AdaReasoner: Dynamic Tool Orchestration for Iterative Visual Reasoning
Abstract: When humans face problems beyond their immediate capabilities, they rely on tools, providing a promising paradigm for improving visual reasoning in multimodal LLMs (MLLMs). Effective reasoning, therefore, hinges on knowing which tools to use, when to invoke them, and how to compose them over multiple steps, even when faced with new tools or new tasks. We introduce \textbf{AdaReasoner}, a family of multimodal models that learn tool use as a general reasoning skill rather than as tool-specific or explicitly supervised behavior. AdaReasoner is enabled by (i) a scalable data curation pipeline exposing models to long-horizon, multi-step tool interactions; (ii) Tool-GRPO, a reinforcement learning algorithm that optimizes tool selection and sequencing based on end-task success; and (iii) an adaptive learning mechanism that dynamically regulates tool usage. Together, these components allow models to infer tool utility from task context and intermediate outcomes, enabling coordination of multiple tools and generalization to unseen tools. Empirically, AdaReasoner exhibits strong tool-adaptive and generalization behaviors: it autonomously adopts beneficial tools, suppresses irrelevant ones, and adjusts tool usage frequency based on task demands, despite never being explicitly trained to do so. These capabilities translate into state-of-the-art performance across challenging benchmarks, improving the 7B base model by +24.9\% on average and surpassing strong proprietary systems such as GPT-5 on multiple tasks, including VSP and Jigsaw.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces AdaReasoner, a smart computer system that can look at images and text and solve tricky visual problems by calling helpful “tools” along the way. Instead of guessing or trying to do everything in its head, AdaReasoner learns when to use tools like reading text in pictures (OCR), pointing to objects, cropping parts of images, or even finding the shortest path across a maze. The big idea is to make tool use a core thinking skill: knowing which tool to use, when to use it, and how to combine several tools over multiple steps.
What questions did the paper ask?
The paper focuses on three simple questions:
- How can a model decide which visual tools to use for a problem?
- When should it call a tool and when should it rely on its own reasoning?
- Can it learn to coordinate multiple tools over several steps, and still work well with brand-new tools it’s never seen before?
How did they do it?
To teach AdaReasoner this skill, the authors built a three-part approach: high-quality practice data, a reward-based training method, and a generalization trick so it doesn’t just memorize tool names.
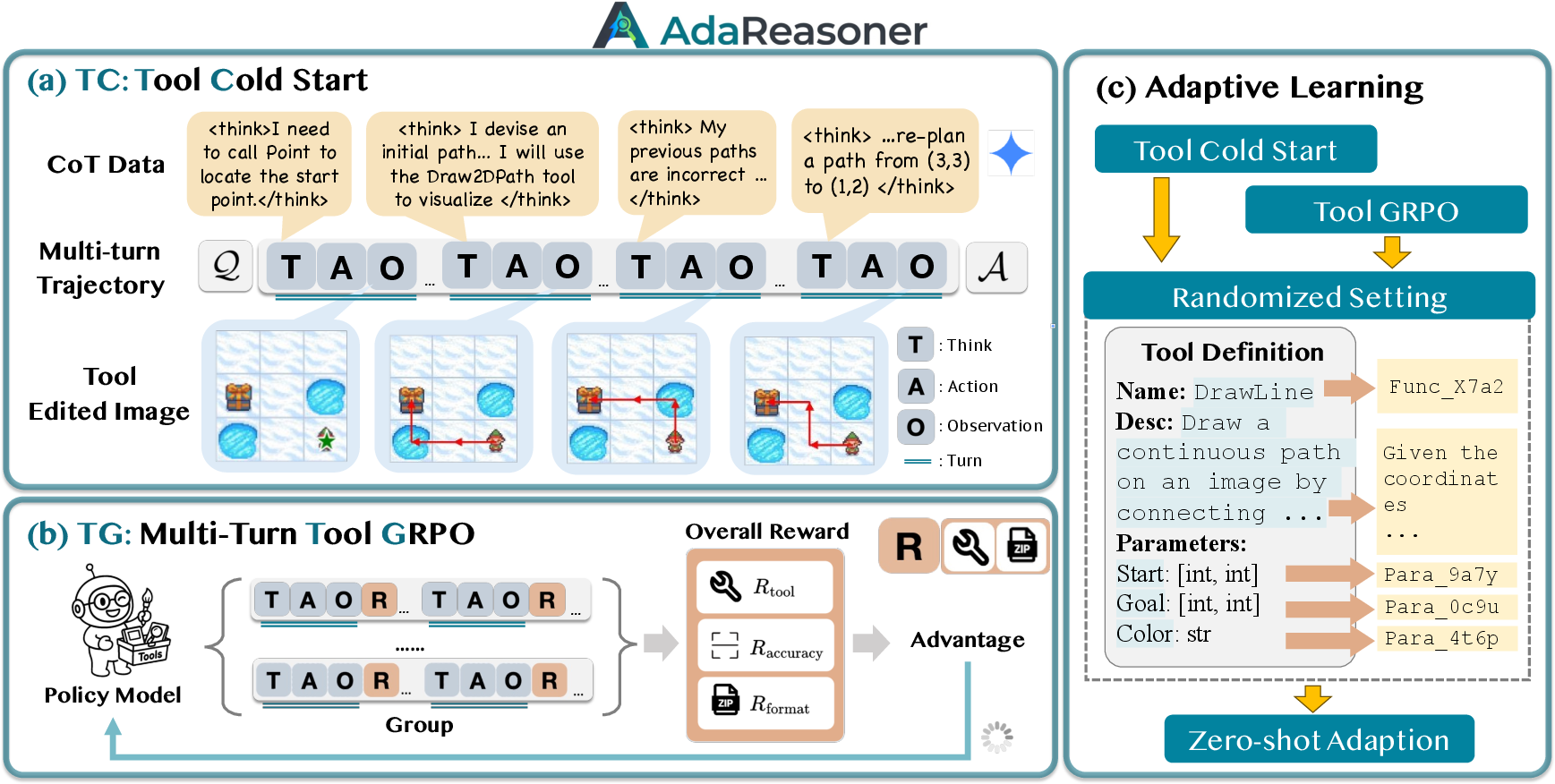
Building practice data (Tool Cold Start, “TC”)
They prepared many “story-like” practice examples where the model solves a problem step by step, and the tools are actually run to produce real outputs. These examples include:
- Reflection and backtracking: the model tries something, checks if it worked, and fixes mistakes.
- Tool failures: sometimes tools don’t help or give bad results. The model learns to recognize this and switch back to reasoning without tools when needed.
This teaches the model not only what tools exist, but why and how they help in different situations.
Training with rewards (Tool-GRPO, “TG”)
They used a reinforcement learning method (think: practice with points) that scores the model for:
- Formatting its tool calls correctly (so tools run successfully).
- Choosing appropriate tools and filling in the right parameters (like coordinates or text).
- Getting the final answer right.
A key idea is an “adaptive” reward:
- If the final answer is correct, the model gets full credit even if it used few tools (to avoid wasting time).
- If the answer is wrong, the model can still earn partial credit for sensible tool usage (to encourage using tools when it’s unsure rather than guessing).
This nudges the model to use tools wisely—often as a backup when uncertain—rather than always or never.
Teaching to generalize (Adaptive Learning, “ADL”)
To prevent memorizing tool names (like “Calculator” or “OCR”), they randomly renamed tools and parameters to nonsense strings and rephrased their descriptions in different words. This forces the model to understand what a tool does from its description and context, not from a familiar name. As a result, AdaReasoner becomes better at using new tools it hasn’t seen before, as long as their descriptions explain how they work.
What are the tools like?
Think of them as small helper apps:
- Perception tools: “Point” to mark objects, “OCR” to read text in images, “Crop” to zoom in.
- Manipulation tools: “DrawLine” or “InsertImage” to modify visuals and test ideas.
- Calculation tools: “A* pathfinding” (AStar) to find the shortest path around obstacles, like in a maze.
What did they find?
Across several challenging tests, AdaReasoner:
- Became much more accurate than the original base model (big average gains; in some tasks it approached near-perfect scores).
- Outperformed some strong proprietary systems (the paper says it beat models like GPT‑5 on tasks such as Visual Spatial Planning and Jigsaw).
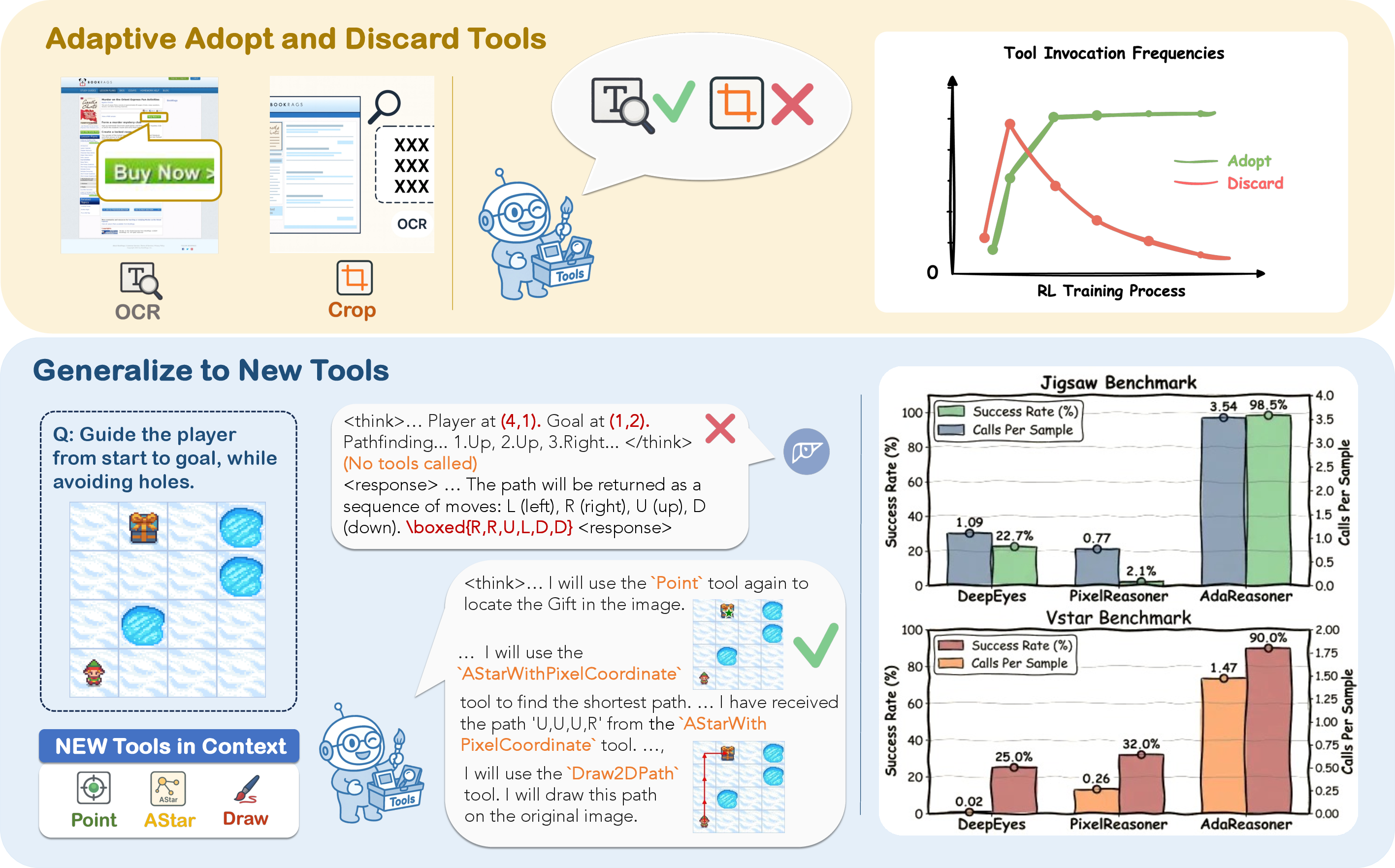
- Showed adaptive behavior:
- Adopted helpful tools more often when they actually improved results (e.g., used A* a lot during navigation tasks).
- Stopped using tools that didn’t help for a given part of a problem (e.g., avoided A* during verification steps).
- Adjusted tool-calling frequency to match the task (used “Point” many times during navigation, only a little during verification).
- Generalized to new tools and new tasks:
- With randomized tool names and descriptions, the model still used tools effectively in zero-shot situations (brand-new tool definitions).
- Skills learned on one task (like Jigsaw) transferred to different tasks (like Visual Spatial Planning and WebQA), boosting scores even without direct training on those tasks.
Why this matters: previous systems often used fixed tool patterns or relied on a single tool; AdaReasoner learns tool use as a flexible, context-aware strategy, which makes it more reliable and powerful.
Why does it matter?
- Better visual reasoning: Tools fill in gaps that models struggle with, like precise reading or measuring. This reduces mistakes and makes step-by-step reasoning more trustworthy.
- Efficiency and robustness: The adaptive reward encourages using tools only when helpful—saving time and avoiding distractions.
- Works with new tools: Randomizing tool names makes the system depend on descriptions and context, so it can pick up new tools quickly.
- Smaller models, bigger results: The paper argues that with good tool orchestration, even a mid-sized open-source model (7B) can reach or beat the performance of much larger, closed-source models on structured visual tasks. In other words, the main bottleneck shifts from “how big the model is” to “how well it uses tools.”
Final thoughts and impact
AdaReasoner shows that teaching a model to plan and use tools—like a careful problem-solver—can dramatically improve visual reasoning. It learns to:
- Choose the right tools,
- Use them at the right time and in the right way,
- Stop using tools when they don’t help,
- And handle brand-new tools and tasks without special training.
This could impact many areas: digital assistants that understand screens and websites, robots that navigate spaces, apps that analyze documents or maps, and more. The takeaway is simple but powerful: with the right training, models don’t need to grow endlessly larger; they need to get smarter about using the tools available to them.
Knowledge Gaps
Below is a single, focused list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research.
- Real-world generalization: The evaluation mostly targets structured, image-based reasoning (VSP, Jigsaw, GUIQA/WebQA); it remains unclear how AdaReasoner performs on unstructured, open-ended tasks, multi-image contexts, and long video sequences requiring temporal reasoning and memory.
- Toolbox scale and diversity: The method is tested with a small, hand-picked set of tools; there is no study of scalability to large, heterogeneous tool ecosystems (e.g., 100+ tools), overlapping functionalities, or tools with complex, nested APIs (OpenAPI/JSON schema).
- True “unseen tool” generalization: Randomizing names and paraphrasing descriptions preserves functionality; the model’s robustness to genuinely novel capabilities, incomplete/ambiguous documentation, or conflicting tool contracts remains untested.
- Tool discovery from documentation: AdaReasoner assumes predefined tool descriptions; it does not learn to autonomously parse, summarize, and select tools from raw documentation, code signatures, or API specs at scale.
- Latency and cost trade-offs: There is no quantification of wall-clock latency, GPU/CPU cost, or throughput impacts of multi-turn tool calls; budgets, timeouts, and cost-aware planning policies are not evaluated.
- Budgeted planning: The framework does not explore accuracy vs. cost trade-offs under explicit tool budgets (e.g., maximum calls per task, per-tool cost constraints) or constrained optimization formulations.
- Robustness to tool errors: Aside from curated “explicit tool failure” cases, systematic evaluation under realistic failure modes (timeouts, rate limits, stochastic outputs, non-deterministic expert models) is missing.
- API robustness: The strict formatting reward discourages minor syntax mistakes during training; the paper does not measure inference-time resilience to API deviations, argument reordering, optional/missing fields, or schema evolution.
- Safety and security: No analysis of prompt injection via tool descriptions, malicious tools, data exfiltration risks, or sandboxing/permission models for tool execution.
- Uncertainty calibration: The adaptive reward assumes the model will use tools more when uncertain, but there is no explicit uncertainty estimator, calibration analysis (e.g., Brier/NLL), or policy linking confidence to tool invocation thresholds.
- Credit assignment in long horizons: GRPO extensions are proposed but lack a study of credit assignment fidelity across multi-step trajectories, sensitivity to horizon length, or comparisons to hierarchical RL/critic-based methods.
- Reward design sensitivity: The method introduces multiple reward components and weights (format, tool, accuracy, adaptive incentives) without reporting sensitivity analyses, ablations, or stability across seeds and tasks.
- Reflection/backtracking stability: Reflection data improves some settings but destabilizes others; principled mechanisms to control reflection depth, detect unproductive loops, and mitigate distraction are not provided.
- Overuse/underuse control: Although modulation of call frequency is observed, there is no explicit mechanism or guarantee preventing pathological overuse, tool thrashing, or premature cessation under distribution shift.
- Fairness of comparisons: Tool-augmented closed-source baselines may not share identical tool interfaces or integration quality (e.g., “GPT-5 + Tools” shows 0 CPS in Jigsaw), leaving open questions about parity and evaluation fairness.
- Data curation bias: Trajectories are LLM-authored with abstract “optimal” blueprints; the effects of synthetic biases, annotation artifacts, or leakage into evaluation distributions are not quantified.
- Domain shift in GUIs: GUI tasks are limited in scope and language (primarily English); robustness to real-world, dynamic, localized GUIs (different languages, layouts, styles) is not investigated.
- Long-horizon scaling: Average interaction depth is modest (≈2–5 turns); there is no stress test on tasks requiring >10–20 steps, hierarchical subgoal decomposition, or interleaved planning across multiple images/sources.
- Multi-agent or modular control: The single-policy setup is not compared with planner–executor–critic decompositions or multi-agent tool orchestration, which may improve credit assignment and robustness.
- Multi-modal breadth: Audio, video, and sensor modalities are out of scope; it is unknown whether the approach extends to non-visual tools and cross-modal tool coordination.
- Tool parameter reliability: While training rewards score parameter names/content, the paper lacks a detailed error taxonomy at inference (wrong parameter values, off-by-one coordinates, unit mismatches) and targeted mitigations.
- Continual learning and forgetting: The impact of adding/removing tools over time, catastrophic forgetting across tasks, and incremental toolset evolution are not studied.
- Tool interchangeability: When multiple tools can accomplish a subtask, the method does not analyze preference formation, redundancy handling, or policy diversity for equivalently capable tools.
- Theoretical guarantees: There is no convergence or regret analysis for Tool-GRPO under adaptive rewards, leaving open questions about stability and optimality in the presence of discrete tool calls.
- Human oversight: The framework does not explore human-in-the-loop intervention (e.g., vetoing calls, approving parameters), nor interfaces to elicit human feedback for error correction or policy shaping.
- Explainability and audits: While CoT is generated, there is no audit protocol to verify that rationales accurately reflect tool-use causality or to detect post-hoc justifications.
- Reproducibility details: Critical TG hyperparameters, seed variability, and per-task training curves are deferred to the appendix; robustness across seeds and compute budgets is not reported in the main text.
- Transfer to robotics/embodied settings: The applicability of dynamic tool orchestration to embodied agents (actuators, physical constraints, safety-critical tools) remains open.
Glossary
- A: A graph search algorithm that finds the shortest path using heuristics; here used as a visual-planning tool. "Use A to find the shortest obstacle-free path"
- Ablation study: An experimental analysis that removes or varies components to assess their impact. "Ablation study on adaptive tool usage."
- Accuracy Reward: A reinforcement learning reward component that depends solely on the correctness of the final answer. "Accuracy Reward This reward is granted only based on the final turn"
- Adaptive Learning: A training strategy that randomizes tool identifiers and paraphrases descriptions to improve generalization to unseen tools/tasks. "Adaptive Learning for Improved Generalization"
- Adaptive Reward: A reward design that grants full credit for correct answers and partial credit for informative tool use when answers are wrong, encouraging robust tool use. "Adaptive Reward for Encouraging Tool Use."
- Agentic Action: A metric evaluating an agent’s ability to take effective actions in interactive tasks. "WebMMU reports the Agentic Action (Act.) score."
- Backtracking: A reasoning behavior where the model revisits and corrects earlier steps after detecting errors. "Reflection and Backtracking: We include trajectories designed to encourage a process of trial and verification."
- Calls per sample (CPS): The average number of tool invocations per input example. "CPS (calls per sample) represents the average number of tool invocations per sample."
- Chain-of-Manipulation (CoM): A data paradigm capturing step-by-step visual manipulation strategies for training tool-use. "Chain-of-Manipulation (CoM) data"
- Chain-of-Thought (CoT): An approach where models generate intermediate reasoning steps to reach an answer. "Chain-of-Thought (CoT) reasoning"
- Data curation pipeline: A scalable process for constructing high-quality training trajectories and tool interactions. "a scalable data curation pipeline exposing models to long-horizon, multi-step tool interactions"
- Draw2DPath: A visual tool that draws a path on an image given directional commands. "Draw a path using directional commands"
- Format Reward: A reward term enforcing correct output formatting at every step in multi-turn trajectories. "Format Reward $R_{\text{format} = \prod_{i=1}^{n} R_{format}(\tau_i)$"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm variant for optimizing reasoning policies with group-relative rewards. "Group Relative Policy Optimization (GRPO)"
- GUIChat: A dataset/benchmark for GUI-based question answering used to evaluate GUI understanding. "GUIChat~\citep{chen2024guicourse}"
- GUIQA: A task focusing on GUI understanding and question answering. "GUIQA involves a focus-then-extract strategy."
- HRBench: A benchmark evaluating visual search/general VQA capabilities. "HRBench\citep{hrbench}"
- Jigsaw-COCO: A dataset for evaluating visual compositionality via jigsaw-style reconstruction challenges. "Jigsaw-COCO dataset"
- Long-horizon: Refers to reasoning or planning over many steps or turns. "long-horizon, multi-step tool interactions"
- Multimodal LLM (MLLM): A LLM that processes and reasons over multiple modalities (e.g., text and images). "multimodal LLMs (MLLMs)"
- OCR: Optical Character Recognition; a tool that extracts and localizes text from images. "Extracts and localizes text from the image"
- Out-of-distribution benchmark: An evaluation set intentionally different from training data to test robustness. "our custom out-of-distribution benchmark (VSPO)"
- Perceptual grounding: Linking linguistic or symbolic reasoning to concrete visual evidence in images. "which assesses multi-step planning and perceptual grounding"
- Pixel-Reasoner: A tool-augmented method focusing on crop-based visual search strategies for reasoning. "Pixel-Reasoner~\citep{su2025pixelreasoner}"
- Reflection: A reasoning behavior where the model explicitly reviews intermediate results to self-correct. "Reflection and Backtracking: We include trajectories designed to encourage a process of trial and verification."
- Reinforcement learning (RL): A learning framework where policies are optimized via rewards from interaction outcomes. "a reinforcement learning algorithm that optimizes tool selection and sequencing based on end-task success"
- Sequential decision-making: Framing reasoning as a sequence of actions taken over states with feedback. "we formalize tool-augmented multimodal reasoning as a sequential decision-making process."
- State-action-observation tuple: The structured unit of a trajectory capturing the current state, chosen action (tool call), and resulting observation. "A trajectory is a sequence of state-action-observation tuples"
- Tool Cold Start (TC): A supervised pretraining stage that constructs multi-turn, tool-augmented trajectories to initialize policy. "Tool Cold Start (TC)"
- Tool GRPO (TG): A reinforcement learning phase using GRPO tailored to multi-turn tool planning and rewards. "Tool GRPO (TG)"
- Tool invocation: The act of calling external tools during reasoning, including choosing when and how often to call them. "unstable tool invocation behaviors"
- Tool Reward: A reward computed from the correctness and structure of tool calls across turns. "Tool Reward ~The overall tool reward is the average of the fine-grained scores from all tool-calling turns"
- Trajectory: The sequence of states, actions, and observations representing the model’s multi-step reasoning process. "A trajectory is a sequence of state-action-observation tuples"
- V* (Vstar): A visual search benchmark evaluating general VQA-style retrieval/search. "specifically V*\citep{wu2024vstar} and HRBench\citep{hrbench}"
- Visual Spatial Planning (VSP): A benchmark/task assessing planning and spatial reasoning grounded in visual inputs. "Visual Spatial Planning, which assesses multi-step planning and perceptual grounding"
- VSPO: An out-of-distribution version of VSP used to test generalization. "our custom out-of-distribution benchmark (VSPO)"
- WebMMU: A benchmark for web-based multimodal tasks, including agent actions. "WebMMU benchmark~\citep{awal2025webmmu}"
- Zero-shot: Using models or tools in scenarios not seen during training without additional fine-tuning. "even in zero-shot settings."
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed with today’s tool ecosystem, leveraging AdaReasoner’s dynamic, multi-turn tool orchestration, reinforcement learning (Tool-GRPO), and adaptive generalization to unseen tool definitions.
- GUI testing and quality assurance
- Sector: Software, QA, DevOps
- What it does: Autonomously validates visual states and flows in apps/websites using OCR, Point, and Draw2DPath; performs focus-then-extract checks (as in GUIQA/WebMMU), and reflects/backtracks on failures.
- Potential products/workflows: “GUIQA bot” integrated with CI/CD to test flows from screenshots or headless renderings; regression checks on visual diffs; accessibility overlays validation.
- Assumptions/dependencies: Stable screenshotting; access to app/web instances; reliable OCR/text localization; tool server latency acceptable for CI; coverage requires curated task blueprints.
- Web form filling and RPA on visually complex pages
- Sector: RPA, Enterprise IT, Government services
- What it does: Acts on canvas-heavy or non-semantic UIs by reading on-screen text (OCR), pointing to targets, verifying entries, and correcting errors; falls back to tools when uncertain, reducing brittle hard-coded scripts.
- Potential products/workflows: “Vision-first RPA” that augments DOM-based agents; hybrid pipelines that invoke OCR and cropping before actions; audit logs of tool calls for compliance.
- Assumptions/dependencies: Screen capture permissions; consistent UI rendering; strong OCR for multilingual UIs; organizational security policies for handling sensitive screenshots.
- Document understanding and compliance checks
- Sector: Finance, Legal, Public sector
- What it does: Extracts text with bounding boxes (OCR) and performs spatial reasoning to verify required disclosures, signatures, stamps, or layout constraints; reflects and retries on ambiguous regions via Crop and InsertImage.
- Potential products/workflows: KYC/AML document validation; invoice/contract cross-checks; regulatory display-compliance (e.g., font size/placement of disclaimers).
- Assumptions/dependencies: High-quality OCR; standardized document templates help; governance for PII redaction; clear acceptance criteria for verification steps.
- Visual ad and content compliance
- Sector: Advertising, E-commerce, Media
- What it does: Localizes text, logos, and sensitive placements; checks spacing and contrast; detects “blackout” regions or overlays (DetectBlackArea) and verifies layout rules with multi-step planning.
- Potential products/workflows: Automated preflight checkers for ad creatives; content moderation assistants that justify decisions with tool outputs.
- Assumptions/dependencies: Up-to-date policy rules; tool definitions that capture perceptual checks; versioning of creative specs.
- Game and level QA via visual spatial planning
- Sector: Gaming
- What it does: Uses A* pathfinding plus Point/Draw2DPath to validate feasibility of routes, puzzle solvability, and navigability; reflects on failed routes and backtracks.
- Potential products/workflows: “Level solvability validators”; automated puzzle testing; bot-based level walkthrough capture.
- Assumptions/dependencies: Access to level snapshots/maps; tool wrappers for in-engine pathfinding or map exports; deterministic layouts.
- Visual search and product catalog QA
- Sector: E-commerce, Retail
- What it does: Locates and verifies product attributes in images; confirms presence/positioning of labels, barcodes, or package text; annotates defects with overlays.
- Potential products/workflows: Catalog onboarding assistants; SKU image audits; shelf monitoring (offline photos).
- Assumptions/dependencies: OCR robustness on varied packaging; clear attribute schemas; data drift monitoring.
- Data labeling acceleration and review
- Sector: ML/AI operations
- What it does: Suggests points, crops, and annotations; composes multiple tools to propose labels, then verifies via reflection/backtracking; flags low-confidence cases for humans.
- Potential products/workflows: “Adaptive pre-labeler” in annotation platforms; verification loops where the agent justifies labels with tool outputs.
- Assumptions/dependencies: Tool success/failure handling; tight human-in-the-loop UX; logging for auditing.
- Customer support from screenshots
- Sector: Customer service, SaaS
- What it does: Interprets user-provided screenshots to pinpoint UI elements, read error text, and produce step-by-step guidance; dynamically invokes tools under uncertainty and validates next steps.
- Potential products/workflows: Triage assistant in support portals; auto-generated click-path instructions with highlighted regions.
- Assumptions/dependencies: Screenshot privacy; varied UI skins; explicit safety filters to avoid risky system actions.
- Accessibility auditing and assistance
- Sector: Accessibility, Public sector compliance, Education
- What it does: Reads on-screen text, checks contrast/placement, and proposes accessible alternatives; produces guided click sequences and highlights interactive targets.
- Potential products/workflows: Automated WCAG visual checks; “assistive overlay” that points and reads elements for low-vision users.
- Assumptions/dependencies: OCR accuracy on small fonts; validators for contrast/spacing; device accessibility APIs.
- Agentic orchestration SDK for tool ecosystems
- Sector: Software, Platform tooling
- What it does: Provides an SDK for dynamic tool selection/sequencing (Tool-GRPO policy), with tool definition randomization to reduce overfitting; supports mixed offline/online visual tools.
- Potential products/workflows: “Adaptive Tool Router” library; registry of tool schemas with description rephrasing; reward logging dashboards.
- Assumptions/dependencies: Tool APIs with clear argument semantics; sandboxed execution; cost/latency budgets; safe defaults under tool failures.
- Education: visual reasoning tutors
- Sector: EdTech
- What it does: Solves geometry diagrams, jigsaw-like visual puzzles, and spatial tasks with explicit intermediate steps and verification; teaches strategies like reflect/backtrack.
- Potential products/workflows: Interactive tutors explaining their tool calls and visual overlays; practice sets with stepwise feedback.
- Assumptions/dependencies: Task datasets with deterministic checks; content moderation for student data; calibrated difficulty.
- Lightweight on-device agents for structured tasks
- Sector: Mobile, Embedded
- What it does: Uses small open-source models (e.g., 7B) plus a curated tool set for high-precision, structured visual tasks (maps, forms, labels) without cloud dependence.
- Potential products/workflows: Private document scanning apps; offline labeling helpers.
- Assumptions/dependencies: On-device OCR/vision models; energy/latency constraints; reduced tool repertoire.
Long-Term Applications
These use cases are promising but need further research, scaling, domain-specific tools, safety validation, or real-time guarantees.
- Household and warehouse robotics with visual tool orchestration
- Sector: Robotics, Logistics
- What it could do: Combine detection/segmentation tools, OCR for labels, and path planners (A*) under a unified reasoning loop to fetch items, navigate clutter, and verify goals.
- Potential products/workflows: “Vision-tool policy head” on top of robot stacks (SLAM as a tool; grasp planners as tools).
- Assumptions/dependencies: Real-time performance; low-latency tool servers; safety/interrupts; robust sim-to-real; certified failure modes.
- Industrial inspection with reflective verification
- Sector: Manufacturing, Energy (solar/wind), Infrastructure
- What it could do: Orchestrate expert defect detectors and measurement tools; iteratively crop, annotate, and verify; plan coverage of large surfaces (A* sweeps).
- Potential products/workflows: Drone/robot inspectors with multi-turn planning and verification; defect triage with rationale trails.
- Assumptions/dependencies: High-accuracy expert tools; adverse conditions (glare, motion); standards for evidence retention; operator-in-the-loop oversight.
- Clinical imaging triage with tool-augmented reasoning
- Sector: Healthcare
- What it could do: Coordinate domain tools (segmentation/classification, measurement) with reflective verification to prioritize cases and flag abnormalities with interpretable overlays.
- Potential products/workflows: Radiology pre-screen assistants; pathology slide scanning plans with coverage guarantees.
- Assumptions/dependencies: Rigorous clinical validation and regulatory approval; bias and drift monitoring; data privacy; domain-specific tool quality far exceeding general OCR/detectors.
- Autonomy in transportation and micro-mobility
- Sector: Automotive, Drones
- What it could do: Use map and perception tools as callable modules (lane/traffic sign detectors as tools; local planners as tools) with adaptive invocation frequency based on uncertainty.
- Potential products/workflows: “Reason-over-tools” supervision layer for explainability; fallback policies when tools disagree.
- Assumptions/dependencies: Hard real-time constraints; formal safety cases; redundancy; certification.
- Emergency response planning from aerial/satellite imagery
- Sector: Public safety, Government
- What it could do: Extract road blockages via perception tools, plan safe routes (A*), verify feasibility with multi-step checks, and update plans as new imagery arrives.
- Potential products/workflows: Rapid routing advisors with visual evidence packs; what-if simulations with tool failure handling.
- Assumptions/dependencies: Fresh imagery; robust detection under smoke/debris; human-in-the-loop; interoperability with dispatch systems.
- Scientific image analysis orchestration
- Sector: Research, Pharma, Materials
- What it could do: Chain specialized tools (cell counters, segmenters, trackers) with reflective verification; modulate tool usage to reduce false positives.
- Potential products/workflows: Reproducible analysis notebooks that log tool calls and rationales; cross-lab generalization via randomized tool definitions.
- Assumptions/dependencies: High-fidelity domain tools; standardized metadata; provenance and audit trails.
- Standardized tool schema governance and marketplaces
- Sector: Policy, Platform economics, Standards bodies
- What it could do: Define interoperable, description-first tool schemas (names/args/descriptions) so models generalize to unseen tools (supported by AdaReasoner’s identifier randomization).
- Potential products/workflows: Tool registries with conformance tests; certification labels for “generalization-ready” tools; auditability of tool-call logs.
- Assumptions/dependencies: Multi-stakeholder buy-in; security and rate-limiting; privacy-by-design.
- Cross-application personal agents
- Sector: Consumer software, Productivity
- What it could do: Learn to operate unfamiliar apps by reading screens, invoking OCR/pointing tools, and reflecting on outcomes; adapt to new “tool definitions” for each app.
- Potential products/workflows: Universal screenshot-based assistant for repetitive tasks across apps; explainable action plans.
- Assumptions/dependencies: Robustness to app updates; permissions and security; safety guardrails to prevent destructive actions.
- Multimodal developer copilots for visual debugging
- Sector: Software engineering
- What it could do: Inspect app screenshots, highlight misalignments/overflows, propose CSS/layout fixes with step-by-step visual verification.
- Potential products/workflows: CI annotators that reproduce bugs and verify fixes with tool-augmented reasoning.
- Assumptions/dependencies: Accurate mapping from visual issues to code regions; integration with build pipelines.
- Governance and risk frameworks for tool-augmented AI
- Sector: Policy, Compliance, Risk
- What it could do: Establish auditing standards for multi-turn tool calls, reward/penalty logs, and fallback strategies under uncertainty (mirroring adaptive rewards).
- Potential products/workflows: Third-party audits of tool orchestration policies; incident response playbooks; red-teaming protocols for tool misuse.
- Assumptions/dependencies: Transparency APIs; clear responsibility boundaries between model and tool providers; standardized logging.
Cross-cutting assumptions and dependencies
- Tool availability and quality: Performance depends on a registry of reliable visual tools (OCR, detectors, path planners) with clear argument semantics and predictable outputs.
- Latency and cost: Multi-turn orchestration adds overhead; batching, caching, and offline tools reduce cost but constrain real-time use.
- Generalization hinges on documentation: Models must receive accurate, semantically meaningful tool descriptions; description randomization in training mitigates overfitting to names.
- Safety and governance: Logging tool calls, handling tool failures, and using asymmetric rewards to discourage unsupported guessing are essential in regulated settings.
- Data security and privacy: Screenshots/documents may contain PII; enforce on-device processing or secure enclaves; adhere to data retention policies.
- Human-in-the-loop: High-stakes domains (healthcare, autonomy, public safety) require expert oversight, validation datasets, and formal verification before deployment.
Collections
Sign up for free to add this paper to one or more collections.

