Beyond the Black Box: Identifiable Interpretation and Control in Generative Models via Causal Minimality
Abstract: Deep generative models, while revolutionizing fields like image and text generation, largely operate as opaque black boxes, hindering human understanding, control, and alignment. While methods like sparse autoencoders (SAEs) show remarkable empirical success, they often lack theoretical guarantees, risking subjective insights. Our primary objective is to establish a principled foundation for interpretable generative models. We demonstrate that the principle of causal minimality -- favoring the simplest causal explanation -- can endow the latent representations of diffusion vision and autoregressive LLMs with clear causal interpretation and robust, component-wise identifiable control. We introduce a novel theoretical framework for hierarchical selection models, where higher-level concepts emerge from the constrained composition of lower-level variables, better capturing the complex dependencies in data generation. Under theoretically derived minimality conditions (manifesting as sparsity or compression constraints), we show that learned representations can be equivalent to the true latent variables of the data-generating process. Empirically, applying these constraints to leading generative models allows us to extract their innate hierarchical concept graphs, offering fresh insights into their internal knowledge organization. Furthermore, these causally grounded concepts serve as levers for fine-grained model steering, paving the way for transparent, reliable systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tries to open up the “black box” of powerful AI models that make images and write text. It asks: can we figure out the actual “concepts” these models use inside (like “cat face,” “wheel,” or “mountain”), and can we control those concepts on purpose? The authors propose a simple but strong rule called “causal minimality” — prefer the simplest explanation that fits the data — to help uncover and control those concepts.
What questions does the paper ask?
- How can we reliably find clear, meaningful “concepts” inside modern generative models (like Stable Diffusion or LLMs)?
- Under what conditions can we prove those concepts are real (not just guesses)?
- How can we use those concepts to steer the model’s behavior—editing or removing ideas in a precise way?
How does the method work? (With simple analogies)
Think of an image or a sentence as being built from a hierarchy of ideas, from big-picture to fine details. For example, a “bicycle” is a high-level concept that depends on a specific arrangement of lower-level parts: wheels, a frame, handlebars. The key is that the higher-level concept doesn’t just “cause” its parts—it “selects” a coherent configuration of them. That’s the selection idea: the model prefers specific combinations that make sense together.
Here’s the core approach:
- Causal minimality: Prefer the simplest structure that explains the data. In practice, this means the connections between concepts should be sparse (not everything connects to everything) or compressed (only the most important states are active).
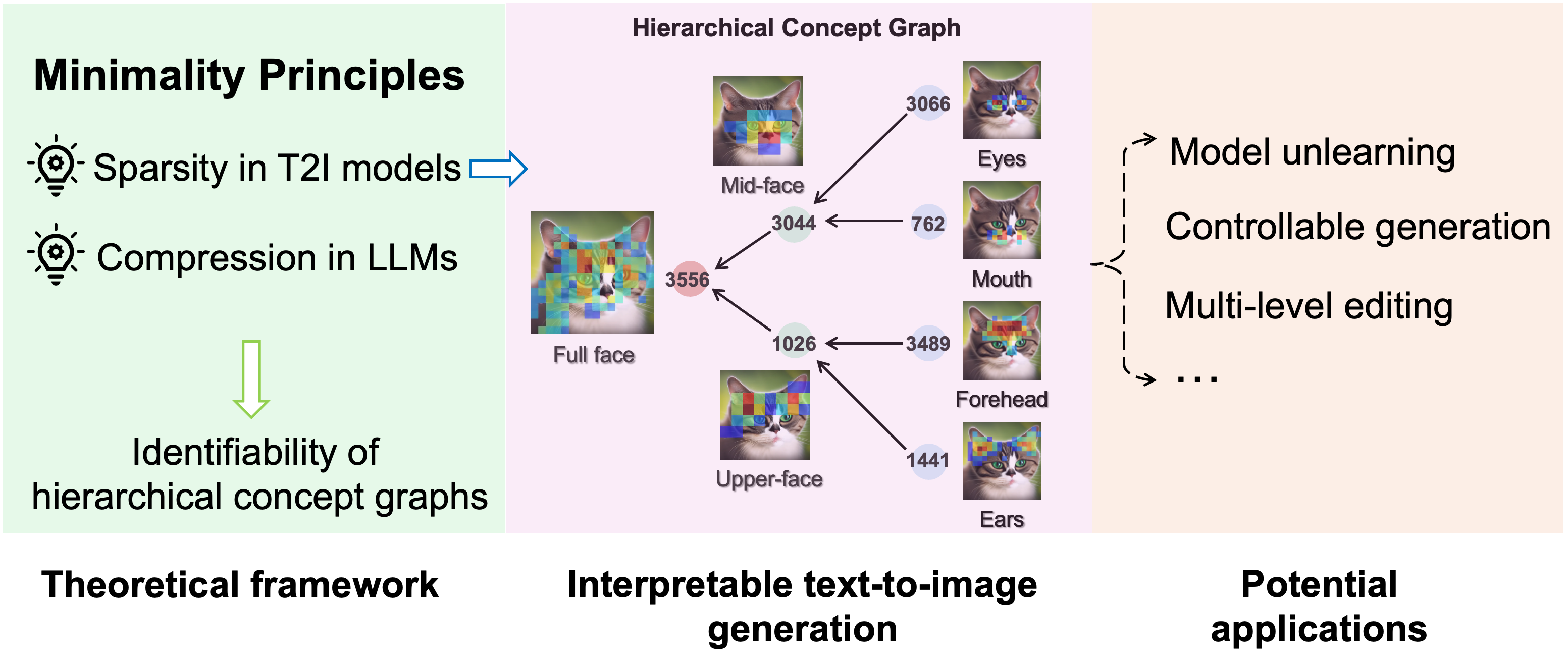
- Hierarchical selection model: Higher-level concepts emerge from the coordinated composition of lower-level ones. Instead of sampling parts independently (which could create nonsense, like wheels floating away from the frame), the higher-level concept “selects” a configuration that fits. This keeps the internal “concept graph” clean and easy to understand.
- Identifiability: The authors prove conditions under which each learned concept inside the model matches a real, single concept in the data one-to-one. In simple terms: each unit inside the model can be matched to a distinct idea, not a muddled mix.
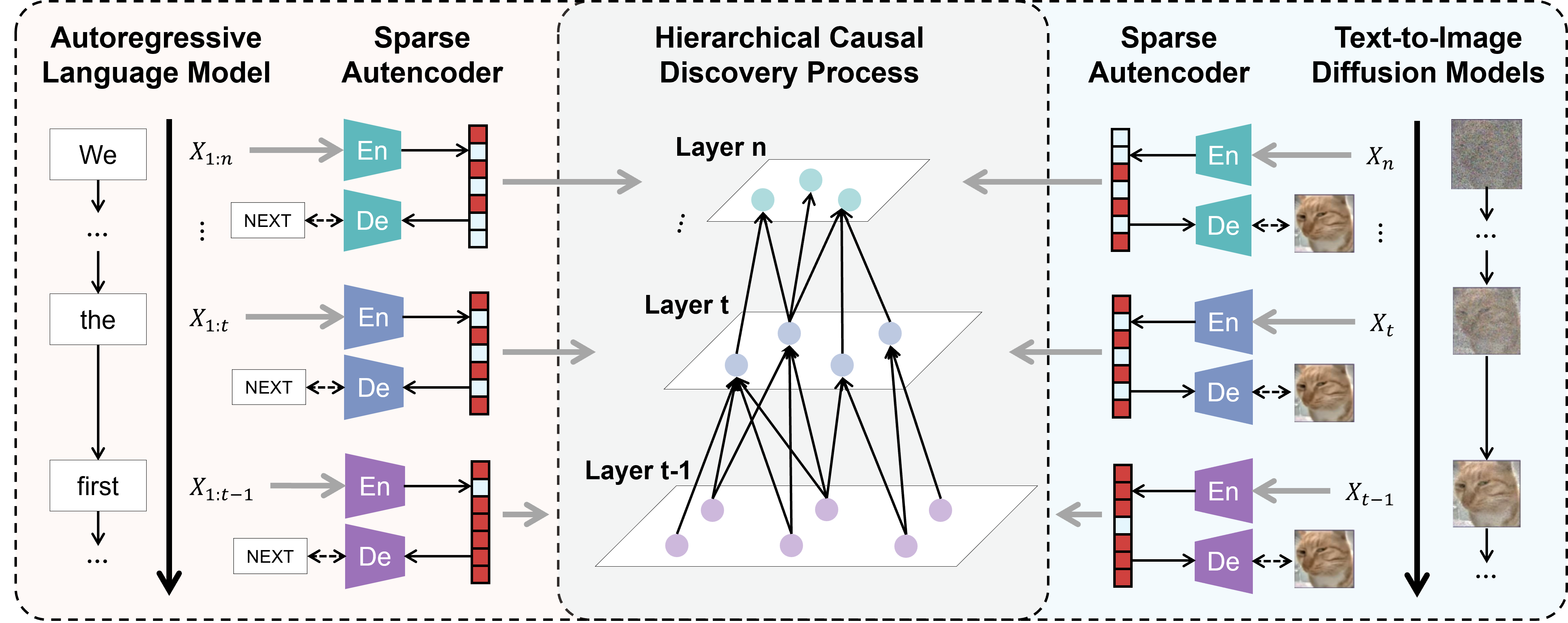
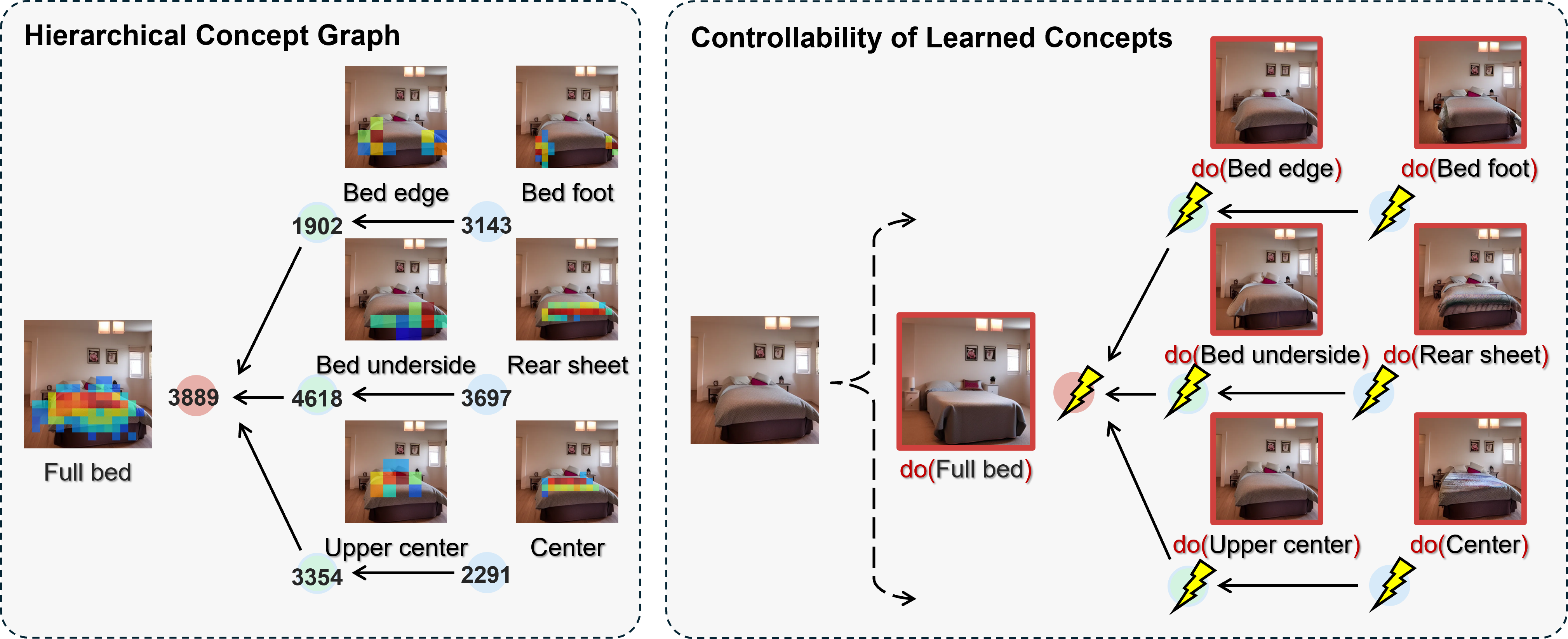
- Practical tools: They use sparse autoencoders (SAEs) to enforce the “simplicity” rule. SAEs learn features that turn on only when needed, which makes them easier to interpret. They also analyze the model at different stages of image generation (early steps = high-level, later steps = fine details) and build a graph of how concepts relate across levels.
To visualize: imagine a map of concepts where top nodes are broad ideas (“cat face”), middle nodes are parts (“eyes,” “nose,” “fur pattern”), and bottom nodes are textures or tiny details. By keeping this map sparse and hierarchical, you can find and tweak specific pieces reliably.
What did they find?
- Theory: Under the minimality conditions (sparsity/compression and some regularity assumptions), the learned internal features can be provably matched to the true underlying concepts, component by component. That means each learned unit corresponds to one real concept in a stable, interpretable way.
- Diffusion models are hierarchical: In image generation, early noisy steps carry broad, high-level concepts (shape, layout), and later cleaner steps add fine details (texture, edges). This matches the idea of a concept hierarchy.
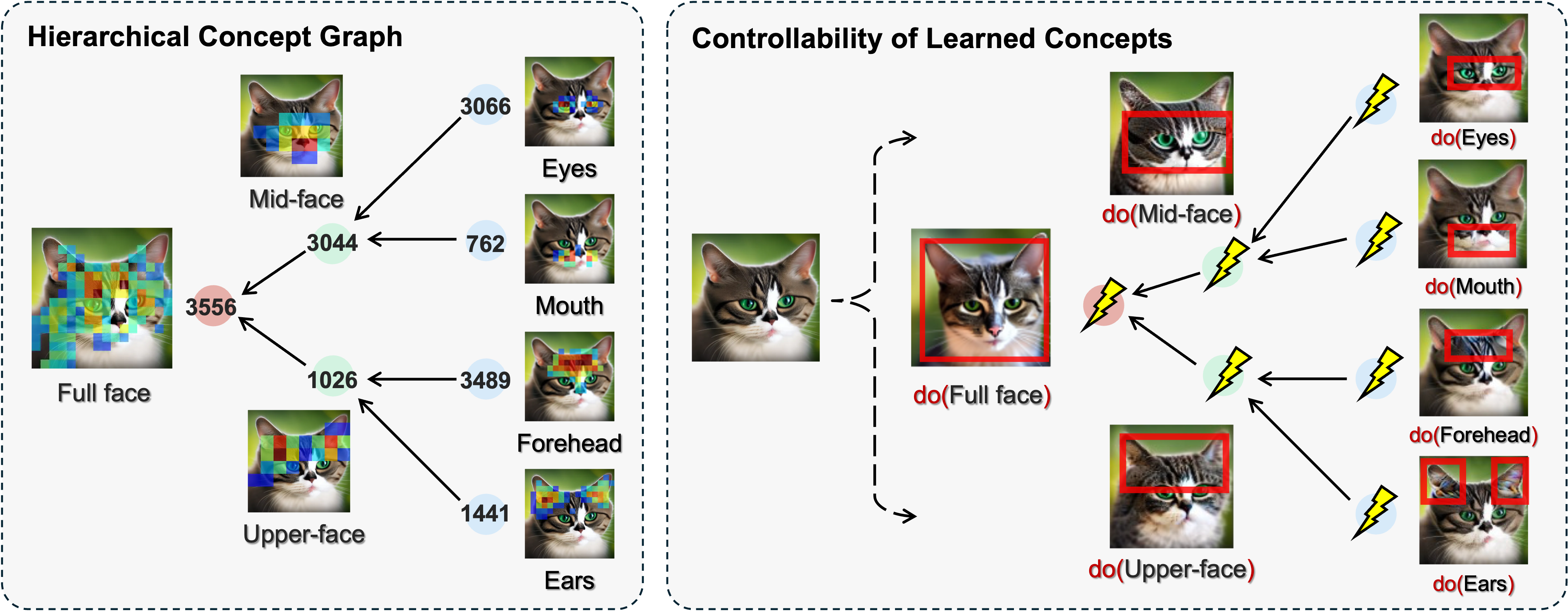
- Extracted concept graphs: Using SAEs and causal analysis, they recovered hierarchical concept graphs inside popular image models (like Stable Diffusion). These graphs showed meaningful nodes such as “full cat face” at high levels and “eye shape” or “mouth detail” at lower levels.
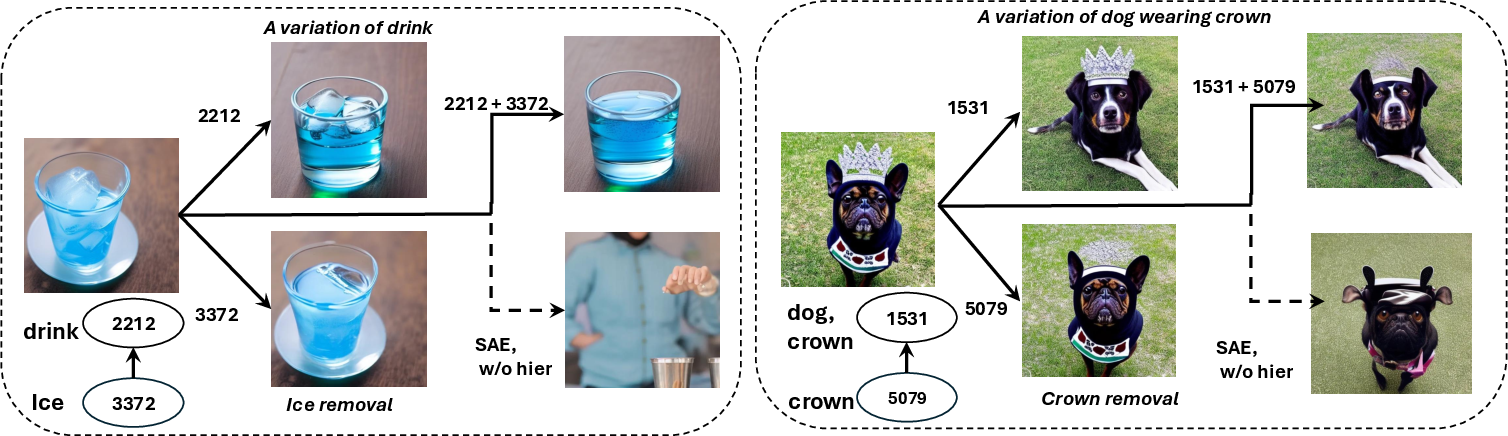
- Precise steering: They could edit the image by turning specific concepts up or down. Changing a high-level node affected the whole face; changing a low-level node only adjusted the eyes. This makes edits more predictable and less likely to cause weird side effects.
- Safer unlearning: They tested removing certain concepts (like unwanted styles or objects) and showed competitive or better performance compared to other methods, while still keeping the model good at normal image generation.
Why is this important?
- Understanding: It gives a principled way to “see” what the model knows, not just guess based on examples.
- Control: You can target exact concepts—replace a rock with a stump, add a pattern to fur, or remove a risky idea—without breaking the rest of the image.
- Trust and safety: With clearer internals and reliable control, it’s easier to align models with human goals and prevent harmful outputs.
What’s the impact and what comes next?
This work provides a strong foundation for transparent, controllable AI:
- Better editing tools: Designers can edit images at the right level—global structure or tiny details—by nudging specific concept nodes.
- Safer systems: Teams can remove or limit certain model behaviors (unlearning) more precisely.
- Generalization to language: While this paper focuses on images, the same ideas (minimality and selection) apply to LLMs. For text, minimality looks like “compressed states” for discrete concepts (like topics or entities), which could enable similar interpretability and control.
In short, by favoring simple, sparse, and hierarchical explanations, the paper shows how to turn generative models from black boxes into systems with understandable, steerable inner concepts. This helps build AI that is more reliable, transparent, and aligned with human intentions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues, uncertainties, and missing elements in the paper that future research could address.
- Formalization of the selection mechanism:
- The paper posits deterministic selection functions but also relies on stochastic conditionals ; a rigorous treatment reconciling deterministic selection with stochastic generative dependencies is missing.
- No constructive algorithm is provided for estimating or validating the selection functions from data/model activations, especially under finite-sample noise.
- Practical enforceability of causal minimality:
- Minimality is instantiated via sparsity (visual) and compression (text), but there is no training-time mechanism for enforcing these constraints within the base generative model (diffusion/transformer) beyond post-hoc SAEs.
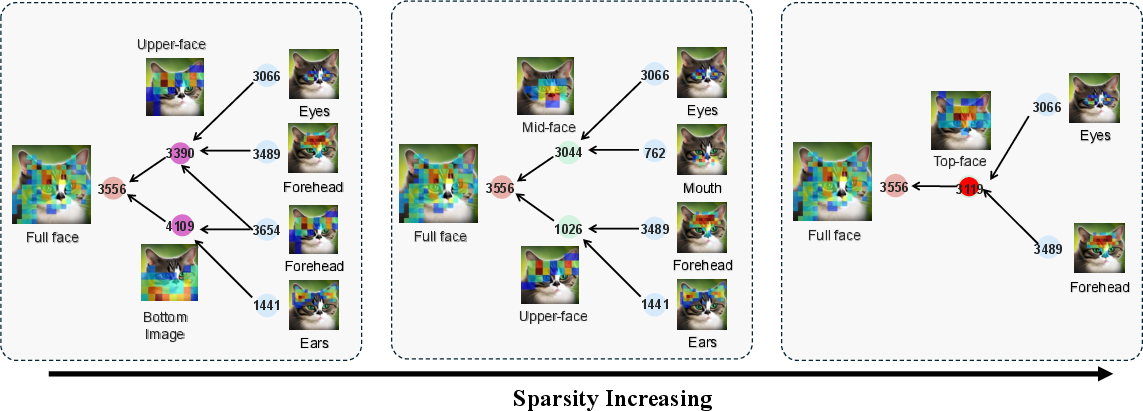
- Criteria for choosing sparsity levels (e.g., K in K-sparse SAEs) are heuristic; a principled procedure to select/validate minimality strength versus fidelity is unresolved.
- Identifiability assumptions and verifiability:
- The diffeomorphism assumption between and is strong and difficult to verify empirically; guidance on diagnostics or relaxations is needed.
- The “Sufficient Variability” (linear independence) condition is nontrivial to assess with model features; practical tests or estimators for this condition are not provided.
- The faithfulness assumption may be violated by deep model representations; the impact of approximate faithfulness on identifiability is not analyzed.
- Ambiguity in mathematical definitions:
- The definition and use of the gradient-based vector for Condition iii are incomplete in the text (equation formatting/macro issues); a clear, consistent formal definition and its role in proofs are needed.
- Several cross-references and conditions (e.g., Conditions/Assumptions with broken labels) are syntactically inconsistent, making it hard to reproduce or verify the theory.
- Scope and limits of component-wise identifiability:
- The theory guarantees identifiability up to component-wise invertible functions, which permits rescalings/monotonic transforms; the implications for semantic stability (consistent human-meaning alignment across runs/SAE trainings) are not explored.
- Effects of approximate sparsity (rather than exact minimality) on identifiability in finite samples are not characterized.
- Dependence on paired text and auxiliary variables:
- Identification relies on paired text acting as auxiliary variables; how to extend to unconditional or weakly supervised settings (e.g., images without prompts) remains open.
- Robustness to prompt variation (paraphrases, multilingual prompts, tokenization changes) and its effect on the identifiability conditions is untested.
- Causal discovery on learned features:
- The use of PC or related algorithms on high-dimensional, learned activations assumes causal sufficiency, acyclicity, and reliable conditional independence tests; violations (latent confounders, measurement error, selection bias) are likely but not addressed.
- Sample complexity, statistical power, and multiple-testing control for independence tests over thousands of features are not analyzed.
- Mapping diffusion timesteps to hierarchical levels:
- The empirical mapping from noise levels/timesteps to abstraction levels is suggestive but lacks formal justification; conditions under which this mapping is model-agnostic (across schedulers, U-Net architectures, noise scales) are unknown.
- How many hierarchical levels are optimal (beyond the chosen three timesteps), and whether finer granularity improves identifiability and control, remains unexplored.
- Generalization across models and modalities:
- Experiments focus on SD 1.4 and Flux.1-Schnell; generality to SDXL, latent diffusion variants, autoregressive image models, or other architectures is not demonstrated.
- Extensions to video/audio generative models (temporal dependencies) and multimodal systems beyond text-to-image are left open.
- LLM counterpart is under-specified:
- The discrete/text theory and experiments are deferred to the appendix with minimal details; how compression minimality is enforced in practice for LMs and whether identifiability holds under transformer dynamics is unclear.
- Concrete algorithms for discovering discrete concept graphs in LMs and validating component-wise control are missing in the main text.
- Real-world concept complexity:
- Scenes with multiple interacting objects and overlapping concepts may break sparsity/minimality; the framework’s behavior in dense graphs and polysemous/conflated concepts (e.g., “knight” vs “horse”) is not fully addressed.
- Handling intra-level dependencies explicitly (within-layer edges) is avoided via selection modeling; when true intra-level causal edges are necessary, how identifiability and minimality adapt is unclear.
- Evaluation limitations:
- Quantitative evaluation of interpretability/control relies on limited metrics (CLIP, LPIPS, DINO) and specific tasks; comprehensive benchmarks, human studies, and ablation across diverse editing/unlearning scenarios are sparse.
- Off-manifold effects of steering (additive decoder perturbations) and long-range unintended consequences are not systematically measured.
- Stability and reproducibility of learned concepts:
- Variability across SAE initializations, seeds, and training runs (concept drift, feature instability) is not quantified; guidance on ensuring reproducible concept graphs is lacking.
- Cross-run and cross-model alignment of concept nodes (canonicalization) is an open problem.
- Safety, alignment, and fairness implications:
- While unlearning results are reported, broader safety impacts (bias mitigation, fairness, harmful content steering) and trade-offs with utility are not deeply analyzed.
- Guarantees that interventions do not induce spurious correlations or degrade non-targeted attributes are absent.
- Choice of independence tests and causal graph structure:
- Independence test selection (kernel vs parametric), thresholds, and robustness to non-Gaussian/nonlinear dependencies are not specified; sensitivity analyses are missing.
- The assumption of acyclic hierarchical graphs may be violated by feedback in generative pipelines; handling cycles or approximate DAGs is an open issue.
- Data and domain shift:
- Reliance on COCO-style prompts and synthetic generations may not reflect natural image distributions; evaluation under OOD prompts, rare concepts, or domain shifts is limited.
- How identifiability and control degrade under domain shift (new styles, lighting, composition) is unknown.
- Concept granularity and type mismatch:
- The framework treats visual concepts as continuous and textual concepts as discrete, but many visual attributes are intrinsically discrete (e.g., presence/absence); handling mixed-type latent variables is not developed.
- Criteria for determining whether a concept should be modeled as continuous vs discrete are not provided.
- Algorithmic scalability:
- Running causal discovery across 5,120-dimensional features at multiple timesteps is computationally heavy; algorithmic improvements, approximations, or subspace selection strategies are not discussed.
- Memory/runtime trade-offs and engineering constraints for large-scale models are not addressed.
- Theoretical robustness to model misspecification:
- If the true data-generating process is not sparse/minimal, or if learned features deviate substantially from true latents, the consequences for identifiability and control are not analyzed.
- Alternative inductive biases (beyond sparsity/compression) that might better capture certain domains are not considered.
- Linking theory to practice:
- Theorem 1 requires a sparsity constraint comparing parent-set sizes (Eq. 7), but the post-hoc SAE training does not guarantee this property holds across levels or components; a gap remains between theoretical conditions and practical enforcement.
- No end-to-end training framework is proposed to jointly learn the generative model and the hierarchical concept graph with provable identifiability.
Practical Applications
Immediate Applications
The following items can be deployed now using the paper’s methods (sparsity- or compression-based causal minimality, hierarchical selection modeling, SAE training per timestep, and causal discovery), given access to model internals and sufficient compute.
- Interpretable audit and diagnostics for generative models (software, AI governance)
- Use sparse autoencoders (SAEs) and causal discovery to extract a hierarchical concept graph from diffusion models (e.g., SD1.4, Flux.1) and LLMs, then audit what internal concepts drive outputs.
- Tools/products: “Concept Graph Explorer” dashboards that visualize nodes by timestep/level and let auditors toggle/trace concepts; model cards augmented with causal concept graphs.
- Dependencies/assumptions: Access to intermediate features and timesteps; faithfulness/minimality hold; sufficient variability in data.
- Fine-grained concept steering for creative tools (media, design, advertising)
- Provide concept sliders that steer high-level (structure/shape), mid-level (parts/regional), and low-level (texture/color) concepts at their corresponding timesteps to reduce artifacts.
- Tools/products: Plugins for SD/Flux that inject steering vectors at specific timesteps; “Concept Palette” UI for compositional edits.
- Dependencies/assumptions: Ability to reinsert steered features into the generation loop; reliably mapped timesteps-to-levels; prompt-to-concept alignment.
- Safer generation via concept blocking and unlearning (platform safety, compliance)
- Remove or attenuate clusters corresponding to protected IP, sensitive or harmful content (e.g., violence, nudity) using concept-level deactivation/removal, with lower collateral damage than global filters.
- Tools/products: Compliance control layer that maintains allowlists/blocklists of concept nodes; pipelines evaluated by unlearning metrics (e.g., I2P, RING-A-BELL).
- Dependencies/assumptions: Concept graphs reflect true latent factors; access to internal features to intercept; policy definitions of “undesirable concepts.”
- Regression testing and drift detection for generative systems (ML Ops)
- Build test harnesses that toggle specific nodes and compare outputs (FID, CLIP, LPIPS, DINO) to detect unintended changes across model updates or fine-tunes.
- Tools/products: “Concept Toggle Test Suite” integrating CI; dashboards showing stability at each hierarchy level.
- Dependencies/assumptions: Stable concept mapping across versions; standardized metrics; consistent SAE sparsity settings.
- Dataset curation and active learning for interpretability (data engineering)
- Identify entangled concepts (e.g., “Knight” and “Horse” always co-occur) and curate counterexamples to satisfy minimality assumptions and improve component-wise identifiability.
- Tools/products: Data curation assistant that flags where co-occurrence breaks are needed and suggests prompts/images to collect.
- Dependencies/assumptions: Label-free concept discovery; availability of synthetic/real data to decorrelate concepts.
- Enterprise explainability and compliance reporting (finance, healthcare, public sector)
- Generate concept-level “cause of output” logs and provenance traces to support audits under the EU AI Act or sectoral regulations.
- Tools/products: Explainability reports linking outputs to specific nodes; API endpoints exposing concept activations.
- Dependencies/assumptions: Regulator acceptance of internal concept graphs as evidence; robust mapping from concepts to policies.
- Accessibility and everyday usability enhancements (daily life, consumer apps)
- Replace opaque prompt engineering with semantic sliders/toggles for face structure, eye shape, texture, and background composition.
- Tools/products: “Prompt Assistant” that proposes causal edits (add/remove nodes) rather than token tweaks.
- Dependencies/assumptions: Intuitive labeling and grouping of learned concepts; consistent behavior across content domains.
- Brand consistency and content localization (marketing)
- Control style, colorways, textures, and product part configurations at mid/low-level nodes to meet brand guidelines across locales.
- Tools/products: Brand style packs encoded as concept subgraphs; automated localization workflows.
- Dependencies/assumptions: Stable concept-to-style mapping; training on brand-relevant data.
- Educational and research tooling (academia, education)
- Interactive labs demonstrating how semantics emerge across diffusion timesteps; reproducible concept discovery benchmarks and datasets.
- Tools/products: Open-source pipelines for level-specific SAEs and PC-based causal discovery; didactic notebooks.
- Dependencies/assumptions: Access to models and datasets; standardized evaluation protocols.
- Synthetic scene control for simulation and perception training (robotics, autonomous systems)
- Compose scenes by controlling high-level object presence and arrangement, mid-level part geometry, and low-level textures for robust perception training.
- Tools/products: Scene assembly APIs driven by concept graphs; safer synthetic data generators.
- Dependencies/assumptions: Valid selection-based composition for target domains; sufficient realism and distribution coverage.
Long-Term Applications
These require further research, scaling, standardization, or broader ecosystem development (e.g., stronger identifiability for LLMs, standardized audits, cross-modal alignment).
- Certified causal interpretability standards and audits (policy, governance)
- Establish accepted protocols for extracting concept graphs, validating minimality/sparsity/compression, and certifying models for transparency and controllability.
- Potential outcomes: Industry standards, third-party audit services, regulatory guidance.
- Dependencies/assumptions: Community consensus; measurement repeatability; legal acceptance.
- Modular generative architectures built from identified subgraphs (software, platform engineering)
- Swap, compose, or “surgically” rewire concept subgraphs to adapt models to domains, repair failure modes, or upgrade capabilities without full retraining.
- Potential products: Concept-module marketplaces; domain-specific packs (e.g., medical textures).
- Dependencies/assumptions: Stable component-wise identifiability under transfer; APIs for safe module insertion.
- Cross-modal hierarchical alignment between text and vision (multimodal AI)
- Build joint concept graphs linking discrete text selectors to continuous visual parts, improving grounded generation, captioning, and VQA alignment.
- Potential products: Multimodal agents with concept-level alignment; cross-modal editing tools.
- Dependencies/assumptions: Text-side compression minimality holds; reliable mapping between discrete and continuous concepts; multimodal datasets.
- Real-time, on-device concept steering (edge AI, creative tools)
- Low-latency steering of concept nodes during generation for interactive editing on consumer devices.
- Potential products: Mobile editors with live concept sliders; AR apps with controllable generative overlays.
- Dependencies/assumptions: Efficient SAE/steering implementations; model quantization; privacy-preserving local inference.
- Automated policy enforcement layers (platform safety)
- Policy-driven interceptors that monitor and constrain concept activations across hierarchy levels in real time, with explainable justifications.
- Potential products: “Policy-as-Concepts” engines; dynamic allow/block rules tied to regulatory changes.
- Dependencies/assumptions: Accurate mapping from policy to concept nodes; minimal performance overhead; robust evasion resistance.
- Domain-specific, regulator-approved generative systems (healthcare, finance)
- Clinically safe medical image augmentation or report generation with concept-level provenance; brand-safe content generators with auditable controls.
- Potential products: FDA/EMA-ready augmentation tools; finance-grade content generators with concept logs.
- Dependencies/assumptions: Rigorous validation; domain datasets; certified development processes.
- Procedural content generation for games and virtual worlds (entertainment)
- Use hierarchical concept graphs to programmatically generate assets with controlled style, parts, and textures, enabling consistent world-building.
- Potential products: PCG engines with concept templates; level editors that steer parts and aesthetics.
- Dependencies/assumptions: Scalable pipelines; integration with existing game engines; artist oversight.
- Personalized value alignment via concept preferences (consumer platforms)
- Learn user-specific “value profiles” mapped to concept nodes, steering outputs toward preferred structures/styles and away from dispreferred ones.
- Potential products: Profile-driven generators; family-safe modes with concept enforcement.
- Dependencies/assumptions: Preference elicitation; privacy-preserving profiling; fairness and bias audits.
- Robust identifiability in large-scale LLMs and multimodal models (research)
- Extend component-wise identifiability beyond subspace-level results in LLMs to practical, production-scale systems.
- Potential outcomes: New training objectives enforcing minimality; integrated SAE-like concept bottlenecks with proofs.
- Dependencies/assumptions: Architectures amenable to selection modeling; availability of auxiliary variables; scalable proofs and training.
- Concept-driven active curation and continual learning (ML lifecycle)
- Closed-loop pipelines that detect newly entangled or drifting concepts, propose disambiguating data collection, and update concept graphs safely over time.
- Potential products: Lifecycle management platforms; drift monitors with concept remediation.
- Dependencies/assumptions: Monitoring coverage; economical data acquisition; safe deployment updates.
Cross-cutting assumptions and dependencies relevant across applications
- Access to internal model features and timesteps, or the ability to instrument models with SAEs and causal discovery.
- Causal faithfulness and minimality conditions (sparsity for vision, compression for text) approximate reality; over-sparsification can harm fidelity.
- Sufficient data variability to break co-occurrence and support component-wise identifiability.
- Compute and engineering resources to train SAEs, run causal discovery, and integrate steering without unacceptable latency.
- Licensing and legal compliance for model modification; regulator acceptance of causal interpretability artifacts as audit evidence.
- Maintenance of concept graphs across model updates to mitigate drift and ensure consistent behavior.
Glossary
- Autoregressive LMs: Sequence models that generate text by predicting the next token conditioned on previous tokens. "autoregressive LMs"
- Causal discovery: Methods for inferring causal structures (graphs) from data. "causal discovery algorithms (e.g., PC~\citep{spirtes2001causation})"
- Causal minimality: The principle that among causal models explaining the data, the true model is the simplest. "causal minimality -- favoring the simplest causal explanation --"
- Collider: A variable in a causal graph with multiple incoming edges; conditioning on it induces dependencies between its parents. "latent variables function as colliders"
- Component-wise identifiability: A strong identifiability notion where each learned latent component corresponds to a single true latent component up to invertible transformation and permutation. "component-wise identifiability for both continuous and discrete hierarchical selection models"
- Confounders: Variables that causally influence two or more others, potentially creating spurious associations. "their role as confounders in the aforementioned prior art"
- Diffusion models: Generative models that iteratively denoise a corrupted signal to produce samples. "text-to-image (T2I) diffusion models"
- Diffeomorphism: A smooth, invertible mapping with a smooth inverse between manifolds. "There exists a diffeomorphism $g_{l}: \left( \lat_{l}, \bm{\epsilon}_{l} \right) \mapsto \obs$"
- Exogenous variables: External, independent noise variables driving stochasticity in structural causal models. "denotes independent exogenous variables"
- Faithfulness condition: The assumption that the causal graph captures exactly the conditional independence relations present in the data distribution. "We assume the standard faithfulness condition"
- Hierarchical selection models: Models where higher-level variables arise as effects of compositions (selections) of lower-level variables. "hierarchical selection models"
- Latent tree models: Probabilistic models with latent variables arranged in a tree, often connecting variables via single undirected paths. "latent tree models, which connect variables via a single undirected path"
- Nonlinear ICA: Independent Component Analysis under nonlinear mixing, used to identify latent factors from observations. "nonlinear ICA literature"
- Selection mechanism: A mapping that determines a higher-level variable as a function of lower-level components, inducing dependencies via selection. "This is captured by a selection mechanism"
- Sparse autoencoders (SAEs): Autoencoders that enforce sparsity in latent codes to yield interpretable features. "sparse autoencoders (SAEs)"
- Sparsity constraint: A restriction that limits the number of active connections or features, encouraging minimal causal structures and identifiability. "along with a sparsity constraint such that"
- U-Net: A convolutional encoder–decoder architecture with skip connections widely used to process features in diffusion models. "U-Net features"
Collections
Sign up for free to add this paper to one or more collections.

