- The paper presents a novel approach leveraging sparse autoencoders for interpretable concept unlearning in diffusion models.
- The method identifies and ablates concept-specific features at cross-attention blocks, preserving overall model performance.
- Experimental results on the UnlearnCanvas benchmark demonstrate state-of-the-art robustness against adversarial attacks.
SAeUron: Interpretable Concept Unlearning in Diffusion Models with Sparse Autoencoders
The paper "SAeUron: Interpretable Concept Unlearning in Diffusion Models with Sparse Autoencoders" (2501.18052) introduces SAeUron, a novel approach for concept unlearning in text-to-image diffusion models using sparse autoencoders (SAEs). Unlike traditional fine-tuning methods, SAeUron leverages the interpretable features learned by SAEs to precisely remove unwanted concepts while preserving the model's overall performance. This approach offers a transparent way to analyze and block concepts prior to unlearning, enhancing interpretability and robustness against adversarial attacks.
Methodological Overview
SAeUron involves training sparse autoencoders on the internal activations of Stable Diffusion models, specifically targeting the cross-attention blocks at various denoising timesteps. The method identifies concept-specific features using a score function that measures the importance of each feature for a given concept. During inference, these identified features are ablated to remove the targeted concept's influence on the generated output (Figure 1). This process leverages the summative nature of SAEs and the sparsity of activated features to ensure minimal impact on the diffusion model's overall performance.
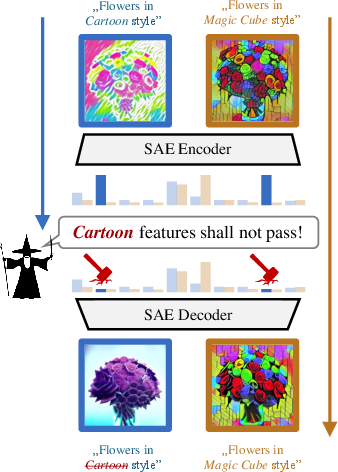
Figure 1: Concept unlearning in SAeUron. We localize and ablate SAE features corresponding to unwanted concept (Cartoon) while preserving overall performance of diffusion model.
The score function is defined as:
score(i,t,c,D)=∑j=1dμ(j,t,Dc)+δμ(i,t,Dc)−∑j=1dμ(j,t,D¬c)+δμ(i,t,D¬c)
where μ(i,t,D) is the average activation of the i-th feature on activations from timestep t, Dc is the dataset containing the target concept, and D¬c is the dataset without the target concept. The ablation is achieved by scaling the selected features with a negative multiplier γc, normalized by the average activation on concept samples.
Sparse Autoencoders for Diffusion Models
The adaptation of sparse autoencoders to Stable Diffusion models involves training them on activations from every denoising step t. These activations are extracted from the cross-attention blocks and form feature maps Ft∈Rh×w×d, where h and w denote the height and width of the feature map, and d is the dimensionality of each feature vector. The SAEs are trained in an unsupervised manner to learn a set of sparse and semantically meaningful features.
The encoder and decoder of the ReLU sparse autoencoder are defined as:
z=ReLU(Wenc(x−bpre)+benc) x^=Wdecz+bpre
where Wenc∈Rn×d and Wdec∈Rd×n are the encoder and decoder weight matrices, and bpre∈Rd and benc∈Rn are learnable bias terms. The paper also explores the use of TopK activation functions and BatchTopK approaches to enhance sparsity and flexibility.
Experimental Validation
The SAeUron method was evaluated using the UnlearnCanvas benchmark, which includes 20 objects and 50 styles. The experiments demonstrated that SAeUron achieves state-of-the-art performance in unlearning without significantly affecting the diffusion model's overall performance. The method's robustness was also tested under adversarial attacks, showing that SAeUron effectively removes targeted concepts rather than merely masking them.
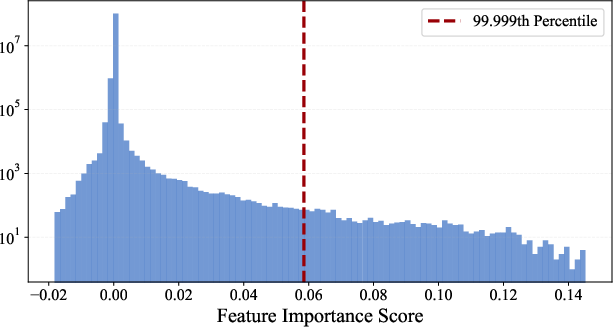
Figure 2: Feature importance scores on validation set. Most of features have feature importance score close to zero signifying that SAE learns only a few concept-specific features. During the evaluation we find a threshold based on percentile of scores and block features with scores greater than it.
Implications and Future Directions
The SAeUron method provides a transparent and interpretable approach to concept unlearning in diffusion models. The use of sparse autoencoders allows for the identification and manipulation of specific features related to unwanted concepts. This approach shows potential for further research in mechanistic interpretability and the development of more robust and controllable generative models. Future work may explore extending SAeUron to other types of generative models and investigating its applicability in various real-world scenarios where concept unlearning is required. Furthermore, the ability to unlearn multiple concepts simultaneously and the demonstrated robustness against adversarial attacks highlight the practical advantages of SAeUron over traditional fine-tuning methods.
Conclusion
SAeUron introduces a novel and effective method for interpretable concept unlearning in diffusion models. By leveraging sparse autoencoders, the approach achieves state-of-the-art performance, robustness, and transparency. This work contributes to the field of machine unlearning and offers a promising direction for future research in controllable and interpretable AI.

