- The paper presents a novel RKHS-based surrogate model that enforces symplectic structure via gradient-constrained kernel interpolation.
- It achieves algebraic error decay with up to 3-4 orders of magnitude reduction in trajectory error compared to conventional integrators on systems like pendulums and spring-mass chains.
- The approach employs an f-greedy algorithm for kernel center selection and symplectic model order reduction, ensuring robust long-term predictions in high-dimensional simulations.
Symplecticity-Preserving Prediction of Hamiltonian Dynamics by Generalized Kernel Interpolation
Introduction and Motivation
This work introduces an RKHS-based surrogate modeling approach for long-horizon prediction of Hamiltonian systems that ensures symplecticity of the learned discrete-time propagator. The core insight is to learn a scalar potential whose gradient, evaluated in a mixed variable, parameterizes an implicit symplectic Euler map. This guarantees that the resulting predictor preserves the canonical symplectic structure, yielding trajectory evolution with no artificial phase-space compression or dilation, invertibility, and robust error behavior over long time scales.
Preservation of geometric properties (energy, symplectic structure) is critical for the physical plausibility and numerical stability of Hamiltonian system simulations, especially over large integration intervals (ΔT). Conventional numerical integrators and neural surrogates typically cannot guarantee these properties, leading to long-term drift or instability. Symplectic neural architectures, symplectic integrators, and flow-map learners have attempted to address these issues, but often with restrictive assumptions (e.g., separability) or at the cost of expressivity. This work generalizes the surrogate design by leveraging generalized (Hermite-Birkhoff) kernel interpolation to match gradients at mixed input arguments, with existence and uniqueness rigorously established under verifiable conditions.
Theoretical Foundations
Hamiltonian flow maps can be characterized as symplectomorphisms. For systems where the exact flow is only accessible via fine-grained simulation, the approach learns a surrogate generating function for the time-ΔT flow via Hermite-Birkhoff interpolation in an RKHS. The interpolation constraints enforce that the gradient of the surrogate, evaluated at a specific mixed input (combining initial configuration and future momentum), matches the observed discrete flow increments.
This leads to a surrogate update of the form
xΔT,pred=x0+ΔTJ2n∇s(q0,pΔT,pred)
where s is the learned scalar-valued kernel surrogate, ensuring that the predictor manifests as a discrete-time symplectic integrator. Uniqueness, existence, and convergence rates for HB interpolation with RKHS kernels are established under natural regularity and data conditions. Precise locality or quantification of the step size required for well-posedness is rigorously analyzed, with global guarantees for the special case of quadratic Hamiltonians.
Algorithmic Construction and Greedy Approximation
Since dense kernel interpolation can be computationally intractable and ill-conditioned for large datasets, an f-greedy algorithm selects a highly informative subset of kernel centers that drive the rapid reduction of the gradient residual, as quantified via power functions and rigorously bounded using AM–GM inequalities and orthogonal projection identities. The f-greedy scheme achieves nearly algebraic error decay in both theory and empirical tests, as evident in results below.
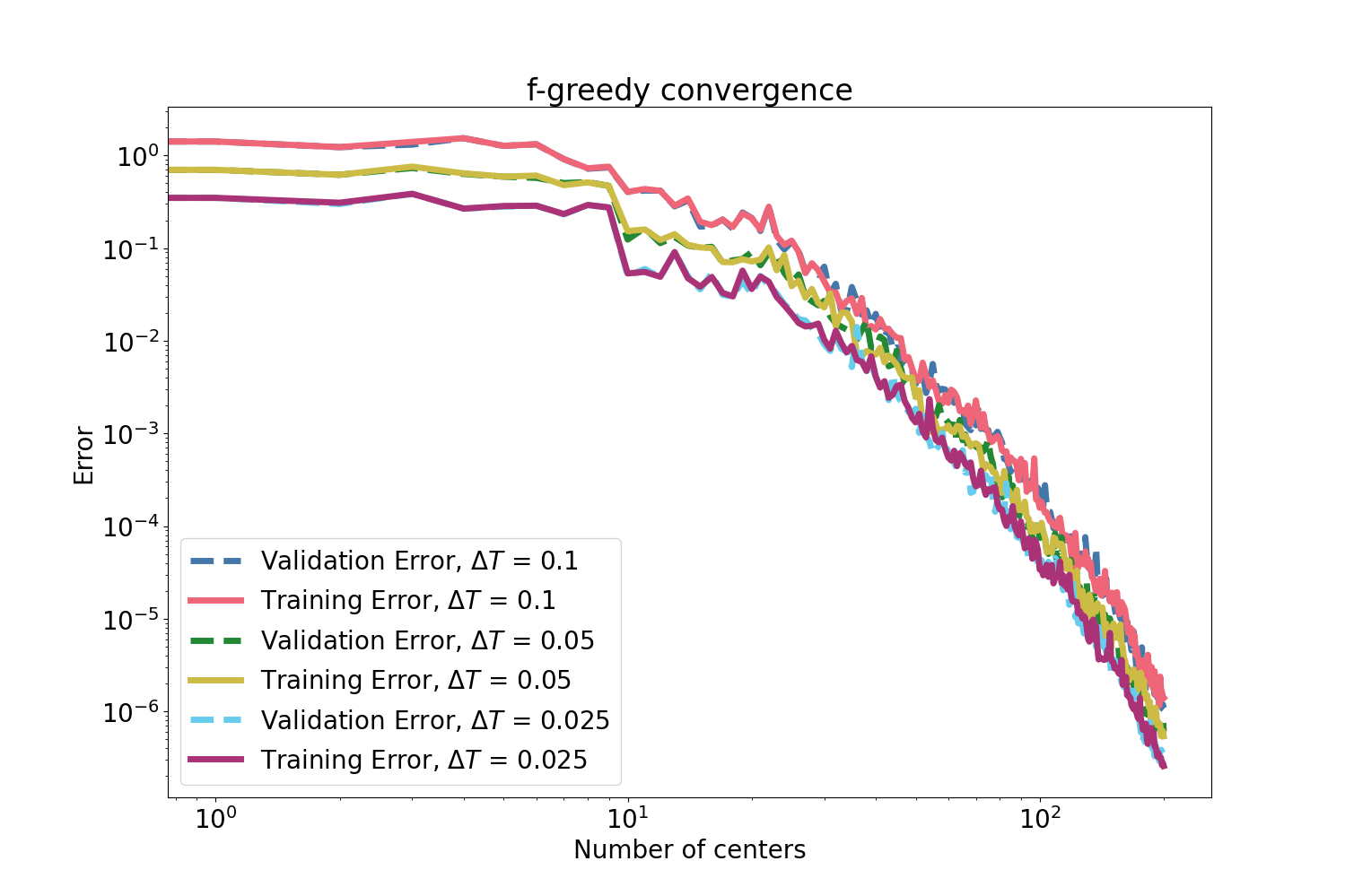
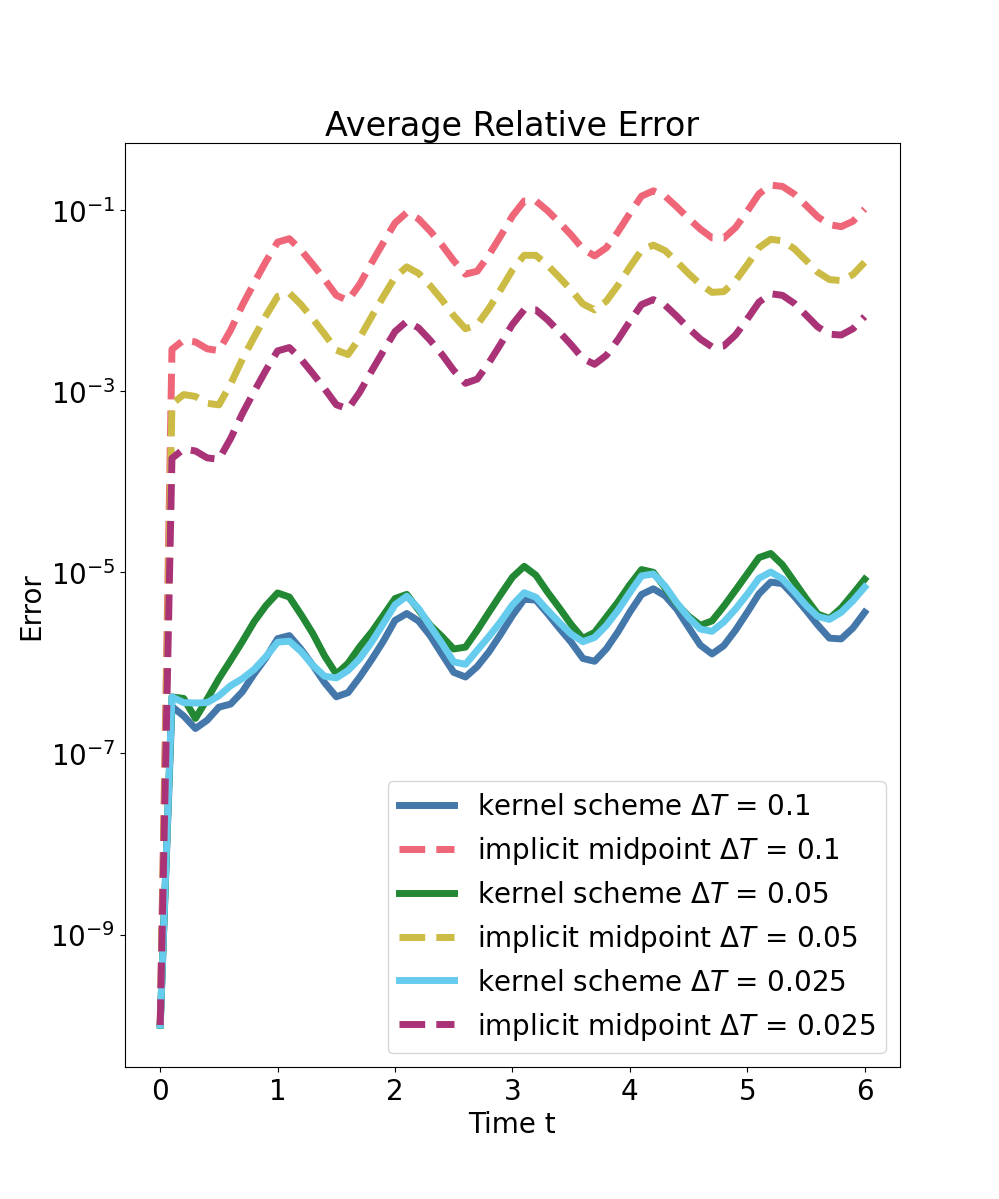
Figure 1: f-greedy interpolation error versus selected centers for three ΔT, showing rapid algebraic convergence in both training and validation for the pendulum.
The learned surrogate is further combined with structure-preserving model order reduction—specifically, symplectic projection using cSVD—for efficient handling of high-dimensional PDE discretizations. This ensures that low-dimensional reduced-order models retain key Hamiltonian properties and enables tractable application on semi-discretized wave equations and other PDEs.
Numerical Results
Pendulum System
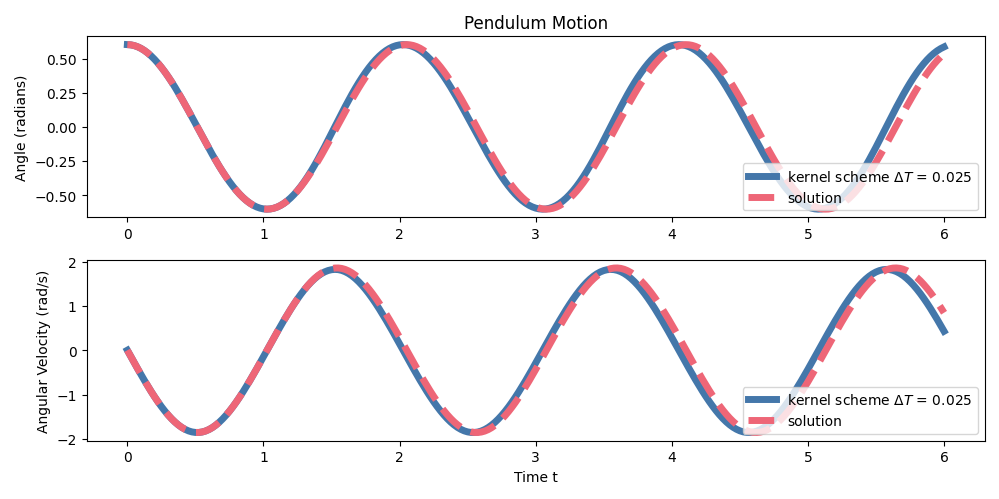
The methodology is validated first on the canonical pendulum with variable macro-step sizes. The f-greedy selection exhibits robust convergence of the interpolant gradient residual on both training and validation sets.
Predictions are compared to high-fidelity implicit midpoint integration (reference solver) and a structure-preserving implicit midpoint baseline at the same macro time step. Strong numerical evidence is provided:
Spring–Mass Chain
For a nonlinear mechanical chain, the kernel surrogate is trained on energy-constrained random initializations and tested on independent samples. Results show that:
- Algebraic error reduction is observed as the number of kernel centers increases.
- Training and validation errors are closely matched, indicating effective generalization and no significant overfitting.
- The predictor outperforms structure-preserving baseline integrators, with an error improvement of one to two orders of magnitude for large steps, even in out-of-domain generalization.
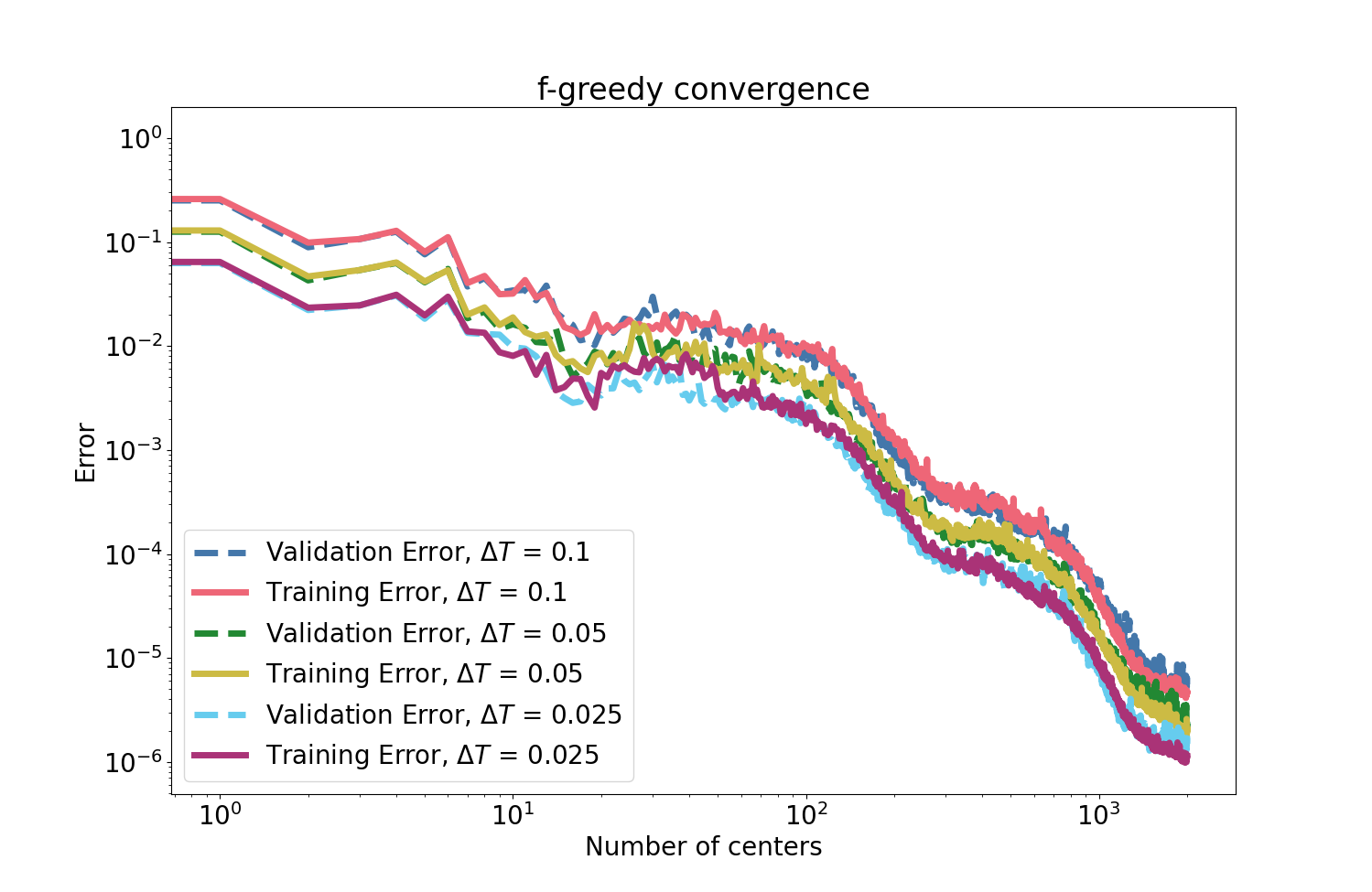
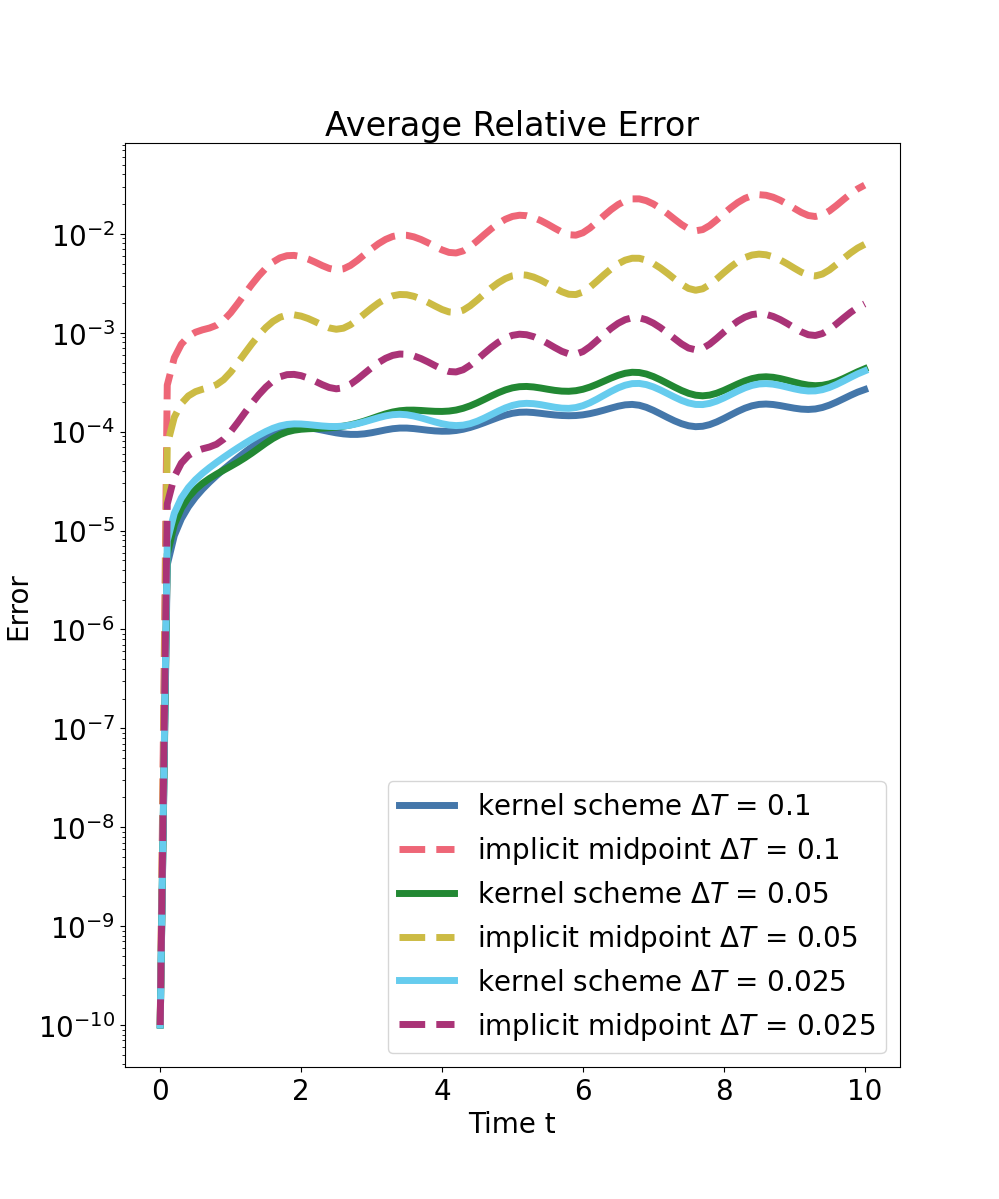
Figure 3: f-greedy interpolation error and its monotonic decrease with number of selected centers for the mass–spring system.
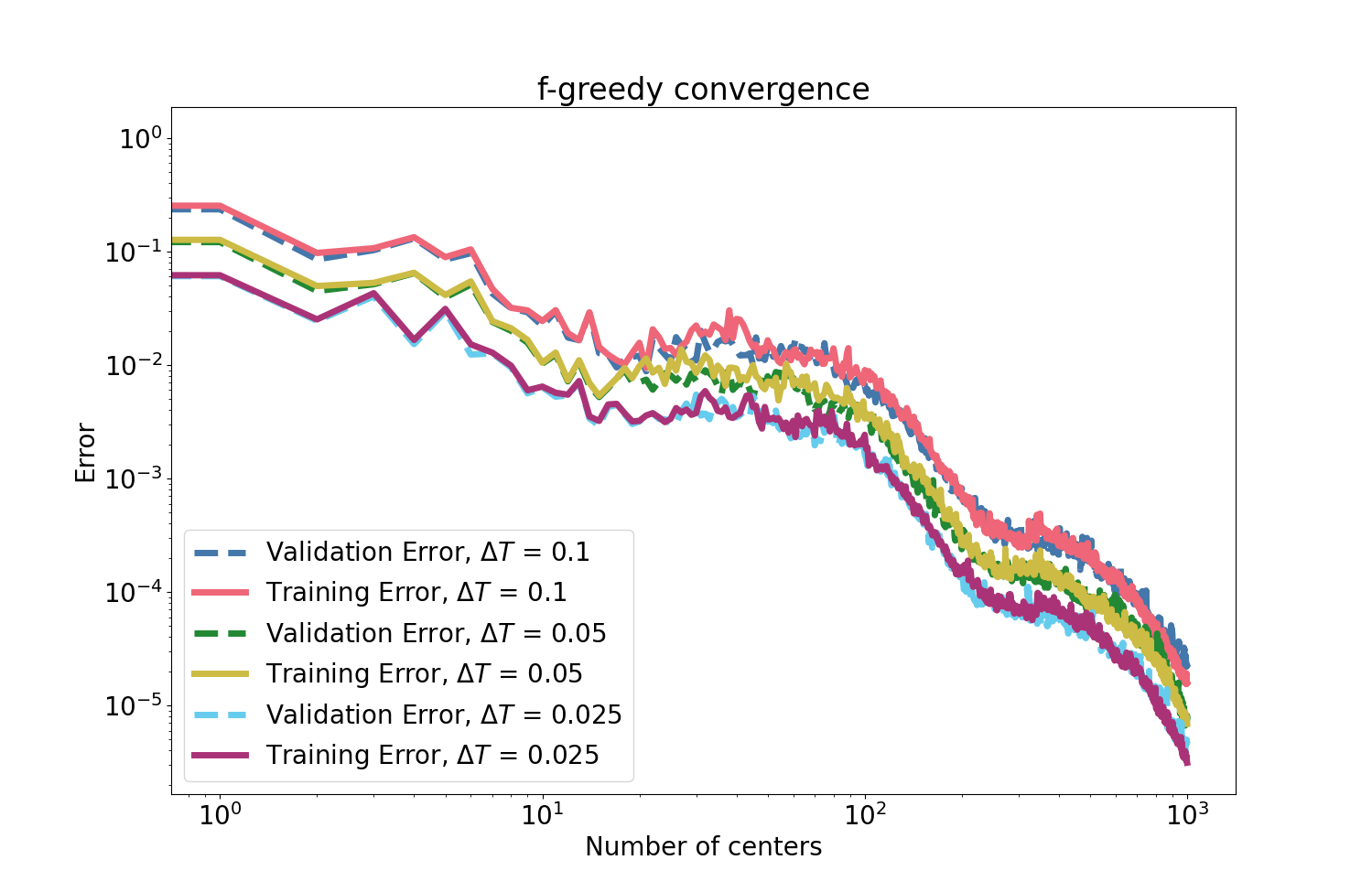
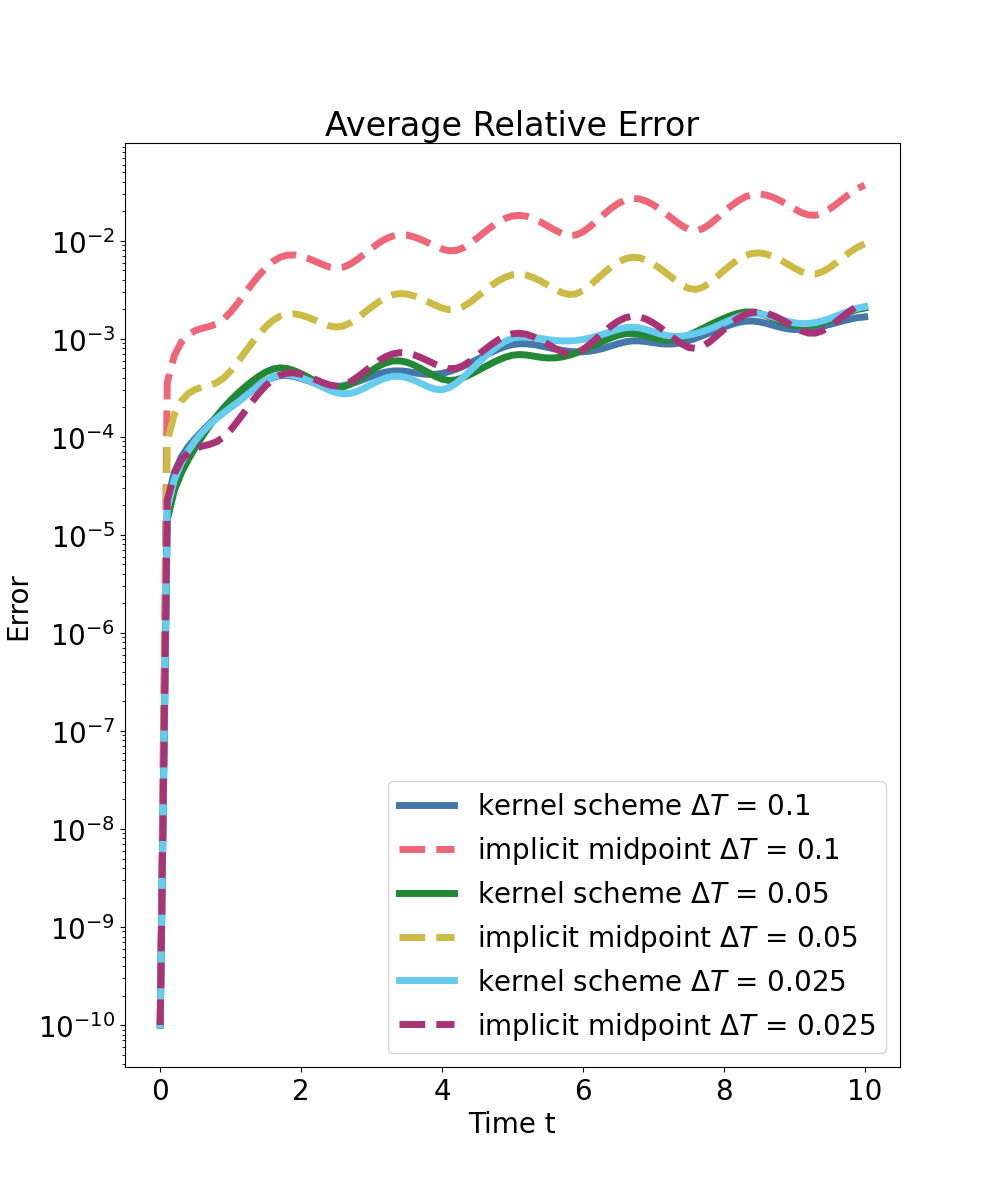
Figure 4: Error convergence maintains its efficacy also with a reduced (half-domain) training set for the mass–spring system.
Semi-Discrete Wave Equation
A high-dimensional wave system discretized with 1000 degrees of freedom and aggressively reduced by symplectic MOR (e.g., cSVD) is considered. The kernel surrogate is trained only on reduced coordinates but maintains the Hamiltonian structure. Key findings include:
- The f-greedy approach continues to yield rapid, algebraically decaying errors in the high-dimensional setting.
- The symplectic kernel predictor consistently achieves error reductions of two to three orders of magnitude for all tested macro time steps compared to the structure-preserving baseline.
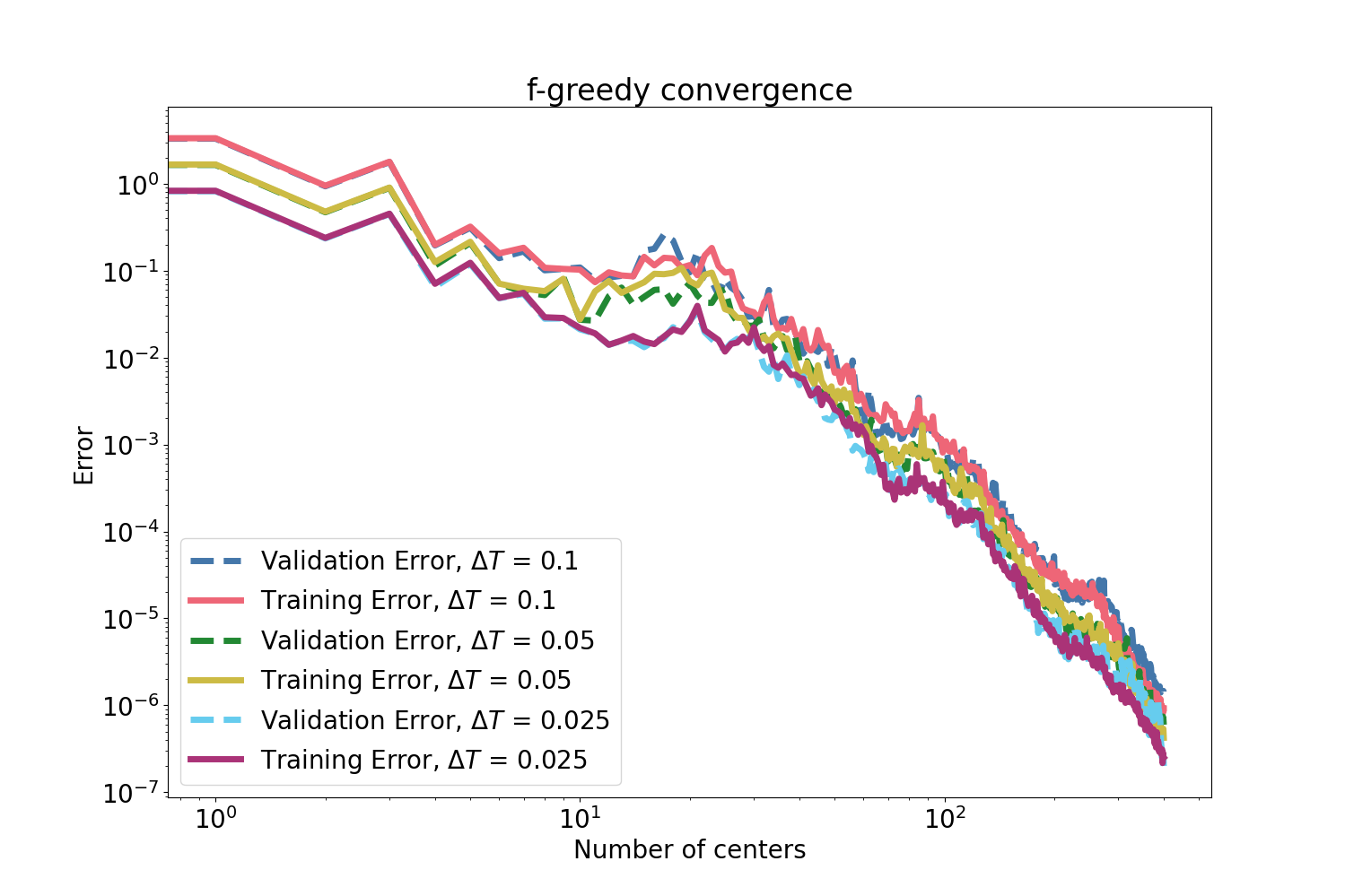
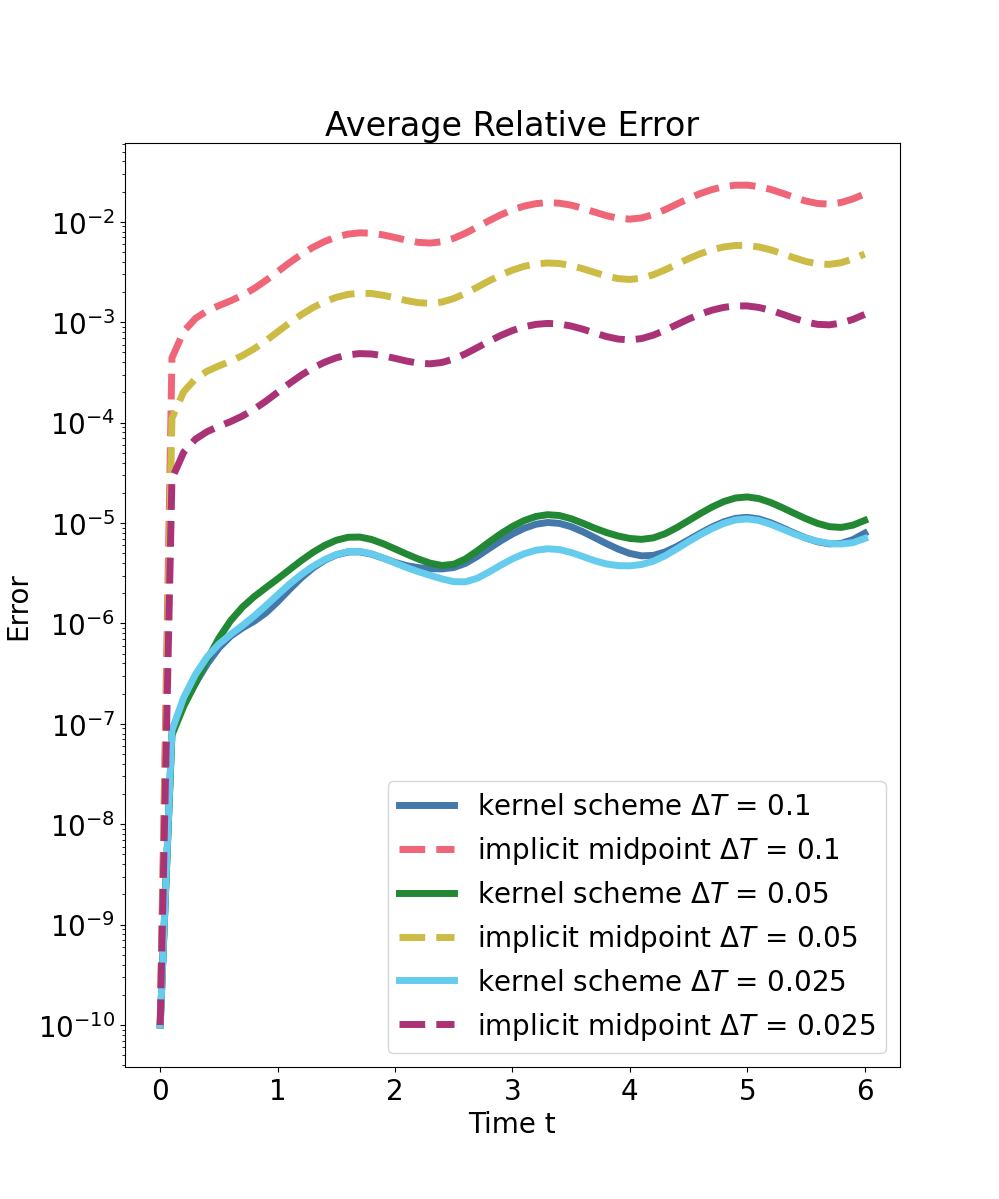
Figure 5: f-greedy interpolation error as a function of selected centers for the reduced wave model, demonstrating consistent error decay across multiple macro time steps.
Implications and Future Directions
This kernel-based symplectic surrogate approach fills a methodological gap in long-horizon prediction for Hamiltonian systems: it removes the necessity for separable Hamiltonian architectures, provides theoretical guarantees on existence, uniqueness, and convergence, and delivers structure preservation by construction, even when training on high-dimensional and long-step data. It supports efficient, robust simulation and forecast in computational physics, control, and engineering.
Key numerical results highlight strong improvements in accuracy and generalization relative to widely used structure-preserving integrators. The demonstrated error contraction rates are reliable and robust under variations in time-step and domain subsampling.
Theoretically, the construction realizes the composition of geometric integrator principles with kernel surrogate modeling. In the PDE and large-scale ODE context, this enables tractable surrogate modeling without sacrificing structural fidelity, which is essential for both stability and interpretability.
Future research avenues include learning surrogates that interpolate not only over states but also step size ΔT, supporting adaptive and variable-step prediction. Leveraging parameterized families of generating functions or time-augmented kernels would further broaden the applicability to adaptive time-stepping and real-time control. Extensions to other symplectic geometric structures (e.g., Poisson, contact flows) are natural next steps.
Conclusion
This study establishes a systematic, RKHS-based construction for learning symplectic discrete-time integrators for Hamiltonian systems by gradient-constrained kernel interpolation. Existence and convergence are rigorously justified. Numerical results for prototypical mechanical systems show rapid (algebraic) error reduction and robust trajectory prediction, outperforming classical structure-preserving baselines. The approach enables scalable, structure-preserving surrogate modeling adaptable to high-dimensional, high-fidelity physical simulations.