- The paper introduces a system that translates free-form sketches into animation code using Vision-Language Models and iterative human-AI clarification.
- It employs a three-stage workflow combining initial sketch mapping, ambiguity clarification cues, and local visual refinement for enhanced control.
- Empirical results reveal improved alignment, user satisfaction, and creative fluidity, supporting non-deterministic, open-ended animation design.
Introduction and Motivation
"SketchDynamics: Exploring Free-Form Sketches for Dynamic Intent Expression in Animation Generation" (2601.20622) interrogates the expressive limits of current sketch-based animation authoring paradigms. Prior systems have dominantly mapped sketches to fixed command vocabularies or pre-coded gesture libraries, significantly constraining the semantic bandwidth of dynamic intent expression (Figure 1). The authors identify that such rigidity is at odds with real-world storyboard and annotation practices in animation, where informal, abstract marks serve as open-ended communicative acts for both temporal and causal phenomena.
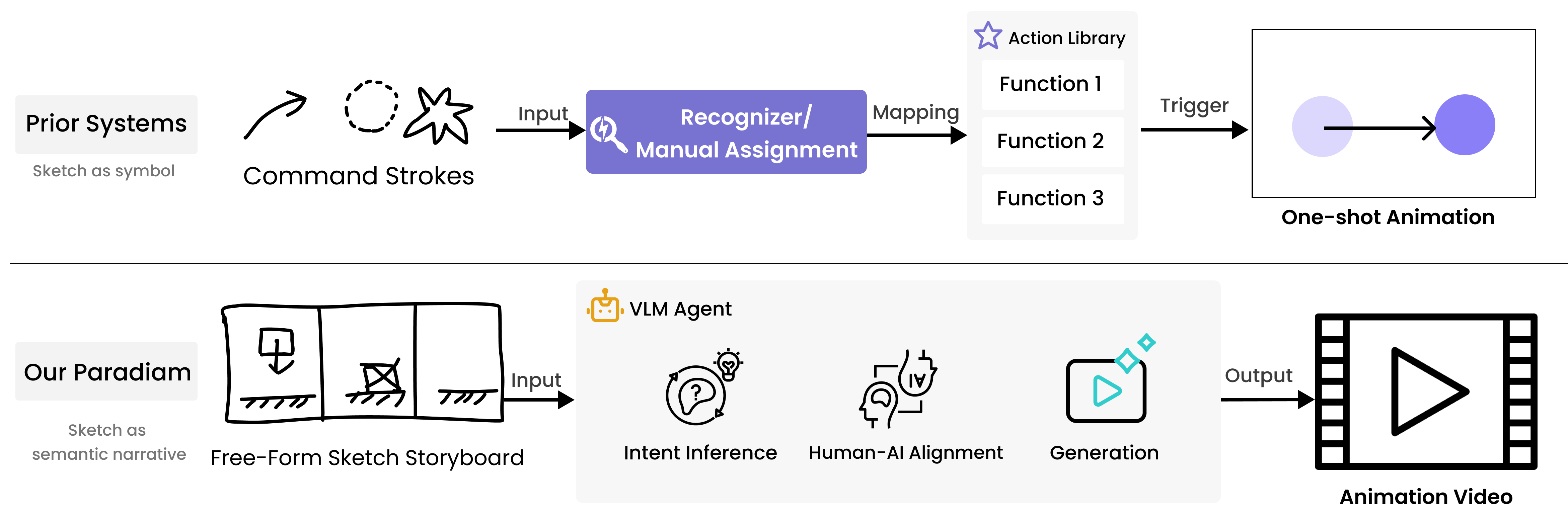
Figure 1: Prior systems (top) treat sketches as tokens mapping to fixed commands, while SketchDynamics (bottom) leverages VLM reasoning and interactive disambiguation to treat sketches as semantic motion expressions.
This work proposes a paradigm in which free-form sketches are interpreted as open, ambiguous prompts, their meaning disambiguated and specified through human–AI interaction cycles. The core premise is that Vision-LLMs (VLMs), with their emergent multimodal reasoning capabilities, serve as plausible interpreters of sketch input—though with significant uncertainty that necessitates user-driven clarification and refinement. The study focuses on explainer-style, code-generated motion graphics, favoring scenarios prioritizing clear motion semantics over photorealism or high-fidelity rendering.
SketchDynamics System and Interaction Design
The authors operationalize their paradigm in SketchDynamics, a proof-of-concept system for sketch-to-motion-graphics generation. The system underpins a three-stage workflow: (1) initial sketch-to-animation translation, (2) stepwise clarification of underspecified/ambiguous sketches, and (3) post-generation iterative visual refinement with contextual editing (Figure 2).

Figure 2: Study workflow: direct sketch input, clarification with user-driven cues, iterative refinement via contextual editing.
The interface allows users to sketch scene-level storyboards, annotate keyframes, and add optional text. A VLM (prompted with paired sketch/code exemplars) translates the sketch storyboard to executable vector-graphic animation code (via Manim), which is rendered as video previews (Figure 3). The study with mixed-experience users evidences that participants utilize highly diverse sketch conventions—ranging from arrows, onion-skinning, sequential indexing, to symbolic marks—underlining the expressive and interpretive variance inherent in unconstrained sketching (Figure 4).
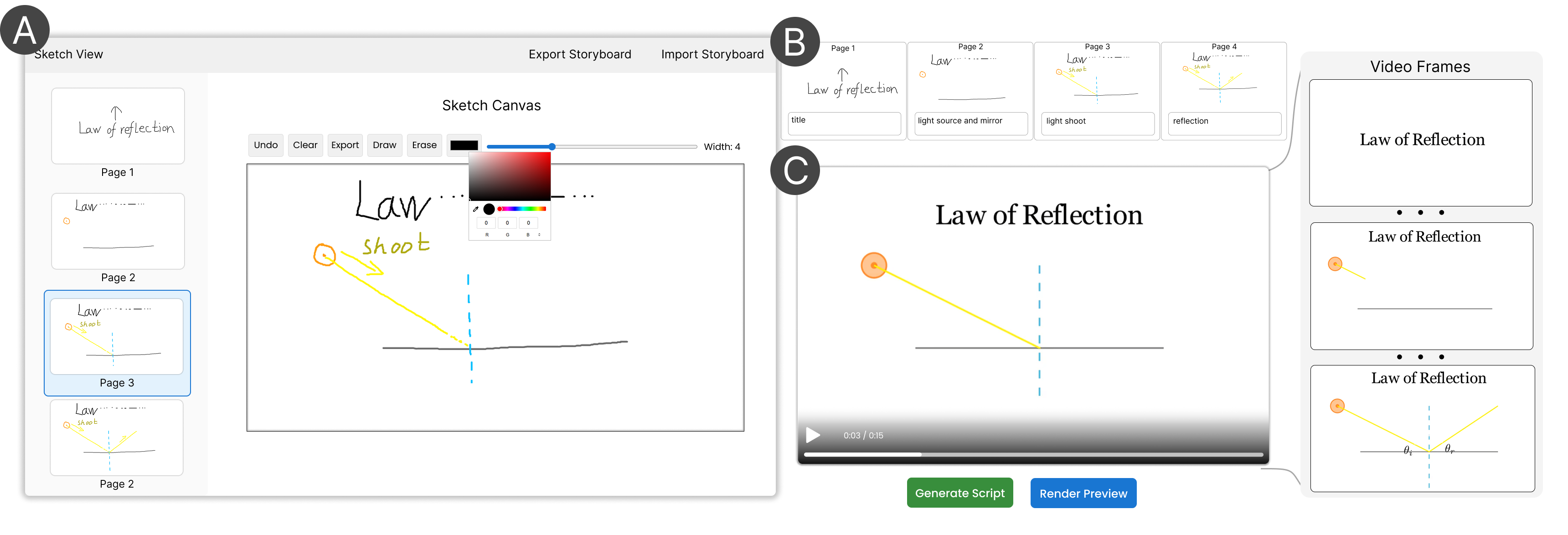
Figure 3: Stage 1 interface, supporting frame-level storyboard sketching, annotation, and code-driven preview generation.
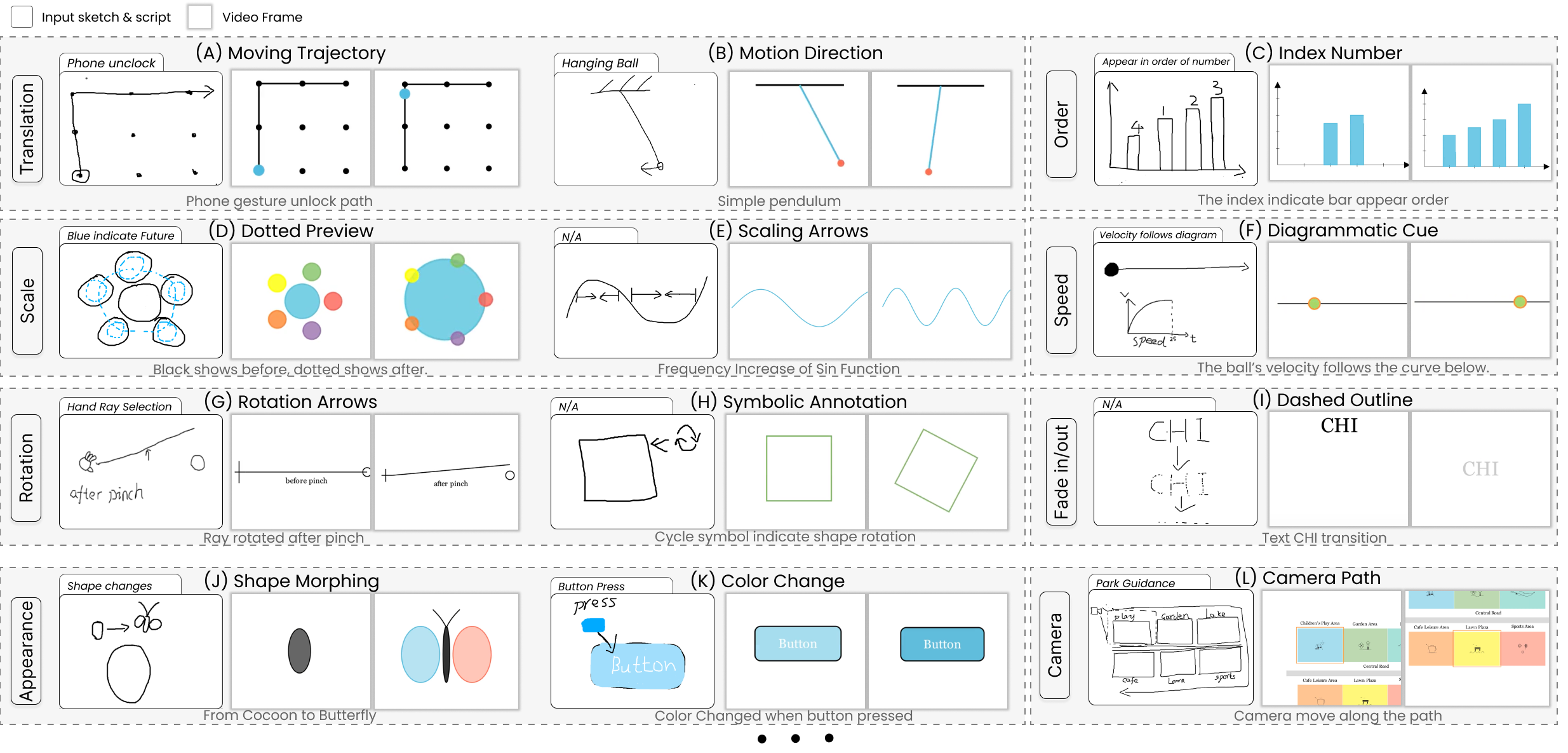
Figure 4: Examples of sketch-script-output triads, demonstrating how users combine abstract visual notations to describe translation, scaling, rotation, or complex appearance events.
Analysis confirms that VLMs privilege semantic intent over literal geometric fidelity: rough, “messy” input yields canonicalized smooth animations, while abstract arrows or curves invite multiple plausible interpretations. This supports efficient idea externalization but also surfaces the gaping ambiguity—both intentional and accidental—that pure sketch input entails.
Stage 2: Clarification Cue Mechanism
To systematize ambiguity management, SketchDynamics introduces a clarification cue mechanism that adaptively triggers minimal, context-relevant interventions according to detected ambiguity (Figure 5, Figure 6). The cues stratify across:
- Quick confirm (binary confirmation)
- Multiple choice (select among system-interpreted animations)
- Fill value (parameter solicitation for critical attributes, e.g., duration)
- Text/upload (free-form specification or resource attachment)
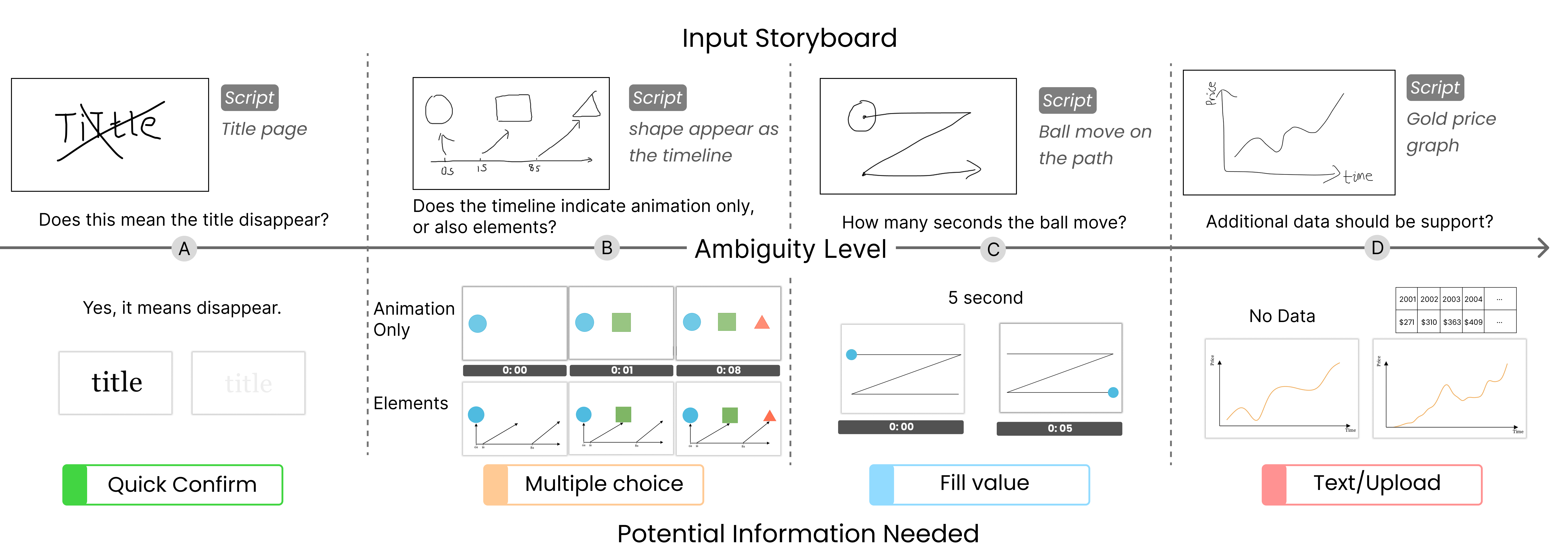
Figure 5: Ambiguity gradation and mapping to clarification strategies—left to right increases in sketch uncertainty and required user intervention.
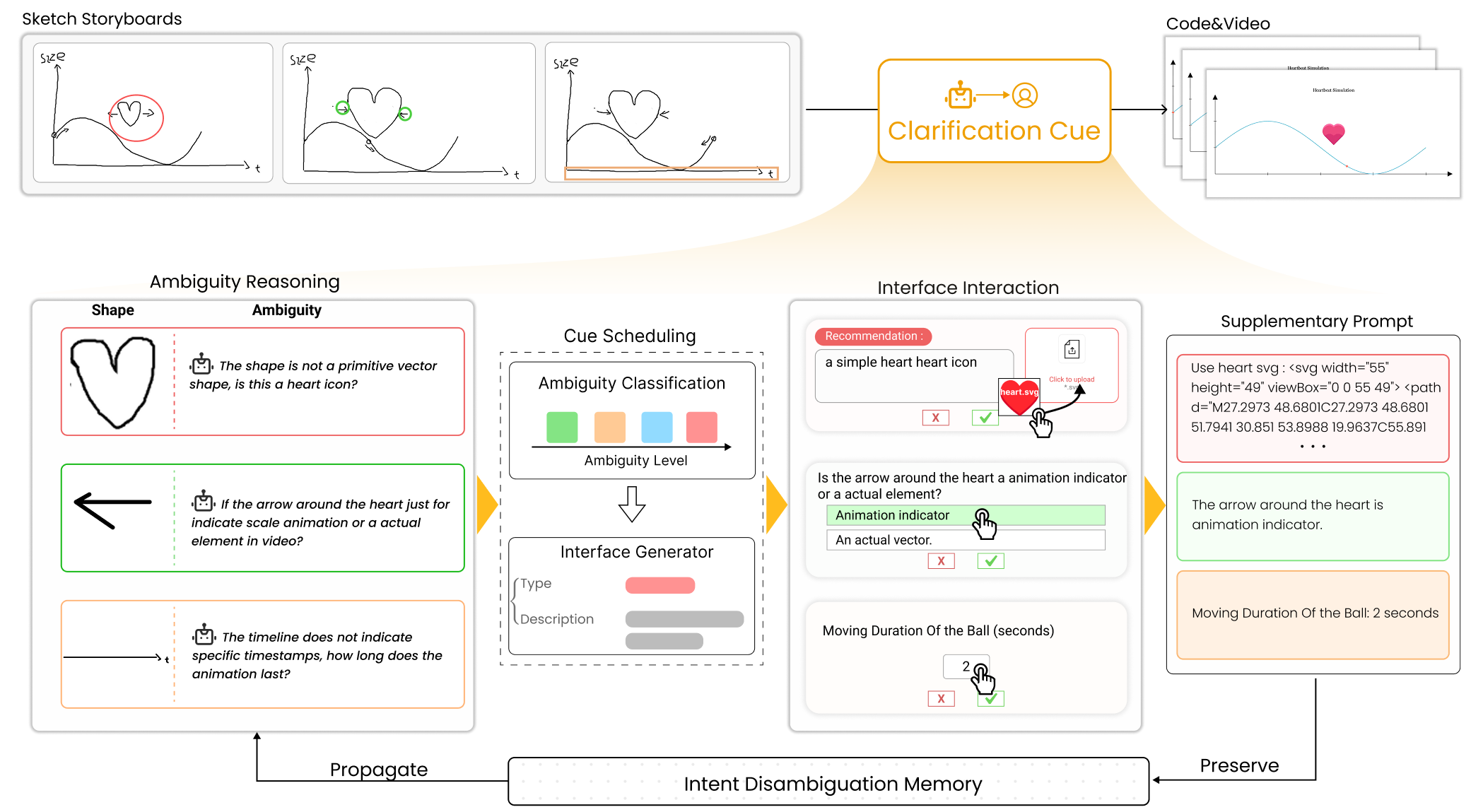
Figure 6: Clarification workflow: automated ambiguity detection, level classification, JSON-based cue generation, interface presentation, memory for resolve reuse.
Empirically, multiple choice cues were the most commonly triggered, reflecting high-symbolic overlap in motion annotations. Participants predominantly viewed clarification as “semantic guardrails” that improved trust without impeding workflow continuity. Objective ratings demonstrated substantial increases in perceived alignment, interpretive control, and overall satisfaction compared to the stage 1 baseline (Figure 7).
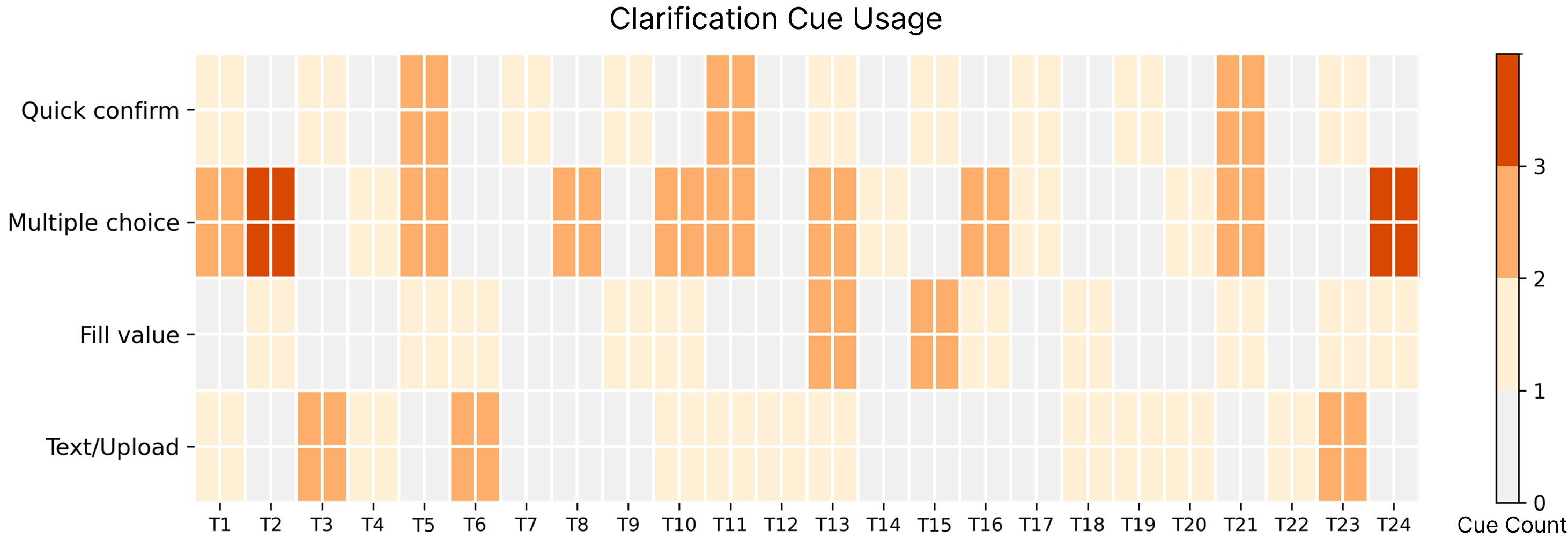
Figure 7: Heatmap of clarification cue usage across tasks, with intensity denoting frequent need for multiple-choice and text/upload clarification types.
Stage 3: Iterative Contextual Refinement
Recognizing that not all intent can be disambiguated a priori—and that video feedback is often essential for concrete specification—the third stage implements a contextual refinement mechanism (Figure 8). Generated videos are decomposed into keyframes; users select targets for local edit, apply further sketches or concise text annotations, and the system maps these visual refinements back into incremental code edits for selective re-rendering.
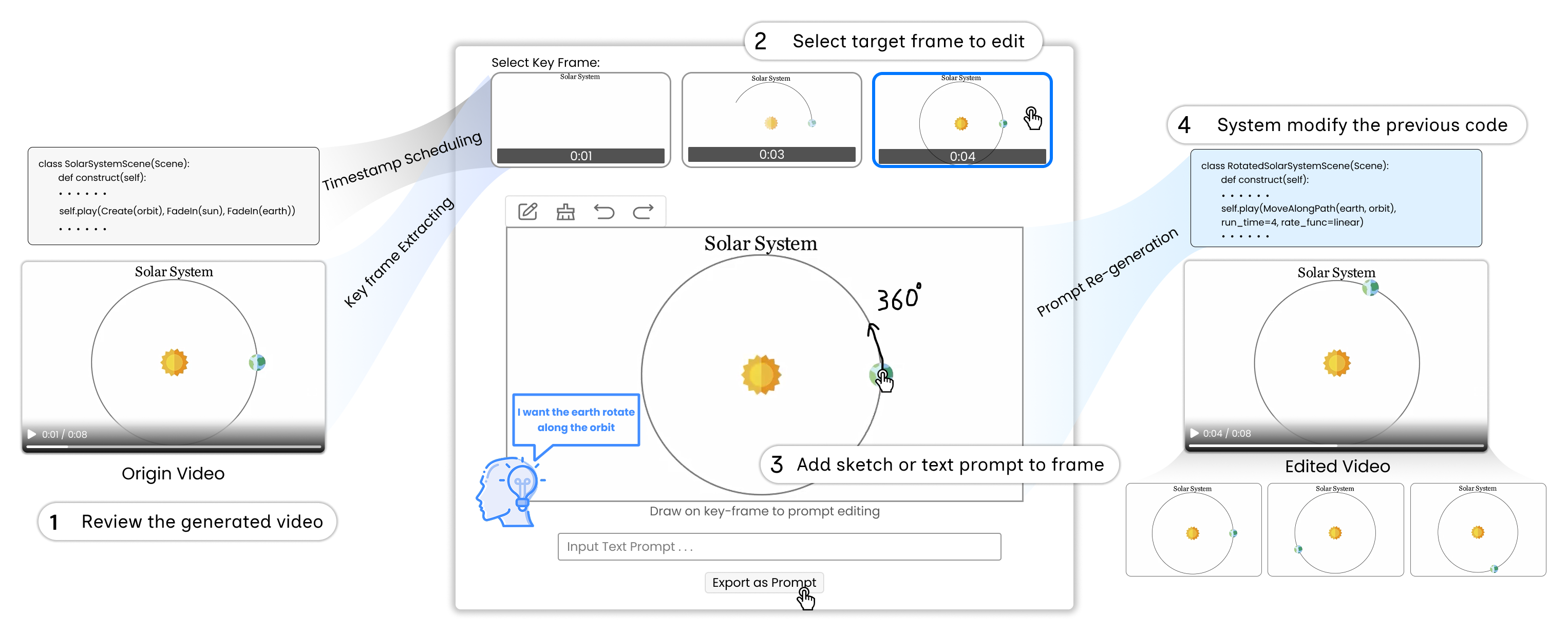
Figure 8: Refinement workflow, enabling users to inject intent by sketching on keyframes with direct mapping to updated animation logic and preview regeneration.
Observations underscore the criticality of locality and non-destructive editing: participants overwhelmingly favored the ability to “fix the part I don’t like” without collateral disruption to unaffected frames. The distinction between spatial and temporal edits naturally bifurcated into sketch-based (trajectories, paths) and text-based (timing, replication) refinement strategies. The method notably shifts authoring from one-shot, high-stakes generation into an incremental, collaborative alignment process (Figure 9).
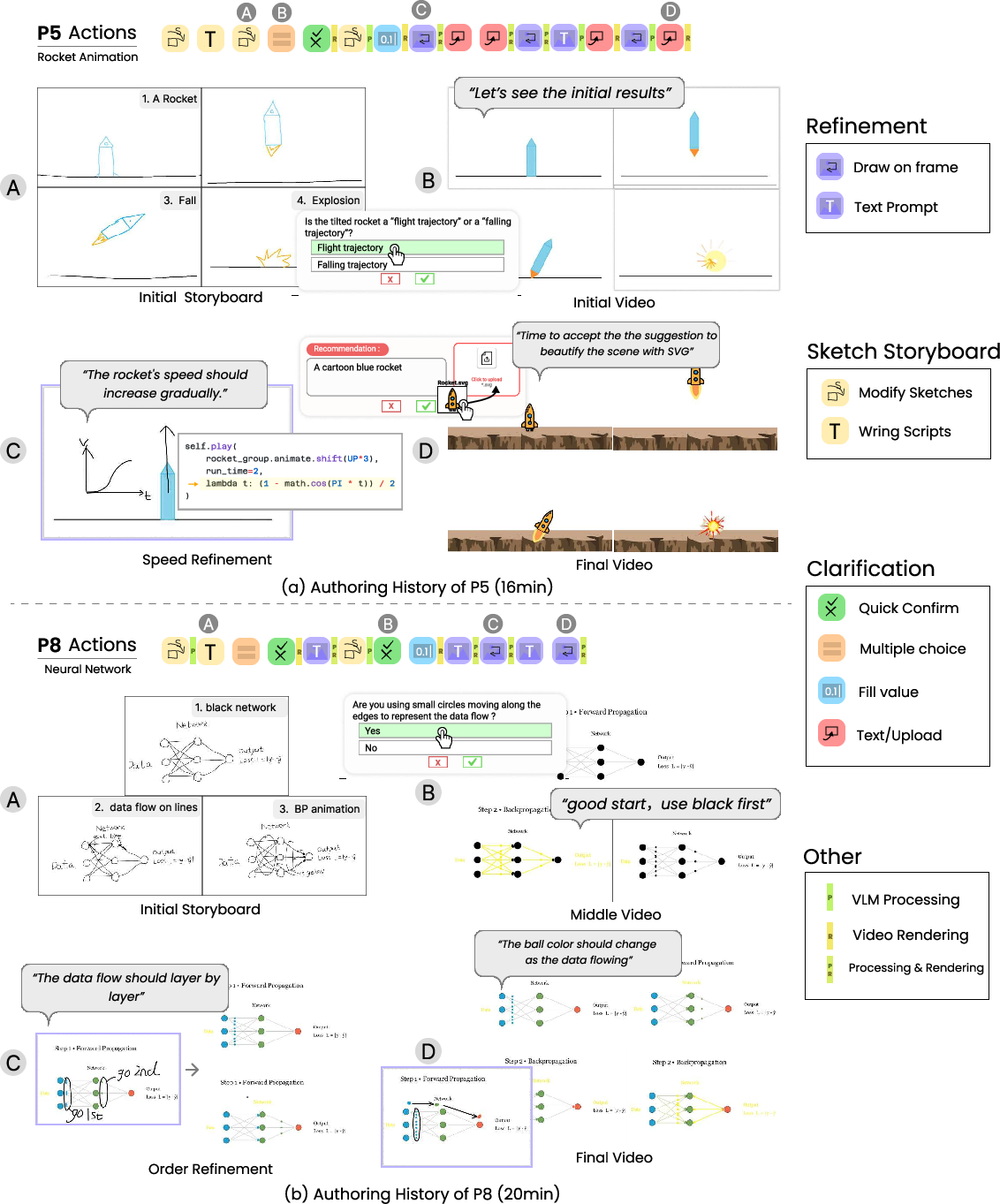
Figure 9: Sequential illustration of authoring and refinement process, with representative user actions and incremental resolution of intent/output mismatch.
Generalizability and Extensibility
Beyond 2D motion graphics, the paradigm is extensible to multi-modal video synthesis and 3D dynamic scene instantiation (Figure 10). In video generation, free-form sketches serve as prompt sources for generative frameworks, inputting abstraction over exacting layout—thereby democratizing access for non-experts and supporting interaction cycles previously unattainable in rigidly keyframed or script-dependent systems. For 3D animation (e.g., Unity), the concept envisions bidirectional sketch/code mappings, where storyboarded sketches are mapped to C# scripts or function calls.

Figure 10: Extensions of SketchDynamics: (A) high-level sketch storyboard to complex video, (B) 3D scene generation and event sequencing from annotated sketches.
Discussion
Synergistic Cue Architecture: Clarification cues and refinement cues function in synergy: clarification acts as a pre-generation, semantic negotiation layer, while refinement operates post hoc to close remaining gaps via local, contextual edits. This enables a “lazy specification” approach—low-effort, high-abstraction sketches are iteratively formalized as necessary, distributing intent articulation across time and dialog cycles.
Sketching Strategy Duality and VLM Limits: Users naturally employ both in-image annotation and across-frame sequencing to record dynamic intent, trading off expressiveness, efficiency, and interpretive ambiguity. Current VLMs are disproportionately effective at high-level motion semantics yet struggle with capturing geometric/temporal details or abstract stylistic requests. Failures run along two axes: overly abstract, symbolic marks and requirements for low-level precision (e.g., parameterized trajectories) not endemic to the model’s learned priors.
Ambiguity as Resource, Not Only Hindrance: The findings endorse ambiguity not as a technical failure but as a positive, generative resource. Interactive disambiguation and refinement reveal users’ own half-formed ideas, driving co-evolution of intent and output. This reframes sketch-based content creation as an opportunity for ongoing, human-in-the-loop interpretation, not deterministic command execution.
System and Study Limitations: User demographics remain narrow (students, mid-level experience). No real-time per-stroke interpretive feedback yet exists (generation is code-first and incurs latency). VLMs’ interpretive bandwidth is both the system’s strength and bottleneck. The expressive envelope of authorable outputs is ultimately constrained by the underlying animation backend and does not (yet) cover high-dimensional tasks such as deformable characters, fluid simulation, or stylistic variance.
Conclusion
SketchDynamics demonstrates that free-form sketching, interpreted through a VLM-augmented, human-in-the-loop pipeline, substantially broadens the semantic palette available for animation intent articulation. By embedding ambiguity-aware clarification and contextual refinement as core mechanisms, the approach transforms the sketch-based authoring workflow from fixed-mapping command invocation into an iterative, dialogic process that mirrors real-world creative practice. Empirical evaluation shows significantly improved alignment, perceived control, and low subjective effort across stages (Figure 11). The paradigm outlines pathways for extending sketch-driven animation generation into rich, accessible modalities underpinned by multimodal AI, with particular prospects for generalizing to complex 2D/3D, video, and narrative generation systems.
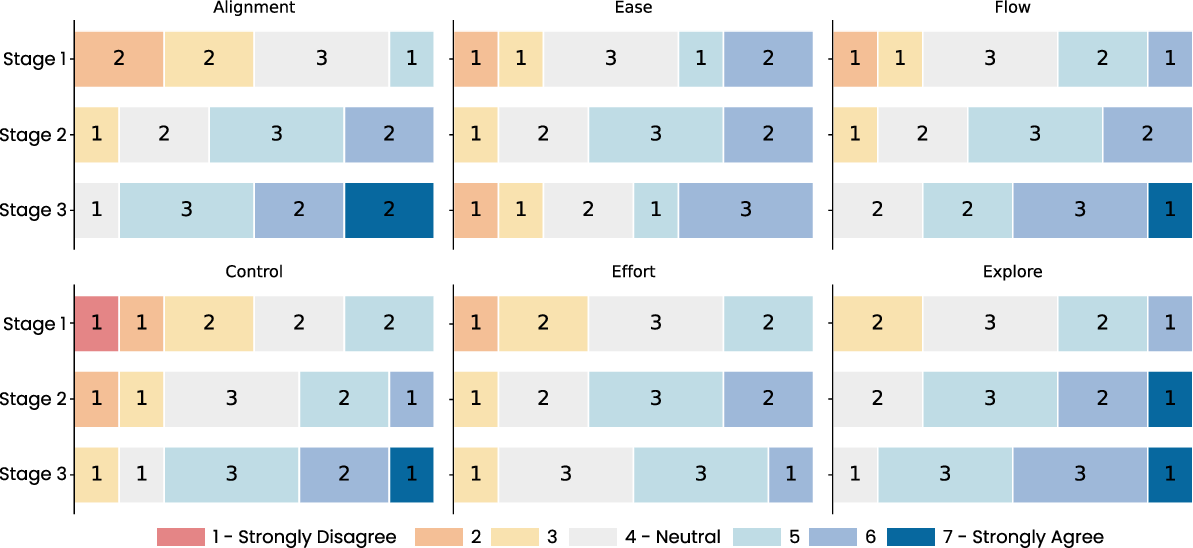
Figure 11: User-rated improvements in alignment, control, perceived effort, and creative flow over the three workflow stages, validating the cumulative effect of clarification and refinement mechanisms.
Future research should target: (1) sketch parsing that fuses vector/stroke data with pixel interpretation for richer, temporally-aware reasoning, (2) VLM finetuning or hybridization for robust ambiguity detection, and (3) full-stack authoring extending to expressive and physically-grounded animation forms. This work reinforces the necessity of bidirectional, interactive pipelines in the advancement of AI-supported creativity support tools.
Reference:
"SketchDynamics: Exploring Free-Form Sketches for Dynamic Intent Expression in Animation Generation" (2601.20622)