KAGE-Bench: Fast Known-Axis Visual Generalization Evaluation for Reinforcement Learning
Abstract: Pixel-based reinforcement learning agents often fail under purely visual distribution shift even when latent dynamics and rewards are unchanged, but existing benchmarks entangle multiple sources of shift and hinder systematic analysis. We introduce KAGE-Env, a JAX-native 2D platformer that factorizes the observation process into independently controllable visual axes while keeping the underlying control problem fixed. By construction, varying a visual axis affects performance only through the induced state-conditional action distribution of a pixel policy, providing a clean abstraction for visual generalization. Building on this environment, we define KAGE-Bench, a benchmark of six known-axis suites comprising 34 train-evaluation configuration pairs that isolate individual visual shifts. Using a standard PPO-CNN baseline, we observe strong axis-dependent failures, with background and photometric shifts often collapsing success, while agent-appearance shifts are comparatively benign. Several shifts preserve forward motion while breaking task completion, showing that return alone can obscure generalization failures. Finally, the fully vectorized JAX implementation enables up to 33M environment steps per second on a single GPU, enabling fast and reproducible sweeps over visual factors. Code: https://avanturist322.github.io/KAGEBench/.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces KAGE-Bench, a way to test whether AI “agents” that learn from images (like video game screens) can handle changes in how things look without breaking. The authors also built KAGE-Env, a simple 2D platformer game in JAX that lets them change one visual thing at a time—like the background, colors, lighting, or the character’s appearance—while keeping the game’s rules and physics exactly the same. This makes it easy to see which visual changes cause the agent to fail and why.
Key Questions
The paper asks three main questions in simple terms:
- If we only change how the game looks, not how it works, do image-based agents still play well?
- Which kinds of visual changes (backgrounds, lighting, colors, etc.) hurt performance the most?
- How can we test these visual changes quickly and fairly, so we know exactly what caused an agent to fail?
How They Did It
The authors built a controlled test environment and benchmark:
The Environment (KAGE-Env)
Think of a side-scrolling platform game where:
- The rules never change: jumping, moving, rewards, and physics stay the same.
- Only the visuals change: things like background images, character skins, color filters, and lighting can be swapped in and out.
- The agent only sees pixels (the image on the screen) and decides what to do from that, just like a person playing by looking at the screen.
They made sure:
- Each “visual axis” is one category of appearance you can change independently. This helps isolate what’s causing trouble.
- Everything runs super fast on a single GPU by using JAX and vectorizing the simulation. This lets them run up to 65,536 games in parallel and reach up to 33 million steps per second. That’s fast enough to try lots of settings and be confident about results.
The six visual axes they focus on are:
- Agent appearance (what the player character looks like or how it animates)
- Background (images or colors behind the level)
- Distractors (moving or static non-player elements that don’t affect the rules)
- Effects (dynamic lighting and similar visual overlays)
- Filters (photographic changes like brightness, contrast, hue, blur)
- Layout (visual arrangement viewed as a rendering choice while keeping the mechanics fixed in their benchmark splits)
The Benchmark (KAGE-Bench)
- They created 34 “train–test” pairs across the six axes. In each pair, they train the agent in one visual setup and test it in another that differs in only one axis.
- They used a standard image-based RL method called PPO with a CNN (often used for learning from pixels).
- They measured not just score (“return”), but also:
- Distance traveled
- Progress toward the goal
- Whether the agent actually completes the task (success rate)
These extra metrics matter because sometimes an agent keeps moving forward but still fails to finish, and total score can hide that kind of failure.
Main Findings
The results show clear, axis-specific behaviors:
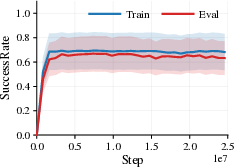
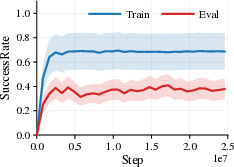
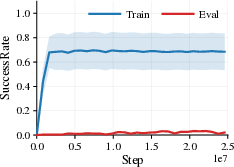
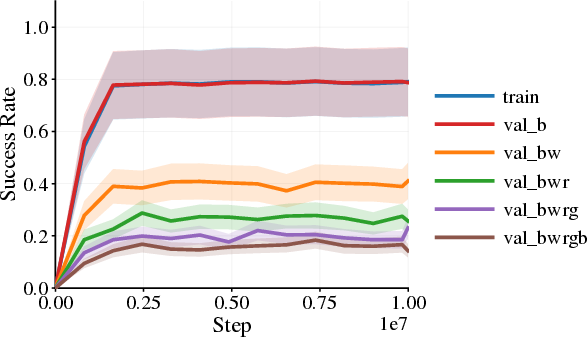
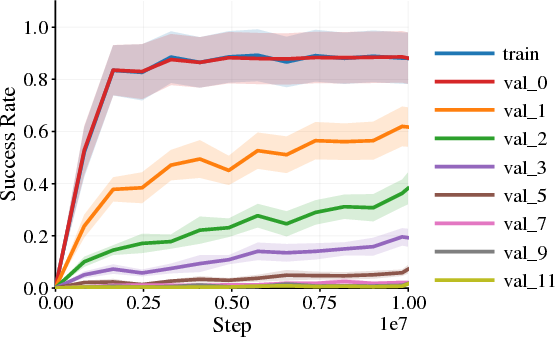
- Background and photometric changes (like brightness, contrast, hue, or strong lighting effects) often cause major failures. Agents trained on one background or color style can struggle badly when those visuals change.
- Changing the agent’s appearance (like the character’s skin or simple shape) tends to be much less harmful. The agent can usually handle these differences.
- Distractors can cause problems, especially when they look similar to the agent or clutter the screen. But not all distractors are equally harmful.
- A surprising pattern appears: sometimes the agent still moves forward (distance looks good) but fails to complete the task (success rate drops). This proves that “return” alone can make things look fine even when important parts of the behavior break.
- Because KAGE-Env is extremely fast, the authors can test many different settings and confirm that these patterns hold across seeds and configurations, making the results more reliable.
Why It Matters
This work helps the field in several ways:
- Clear diagnosis: By changing one visual axis at a time and keeping the game’s rules the same, we can pinpoint what exactly breaks an agent’s performance. That’s much cleaner than mixing many changes at once.
- Better training methods: Knowing which visual changes are the most harmful guides researchers toward smarter data augmentation, better representations, or architectures that focus on the important parts of the scene.
- Real-world relevance: In robotics or navigation, visuals often change (lighting, textures, backgrounds) even when the task doesn’t. If agents fail under these conditions, they’re not ready for deployment. KAGE-Bench helps expose and fix that fragility.
- Fast experimentation: The JAX-based setup makes it feasible to run large, careful studies quickly, speeding up progress.
In short, the paper shows that visual changes alone can seriously break image-based agents, identifies which kinds of changes are most dangerous, and provides a fast, fair way to measure and improve visual generalization.
Knowledge Gaps
Below is a single, consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each item is framed to be concrete and actionable for future investigation.
- Theory and scope limited to reactive, single-frame pixel policies: extend the induced state-policy reduction and evaluation protocol to recurrent/temporal policies (e.g., RNNs, frame stacking) and belief-state formulations.
- Domain coverage restricted to a 2D platformer: test whether findings and axis sensitivities transfer to 3D environments, continuous-control tasks, manipulation, navigation, and robotics.
- Axis isolation vs. interaction effects: systematically study multi-axis and compounding shifts to quantify non-linear interactions (e.g., background+lighting+filters jointly), not just single-axis interventions.
- Training distribution breadth: evaluate robust training strategies that randomize along known axes (domain randomization, curriculum over axes) and measure how train-distribution diversity impacts out-of-distribution generalization.
- Baseline diversity: benchmark a wider set of architectures and methods (e.g., ResNet/ViT encoders, SAC/IMPALA/DQN, RAD/DrQ/CURL/AugMix/invariance regularizers) to test whether axis-dependent failures persist across approaches.
- Aggregation by “max-over-training” may mask instability: compare evaluation protocols (final checkpoint, area-under-curve, fixed-iteration checkpoints, early stopping) and quantify sensitivity to checkpoint selection.
- Reward shaping robustness: assess how changes in α1–α4 (first-time progress bonus, jump penalty, time cost, idle penalty) affect return vs. trajectory metrics and whether gaps are artifacts of shaping choices.
- Layout suite validity: verify—via automated invariance checks and unit tests—that layout changes do not alter latent dynamics P or rewards r; refine the suite if any latent-control confounds exist.
- Realism and external validity of visual shifts: calibrate parameter ranges (e.g., lighting falloff, brightness/contrast/saturation) against real sensor/camera distributions; relate KAGE axes to measurable image statistics (e.g., luminance histograms, color-space distances, SNR).
- Asset diversity and ecological validity: expand backgrounds/sprites to include more naturalistic textures, occlusions, and viewpoint changes; quantify asset bias and its effect on axis-level conclusions.
- Temporal coherence of effects: characterize time-varying rendering (e.g., dynamic lights, flicker) and its interaction with memoryless vs. memory-based policies; include temporal stability metrics.
- Resolution dependence: measure generalization gaps across image resolutions and down/up-sampling regimes; quantify trade-offs between throughput and robustness.
- Determinism and reproducibility on accelerators: document and test for cross-hardware determinism (PRNG splitting, XLA/JAX semantics); provide reproducibility harnesses and seed-control guidelines.
- Observability analysis: quantify how each axis shift affects information content (e.g., occlusions, blur-induced SNR loss) and map observability changes to performance degradation.
- End-to-end profiling: report training-time bottlenecks (optimizer, data transfer, batching) alongside environment throughput; identify the dominant compute barriers in large-scale sweeps.
- Multi-task generalization: introduce additional tasks/goals with fixed latent dynamics to test if visual robustness findings hold beyond a single side-scrolling objective.
- Cross-benchmark validation: run comparable suites in Procgen, DCS, DMC-VB, and Distracting MetaWorld to establish external validity and correlate axis-wise gaps across benchmarks.
- Failure-mode interpretability: use saliency/occlusion studies to identify which visual cues (e.g., background textures vs. agent contours) are exploited or ignored by policies on each axis.
- Graded shift curves: replace discrete train–eval pairs with parametric sweeps to produce performance–shift curves; map axis parameter values to quantitative distances and identify breakdown thresholds.
- Statistical power: increase seed counts and report variance decomposition (between seeds, between configs, between suites); conduct significance testing for axis-level differences.
- Agent embodiment shifts beyond appearance: test purely visual changes in agent size/outline and systematically separate them from changes that alter dynamics (kinematics, collision boxes).
- Distractor semantics: parameterize distractor similarity (shape, color, motion patterns, “same-as-agent” appearances) and relate similarity metrics to failure rates.
- Exploration confounds: disentangle axis-induced failures from exploration inefficiency by evaluating alternative exploration strategies and intrinsic reward schemes on the same suites.
- Integration breadth: provide PyTorch and off-policy training examples; assess how environment vectorization interacts with on-policy rollouts and replay-based algorithms at scale.
- Robustness baselines: quantify axis-specific gains from common visual augmentation pipelines (RAD, DrQ, RandAugment/AugMix) and representation learning (contrastive/self-supervised) on KAGE-Bench.
- Domain adaptation/finetuning: study sample complexity and effectiveness of finetuning on the eval axis (few-shot adaptation, offline finetuning) and whether adaptation transfers across axes.
- Trajectory-metric coverage: add metrics for collisions, safety violations, jump usage, and stall events to distinguish nuanced failure modes beyond distance/progress/success.
- Predictive modeling of gaps: develop models that predict eval performance from train metrics and axis parameters; explore meta-learning to identify and preempt vulnerable axes.
- Suite selection bias: replace manual curation of 34 pairs with automated procedures (e.g., pilot sweep + optimization for diversity and difficulty) to reduce selection bias and improve coverage.
- Camera dynamics and parallax: analyze whether parallax/background motion confounds perceived agent motion; add controls to isolate camera-induced artifacts from true visual shift.
- Renderer generality: compare JAX-native rendering with alternative pipelines to ensure axis-wise findings are not renderer-specific; validate portability across graphics backends.
- Synthetic-to-real transfer: evaluate policies trained in KAGE-Env against real video backgrounds or camera feeds to assess how known-axis robustness translates to real-world visual variation.
Glossary
- accelerator-native RL systems: Reinforcement learning simulators that run environment stepping as compiled, parallel code on accelerators like GPUs/TPUs. "Recent work addresses this bottleneck through accelerator-native RL systems, where environment stepping is implemented as compiled, vectorized computation on GPUs or TPUs."
- bitmask actions: An action encoding where each bit of an integer corresponds to a discrete action component that can be combined. "# action per env in 0, 7"
- data augmentation: Techniques that transform input observations during training to improve robustness and generalization. "Accordingly, many approaches have been proposed to improve robustness, including data augmentation, auxiliary representation learning objectives, and regularization methods"
- distribution shift: A change between training and evaluation data distributions that can degrade learned policy performance. "Pixel-based reinforcement learning agents often fail under purely visual distribution shift"
- equality in law: A probabilistic notion indicating two stochastic processes have the same distribution. "(Equality in law of state--action processes.)"
- falloff (lighting): The rate at which a light’s intensity decreases with distance in a renderer. "dynamic point lights with configurable count, intensity, radius, falloff, and color."
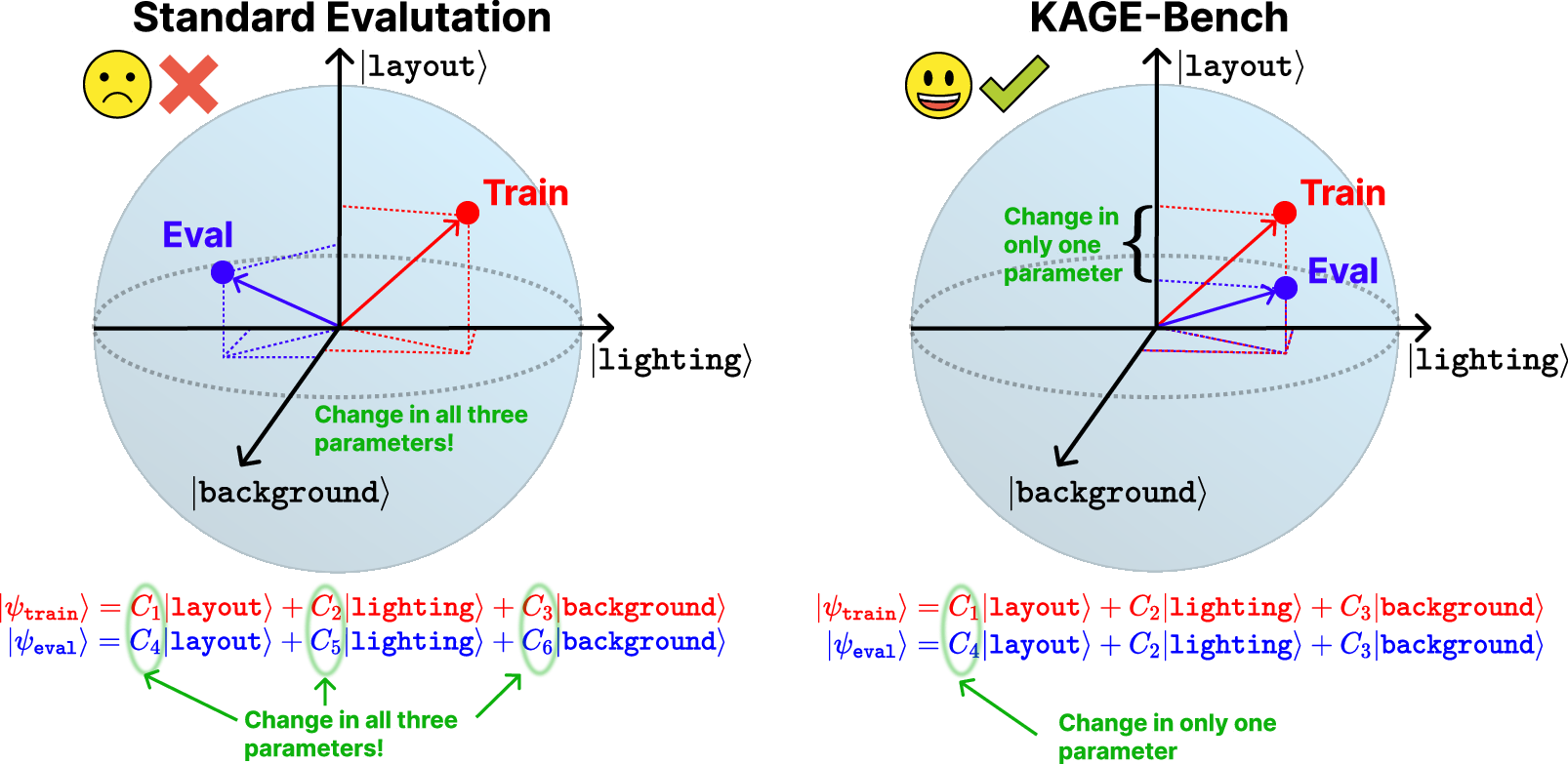
- generalization gap: The performance difference between training and evaluation settings; here, under visual shifts with fixed dynamics. "We define the visual generalization gap as the performance difference between the training and evaluation configurations of a pair."
- induced state policy: The state-conditional policy obtained by composing the observation kernel with a pixel policy and marginalizing over observations. "The induced state policy π_ξ is defined by"
- JAX-native: Implemented directly in JAX to enable compilation and efficient parallelism on accelerators. "We introduce KAGE-Env, a JAX-native 2D platformer"
- jit compilation: Just-in-time compilation that turns Python/JAX functions into optimized executable code for accelerators. "end-to-end jit compilation and vectorized execution via vmap and lax.scan"
- known-axis visual generalization: Evaluation where only a single, explicitly chosen visual factor (axis) is changed between train and eval, isolating its effect. "KAGE-Bench focuses on known-axis visual generalization."
- lax.scan: A JAX control-flow primitive that compiles loop-like computations efficiently over sequences. "end-to-end jit compilation and vectorized execution via vmap and lax.scan"
- latent dynamics: The underlying state-transition mechanics of the environment that are not directly observed via pixels. "latent dynamics and rewards are held fixed"
- latent MDP: The Markov decision process defined over unobserved (latent) states, independent of rendering. "as executing π_ξ in the latent MDP M."
- marginalizing (over observations): Integrating out observations to derive a distribution over actions conditioned on latent state. "by marginalizing the intermediate observation:"
- observation kernel: A conditional distribution mapping latent states to rendered observations. " is the observation (rendering) kernel parameterized by ."
- out-of-distribution performance: Performance when evaluating on data or configurations different from those seen during training. "we report in-distribution and out-of-distribution performance"
- partially observable Markov decision process (POMDP): A framework where the agent receives observations that provide incomplete information about the true state. "We consider episodic control with horizon T in a partially observable Markov decision process (POMDP)."
- parallax factor: A rendering parameter controlling differential background motion relative to the foreground to create depth. "parallax_factor: 0.5"
- photometric filters: Image-level transformations (e.g., brightness, hue, contrast) applied to observations that alter visual appearance without changing dynamics. "photometric filters"
- pixel-based policy: A policy that maps raw image observations directly to action distributions without explicit state estimation. "We focus on reactive pixel-based policies that map observations directly to action distributions: π(a \mid o)."
- PPO-CNN: A convolutional policy trained with the Proximal Policy Optimization algorithm. "using a standard PPO-CNN baseline"
- procedural generation: Programmatic creation of varied environments or assets, often leading to diverse appearances and layouts. "Procgen relies on procedural generation, so train--test gaps typically reflect entangled shifts in appearance and scene composition"
- push-scrolling camera: A camera mechanism in side-scrollers that advances as the agent moves, pushing the viewport along. "a push-scrolling camera."
- renderer: The component that generates pixel observations from latent states according to configurable visual parameters. "The renderer further exposes photometric and spatial transformations"
- reward shaping: Modifying the reward signal with additional terms to guide learning, which can confound return as a robustness metric. "including reward shaping, exploration inefficiency, and penalty terms"
- return-based generalization gap: The difference in discounted returns between train and eval configurations under visual shifts. "and define the return-based generalization gap"
- spurious visual correlations: Incidental visual features exploited by a model that do not truly relate to the underlying task and hurt transfer. "exploit spurious visual correlations"
- state-conditional action distribution: The distribution over actions conditioned on the latent state induced by composing the observation kernel with the policy. "state-conditional action distribution by marginalizing the intermediate observation:"
- time-limit truncation: Ending an episode when a maximum time horizon is reached, regardless of task completion. "Episodes terminate only by time-limit truncation at T=episode_length."
- transition kernel: The conditional distribution over next states given the current state and action. " is the transition kernel"
- vectorized execution: Running many environment instances or computations in parallel as a single batched operation for efficiency. "end-to-end jit compilation and vectorized execution via vmap and lax.scan"
- visual generalization: Robustness of policies to changes in the observation process while keeping latent dynamics and rewards fixed. "Visual generalization concerns the behavior of policies under such changes in the observation process"
- visual POMDP: A POMDP where the observation function is a visual renderer parameterized by visual configuration. "However, in a visual POMDP , the observation kernel ..."
- vignetting: A photometric effect that darkens image corners relative to the center. "vignetting) and lighting/overlay effects"
- vmap: A JAX transformation that vectorizes a function over leading batch dimensions, enabling parallel evaluation. "end-to-end jit compilation and vectorized execution via vmap and lax.scan"
Practical Applications
Immediate Applications
The following applications are directly enabled by the paper’s environment, benchmark design, throughput, and empirical findings. They can be adopted now with the released code, JAX tooling, and a GPU (or Colab/T4 for small-scale runs).
- Visual robustness audit for pixel-based RL policies in robotics and automation (sector: robotics, manufacturing, logistics)
- Use case: Pre-deployment “known-axis” stress testing of policies controlling mobile robots, pick-and-place arms, or warehouse AGVs under camera-only changes (background, lighting, filters, distractors) while keeping dynamics and rewards fixed.
- Workflow: Configure KAGE-Env via YAML to match camera characteristics; run axis-specific train–eval splits from KAGE-Bench; report gaps across distance/progress/success/return; gate release on robustness scorecard thresholds.
- Tools/products: KAGE-Env + KAGE-Bench; “Visual Generalization Scorecard” that highlights large axis-dependent gaps (e.g., backgrounds and photometric filters) and benign axes (e.g., agent appearance).
- Assumptions/dependencies: Policies are reactive and pixel-based; latent dynamics remain unchanged between train and eval; mapping from real camera pipeline to benchmark axes is approximate; requires JAX setup and GPU for high throughput.
- Axis-wise augmentation and preprocessing selection (sector: software/ML engineering for RL)
- Use case: Empirically choose data augmentations and preprocessing that specifically mitigate the worst axes (e.g., background textures and photometric filters) observed to collapse success.
- Workflow: Run fast sweeps (millions of steps/sec) to compare augmentation recipes per axis; prefer augmentations that reduce success gap rather than only improve return; codify axis-wise ablations in CI.
- Tools/products: CleanRL PPO-CNN baselines; KAGE-Env vectorized JAX harness; “Axis-wise Augmentation Tuner” that outputs recommended pipelines per target deployment.
- Assumptions/dependencies: Benchmark transferability to target domain; augmentation benefits may be axis-specific; throughput relies on accelerator availability.
- Continuous Integration (CI) gate for visual generalization (sector: software/DevOps for RL)
- Use case: Prevent regressions by automatically running KAGE-Bench suites on policy PRs; fail if generalization gaps exceed thresholds (especially for background/lighting axes).
- Workflow: Integrate YAML-defined suites; run multi-seed batched evals; publish per-axis metrics (distance, progress, success) in CI reports; flag spurious improvements where return rises but success collapses.
- Tools/products: “Known-Axis CI plugin” for RL repos; GPU-backed runners; artifact dashboards.
- Assumptions/dependencies: Standardized metric thresholds; access to accelerators; policy training seeds controlled for reproducibility.
- Curriculum design and teaching labs in RL (sector: education, academia)
- Use case: Course modules on visual generalization that demonstrate axis-dependent failures and the importance of trajectory-level metrics over return alone.
- Workflow: Students edit YAML to vary one axis (e.g., brightness, distractors); run PPO; analyze progress vs. success curves; write reports on induced state-conditional behavior.
- Tools/products: Colab notebooks (T4 GPU), KAGE-Env assets, pre-made assignments; “KAGE Inspector” visualizer for axis variation.
- Assumptions/dependencies: 2D platformer abstraction; limited realism for real robotics; requires minimal JAX familiarity.
- Benchmarking and paper replication for representation learning and augmentation methods (sector: academia/research)
- Use case: Publish axis-isolated robustness claims for new architectures, self-supervised objectives, or augmentation policies; attribute gains to specific visual factors rather than entangled changes.
- Workflow: Use KAGE-Bench’s six suites (agent appearance, background, distractors, effects, filters, layout); report per-axis gaps and trajectory metrics; scale ablations with 33M steps/sec throughput.
- Tools/products: Standardized experiment manifests; per-axis leaderboards; reproducible JAX code.
- Assumptions/dependencies: Comparability across methods; consistent PPO-CNN baselines or replacement baselines; fixed latent dynamics.
- Game AI QA against spurious visual correlations (sector: gaming/software)
- Use case: Detect agents that overfit to skins, backgrounds, or post-processing effects; prevent production failures when art assets change.
- Workflow: Adapt assets and filter suites; run evaluation pairs varying only art axes; score risk before asset updates; add axis-wise gates to asset pipeline.
- Tools/products: “Art-Change Robustness Check” workflow; asset change pre-flight using known-axis splits.
- Assumptions/dependencies: Mapping of in-game rendering pipeline to benchmark axes; action/dynamics equivalence holds for tests.
- Interim reporting guidelines for safer RL deployments (sector: policy, governance, safety)
- Use case: Encourage teams and reviewers to report axis-wise generalization gaps and trajectory-level metrics (progress, success), not only return, to avoid obscuring failures.
- Workflow: Include a “Known-Axis Evaluation” section in internal audits and publications; prioritize high-risk axes (background, filters) for remediation.
- Tools/products: Template for safety review; standard scorecard format.
- Assumptions/dependencies: Voluntary adoption; sector-specific norms; benchmark may need domain-tailored axes.
Long-Term Applications
These applications need further research, adaptation to domain-specific renderers/simulators, scaling beyond 2D, or industry standards development.
- Certified visual robustness for safety-critical robots (sector: healthcare, industrial robotics)
- Use case: Regulatory or third-party certification requiring axis-isolated robustness tests for pixel-RL policies (e.g., surgical robots, inspection drones) with defined pass/fail thresholds.
- Workflow: Extend KAGE principles to photorealistic domain simulators; define axis taxonomies tied to surgical lighting, instrument specularities, smoke, blood color shifts; test policies under standardized suites.
- Tools/products: “Known-Axis Certification Suite,” compliance audits, standardized reporting.
- Assumptions/dependencies: High-fidelity simulators with controllable visual axes; accepted standards; mapping from axes to clinical risk; multi-stakeholder buy-in.
- KAGE-3D: photorealistic, accelerator-native known-axis environments (sector: autonomous driving, drones, AR/VR)
- Use case: Axis-isolated stress tests in 3D for viewpoint, motion blur, dynamic lighting, weather, texture domains, while keeping latent dynamics/rewards fixed.
- Workflow: Build GPU-native 3D renderers with factorized observation kernels; run large-batch sweeps to diagnose failures per axis; feed results into training and sensor design.
- Tools/products: JAX- or CUDA-native 3D environments; dataset generators with axis labels; visualization dashboards.
- Assumptions/dependencies: Significant engineering; realistic assets; validated equivalence of dynamics across visual configs; hardware scaling.
- Generalization-aware training objectives and induced-policy regularizers (sector: ML research, software)
- Use case: Train policies to minimize induced state-policy divergence across axes (via invariance losses or adversarial renderers) so the same latent state yields consistent actions under visual shifts.
- Workflow: Derive losses from induced-policy definitions; optimize with multi-axis mini-batches; monitor per-axis gaps and trajectory metrics during training.
- Tools/products: “Induced-Policy Consistency Loss,” axis-conditioned training curricula, adversarial renderer modules.
- Assumptions/dependencies: Access to axis-labeled renderers; stability of new objectives; careful tuning to avoid over-regularization.
- Sim2Real pipeline design guided by axis-wise failures (sector: robotics, energy, infrastructure)
- Use case: Use benchmark results to prioritize domain randomization, sensor placement, lighting control, and background management for field robots (inspection, maintenance).
- Workflow: Identify worst axes (e.g., background clutter and photometric filters); engineer camera housings, HDR pipelines, or environmental controls; align sim axes with site conditions.
- Tools/products: “Axis-to-Engineering Checklist” mapping failure axes to physical mitigations; sensor calibration protocols.
- Assumptions/dependencies: Feasibility of environmental control; cost-benefit trade-offs; domain alignment.
- SaaS “Visual Generalization Auditor” for enterprise RL (sector: software platforms, cloud)
- Use case: Hosted service that runs known-axis evaluations, produces standardized scorecards, and recommends augmentation/preprocessing and sensor changes.
- Workflow: Upload policies and render configs; run multi-seed batched suites; analyze gaps and recommend remediations; integrate with CI/CD.
- Tools/products: Managed GPU clusters; web dashboards; API integration with RL frameworks.
- Assumptions/dependencies: Customer data security; domain-specific axis libraries; operational cost of GPU workloads.
- Standards and procurement guidelines for pixel-RL (sector: policy, public procurement, safety)
- Use case: Require “known-axis visual generalization evaluation” in tenders and safety cases for RL-powered systems; specify minimum performance on trajectory-level metrics across defined axes.
- Workflow: Develop sector-specific axis taxonomies; publish test suites; set thresholds and reporting formats; audit compliance.
- Tools/products: Policy documents; reference testbeds; certification tooling.
- Assumptions/dependencies: Industry consensus; regulator involvement; maintenance of testbeds.
- Renderer factorization layer for production systems (sector: robotics/embedded systems)
- Use case: Embed axis-tagged rendering stages in real camera pipelines (e.g., controlled post-processing modules) to enable live axis-wise testing and monitoring.
- Workflow: Instrument camera software to toggle lighting/filters/background overlays without changing control dynamics; run periodic checks; log induced-policy deviations.
- Tools/products: “Axis Controller” middleware; monitoring agents; alerting based on trajectory metrics.
- Assumptions/dependencies: Access to camera pipeline; ability to perturb visuals safely; on-device compute constraints.
- Multi-camera and viewpoint robustness calibration (sector: drones, autonomous vehicles)
- Use case: Systematically evaluate policies under axis changes induced by viewpoint and sensor differences; calibrate camera networks to reduce induced-policy variance.
- Workflow: Extend suites to viewpoint axes; design camera placements minimizing worst-axis gaps; align preprocessing across cameras.
- Tools/products: Camera network design tools; axis-wise calibration procedures.
- Assumptions/dependencies: 3D renderer support; consistent dynamics across cameras; hardware constraints.
Across these applications, the paper’s core insights and tools drive practical workflows:
- Factorizing the observation process into independently controllable axes enables precise attribution of failures to specific visual causes.
- High-throughput, GPU-native simulation unlocks large-scale, multi-seed sweeps and ablations that were previously prohibitive.
- Reporting trajectory-level metrics (distance, progress, success) alongside return prevents masking of catastrophic failures by reward shaping.
- Empirical findings (e.g., background and photometric shifts often collapse success; agent-appearance shifts are comparatively benign) provide immediate guidance on where to focus augmentation, sensor engineering, and QA efforts.
Collections
Sign up for free to add this paper to one or more collections.