- The paper introduces Dep-Search, a framework that explicitly decomposes questions into dependency-based sub-questions using QDMR to improve multi-hop reasoning.
- The paper integrates a fixed-capacity LRU memory that stores summarized facts, enabling efficient knowledge reuse and reducing redundant retrievals.
- The paper leverages Grouped Relative Policy Optimization for trajectory-level reinforcement learning, achieving superior performance across seven multi-hop QA benchmarks.
Dep-Search: Dependency-Aware Reasoning Traces with Persistent Memory in Search-Augmented LLMs
Introduction and Motivation
Dep-Search (2601.18771) formalizes a new dependency-aware search paradigm for reasoning-augmented LLMs in complex multi-hop question answering over external knowledge sources. Existing retrieval-augmented generation (RAG) and agentic search frameworks interleave document retrieval with chain-of-thought style natural language reasoning, but rely on implicit token-level strategies to model reasoning steps and knowledge dependencies. This approach leads to inefficiencies such as redundant searches, sub-optimal order in sub-question answering, and poor exploitation of previously retrieved knowledge, especially under trajectory-level reinforcement learning objectives. Dep-Search explicitly disentangles reasoning traces, retrieval, and memory, introducing structural control tokens for explicit decomposition, retrieval, memory access, and summarization actions. Its core technical innovation is the integration of explicit dependency modeling via QDMR-style decomposition, persistent memory for verifiable knowledge reuse, and trajectory-level reinforcement learning via Grouped Relative Policy Optimization (GRPO).
Framework Overview
Dep-Search operates as a token-level decision process where the LLM agent decomposes questions into a directed acyclic graph (DAG) of dependent sub-questions, retrieves evidence at strategic points, and writes/reads summarized facts in a fixed-capacity least-recently-used (LRU) memory buffer. All components (decomposition, retrieval, memory access, reasoning, and summarization) are mediated by control tokens. The agent’s decision policy, parameterized for end-to-end RL via GRPO, determines the optimal timing and content for these discrete actions, maximizing expected answer reward while penalizing excessive search and decomposition.
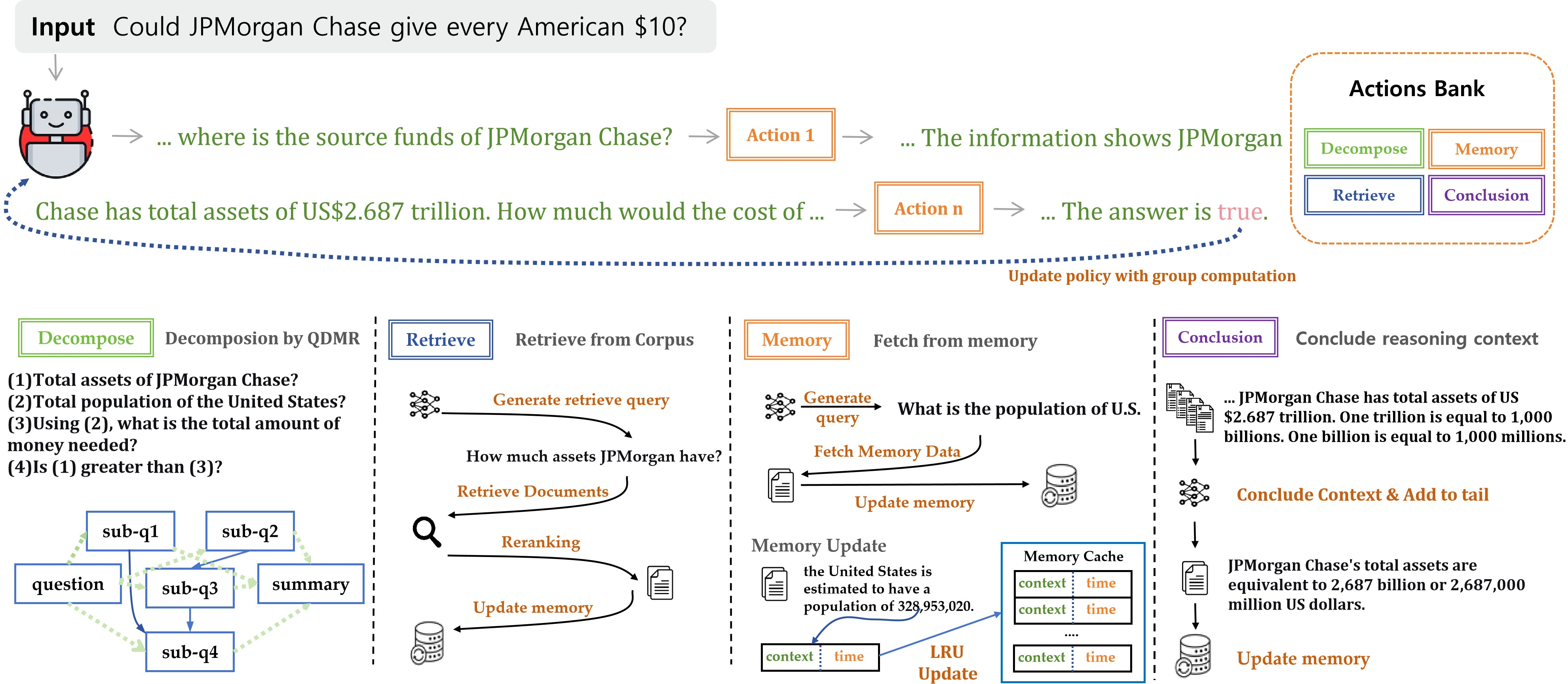
Figure 1: Overview of the Dep-Search architecture, demonstrating question decomposition, targeted retrieval, persistent memory access, and answer synthesis governed by trajectory-level RL.
Dep-Search’s state representation is tupled: (Tt,Ct,Mt) for reasoning trace, context, and memory, respectively. The memory buffer accumulates fact sentences—either extracted from retrieved documents or generated via explicit summarization—enabling the model to recall and synthesize previously acquired knowledge. This persistent state supports effective solution of complex multi-hop queries requiring knowledge accumulation and dependency chaining, with memory eviction handled strictly by environment rules.
Methodological Innovation
Explicit Dependency-Aware Decomposition
Dep-Search leverages explicit dependency-based question decomposition following QDMR (Question Decomposition Meaning Representation) conventions. Unlike sequential or stepwise approaches, the decomposition token instructs the agent to break down the input query into structured sub-questions, specifying prerequisite relations as a DAG. Sub-questions are answered in topological order, ensuring correct propagation of knowledge dependencies throughout the reasoning trace.
Persistent Memory with Structured Summarization
Fact sentences are ingested into a memory buffer at two points: after retrieval via automatic summarization and via explicit conclusion actions. Memory access actions allow the agent to query by semantic similarity, retrieving both the most recently written items and entries exceeding embedding similarity thresholds. This mechanism enables efficient knowledge reuse, dramatically reducing redundant retrieval operations and facilitating context compression for long reasoning traces.
Grouped Relative Policy Optimization (GRPO)
Dep-Search is trained via GRPO, an RL algorithm that computes trajectory-level returns and advantages relative to per-question rollout groups. This approach stabilizes optimization across varying question difficulties, allowing shared comparison of reasoning trajectories, and supporting joint learning of decomposition, retrieval, memory, and reasoning policies. Trajectory-level rewards combine normalized answer quality (Exact Match or F1) and linear penalties for retrieval and decomposition actions surpassing configurable thresholds, ensuring resource-efficient operation.
Empirical Evaluation
Dep-Search is rigorously evaluated on seven datasets (HotpotQA, 2WikiMultihopQA, Musique, Bamboogle, TriviaQA, PopQA, NQ) spanning both single-hop and multi-hop QA regimes. Two backbone models—Qwen2.5-3B-Instruct and Qwen2.5-7B-Instruct—are used as the reasoning agent.
Numerical results demonstrate:
- Best absolute and relative performance across all datasets and both model scales, with higher gains on multi-hop questions. Dep-Search’s average scores reach 39.29 (3B) and 49.77 (7B), outperforming the strongest baselines by 3–4 points or more.
- Larger models demonstrate greater absolute performance improvement, but smaller models exhibit pronounced relative gains caused by more disciplined decomposition and memory use.
- Ablation reveals that explicit dependency decomposition and persistent memory are independently critical, with memory removal degrading performance by up to 5 points and decomposition removal by over 3 points.
- Optimal memory buffer size is identified (15 entries) with additional capacity leading to decreased memory reuse and a marginal performance fall-off. This validates the LRU buffer strategy and the need for careful capacity tuning.
- Analysis of decomposition strategies (QDMR, sequential, pairwise) on HotpotQA and 2WikiMHQA establishes superior accuracy and performance for the QDMR dependency-based approach.
- Reward threshold and action usage analytics demonstrate the importance of calibrated penalties and action frequency for optimal reasoning flow.
Case Studies and Error Analysis
Qualitative case studies, including bridge, comparison, and parallel reasoning questions, illustrate Dep-Search’s process of decomposition, retrieval, memory writing/reading, and summarization. The persistent memory system enables dynamic knowledge chaining, accurate merging of facts obtained in separate sub-questions, and efficient responses to multi-hop or entity-attribute queries. The framework adaptively balances retrieval and memory usage, compressing long contexts and reducing token overhead via explicit conclusion actions.
Implications and Future Prospects
Dep-Search advances the state of agentic, search-augmented reasoning by providing explicit, verifiable memory and structural dependency tracking—critically required for scalable, sample-efficient multi-hop QA. The architecture’s modular decomposed state and explicit control traces enhance RL credit assignment and support trajectory-level optimization, raising answer accuracy and operational efficiency.
Theoretically, this delineation between reasoning, retrieval, and memory actions could inform the development of higher-level agent architectures with dynamic tool selection and longer-term memory integration, including adaptive buffer sizes and hierarchical dependency graphs. Practically, frameworks like Dep-Search enable construction of more reliable, auditable LLM-based agents for open-domain knowledge exploration, research, and complex decision support.
Open avenues include expansion to more advanced dependency representations, integration with dynamic external knowledge sources, hierarchical and multi-agent approaches, and exploration of lifelong or cross-question memory sharing.
Conclusion
Dep-Search establishes a dependency-aware, persistent memory-based paradigm for search-augmented LLM reasoning under trajectory-level RL. Empirical evidence confirms its superiority over implicit, heuristic-driven models, particularly in multi-hop QA, with individual architectural components contributing substantial gains. The framework enables precise reasoning chain management, structured memory reuse, and efficient RL, offering a blueprint for next-generation agentic reasoning systems. Future directions should explore scaling of dependency structures and dynamic memory mechanisms to broader reasoning domains.