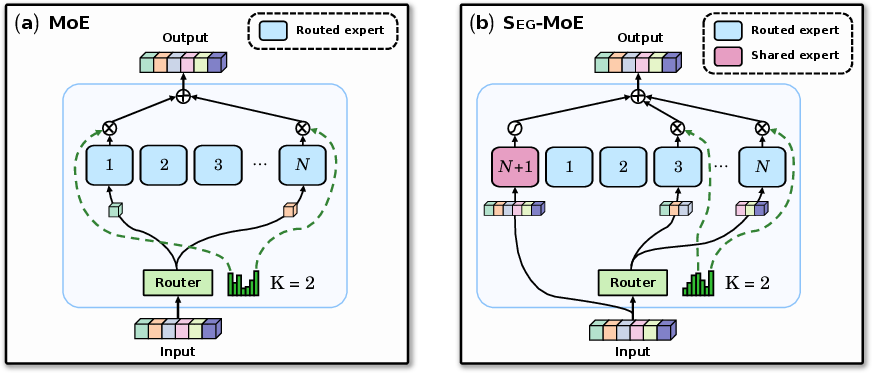
- The paper proposes a segment-wise routing mechanism that groups contiguous time steps, enhancing local temporal modeling in forecasting.
- It leverages multi-resolution segment schedules and a shared expert to balance prediction accuracy with computational efficiency.
- Empirical results on diverse benchmarks demonstrate superior performance over traditional token-wise MoE approaches.
Introduction
"Seg-MoE: Multi-Resolution Segment-wise Mixture-of-Experts for Time Series Forecasting Transformers" (2601.21641) addresses the longstanding challenge of efficiently scaling Transformer architectures for long-range, multivariate time series forecasting. While sparse Mixture-of-Experts (MoE) layers have proven effective for scaling in NLP and vision applications, their extension to time series has been limited by token-wise routing granularity, failing to leverage the temporal continuity intrinsic to sequential data. This work proposes Seg-MoE, a conditional sparsity mechanism that routes contiguous segments—rather than individual tokens—through expert subnetworks, tightly aligning the routing paradigm with the locality structure of real-world time series.
Transformer-based models have achieved substantial advances in sequence modeling, owing primarily to their parallelizability and capacity for modeling long-range dependencies. However, for long or high-resolution time series, quadratic computational overhead and memory consumption of attention mechanisms impede their practical deployment. Various modifications—such as sparse attention, patching, and channel independence—have been introduced to mitigate computational bottlenecks. Sparse MoE layers, which divide computation across several expert FFNs activated on a routing basis, have enabled parameter scaling in LLMs without proportional increases in inference cost [shazeer2017outrageously, fedus2022switch].
Despite this, standard MoE layers rely on independent token-wise gating, resulting in experts seldom specializing on local temporal features or recurring subsequences. In the context of time series, where patterns (e.g., oscillations, cycles, regime changes) manifest over contiguous intervals, expert fragmentation can diminish model fidelity and hinder accurate extrapolation. Previous efforts such as Time-MoE [shi2024time] and Moirai [liu2024moirai] have introduced MoE for time series, but continue to apply token-level gating, leaving the structured local dependencies underexploited.
Seg-MoE Architecture
Seg-MoE introduces a segment-wise routing and processing paradigm. Instead of routing each token (time step) independently, the input sequence is partitioned into contiguous, non-overlapping segments. Each segment is embedded, optionally flattened, and routed jointly to a subset of K out of N available expert networks according to a trainable gating mechanism. Each expert operates over the entire segment, capturing intra-segment dependency, enabling the model to internalize local motifs, dynamic structure, and abrupt transitions.
Critical architectural features include:
Empirical Evaluation
The authors evaluate Seg-MoE extensively across seven standardized multivariate time series forecasting datasets, including challenging benchmarks such as ETTh1/2, ETTm1/2, Weather, ECL, and Traffic. Metrics include mean squared error (MSE) and mean absolute error (MAE) over multiple forecast horizons (H∈{96,192,336,720}).
Key observations:
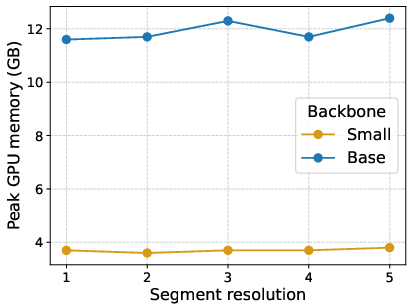
Ablation and Efficiency
Comprehensive ablation studies demonstrate that:
- Segment-wise routing consistently outperforms token-wise routing (i.e., setting ω=1) for a range of N, K, and segment resolutions. Notably, no single segment size is optimal for all benchmarks—underscoring the need for multi-resolution architectures.
- Training memory costs remain comparable between Seg-MoE and standard MoE for moderate segment sizes.
Practical and Theoretical Implications
Seg-MoE highlights the importance of aligning architectural sparsity mechanisms with the native structure of temporal data. The segment-wise inductive bias enables efficient capacity scaling while enhancing robustness and fidelity for both short- and long-range dynamics. From a practical perspective, the sparsity and expert modularization of Seg-MoE unlock the deployment of larger, deeper models in resource-constrained forecasting applications (e.g., energy, traffic, climate), with higher accuracy per compute.
Theoretically, this architectural principle—i.e., matching the granularity of sparsity/routing with salient compositional structure—may be generalized to other sequential domains, pointing toward domain-tailored conditional computation in sequence modeling.
Future Directions
The Seg-MoE paradigm suggests several avenues for further investigation:
- Adaptive Segment Resolution: Learning segment sizes or adapting them dynamically during training/inference could further enhance representational flexibility.
- Expert Diversity: Integrating heterogeneous expert architectures (e.g., convolutional, recurrent) may allow the model to capture a broader set of temporal phenomena.
- Zero-Shot/Pre-trained Foundation Models: Scaling Seg-MoE with large-scale pre-training may enable universal forecasting models with strong domain transfer properties.
- Application to Anomalous, Irregular, or Nonstationary Series: Extending to highly irregular or event-driven sequential data, such as medical signals, could validate the generality of the segment-wise sparsity principle.
Conclusion
Seg-MoE represents a significant advancement in the modeling of time series with Transformers by introducing segment-level conditional sparsity aligned with temporal locality. Through extensive empirical study, segment-wise routing demonstrates clear advantages over token-level MoE architectures for long-term, multivariate forecasting across domains. The inductive bias inherent in Seg-MoE opens a new direction for the design of efficient and specialized sequence models, with potential impact extending beyond time series forecasting to general sequential data processing.