- The paper presents a unified framework for selective knowledge distillation by decomposing it into position, class, and sample axes.
- It introduces Student Entropy-guided KD (SE-KD) that selects the top 20% uncertain tokens, yielding improved accuracy and efficiency over full distillation.
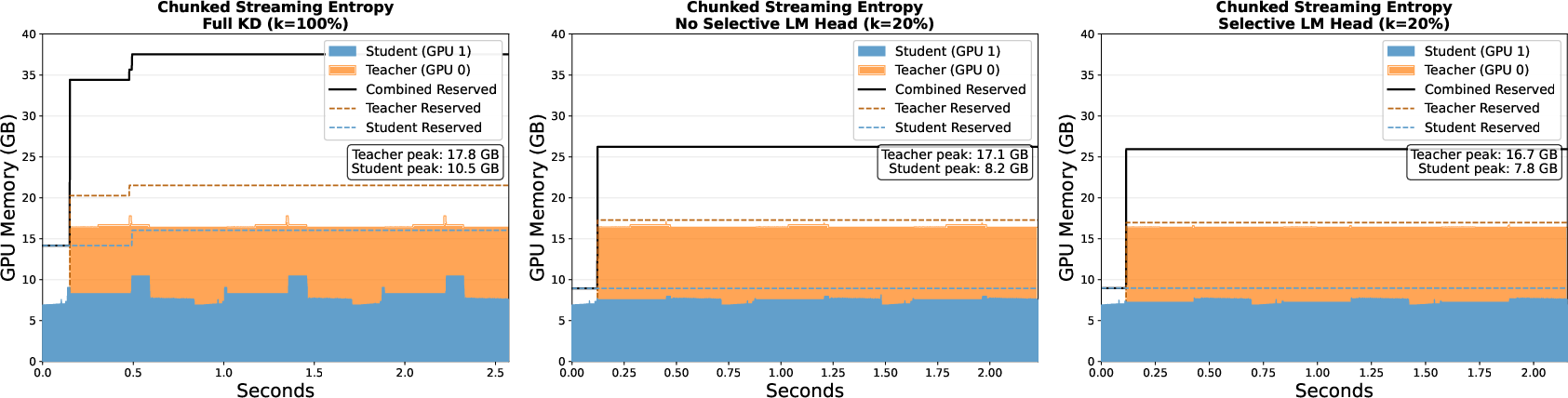
- The method reduces storage, runtime, and memory demands significantly, enabling scalable deployment of large language models.
Rethinking Selective Knowledge Distillation: A Systematic Analysis and Unification of Multi-Axis Selection Strategies
Introduction
This paper presents a formal analysis and systematic investigation of selective knowledge distillation (KD) for autoregressive LLMs. It reconceptualizes distillation not as a blanket process over all sequence positions, classes, and samples but as a structured, multi-axis selection problem. The authors decompose the selective KD landscape along the position, class, and sample axes and propose a unifying framework that situates prior methods and reveals underexplored directions. The contribution is both theoretical—in providing a rigorous framework—and practical, with the development and extensive empirical validation of Student Entropy-guided Knowledge Distillation (SE-KD), including its three-axis variant, SE-KD.
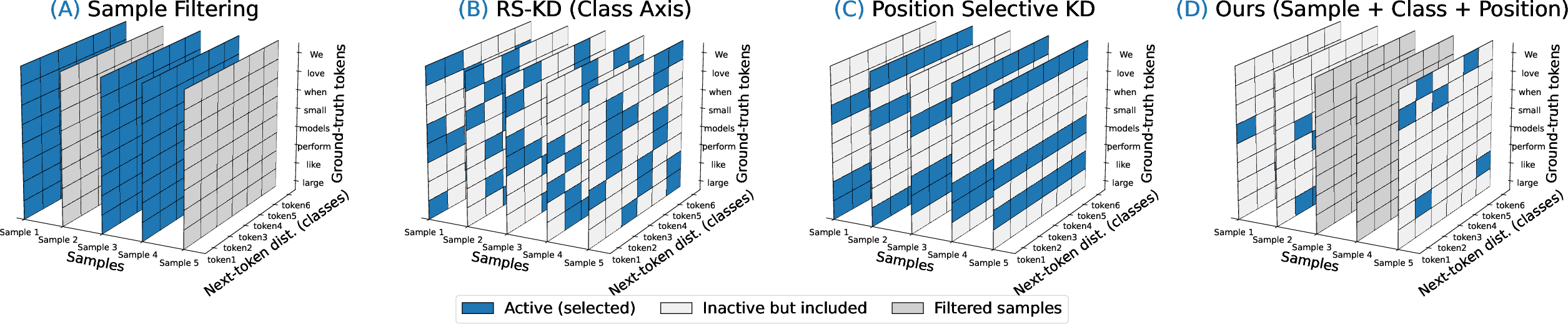
Figure 1: The three selection axes for knowledge distillation: (A) sample selection, (B) class sampling (RS-KD), (C) position-selective KD, and (D) the proposed SE-KD approach integrating all axes.
Unified Framework for Selective Knowledge Distillation
The core insight is that KD should be understood as a process with orthogonal axes of selectivity:
- Alignment criterion: The nature of the loss for teacher–student alignment, typically KL divergence or decoupled variants.
- Position axis: Token positions within sequences selected for distillation, guided by token-importance metrics.
- Class axis: Classes (vocabulary indices) over which the KL is computed, enabling sparse or sampled outputs.
- Sample axis: Subsets of training examples chosen for teacher supervision.
- Feature axis: (Not studied in depth, but noted as a future direction) Selection over internal representations.
This reframing clearly distinguishes between selection mechanism and the axis of selectivity, allowing both a comprehensive comparison of prior approaches and the identification of important, previously unstudied combinations—especially joint, multi-axis selectivity.
Analysis of Importance Metrics and Selection Policies
A thorough empirical study was conducted across nine importance metrics, five selection policies, and multiple established selective-KD baselines. Key findings are:
- Student entropy emerges as a robust signal on the position axis. Selecting the top 20% most uncertain positions (by student entropy) outperforms both dense (full) KD and random selection schemes, achieving 64.8 average accuracy and perplexity of 6.9.
- Teacher-based signals (entropy, CE) are less effective for position selection. Discrepancy-based metrics (teacher–student KL, CE ratio) are competitive and provide best-in-class calibration, but do not outperform student entropy in accuracy.
- Position selection policy matters: Deterministic Top-k positional supervision driven by student entropy is consistently strong. Curriculum and GLS provide marginal gains but introduce extra complexity and hyperparameters, while stochastic entropy-weighted sampling (RS-KD) underperforms, likely due to variance and coverage inefficiency.
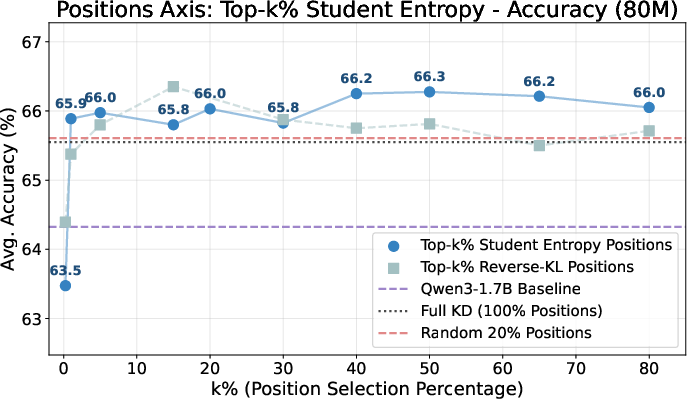
Figure 2: Performance as a function of the position axis supervision budget; Top-k% student-entropy and reverse-KL selection robustly outperform dense and random selection for k∈[1,20]%.
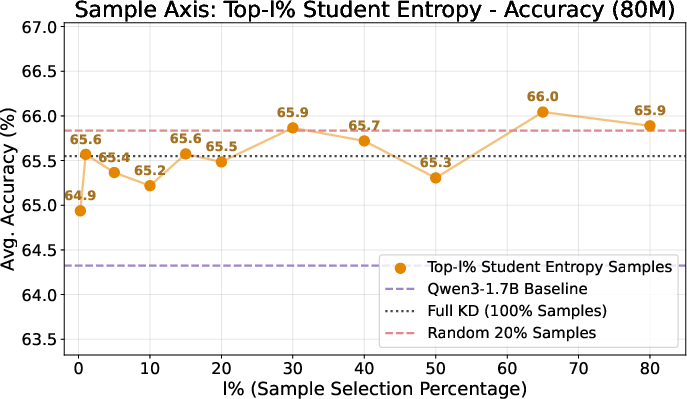
Figure 3: Variation in accuracy versus sample selection budget shows that distillation is robust to strong sample sub-selection, enabling significant computational gains with little trade-off in final performance.
Multi-Axis Selection: Efficiency and Practical Benefits
By leveraging selectivity along the class, position, and sample axes, the proposed SE-KD (SE−KD3-axis) not only preserves or improves accuracy but also yields substantial efficiency gains:
Empirical Results and Benchmarks
The approach is validated on a comprehensive suite of general and task-specific benchmarks, including HellaSwag, PIQA, Arc-E, GSM8K, and instruction-following (IFEval). The most salient results show:
- For general-purpose distillation: SE-KD provides non-trivial gains over Full KD (64.8 versus 64.4 in average accuracy), better perplexity (6.9), and instruction-following, while slightly increasing ECE due to sparser supervision.
- Task-specific distillation (e.g., math reasoning): The superiority of position selection is dataset-dependent; full KD can outperform SE-KD on smaller or homogeneous datasets (e.g., GSM8K) but multi-axis SE-KD remains highly competitive with much less supervision.
- Efficiency/cost analysis: Sample-level selection is the dominant source of runtime savings, while class-level selection is essential for lowering storage.
Theoretical and Practical Implications
The findings have significant implications:
- Dense next-token KD is unnecessary: Focusing supervision on high-uncertainty tokens brings efficiency with equal or superior student performance.
- Multi-axis selectivity is feasible and beneficial: Achieving strong trade-offs in both accuracy and cost by composing selection strategies.
- SE-KD enables resource-constrained deployment and adaptation: Lower storage, memory, and runtime requirements widen the practical accessibility of advanced distillation for LLMs.
- Generalizability: The approach demonstrates strong transferability to on-policy and task-specific scenarios, suggesting extensibility to a wider range of settings and models.
The work also clearly outlines limitations—a single teacher–student pair is studied, and the apparent advantage of selective policies in generalized distillation doesn’t always transfer to small downstream datasets or tasks. Extending analysis to feature-level selection (hidden states, attention maps) and broader model families is a rich direction for future work.
Conclusion
This paper presents a principled re-examination of selective KD for LLMs, establishing a general framework, carefully dissecting axis- and signal-level design choices, and validating the strong empirical advantages of student-entropy-guided position selectivity. By extending selectivity to classes and samples, SE-KD not only improves distillation performance but also dramatically reduces computational and practical cost, enabling scalable and versatile deployment.
The formalism and evidence underscore that optimizing where and how to distill is as vital as what to distill, with direct implications for both the theory and practice of scalable LLM development. The work paves the way for further research into adaptive, efficient, and task-aware knowledge distillation, potentially integrating more complex selection and alignment mechanisms, broader model families, and richer forms of supervision.