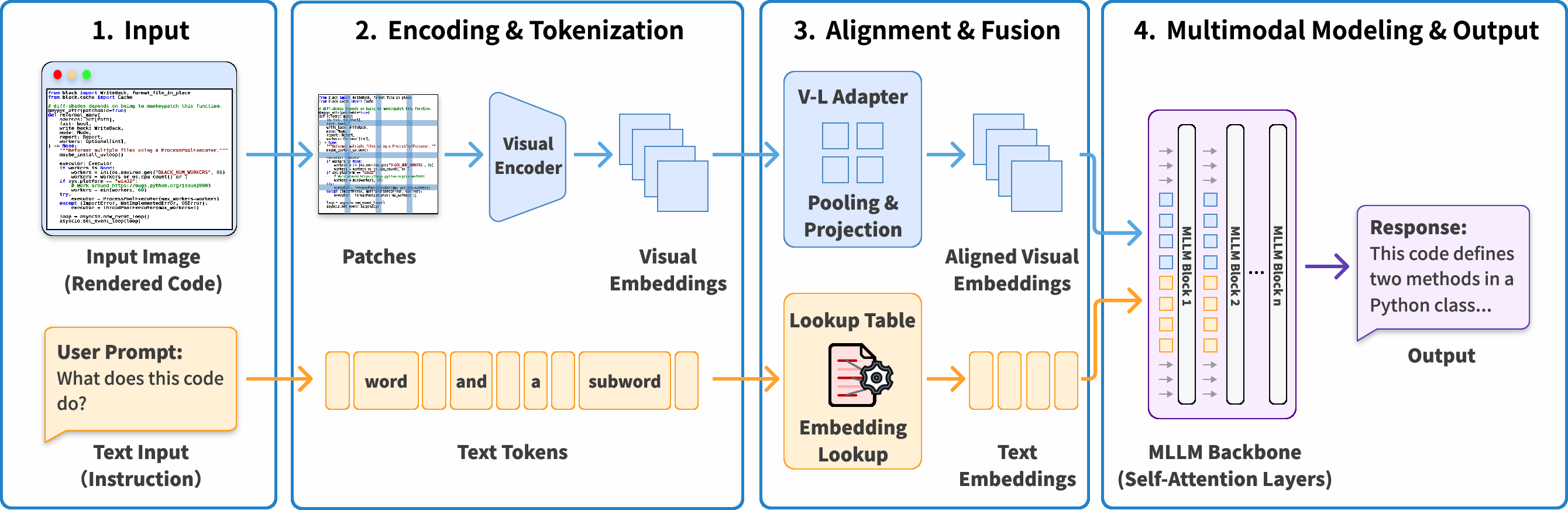
Imagine you have a page of code. Normally, an AI reads this as text, breaking it into tiny units called “tokens” (like chopping a sentence into small pieces or LEGO bricks). Reading lots of tokens is slow and expensive.
Instead, the authors turn code into images—like screenshots—then feed those images to vision-language AIs. Here’s the basic idea:
- Rendering code as images: The code is turned into clean pictures using a monospace font (like in a code editor). They also try versions with syntax highlighting (colored keywords) and bold text.
- Compression: To save cost, they shrink image size. It’s like making a photo smaller so it uses fewer tokens, but you can still make out the text. They test “1×, 2×, 4×, 8×” compression—8× uses only 12.5% of the tokens compared to the full text input.
- How the AI reads images: The AI chops the image into tiny patches (think of a photo split into tiles), turns each tile into a “visual token,” and mixes these visual tokens with normal text tokens (like the instruction “finish this code” or “answer this question”). Then it reasons over both together.
- Tasks they tested:
- Code completion: Finish a missing part of code. Think of it like finishing a sentence or completing a puzzle.
- Code summarization: Write a short doc summary for a long module. Like describing what a long recipe does.
- Clone detection: Decide if two different-looking pieces of code do the same thing. Like checking if two recipes make the same dish.
- Code question answering: Read code, then answer multiple-choice questions about it. Like a test based on a passage you read.
- Models: They evaluate seven modern vision-LLMs (including Gemini-3 and GPT-5 series, plus open-source models like Qwen-3-VL), and compare image inputs against normal text inputs.
- Fairness: For each sample, they match the “token budget” between text and image at 1×, then test higher compression to see what happens.
What did they find, and why does it matter?
Here are the core results explained simply:
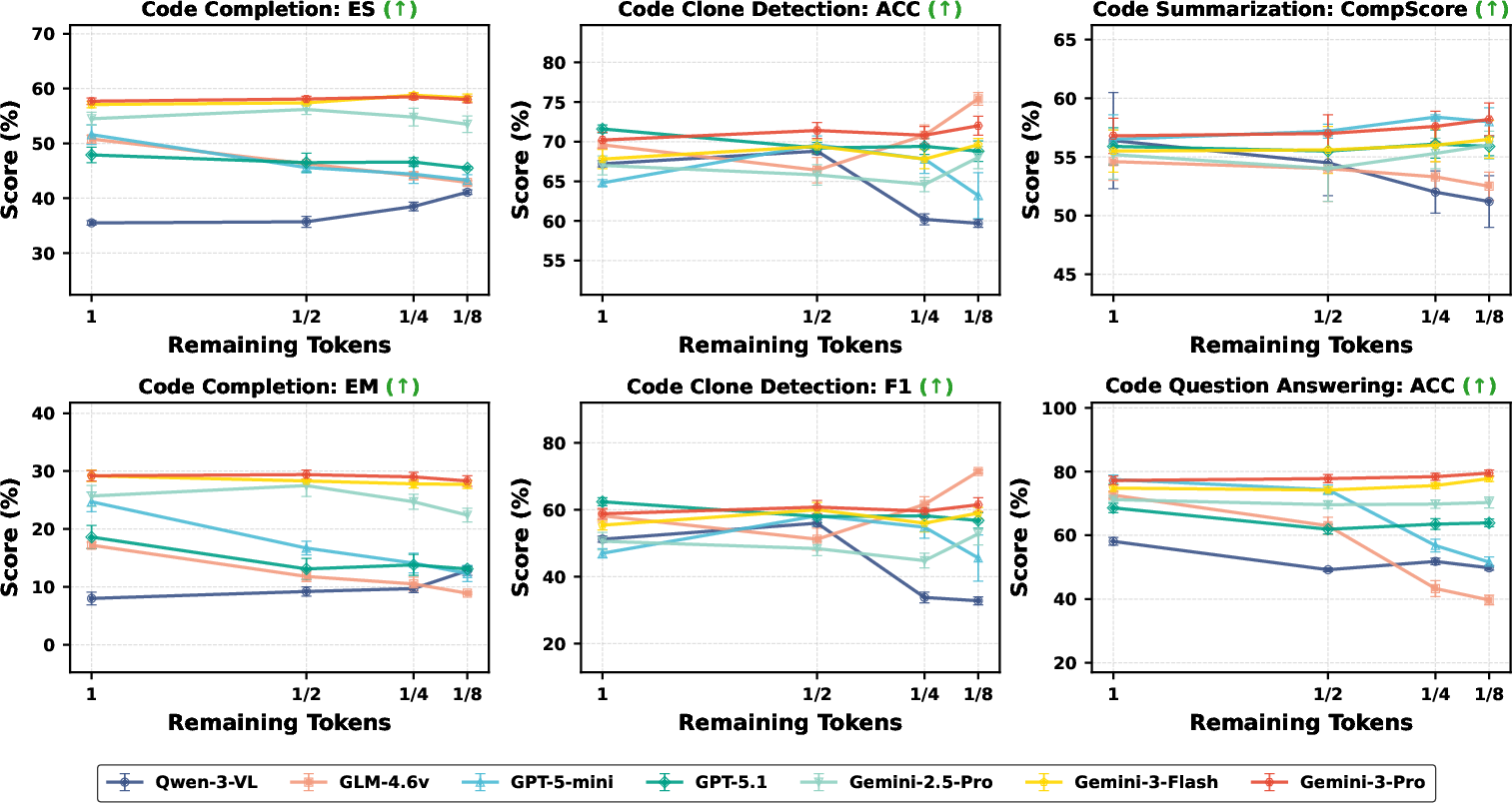
- Image-based code works, sometimes better than text:
- Several models understood code images as well as, or even better than, plain text.
- Example: For clone detection, GPT-5-mini improved its F1 score by about 42% using images instead of text.
- For code question answering, Gemini-3-Pro hit about 79.5% accuracy even at 8× compression, beating its text baseline (~74.8%).
- Big compression with small performance loss:
- Many models stayed strong even when the code images were shrunk a lot—up to 8× compression (using only 12.5% of tokens).
- This suggests a major way to save cost and stay within context limits for large projects.
- Visual cues help—up to a point:
- Syntax highlighting and bold text tended to help at low to moderate compression (1×–4×), where the image is still clear.
- At very high compression (8×), the benefits fade, and bold can even make things blurrier.
- Works across languages:
- The same trends held for Java, not just Python. That means the idea is general, not language-specific.
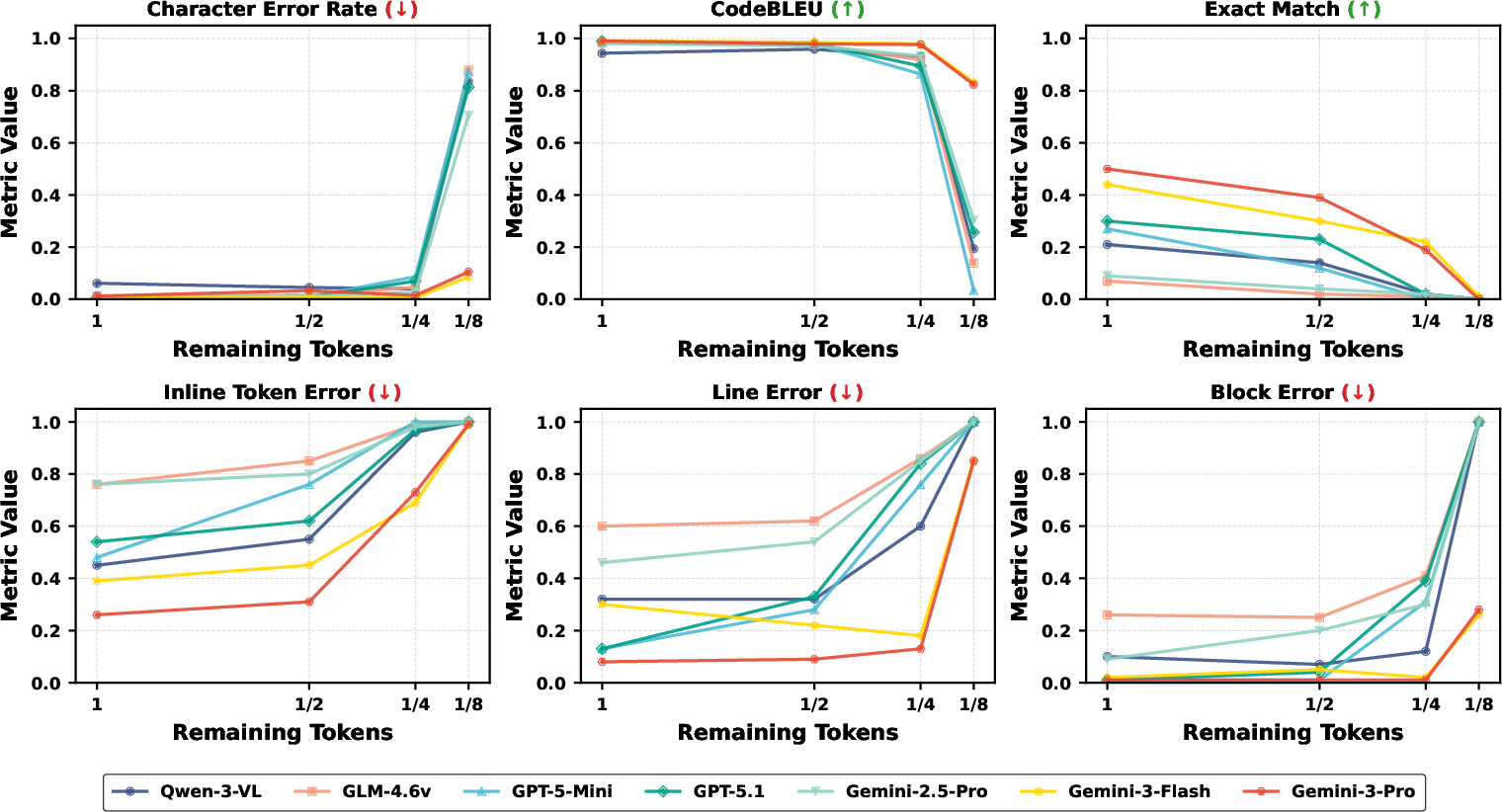
- What goes wrong when images get too small:
- At light compression, small “token-level” mistakes happen (like a single character or keyword error).
- At medium compression, “line-level” mistakes appear (missing or misread lines).
- At high compression, “block-level” mistakes show up (whole chunks misunderstood).
- Interestingly, small token mistakes don’t always hurt final results—the AI can often guess the right logic even if a few characters are blurry.
Why this matters: If AI can read code as images and still perform well, we can handle much bigger codebases for less cost. That’s crucial when working with long files or entire projects that exceed normal text token limits.
What does this mean for the future?
- More efficient AI coding tools: Representing code as images could make AI assistants cheaper and faster, especially for large-scale software.
- Design smarter code views: Adding helpful visuals (like syntax colors) can boost performance—if the images aren’t too compressed.
- Model improvements: Not all models performed equally. Stronger models (e.g., Gemini-3 and GPT-5 series) were consistently better with code images. There’s room to tune open-source models for image-based code understanding.
- New tools and workflows: The authors built CodeOCR to make it easy to render code to images with adjustable compression and visual styles. This could become a practical add-on for IDEs or AI pipelines.
In short: Turning code into images might sound odd, but it can save a lot of tokens and money while keeping performance high. With the right models and smart rendering, this approach could help AI understand huge codebases more efficiently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be concrete and actionable for future research.
- Real-world robustness: The study renders synthetic code images (fixed font, VSCode “Default Light”, bilinear downsampling). It does not evaluate robustness to real screenshots (variable fonts/themes, DPI, antialiasing, JPEG/PNG artifacts, window chrome, line wrapping). Assess performance on heterogeneous, noisy, real-world inputs.
- Language coverage: Experiments only include Python and Java. Evaluate languages with different scripts and syntax (e.g., C/C++, Rust, Go, Kotlin), whitespace-sensitive languages (e.g., Haskell), non-Latin/Unicode-heavy codebases (e.g., comments/identifiers in Chinese), and DSLs.
- Task breadth: Four tasks are covered; tasks requiring exact character-level fidelity (program repair/patch generation, refactoring edits, formatting, type annotation fixes, security vulnerability patching, code obfuscation/deobfuscation) are not evaluated. Test viability where single-character errors break correctness.
- Multi-file, cross-repo reasoning: Codebase-scale understanding (project-wide dependencies, multi-file navigation, build configuration, test integration) is not assessed. Benchmark multi-image, multi-file reasoning at realistic scales (e.g., 50–500 files, >200k tokens).
- Hybrid representations: The paper decouples code-as-image and instructions-as-text, but does not explore mixed inputs (e.g., critical tokens/identifiers in text plus broad context as image). Study optimal text–image partitioning strategies by task and compression level.
- Rendering design space: Only syntax highlighting and bolding are tested. Investigate richer visual cues: line numbers, indentation guides, bracket/structure overlays, semantic coloring (types/scopes), AST or CFG thumbnails, minimap, code folding indicators, error markers, or call graph insets—especially adaptive to compression.
- Compression method choices: Bilinear downsampling is fixed. Compare alternative compression/sampling (nearest-neighbor, bicubic, JPEG/WebP with controllable quality, super-resolution pre/post-processing) and their impact on OCR fidelity and downstream performance.
- Model-token calibration: “Equal tokens” are computed via visual patches vs text tokens, but visual tokenization varies across models (patch size, pooling, adapters). Establish a standardized calibration protocol across models to ensure fair budget matching and analyze sensitivity to patch size/alignment.
- End-to-end efficiency: Claims of token savings are not accompanied by measured latency, throughput, memory, and cost across providers. Quantify actual wall-clock speedups, GPU utilization, and dollar cost—including rendering overhead and multi-image I/O—under different compression settings.
- Fine-tuning and adapters: All results use off-the-shelf MLLMs at inference-time. Evaluate whether fine-tuning (or adapter/LoRA training) on code images improves accuracy, compression resilience, and error profiles; determine data scale required and transfer across tasks/languages.
- Architectural attribution: The paper observes model-dependent variation without probing visual encoder/backbone differences. Perform controlled ablations on open-weight models (encoder depth, patch size, V-L adapter pooling) to identify features that drive compression robustness.
- OCR mitigation strategies: The degradation analysis characterizes token/line/block error tiers but does not test mitigation. Evaluate pipelines combining external OCR, iterative zoom-in (“crop-and-read”), super-resolution, or hybrid OCR+LLM approaches, and quantify downstream gains.
- Multi-image sequencing/layout: Assumes models process multi-image inputs “in provided order” but does not study ordering/layout effects (pagination, headers, anchors, cross-page references). Design and test layout strategies that preserve code locality and semantic grouping.
- Dataset scale and leakage auditing: Aside from QA (newly curated), other datasets may overlap with model training corpora. Conduct leakage audits (n-gram overlap, repository provenance) and expand datasets to larger, diverse, time-bounded samples to reduce contamination.
- Evaluation reliability: Code summarization uses an LLM-as-judge (CompScore) without human correlation studies. Validate with expert human ratings, report inter-rater reliability, and examine judge-model bias (same-family advantages).
- Statistical rigor: Multiple Wilcoxon tests are run across models/tasks without multiple-comparisons correction. Apply corrections (e.g., Holm–Bonferroni) and report effect sizes to solidify significance claims.
- Failure mode taxonomy: The paper gives a high-level error tiering but lacks granular taxonomy (e.g., identifier confusions, punctuation/brace loss, indentation misreads, numeric literal errors). Build fine-grained error labels to target remediation techniques.
- Security and privacy: Image-based pipelines may alter risk profiles (e.g., embedded credentials in screenshots, exfiltration via images, metadata leakage). Assess privacy/security implications versus text pipelines and propose safeguards.
- Accessibility and developer ergonomics: The practical impact of image-based code on developer workflows (searchability, diffing, versioning, accessibility tools like screen readers) is not examined. Study integration with IDEs and DevOps tools, and human-in-the-loop usability.
- Generalization across themes and dark mode: Only a single light theme is used. Evaluate theme/style generalization (dark mode, high-contrast schemes), as color cues invert or saturate under compression and may affect recognition.
- Effect of line wrapping and long lines: Fixed rendering avoids arbitrary wrapping; real code often contains very long lines. Measure performance when wrapping/cropping occurs and develop wrapping-aware rendering policies.
- Navigation strategies at scale: No methods are proposed for “read-large-codebase” strategies (e.g., hierarchical thumbnails, overview+detail). Explore multiscale representations that combine low-res overview with high-res focus crops guided by the model.
- Economic sensitivity: Assumption of parity between text and image token pricing may change. Analyze sensitivity under varied pricing models and provider tokenization schemes to determine when image modality is cost-effective.
- Reproducibility under model drift: Proprietary APIs evolve over time. Establish reproducible baselines with pinned versions, document parameter seeds, and monitor performance drift to ensure stable conclusions.
- Interaction with comments and documentation: The influence of natural-language comments (fonts, italics, hyperlinks) in images on comprehension is not studied. Evaluate how comment density and style affect performance and whether separate text extraction helps.
- Impact on exact compilation/execution: Visual inputs can obscure whitespace/significant characters (tabs vs spaces in Makefiles, invisible Unicode). Test tasks where exact reproduction/execution is required and design renderings that preserve such signals under compression.
- Tooling overhead: CodeOCR’s rendering cost (time/CPU/GPU), pipeline reliability, and integration friction are not reported. Benchmark rendering throughput and provide guidelines for production deployment.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging CodeOCR and the paper’s empirical findings on visual code understanding, compression resilience, and visual cue design.
- Software engineering: Token-cost reduction for code assistants and RAG pipelines
- What: Integrate CodeOCR to render retrieved code context as images at 2×–8× compression, with syntax highlighting at 1×–4×, for tasks like completion, QA, and summarization.
- Why: Comparable or better task performance versus text while cutting context tokens and cost; Gemini-3 series and GPT-5 family showed strong robustness; QA remained strong at 8× for top models.
- Tools/workflow: IDE extension or server-side middleware that auto-renders relevant files to images, chunks long files into multi-image inputs, and selects compression per task.
- Assumptions/dependencies: Requires MLLMs with reliable multimodal support and pricing parity for visual tokens; performance varies by model family (Gemini-3 ≥ GPT-5 > current open weights); must respect provider image-size limits and patch-size divisibility; multi-image ordering preserved.
- DevOps/Code review: Large-diff summarization and risk triage under tight token budgets
- What: Feed PR diffs as images (with highlighting of additions/deletions) for LLM-generated summaries, impact analysis, and risk flags.
- Why: Summarization via images is on par with text; visual cues help models perceive structure holistically; compression allows full diffs to fit in context.
- Tools/workflow: CI bot that renders diffs, selects 2×–4× compression with highlighting, escalates to 1× for ambiguous sections.
- Assumptions/dependencies: Adequate rendering quality; extreme compression may blur fine-grained tokens—reserve 1×–2× for critical sections.
- AppSec/Compliance: Faster semantic clone detection across repositories
- What: Use image-based pairwise analysis for Type-4 (semantic) clones to flag potential license or vulnerable clone propagation.
- Why: GPT-5 series improved F1 significantly with images; moderate compression can act like denoising, emphasizing semantics over syntax.
- Tools/workflow: CI stage that screens for clones at 4×–8× for breadth, then zooms to 1×–2× on candidates before enforcement.
- Assumptions/dependencies: Threshold tuning to manage false positives; model choice matters (top-tier models recommended); legal sign-off for enforcement actions.
- Developer enablement: Code QA bots for very large repositories
- What: Organization-internal QA assistants that answer questions using long, multi-file code contexts rendered as images.
- Why: Gemini-3-Pro outperformed its text baseline at 8× compression; multi-image inputs preserve ordering and coverage.
- Tools/workflow: Slack/ChatOps integration with adaptive compression and “zoom-in-on-demand” for follow-ups.
- Assumptions/dependencies: Security review for sending code to third-party LLMs; consider self-hosted multimodal models if needed.
- Technical documentation at scale: Module and API summarization
- What: Generate documentation for large modules by rendering files to images and prompting for summaries.
- Why: Summarization quality with images matches text; compression allows multi-file coverage.
- Tools/workflow: Nightly doc jobs using 2×–4× compression with syntax highlighting for readability.
- Assumptions/dependencies: For highly detailed API docs, fallback to 1× for precision; ensure font/theme consistency.
- MLOps/PromptOps: Token-aware middleware for adaptive rendering
- What: A “compression controller” that auto-selects resolution (1×/2×/4×/8×) and visual cues (highlighting/bold) by task and model.
- Why: Visual enhancements help most at 1×–4× but not at 8×; different tasks show different resilience profiles.
- Tools/workflow: Policy engine that routes tasks to models and rendering presets; monitors latency/cost/quality.
- Assumptions/dependencies: Requires per-model calibration; continual monitoring as providers update models and pricing.
- Individual developers: Practical context packing to stay within LLM limits
- What: Use CodeOCR to capture large files and related snippets as images to fit the assistant’s context window and budget.
- Why: Maintains performance while avoiding copy/paste and token overruns; works with Gemini-3 and GPT-5 assistants now.
- Tools/workflow: Lightweight local tool or IDE plugin bundling code images into a single multimodal prompt.
- Assumptions/dependencies: Visual token pricing; image upload limits in the chosen client.
- Academia/Benchmarking: Leakage checks and evaluation hygiene
- What: Adopt NoCtx baselines and curated, validated QA sets to ensure models use code context rather than memorization.
- Why: The paper uncovered QA leakage; image modality isolates code content and instruction streams for cleaner evaluation.
- Tools/workflow: Benchmark harness that runs NoCtx, Text, and Image variants; publishes per-task compression curves.
- Assumptions/dependencies: Community adoption; agreement on LLM-as-judge settings and protocols.
- Procurement/Policy: Vendor selection guided by compression resilience
- What: Evaluate candidate models’ quality-cost curves across 1×–8× compression for your tasks before committing.
- Why: Strong model heterogeneity; top-tier multimodal models stay robust under compression and lower costs.
- Tools/workflow: RFPs requiring multimodal benchmarks; pilot runs on your code and tasks.
- Assumptions/dependencies: Access to representative code and internal acceptance testing; evolving provider capabilities.
Long-Term Applications
These opportunities require further model optimization, productization, standardization, or organizational change.
- Software and security: Tiered “zoom” pipelines for large-scale analysis
- What: Enterprise systems that screen entire codebases at 8× for coarse detection (clones, hotspots), then “zoom in” to 2×–1× on flagged regions.
- Why: Degradation analysis shows predictable error tiers (token → line → block); robust at 4×–8× for coarse tasks.
- Tools/products: Orchestrators with automatic re-rendering, uncertainty estimation, and escalation policies.
- Dependencies: High-quality uncertainty metrics; integration with SCM/CI; model reliability guarantees.
- CodeVision models: Multimodal encoders trained specifically on code images
- What: Train vision encoders on code screenshots with syntax themes, indentation patterns, and multi-language corpora.
- Why: Current gains are achieved without targeted optimization; dedicated pretraining should lift accuracy and compression tolerance.
- Tools/products: Open-weight CodeVision backbones; adapters for AST overlays; task-tuned checkpoints.
- Dependencies: Large, diverse code-image datasets; compute; licensing for code corpora.
- Hybrid representations: Image + structured code signals (AST/CFG/bytecode)
- What: Fuse code images with AST/CFG to retain semantic precision while keeping context compact.
- Why: Images give global structure and token efficiency; structured signals anchor exact semantics when needed.
- Tools/products: Multimodal fusion frameworks; adapters mapping AST nodes to visual regions.
- Dependencies: Robust alignment between visual tokens and code structure; training objectives; evaluation suites.
- Enterprise code search and clone detection via visual embeddings
- What: Use vision encoders to index code “scenes” for semantic search robust to refactoring and style changes.
- Why: Visual encoders emphasize structural patterns, improving Type-4 clone recall.
- Tools/products: “CodeVision Search” appliances; visual embedding stores; cross-repo compliance monitors.
- Dependencies: Scalable vector infra; deduplication; precision/recall guarantees for audit contexts.
- Compliance and DLP modernization for code-in-images
- What: Update data loss prevention to detect and govern source code in images and screenshots.
- Why: As teams adopt image-based workflows, code can bypass text-only DLP.
- Tools/products: Code-aware OCR detectors; policy packs covering multimodal flows.
- Dependencies: Accurate code OCR across languages/themes; organizational policy updates; user training.
- Standards and interoperability: Code-image packaging and metadata
- What: Define a portable format that bundles code images with line/column maps, fonts/themes, and page order.
- Why: Ensures reproducibility across providers and stable multi-image ordering.
- Tools/products: Open spec and SDKs; converters for common IDEs/CI systems.
- Dependencies: Community and vendor buy-in; backward compatibility; accessibility considerations.
- On-device and mobile assistants for real-world code capture
- What: Capture whiteboard or projector code with a camera, then reason locally or with hybrid offloading.
- Why: OCR-style reconstruction remained strong at moderate compression; useful for classes, interviews, and field work.
- Tools/products: Lightweight VLMs optimized for code scenes; privacy-preserving edge inferencing.
- Dependencies: Efficient local models; hardware acceleration; robust low-light and glare handling.
- Cross-language and domain extensions
- What: Extend beyond Python/Java to C/C++, Rust, Go, Swift, and domain DSLs (e.g., Verilog, SQL).
- Why: The paper shows cross-language trends for two languages; broader support expands utility.
- Tools/products: Language-aware renderers (linters, themes, glyph sets); per-language calibration.
- Dependencies: Benchmarks, training data, and font/rendering nuances per language; mixed right-to-left scripts.
- Energy- and cost-aware CI/CD optimization
- What: Profile and minimize carbon and cost by favoring image compression modes where quality is maintained.
- Why: Visual compression reduces tokens and API costs; scheduling can align with green energy windows.
- Tools/products: CI controllers with sustainability policies; dashboards tracking quality-cost-energy trade-offs.
- Dependencies: Provider transparency on energy; stable performance under compression; governance targets.
- Education and assessment: Robust multimodal auto-grading
- What: Grade photographed or scanned code (exams, whiteboards) with multimodal models that understand highlighting and layout.
- Why: Visual cues help interpret structure and intent; resilient to handwriting or projector blur with proper training.
- Tools/products: LMS integrations; rubrics aligned to visual+semantic understanding.
- Dependencies: Datasets of handwritten/board code; fairness and bias evaluation; academic integrity controls.
Key assumptions and dependencies across applications
- Model capability: Results depend heavily on top-tier multimodal LLMs (e.g., Gemini-3 family, GPT-5 series). Open-weight models currently trail on some tasks.
- Pricing and limits: Visual-token pricing parity and image-size limits vary by provider and may change; check patch sizes and input caps.
- Rendering quality: Font, syntax theme, spacing, and bilinear downsampling affect legibility—especially beyond 4× compression.
- Task sensitivity: Fine-grained tasks (exact diffs, minified code) require lower compression; highlighting helps mainly at 1×–4×.
- Security and privacy: Images still constitute code disclosure. Apply the same governance and DLP controls used for text; update policies for multimodal flows.
- Generalization: Trends shown for Python and Java likely extend, but domain-specific languages and non-Latin scripts need validation.
Glossary
- Alignment modules: Components that map modality-specific embeddings into a common space before fusion. "The visual and text tokens are processed through separate alignment modules before fusion."
- Bilinear downsampling: An image resizing method that interpolates pixel values using a weighted average of the four nearest neighbors. "We then apply bilinear downsampling to reach the exact target resolution corresponding to the desired à compression."
- CodeBLEU: A code-specific evaluation metric combining syntax, data flow, and n-gram matches to assess generated code quality. "the Gemini-3 family maintains stability with high CodeBLEU even at 8Ã compression."
- Code images: Rendered screenshots of source code used as visual inputs for multimodal models. "representing source code as rendered images (i.e., code images) could provide a more scalable and computationally efficient alternative to traditional text representations."
- CompScore: An LLM-judged documentation quality metric comparing generated summaries to ground truth. "We adopt CompScore~\citep{bogomolovLongCodeArena2024}, an LLM-as-judge metric where DeepSeek-V3.2~\citep{deepseekai2024deepseekv3} compares generated documentation against ground truth with bidirectional averaging to mitigate ordering bias (scores range 0--100, where 50 indicates parity)."
- Compression ratio: The factor by which visual tokens are reduced relative to text tokens for the same content. "We define compression ratio à such that the visual token count equals exactly $1/k$ of the original text token count;"
- Context-window constraints: Limits on the maximum number of tokens a model can process in one input. "This flexibility highlights the potential of code images to alleviate the high inference costs and context-window constraints faced by current LLMs"
- Edit Similarity (ES): A code-completion metric measuring closeness to ground truth using token-level edit distance. "We use Exact Match (EM) and Edit Similarity (ES)~\citep{guo2023longcoder} for evaluation:"
- Exact Match (EM): A strict metric that requires the generated output to exactly match the ground truth. "We use Exact Match (EM) and Edit Similarity (ES)~\citep{guo2023longcoder} for evaluation:"
- Levenshtein distance: The minimal number of token insertions, deletions, or substitutions required to transform one sequence into another. "ES captures partial correctness via token-level Levenshtein distance."
- LLM-as-judge: An evaluation setup where a LLM serves as an automatic judge of output quality. "an LLM-as-judge metric where DeepSeek-V3.2~\citep{deepseekai2024deepseekv3} compares generated documentation against ground truth"
- MLP: A multilayer perceptron used here to project concatenated visual features into aligned embeddings. "T_v = \text{MLP}(\text{Concat}(v_{i,j}, v_{i+1,j}, v_{i,j+1}, v_{i+1,j+1}))"
- Multimodal LLMs (MLLMs): LLMs that process and integrate multiple input modalities, such as text and images. "The rapid advancement of Multimodal LLMs (MLLMs) introduces an opportunity to optimize efficiency by representing source code as rendered images."
- OCR-style code reconstruction: A task where models reproduce code text from images, akin to optical character recognition. "we perform OCR-style code reconstruction experiments, in which LLMs are required to reproduce the code content from compressed code images"
- Open-weight models: Models whose parameters are publicly available for download and local inference. "For open-weight models, we include Qwen-3-VL with 235B parameters~\citep{bai2025qwen3vltechnicalreport} and GLM-4.6v with 108B parameters~\citep{vteam2026glm45v}"
- Optical compression: Reducing information via image resolution scaling to lower token cost while retaining recognizability. "we explore the core advantage of the visual modalityâoptical compressionâby systematically varying resolution (RQ2)."
- Pooling: An operation that aggregates nearby features to reduce sequence length and emphasize salient information. "For instance, a pooling operation merges four patches:"
- Retrieval-Augmented Generation (RAG): A technique that retrieves relevant documents or code snippets to provide context for generation. "We apply Retrieval-Augmented Generation (RAG) to provide relevant code context"
- Syntax highlighting: Visual styling of code tokens (e.g., keywords, strings) to emphasize structure and semantics. "Can visual enhancements (e.g., syntax highlighting, bold rendering) further improve LLMs' understanding of code images?"
- Token pruning: Removing less important tokens to compress inputs at the potential cost of information loss. "text-based compression methods that achieve similar reduction ratios typically rely on token pruning"
- Type-4 (semantic) clones: Functionally identical code with different syntax/structure, requiring semantic understanding to detect. "focusing on Type-4 (semantic) clones---code pairs implementing identical functionality with different syntax and structure."
- V-L Adapter: A module that aligns visual features with language features via pooling and projection before fusion. "For visual tokens, a V-L Adapter applies pooling and projection to compress adjacent patches into aligned visual embeddings."
- Vision LLMs (VLMs): Models combining vision and language understanding within a unified architecture. "Vision LLMs (VLMs) that integrate visual understanding capabilities"
- Vision Transformer: A transformer-based visual encoder that processes images as sequences of patches. "A visual encoder (typically a Vision Transformer) converts these patches into visual embeddings:"
- Visual embeddings: Dense vector representations of image patches used by multimodal models. "A visual encoder (typically a Vision Transformer) converts these patches into visual embeddings:"
- Visual encoder: The component that converts images (or patches) into visual embeddings for downstream fusion. "A visual encoder (typically a Vision Transformer) converts these patches into visual embeddings:"
- Visual tokens: Discrete units representing image patches after encoding, analogous to text tokens. "the visual token count is ."
- Wilcoxon signed-rank test: A non-parametric statistical test for comparing paired samples. "We use the Wilcoxon signed-rank test~\citep{wilcoxon1945individual} to assess statistical significance between Text and Image inputs."
Collections
Sign up for free to add this paper to one or more collections.