- The paper presents a rigorous pathwise error analysis for generalized Langevin equations with approximated memory kernels.
- It derives explicit error bounds via Volterra resolvent theory and hypocoercive Lyapunov techniques, linking decay rates to kernel approximation quality.
- Numerical experiments validate the scaling laws, providing practical insights for kernel learning and model reduction in non-Markovian systems.
Error Analysis of Generalized Langevin Equations with Approximated Memory Kernels
Introduction and Motivation
This paper analyzes the propagation of kernel approximation errors in generalized Langevin equations (GLEs) understood as non-Markovian stochastic Volterra systems. The GLE plays a central role in coarse-grained modeling of high-dimensional stochastic dynamics, encapsulating both memory-dependent friction and stochastic forcing. In many practical and data-driven contexts, the memory kernel K(t,s) must be estimated from finite data via machine learning or kernel identification schemes. Understanding how trajectory prediction errors scale in terms of the kernel estimation error is essential for both theoretical and practical aspects of reliable model reduction.
A key technical challenge addressed here is the analysis of pathwise error bounds and decay rates in models with subexponentially or exponentially decaying kernels, particularly where translation invariance is broken (e.g., kernels arising from HiPPO/SSM constructions in LLMs). The analysis rests on the interplay between Volterra resolvent theory, weighted operator norms, and hypocoercive Lyapunov distances.
Mathematical Framework and Main Results
The GLE for a position-velocity pair (Xt,Vt) reads: dXt=Vtdt,dVt=−γVtdt−∇U(Xt)dt−∫0tK(t,s)Vsdsdt+σdBt
with confining potential U, noise σdBt, and memory kernel K(t,s). The analysis considers both (i) first-order models (removing inertia), and (ii) second-order (underdamped) models, under both white noise and various classes of K.
The paper proves that, under mild regularity on K(t,s) (notably, subexponential or exponential decay in a weighted sense---as formalized by the class U(μ)), the trajectory discrepancy between a GLE using K and that using a perturbed kernel K~, with synchronized (matched) noise realizations, can be uniformly controlled: t≥0supE∥Vt−V~t∥2≤C∥K−K~∥h2h(t)+(noise term)
where h(t) encodes the decay of the kernel, and ∥⋅∥h is a Schur-type operator norm weighted by h.
The approach synthesizes (i) the Volterra resolvent framework for first/second-order systems, (ii) precise characterization of decay rates for classes of subexponential and exponential kernels, and (iii) Lyapunov-based hypocoercivity arguments for contracting dynamics under strongly convex U. The error contracts at the rate dictated by the tail of the memory kernel, and its prefactor is directly proportional to the L2-type weighted kernel error.
For second-order GLEs with a confining potential, Lyapunov functionals of combined position/velocity are introduced, leveraging the hypocoercive structure to extend contraction and error stability to the underdamped context.
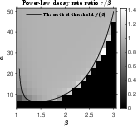
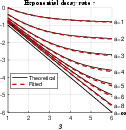
Figure 1: Ratio r/β between fitted and predicted decay rates for trajectories with power-law kernel k(t)=(t+0.1)−β; optimal decay is achieved precisely when theoretical conditions are met.
Analysis and Theoretical Insights
Volterra Comparison and Decay Classes
The authors generalize classical Grönwall-type estimates to the Volterra context, deriving explicit bounds via a comparison theorem valid in weighted spaces. For subexponential k, exponential k, and mixed regimes, they use resolvent constructions to show that solutions exhibit the same decay as k up to multiplicative constants.
Key to these results is the scale of the weighted Schur norm ∥K∥h, which reflects both the tail behavior of K and the structure of the weighting function h. For classical translation-invariant kernels, the Schur norm reduces to a weighted L2 norm.
Pathwise Error Control for Perturbed Kernels
Letting δK:=K−K~, the paper establishes (for both first- and second-order models) that the error in the coupled process contracts at the kernel's decay rate, with overall error bounded by: E∣Vt−V~t∣2≲∥δK∥h2h(t)+(initial error+noise contribution)
where the constant depends on the kernel decay, friction, and the confining potential (in the underdamped case). Wasserstein-2 distances between evolved laws of (Xt,Vt) and (X~t,V~t) are likewise bounded.
These results hold for non-translation-invariant matrix-valued kernels, as relevant in state-space models inspired by HiPPO/LLM architectures, and for both white noise and translation-varying noise models, provided FDT compatibility is not strictly imposed.
Hypocoercive Metrics for Second-Order GLEs
In the presence of a strongly convex potential U, the analysis constructs a family of Lyapunov distance functionals r((x,v),(x~,v~)) that are contractive under the dynamics with explicit constants, using coupling and derivative calculations extended from prior work on Markovian Langevin processes. This is a critical innovation: it allows the extension of error control into the underdamped regime, encompassing long-memory and inertial effects not accessible to prior approaches.
Numerical Experiments
The numerical section validates the theory using both power-law (subexponential) and exponential kernel models, and a range of perturbation structures (translation, dilation, cutoff, and oscillatory perturbations). Two key findings emerge:
- The empirical error in trajectory predictions scales linearly with the squared kernel norm ∥K−K~∥h2, except in cases where the kernel decay regime is violated (e.g., cutoff/dilation outside theoretical assumptions).
- The fitted decay rate of the error aligns quantitatively with the theoretical predictions, confirming both the sharpness and necessity of the decay conditions established.
Figure 1: Empirical vs. theoretical decay rates for power-law and exponential kernels across a range of kernel and friction parameters.
In both first- and second-order systems, the scaling law and decay rate are robust to the dimension and to matrix-valued kernels.
Implications and Future Directions
The results provide a foundational trajectory-level stability estimate suitable for data-driven modeling of non-Markovian phenomena. Practically, this analysis offers explicit guidance for kernel learning and model reduction: one can directly target weighted L2 kernel error minimization to control prediction performance to within a quantified bound at any finite time. The framework accommodates non-translation-invariant and non-stationary kernels, making it relevant for emerging architectures in signal processing, SSMs, and LLMs.
Theoretically, the work invites extensions in several directions: incorporation of fluctuation-dissipation-consistent correlated noise, resolving sharp contraction rates in the underdamped, small-friction regime, and generalization to nonlinear kernel structures or high-order Volterra-type systems. Further integration with kinetic and PDE-based techniques for hypocoercivity and decay analysis could sharpen or relax current assumptions.
Conclusion
This paper delivers a comprehensive, quantitative assessment of trajectory prediction errors in GLEs as a function of the underlying memory kernel approximation. The analysis establishes time-uniform pathwise stability in Volterra-type non-Markovian SDEs, with constants scaling linearly in a weighted kernel norm and decay rates determined by the tail behavior of K. The results fill a gap between closure-level analysis and full pathwise control, offering both theoretical insight and practical utility for kernel identification and model reduction in high-dimensional stochastic systems (2512.10256).