GAP: Graph-Based Agent Planning with Parallel Tool Use and Reinforcement Learning
Abstract: Autonomous agents powered by LLMs have shown impressive capabilities in tool manipulation for complex task-solving. However, existing paradigms such as ReAct rely on sequential reasoning and execution, failing to exploit the inherent parallelism among independent sub-tasks. This sequential bottleneck leads to inefficient tool utilization and suboptimal performance in multi-step reasoning scenarios. We introduce Graph-based Agent Planning (GAP), a novel framework that explicitly models inter-task dependencies through graph-based planning to enable adaptive parallel and serial tool execution. Our approach trains agent foundation models to decompose complex tasks into dependency-aware sub-task graphs, autonomously determining which tools can be executed in parallel and which must follow sequential dependencies. This dependency-aware orchestration achieves substantial improvements in both execution efficiency and task accuracy. To train GAP, we construct a high-quality dataset of graph-based planning traces derived from the Multi-Hop Question Answering (MHQA) benchmark. We employ a two-stage training strategy: supervised fine-tuning (SFT) on the curated dataset, followed by reinforcement learning (RL) with a correctness-based reward function on strategically sampled queries where tool-based reasoning provides maximum value. Experimental results on MHQA datasets demonstrate that GAP significantly outperforms traditional ReAct baselines, particularly on multi-step retrieval tasks, while achieving dramatic improvements in tool invocation efficiency through intelligent parallelization. The project page is available at: https://github.com/WJQ7777/Graph-Agent-Planning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
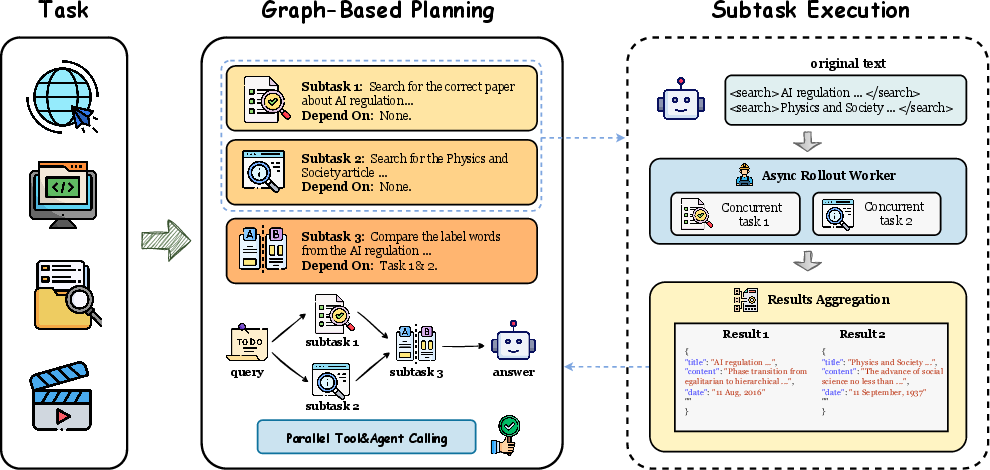
This paper introduces GAP (Graph-based Agent Planning), a smarter way for AI assistants that use LLMs to solve complex tasks with tools like search engines, calculators, or code runners. Instead of doing one step at a time, GAP teaches the AI to plan tasks as a “map” (a graph) that shows which steps depend on others. This lets the AI run independent steps in parallel (at the same time) and do dependent steps in order, making it faster and more accurate.
Key Objectives and Questions
The paper focuses on simple but important questions:
- How can an AI break a big problem into smaller steps that clearly show what depends on what?
- How can the AI decide which tools to use at the same time and which to use one after another?
- Does this planning style make the AI both faster and more correct on multi-step questions?
How GAP Works (In Everyday Terms)
Think of solving a complex question like doing a group project:
- Some tasks can be done by different teammates at the same time (like “find facts A and B”).
- Other tasks must wait for results from earlier tasks (like “compare A and B after both are found”).
GAP trains the AI to make a “task map” called a dependency graph:
- A graph is like a flowchart where each node is a sub-task (small step), and arrows show which steps must come first.
- If there’s no arrow between two tasks, they’re independent and can be done in parallel.
Here’s the overall approach, explained in friendly steps:
- Planning: The AI reads the question and breaks it into sub-tasks. It then builds a graph showing dependencies (which tasks need to be completed before others).
- Scheduling: The AI groups tasks into “levels.” All tasks in the same level have everything they need and can run together. After finishing one level, it moves to the next.
- Parallel Tool Use: For tasks in the same level, the AI triggers multiple tool calls at once (like running several searches at the same time), waits for the results, and then continues.
Data and Training (What the authors did behind the scenes)
To teach the AI this skill:
- They created about 7,000 examples of graph-based plans from multi-hop question datasets (questions that need multiple facts and steps).
- Stage 1: Supervised Fine-Tuning (SFT)
- The AI (a small model: Qwen2.5-3B-Instruct) learned to copy the planning style from the curated examples, including how to write the plan and how to group tasks for parallel execution.
- Stage 2: Reinforcement Learning (RL)
- The AI practiced and got rewarded when it produced correct answers. This pushes it to choose smarter plans and tool calls.
- The reward is simple: 1 for a correct answer, 0 for incorrect.
- This helps the AI learn when parallelizing helps and when it’s better to wait, while also keeping outputs short and efficient.
Main Findings and Why They Matter
GAP was tested on several question-answering benchmarks, especially “multi-hop” ones that need multiple steps and sources. The key results:
- Better accuracy on complex, multi-step questions
- On average, GAP improved accuracy by about 0.9% over strong baselines across multi-hop datasets (like HotpotQA and 2Wiki).
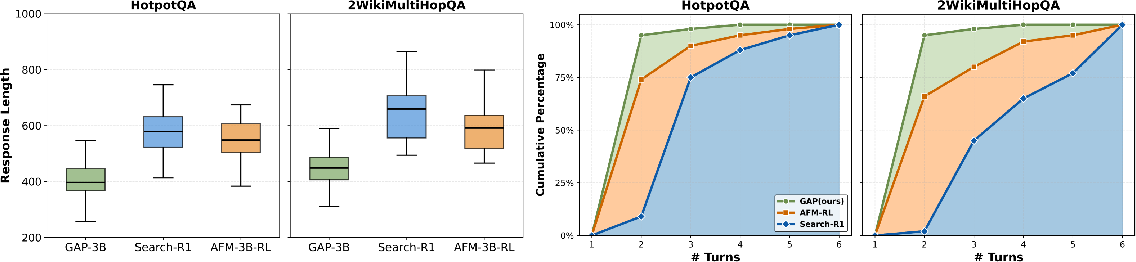
- Fewer turns (fewer back-and-forth interactions)
- On HotpotQA, GAP needed ~1.78 turns versus ~2.27 for a strong baseline (about 22% fewer).
- On 2Wiki, it needed ~2.03 turns versus ~3.05 (about 33% fewer).
- Shorter responses (fewer tokens → lower cost)
- On HotpotQA, GAP’s answers were ~25% shorter (416 vs. 554 tokens).
- On 2Wiki, ~20% shorter (452 vs. 567 tokens).
- Faster and cheaper
- Running time per batch dropped by ~32% on HotpotQA and ~21% on 2Wiki.
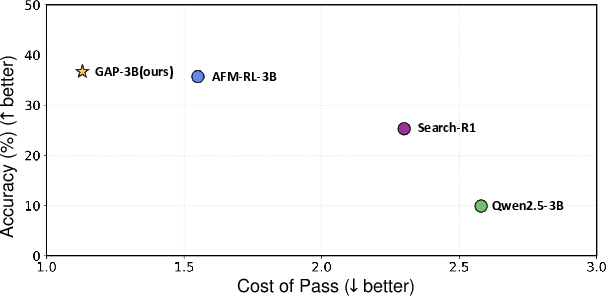
- Using the “cost-of-pass” idea (how much you spend per correct answer), GAP gave the best trade-off: high accuracy at lower cost.
These results show that smart planning and parallel tool use aren’t just clever—they make AI assistants more practical: quicker, cheaper, and still accurate.
Implications: Why GAP could change AI assistants
GAP proves that teaching AI to plan with a graph of dependencies can:
- Make AI assistants faster without sacrificing correctness, which is crucial for real-world tasks like research, web browsing, data analysis, and coding.
- Lower deployment costs by reducing tokens and tool calls.
- Bridge the gap between simple, step-by-step agents and complex multi-agent systems, but without the heavy coordination overhead.
In short, GAP helps AI “think ahead” about what can be done in parallel and what must be done in order—much like how organized people tackle big projects—making future AI assistants more efficient and reliable.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper. Each point is formulated to be concrete and actionable for future research.
- Validate GAP beyond search-only MHQA: extend experiments to heterogeneous tool suites (e.g., calculator, code interpreter, API calls, databases) to test whether graph-based parallelization generalizes across tool latencies, argument structures, and error modes.
- Realistic web environments: evaluate on dynamic, noisy, rate-limited web tasks (e.g., WebArena, live web search) to assess robustness to changing content, throttling, and partial failures under parallel calls.
- Dataset coverage and scale: increase and diversify the 7,000 GPT-4o-synthesized planning traces beyond MHQA, including non-QA tasks (code, data wrangling, multi-API workflows), and analyze domain transfer more broadly.
- Synthetic-data bias: quantify and mitigate biases introduced by GPT-4o-generated plans (e.g., stylistic homogeneity, dependency simplifications); release or benchmark against human-annotated dependency graphs for calibration.
- Graph correctness metrics: introduce evaluation of planning quality (e.g., precision/recall for dependencies, cycle detection accuracy, sub-task completeness) rather than relying only on final EM.
- DAG assumption: address tasks with iterative loops, backtracking, conditional branching, and cycles; develop methods to handle non-DAG dependencies or dynamic graphs that evolve with observations.
- Scheduling optimality: compare topological-level batching to more sophisticated schedulers (critical path analysis, latency-aware scheduling, resource-aware concurrency limits) and quantify impact on wall-clock time and token cost.
- Multi-objective RL: design and test reward functions that simultaneously optimize correctness, token length, number of turns, tool costs, latency, and plan validity—beyond the current binary correctness reward.
- Credit assignment for planning steps: explore intermediate or shaped rewards for correct graph construction (nodes, edges, parallel groups) to reduce sparse rewards and improve plan learning stability.
- Efficiency-vs-accuracy trade-offs: systematically study when parallelization harms accuracy (e.g., premature parallelization, noisy contexts); measure mis-parallelization rates and introduce guardrails.
- Adaptive re-planning: implement and evaluate dynamic plan revision (reflection) triggered by new observations, tool failures, or contradictions; measure gains from on-the-fly graph updates.
- Tool failure handling: add explicit strategies (fallbacks, retries, hedged queries, timeouts) under parallel execution; quantify robustness when some tools return errors or delayed results.
- Fairness of baselines: ensure baseline methods use identical retrieval corpora, tool stacks, and cost accounting; report setup parity to avoid confounds in performance and efficiency comparisons.
- Statistical rigor: report confidence intervals, significance tests, and variance across multiple seeds; include per-category breakdowns to identify which question types benefit most from GAP.
- Ablation studies: isolate contributions of planning, parallelization, SFT, and RL (e.g., SFT-only vs. RL-only vs. graph-disabled variants) to clarify what drives accuracy and efficiency gains.
- Context-window management: quantify how parallel batches affect context utilization (e.g., token sprawl, truncation risks), and develop strategies (result summarization, selective retention) to stay within budget.
- Parser robustness: evaluate failure modes in parsing special-token graph formats (malformed nodes/edges, missing attributes) and integrate validation/recovery mechanisms.
- Resource constraints: incorporate real-world limits (API quotas, GPU/CPU concurrency caps) into the scheduler and measure performance under constrained parallelism.
- Cost-of-pass coverage: expand cost analysis beyond tokens to include tool/API costs, latency variability, and compute utilization; report training costs (SFT, RL) for total cost-of-ownership.
- Corpus recency: assess sensitivity to outdated corpora (2018 Wikipedia) and evaluate on up-to-date or domain-specific sources to understand performance in current, evolving knowledge settings.
- Conflict resolution: develop methods for aggregating or reconciling contradictory tool outputs returned in parallel; measure the impact of conflict handling on final accuracy.
- Plan granularity: study the effects of over- and under-decomposition (too many fine-grained tasks vs. coarse tasks) on efficiency and correctness; propose adaptive granularity controls.
- Large-model scaling: evaluate GAP on larger backbones and across parameter scales; investigate whether planning advantages grow, plateau, or diminish with model size.
- Generalization to composite operations: test tasks requiring reduce/aggregate steps (e.g., joins, arithmetic, set operations) and measure how well the graph captures shared intermediates and non-trivial orchestration.
- Reproducibility and release: provide full details of prompts, synthesis pipeline, filtering criteria, hyperparameters, and code for parallel execution; release datasets and logs to enable independent verification.
Practical Applications
Immediate Applications
Below are practical applications that can be deployed now, leveraging GAP’s dependency-aware graph planning and parallel tool execution. Each item highlights the sector, concrete use case, emerging tools/workflows, and key assumptions/dependencies that affect feasibility.
- Enterprise search and knowledge management (software; knowledge ops)
- Use case: Internal question answering over wikis, tickets, and docs where sub-queries (e.g., “find policy A,” “find procedure B,” “extract step C”) can be retrieved in parallel and then synthesized.
- Tools/workflows: “GAP Planner SDK” to build DAGs of sub-queries; parallel search executor; graph-trace logging for audit.
- Assumptions/dependencies: Tools/APIs must support concurrent calls and rate-limiting; corpora are indexed and retrievable; the agent can correctly infer independence between sub-tasks.
- Web automation and RPA (software; operations)
- Use case: Automate multi-tab web research tasks (e.g., price comparisons, vendor compliance checks) with parallel browsing, then aggregate results into a decision.
- Tools/workflows: Browser-agent orchestrator that batches <search> calls; topological scheduling of page interactions; caching.
- Assumptions/dependencies: Stable DOM/API endpoints; concurrency controls; anti-bot policies; robust timeout/error handling.
- Customer support knowledge agents (service; contact center)
- Use case: Resolve tickets faster by parallel retrieval across FAQs, historical tickets, and product manuals, then synthesize a resolution.
- Tools/workflows: Agent DAG Scheduler integrated with CRM/KB APIs; parallel embedding-based retrieval (E5 or equivalent).
- Assumptions/dependencies: Knowledge sources are accessible and up to date; token budgets permit multiple retrievals; correct dependency modeling for steps that truly require sequential context.
- Data analysis and BI (software; analytics)
- Use case: Parallel querying of multiple databases/data marts for KPI components (e.g., revenue, costs, headcount) followed by an overview step.
- Tools/workflows: SQL/API call batching per execution level; result aggregator; provenance via graph traces.
- Assumptions/dependencies: Data sources can be queried concurrently; eventual consistency won’t mislead synthesis; access control and auditing are in place.
- Scientific and market research assistants (academia; finance; product)
- Use case: Multi-hop literature or market landscape reviews where independent sub-questions (competitors, metrics, regulatory constraints) are retrieved in parallel.
- Tools/workflows: Parallel retrieval from PubMed/arXiv/industry databases; hybrid search + summarization; dependency-aware synthesis.
- Assumptions/dependencies: High-quality indices; domain-specific query templates; duplication/overlap managed during synthesis.
- Software engineering workflows (software; devops)
- Use case: Agent-driven code refactoring or feature design that parallelizes auxiliary tasks (collect references, check tests, read docs), then plans sequential integration/testing.
- Tools/workflows: CI plug-in that creates DAGs of checks; batch runs of static analysis/tests; synthesis of findings.
- Assumptions/dependencies: Compute capacity for concurrency; flaky tests handled; security policies for tool invocation.
- Legal and compliance e-discovery (legal; compliance)
- Use case: Parallel search across document repositories, case law, and policy archives followed by a sequential legal synthesis.
- Tools/workflows: Parallel query executor tied to legal databases; graph-based trace for auditability.
- Assumptions/dependencies: Licensing and access; standardized citation workflows; careful management of hallucination risks.
- Education and tutoring (education)
- Use case: Personalized study plans where independent sub-topics (definitions, examples, exercises) are sourced in parallel, then presented as a dependency-aware learning path.
- Tools/workflows: Curriculum planner that encodes prerequisite DAGs; parallel content retrieval; sequenced practice generation.
- Assumptions/dependencies: Curriculum mappings available; content quality filters; teacher oversight for correctness.
- Healthcare information retrieval (healthcare; clinical ops)
- Use case: Non-diagnostic knowledge queries (guidelines, drug interactions, coverage policies) decomposed into parallel sub-queries and consolidated for clinicians or staff.
- Tools/workflows: Parallel search across guideline repositories/drug databases; synthesis with traceable references.
- Assumptions/dependencies: Regulatory constraints; strict accuracy requirements; reliable source provenance.
- Personal productivity assistants (daily life)
- Use case: Travel planning that parallelizes flight/hotel/local activity searches, then sequences bookings as dependencies are resolved.
- Tools/workflows: Agent-enabled parallel API calls to travel sites; plan DAG visualization; synthesis and recommendation.
- Assumptions/dependencies: API rate limits; time-sensitive prices; user consent and data usage policies.
- Cost-aware deployment and monitoring (software; platform ops)
- Use case: Adopt cost-of-pass monitoring to measure token cost vs. success rates for agent tasks and dynamically tune parallelism.
- Tools/workflows: “Cost-of-Pass monitor” tied to graph-execution telemetry; concurrency tuning per task type.
- Assumptions/dependencies: Accurate success metrics; cost dashboards; organizational appetite for cost-performance optimization.
- Agent platform integration (software; MLOps)
- Use case: Integrate GAP into LangChain/LlamaIndex-style frameworks as a planning module that emits DAGs and execution levels for existing tools.
- Tools/workflows: GAP Planner adaptor; parallel batch executor; structured trace outputs.
- Assumptions/dependencies: Smooth interoperability with tool runners; robust parsing of plan schemas; fallback to sequential when uncertainties are high.
Long-Term Applications
These applications are promising but require additional research, scaling, safety validation, or domain adaptation beyond multi-hop QA.
- Autonomic enterprise workflow orchestration (software; enterprise IT)
- Use case: Agents learn and reconfigure complex business workflows (procure-to-pay, incident response) with DAG-based planning and adaptive parallelism.
- Tools/workflows: End-to-end agent orchestration layer over microservices; dynamic dependency learning from logs; policy-constrained scheduling.
- Assumptions/dependencies: Verified safety policies; strong observability; change management; reliable automatic dependency extraction.
- Mission-critical healthcare assistants (healthcare)
- Use case: Advanced clinical decision support with parallel retrieval of evidence, labs, and history, followed by safety-checked synthesis and recommendations.
- Tools/workflows: Medical-grade agents with validated DAG planners; human-in-the-loop reviews; strict compliance (HIPAA, GDPR).
- Assumptions/dependencies: Clinically validated models; robust calibration; liability frameworks; audit trails.
- Robotics and autonomous systems (robotics)
- Use case: Parallel sensor fusion and task planning where independent perception tasks execute concurrently and feed sequential control decisions.
- Tools/workflows: Multi-modal DAGs; real-time schedulers; latency-aware execution levels.
- Assumptions/dependencies: Real-time guarantees; hardware acceleration; safety certification; reliable independence detection across modalities.
- Smart grid and energy operations (energy)
- Use case: Parallel forecasting of demand, generation, and prices feeding sequential dispatch and storage strategies.
- Tools/workflows: DAG-based planning across time-series models; parallel inference pipelines; operator-in-the-loop synthesis.
- Assumptions/dependencies: High data quality; resilience to model drift; regulatory oversight.
- Financial research and risk analysis (finance)
- Use case: Parallel data ingestion from markets, filings, and news, then sequential risk aggregation and scenario planning with provenance.
- Tools/workflows: Compliance-aware planning graphs; explainable synthesis; cost-of-pass optimization for high-volume analyses.
- Assumptions/dependencies: Data licensing; adversarial information risks; explainability demands.
- Government digital services and policy evaluation (policy; public sector)
- Use case: Parallel evidence collection across agencies and public datasets; sequential synthesis into policy briefs with transparent dependency graphs.
- Tools/workflows: Audit-ready graph traces; standardized evaluation pipelines; public accountability dashboards.
- Assumptions/dependencies: Inter-agency data sharing; privacy/security; procurement standards for agent systems.
- Multi-agent simulation within single AFMs (academia; software)
- Use case: A single model internally simulates multi-agent coordination using graph planning, achieving MAS-like performance without orchestration overhead.
- Tools/workflows: Advanced AFM training with multi-objective rewards (accuracy, latency, cost, safety); curriculum for dependency learning.
- Assumptions/dependencies: Scalable RL (ToRL/DAPO variants); robust reward shaping beyond binary correctness; reliable generalization across domains.
- Automatic dependency discovery and learning (software; data engineering)
- Use case: Agents infer latent dependencies from logs and traces to build DAGs automatically, reducing manual workflow design.
- Tools/workflows: Sequence mining for dependency detection; uncertainty-aware planners; continuous learning.
- Assumptions/dependencies: High-quality telemetry; mechanisms to avoid spurious correlations; human verification in critical contexts.
- Safety, reliability, and governance frameworks for agent DAGs (policy; standards)
- Use case: Standardize graph-trace formats, risk assessments, and compliance checks for parallel tool use in regulated industries.
- Tools/workflows: “Graph Trace Logger” standards; audit schemas; incident review protocols; red-teaming of dependency planners.
- Assumptions/dependencies: Cross-industry consensus; certification bodies; integration with existing governance processes.
- Edge and on-device agent execution (software; IoT)
- Use case: Run small AFMs (e.g., 3B class) with parallel tool orchestration on constrained hardware for local tasks (factory monitoring, smart home).
- Tools/workflows: Lightweight DAG schedulers; streaming context management; tool-call batching optimized for low memory.
- Assumptions/dependencies: Hardware acceleration; robust local toolset; privacy-preserving designs; model compression.
- Human-agent co-planning interfaces (daily life; enterprise)
- Use case: Visual DAG editors where users approve or adjust dependency graphs before execution, combining transparency with efficiency.
- Tools/workflows: Interactive plan visualizers; execution-level previews; “what-if” parallelization simulators.
- Assumptions/dependencies: Usability research; effective explanations; training for non-technical users.
- Advanced evaluation and procurement practices (policy; platform ops)
- Use case: Institutionalize cost-of-pass and efficiency metrics (turns, tokens, latency) in model procurement and benchmarking.
- Tools/workflows: Unified evaluation suites; scenario-based tests for parallelism benefits; budget-aware orchestration policies.
- Assumptions/dependencies: Reliable, comparable metrics; acceptance in procurement; alignment to organizational KPIs.
Glossary
- Adjacency structure: A representation of a graph storing, for each node, the set of nodes it connects to. "We represent this graph using an adjacency structure that explicitly encodes:"
- Agent Foundation Models (AFMs): Foundation models trained for intrinsic agentic abilities such as planning and tool use. "We introduce GAP, a novel training paradigm for agent foundation models that incorporates dependency-aware task planning, enabling dynamic parallel and serial tool execution."
- Cost-of-pass metric: An efficiency metric measuring expected cost to obtain a correct answer, computed as cost per attempt divided by success rate. "we follow \citep{erol2025cost} and adopt the cost-of-pass metric to quantify model efficiency."
- DAPO: A large-scale reinforcement learning algorithm used to optimize policy parameters for agent training. "and optimize policy parameters with DAPO\citep{yu2025dapo}."
- Dependency graph: A graph where nodes are sub-tasks and edges encode prerequisite relationships among them. "Given the constructed dependency graph , GAP determines an optimal execution strategy that balances parallelization opportunities with dependency constraints."
- Dependency-aware planning: Planning that explicitly models which sub-tasks depend on others to decide parallel vs. sequential execution. "enables LLM-based agents to perform dependency-aware planning through explicit graph-based reasoning."
- Directed acyclic graph (DAG): A directed graph with no cycles, often used to encode dependencies. "We model task dependencies as a directed acyclic graph (DAG): , where each vertex represents a sub-task and each directed edge indicates that sub-task depends on the output of sub-task ."
- End-to-End Agentic Reinforcement Learning: A training setup where the entire agent, including planning and tool use, is optimized via RL directly from task outcomes. "End-to-End Agentic Reinforcement Learning"
- Exact Match (EM): A strict accuracy metric that checks if the predicted answer string exactly equals the ground truth. "We use Exact Match (EM) as the evaluation metric to assess both in-domain and out-of-domain performance."
- Execution levels: Layers of nodes in a DAG (obtained via topological sorting) where nodes in the same layer can run in parallel. "We partition the graph into execution levels using topological sorting, where:"
- Graph-based Agent Planning (GAP): The proposed framework that builds and reasons over dependency graphs to orchestrate parallel and sequential tool use. "We introduce Graph-based Agent Planning (GAP), a novel framework that explicitly models inter-task dependencies through graph-based planning to enable adaptive parallel and serial tool execution."
- Graph-based dependency modeling: Modeling task relationships using graph structures to inform execution order and parallelism. "Our work establishes graph-based dependency modeling as a critical direction for developing more efficient autonomous agents,"
- Multi-agent systems (MAS): Architectures with multiple specialized agents collaborating to solve tasks. "Current approaches to tool-augmented reasoning can be broadly categorized into two paradigms: multi-agent systems (MAS) and tool-integrated reasoning (TIR) models."
- Multi-Hop Question Answering (MHQA): QA tasks requiring reasoning across multiple pieces of evidence via intermediate steps. "graph-based planning traces derived from the Multi-Hop Question Answering (MHQA) benchmark."
- Observation masking: Training technique that masks tool outputs in the loss to avoid overfitting to environment noise. "with observation masking () to prevent environmental noise propagation."
- Parallel tool call batch: A set of tool invocations issued simultaneously for independent sub-tasks. "the model generates a parallel tool call batch:"
- Parallel tool execution: Executing multiple tool calls at the same time when sub-tasks are independent. "Graph-based Agent Planning with Parallel Tool Execution"
- Parametric knowledge: Information encoded in model parameters rather than retrieved or computed externally. "beyond the inherent limitations of parametric knowledge."
- ReAct: A reasoning-and-acting paradigm where LLMs interleave thoughts, actions, and observations in sequence. "existing paradigms such as ReAct rely on sequential reasoning and execution, failing to exploit the inherent parallelism among independent sub-tasks."
- ReAct-style Tool-Using: The specific ReAct approach of interleaving “Thought-Action-Observation” steps for tool use. "ReAct-style Tool-Using"
- Reward function: The signal used in RL to evaluate and improve the agent’s behavior, often based on answer correctness. "followed by reinforcement learning (RL) with a correctness-based reward function"
- Supervised Fine-Tuning (SFT): Training a model on curated demonstrations to teach desired behaviors before RL. "We employ a two-stage training strategy: supervised fine-tuning (SFT) on the curated dataset,"
- Tool-augmented reasoning: Reasoning that integrates external tools (e.g., search, code) to extend model capabilities. "A key enabler of these capabilities is tool-augmented reasoning, where agents leverage external tools"
- Tool-Integrated Reasoning (TIR): Paradigm that trains LLMs to invoke tools as part of their reasoning process. "Tool-Integrated Reasoning (TIR) models represent an emerging paradigm that explicitly trains LLMs to incorporate tool usage into their reasoning process."
- Topological sorting: An ordering of DAG nodes such that all dependencies precede dependent tasks, used for scheduling. "We partition the graph into execution levels using topological sorting, where:"
- Trajectory synthesis: Automated generation of reasoning traces (plans/executions) for training data. "approximately 7,000 high-quality training trajectories were generated through trajectory synthesis and quality filtering."
- VeRL: An RL framework used to train LLMs efficiently. "We use the VeRL framework\citep{sheng2025hybridflow} for DAPO training."
Collections
Sign up for free to add this paper to one or more collections.